常用语法
函数重载(Overload)
规则:
-
函数名相同
-
参数个数不同、参数类型不同、参数顺序不同
注意:
-
返回值类型与函数重载无关
-
调用函数时,实参的隐式类型转换可能会产生二义性
默认参数
C++ 允许函数设置默认参数,在调用时可以根据情况省略实参。规则如下:
- 默认参数只能按照从右到左的顺序
- 如果函数同时有声明、实现,默认参数只能放在函数声明中
- 默认参数的值可以是常量、全局符号(全局变量、函数名)
如果函数的实参经常是同一个值,可以考虑使用默认参数。
int age = 33;
void test() {
cout << "test()" << endl;
}
void display(int a = 11, int b = 22, int c = age, void (*func)() = test) {
cout << "a is " << a << endl;
cout << "b is "<< b << endl;
cout << "c is " << c << endl;
func();
}
int main() {
display();
}
函数重载、默认参数可能会产生冲突、二义性(建议优先选择使用默认参数)
void display(int a, int b = 20) {
cout << "a is " << a << endl;
}
void display(int a) {
cout << "a is " << a << endl;
}
int main() {
display(10); // 编译失败,存在二义性
}
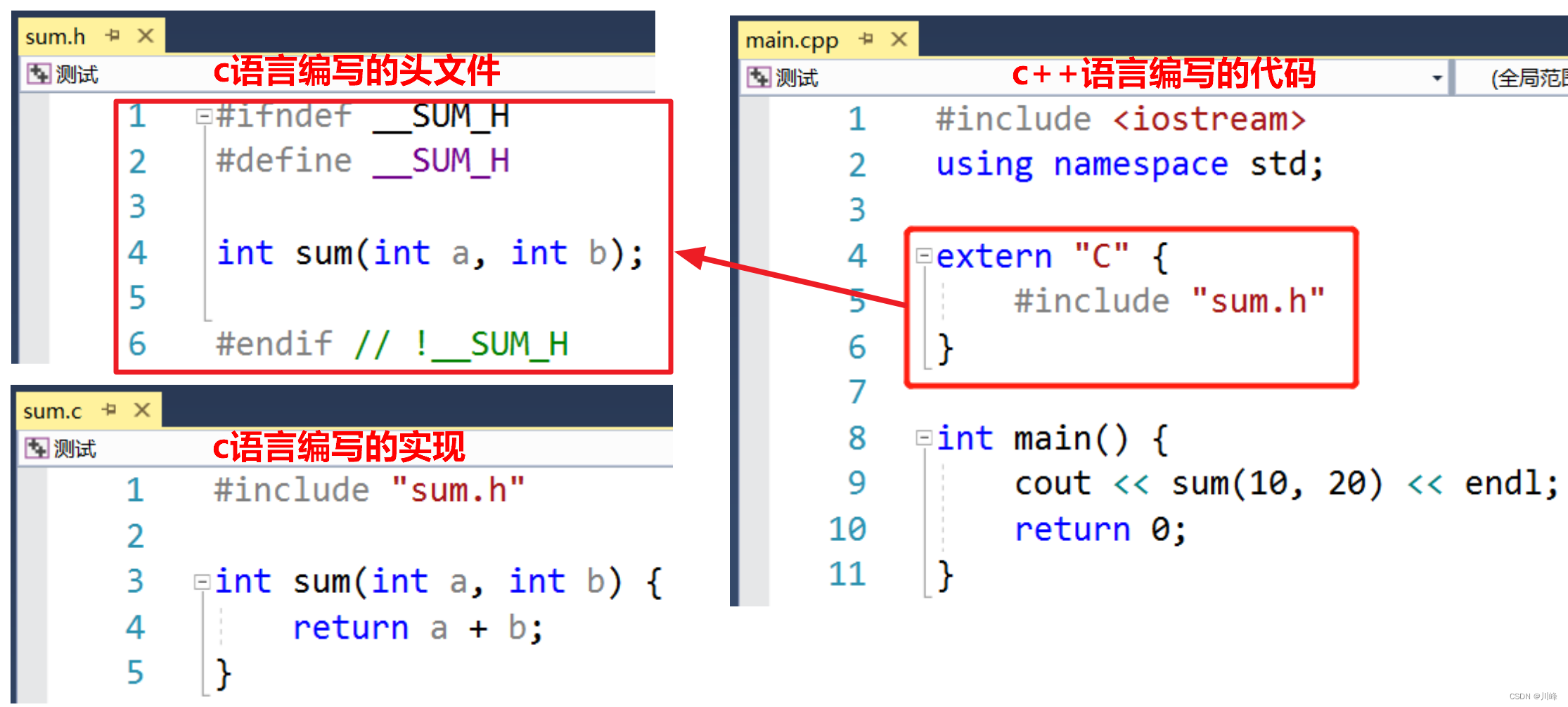
extern "C"
被 extern "C" 修饰的代码会按照 C 语言的方式去编译
extern "C" void func() {
cout << "func()" << endl;
}
extern "C" void func1(int age) {
cout << "func(int age) " << age << endl;
}
如果函数同时有声明和实现,要让函数声明被 extern “C” 修饰,函数实现可以不修饰
extern "C" void func();
extern "C" void func1(int age);
void func() {
cout << "func()" << endl;
}
void func1(int age) {
cout << "func(int age) " << age << endl;
}
extern "C" {
void func();
void func1(int age);
}
void func() {
cout << "func()" << endl;
}
void func1(int age) {
cout << "func(int age) " << age << endl;
}
由于C、C++ 编译规则的不同,在C、C++ 混合开发时,可能会经常出现以下操作:
-
C++ 在调用 C 语言 API 时,需要使用
extern "C"修饰 C 语言的函数声明
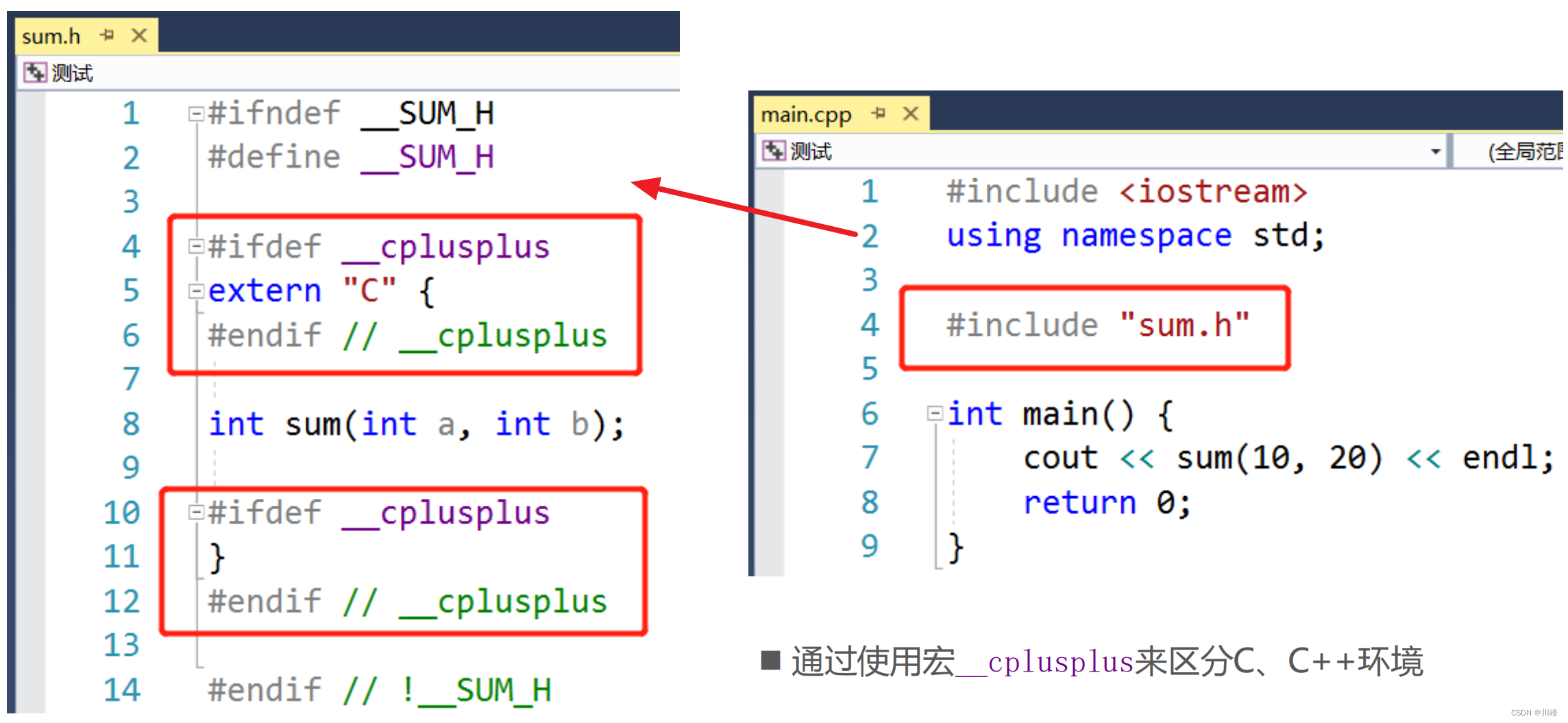
-
有时也会在编写 C 语言代码中直接使用
extern "C",这样就可以直接被 C++ 调用了
#pragma once
我们经常使用#ifndef、#define、#endif来防止头文件的内容被重复包含
#pragma once可以防止整个文件的内容被重复包含
区别:
-
#ifndef、#define、#endif受 C/C++ 标准的支持,不受编译器的任何限制 -
有些编译器不支持
#pragna once(较老编译器不支持,如GCC 3.4版本之前),兼容性不够好 -
#ifndef、#define、#endif可以针对一个文件中的部分代码,而#pragma once只能针对整个文件
内联函数(inline function)
使用inline修饰函数的声明或者实现,可以使其变成内联函数。建议声明和实现都增加inline修饰。
特点:
- 编译器会将函数调用直接展开为函数体代码
- 可以减少函数调用的开销
- 会增大代码体积
注意:
-
尽量不要内联超过10行代码的函数
-
有些函数即使声明为
inline,也不一定会被编译器内联,比如递归函数
VS中可通过如下配置选择禁用或启用内联扩展:
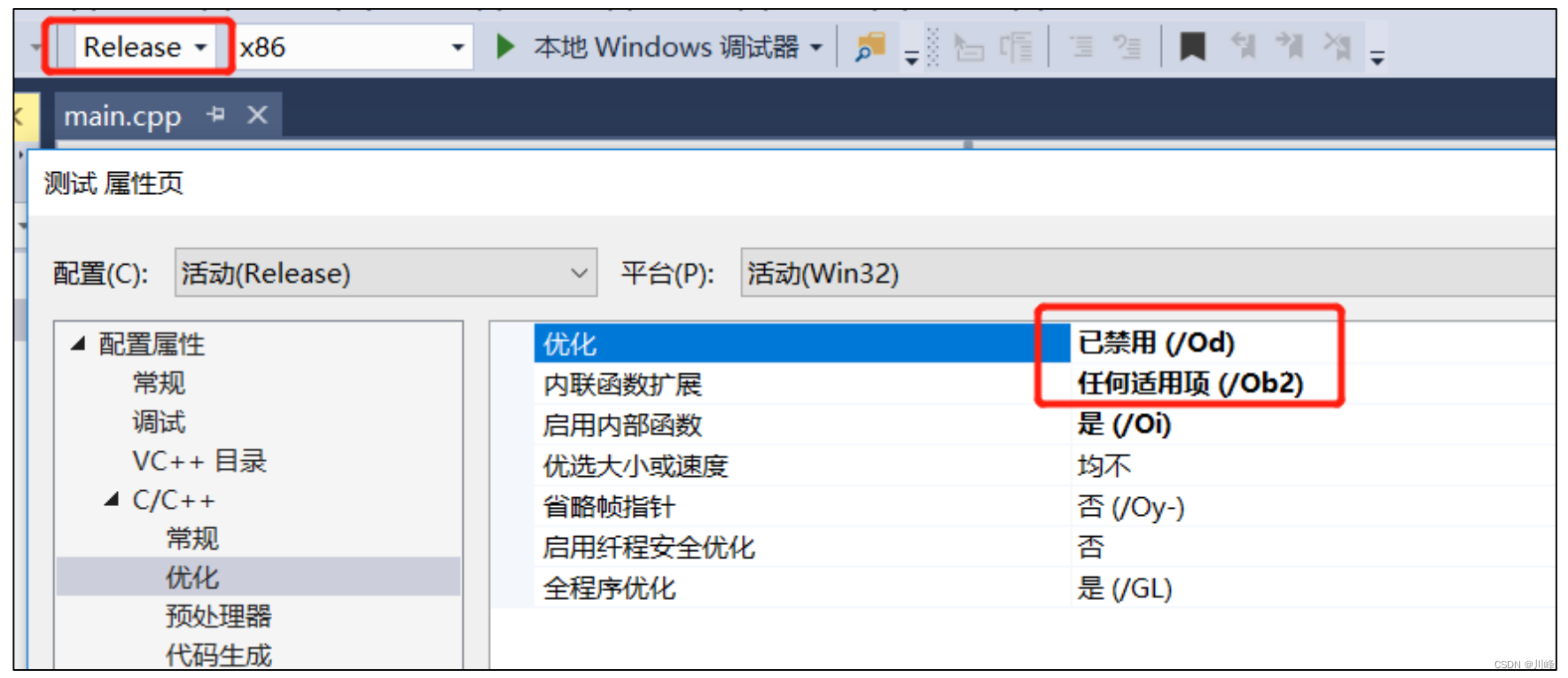
内联函数与宏
-
内联函数和宏,都可以减少函数调用的开销
-
对比宏,内联函数多了语法检测和函数特性
思考以下代码的区别
#define sum(x) (x + x)
int a = 10;
int main() {
std::cout << sum(a++) << std::endl; // 21
std::cout << a << std::endl; // 12
}
- 上面代码中
sum(a++)等价于(a++) + (a++),sum的计算结果会先取a的值(10)再取a++之后a的值(11)所以之和是21,而a本身由于自增了两次所以结果是12
inline int sum(int x) {
return x + x; }
int a = 10;
int main() {
std::cout << sum(a++) << std::endl; // 20
std::cout << a << std::endl; // 11
}
- 上面代码中
sum(a++)属于函数调用,因此会捕获a的副本(10)传入函数中,在函数体中执行10 + 10得到结果是20,在这之后由于a本身执行自增操作变成了11
表达式
C++ 的有些表达式是可以被赋值的
int a = 1;
int b = 2;
(a = b) = 3; // 赋值给了 a
(a < b ? a : b) = 4; // 赋值给了 b
const
-
const是常量的意思,被其修饰的变量不可修改 -
如果修饰的是类、结构体(的指针),其成员也不可以更改
struct Student {
int age; };
int main() {
Student stu1 = {
10};
Student stu2 = {
20};
const Student *pStu1 = &stu1;
*pStu1 = stu2; // 编译报错,*pStu1不能修改
(*pStu1).age = 30; // 编译报错,*pStu1的成员不能修改
pStu1->age = 30; // 编译报错,*pStu1的成员不能修改
pStu1 = &stu2; // 编译成功,pStu1指向可以修改
Student * const pStu2 = &stu2;
*pStu2 = stu1; // 编译成功,*pStu2 可以修改
(*pStu2).age = 30; // 编译成功,*pStu2 的成员可以修改
pStu2->age = 30; // 编译成功,*pStu2 的成员可以修改
pStu2 = &stu1; // 编译报错,pStu2不能修改指向
}
思考:以下5个指针分别是什么含义?
int age = 10;
const int *p0 = &age;
int const *p1 = &age;
int * const p2 = &age;
const int * const p3 = &age;
int const * const p4 = &age;
上面的指针问题可以用以下结论来解决:const修饰的是其右边的内容
验证代码:
int main() {
int a = 2;
int age = 10;
const int *p0 = &age;
p0 = &a; // p0 可以修改
*p0 = 3; // *p0 不能修改, 编译报错
int const *p1 = &age;
p1 = &a; // p1 可以修改
*p1 = 3; // *p1 不能修改, 编译报错
int * const p2 = &age;
p2 = &a; // p2 不能修改, 编译报错
*p2 = 3; // *p2 可以修改
const int * const p3 = &age;
p3 = &a; // p3 不能修改, 编译报错
*p3 = 3; // *p3 不能修改, 编译报错
int const * const p4 = &age;
p4 = &a; // p4 不能修改, 编译报错
*p4 = 3; // *p4 不能修改, 编译报错
}
引用(Reference)
- 在C语言中,使用指针(Pointer)可以间接获取、修改某个变量的值
- 在C++中,使用引用(Reference)可以起到跟指针类似的功能
int age = 20;
// rage 就是一个引用
int &rage = age;
注意点:
- 引用相当于是变量的别名(基本数据类型、枚举、结构体、类、指针、数组等,都可以有引用)
- 对引用做计算,就是对引用所指向的变量做计算
- 在定义的时候就必须初始化,一旦指向了某个变量,就不可以再改变,“从一而终”
- 可以利用引用初始化另一个引用,相当于某个变量的多个别名
- 不存在【引用的引用、指向引用的指针、引用数组】
引用存在的价值之一:比指针更安全、函数返回值可以被赋值
引用的本质
-
引用的本质就是指针,只是编译器削弱了它的功能,所以引用就是弱化了的指针
-
一个引用占用一个指针的大小
常引用(Const Reference)
引用可以被const修饰,这样就无法通过引用修改数据了,可以称为常引用
const必须写在&符号的左边,才能算是常引用
const引用的特点:
- 可以指向临时数据(常量、表达式、函数返回值等)
- 可以指向不同类型的数据
- 作为函数参数时(此规则也适用于
const指针):
✓ 可以接受const和非const实参(但非const引用只能接受非const实参)
✓ 可以跟非const引用构成重载
注意:当常引用指向了不同类型的数据时,会产生临时变量,即引用指向的并不是初始化时的那个变量。
数组的引用
常见的2种写法:
int array[] = {
10,20,30 };
int (&ref1)[3] = array;
int * const &ref2 = array;
ref1[0] = 8;
int a = ref1[2];
ref2[1] = 4;
int b = ref2[2]
变量地址总结
一个变量的地址值,是它所有字节地址中的最小值
面向对象
类
- C++ 中可以使用
struct、class来定义一个类
struct 和 class 的区别:
struct的默认成员权限是publicclass的默认成员权限是private


- 上面代码中
person对象、p指针的内存都是在函数的栈空间,自动分配和回收的 - 可以尝试反汇编
struct和class,看看是否有其他区别 - 实际开发中,用
class表示类比较多
C++编程规范
每个人都可以有自己的编程规范,没有统一的标准,没有标准答案,没有最好的编程规范
变量名规范参考:
- 全局变量:
g_ - 成员变量:
m_ - 静态变量:
S_ - 常量:
C_ - 使用驼峰标识
对象的内存布局
思考:如果类中有多个成员变量,对象的内存又是如何布局的?
struct Person {
int m_id;
int m_age;
int m_height;
void display() {
cout << "m id is " << m_id << endl;
cout << "m_age is " << m_age << endl;
cout << "m_height is " << m_height << endl;
}
};
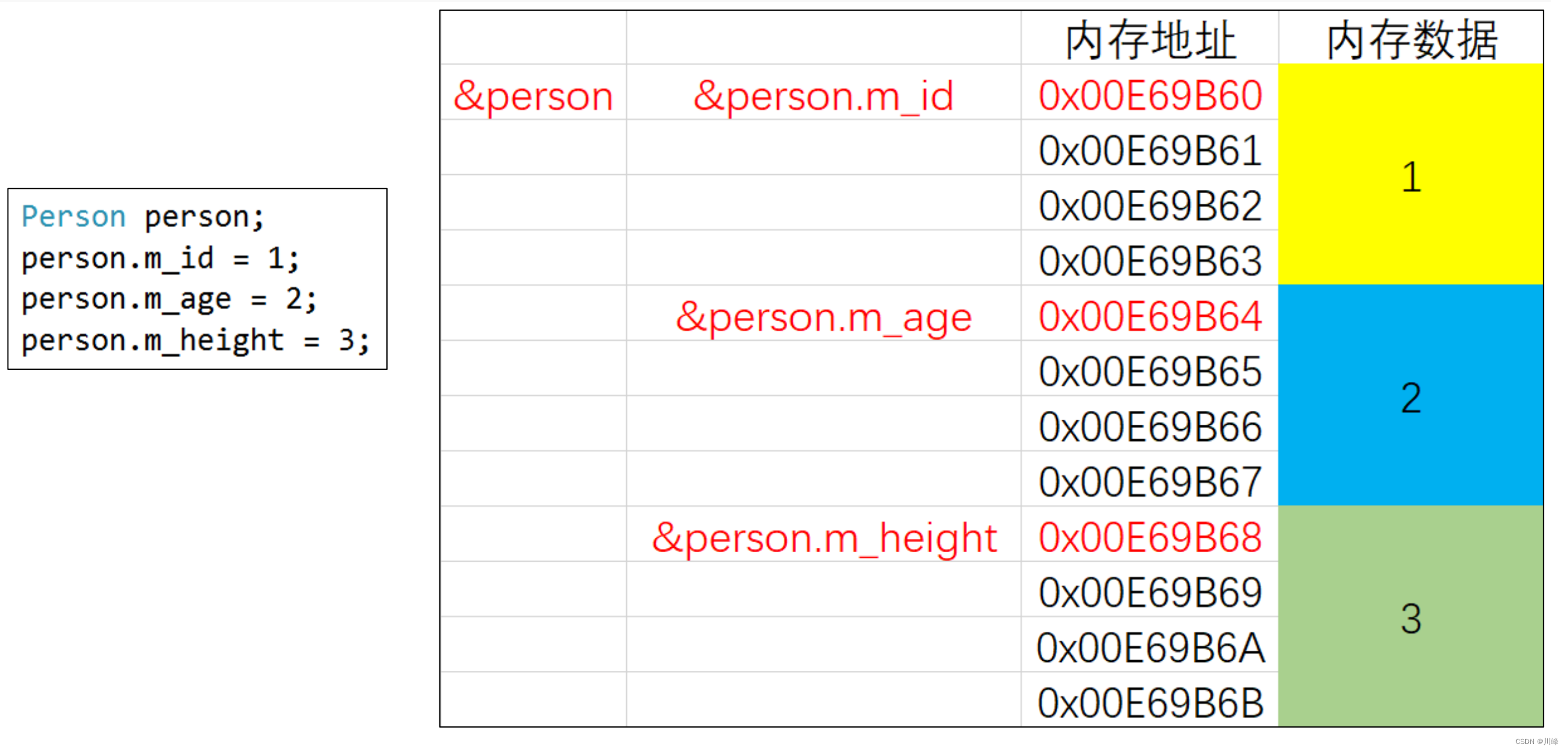
this
-
this是指向当前对象的指针 -
对象在调用成员函数的时候,会自动传入当前对象的内存地址
struct Person {
int m_id;
int m_age;
int m_height;
void display() {
cout << "m id is " << this->m_id << endl;
cout << "m_age is " << this->m_age << endl;
cout << "m_height is " << this->m_height << endl;
}
};
思考:可以利用 this.m_age 来访问成员变量么?
- 不可以,因为
this是指针,必须用this->m_age
指针访问对象成员的本质
思考:以下代码最后打印出来的每个成员变量值是多少?
struct Person {
int m_id;
int m_age;
int m_height;
void display() {
cout << "m id is " << this->m_id << endl;
cout << "m_age is " << this->m_age << endl;
cout << "m_height is " << this->m_height << endl;
}
};
int main() {
Person person;
person.m_id = 10;
person.m_age = 20;
person.m_height = 30;
Person *p = (Person *) &person.m_age;
p->m_id = 40;
p->m_age = 50;
person.display();
}
答案输出是:
m id is 10
m_age is 40
m_height is 50
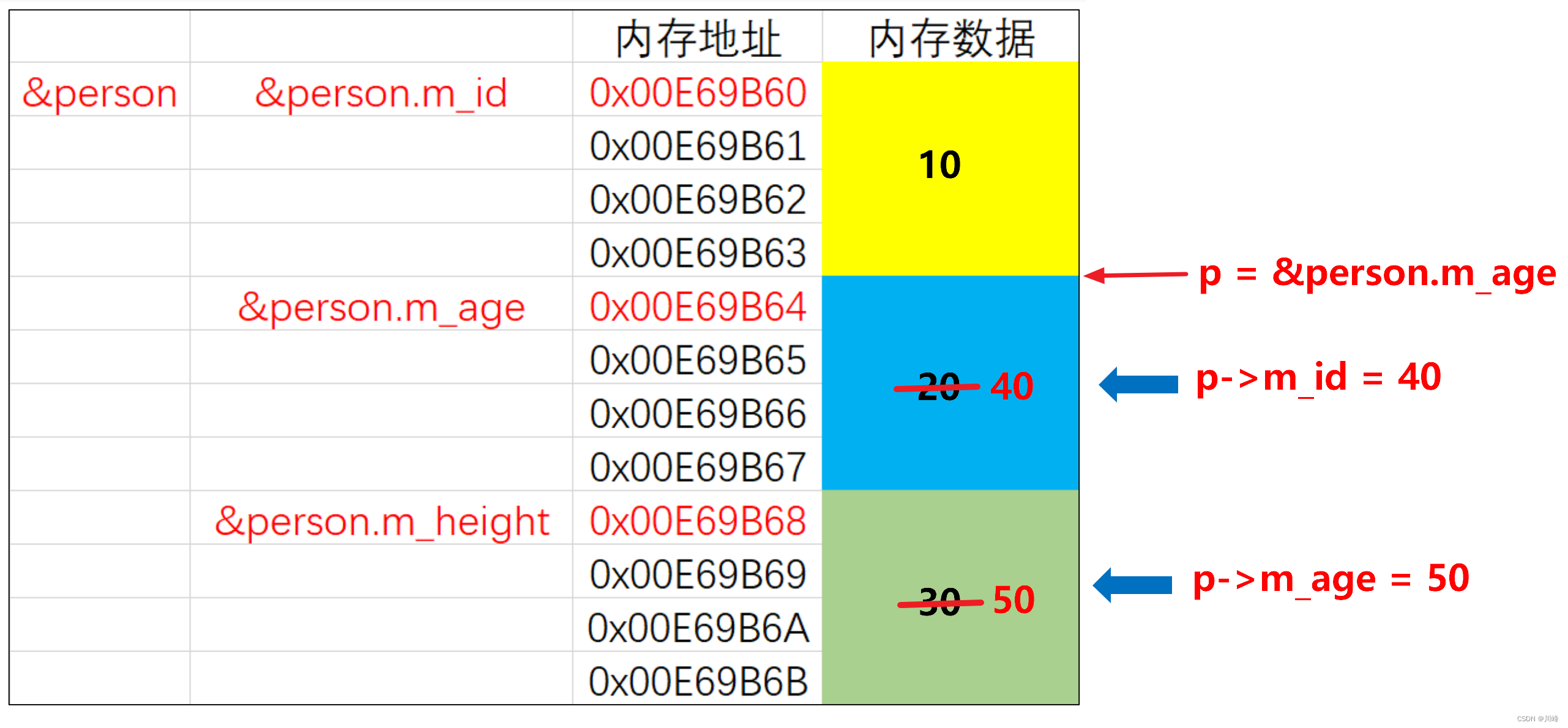
思考:如果将 person.display() 换成 p->display() 呢?
输出如下:
m id is 40
m_age is 50
m_height is -1063256544
此时 p->m_height 指向了一块未知的内存。、
封装
成员变量私有化,提供公共的getter和setter给外界去访问成员变量
struct Person{
private:
int m_age;
public:
void setAge(int age) {
this->m_age = age;
}
int getAge() {
return this->m_age;
}
};
Person person;
person.setAge(20);
cout << person.getAge() << endl;
内存空间的布局
每个应用都有自己独立的内存空间,其内存空间一般都有以下几大区域

-
代码段(代码区):用于存放代码
-
数据段(全局区):用于存放全局变量等
-
栈空间:
- 每调用一个函数就会给它分配一段连续的栈空间,等函数调用完毕后会自动回收这段栈空间
- 自动分配和回收
-
堆空间:需要主动去申请和释放
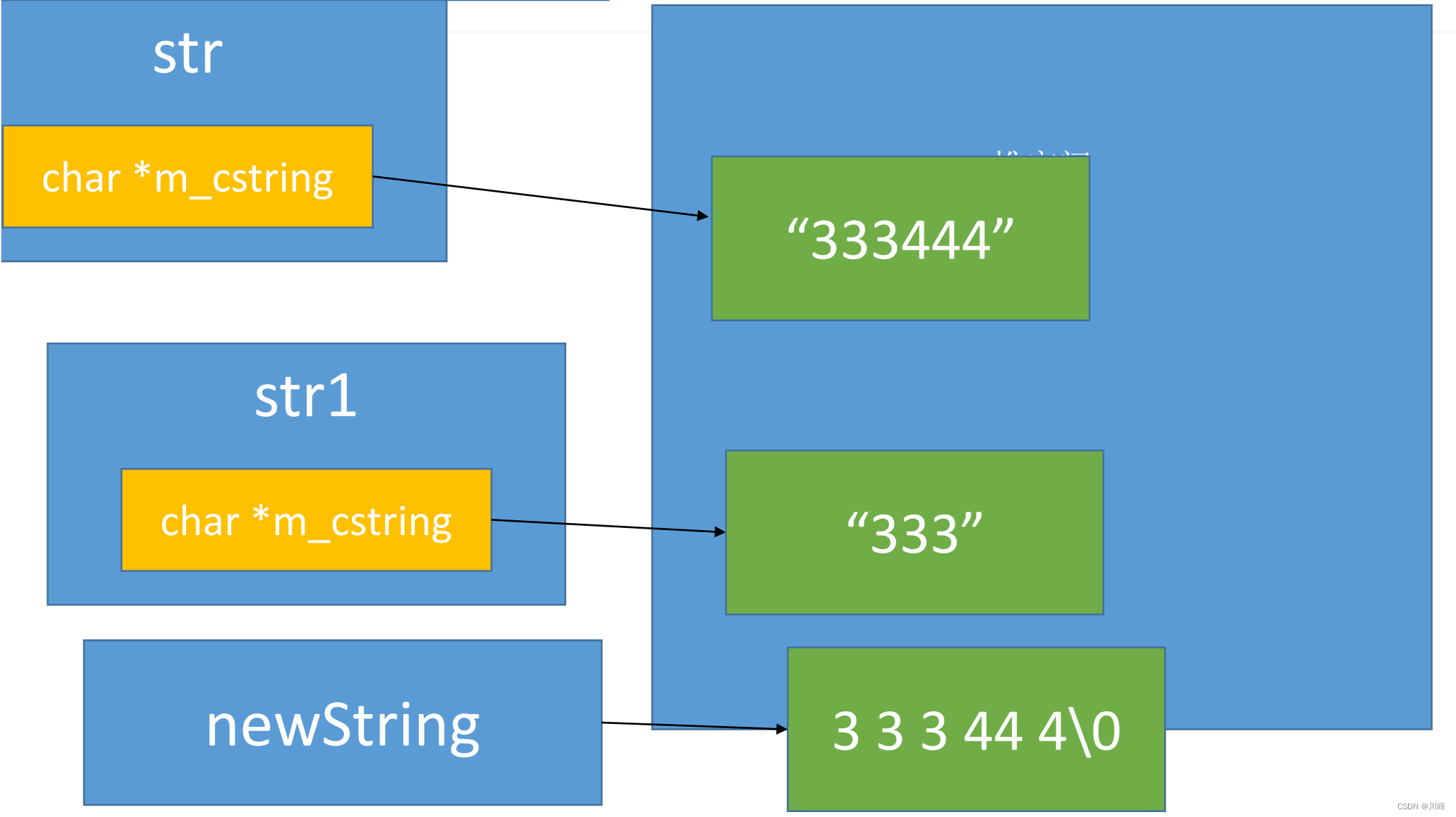
堆空间
在程序运行过程,为了能够自由控制内存的生命周期、大小,会经常使用堆空间的内存
堆空间的申请\释放
-
malloc \ free -
new \ delete -
new[] \ delete[]
注意:
-
申请堆空间成功后,会返回那一段内存空间的地址
-
申请和释放必须是1对1的关系,不然可能会存在内存泄露
现在的很多高级编程语言不需要开发人员去管理内存(比如Java),屏蔽了很多内存细节,利弊同时存在
-
利:提高开发效率,避免内存使用不当或泄露
-
弊:不利于开发人员了解本质,永远停留在API调用和表层语法糖,对性能优化无从下手
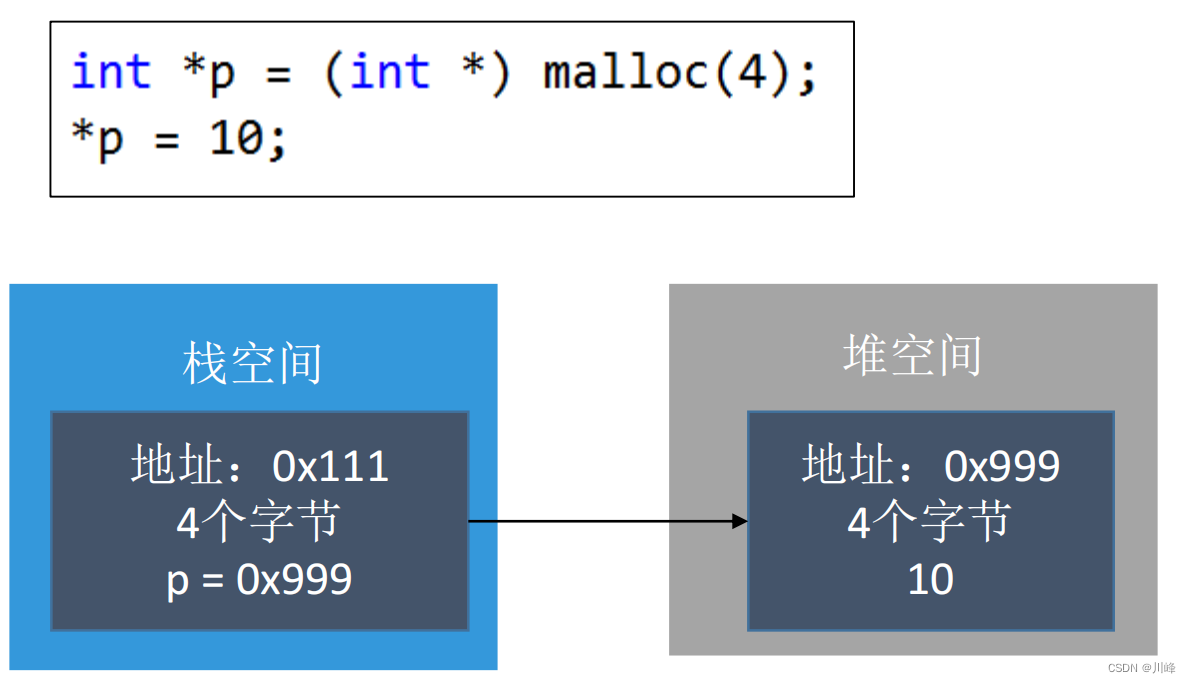
下图是x86环境(32bit):
堆空间的初始化
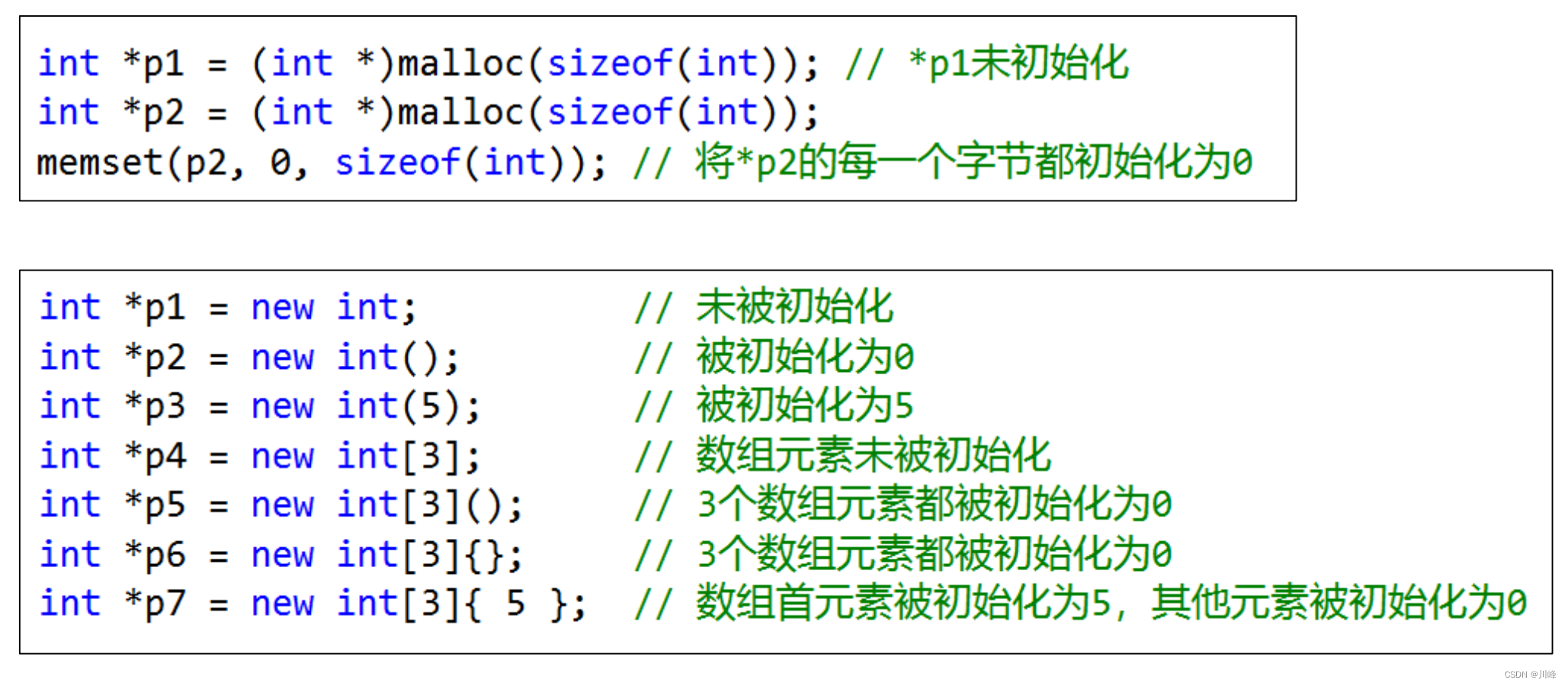
memset
memset函数是将较大的数据结构(比如对象、数组等)内存清零的比较快的方法
Person person;
person.m_id = 1;
person.m_age = 20;
person.m_height = 180;
memset(&person, 0, sizeof(person));
Person persons[] ={
{
1,20,180 }, {
2,25,165,},{
3,27,170 } };
memset(persons, 0, sizeof(persons));
对象的内存
对象的内存可以存在于3种地方:
- 全局区(数据段):全局变量
- 栈空间:函数里面的局部变量
- 堆空间:动态申请内存(
malloc、new等)


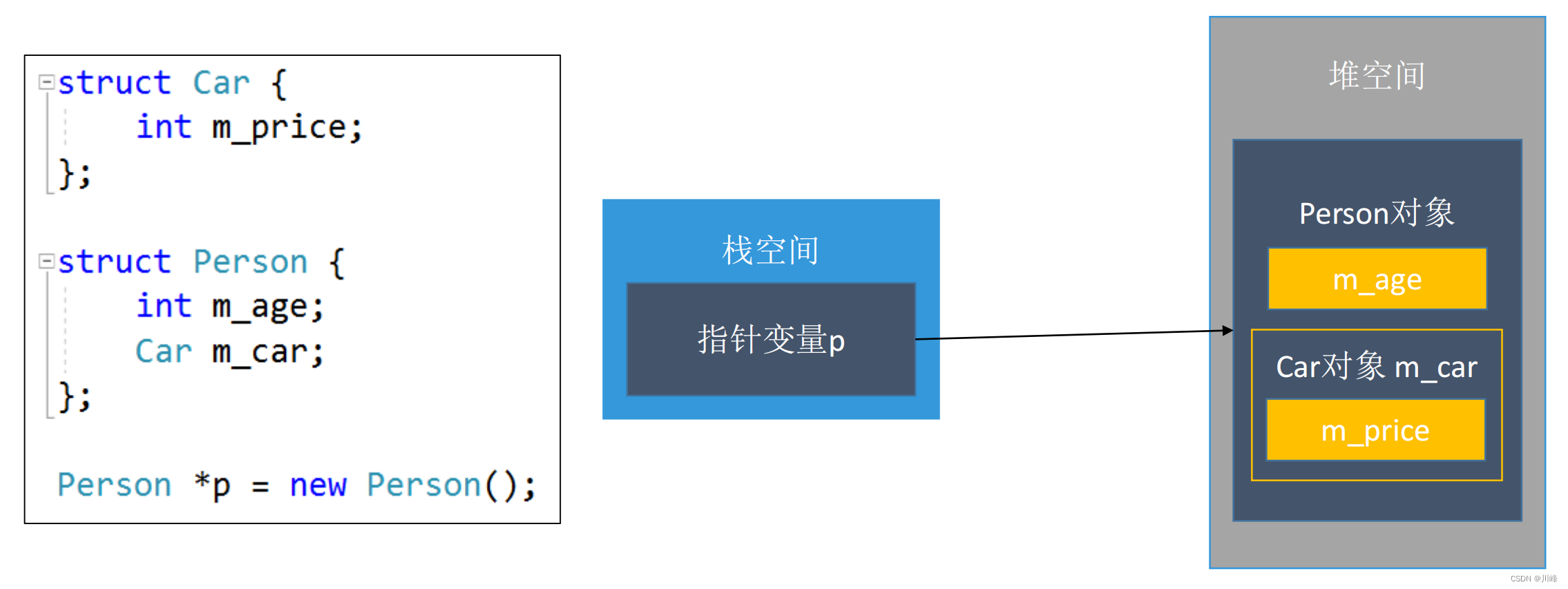
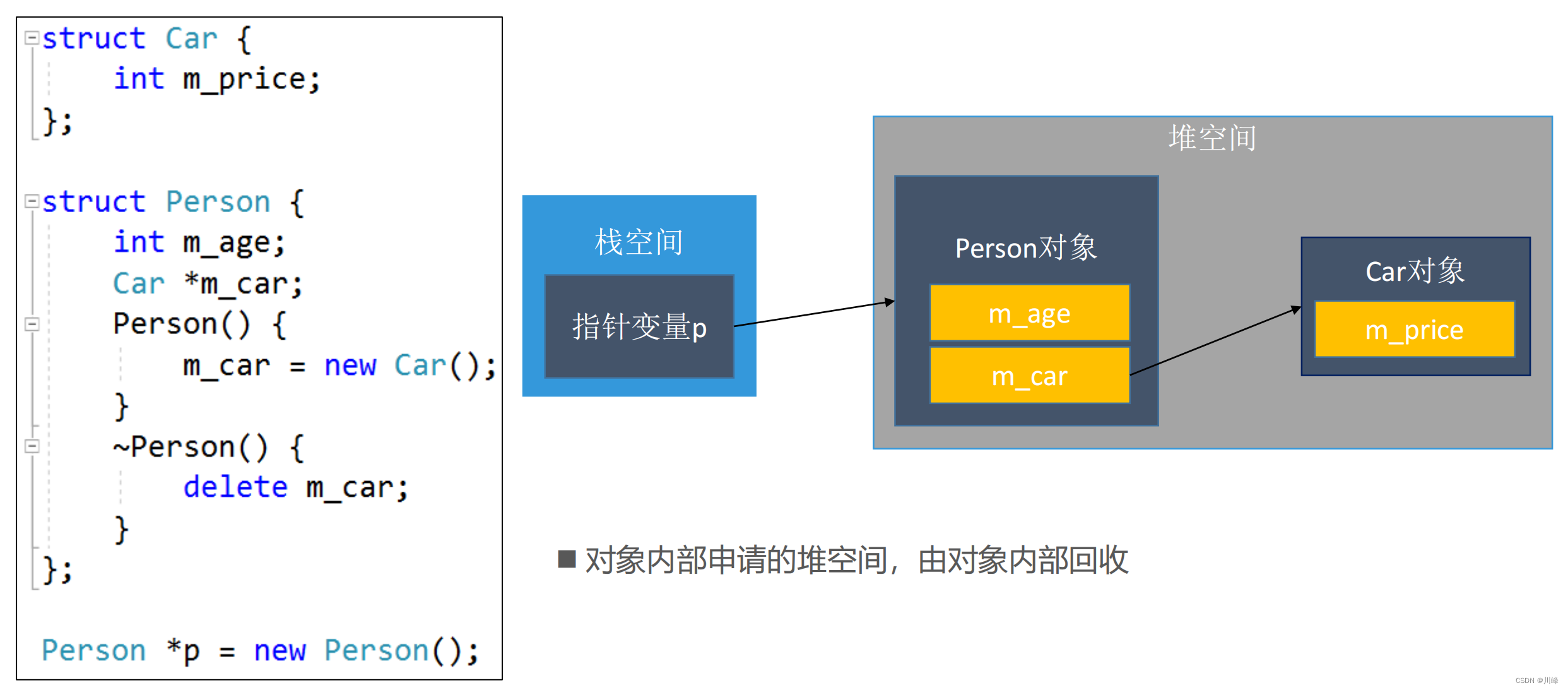
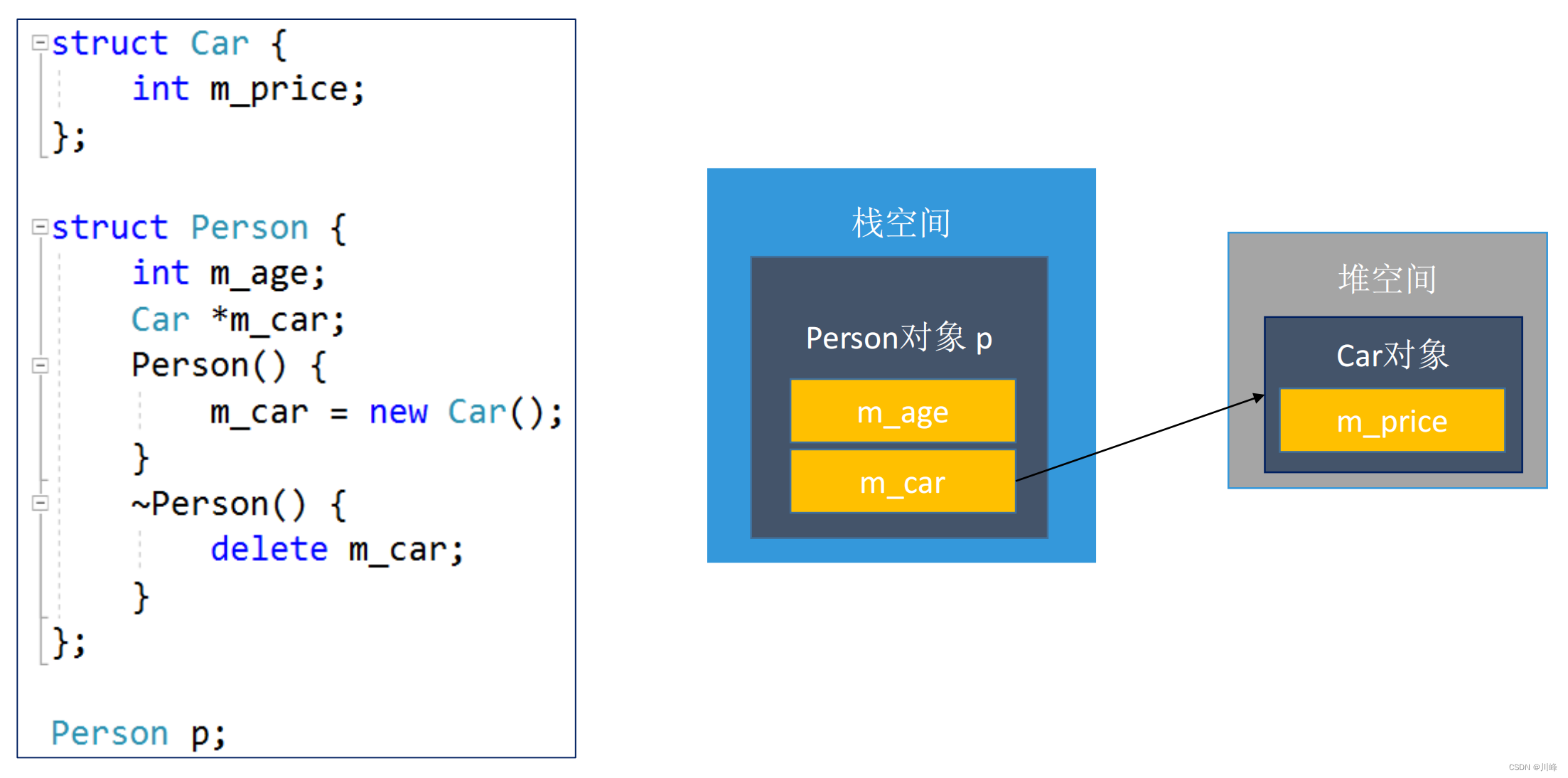
构造函数(Constructor)
构造函数(也叫构造器),在对象创建的时候自动调用,一般用于完成对象的初始化工作
特点:
- 函数名与类同名,无返回值(
void都不能写),可以有参数,可以重载,可以有多个构造函数 - 一旦自定义了构造函数,必须用其中一个自定义的构造函数来初始化对象
注意:
- 通过
malloc分配的对象不会调用构造函数
一个广为流传的、很多教程/书籍都推崇的错误结论:
-
默认情况下,编译器会为每一个类生成空的无参的构造函数
-
正确理解:在某些特定的情况下,编译器才会为类生成空的无参的构造函数(哪些特定的情况?以后再提)
构造函数的调用
struct Person {
int m_age;
Person() {
cout << "Person()" << endl;
}
Person(int age) {
cout << "Person(int age)" << endl;
}
}

默认情况下,成员变量的初始化

- 如果自定义了构造函数,除了全局区,其他内存空间的成员变量默认都不会被初始化,需要开发人员手动初始化。
成员变量的初始化
对象初始化
Person() {
memset(this, 0, sizeof(Person));
}
析构函数(Destructor)
析构函数(也叫析构器),在对象销毁的时候自动调用,一般用于完成对象的清理工作
特点:
- 函数名以
~开头,与类同名,无返回值(void都不能写),无参,不可以重载,有且只有一个析构函数
注意:
- 通过
malloc分配的对象free的时候不会调用析构函数 - 构造函数、析构函数要声明为
public,才能被外界正常使用。
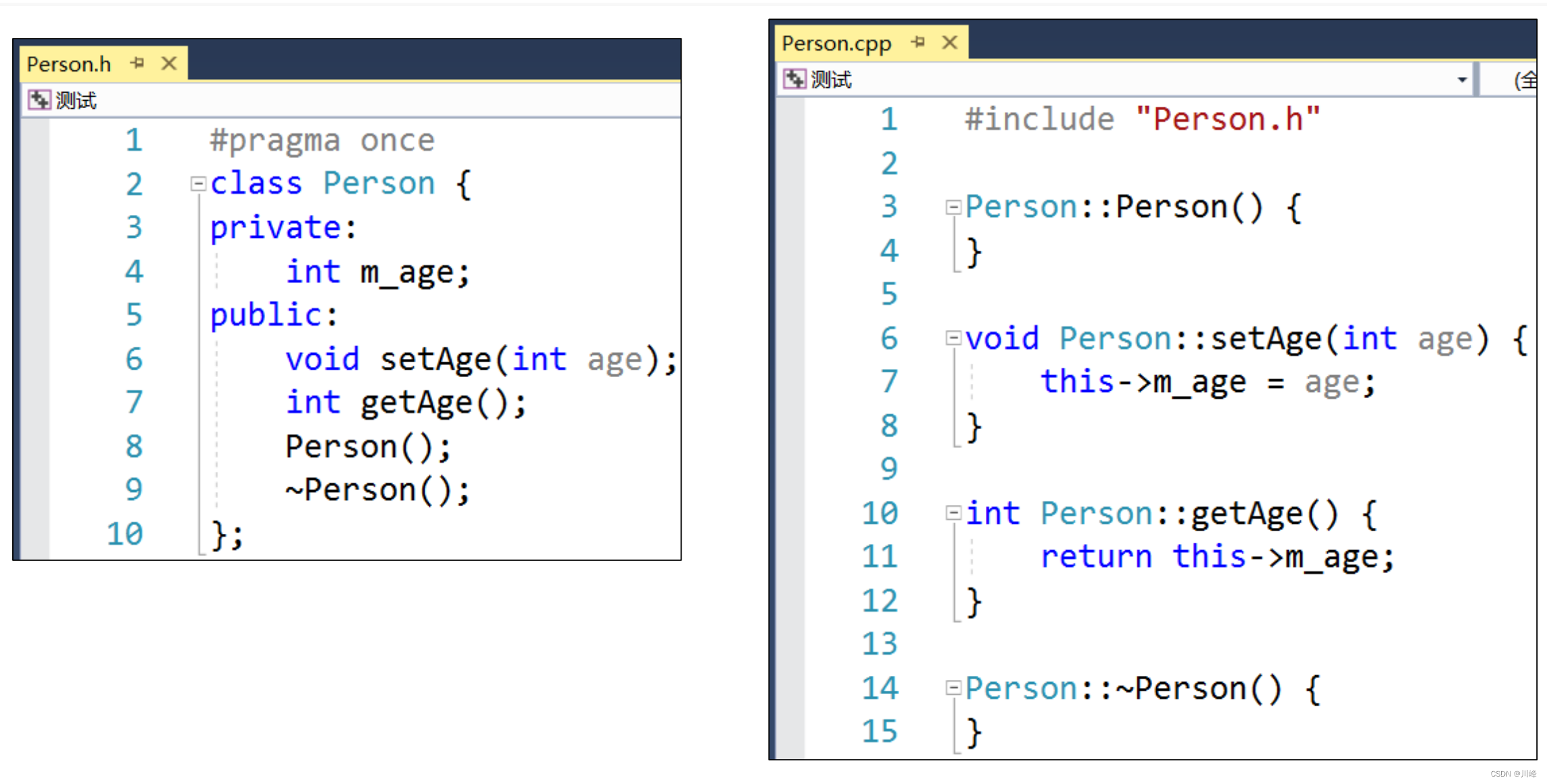
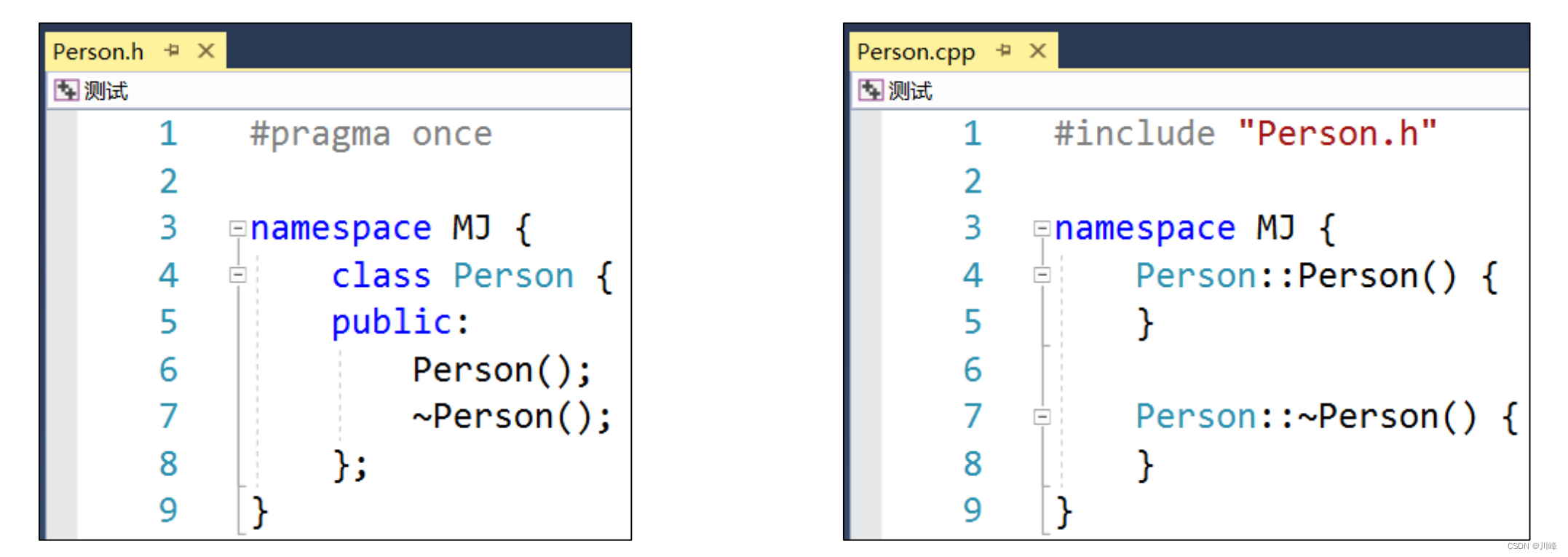
声明和实现分离
命名空间
命名空间可以用来避免命名冲突

思考:如下代码能通过编译吗?
namespace MJ {
int g_age;
}
namespace FX {
int g_age;
}
using namespace MJ;
using namespace FX;
// 这句代码能编译通过么?
g_age = 20;
- 不能,必须指明命名空间前缀,否则具有二义性,编译器无法做出判断
命名空间的嵌套
有个默认的全局命名空间,我们创建的命名空间默认都嵌套在它里面
namespace MJ {
namespace SS {
int g_age;
}
}
int main() {
MJ::SS::g_age = 10;
using namespace MJ::SS;
g_age = 20;
using MJ::SS::g_age;
g_age = 30;
}
int g_no = 20;
namespace MJ {
namespace SS {
int g_age;
}
}
int main() {
::g_no = 20;
::MJ:SS::g_age = 30;
}
命名空间的合并
以下2种写法是等价的:
namespace MJ {
int g_age;
}
namespace MJ {
int g_no;
}
namespace MJ {
int g_age;
int g_no;
}
其他编程语言的命名空间
Java:
- Package
Objective-C:
- 类前缀
继承
继承,可以让子类拥有父类的所有成员(变量\函数)
struct Person {
int m_age;
void run() {
cout << "Person::run()" << endl;
}
};
struct Student : Person {
int m_no;
void study() {
cout << "Student::study()" << endl;
}
};
int main() {
Student student;
student.m_age = 20;
student.m_no = 1;
student.run();
student.study();
}
关系描述
Student是子类(subclass,派生类)Person是父类(superclass,超类)
C++中没有像Java, Objective-C的基类:
- Java:
java.lang.Object - Objective-C:
NSObject
继承关系中的对象内存布局

构造函数的初始化列表
- 一种便捷的初始化成员变量的方式
- 只能用在构造函数中
- 初始化顺序只跟成员变量的声明顺序有关
下面两种代码写法是等价的:
struct Person {
int m_age;
int m_height;
Person(int age, int hei