文章目录
- 前言
- 人工智能:一种现代的方法 第二章 智能体
- 2.1 环境与智能体
- 2.2 理性概念
- 2.3环境的性质
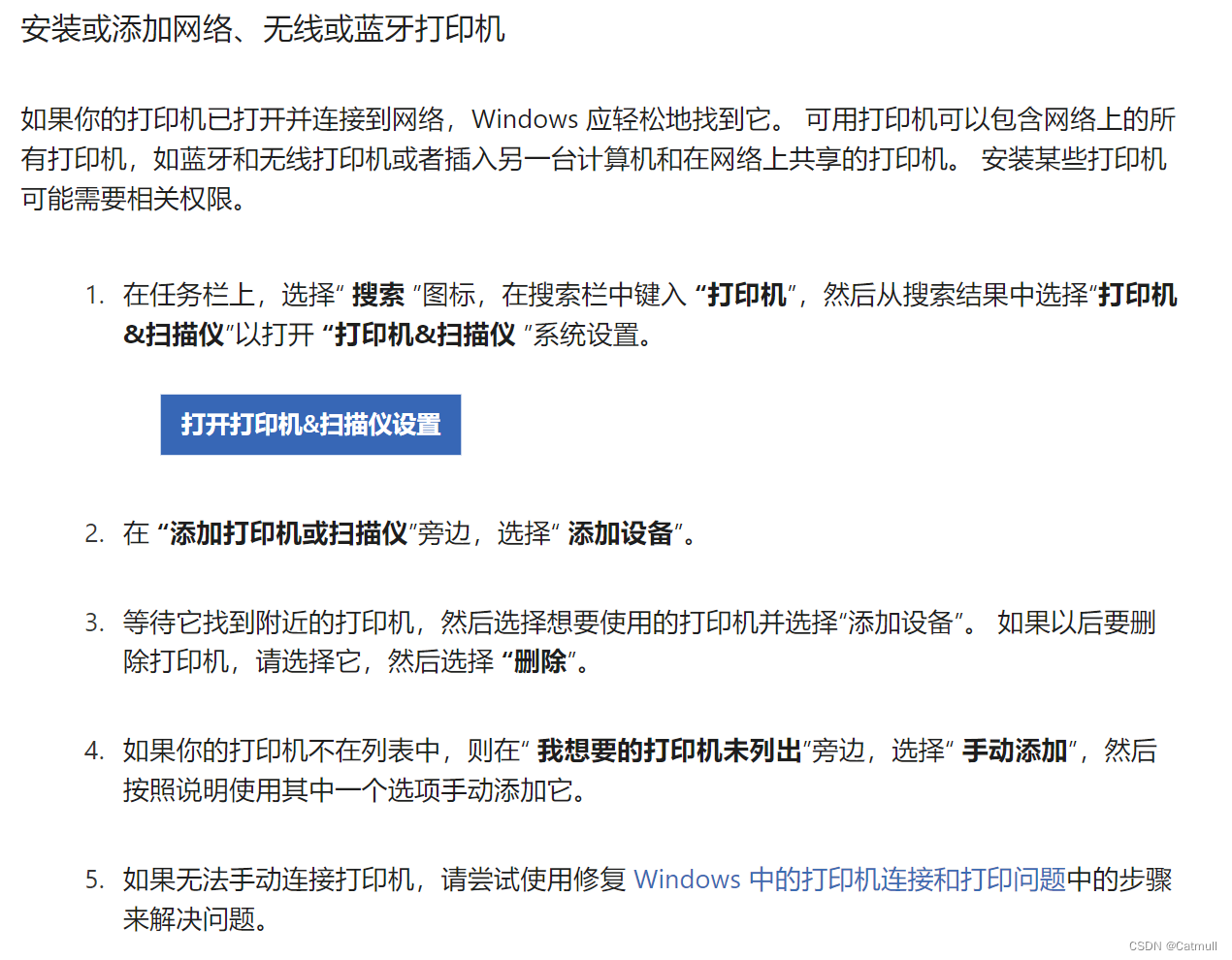
- 2.3.1任务环境的规范描述:PEAS
- 2.3.2环境的性质
- 2.4智能体结构
前言
本章属于本书的开篇,有两个不便于理解的地方一是讲述的概念过于抽象,且本书的例子有点老套,所以本人以自动驾驶为例来理解本章的概念。二是本文的伪代码不太好看懂,于是改为c伪代码
人工智能:一种现代的方法 第二章 智能体
2.1 环境与智能体
智能体(intelligent agent):可以感知其环境,自主行动以实现目标,并可以通过学习提高其性能或使用知识的事物
- 通过传感器感知环境,任何给定时刻Agent的感知序列【输入】
- 通过执行器对所处环境产生影响,Agent的动作执行对环境进行改变【输出】
- 根据感知信息,为达到目标,选择环境中最好的可能行为【Agent函数】
智能体通过感知器(sensors)来感知环境,这可能包括摄像头、麦克风、红外线传感器,或者从数据库或网络获取的数据等。智能体通过执行器(actuators)来影响环境,这可能包括马达、扬声器,或者向数据库或网络发送数据等。
环境是智能体所在的上下文,智能体通过与环境交互来实现其目标。环境可以是物理世界,也可以是一个虚拟的世界,如一个计算机游戏或一个网络环境。环境为智能体提供了感知的来源,并接受智能体的行动。
以自动驾驶汽车为例

智能体是自动驾驶系统。它的目标可能是将乘客安全、准时地送达目的地。为了实现这个目标,它需要感知并理解其周围的环境,并做出适当的决策和行动。
自动驾驶系统通过各种感知器来感知环境,这可能包括摄像头(用于识别道路、行人、其他车辆等)、雷达和激光雷达(用于测量物体的距离和速度)、GPS(用于确定车辆的位置),以及各种车载传感器(用于测量车辆的速度、方向、燃油消耗等)。自动驾驶系统通过执行器来影响环境,这可能包括控制汽车的转向、加速、刹车等。
环境是自动驾驶汽车所在的道路和周围的世界。环境为自动驾驶系统提供了感知的来源,并接受其行动。环境包括了其他的车辆、行人、道路、交通信号、天气条件等。
2.2 理性概念
对每一个可能的感知序列,根据已知的感知序列提供的证据和Agent具有的先验知识,理性Agent应该选择能使其性能度量最大化的动作,理性Agent是相对的
以自动驾驶汽车为例
- 感知序列:自动驾驶汽车通过各种传感器收集到的连续环境信息。这些信息可能包括周围车辆的位置和速度、道路状况、交通信号等。
- 先验知识:自动驾驶汽车在驾驶中应用的已知信息。这可能包括交通规则(如红灯停、绿灯行)、驾驶策略(如保持安全距离、不超速行驶)、以及通过机器学习从大量驾驶数据中学习到的模型(如其他车辆的行为模式、道路状况的影响等)。
- 性能度量:用于评估自动驾驶汽车行驶性能的标准。这可能包括行驶的安全性(如没有交通事故)、准时性(如按时到达目的地)、舒适性(如避免急刹车和急转弯)等。
- 理性的决策:在这个上下文中,一个理性的自动驾驶汽车应该根据其感知序列和先验知识,选择那些预期会最大化其性能度量的行动。
2.3环境的性质
2.3.1任务环境的规范描述:PEAS
在人工智能中,PEAS代表了“性能度量(Performance Measure)”,“环境(Environment)”,“执行器(Actuators)”,“传感器(Sensors)”。这是一个用来描述智能系统的框架。
以自动驾驶汽车为例
- 性能度量(Performance Measure): 这是用来评估Agent行为的标准。例如,对于一个自动驾驶汽车,性能度量可能包括安全性(事故的数量),效率(到达目的地的时间),法规遵守(遵守交通规则)等。
- 环境(Environment): Agent所在的环境。对于自动驾驶汽车,环境可能包括道路,其他车辆,行人,交通信号等。
- 执行器(Actuators): Agent与环境交互的方式。对于自动驾驶汽车,执行器可能包括用来控制车辆的方向盘,油门,刹车等。
- 传感器(Sensors): Agent获取环境信息的方式。对于自动驾驶汽车,传感器可能包括摄像头,雷达,激光雷达等。
| 人工智能系统 | 性能度量 | 环境 | 执行器 | 传感器 |
|---|---|---|---|---|
| 自动驾驶汽车 | 安全性,效率,法规遵守 | 道路,其他车辆,行人,交通信号 | 方向盘,油门,刹车 | 摄像头,雷达,激光雷达 |
| 股票交易机器人 | 利润,风险控制 | 股市,经济新闻,公司财报 | 买卖命令 | 市场数据,新闻,财报 |
| 自动扫地机器人 | 清洁效率,电池使用效率 | 家庭环境,障碍物 | 马达,吸尘器 | 摄像头,红外线传感器,碰撞传感器 |
| 机器人手臂 | 精确度,速度,安全性 | 工作台,工件,其他设备 | 电机,抓取器 | 摄像头,触摸传感器,距离传感器 |
| 推荐系统 | 用户满意度,点击率,购买率 | 用户数据,商品数据 | 显示推荐商品 | 用户行为数据,商品点击数据 |
2.3.2环境的性质
| 环境性质 | 描述 | 例子 |
|---|---|---|
| 完全可观察 vs 部分可观察 | 完全可观察的环境是指Agent可以获取环境的所有信息,而部分可观察的环境是指Agent只能获取环境的部分信息。 | 完全可观察:棋类游戏,部分可观察:扑克牌游戏 |
| 单Agent vs 多Agent | 单Agent环境是指只有一个Agent在进行决策,而多Agent环境是指有多个Agent同时进行决策。 | 单Agent:一个自动驾驶汽车在空旷道路上行驶,多Agent:多个自动驾驶汽车在同一条道路上行驶 |
| 确定的 vs 随机的 | 确定的环境是指在给定状态和行动下,下一个状态是确定的,而随机的环境是指在给定状态和行动下,下一个状态是随机的。 | 确定的:棋类游戏,随机的:股市 |
| 片段式的 vs 延续式的 | 片段式的环境是指任务可以分解成多个独立的片段,每个片段的结果不影响其他片段,而延续式的环境是指任务是连续的,前一步的结果会影响后一步。 | 片段式的:扔骰子的游戏,延续式的:下棋的游戏 |
| 静态的 vs 动态的 | 静态的环境是指环境的状态在不采取行动的情况下不会改变,而动态的环境是指环境的状态在不采取行动的情况下会改变。 | 静态的:棋类游戏,动态的:股市 |
| 离散的 vs 连续的 | 离散的环境是指状态或行动的空间是离散的,而连续的环境是指状态或行动的空间是连续的。 | 离散的:棋类游戏,连续的:自动驾驶汽车的驾驶 |
| 已知的 vs 未知的 | 已知的环境是指环境的规则或动态是已知的,而未知的环境是指环境的规则或动态是未知的。 | 已知的:棋类游戏,未知的:探索未知的环境 |
2.4智能体结构
- 简单反射Agent
- 基于模型的反射Agent
- 基于目标的Agent
- 基于效用的Agent
自动驾驶为例

| 智能体类型 | 行为 | 举例 |
|---|---|---|
| 简单反应型智能体 | 根据当前感知做出反应 | 红灯停,绿灯行 |
| 基于模型的反应型智能体 | 根据当前和过去的感知以及内部的世界模型做出反应 | 知道红绿灯的周期,预测何时灯会变绿,然后决定是否需要完全停车或者是减速等待 |
| 基于目标的智能体 | 根据目标和当前的环境状态做出反应 | 知道红绿灯的周期,如果预计等待时间过长,可能会选择绕行以达到尽快到达目的地的目标 |
| 基于效用的智能体 | 根据效用函数做出反应,效用函数会考虑多个目标和目标之间的权衡 | 知道红绿灯的周期,如果预计等待时间过长,但绕行会增加燃油消耗,会根据效用函数权衡是否绕行 |
简单反应型智能体:
// 简单反应型智能体函数
char* SIMPLE_REFLEX_AGENT(char* percept) {
// 如果感知到红灯,停车
if (strcmp(percept, "red") == 0) {
return "stop";
}
// 如果感知到绿灯,开车
else if (strcmp(percept, "green") == 0) {
return "go";
}
}
基于模型的反应型智能体:
// 基于模型的反应型智能体函数
char* MODEL_BASED_REFLEX_AGENT(char* percept) {
// 持久性变量:状态和模型
static char* state;
static char* model;
// 更新状态
state = UPDATE_STATE(state, percept, model);
// 如果状态是红灯,停车
if (strcmp(state, "red_light") == 0) {
return "stop";
}
// 如果状态是绿灯,开车
else if (strcmp(state, "green_light") == 0) {
return "go";
}
// 如果状态是红灯即将结束,准备开车
else if (strcmp(state, "red_light_almost_over") == 0) {
return "prepare_to_go";
}
}
基于目标的智能体:
// 基于目标的智能体函数
char* GOAL_BASED_AGENT(char* percept) {
// 持久性变量:状态、模型和目标
static char* state;
static char* model;
static char* goal;
// 更新状态
state = UPDATE_STATE(state, percept, model);
// 如果目标是快速到达目的地
if (strcmp(goal, "reach_destination_fast") == 0) {
// 如果状态是红灯,并且红灯的持续时间超过阈值,绕道
if (strcmp(state, "red_light") == 0 && LIGHT_DURATION(state) > THRESHOLD) {
return "detour";
}
// 否则,遵循交通信号
else {
return "follow_traffic_lights";
}
}
}
基于效用的智能体:
// 基于效用的智能体函数
char* UTILITY_BASED_AGENT(char* percept) {
// 持久性变量:状态、模型和效用函数
static char* state;
static char* model;
static int (*utility_function)(char*);
// 更新状态
state = UPDATE_STATE(state, percept, model);
// 获取可能的动作
char* actions[] = POSSIBLE_ACTIONS(state);
// 计算每个动作的效用值
int utility_values[sizeof(actions)/sizeof(char*)];
for (int i = 0; i < sizeof(actions)/sizeof(char*); i++) {
utility_values[i] = UTILITY(actions[i], state, utility_function);
}
// 返回效用值最大的动作
return actions[ARGMAX(utility_values)];
}

![[机缘参悟-118] :如何做到:从无到有,从0到1设计一个新系统或产品?如何做到总是能快速的解决复杂技术难题?](https://img-blog.csdnimg.cn/91dfe26d385a4df3b709dc352c15c7f2.png)