Comparing Code Explanations Created by Students and Large Language Models
- 写在最前面
- 总结
- 思考
- 背景介绍
- 编程教育—代码理解和解释技能培养
- 编程教育—解决方案
- 研究问题
- 研究结果
- 相关工作
- Code Comprehension
- Pedagogical Benifis of code explanation
- Large Language Models in CS Education
- Contribution of this paper
- 方法与分析
- 数据集
- 数据来源
- 数据收集
- 数据抽样
- 数据分析
- 描述性统计
- 学生和LLM生成的代码解释质量差异
- 讨论与总结
- 来自 GPT-3 和学生的好坏解释示例
- 1
- 2
- 3
- 4
- 代码解释的特征
- 学生和LLM创建的代码解释之间的差异
- GitHub Copilot工具
- 缺点:过度依赖LLM
- What Do Students Value in Code Explanations?
- Limitations
- Future work
写在最前面
本文为邹德清教授的《网络安全专题》课堂笔记系列的文章,本次专题主题为AIGC。
李智佳同学分享了Comparing Code Explanations Created by Students and Large Language Models《学生和大型语言模型创建的代码解释比较》
https://doi.org/10.48550/arXiv.2304.03938
Submitted on 8 Apr 2023
Computer Science > Computers and Society
感觉这篇有点偏gpt生成的代码解释分析,以及和学生生成解释的对比(用的统计问卷分析,序数选项:非参数 Mann-Whitney U 检验)。
不是常规论文的那种思路——提升gpt生成性能
总结
本文通过让学生创建代码解释,然后对比评估他们同伴的代码解释以及 GPT-3 创建的代码解释。实验发现:
1、学生和 LLM 创建的代码解释在感知长度和实际长度上没有差异,
2、但学生对 GPT-3 创建的代码解释的准确性和可理解性的评价都更高。
3、此外,我们发现学生更喜欢详细的解释,而不是简明扼要的高层次解释。
4、LLM 创建的代码解释对练习代码阅读和解释的学生很有益处。
思考
1、随着基于LLM的人工智能代码生成器(如 GitHub Copilot)的出现,未来软件开发人员的角色将越来越多地是评估 LLM 生成的源代码,而不是从头开始编写代码。
2、GPT在面对错误代码时将如何解释?是否可以发现错误并改正?
背景介绍
编程教育—代码理解和解释技能培养
理解和解释代码的能力是计算机科学专业学生需要培养的一项重要技能。学生解释代码的能力与编写、跟踪代码等其他技能之间的关系,在计算教育领域已经有了广泛的研究。特别是,在高度抽象的水平上描述代码如何在所有可能的输入中表现的能力与代码写作技巧密切相关。
然而,学生很难解释自己的代码,而且解释代码的能力也是一项难以培养的技能,其并未明确列为学习目标。培养能够准确、简洁地理解和解释代码的专业技能对许多学生来说是一个挑战。
编程教育—解决方案

研究问题
问题 1 学生和LLM创建的代码解释在准确性、长度和可理解性方面有多大差异?
问题 2 学生重视代码解释的哪些方面?
研究结果
本文通过对比学生与LLMs创建的代码解释在准确性、可理解性和长度方面的优劣,评估了LLMs在生成解释方面的潜力。实验结果表明,LLM和学生生成的代码解释在理想长度上相当,LLM创建的、可按需自动生成的解释更容易理解且更准确。这对将这些模型纳入入门编程教育具有重要意义。
相关工作
Code Comprehension
代码理解技能对于帮助编程学生理解代码片段背后的逻辑和功能非常重要,程序员可以采用各种代码理解策略,从而灵活地理解编程概念。

Pedagogical Benifis of code explanation
代码解释可以帮助学生理解代码片段是如何执行的 ,从而帮助学生提高编写自己代码的推理能力 。它们还能通过分解复杂的概念来减轻压力。

Large Language Models in CS Education
基于人工智能的代码生成模型引发了计算教育研究领域的极大兴趣,初步研究主要集中在评估这些模型在解决入门课程中常见的编程问题时的性能。
例如“The Robots are Coming”[13],它利用了 Codex 模型和一个从高分终结性评估中提取的私人编程问题库。研究结果表明,Codex 生成的解决方案在评估中的得分率约为 80%。
此外,还有一些辅助研究对基于人工智能的代码生成模型生成学习资源的潜力进行了调查。
例如,Sarsa 等人[36]探索了使用 Codex 模型生成代码解释和编程练习的各种提示和方法,发现它经常生成新颖和高质量的资源。
MacNeil 等人[24]使用 GPT-3 模型生成简短代码片段的解释,然后将这些解释和相应的代码一起以在线电子书的形式呈现给学生。
问题:这种参与度低于预期,学生既没有参与代码示例的创建,也没有参与附带的解释。

Contribution of this paper
本研究通过直接比较学生生成的代码解释与人工智能模型生成的代码解释,做出了独特的贡献。
虽然之前的研究已经证明,LLM 可以生成专家和新手都认为是高质量的代码解释,但这是第一项调查学生如何评价同伴创建的代码解释与人工智能模型生成的代码解释的研究。
方法与分析
数据集
数据来源
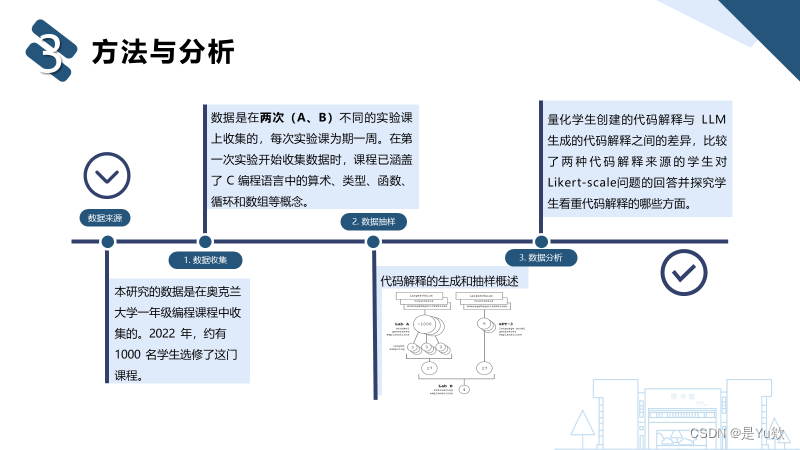
本研究的数据是在奥克兰大学一年级编程课程中收集的。2022 年,约有 1000 名学生选修了这门课程。
数据收集
数据是在两次(A、B)不同的实验课上收集的,每次实验课为期一周。在第一次实验开始收集数据时,课程已涵盖了 C 编程语言中的算术、类型、函数、循环和数组等概念。
在第一个实验(Lab A)中,学生们看到了三个函数定义,并被要求总结和解释每个函数的预期目的。第二个实验(Lab B)中,学生们被要求对随机抽取的4份代码解释(一部分来自学生,一部分来自GPT-3)的准确性、可理解性和长度进行评分。
最后,学生回答以下问题:你们认为好的代码解释最有用的特征是什么?代码解释的哪些方面对你有用?
数据抽样
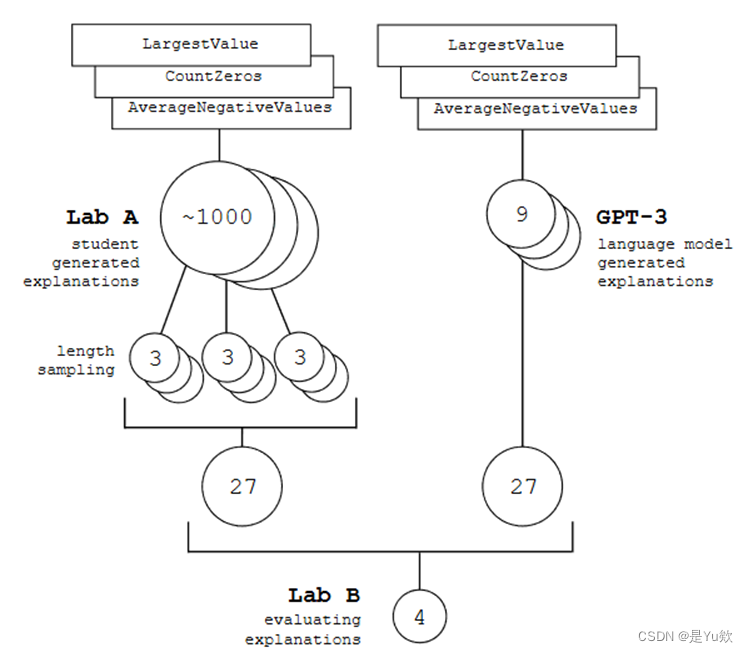
代码解释的生成和抽样概述
在Lab A中3个函数分别提交了963份解释,根据代码解释字长分为3类,每类抽取3条,共27条,研究又增加了27条GPT-3创建的解释。
在Lab B中,每个学生从54条解释中随机抽取4条,并对其评分:
(5个选项:非常不同意、不同意、中立、同意、非常同意)
A该解释通俗易懂
B该解释准确概括了代码
C该解释长度理想
D该解释非常准确概括了代码
数据分析
量化学生创建的代码解释与 LLM 生成的代码解释之间的差异,比较了两种代码解释来源的学生对Likert-scale问题的回答并探究学生看重代码解释的哪些方面。
为了回答问题 1 ,比较了两种代码解释来源的学生对Likert-scale问题的回答。由于Likert-scale表回答数据是序数,本文使用了非参数 Mann-Whitney U 检验来检验学生和LLM代码解释之间的差异。检验了:
①在代码解释是否通俗易懂方面是否存在差异;
②在代码解释是否准确概括代码方面是否存在差异;
③在代码解释长度是否理想方面是否存在差异。
④研究了代码解释的实际长度,以形成学生和 GPT-3 之间代码解释长度是否存在差异的基线,这有助于解释其他研究结果。
对于四次 Mann-Whitney U 检验,使用 Bonferroni 校正 p < 0.05/4 作为统计显著性的临界值。
为了回答问题 2,即研究学生重视代码解释的哪些方面,对随机抽取的 100 份学生对开放式问题 "代码解释的哪些方面对你有用?"的回答进行了专题分析。
描述性统计
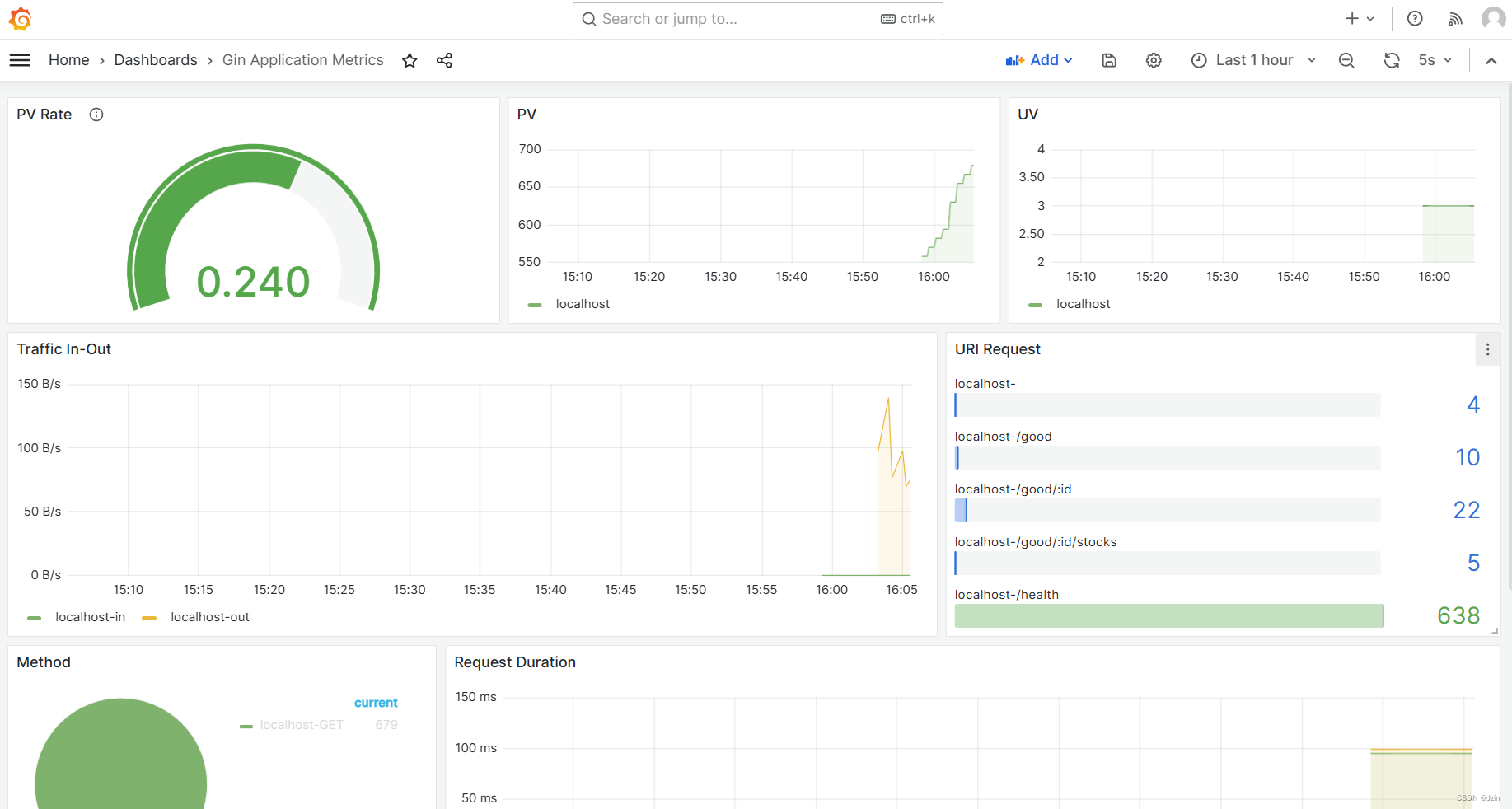
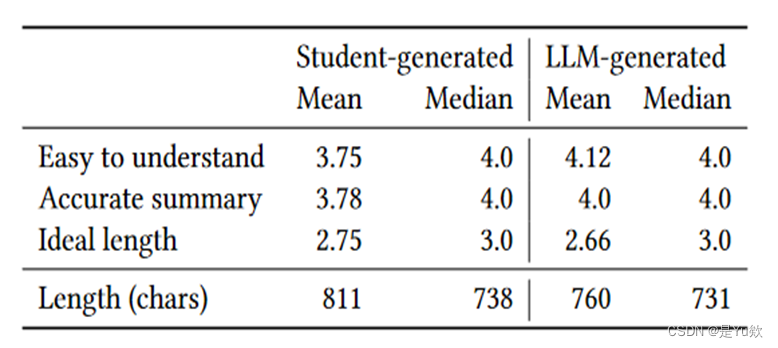
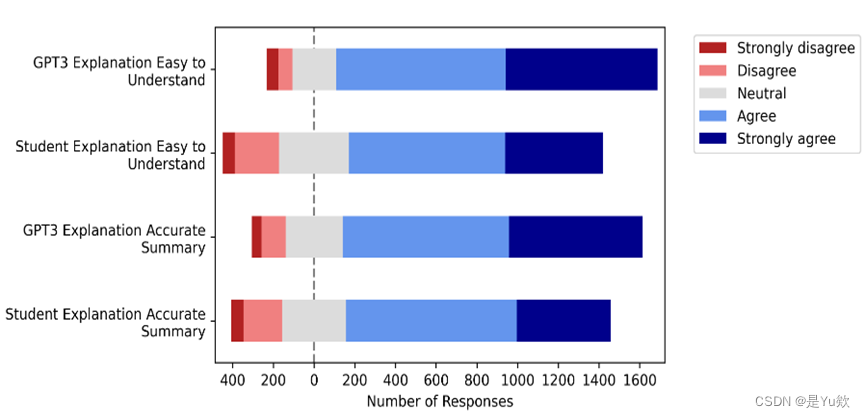
共有 954 名学生参与了评估代码解释质量的活动。表 1 显示了这些回答的平均值和中位数,以及学生创建的代码解释和 LLM 生成的代码解释的平均长度。图 3 进一步概括了回答的分布情况,对不同的回答分别用不同的颜色进行了标注,并对不同的回答值进行了直观的比较。
学生和LLM生成的代码解释质量差异
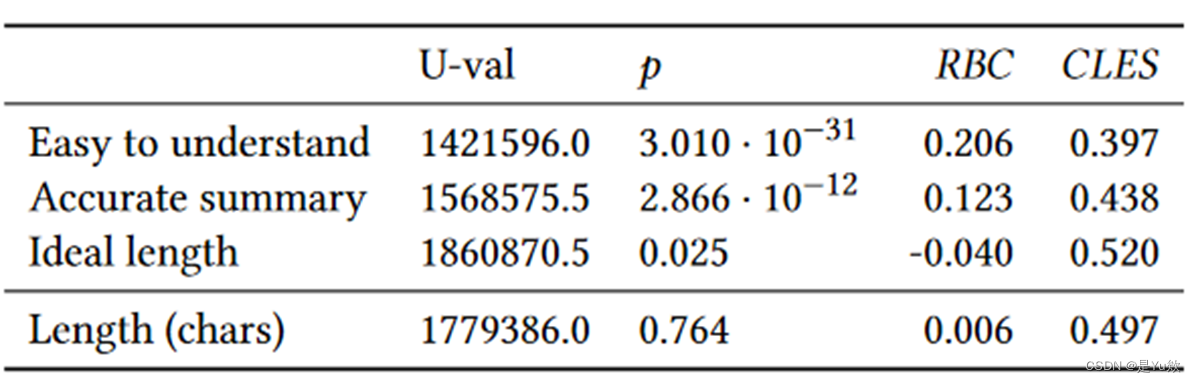
本文进行了Mann-Whitney U 检验,以研究学生和 LLM 生成的代码解释之间的差异。从表 2 中的共同语言效应大小(CLES)来看,学生和LLM生成的代码解释对中,学生生成的代码解释更容易理解的比例约为 40%,而LLM的比例约为 60%。同样,在学生生成的代码解释和LLM生成的代码解释中,学生生成的代码解释是更准确的摘要的比例约为 44%,而LLM生成的代码解释是更准确的摘要的比例约为 56%。根据 Bonferroni 修正,学生对代码解释长度是否理想的看法在统计学上没有显著差异,代码解释的实际长度在统计学上也没有显著差异。
讨论与总结
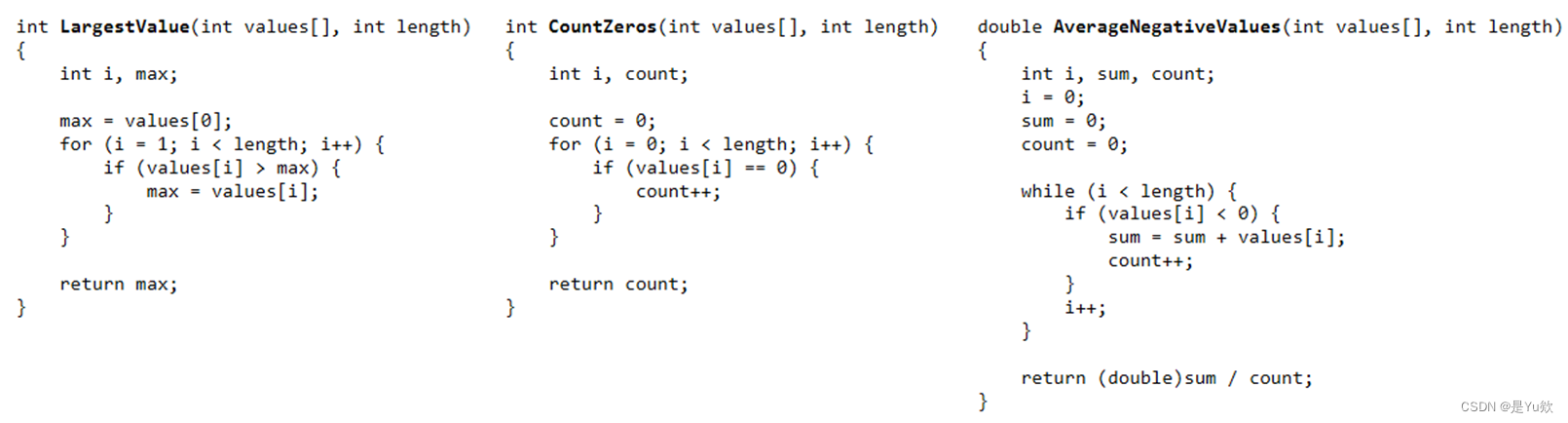
来自 GPT-3 和学生的好坏解释示例
为了说明 GPT-3 和学生创建的解释类型,本文介绍了四个学生认为质量不同的解释示例–LLM 和学生创建的最大值函数的最高和最低解释。
学生们更喜欢以逐行的形式来说明函数是什么和如何操作的解释。
许多学生还认为,好的解释应说明代码的输入和输出。糟糕的解释则是遗漏了代码的某些细节,同时篇幅过长或过短。例如,解释可能会在较高的层次上说明代码的目的,但没有详细说明使用了哪些数据结构,或函数的输入是什么。
此外,论文发现所有 LLM 生成的解释都以 "此代码片段 "或 "此代码片段的目的 "开头,而学生生成的解释则差异较大。这部分是由于 LLM 的提示,它被要求解释 "以下代码片段 "的目的。不过,学生和LLM的大多数解释一般都遵循类似的结构:函数的目的、代码分析以及最后的返回输出。
1

2


3

4

代码解释的特征
在专题分析(n=100)中,发现学生们几乎各占一半,分别侧重于代码的特定方面和一般方面,有些学生的回答还包括这两方面。在关注代码的具体方面时,学生描述了逐行解释的必要性(21%)。学生们还关注更低级别的细节,如变量名、输入和输出参数(36%)以及术语定义(8%)。一些学生要求提供代码解释中很少包含的其他方面。例如,学生要求提供示例、模板以及编写代码背后的思考过程。
学生们广泛地评论了好的解释应具备的品质。篇幅是一个重要方面,40% 的学生明确评论了解释的篇幅。然而,对于最理想的确切长度并没有达成明确的共识。相反,评论往往侧重于效率;用最少的字数传达最多的信息。学生似乎对简短的解释评价不高。部分原因可能是这些解释几乎或根本没有提供函数中不明显的额外信息,例如函数名称。
学生作为新手,可能更喜欢更详细的解释,因为这有助于他们更好地学习和理解代码中实际发生的事情。
学生和LLM创建的代码解释之间的差异
GitHub Copilot工具
将重点从编写代码转移到理解代码的目的、评估生成的代码是否合适以及根据需要修改代码,从而使代码理解成为一项更加重要的技能。而,LLM 不仅可以帮助学生生成代码,还可以通过创建代码解释(可用作代码理解练习)来帮助学生理解代码。
缺点:过度依赖LLM
对抗过度依赖LLM创建的代码解释的方法之一是监控学生使用这类工具的使用(例如,给予学生有限数量的tokens ,这些tokens会在他们向LLM请求解释时使用)。例如,学生可以通过要求解释来获得固定数量的代币开始和使用,然后通过编写自己的手工代码解释来获得代币。
What Do Students Value in Code Explanations?
在专题分析中发现,学生们表示更喜欢逐行解释。这也是LLM似乎最擅长的解释类型。
这表明,教师和学生对什么是好的解释可能存在不一致的意见。甚至可能是一些先前的工作"不公平"地对学生的多结构解释进行了较低的评价,因为学生可能能够产生更抽象的关系解释,但他们认为更长、更详细的解释是"更好"的,从而产生了这些类型的解释。
在专题分析中,还观察到,LLM 创建的解释密切遵循标准格式。向学生展示 LLM 创建的解释可能有助于他们在自己的解释中采用标准格式,这可能有助于做出更好的解释。
Limitations
关于普适性,我们研究中的学生都是新手。这可能会影响他们创建的解释类型,以及他们如何评价同伴和 GPT-3 创建的解释。
有可能水平较高的学生或指导老师所创建的代码解释的评分会高于 GPT-3 创建的解释。
一旦学生积累了更多经验,他们可能会开始重视更抽象、更简短的解释。
只考察了学生对解释质量的看法,未考虑学习效果差异。
Future work
评估学生和 LLM 在解释和检测错误代码中的错误方面的表现
研究在使用学生和 LLM 创建的代码解释时,学生的学习效果是否存在差异。