目录
类 & 对象
类定义
对象的建立和使用
构造函数(Constructor)
析构函数(Destructor)
拷贝构造函数
扩展知识
this指针
友元函数的使用方法
友元类的使用方法
常数据的使用及初始化
类 & 对象
什么是类?什么是对象?对于面向对象的C++语言学习,类和对象的理解是整个语言学习中核心的基础。通俗的理解,类其实就是一个模子,是一个变量类型,对象就是这个类型定义出来的具体的变量,就像int a;这句话,int对应类,a就对应对象。这样大家应该就好理解了,但需要注意的是int是C++的内置类型,并不是真正的类。
所以,概括的讲:类是对象的抽象和概括,而对象是类的具体和实例。
类定义
在C++中,类是一种用户自定义的数据类型,用于封装数据和相关的操作。类定义了对象的属性(成员变量)和行为(成员函数),并提供了一种实例化对象的模板。
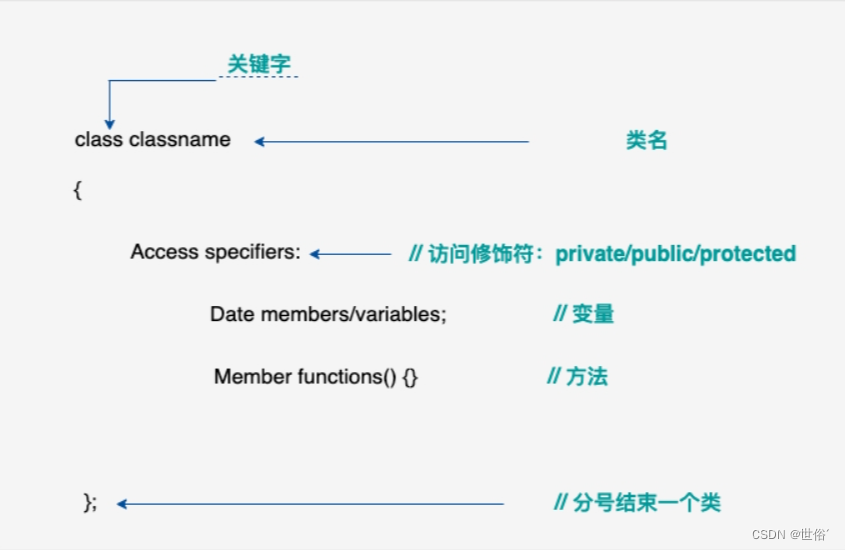
下面是一个简单的C++类定义的示例:
#include <iostream>
// 定义一个名为Person的类
class Person {
// 类的成员变量(属性)
std::string name;
int age;
public:
// 类的构造函数
Person(std::string n, int a) {
name = n;
age = a;
}
// 类的成员函数(方法)
void displayInfo() {
std::cout << "Name: " << name << std::endl;
std::cout << "Age: " << age << std::endl;
}
};
在上述示例中,我们定义了一个名为Person的类。它包含了两个私有成员变量name和age,以及一个公有成员函数displayInfo。
注意:在类中声明函数原型的方法与一般C语言的函数原型声明一样,而在类外定义函数的方法,则需要类名加::作用域限定符表示。
在类的定义中,通过public:、private:和protected:来分隔不同权限的成员。其中private表示私有,被它声明的成员,仅仅能被该类里的成员访问,外界不能访问,是最封闭的一种权限;protected比private稍微公开一些,除了类内自己的成员可以访问外,它的子类也可以访问(关于子类的概念我们会在后面详细展开);而public声明的成员,则可以被该类的任何对象访问,是完全公开的数据。
类的构造函数用于初始化对象的成员变量。在上述示例中,我们定义了一个接受两个参数的构造函数,并在构造函数中将参数值赋给成员变量。
类的成员函数用于定义类的行为。在上述示例中,displayInfo函数用于输出对象的属性值。
对象的建立和使用
1. 对象的创建:
在 C++ 中,对象是类的实例。要创建一个对象,必须先定义一个类以及使用该类的构造函数进行初始化。对象可以在栈上或堆上创建。
a. 在栈上创建对象:
通过使用类名和变量名定义对象,对象将分配在栈上,并在它的作用域结束时自动销毁。例如:
#include <iostream>
using namespace std;
class Person {
public:
int age;
string name;
void sayHello() {
cout << "Hello, my name is " << name << ", and I am " << age << " years old." << endl;
}
};
int main() {
Person p; // 在栈上创建对象
p.age = 20;
p.name = "Alice";
p.sayHello();
return 0;
}
b. 在堆上创建对象:
使用 new 运算符在堆上分配内存来创建对象,返回指向该对象的指针。需要手动调用 delete 运算符来释放内存,否则会导致内存泄漏。例如:
#include <iostream>
using namespace std;
class Person {
public:
int age;
string name;
void sayHello() {
cout << "Hello, my name is " << name << ", and I am " << age << " years old." << endl;
}
};
int main() {
Person* p = new Person(); // 在堆上创建对象
p->age = 20;
p->name = "Alice";
p->sayHello();
delete p; // 释放内存
return 0;
}
2. 对象的指针:
对象的指针是指向对象的地址的指针。可以使用“->”运算符来访问对象的成员。
例如,在堆上创建对象并使用对象的指针:
#include <iostream>
using namespace std;
class Person {
public:
int age;
string name;
void sayHello() {
cout << "Hello, my name is " << name << ", and I am " << age << " years old." << endl;
}
};
int main() {
Person* p = new Person();
p->age = 20;
p->name = "Alice";
p->sayHello();
delete p;
return 0;
}
3. 对象的引用:
对象的引用是对象的别名,使用“&”符号定义。可以将引用看作是一个对对象的另一种名称,修改引用将直接影响到原对象。
需要注意的是:
1. 与指针一样,两者必须是同类型才可以引用。
2. 除非做函数的返回值或形参时,其余定义引用类型的同时就要初始化!
3. 引用类型并非是新建立一个对象,因此也不会调用构造函数。
例如:
#include <iostream>
using namespace std;
class Person {
public:
int age;
string name;
void sayHello() {
cout << "Hello, my name is " << name << ", and I am " << age << " years old." << endl;
}
};
int main() {
Person p1;
p1.age = 20;
p1.name = "Alice";
Person& p2 = p1; // 引用p1
p2.age = 30;
p2.sayHello(); // 输出“Hello, my name is Alice, and I am 30 years old.”
p1.sayHello(); // 输出“Hello, my name is Alice, and I am 30 years old.”
return 0;
}
这就是对象的建立和使用。可以通过创建对象、使用对象的指针或引用来访问对象的成员和方法。
构造函数(Constructor)
构造函数(Constructor)是一种特殊的成员函数,用于在创建对象时初始化对象的成员变量。构造函数的名称与类名相同,没有返回类型(包括void),并且不能被直接调用。
构造函数在以下情况下被调用:
- 在创建对象时自动调用构造函数进行初始化。
- 使用 new 运算符在堆上创建对象时,需要显式调用构造函数进行初始化。
- 当对象作为参数传递给函数时,会调用复制构造函数进行初始化。
构造函数可以有多个重载版本,允许根据不同的参数列表对对象进行不同的初始化。
以下是一个示例,展示了如何定义和使用构造函数:
#include <iostream>
#include <cstring>
using namespace std;
class Student {
private:
int num; // 学号
char name[100]; // 姓名
int score; // 成绩
public:
Student(int n, const char* str, int s); // 构造函数
void print(); // 打印学生信息
void set(int n, const char* str, int s); // 设置学生信息
};
Student::Student(int n, const char* str, int s) {
num = n;
strcpy_s(name, str);
score = s;
cout << "Constructor" << endl;
}
void Student::print() {
cout << num << " " << name << " " << score << endl;
}
void Student::set(int n, const char* str, int s) {
num = n;
strcpy_s(name, str);
score = s;
}
int main() {
Student A(100, "dotcpp", 11);
A.print();
return 0;
}
输出:
Constructor
100 dotcpp 11这段代码定义了一个 Student 类,包括三个私有属性和三个公有方法。
其中,构造函数 Student(int n, char *str, int s) 用于初始化学生对象的属性,其中 n 是学号,str 是姓名,s 是成绩。在构造函数中,使用 strcpy() 函数将姓名复制到类的 name 成员变量中。构造函数中还输出了一条语句,用于提示当对象创建时构造函数被调用了。
print() 方法用于打印学生的学号、姓名和成绩,然后返回一个整数。
set(int n, const char* str, int s)方法用于设置学生对象的学号、姓名和成绩。在该方法中同样使用 strcpy_s() 函数将姓名复制到成员变量中。
在 main() 函数中,创建了一个名为 A 的 Student 对象,并通过构造函数传入了学号、姓名和成绩。然后调用 print() 方法打印学生信息,最后结束程序。
需要注意的是,在类内部定义方法时,不需要再加上类名作为前缀。而在类外部定义方法时,需要加上类名作为前缀,指明该方法是属于哪个类的。
析构函数(Destructor)
析构函数是一个特殊的成员函数,它在对象被销毁时自动调用。它的名称与类名相同,前面加上一个波浪线(~)作为前缀,没有参数和返回值。析构函数主要用于释放对象占用的资源,例如释放动态分配的内存或关闭打开的文件等。
析构函数的定义方式与普通成员函数相似,在类的声明中声明它,并在类的定义中实现它。例如:
class MyClass {
public:
// 构造函数
MyClass();
// 析构函数
~MyClass();
};
MyClass::MyClass() {
// 构造函数的实现
}
MyClass::~MyClass() {
// 析构函数的实现
}
当对象被销毁时(例如超出其作用域、delete 运算符被调用或程序执行结束),析构函数会自动调用。在调用析构函数之前,对象的成员变量已经被自动销毁,析构函数主要负责清理其他资源并执行必要的清理操作。
需要注意的是,如果没有显式定义析构函数,编译器会生成默认的析构函数。默认的析构函数为空,不执行任何操作。对于大多数情况下,可以依赖编译器生成的默认析构函数。但如果类中有需要释放的资源(如动态分配的内存),则需要显式定义析构函数来进行资源的释放。
以下是一个示例,展示了如何在析构函数中释放动态分配的内存:
#include <iostream>
class DynamicArray {
private:
int* arr;
int size;
public:
DynamicArray(int s);
~DynamicArray();
};
DynamicArray::DynamicArray(int s) {
size = s;
arr = new int[size];
std::cout << "DynamicArray 构造函数" << std::endl;
}
DynamicArray::~DynamicArray() {
delete[] arr;
std::cout << "DynamicArray 析构函数" << std::endl;
}
int main() {
DynamicArray array(5);
return 0;
}
在上面的示例中,DynamicArray 类包含一个动态分配的整数数组 arr 和数组的大小 size。在构造函数中,使用 new 运算符动态分配了一块内存空间,并将指针赋值给成员变量 arr。在析构函数中,使用 delete[] 运算符释放了之前分配的内存空间。
当对象超出作用域时,析构函数会自动调用,释放动态分配的内存。输出结果将显示构造函数和析构函数的调用顺序。
总之,析构函数在对象销毁时执行必要的清理操作,是重要的资源管理工具之一。它的设计和实现应该与类的构造函数相对应,确保资源的正确释放和清理。
拷贝构造函数
拷贝构造函数是一种特殊的构造函数,用于创建一个新对象,该对象是已有对象的副本。它接受一个同类对象作为参数,并使用该对象的值来初始化新对象。拷贝构造函数通常用于以下场景:
- 当使用一个对象初始化另一个对象时,例如通过赋值操作、传递参数给函数、从函数返回对象等。
- 当对象按值传递给函数或从函数返回时,会调用拷贝构造函数创建对象的副本。
拷贝构造函数的定义方式与普通构造函数的语法相似,但是参数是对同类的引用。例如:
class MyClass {
public:
// 拷贝构造函数
MyClass(const MyClass& other);
// 其他成员函数和构造函数
};
在拷贝构造函数中,我们通常需要执行深拷贝(deep copy),以确保新对象与原始对象是独立的,而不是共享相同的资源。这意味着拷贝构造函数应该复制所有的成员变量,包括动态分配的资源(如堆上的内存)。
以下是一个示例,展示了如何定义和使用拷贝构造函数:
#include <iostream>
#include <cstring>
class String {
private:
char* data;
int length;
public:
// 构造函数
String(const char* str);
// 拷贝构造函数
String(const String& other);
// 析构函数
~String();
// 其他成员函数和操作符重载
};
String::String(const char* str) {
length = strlen(str);
data = new char[length + 1];
strcpy_s(data, length + 1, str);
std::cout << "构造函数" << std::endl;
}
String::String(const String& other) {
length = other.length;
data = new char[length + 1];
strcpy_s(data, length + 1, other.data);
std::cout << "复制构造函数" << std::endl;
}
String::~String() {
delete[] data;
std::cout << "析构函数" << std::endl;
}
int main() {
String str1("Hello");
String str2 = str1; // 使用拷贝构造函数创建对象副本
return 0;
}
在上面的示例中,String 类表示一个动态分配的字符串。在构造函数中,我们通过将传入的字符串复制到新分配的内存中来初始化对象。在拷贝构造函数中,我们使用参数对象的值来初始化新对象。通过在 main() 函数中创建对象 str1 和 str2,并复制 str1 给 str2,我们可以看到构造函数和拷贝构造函数的调用顺序。
需要注意的是,如果没有显式定义拷贝构造函数,编译器会生成默认的拷贝构造函数。默认的拷贝构造函数会逐个复制每个成员变量,但对于动态分配的资源,它只会进行浅拷贝(shallow copy),即复制指针而不是复制指针所指向的内容。这可能导致多个对象共享同一个资源,从而引发潜在的问题。因此,如果类中有动态分配的资源,通常需要显式定义拷贝构造函数来执行深拷贝。
总结起来,拷贝构造函数用于创建对象的副本,并确保副本对象是独立的。它在对象拷贝和传递过程中扮演着重要角色,特别是当类中包含动态分配的资源时。
扩展知识
在C++中,浅拷贝与深拷贝的比较:
1、默认拷贝构造函数:
- 默认拷贝构造函数会进行浅拷贝。它会简单地按位复制对象的数据成员,包括指针成员的地址。
- 浅拷贝创建的对象和原始对象共享指针成员所指向的资源。
2、自定义拷贝构造函数或重载赋值运算符:
- 如果需要进行深拷贝,我们必须自定义拷贝构造函数或重载赋值运算符。
- 在自定义的拷贝构造函数或赋值运算符中,我们需要对指针成员进行动态分配内存,并复制原始对象的资源。
下面是一些比较浅拷贝和深拷贝的关键点:
- 对象的生命周期:浅拷贝创建的对象和原始对象共享资源,当其中一个对象被销毁时,资源可能会被提前释放,导致其他对象无法访问。而深拷贝创建的对象独立于原始对象,每个对象有自己的资源副本,它们的生命周期是相互独立的。
- 资源管理:浅拷贝可能会导致资源泄漏或重复释放,因为多个对象共享相同的资源。而深拷贝通过复制资源的内容来避免这些问题,每个对象都有自己的资源副本,可以独立管理和释放资源。
- 对象之间的关系:浅拷贝会导致多个对象之间存在强耦合关系,一个对象的修改会影响其他对象。而深拷贝创建的对象相互独立,修改一个对象不会影响其他对象,它们之间没有耦合关系。
- 深度嵌套对象的处理:在涉及深度嵌套对象的情况下,浅拷贝可能无法正确处理内部对象的拷贝。而深拷贝可以递归地复制内部对象,确保每个对象都有独立的资源副本。
总的来说,在C++中,浅拷贝和深拷贝的选择取决于对象的特性、资源的复杂性以及对对象之间关系的需求。如果对象包含指针成员变量指向的动态分配资源,通常需要使用深拷贝以确保每个对象都有独立的资源副本。而对于简单的值类型成员变量和不涉及资源管理的情况,浅拷贝可能是更简单和高效的选择。
下面是一个示例,它演示了如何在一个类中使用浅拷贝和深拷贝来管理多个资源。
#include <iostream>
#include <cstring>
class Person {
private:
char* name;
int age;
double* scores;
public:
// 默认构造函数
Person(const char* n, int a, double* s) : age(a) {
// 分配内存并复制名称
name = new char[strlen(n) + 1];
strcpy_s(name, strlen(n) + 1, n);
// 分配内存并复制成绩
scores = new double[3];
memcpy(scores, s, sizeof(double) * 3);
}
// 拷贝构造函数
Person(const Person& other) : age(other.age) {
// 分配新内存并复制名称
name = new char[strlen(other.name) + 1];
strcpy_s(name, strlen(other.name) + 1, other.name);
// 分配新内存并复制成绩
scores = new double[3];
memcpy(scores, other.scores, sizeof(double) * 3);
}
// 析构函数
~Person() {
// 释放内存
delete[] name;
delete[] scores;
}
// 打印信息
void printInfo() {
std::cout << "姓名:" << name << std::endl;
std::cout << "年龄:" << age << std::endl;
std::cout << "成绩:";
for (int i = 0; i < 3; i++) {
std::cout << scores[i] << " ";
}
std::cout << std::endl;
}
// 获取成绩数组
double* getScores() const {
return scores;
}
// 修改成绩数组
void setScores(double* s) {
memcpy(scores, s, sizeof(double) * 3);
}
};
int main() {
double scores[] = { 80.0, 90.0, 95.0 };
Person p1("张三", 20, scores);
Person p2 = p1;// 浅拷贝
p1.printInfo(); //输出:成绩:80 90 95
p2.printInfo(); //输出:成绩:80 90 95
// 修改p2的成绩
double newScores[] = { 85.0, 92.0, 98.0 };
p2.setScores(newScores);
p1.printInfo(); // 输出:成绩:80 90 95
p2.printInfo(); // 输出:成绩:85 92 98
return 0;
}
在上面的代码示例中,Person类包含了多个资源,包括一个字符数组名称、一个整数年龄和一个双精度浮点型数组成绩。它实现了一个默认构造函数来分配内存并复制这些资源,以及一个浅拷贝构造函数和深拷贝构造函数。
在浅拷贝构造函数中,我们简单地复制指针,这样新对象和原始对象将共享相同的资源。在深拷贝构造函数中,我们为每个资源分配新内存,并将原始对象的资源复制到新内存中,以确保每个对象都有独立的资源副本。
在main()函数中,我们创建了两个Person对象p1和p2,并进行了浅拷贝。然后,我们修改了p2的一个成绩,而p1也受到了影响,因为它们共享相同的成绩数组。
这说明了浅拷贝的一个缺点:当多个对象共享相同的资源时,修改任何一个对象都会影响其他对象。因此,在处理包含多个资源的对象时,需要慎重考虑浅拷贝和深拷贝之间的选择,以确保对象的行为符合预期,并避免意外的错误。
this指针
C++中的this指针是一个隐含的指针,它指向当前对象的地址。在成员函数中,可以使用this指针来访问该对象的成员变量和成员函数。
在类定义中,成员函数的声明中并没有this指针,但在实现时会隐含加上。例如:
class Person {
public:
void setName(const char* name);
const char* getName() const;
private:
char* m_name;
};
void Person::setName(const char* name) {
this->m_name = new char[strlen(name) + 1];
strcpy(this->m_name, name);
}
const char* Person::getName() const {
return this->m_name;
}
在上面的代码中,成员函数setName()和getName()中均使用了this指针来访问m_name成员变量。例如,在setName()函数中,我们使用了this->m_name来表示当前对象的m_name成员变量。
在实际使用中,this指针通常用于解决命名冲突问题。例如,在下面的代码中,我们定义了一个成员变量和一个函数参数同名(都为name)的情况:
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
class Person {
public:
void setName(const char* name);
const char* getName() const;
private:
char* name;
};
void Person::setName(const char* name) {
this->name = new char[strlen(name) + 1];
strcpy(this->name, name);
}
const char* Person::getName() const {
return this->name;
}
int main() {
Person p;
const char* name = "John";
p.setName(name);
std::cout << p.getName() << std::endl;
return 0;
}
在上面的代码中,我们使用了this指针来区分成员变量name和参数name。例如,在setName()函数中,我们使用了this->name来表示当前对象的name成员变量。
总之,this指针是C++中一个非常重要的概念,它可以帮助我们访问当前对象的成员变量和成员函数,并解决命名冲突问题。
友元函数的使用方法
在C++中,友元函数是一种特殊的函数,它能够访问其它类的私有成员和保护成员。通常情况下,只有类的成员函数和派生类才能访问类的私有成员和保护成员。但是,在某些情况下,如果我们需要外部函数或者类来访问类的私有成员和保护成员时,就可以使用友元函数。
友元函数并不是类的成员函数,它只是被声明为友元的普通函数,但是其声明方式与类的成员函数类似,将该函数的声明放在类定义的public、protected、private之外,并且在函数名前加上关键字friend,如下所示:
class MyClass {
public:
friend void friendFunction();
};
void friendFunction() {
// 可以访问MyClass的私有成员和保护成员
}
friendFunction被声明为MyClass的友元函数,因此它可以访问MyClass的私有成员和保护成员。友元函数可以在类内或类外定义,但需要注意的是,在定义友元函数时,不需要再次使用friend关键字。
另外,一个类可以有多个友元函数,也可以是多个类的友元函数。例如:
class MyClass2;
class MyClass1 {
public:
friend void friendFunction1(MyClass1& obj); // MyClass1的友元函数
friend void friendFunction2(MyClass1& obj, MyClass2& obj2); // MyClass1和MyClass2的友元函数
private:
int m_privateData;
};
class MyClass2 {
public:
friend void friendFunction2(MyClass1& obj, MyClass2& obj2); // MyClass1和MyClass2的友元函数
private:
int m_privateData;
};
void friendFunction1(MyClass1& obj) {
std::cout << "friendFunction1 访问 MyClass1 的私有数据: " << obj.m_privateData << std::endl;
}
void friendFunction2(MyClass1& obj, MyClass2& obj2) {
std::cout << "friendFunction2 访问 MyClass1 的私有数据: " << obj.m_privateData << std::endl;
std::cout << "friendFunction2 访问 MyClass2 的私有数据:" << obj2.m_privateData << std::endl;
}
在上面的代码中,MyClass1和MyClass2都声明了一个私有成员变量m_privateData。friendFunction1是MyClass1的友元函数,可以访问MyClass1的私有成员;friendFunction2是MyClass1和MyClass2的友元函数,可以访问两个类的私有成员。
需要注意的是,友元函数并不属于类的成员函数,因此它不能使用this指针来访问对象的成员。但是,可以通过参数传递对象的引用或指针来访问对象的成员。
友元类的使用方法
在C++中,友元类是一种特殊的类,它可以访问其它类的私有成员和保护成员。与友元函数类似,通常情况下,只有类的成员函数和派生类才能访问类的私有成员和保护成员。但是,在某些情况下,如果我们需要外部类来访问类的私有成员和保护成员时,就可以使用友元类。
友元类是通过在类定义中将另一个类声明为友元来实现的。被声明为友元的类可以访问该类的私有成员和保护成员。友元类的声明方式如下:
class MyClass {
friend class FriendClass;
};
以上代码将FriendClass声明为MyClass的友元类。这意味着FriendClass可以访问MyClass的私有成员和保护成员。需要注意的是,友元关系是单向的,即如果将FriendClass声明为MyClass的友元类,则MyClass不能访问FriendClass的私有成员和保护成员。
友元类的使用方法与友元函数类似,但是需要注意以下几点:
- 友元类只能在类定义中声明,不能在类的成员函数或类外声明。
- 友元类的访问权限不受访问控制修饰符的限制,即无论FriendClass是public、protected还是private,都可以访问MyClass的私有成员和保护成员。
下面是一个使用友元类的例子:
#include <iostream>
class MyClass {
public:
MyClass(int data) : m_data(data) {}
private:
int m_data;
friend class FriendClass; // 友元类声明
};
class FriendClass {
public:
void printData(const MyClass& obj) {
std::cout << "Friend Class访问My Class的私人数据: " << obj.m_data << std::endl;
}
};
int main() {
MyClass obj(100);
FriendClass fc;
fc.printData(obj); // 输出:Friend Class访问My Class的私人数据: 100
return 0;
}
在上面的代码中,MyClass声明了一个私有成员变量m_data,并将FriendClass声明为友元类。FriendClass可以访问MyClass的私有成员,因此在printData函数中可以输出MyClass对象的私有成员m_data。在主函数中,创建了一个MyClass对象和一个FriendClass对象,并通过FriendClass的printData函数访问了MyClass对象的私有成员。
需要注意的是,虽然友元类可以访问类的私有成员和保护成员,但过度使用友元类可能会破坏封装性和安全性,因此应该谨慎使用。
常数据的使用及初始化
1、常数据成员
常数据成员是指在类中声明为常量的数据成员,它们的值在对象创建后不能再被修改。常数据成员可以用来表示对象的特定属性或限制其状态的不可变性。
在类中声明常数据成员时,需要使用const关键字进行修饰。常数据成员必须在对象的构造函数初始化列表中进行初始化,因为它们的值在对象构造时就确定了,并且不能在构造函数内部进行修改。使用的格式如下:
数据类型 const 数据成员名;
或
const 数据类型 数据成员名;另外,有一个特殊情况,如果成员是static类型,即静态常数据成员,因为是静态的属性,初始化则需在类外进行初始化。
例如,下面是一个表示圆的类,其中pi是一个常数据成员:
class Circle {
private:
const double pi = 3.14159;
double radius;
public:
Circle(double r) : radius(r) {}
double calculateArea() const {
return pi * radius * radius;
}
};
在上面的代码中,pi被声明为常数据成员,并在构造函数初始化列表中初始化。它的值在对象创建后不能再被修改。
2、常成员函数
常成员函数是指在类中声明为常量的成员函数,它们在函数体内不能修改对象的非常数据成员。常成员函数可以用来提取对象的信息或执行一些只读操作,保证不会对对象的状态造成改变。
声明常成员函数时,在函数声明的末尾使用const关键字进行修饰。常成员函数被称为常函数,它们可以被常对象调用。定义格式如下:
返回类型 函数名(形参表列) const;需要注意:
(1)常成员函数的定义和声明部分都要包含const;
(2)常成员函数只能调用常成员函数,而不能调用非常成员函数,访问但不可以更改非常成员变量。
例如,以下是一个表示矩形的类,其中getArea()是一个常成员函数:
class Rectangle {
private:
double length;
double width;
public:
Rectangle(double l, double w) : length(l), width(w) {}
double getArea() const {
return length * width;
}
};
在上面的代码中,getArea()被声明为常成员函数,并在函数声明末尾使用了const关键字。这表明该函数不会对对象的状态进行修改。
3、常对象
常对象是指通过将对象声明为常量来限制其状态的对象,常对象的数据成员在对象创建后不能再被修改。常对象只能调用常成员函数,而不能调用非常成员函数。
创建常对象时,在对象的类型前加上const关键字即可。常对象的值在创建后不能再被修改。定义格式如下:
类型 const 对象名;
或
const 类型 对象名;需要注意的是,常对象不可以访问类中的非常成员函数,只能访问常成员函数。
例如,以下是一个使用常对象的示例:
int main() {
const Rectangle r(10, 5); // 创建一个常对象
double area = r.getArea(); // 可以调用常成员函数
// r.length = 20; // 错误!常对象的数据成员不可修改
return 0;
}
在上面的代码中,r是一个常对象,它的值在创建后不能再被修改。因此,尝试修改r的数据成员会导致编译错误。
通过使用常数据成员、常成员函数和常对象,可以确保对象的状态不会被修改,并提供更安全和可靠的代码。常数据成员和常成员函数的使用可以在类内部和外部限制对对象的修改,而常对象可以确保在特定情况下对象的状态不会被改变。



![web:[CISCN2019 华北赛区 Day2 Web1]Hack World](https://img-blog.csdnimg.cn/68d2d91882e04a40bac769dad3559130.png)