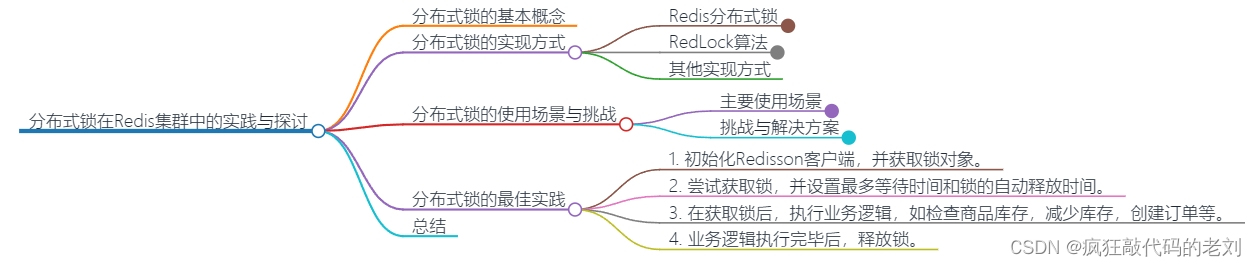
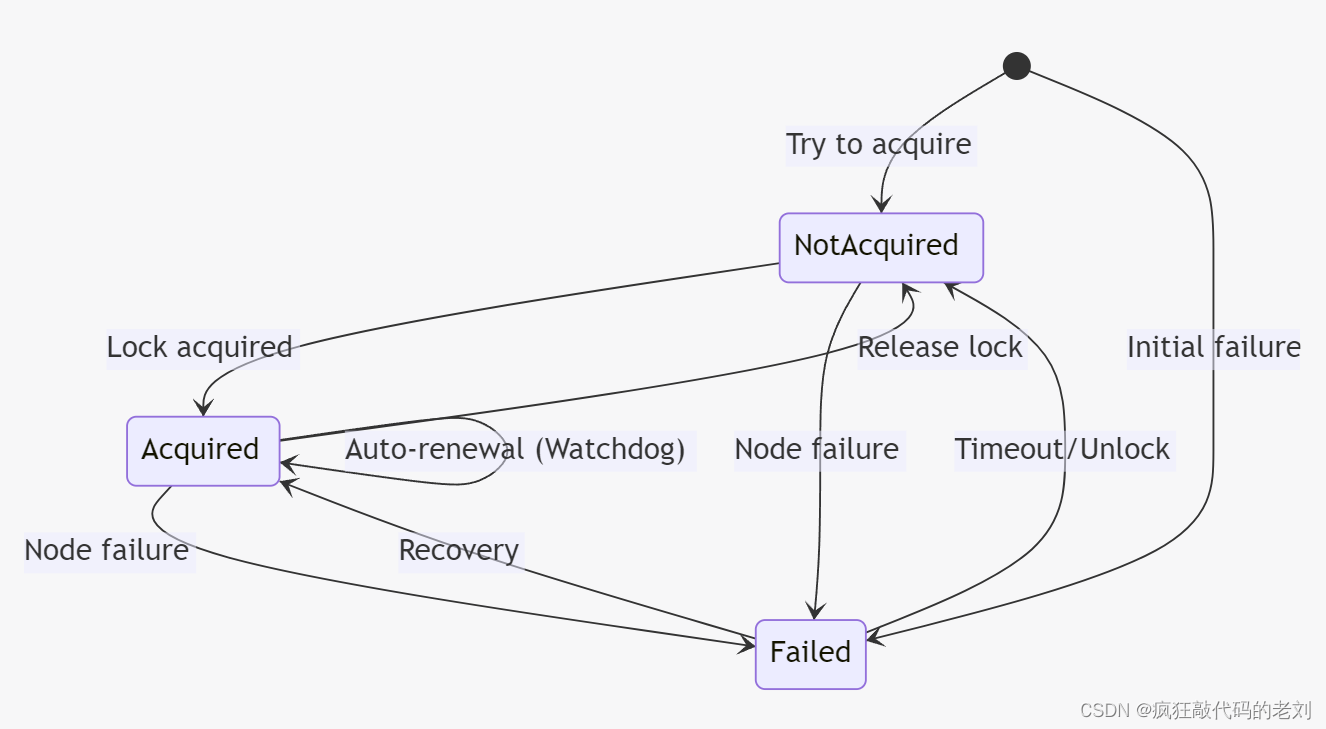
分布式锁的基本概念
分布式锁是在分布式计算环境下,用来确保多个进程或线程在访问某些共享资源时能够避免冲突的一种同步机制。其主要目的是为了保持数据的一致性和完整性。为了达到这个目的,分布式锁需要满足互斥性、无死锁和容错性三个基本条件。
互斥性:这是分布式锁最基本的要求,它确保在任何时刻,只有一个进程或线程能访问共享资源。这就像是在公共洗手间的厕所里,当一个人进去后,门会锁上,其他人就无法进入,直到里面的人出来并打开锁。这样可以防止资源的冲突和数据的不一致。
无死锁:在分布式系统中,由于网络延迟或者其他原因,可能会出现一个进程持有了一个锁,而又去请求另一个已经被其他进程持有的锁,这样就形成了死锁。分布式锁需要有机制来避免这种情况的发生,或者在死锁发生后能够检测到并进行恢复。
容错性:分布式系统中的机器难免会出现故障,分布式锁需要确保即使系统中的某些部分发生故障,仍然能够正常工作。这通常需要锁服务本身就是高可用的,即使个别服务器宕机,整个锁服务仍然可用。
在实际应用中,分布式锁可以使用不同的技术来实现,常见的有基于数据库的锁、基于缓存(如Redis)的锁和基于Zookeeper的锁等。这些实现方式各有优缺点,需要根据具体的应用场景和需求来选择。
以Redis为例,它提供了SETNX命令,可以用来实现分布式锁。SETNX命令的作用是“SET if Not eXists”,即当锁不存在时,就设置锁的值,返回1;如果锁已经存在,则不做任何操作,返回0。这样就保证了只有一个客户端能够成功设置锁,从而达到了锁的效果。为了防止锁永远不被释放,还需要为锁设置一个过期时间,这可以通过EXPIRE命令来实现。
分布式锁的实现方式
在分布式系统中,为了确保数据一致性和系统稳定性,我们需要使用分布式锁来控制对共享资源的访问。本部分将深入探讨分布式锁的不同实现方式,并结合文档内容,为你提供详细的解释和示例。
Redis分布式锁
Redis是一种常用的分布式锁实现方式,其提供了多种锁的实现方案。在文档中,我们看到了使用Redlock+Redisson来实现分布式锁的示例。这种方案通过在多个Redis节点上获取锁,并利用看门狗机制自动续期锁的过期时间,来提高锁的可用性和安全性。即使在部分节点宕机的情况下,这种方案仍能保持锁的正常工作和安全性。
例如,在一个电商平台的商品秒杀活动中,我们可以使用Redlock+Redisson方案来控制商品库存的减少操作,防止超卖。以下是一个使用Redisson客户端获取分布式锁的Java代码示例:
// 初始化 Redisson 客户端
RedissonClient redisson = Redisson.create(config);
// 尝试获取锁
RLock lock = redisson.getLock("product_stock_lock");
try {
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
if (lock.tryLock(100, 10, TimeUnit.SECONDS)) {
// 获取锁成功,执行业务逻辑
// 检查商品库存
int stock = checkStock(productId);
if (stock > 0) {
// 减少库存
reduceStock(productId);
// 创建订单
createOrder(userId, productId);
}
}
} finally {
// 释放锁
lock.unlock();
}
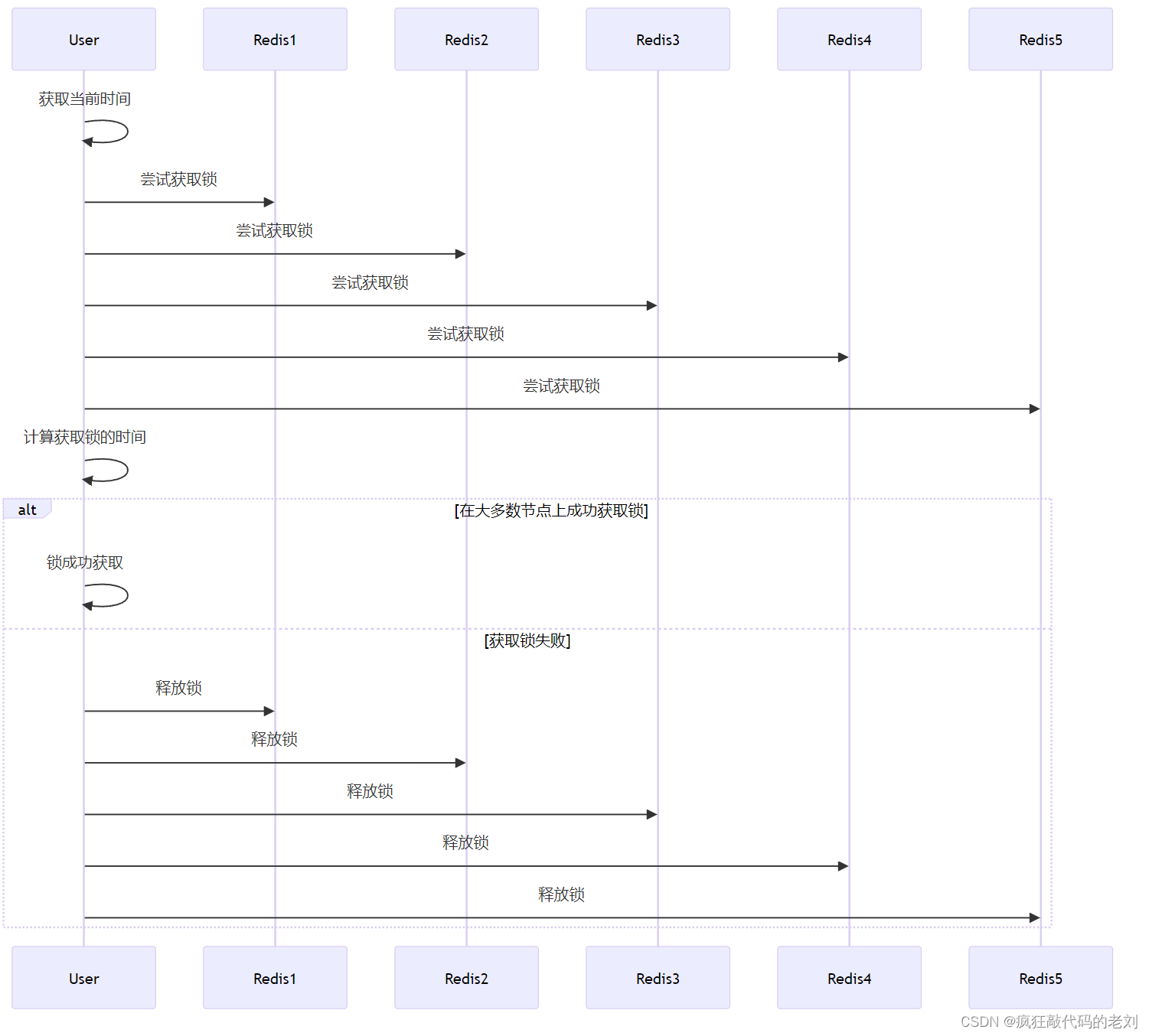
RedLock算法
RedLock算法是另一种在Redis集群环境下实现分布式锁的方法。它通过在多个独立的Redis节点上获取锁,并确保在大多数节点上成功获取锁来提高锁的安全性和可用性。即使部分Redis节点发生故障或网络分区,只要大多数节点上的锁被成功获取,整个分布式锁就被认为是成功获取。
以下是使用RedLock算法获取分布式锁的步骤:
- 获取当前时间。
- 依次尝试在五个Redis节点上获取锁,设置锁的过期时间。
- 计算获取锁的时间,如果在大多数节点(至少三个)上成功获取锁,并且获取锁的总时间小于锁的过期时间,那么认为锁获取成功。
- 如果锁获取失败(没有在大多数节点上获取锁或获取锁的时间过长),则在所有节点上释放锁。
其他实现方式
除了Redis外,还有其他一些技术可以用来实现分布式锁,如Zookeeper和Memcached。这些技术各有其优势和适用场景,但它们的核心目的都是为了在分布式环境中提供一种可靠的锁机制,以确保数据的一致性和系统的稳定性。
在选择分布式锁的实现方式时,我们需要根据系统的具体需求和特点来做出决策。例如,如果系统对锁的响应时间和吞吐量有较高的要求,可能需要考虑使用性能更优的轻量级锁实现。如果系统需要在分布式环境下提供高度的可用性和稳定性,可能需要考虑使用支持集群部署和自动故障转移的锁实现。
分布式锁的使用场景与挑战
分布式锁在现代分布式系统中扮演着至关重要的角色,它不仅确保了在并发环境下数据的一致性和系统的稳定性,还解决了多个节点间协调一致性的问题。本部分将探讨分布式锁的主要使用场景和在实际应用中可能遇到的挑战。
主要使用场景
分布式锁主要用于解决分布式系统中的资源竞争问题,确保在同一时间只有一个节点或进程能够访问共享资源。以下是一些常见的使用场景:
-
数据一致性保障:在分布式数据库或分布式缓存系统中,分布式锁用于保证数据的一致性。当多个节点试图同时修改同一条数据时,分布式锁确保只有一个节点能够进行操作,从而避免数据冲突和不一致的情况发生。
-
分布式事务控制:在需要进行分布式事务处理的系统中,分布式锁用于协调不同节点间的事务,确保事务的原子性和一致性。
-
系统资源的互斥访问:在某些系统中,可能存在一些资源或服务需要被互斥访问,分布式锁可以用来控制对这些资源或服务的访问,防止资源冲突。
-
实现分布式计算和任务调度:在分布式计算框架中,分布式锁用于协调不同计算节点的任务执行,确保任务的正确执行和资源的合理分配。
挑战与解决方案
虽然分布式锁在分布式系统中发挥着重要作用,但在实际应用中也面临着一系列的挑战:
-
性能问题:分布式锁的性能直接影响到系统的响应时间和吞吐量。为了提高性能,我们需要选择合适的分布式锁实现,并对其进行优化。例如,使用轻量级的锁实现,减少网络通信的开销,优化锁的获取和释放过程。
-
死锁问题:在分布式系统中,死锁问题更加复杂和难以解决。我们需要设计合理的锁获取和释放策略,避免死锁的发生。同时,也可以引入死锁检测和恢复机制,当检测到死锁时,自动进行恢复。
-
锁的可用性和稳定性:分布式锁需要在分布式环境下提供高度的可用性和稳定性。我们可以通过在多个节点上部署锁服务,使用集群和复制技术来提高锁的可用性和稳定性。
-
锁的粒度和性能权衡:锁的粒度直接影响到系统的并发度和性能。过细的锁粒度可以提高系统的并发度,但可能增加锁的管理开销;过粗的锁粒度可能降低系统的并发度。我们需要根据具体的应用场景和需求,合理选择锁的粒度,并进行性能测试和优化。
分布式锁的最佳实践
在分布式系统中,为了确保数据一致性和系统稳定性,分布式锁成为了一种不可或缺的同步机制。本文将深入探讨如何在Redis集群环境下,通过Redlock算法和Redisson框架实现分布式锁的最佳实践。
Redlock算法结合Redisson框架,提供了一种在Redis集群环境下实现分布式锁的解决方案。这种方案的核心思想是在多个Redis节点上获取锁,并利用看门狗机制自动续期锁的过期时间,从而提高锁的可用性和安全性。即使在部分节点宕机的情况下,这种方案仍能保持锁的正常工作和安全性。
以一个电商平台的商品秒杀活动为例,我们需要在活动开始时控制商品库存的减少操作,防止超卖现象的发生。通过使用Redlock+Redisson方案,我们可以确保在同一时间只有一个用户能够成功下单。具体实现如下:
-
初始化Redisson客户端,并获取锁对象。
RedissonClient redisson = Redisson.create(config); RLock lock = redisson.getLock("product_stock_lock"); -
尝试获取锁,并设置最多等待时间和锁的自动释放时间。
if (lock.tryLock(100, 10, TimeUnit.SECONDS)) { // 执行业务逻辑 } -
在获取锁后,执行业务逻辑,如检查商品库存,减少库存,创建订单等。
int stock = checkStock(productId); if (stock > 0) { reduceStock(productId); createOrder(userId, productId); } -
业务逻辑执行完毕后,释放锁。
lock.unlock();
通过这种方式,我们不仅确保了在高并发的秒杀活动中商品库存的准确性,也提高了系统的稳定性和可靠性。Redlock+Redisson方案通过在多个Redis节点上获取锁,并利用看门狗机制自动续期锁的过期时间,确保了即使在部分节点宕机的情况下,锁仍能正常工作,从而提高了分布式锁的可用性和安全性。
总结
本文深入探讨了分布式锁的核心概念、实现机制以及最佳实践。
选择合适的分布式锁实现方式对于确保系统的稳定性和性能至关重要。无论是选择基于Redis的RedLock算法,还是其他分布式锁解决方案,我们都需要仔细考虑其安全性、性能和可用性。
通过实践和不断优化,我们可以在分布式环境中实现高效且可靠的锁机制,确保系统资源的安全访问和高效利用。
![[自学记录08*]LDR、HDR与ToneMapping](https://img-blog.csdnimg.cn/4eb14a68616340a186d801650c81be20.png)