关于Document,Multimodal,RAG最新的进展
- 一:PDFTriage
一:PDFTriage
题目: PDFTriage: Question Answering over Long, Structured Documents
机构:斯坦福大学,Adobe Research
论文: https://arxiv.org/pdf/2309.08872.pdf
任务: 结构化文档QA
Motivation:解决ChatGPT等大语言模型在处理长篇、结构复杂的文档(如PDF、网页、演示文稿等)回答不准的问题,之前的方法会存在如下的一些问题:
- 上下文窗口限制,一次只能处理有限tokens数目,因此需要先进行文档预处理以及分割;
- 文档结构化信息利用不足,比如页面,标题,表格等;查询不准确;信息获取不全;
方法:PDFTriage通过允许模型基于结构或内容检索上下文来缓解上述问题。它首先将PDF转化为结构化文档元数据,为模型提供了关于文档结构的信息,然后通过使用一系列基于模型的可调用检索函数和文档结构元数据,对提示进行增强,使模型能够从文档中检索上下文。通过提供结构和能够查询该结构的能力,PDFTriage增强模型能够可靠地回答一些常规的检索增强LLMs不能回答的问题。参考: PDFTriage:长篇结构化文件的问答系统
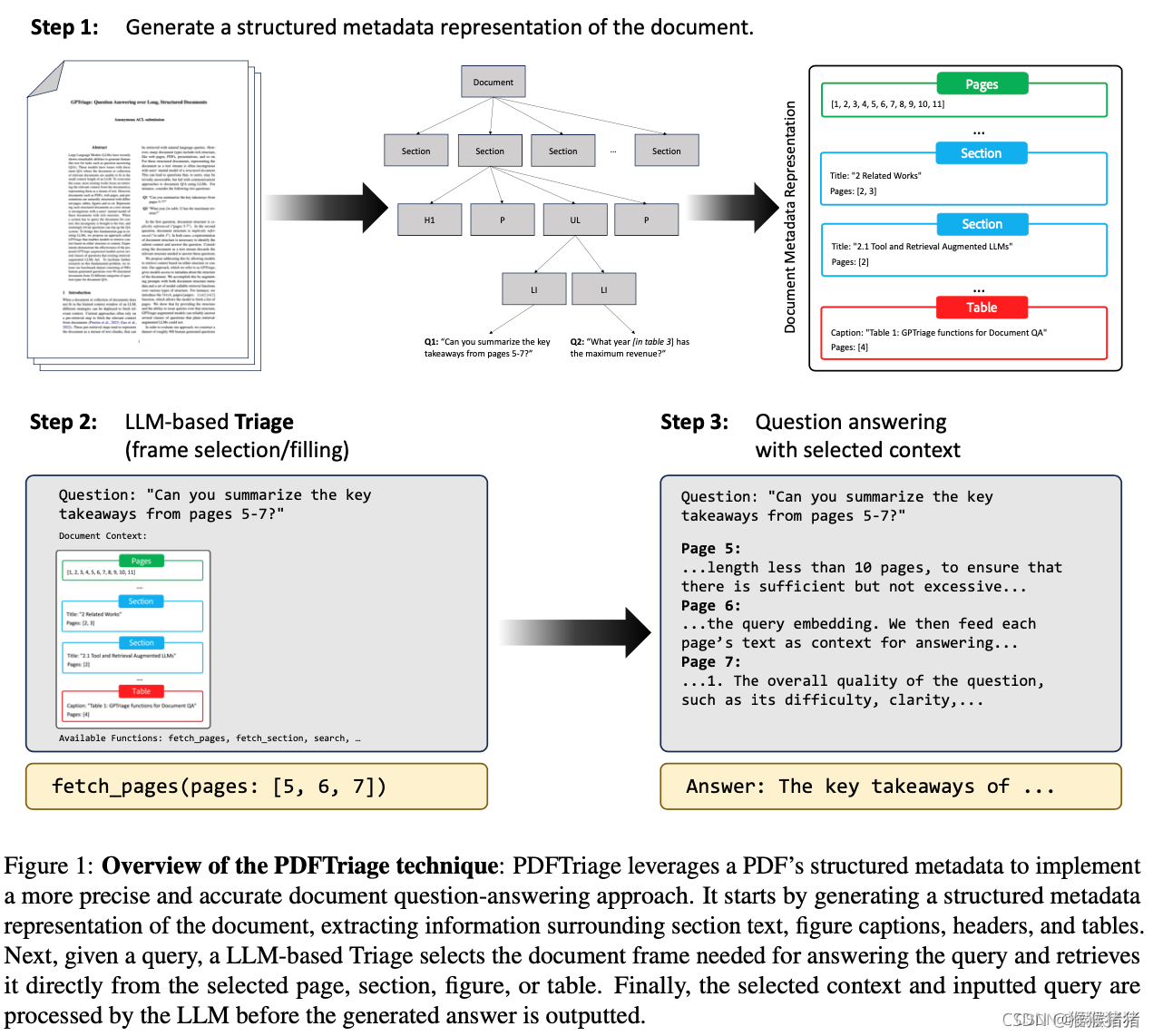
- 结构化元数据提取:使用Adobe Extract API来解析PDF文档,提取出章节、章节标题、页码信息、表格和图像等结构元素。然后用json格式进行结构化组织,并且作为prompts。
- 文档内容检索: 定义了五个不同的函数:fetch_pages,fetch_sections,fetch_table,fetch_figure和retrieve。fetch_pages函数允许模型获取一组页面,fetch_sections函数允许模型获取一组章节,fetch_table函数允许模型获取表格,fetch_figure函数允许模型获取图像,retrieve函数则提供其他类型的检索功能。模型通过调用这些函数来查询文档,以获取回答问题所需的信息。
- 基于检索内容进行QA
一些结论:
- 在作者自建的评测集上,PDFTriage生成的答案在多页任务(如结构问题和表格推理)中排名更高,而在一般文本任务(如分类和文本问题)中排名较低。然而,在所有问题类别中,PDFTriage都优于页面检索和块检索方法。
- PDFTriage能够处理不同长度的文档,并且在处理不同长度的文档时表现一致。因为能根据结构信息和内容信息,选择相关的上下文,并最小化无关信息,更好地利用了有限的上下文窗口,从而发挥了更好的性能。
- PDFTriage的答案质量与文档长度之间几乎没有相关性。
- 未来,PDFTriage在处理多模态问题(如表格和图像)时还可以进一步改进其性能
一些坑:
并没有对LLM提出一些建设性的意见,直接用的是GPT强大的能力;
用了adobe的PDF结构化解析能力,但是官方是未完全开源的,可能如下评论所言,kosmos2.5以及nougat是一种可能的替代方案。






![前沿重器[37] | 大模型对任务型对话的作用研究](https://img-blog.csdnimg.cn/img_convert/6404b49ac74071254823683c0bb37cfd.png)