1. 单链表与双链表的区别
单链表(Singly Linked List)和双链表(Doubly Linked List)是两种常见的链表数据结构,它们在节点之间的连接方式上有所区别。
单链表:
- 单链表的每个节点包含两个部分:数据域和指针域。
- 数据域存储节点的值或数据。
- 指针域存储指向下一个节点的指针,即单链表的指针指向下一个节点。
- 单链表只能从头节点开始顺序访问,通过指针域进行节点之间的连接。
- 单链表只能单向遍历,即只能从头节点开始,沿着指针域逐个访问下一个节点。
- 无法逆向检索,有时候不太方便
双链表:
7. 双链表的每个节点包含三个部分:数据域、指向前一个节点的指针和指向下一个节点的指针。
8. 数据域存储节点的值或数据。
9. 前驱指针指向前一个节点,后继指针指向下一个节点。
10. 双链表可以双向遍历,既能从头节点顺序遍历,也可以从尾节点逆序遍历。
11. 双链表相较于单链表需要额外存储指向前一个节点的指针,因此会在空间上占用更多的内存。
12. 可进可退,存储密度更低一点
单链表和双链表的选择取决于需要解决的问题和应用场景。对于只需要顺序遍历或仅从头部开始操作的情况,单链表可能是更简洁和高效的选择。但对于需要在两个方向上遍历或在任意位置插入或删除节点的情况,双链表就更有优势了。
双链表: 初始化、插入、删除、遍历
2. 双链表的初始化(带头结点)
//初始化双链表
typedef struct DNode //定义双链表结点类型
{
Elemtype data; //数据域
struct DNode *prior, *next; //前驱和后继指针
}DNode, *DLinkList;
bool InitDLinkList(DLinkList &L)
{
L = (DNode *) malloc(sizeof(DNode)); //分配一个头结点
if(L == NULL) //内存不足,分配失败
return false;
L->prior = NULL; //头结点的prior永远指向NULL
L->next = NULL; //头结点之后暂时还没有结点
return true;
}
void testDLinkList()
{
DLinkList L; //初始化双链表
InitDLinkList(L);
//后续代码......
}
//判断双链表是否为空(带头结点)
bool Empty(DLinkList L)
{
if(L->next == NULL)
return true;
else
return false;
}
3. 双链表的插入
在双链表中插入节点需要更新前驱节点和后继节点的指针连接,操作相对比较复杂。
- 首先,创建一个新节点,并设置它的数据值。
- 找到要插入位置的前驱节点。
- 将新节点的前驱指针指向前驱节点。
- 将新节点的后继指针指向前驱节点的后继节点。
- 更新前驱节点的后继指针指向新节点。
- 如果新节点的后继节点非空,将后继节点的前驱指针指向新节点。
- 若结点在双链表插入数据元素e,且p结点有后继结点,如下图所示。
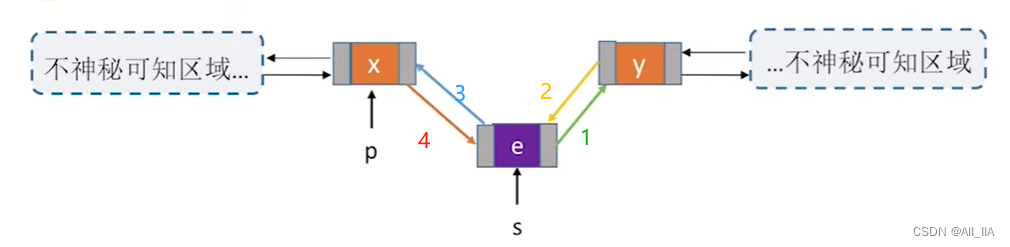
程序设计如下:
//在p结点之后插入s结点
bool InsertNextDNode(DNode *P, DNode *s)
{
s->next = p->next; //将结点*s插入到结点*p之后, 如上图步骤1
p->next->prior = s; //如上图步骤2
s->prior = p; //如上图步骤3
p->next = s; //如上图步骤4
}

- 如果p是最后一个结点,会发生什么?
p->next->prior = s; //如上图步骤2 这一行代码将出现问题 p->next指向的是NULL, 改进如下:
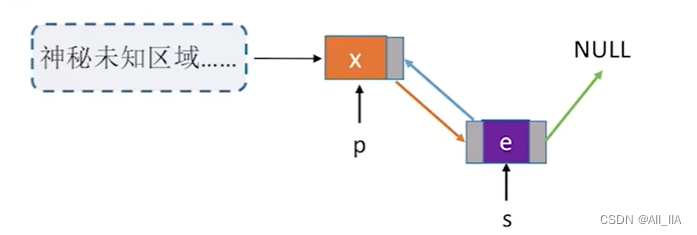
程序设计如下:注意修改指针时要注意顺序!!!
//在p结点之后插入s结点
bool InsertNextDNode(DNode *p, DNode *s)
{
if (p == NULL || s == NULL) //非法参数
return false;
s->next = p->next; // (*)
if(p->next != NULL)
{
p->next->prior = s; //如果p结点有后继结点,就回到了上一个情况
}
s->prior = p; //蓝色箭头操作
p->next = s; //橙色箭头操作 (**)
return true; //插入成功
}
- 指针顺序不能错! 假如 (*) 与(**)行交换。 那么就会出现如下图情况,p指针next与s->next指向同一位置。
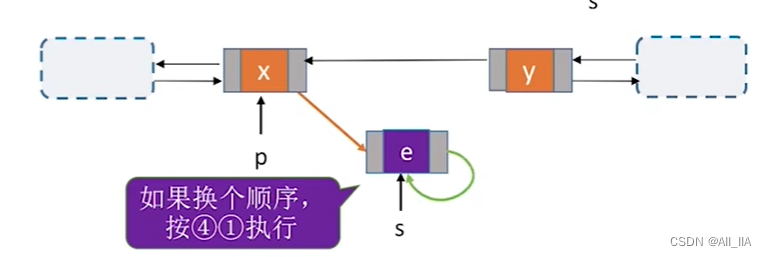
用后插操作实现结点插入有什么好处? - 按位序插入前插操作:效果等同于 ====> 可以先找到前驱结点,再对其做后插操作
- 其他插入操作,都可以转换成后插操作

4. 双链表的删除
在双链表中删除节点的操作相对比较复杂,因为我们需要维护前驱节点和后继节点之间的指针连接。
以下是删除双链表中某个节点的一般步骤:
- 首先,找到要删除的节点。
- 如果要删除的节点是头节点,将头节点指针指向下一个节点,并更新下一个节点的前驱指针为 nullptr。
- 如果要删除的节点是尾节点,将前一个节点的后继指针设为 nullptr,并更新尾节点指针为前一个节点。
- 如果要删除的节点既不是头节点也不是尾节点,将前一个节点的后继指针指向要删除节点的后一个节点,将后一个节点的前驱指针指向要删除节点的前一个节点。
- 释放要删除的节点的内存空间。
//删除p的后继结点q, 如下图所示
p->next = q->next;
q->next->prior = p;
free(q);

在实际使用中,应该确保要删除的节点在链表中确实存在。如果删除的节点不存在于链表中,需要根据具体的需求进行错误处理。同时,删除节点后必须确保释放相应的内存空间,以防止内存泄漏问题的发生。
删除q结点
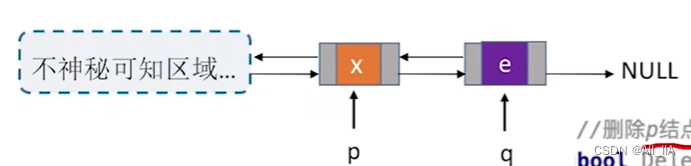
将 p 结点的next指针,指向q结点的后继结点。
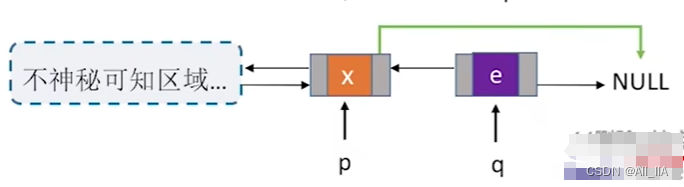
释放 q 结点空间
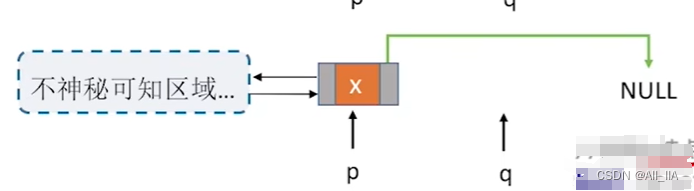
3.1 删除p结点的后继结点
//删除p结点的后继结点
bool DeleteNextDNode(DNode *p)
{
if(p==NULL)
return false;
DNode *q = p->next; //找到p的后继结点
if(q==NULL)
return false; //p没有后继结点
p->next = q->next;
if(q->next != NULL) //q结点不是最后一个结点
q->next->prior = p;
free(q); //释放结点空间
return true; //删除成功
}
3.2 销毁一个双链表
//销毁一个双链表
void DestoryList(DLinkList &L)
{
//循环释放各个数据结点
while(L->next != NULL) //判断头结点是否有后继结点,直到头结点后再无其他结点结束循环
{
DeleteNextDNode(L); //删除p结点的后继结点
}
free(L); //释放头结点
L = NULL; //头指针指向NULL
}
5. 双链表的遍历
4.1 后向遍历
while(p != NULL)
{
//对结点p做相应处理,如打印
p = p->next;
}
4.2 前向遍历
while(p != NULL)
{
//对结点p做响应处理
p = p->prior;
}
4.3 前向遍历(跳过头结点)
while(p->prior != NULL) //当前驱为NULL时,此时遍历到第一个结点,退出循环,跳过了头结点。
{
//对结点p做相应处理
p = p->prior;
}
双链表不可随机存取,按位查找、按值查找操作都只能用遍历的方式实现,时间复杂度为O(n)
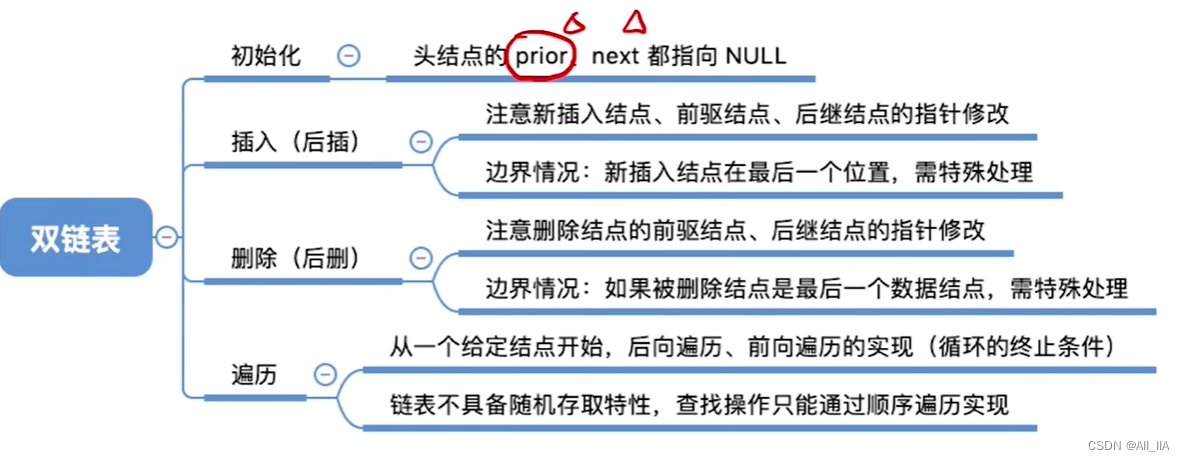
6. 知识点回顾













![[计算机网络]认识“协议”](https://img-blog.csdnimg.cn/img_convert/a28d84f47056abb60207850630e6f020.png)