文章目录
- 1. Python高级特性(切片、列表生成式)
- a) 切片的概念、列表/元组/字符串的切片
- 切片的概念
- 列表切片
- 基本索引
- 简单切片
- 超出有效索引范围
- 缺省
- 扩展切片
- step为正数
- step为负数
- b) 列表生成式以及使用列表生成式需要注意的地方
- 概念
- 举例说明
- 1. 生成一个列表,列表元素分别为 [1\*1,2\*2,3\*3……n\*n],假设n = 10。
- 2. 接着上一个需求,要求返回的序列中不存在偶数项:
- 3. 字符串s1 ='ABC',字符串 s2 = '123',要求:生成序列A1 A2 A3 B1 B2 B3 C1 C2 C3
- 2. 字符串的正则表达式
- 概念
- Python中的正则表达式模块re
- 正则表达式语法
- 正则表达式函数
- 示例
- 1、re.match()方法
- 2、re.search()方法
- 3、re.findall()方法
- 4、re.sub()方法
- 3. 函数
- a) 函数的概念
- b) 函数的定义与调用
- 函数名
- 形参列表
- 返回值
- 实际运用举例
- c) 函数的参数(位置参数、默认参数、关键字参数)
- 举例说明
- d) 递归函数(举一个简单的例子帮助理解)(选讲)
- 4. 模块
- 概念
- a) 使用内置模块(如random、os、time等)
- random模块常用函数
- os模块常用函数
- time模块常用函数
- b) 使用第三方模块(安装,导入,使用、如requests等)
- 安装
- 导入
- 使用
- c) Import自己写的文件,相对导入和绝对导入
- Python Modules模块
- 举个例子
- 导入模块
- 单独运行模块
- 利用相对路径引用包和模块
- 5. Python常用内置函数
- a) 求和函数sum
- b) 排序函数sorted
- c) 过滤函数filter
- d) 其他函数(max、min、abs)
- max
- min
- abs
- e) 流程函数map(选讲)
- 6.错误处理 (选讲)
- 思考题
- 为什么有len(a)和省略len(a)结果会不一样?
- 找出1-10之间所有的偶数,并且返回一个列表(这个列表中含以这个偶数为半径的圆的面积)
- 匹配手机号码
- 匹配邮箱地址
- 替换字符串
1. Python高级特性(切片、列表生成式)
a) 切片的概念、列表/元组/字符串的切片
切片的概念
在Python中,切片(slice)是对序列型对象(如list, string, tuple)的一种高级索引方法。普通索引只取出序列中一个下标对应的元素,而切片取出序列中一个范围对应的元素。
列表切片
基本索引

简单切片
简单切片指的是这样的切片形式:a[start:stop],其行为是得到下标在这样一个前闭后开区间范围内的元素,其中start和stop为负数时,简单看作是负数下标对应的位置即可:
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(a[2:3])
# [2]
print(a[5:9])
# [5, 6, 7, 8]
print(a[5:-1])
# [5, 6, 7, 8]
print(a[-5:9])
# [5, 6, 7, 8]
print(a[-5:-1])
# [5, 6, 7, 8]
两个比较特殊的情况:超出有效索引范围和缺省。
超出有效索引范围
当start或stop超出上文提到的有效索引范围时,切片操作不会抛出异常,而是进行截断。
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(a[-100:5])
# [0, 1, 2, 3, 4]
print(a[5:100])
# [5, 6, 7, 8, 9]
print(a[-100:100])
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(a[100:1000])
# []
另外,如果start的位置比stop还靠后怎么办?Python还是不会抛出异常,而是直接返回空序列:
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(a[6:5])
# []
缺省
start和stop都是可以缺省的,在缺省的情况下,Python的行为是尽可能取最大区间,具体来说:
按照扩充索引范围的观点,start的缺省值是无穷小(),stop的缺省值是无穷大()。
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(a[:5])
# [0, 1, 2, 3, 4]
print(a[5:])
# [5, 6, 7, 8, 9]
print(a[100:])
# []
扩展切片
扩展切片指的是这样的切片形式:a[start:stop:step],其中step是一个非零整数,即比简单切片多了调整步长的功能,此时切片的行为可概括为:从start对应的位置出发,以step为步长索引序列,直至越过stop对应的位置,且不包括stop本身。事实上,简单切片就是step=1的扩展切片的特殊情况。需要详细解释的是step分别为正数和负数的两种情况。
step为正数
当step为正数时,切片行为很容易理解,start和stop的截断和缺省规则也与简单切片完全一致:
# step为正数
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(a[0:6:2])
# [0, 2, 4]
print(a[::2])
# [0, 2, 4, 6, 8]
print(a[:-2:2])
# [0, 2, 4, 6]
print(a[4::2])
# [4, 6, 8]
step为负数
当step为负数时,切片将其解释为从start出发以步长|step|逆序索引序列,此时,start和stop的截断依然遵循前述规则,但缺省发生一点变化,因为我们说过,在缺省的情况下,Python的行为是尽可能取最大区间,此时访问是逆序的,start应尽量取大,stop应尽量取小,才能保证区间最大,因此:
按照扩充索引范围的观点,start的缺省值是无穷大(),stop的缺省值是无穷小()
# step为负数
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(a[5::-1])
# [5, 4, 3, 2, 1, 0]
print(a[:4:-2])
# [9, 7, 5]
print(a[::-1])
# [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
b) 列表生成式以及使用列表生成式需要注意的地方
概念
列表生成式即List Comprehensions,是Python内置的非常简单却强大的可以用来创建list的生成式。
列表生成式的结构是在一个中括号里包含一个表达式,然后是一个for语句,然后是0个或多个for或者if语句。列表表达式可以是任意的,意思是你可以在列表中放入任意类型的对象。返回结果将是一个新的列表,在这个以if和for语句为上下文的表达式运行完成之后产生。
举例说明
1. 生成一个列表,列表元素分别为 [1*1,2*2,3*3……n*n],假设n = 10。
一般方法:
l1 = []
for i in range(1,11):
l1.append(i*i)
print(l1)
列表生成式:
l2 = [i*i for i in range(1,11)]
print(l2)
2. 接着上一个需求,要求返回的序列中不存在偶数项:
一般形式:
l3 = []
for i in range(1,11):
if i%2 != 0:
l3.append(i*i)
print(l3)
列表生成式
l4 = [i*i for i in range(1,11) if i%2 != 0]
print(l4)
3. 字符串s1 =‘ABC’,字符串 s2 = ‘123’,要求:生成序列A1 A2 A3 B1 B2 B3 C1 C2 C3
列表生成式
l5 = [i+j for i in 'ABC' for j in '123']
print(l5)
一般模式
l6 = []
for i in 'ABC':
for j in '123':
l6.append(i+j)
print(l6)
2. 字符串的正则表达式
概念
正则表达式是一种用来描述字符串模式的文本。它由一些特殊字符和普通字符组成,可以用来匹配特定的字符串模式。例如,可以使用正则表达式匹配所有的电子邮件地址、所有的URL、所有的电话号码等。正则表达式不仅可以用来匹配字符串,还可以用来替换字符串,或者提取字符串中的某些部分。
Python中的正则表达式模块re
在Python中,正则表达式模块为re,它提供了一组函数和类,用于操作正则表达式。在使用re模块之前,需要先导入re模块,可以使用以下代码进行导入:
import re
正则表达式语法
正则表达式语法包括一些特殊字符和普通字符,它们组合起来形成了正则表达式模式。以下是一些常用的正则表达式语法:
- . 表示匹配任意一个字符。
- ^ 表示匹配字符串的开始位置。
- $ 表示匹配字符串的结束位置。
- *表示匹配前一个字符0次或多次。
- +表示匹配前一个字符1次或多次。
- ? 表示匹配前一个字符0次或1次。
- \ 表示转义字符。
- [] 表示字符集合,匹配其中任意一个字符。
- [^] 表示字符集合取反,匹配不在其中的任意一个字符。
- () 表示子模式,可以将多个字符组成一个整体,方便后续引用。
- {n} 匹配n个前面表达式。例如,"o{2}“不能匹配"Bob"中的"o”,但是能匹配"food"中的两个o。
- {n,} 精确匹配n个前面表达式。例如,"o{2,}“不能匹配"Bob"中的"o”,但能匹配"foooood"中的所有o。"o{1,}“等价于"o+”。"o{0,}“则等价于"o*”。
特殊字符类
- . 匹配除 “\n” 之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用象 ‘[.\n]’ 的模式。
- \d 匹配一个数字字符。等价于 [0-9]。
- \D 匹配一个非数字字符。等价于 [^0-9]。
- \s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。
- \S 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。
- \w 匹配包括下划线的任何单词字符。等价于’[A-Za-z0-9_]'。
- \W 匹配任何非单词字符。等价于 ‘[^A-Za-z0-9_]’。
正则表达式函数
re模块提供了一组函数,用于操作正则表达式,常用的函数包括:
- re.match(pattern, string, flags=0):尝试从字符串的开始位置匹配一个模式,如果匹配成功,则返回一个Match对象,否则返回None。
- re.search(pattern, string, flags=0):在字符串中搜索模式,如果匹配成功,则返回一个Match对象,否则返回None。
- re.findall(pattern, string, flags=0):在字符串中查找模式,返回所有匹配成功的结果。
- re.sub(pattern, repl, string, count=0, flags=0):将字符串中所有匹配模式的部分替换为指定的字符串。
参数说明:
- pattern: 匹配的正则表达式
- string: 要匹配的字符串。
- flags: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
– re.I 使匹配对大小写不敏感
– re.L 做本地化识别(locale-aware)匹配
– re.M 多行匹配,影响 ^ 和 $
– re.S 使 . 匹配包括换行在内的所有字符
– re.U 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B.
– re.X 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 - repl : 替换的字符串,也可为一个函数。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
示例
下面通过一些示例来说明Python中正则表达式的使用。
1、re.match()方法
re.match()方法用于从字符串的开头开始匹配模式,如果匹配成功,则返回一个匹配对象;否则返回None。
import re
pattern = r"hello"
string = "hello world"
result = re.match(pattern, string)
if result:
print("Match found!")
else:
print("No match")
2、re.search()方法
re.search()方法用于在字符串中搜索匹配模式,如果找到任意位置的匹配,则返回一个匹配对象;否则返回None。
import re
pattern = r"world"
string = "hello world"
result = re.search(pattern, string)
if result:
print("Match found!")
else:
print("No match")
3、re.findall()方法
re.findall()方法用于在字符串中搜索所有匹配模式的子串,并将它们作为列表返回。
import re
pattern = r"\d+"
string = "I have 10 apples and 20 oranges."
result = re.findall(pattern, string)
print(result) # Output: ['10', '20']
4、re.sub()方法
re.sub()方法用于在字符串中搜索匹配模式的子串,并将其替换为指定的字符串。
import re
pattern = r"apple"
string = "I have an apple."
result = re.sub(pattern, "banana", string)
print(result) # Output: "I have an banana."
3. 函数
a) 函数的概念
- 函数是可以重复执行一定任务的代码片段,具有独立的固定的输入输出接口。
- 函数定义的本质,是给一段代码取个名字,方便以后重复使用
- 为了方便以后调用这个函数,在定义它的时候,就需要明确它的输入(参数)与输出(返回值)
b) 函数的定义与调用
定义函数的语法格式
def 函数名(形参列表):
#可执行语句
return 返回值
函数名
- 只要是合法的标识符即可(同变量命名)
- 为了提高可读性,建议函数名由一个或多个有意义的单词组成,单词之间用下划线_分隔,字母全部小写
形参列表
- 在函数名后面的括号内,多个形参用逗号分隔,可以没有参数
- 参数可以有默认值,可以用等号=直接指定默认值,有默认值的参数必须排最后
- 没有默认值的参数,在调用的时候必须指定
- 形参也可以没有,但是括号不能省略
- 调用有默认值的参数要指定名字
返回值
- 返回值可以没有,直接省略return这句话
- 返回值可以是一个或多个,用逗号分隔,组合成一个元组
- 返回值还可以是表达式
- 多个返回值,不需要的用下划线顶替
实际运用举例
# 函数定义
def myfunc(arg1, arg2, arg3=None):
'''
This is a example for python documentation.
这是一个为python函数提供文档的例子。
arg1: 第一个参数的说明
arg2: 第二个参数的说明
arg3: 第三个参数的说明(这个参数有默认值)
v1, v2, v3: 返回值的说明
'''
v1 = arg1 + arg2
v2 = arg1 * arg2
if arg3 is None:
v3 = arg1 + arg2
else:
v3 = arg1 + arg2 + arg3
return v1, v2, v3
# 函数调用
v1, v2, v3 = myfunc(5, 3, arg3=4)
print(v1, v2, v3) #8 15 12
# 使用arg3的默认值调用函数
v1, v2, v3 = myfunc(5, 3)
print(v1, v2, v3) #8 15 8
# 忽略一个返回值
v1, v2, _ = myfunc(5, 3)
print(v1, v2, v3) #8 15 8
# 看看返回值是元组tuple,在返回的过程中被自动解包
print(type(myfunc(5,3))) #<class 'tuple'>
c) 函数的参数(位置参数、默认参数、关键字参数)
- 函数的参数是参数与外部可变的输入之间交互的通道。
- 函数的参数名称应该满足标识符命名规范,应该有明确的含义,可通过参数名称知道每个参数的含义。
- 在函数定义下面的注释中逐个注明函数(和返回值)的含义,以便用户即使不甚了解函数中的具体内容也能正确无误的使用它。
- 实参:实际参数,从外面传递来的实际的参数
- 形参:形式参数,在函数内部它形式上的名字
- 调用函数时,实参按照顺序位置与形参绑定,称为位置参数(Positional Argument)
- 也可以在调用时,写明实参与形参的对应关系,称作传递关键字参数(Keyword Argument),这时候位置信息被忽略了
- 同时传递位置参数与关键字参数,应该先传递位置参数,再传递关键字参数!
- 函数定义的时候,可以指定默认值,但带默认值的参数必须列在参数列表的最后
举例说明
#举一个小栗子,计算纸箱子的体积
def cube_volume(length, width, height = 0.25):
'''
计算纸箱子的体积(单位:m)
length: 长; width: 宽
height: 高(默认参数0.25)
v: 返回值,纸箱的体积,单位m**3
'''
if length <= 0:
print('length must larger than 0!')
return 0
if width <= 0:
print('width must larger than 0!')
return 0
if height <= 0:
print('height must larger than 0!')
return 0
v = length*width*height
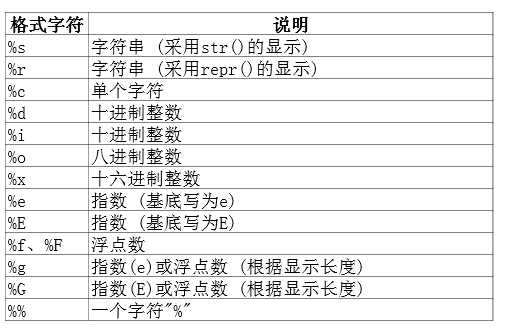
print('length = %.2f; width = %.2f; height = %.2f; cube volume = %.2f' % \
(length, width, height, v))
return v
# 使用位置参数调用
v = cube_volume(1, 2, 3)
# 使用关键字参数调用
v = cube_volume(width = 1, height = 2, length = 3)
# 位置参数和关键字参数混用
v = cube_volume(1, height = 2, width = 3)
# 关键字参数在位置参数之前会报错
# v = cube_volume(width = 1, 2, 3)
d) 递归函数(举一个简单的例子帮助理解)(选讲)
- 在一个函数里面调用它自己,称为递归。
- 递归可以视作一种隐式的循环,不需要循环语句控制也可实现重复执行某段代码。
- 递归在大型复杂程序中非常有用,在数值和非数值算法中都能大显身手!
- 使用递归的时候要注意,当一个函数不断调用自己的时候,必须保证在某个时刻函数的返回值是确定的,即不再调用自己。
经典递归应用:斐波拉契数列
# 斐波那契数列(Fibonacci sequence)
def Fibonacci(n):
''' Fibonacci sequence
f(0)=1, f(1) = 1, f(n) = f(n-1)+f(n-2)
'''
if n == 0 or n == 1:
return 1
else:
return Fibonacci(n-1) + Fibonacci(n-2)
# 测试一下,注意n不要设的太大,python的递归效率是比较低的,太大会死机
print(Fibonacci(5))
# 斐波那契数列,前20位
print('Fibonacci sequence:')
for i in range(20):
print('%d: %d' % (i,Fibonacci(i)))
4. 模块
概念
在刚入门python时,模块化编程、模块、类库等术语常常并不容易理清。尤其是Modules(模块)和Packages(包),在import引用时很容易混淆出错。
实际上,Python中的函数(Function)、类(Class)、模块(Module)、包库(Package),都是为了实现模块化引用,让程序的组织更清晰有条理。
👉通常,函数、变量、类存储在被称为模块(Module)的.py文件中,一组模块文件又组成了包(Package)。
👉将函数、变量、类存储在存储在独立的.py文件中,可隐藏代码实现的细节,将不同代码块重新组织,与主程序分离,简化主程序的逻辑,提高主程序的可读性。
👉 有了包和模块文件,可以在其他不同程序中进行复用,还可以使用其他人开发的第三方依赖库。
a) 使用内置模块(如random、os、time等)
random模块常用函数
随机数模块,该模块中定义了多个可产生各种随机数的函数。
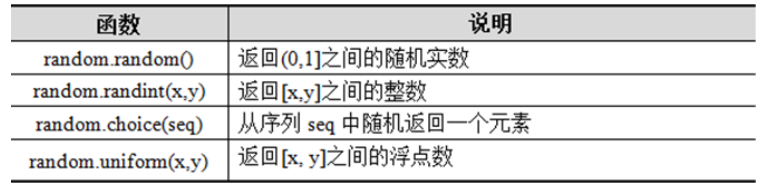
import random
print(random.random())
print(random.randint(3,100))
rl = [2,1,3,4,2,2,1,4,5,6,2,5,2,1]
print(random.choice(rl))
print(random.uniform(1,2))
os模块常用函数
提供了访问操作系统服务的功能,该模块中常用函数如下表所示。
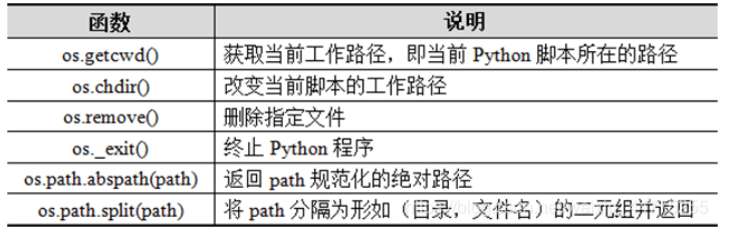
import os
print(os.getcwd())
print(os.path.abspath(os.getcwd()))
print(os.path.split(os.getcwd()))
time模块常用函数
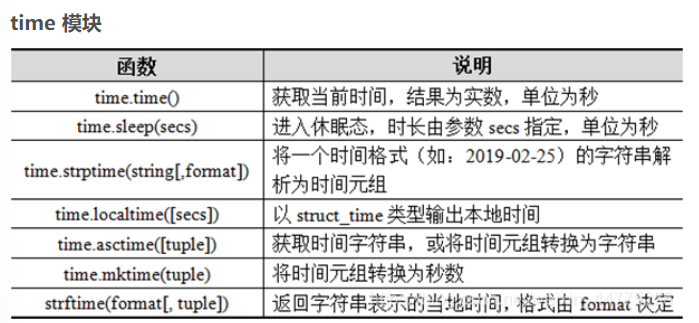
import time
print(time.time())
print(time.localtime())
print("---start---")
time.sleep(2) # 休眠2秒
print("-- end---")
b) 使用第三方模块(安装,导入,使用、如requests等)
以requests为例:
安装
对于第三方模块需要先进行安装操作
pip install requests
导入
安装好对应包后再项目中进行导入
import requests
使用
导入对应的包后即可在项目中使用包中的对应函数方法
response = requests.get('http://httpbin.org/get')
print(response.text)
将返回值以json形式打印
import requests
import json
response = requests.get("http://httpbin.org/get")
print(type(response.text))
print(response.json())
print(json.loads(response.text))
print(type(response.json()))
c) Import自己写的文件,相对导入和绝对导入
Python Modules模块
Modules模块是包含 Python 定义和语句的文件。以.py为后缀的文件名就是模块名称。
举个例子
我们创建了一个fibo.py文件,文件内容为:
# Fibonacci numbers module
def fib(n): # write Fibonacci series up to n
a, b = 0, 1
while a < n:
print(a, end=' ')
a, b = b, a+b
print()
def fib2(n): # return Fibonacci series up to n
result = []
a, b = 0, 1
while a < n:
result.append(a)
a, b = b, a+b
return result
这里fibo.py就是一个模块,fib、fib2是fibo模块中的函数。
导入模块
如果我们想要在其他程序中使用fibo模块,可以有以下三种方式导入:
①导入整个模块
#import module_name
import fibo
可使用下面的语法来使用其中任何一个函数:
#module_name.func()
fibo.fib(10)
⭕ 注意:这里模块名+句点不可省略。
②导入模块中的特定函数
#from module_name import function_name
from fibo import fib, fib2
fib(10)
若使用这种语法,调用函数时就无需使用模块名+句点。
因为在import语句中已经显式地导入了函数fib和fib2,因此调用它时只需指定其名称。
③导入模块中的所有函数
#from module_name import *
from fibo import *
fib(20)
这种方式会导入除可下划线 (__)开头的名称以外的所有函数。
⭕ 注意:在大多数情况下,通常不推荐*这种用法,因为它可能会在解释器中引入了一组未知的名称,而且通常会导致代码可读性变差。
给导入的模块一个别名
# import module as m
import numpy as np
a = np.arange(100)
利用as给导入模块一个别名,简化代码中的调用写法。
单独运行模块
如果我们想单独测试下模块,可以在模块中添加以下代码,就可以既用作脚本,也可用作可导入模块:
if __name__ == "__main__":
fib(10)
利用相对路径引用包和模块
这里的.可以访问同级目录下的包(Package)或者模块(Module)。
这里的..可以访问上一级目录下的包(Package)或者模块(Module)。
5. Python常用内置函数
a) 求和函数sum
描述
sum() 方法对序列进行求和计算。
语法
以下是 sum() 方法的语法:
sum(iterable[, start])
参数
- iterable – 可迭代对象,如:列表、元组、集合。
- start – 指定相加的参数,如果没有设置这个值,默认为0。
返回值
返回计算结果。
实例
print(sum([0,1,2]))
print(sum((2, 3, 4), 1)) # 元组计算总和后再加 1
print(sum([0,1,2,3,4], 2)) # 列表计算总和后再加 2
b) 排序函数sorted
描述
sorted() 函数对所有可迭代的对象进行排序操作。
sort 与 sorted 区别:
sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
list 的 sort 方法返回的是对已经存在的列表进行操作,无返回值,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
语法
sorted 语法:
sorted(iterable, key=None, reverse=False)
参数说明:
-
iterable – 可迭代对象。
-
key – 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
-
reverse – 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
返回值
返回重新排序的列表。
# b) 排序函数sorted
a = [5, 7, 6, 3, 4, 1, 2]
b = sorted(a) # 保留原列表
print(a)
# [5, 7, 6, 3, 4, 1, 2]
print(b)
# [1, 2, 3, 4, 5, 6, 7]
L = [('f', 2), ('a', 1), ('c', 3), ('d', 4)]
L1 = sorted(L, key=lambda x: x[1]) # 利用key
L2 = sorted(L, key=lambda x: x[0]) # 利用key
print(L1)
# [('a', 1), ('b', 2), ('c', 3), ('d', 4)]
print(L2)
# [('a', 1), ('c', 3), ('d', 4), ('f', 2)]
students = [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
res1 = sorted(students, key=lambda s: s[2]) # 按年龄排序
print(res1)
# [('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]
res2 = sorted(students, key=lambda s: s[2], reverse=True) # 按降序
print(res2)
# [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
res3 = sorted(students, key=lambda s: (s[1],s[2])) # 按分类排序,分类相同按年龄
print(res3)
# [('john', 'A', 15), ('dave', 'B', 10), ('jane', 'B', 12)]
c) 过滤函数filter
描述
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
语法
以下是 filter() 方法的语法:
filter(function, iterable)
参数
- function – 判断函数。
- iterable – 可迭代对象。
返回值
返回一个迭代器对象
实例
过滤出列表中的所有奇数:
def is_odd(n):
return n % 2 == 1
tmplist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
newlist = list(tmplist)
print(newlist)
# [1, 3, 5, 7, 9]
过滤出1~100中平方根是整数的数:
import math
def is_sqr(x):
return math.sqrt(x) % 1 == 0
tmplist = filter(is_sqr, range(1, 101))
newlist = list(tmplist)
print(newlist)
# [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
d) 其他函数(max、min、abs)
max
描述
max() 方法返回给定参数的最大值,参数可以为序列。
语法
以下是 max() 方法的语法:
max( x, y, z, .... )
参数
- x – 数值表达式。
- y – 数值表达式。
- z – 数值表达式。
返回值
返回给定参数的最大值。
实例
以下展示了使用 max() 方法的实例:
print ("max(80, 100, 1000) : ", max(80, 100, 1000))
print ("max(-20, 100, 400) : ", max(-20, 100, 400))
print ("max(-80, -20, -10) : ", max(-80, -20, -10))
print ("max(0, 100, -400) : ", max(0, 100, -400))
以上实例运行后输出结果为:
max(80, 100, 1000) : 1000
max(-20, 100, 400) : 400
max(-80, -20, -10) : -10
max(0, 100, -400) : 100
min
描述
min() 方法返回给定参数的最小值,参数可以为序列。
语法
以下是 min() 方法的语法:
min( x, y, z, .... )
参数
- x – 数值表达式。
- y – 数值表达式。
- z – 数值表达式。
返回值
返回给定参数的最小值。
实例
以下展示了使用 min() 方法的实例:
print ("min(80, 100, 1000) : ", min(80, 100, 1000))
print ("min(-20, 100, 400) : ", min(-20, 100, 400))
print ("min(-80, -20, -10) : ", min(-80, -20, -10))
print ("min(0, 100, -400) : ", min(0, 100, -400))
以上实例运行后输出结果为:
min(80, 100, 1000) : 80
min(-20, 100, 400) : -20
min(-80, -20, -10) : -80
min(0, 100, -400) : -400
abs
描述
abs() 函数返回数字的绝对值。
语法
以下是 abs() 方法的语法:
abs( x )
参数
- x – 数值表达式,可以是整数,浮点数,复数。
返回值
函数返回 x(数字)的绝对值,如果参数是一个复数,则返回它的大小。
实例
以下展示了使用 abs() 方法的实例:
print ("abs(-40) : ", abs(-40))
print ("abs(100.10) : ", abs(100.10))
以上实例运行后输出结果为:
abs(-40) : 40
abs(100.10) : 100.1
e) 流程函数map(选讲)
描述
map() 函数会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
语法
以下是 map() 方法的语法:
map(function, iterable, ...)
参数
- function – 函数
- iterable – 一个或多个序列
返回值
返回一个迭代器。
实例
以下实例展示了 map() 的使用方法:
def square(x) : # 计算平方数
return x ** 2
map_return = map(square, [1,2,3,4,5]) # 计算列表各个元素的平方
print(map_return)
# <map object at 0x0000022FB28CFA30> # 返回迭代器
map_return_list = list(map(square, [1,2,3,4,5])) # 使用 list() 转换为列表
print(map_return_list)
# [1, 4, 9, 16, 25]
6.错误处理 (选讲)
Python3 错误和异常
实例
使用 try…except…finally 语句
print("===== 错误处理 =====")
# 不加错误处理时:
a = 3
b = 0
# 这里会报除零错误
# print(a / b)
# 采用错误处理
try:
print(a / b)
except ZeroDivisionError as ex1: # 捕获除零错误
print("除零错误!", ex1)
finally:
print("程序结束")
print("===== 错误处理2 ======")
# 同时处理多种错误
c = 5
d = "ss"
try:
print(c / d)
except ZeroDivisionError as ex1:
print("除零错误!", ex1)
except TypeError as ex2:
print("类型不对!必须都为数值!", ex2)
except Exception as ex3:
print("未知错误!", ex3)
finally:
print("程序结束!")
思考题
为什么有len(a)和省略len(a)结果会不一样?
# 为什么有len(a)和省略len(a)结果会不一样?
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(a[0::-1])
# [0]
print(a[0:len(a):-1])
# []
当step为负数时,切片将其解释为从start出发以步长|step|逆序索引序列,此时,start和stop的截断依然遵循前述规则,但缺省发生一点变化,因为我们说过,在缺省的情况下,Python的行为是尽可能取最大区间,此时访问是逆序的,start应尽量取大,stop应尽量取小,才能保证区间最大,因此:
按照扩充索引范围的观点,start的缺省值是无穷大(),stop的缺省值是无穷小()
找出1-10之间所有的偶数,并且返回一个列表(这个列表中含以这个偶数为半径的圆的面积)
方法一:使用列表生成式,计算圆的面积要用到圆周率参数,需要导入math模块:
import math
print([math.pi * r * r for r in range(2,11,2)])
方法二:定义一个求圆面积的函数,然后在列表生成式中直接调用函数,从而求出序列中符合条件的半径的面积:
def square(r):
res = math.pi * r *r
return res
print([square(r) for r in range(2,11,2)])
匹配手机号码
手机号码由11位数字组成,通常以1开头。使用正则表达式可以匹配符合这种模式的手机号码。以下是一个匹配手机号码的正则表达式:
pattern = r'^1\d{10}$'
其中,^表示字符串的开始位置,1表示必须以1开头,\d表示匹配任意一个数字,{10}表示匹配前一个字符10次,$表示字符串的结束位置。可以使用re.match函数来匹配手机号码:
import re
pattern = r'^1\d{10}$'
string = '12312345678'
match = re.match(pattern, string)
if match:
print('匹配成功')
else:
print('匹配失败')
输出结果为:
匹配成功
匹配邮箱地址
邮箱地址通常包含@符号和.符号,使用正则表达式可以匹配符合这种模式的邮箱地址。以下是一个匹配邮箱地址的正则表达式:
pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$'
其中,[a-zA-Z0-9._%±]表示匹配任意一个字母、数字、下划线、点、百分号、加号、减号,
+表示匹配前一个字符1次或多次,@表示匹配@符号,[a-zA-Z0-9.-]表示匹配任意一个字母、数字、点、减号,.[a-zA-Z]{2,}表示匹配.符号和至少两个字母的组合。可以使用re.match函数来匹配邮箱地址:
import re
pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$'
string = 'example@example.com'
match = re.match(pattern, string)
if match:
print('匹配成功')
else:
print('匹配失败')
输出结果为:
匹配成功
替换字符串
使用正则表达式可以替换字符串中符合特定模式的部分。以下是一个替换字符串的示例:
import re
pattern = r'\d+'
string = 'a1b2c3d4'
replacement = 'X'
new_string = re.sub(pattern, replacement, string)
print(new_string)
输出结果为:
aXbXcXdX
在上面的示例中,\d+表示匹配任意一个数字,re.sub函数将字符串中所有匹配到的数字替换为X。
[Python]切片完全指南(语法篇)
python——列表生成式
【全文干货】python—函数详解(值得收藏的学习手册)
python中requests库使用方法详解
详解Python模块化——模块(Modules)和包(Packages)
Python sorted()函数的高级使用(多条件)
python 生成器 generator 详解
玩转Python正则表达式:实用教程带你快速入门
Python正则表达式入门
Python3 正则表达式