一、介绍
在数据驱动的决策时代,收集、处理和分析数据的过程在从医疗保健到金融,从营销到研究的各个领域都发挥着举足轻重的作用。数据分析的基本步骤之一是正确识别数据集中的标签或类别。然而,这项看似简单的任务可能充满挑战,尤其是在发生数据泄漏时。标签识别中的数据泄露可能会产生深远的影响,影响数据分析的可靠性和完整性。本文探讨了标签识别中数据泄漏的概念、原因、后果以及减轻其影响的策略。
标签识别中的数据泄漏:批判性分析告诉我们,在数据领域,微小的泄漏可能会造成后果的浪潮。谨慎处理数据,让透明度成为分析海洋中的指南针。
二、了解数据泄漏
数据泄露是指数据集中敏感信息或属性的意外或未经授权的暴露。在标签识别方面,当在模型训练过程中本应隐藏的信息被无意中泄露时,就会发生数据泄露,导致模型从不应访问的数据中学习。这可能会导致误导性结果和对模型性能的高估。
三、数据泄露的原因
标签识别中的数据泄漏可能源于各种来源:
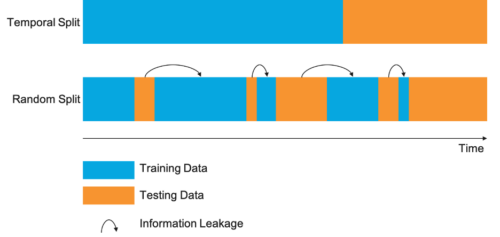
- 数据拆分不足:将数据集划分为训练和测试子集时,确保标签在训练期间对模型保持隐藏至关重要。未能正确隔离数据可能会导致意外的数据泄露。
- 泄漏通过 特点:有时,模型训练中使用的特征包含有关标签的信息。当要素派生自标注本身时,或者某些要素与标注之间存在强相关性时,可能会发生这种情况。
- 颞部渗漏:在时间序列数据中,如果使用未来信息来预测过去的标签,则可能会发生数据泄露。例如,使用未来的股票价格来预测历史市场走势会引入数据泄露。
- 外部数据:合并外部数据源而未将其与训练过程正确隔离可能会导致数据泄漏,因为这些数据源可能包含有关模型不应访问的标签的信息。
四、数据泄露的后果
标签识别中的数据泄露可能会产生深远的后果:
- 高估模型性能:当模型无意中从标签中学习时,它可能在训练期间表现得异常出色,但无法泛化到新的、看不见的数据。这种对模型性能的高估可能会导致错误的决策。
- 模型鲁棒性降低:受数据泄漏影响的模型在实际场景中往往不太可靠,因为它们依赖于新数据中可能不存在的模式。
- 偏倚结果:数据泄露会给模型带来偏差,导致模型做出错误的预测,尤其是在涉及敏感信息(例如贷款审批或医疗诊断)的情况下。
- 失去信任:数据泄露会侵蚀对数据分析过程和所用模型的信任,因为利益相关者可能会质疑结果的可靠性。
五、缓解数据泄漏
减少标签识别中的数据泄漏对于确保数据分析的完整性至关重要。可以采用以下几种策略:
- 仔细的数据拆分:确保数据拆分过程将训练数据和测试数据清晰地分开,并在模型训练期间隐藏标签。
- 功能选择:仔细检查特征是否存在任何潜在泄漏,并根据需要删除或转换它们,以防止模型学习标签。
- 交叉验证: 采用交叉验证技术来更准确地评估模型性能并降低数据泄露的风险。
- 定期审核数据源:定期查看数据源,以识别和消除任何潜在的泄漏点,例如可能包含标签的外部数据。
- 专家咨询:在复杂的情况下,请考虑让领域专家参与进来,他们可以深入了解数据泄露的可能性并协助防止数据泄露。
六、代码
创建一个完整的 Python 代码示例来说明数据集和绘图的数据泄漏可能是一项复杂的任务,因为它取决于特定的数据集和场景。但是,我可以为您提供一个使用合成数据集和绘图的数据泄漏的简化示例。
在此示例中,我们将创建一个发生数据泄漏的数据集,然后使用绘图将其可视化。为简单起见,我们将使用合成数据和流行的 scikit-learn 库来实现此目的。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# Create a synthetic dataset
X, y = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_repeated=0, random_state=42)
# Introduce data leakage by using a feature directly related to the target variable
leakage_feature = y * 5 + np.random.normal(0, 1, len(y))
X_leak = np.column_stack((X, leakage_feature))
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X_leak, y, test_size=0.3, random_state=42)
# Train a logistic regression model
model = LogisticRegression()
model.fit(X_train, y_train)
# Evaluate the model on the testing set
test_accuracy = model.score(X_test, y_test)
# Visualize the data and model decision boundary
plt.figure(figsize=(12, 5))
# Plot the data points with color representing the true labels
plt.subplot(1, 2, 1)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Paired)
plt.title("True Labels")
# Plot the data points with color representing the predicted labels
plt.subplot(1, 2, 2)
plt.scatter(X[:, 0], X[:, 1], c=model.predict(X_leak), cmap=plt.cm.Paired)
plt.title("Predicted Labels")
plt.show()
# Print accuracy results
print(f"Testing Accuracy: {test_accuracy:.2f}")在此代码中:
- 我们使用
make_classification,scikit-learn 创建一个合成数据集。 - 我们通过创建一个与目标变量直接相关的新特征
leakage_feature() 来引入数据泄漏。 - 我们将数据集拆分为训练集和测试集。
- 我们在具有数据泄漏的数据集上训练逻辑回归模型。
- 我们使用两个图可视化数据点和模型的决策边界。
- 最后,我们打印训练和测试的准确性。
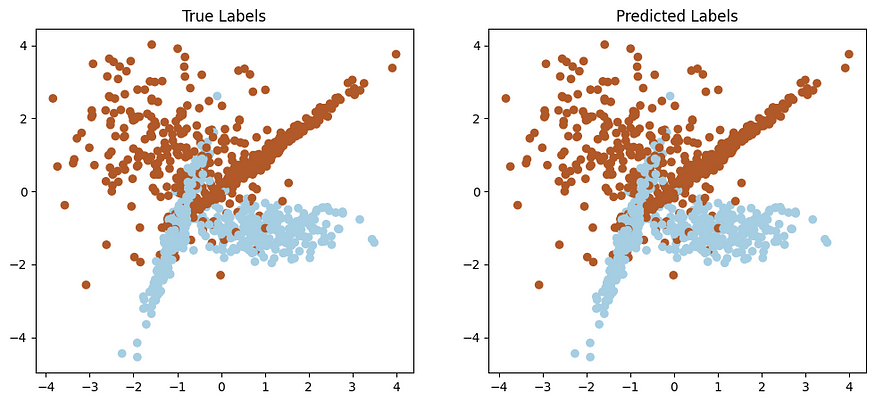
Testing Accuracy: 1.00这个例子的关键点是数据集中引入的leakage_feature直接依赖于目标变量'y',导致数据泄漏。结果,该模型在训练中人为地实现了高精度,但无法正确泛化,如可视化所示。
七、结论
标签识别中的数据泄漏是一个关键问题,可能会破坏数据分析的完整性。了解数据泄露的原因、后果和缓解策略对于数据科学家、机器学习从业者和决策者至关重要。通过实施谨慎的数据处理和模型训练实践,可以最大限度地降低与数据泄露相关的风险,确保在数据分析和机器学习领域获得更可靠和准确的结果。




![[BUUCTF NewStar 2023] week5 Crypto/pwn](https://img-blog.csdnimg.cn/b72e3abe449d476b85135804cb1a0304.png)