目录
一、数据及分析对象
二、目的及分析任务
三、方法及工具
四、数据读入
五、数据理解
六、数据预处理
七、生成频繁项集
八、计算关联度
九、可视化
一、数据及分析对象
数据集链接:Online Retail.xlsx
该数据集记录了2010年12月01日至2011年12月09日的541909条在线交际记录,包含以下8个属性:
(1)InvoiceNo:订单编号,由6位整数表示,退货单号由字母“C”开头;
(2)StockCode:产品编号,每个不同的产品由不重复的5位整数表示;
(3)Description:产品描述;
(4)Quantity:产品数量,每笔交易的每件产品的数量;
(5)InvoiceDate:订单日期和时间,表示生成每笔交易的日期和时间;
(6)UnitPrice:单价,每件产品的英镑价格;
(7)CustomerID:顾客编号,每位客户由唯一的5位整数表示;
(8)Country:国家名称,每位客户所在国家/地区的名称。
二、目的及分析任务
理解Apriori算法的具体应用
(1)计算最小支持度为0.07的德国客户购买产品的频繁项集。
(2)计算最小置信度为0.8且提升度不小于2的德国客户购买产品的关联关系。
三、方法及工具
能够实现Aprior算法的Python第三方工具包有mlxtend、kiwi-apriori、apyori、apriori_python、efficient-apriori等,比较常用的是mlxtend、apriori_python、efficient-apriori,本项目采用的是mlxtend包。
四、数据读入
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rulesdf_Retails=pd.read_excel("C:\\Users\\LEGION\\AppData\\Local\\Temp\\360zip$Temp\\360$0\\Online Retail.xlsx")
df_Retails.head()
五、数据理解
调用shape属性查看数据框df_Retails的形状。
df_Retails.shape![]()
查看列名称
df_Retails.columnsIndex(['InvoiceNo', 'StockCode', 'Description', 'Quantity', 'InvoiceDate', 'UnitPrice', 'CustomerID', 'Country'], dtype='object')
对数据框df_Retails进行探索性分析。
df_Retails.describe()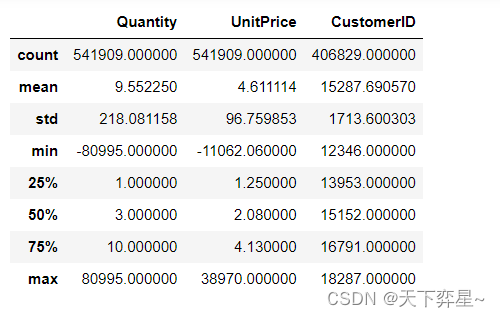
其中,count、mean、std、min、25%、50%、75%和max的含义分别为个数、均值、标准差、最小值、上四分位数、中位数、下四分位数和最大值。
除了describe()方法,还可以调用info()方法查看样本数据的相关信息概览:
df_Retails.info()
从输出结果可以看出,数据框df_Retails的Description和CustomerID两列有缺失值。
看国家一列:
df_Retails.Country.unique()array(['United Kingdom', 'France', 'Australia', 'Netherlands', 'Germany', 'Norway', 'EIRE', 'Switzerland', 'Spain', 'Poland', 'Portugal', 'Italy', 'Belgium', 'Lithuania', 'Japan', 'Iceland', 'Channel Islands', 'Denmark', 'Cyprus', 'Sweden', 'Austria', 'Israel', 'Finland', 'Bahrain', 'Greece', 'Hong Kong', 'Singapore', 'Lebanon', 'United Arab Emirates', 'Saudi Arabia', 'Czech Republic', 'Canada', 'Unspecified', 'Brazil', 'USA', 'European Community', 'Malta', 'RSA'], dtype=object)
df_Retails["Country"].unique()array(['United Kingdom', 'France', 'Australia', 'Netherlands', 'Germany', 'Norway', 'EIRE', 'Switzerland', 'Spain', 'Poland', 'Portugal', 'Italy', 'Belgium', 'Lithuania', 'Japan', 'Iceland', 'Channel Islands', 'Denmark', 'Cyprus', 'Sweden', 'Austria', 'Israel', 'Finland', 'Bahrain', 'Greece', 'Hong Kong', 'Singapore', 'Lebanon', 'United Arab Emirates', 'Saudi Arabia', 'Czech Republic', 'Canada', 'Unspecified', 'Brazil', 'USA', 'European Community', 'Malta', 'RSA'], dtype=object)
查看各国家的购物数量:
df_Retails["Country"].value_counts()United Kingdom 495478 Germany 9495 France 8557 EIRE 8196 Spain 2533 Netherlands 2371 Belgium 2069 Switzerland 2002 Portugal 1519 Australia 1259 Norway 1086 Italy 803 Channel Islands 758 Finland 695 Cyprus 622 Sweden 462 Unspecified 446 Austria 401 Denmark 389 Japan 358 Poland 341 Israel 297 USA 291 Hong Kong 288 Singapore 229 Iceland 182 Canada 151 Greece 146 Malta 127 United Arab Emirates 68 European Community 61 RSA 58 Lebanon 45 Lithuania 35 Brazil 32 Czech Republic 30 Bahrain 19 Saudi Arabia 10 Name: Country, dtype: int64
可以看出,英国的客户购买商品数量最多,为495478条记录,其次是德国的客户,为9495条记录。
查看订单编号(InvoiceNo)一列中是否有重复的值。
df_Retails.duplicated(subset=["InvoiceNo"]).any()True
订单编号有重复表示同一个订单中有多个同时购买的产品,符合Apriori算法的数据要求。
六、数据预处理
查看数据中是否有缺失值。
df_Retails.isna().sum()InvoiceNo 0 StockCode 0 Description 1454 Quantity 0 InvoiceDate 0 UnitPrice 0 CustomerID 135080 Country 0 dtype: int64
可以看出,Description的缺失值有1454条,CustomerID的缺失值有135080条。
将商品名称(Description)一列的字符串头尾的空白字符删除:
df_Retails['Description']=df_Retails['Description'].str.strip()再次查看数据集形状;
df_Retails.shape(541909, 8)
查看商品名称(Description)一列的缺失值个数:
df_Retails['Description'].isna().sum()1455
在对商品名称(Description)一列进行空白字符处理后,缺失值增加了一个。去除所有的缺失值:
df_Retails.dropna(axis=0,subset=['Description'],inplace=True)再次查看数据集形状:
df_Retails.shape(540454, 8)
检查此时的数据集是否还有缺失值:
df_Retails['Description'].isna().sum()0
可以看出,数据框df_Retails中商品名称(Description)一列的缺失值已全部删除。
由于退货的订单由字母“C”开头,删除含有C字母的已取消订单:
df_Retails['InvoiceNo']=df_Retails['InvoiceNo'].astype('str')
df_Retails=df_Retails[~df_Retails['InvoiceNo'].str.contains('C')]df_Retails.shape(531166, 8)
将数据改为每一行一条记录,并考虑到内存限制以及德国(Germany)的购物数量位居第二,因此在本项目中只计算德国客户购买的商品的频繁项集及关联规则,全部计算则计算量太大。
df_ShoppingCarts=(df_Retails[df_Retails['Country']=="Germany"].groupby(['InvoiceNo','Description'])['Quantity'].sum().unstack()
.reset_index().fillna(0).set_index('InvoiceNo'))
df_ShoppingCarts.shape(457, 1695)
df_ShoppingCarts.head()
德国的购物记录共有457条,共包含1695件不同的商品。
查看订单编号(InvoiceNo)一列是否有重复的值:
df_Retails.duplicated(subset=["InvoiceNo"]).any()True
订单编号有重复表示同一个订单中有多个同时购买的产品,符合Apriori算法的数据要求。由于apriori方法中df参数允许的值为0/1或True/False,在此将这些项在数据框中转换为0/1形式,即转换为模型可接受格式的数据即可进行频繁项集和关联度的计算。
def encode_units(x):
if x<=0:
return 0
if x>=1:
return 1
df_ShoppingCarts_sets=df_ShoppingCarts.applymap(encode_units)七、生成频繁项集
mlxtend.frequnet_patterns的apriori()方法可进行频繁项集的计算,将最小支持度设定为0.07:
df_Frequent_Itemsets=apriori(df_ShoppingCarts_sets,min_support=0.07,use_colnames=True)
df_Frequent_Itemsets

查看数据框df_Frequent_Itemsets的形状:
df_Frequent_Itemsets.shape(39, 2)
可以看出,满足最小支持度0.07的频繁项集有39个。
八、计算关联度
将提升度(lift)作为度量计算关联规则,并设置阈值为1,表示计算具有正相关关系的关联规则。该任务由mlxtend.frequent_patterns的association_rules()方法实现:
df_AssociationRules=association_rules(df_Frequent_Itemsets,metric="lift",min_threshold=1)
df_AssociationRules
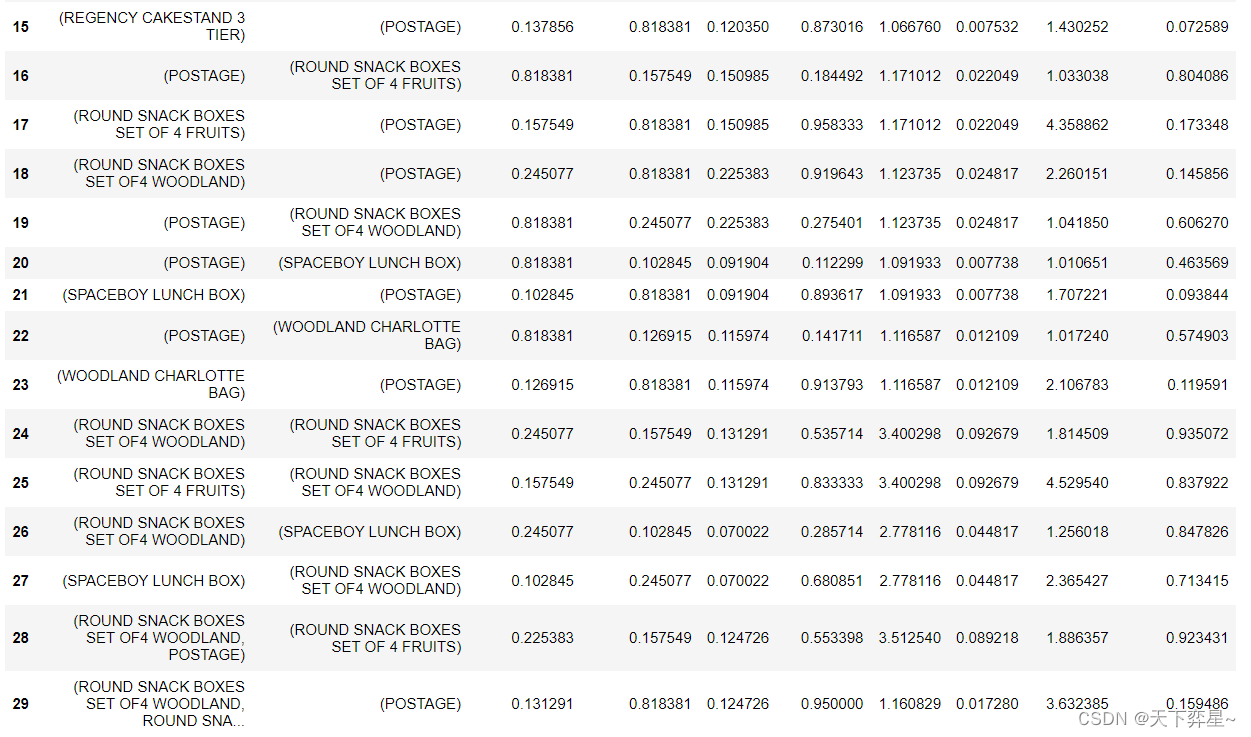

从结果可以看出各项关联规则的详细信息。
以第一条关联规则为{6 RIBBONS RUSTIC CHARM}—>{POSTAGE}为例,{6 RIBBONS RUSTIC CHARM}的支持度为0.102845,{POSTAGE}的支持度为0.818381,项集{{6 RIBBONS RUSTIC CHARM,POSTAGE}的支持度为0.091904,客户购买6 RIBBONS RUSTIC CHARM的同时也购买POSTAGE的置信度为0.893617,提升度为1.091933,规则杠杆率(即当6 RIBBONS RUSTIC CHARM和POSTAGE一起出现的次数比预期多)为0.007738,规则确信度(与提升度类似,但用差值表示,确信度越大则6 RIBBONS RUSTIC CHARM和POSTAGE关联关系越强)为1.707221。
查看数据框df_AssocaitionRules的形状:
df_AssociationRules.shape(34, 10)
可以看出,总共输出了34条关联规则。接着筛选提升度不小于2且置信度不小于0.8的关联规则:
df_A=df_AssociationRules[(df_AssociationRules['lift']>2)&(df_AssociationRules['confidence']>=0.8)]
df_A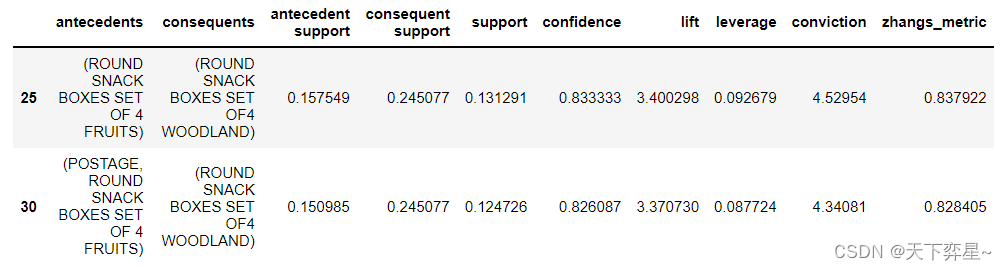
由此可知,提升度不小于2且满足最小置信度0.8的强关联规则有两条,分别为:{ROUND SNACK BOXES SET OF 4 FRUITS}—>{ROUND SNACK BOXES SET OF4 WOODLAND}和{POSTAGE, ROUND SNACK BOXES SET OF 4 FRUITS}—>{ROUND SNACK BOXES SET OF4 WOODLAND}。
九、可视化
绘制出提升度不小于1的关联规则的散点图,横坐标设置为支持度,纵坐标为置信度,散点的大小表示提升度。该可视化任务由matplotlib.pyplot的scatter函数实现:
import matplotlib.pyplot as plt
#将点的大小放大20倍
plt.scatter(x=df_AssociationRules['support'],y=df_AssociationRules['confidence'],s=df_AssociationRules['lift']*20)
plt.show()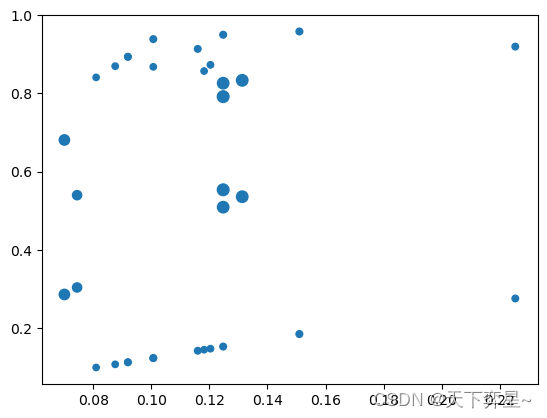










![[黑马程序员SpringBoot2]——运维实用篇](https://img-blog.csdnimg.cn/cc64e94f957e4443b96b16d19fb11a53.png)