文章目录
- 总表
- 均匀分布和三角分布
- 幂分布
- 与正态分布相关的分布
- 与Gamma相关的分布
- 极值分布
总表
np.random中提供了一系列的分布函数,用以生成符合某种分布的随机数。下表中,如未作特殊说明,均有一个size参数,用以描述生成数组的尺寸。
这些分布函数会频繁的使用 Γ \Gamma Γ函数,其定义为
Γ ( x ) = ∫ 0 − ∞ t x − 1 d − t d t \Gamma(x)=\int_0^{-\infty}t^{x-1}d^{-t}\text dt Γ(x)=∫0−∞tx−1d−tdt
当 x x x为整数时, Γ ( x ) = x ! \Gamma(x)=x! Γ(x)=x!。
符号 ( n N ) \binom{n}{N} (Nn)为组合符号,用 Γ \Gamma Γ函数表示为
( n N ) = Γ ( N ) Γ ( N − n ) Γ ( n ) \binom{n}{N}=\frac{\Gamma(N)}{\Gamma(N-n)\Gamma(n)} (Nn)=Γ(N−n)Γ(n)Γ(N)
| 函数 | 概率密度函数(PDF) | 备注 |
|---|---|---|
| binomial(n, p) | p ( N ) = ( n N ) p N ( 1 − p ) n − N p(N) = \binom{n}{N}p^N(1-p)^{n-N} p(N)=(Nn)pN(1−p)n−N | 二项分布 |
| multinomial(n, pvals) | 多项分布 | |
| geometric§ | f ( n ) = ( 1 − p ) n − 1 p f(n)=(1-p)^{n-1}p f(n)=(1−p)n−1p | 几何分布 |
| negative_binomial(n, p) | p ( N ) = Γ ( N + n ) N ! Γ ( n ) p n ( 1 − p ) N p(N)=\frac{\Gamma(N+n)}{N!\Gamma(n)}p^n(1-p)^N p(N)=N!Γ(n)Γ(N+n)pn(1−p)N | 负二项分布 |
| poisson([lam]) | f ( k ) = λ k e − λ k ! f(k)=\frac{\lambda^ke^{-\lambda}}{k!} f(k)=k!λke−λ | 泊松分布 |
| logseries§ | p ( k ) = − p k k ln ( 1 − p ) p(k)=\frac{-p^k}{k\ln(1-p)} p(k)=kln(1−p)−pk | 对数级数分布 |
| gamma(shape[, scale]) | p ( x ) = x k − 1 e − x / θ θ k Γ ( k ) p(x)=x^{k-1}\frac{e^{-x/\theta}}{\theta^k\Gamma(k)} p(x)=xk−1θkΓ(k)e−x/θ | 伽马分布 |
| beta(a, b) | Γ ( a + b ) Γ ( a ) Γ ( b ) x a − 1 ( 1 − x ) b − 1 \frac{\Gamma(a+b)}{\Gamma(a)\Gamma(b)}x^{a-1}(1-x)^{b-1} Γ(a)Γ(b)Γ(a+b)xa−1(1−x)b−1 | 贝塔分布 |
| dirichlet(alpha) | p ( x ) = ∏ i = 1 k x i α i − 1 p(x)=\prod_{i=1}^kx_i^{\alpha_i-1} p(x)=∏i=1kxiαi−1 | 狄利克雷分布 |
| logistic([loc, scale]) | p ( x ) = ( x − μ ) / s s ( 1 + exp [ − ( x − μ ) / s ] ) 2 p(x)=\frac{(x-\mu)/s}{s(1+\exp[-(x-\mu)/s])^2} p(x)=s(1+exp[−(x−μ)/s])2(x−μ)/s | Logistic分布 |
| triangular(L, M, R) | 三角形分布 | |
| uniform([low, high]) | p ( x ) = 1 b − a p(x)=\frac{1}{b-a} p(x)=b−a1 | 均匀分布 |
| vonmises(mu, kappa) | p ( x ) = exp [ κ ( x − μ ) ] 2 π I 0 ( κ ) p(x)=\frac{\exp[{\kappa(x-\mu)}]}{2\pi I_0(\kappa)} p(x)=2πI0(κ)exp[κ(x−μ)] | von Mises分布 |
| zipf(a) | p ( k ) = k − a ζ ( a ) p(k)=\frac{k^{-a}}{\zeta(a)} p(k)=ζ(a)k−a | 齐普夫分布 |
| pareto(a) | p ( x ) = m a x a p(x)=\frac{m^a}{x^{a}} p(x)=xama | 帕累托分布 |
| power(a) | p ( x ) = a x a − 1 p(x)=ax^{a-1} p(x)=axa−1 | 幂分布 |
| gumbel([loc, scale]) | exp [ − z − e − z ] , z = x − μ λ \exp[{-z-e^{-z}}], z=\frac{x-\mu}{\lambda} exp[−z−e−z],z=λx−μ | 耿贝尔分布 |
| chisquare(df) | ( 1 / 2 ) k / 2 Γ ( k / 2 ) x k / 2 − 1 e − x / 2 \frac{(1/2)^{k/2}}{\Gamma(k/2)}x^{k/2-1}e^{-x/2} Γ(k/2)(1/2)k/2xk/2−1e−x/2 | 卡方分布 |
| f(dfnum, dfden) | F分布 | |
| noncentral_chisquare | 非中心卡方分布 | |
| noncentral_f | 非中心F分布 | |
| hypergeometric | p ( x ) = ( g x ) ( b n − x ) ( g + b n ) p(x)=\frac{\binom{g}{x}\binom{b}{n-x}}{\binom{g+b}{n}} p(x)=(ng+b)(xg)(n−xb) | 超几何分布 |
loc一般在函数中为
μ
\mu
μ, scale为
λ
\lambda
λ或
k
k
k等。
I 0 I_0 I0为0阶Bessel函数。
上表中,有一些概率密度表达式过于复杂,故而未列入表中。
首先,numpy提供了五种标准分布
| 概率密度表达式 | ||
|---|---|---|
| standard_cauchy() | 标准柯西分布 | P ( x ) = 1 π ( 1 + x 2 ) P(x)=\frac{1}{\pi(1+x^2)} P(x)=π(1+x2)1 |
| standard_exponential() | 标准指数分布 | P ( x ) = e − x P(x)=e^{-x} P(x)=e−x |
| standard_gamma(k) | 标准伽马分布 | P ( x ) = x k − 1 e − x Γ ( k ) P(x)=x^{k-1}\frac{e^{-x}}{\Gamma(k)} P(x)=xk−1Γ(k)e−x |
| standard_normal() | 标准正态分布 | P ( x ) = e − x 2 P(x) = e^{-x^2} P(x)=e−x2 |
| standard_t(df) | 标准学生分布 |
详情可见Numpy中提供的五种标准随机分布详解
均匀分布和三角分布
所谓均匀分布,就是在事件空间中,所有事件的概率都是相等的连续分布,是最简单的分布函数,在 ( a , b ) (a,b) (a,b)区间内,所有点差不多构成了一个矩形,所以均匀分布也叫矩形分布;和矩形分布相似,概率密度函数为三角形的分布,就是三角形分布。
Python均匀分布和三角形分布
幂分布
幂分布的形式是非常简单的,其概率密度函数为 p ( x ) = a x a − 1 p(x)=ax^{a-1} p(x)=axa−1,在Python中,除了幂分布之外,还提供了另外两种幂分布,记帕累托分布和奇普夫分布。
帕累托在1906年提出了有关意大利社会财富分配的分配规律,即20%的人口掌握了80%的财富,这个规律后来被发现十分普遍,以至于约瑟夫·朱兰后来将其称为帕累托法则,也被成为八二法则。
美国学者Zipf在研究词频的时候发现,如果统计一篇较长文章中的词频,并将词频按照高低从前向后依次排列,将频次最高的词记为1、次高的词记为2,依次类推,最后使用频率最低的词为N。若用f表示频次,r表示等级序号,则fr是常数,此即Zipf定律。
Python幂分布
与正态分布相关的分布
正态分布,最早由棣莫弗在二项分布的渐近公式中得到,而真正奠定正态分布地位的,却是高斯对测量误差的研究。测量是人类与自然界交互中必不可少的环节,测量误差的普遍性,确立了正态分布作用范围的广泛性,或许正因如此,正态分布才又被称为Gauss分布。
Python生成正态分布的随机数
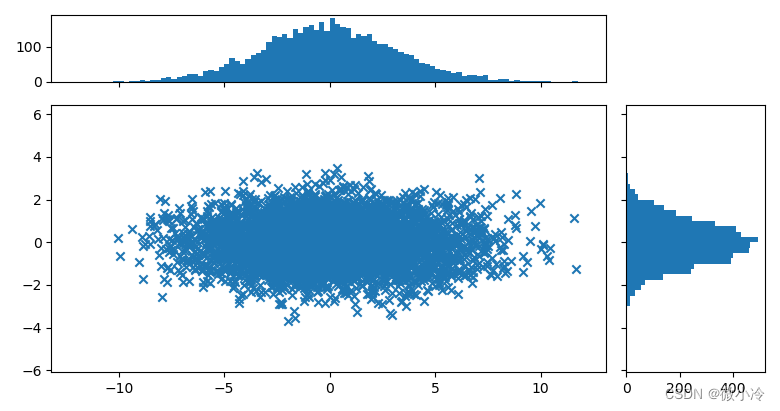
若 k k k个互相独立的随机变量 ξ 1 , ξ 2 , ⋯ , ξ k \xi_1, \xi_2,\cdots,\xi_k ξ1,ξ2,⋯,ξk,均服从标准正态分布,则这k个随机变量的平方和构成一个新变量,新变量服从 χ 2 \chi^2 χ2分布。
Python卡方分布
与Gamma相关的分布
在我的印象中,二项分布貌似是高中学到的第一个分布,就算不是第一个,也是第一批。所以从理解上来说是不存在困难的,在 N N N次独立重复的伯努利试验中,设A在每次实验中发生的概率均为 p p p。则 N N N次试验后A发生 k k k次的概率分布,就是二项分布。
从二项分布到泊松分布
多项分布是对二项分布的一个自然的推广。
二项分布最常见的案例就是投硬币,那么投掷硬币可能有两个结果产生,所以谓之二项;如果把硬币改成骰子,由于骰子有6个面,相当于每次对应六个可能发生的结果,从而可以谓之六项分布。总而言之,把一个总体按照某种属性分成有限个类的时候,就会涉及到多项分布
Python生成多项分布随机数

Poisson分布指的是,单个事件在某一刻发生的概率。Gamma分布更进一步,指的是某个事件在某个时刻发生第
n
n
n次的概率。
【Python】Gamma分布详解
投硬币,硬币是正还是反,这属于两点分布的问题。
疯狂投硬币,正面出现的次数,服从二项分布。
二项分布中,若特定时间内的伯努利试验次数趋于无穷大,那么在某一时刻发生某事件的概率,服从泊松分布。
在某一时刻,发生第N次事件,其概率服从 Γ \Gamma Γ分布。
回到抛硬币的问题,如果硬币出现正反的概率是未知的,考虑到时间地点重力等因素的不同,硬币出现正面的概率甚至可能是不稳定的,换言之,硬币出现正面的概率,或许也是服从某种分布的,此即Beta分布
【Python】Beta分布详解

极值分布
设 X 1 , X 2 … , X n X_1,X_2\dots,X_n X1,X2…,Xn为从总体 F F F中抽出的独立同分布样本,且
M = max ( X 1 , … , X n ) , m = min ( X 1 , … , X n ) M=\max(X_1,\dots,X_n), m=\min(X_1,\dots,X_n) M=max(X1,…,Xn),m=min(X1,…,Xn)
若存在 C n > 0 C_n>0 Cn>0和 D n D_n Dn,使得 C n M + D n C_nM+D_n CnM+Dn按分布收敛于 G ( x ) G(x) G(x),则此 G ( x ) G(x) G(x)为极大值分布,同理可定义极小值分布。Fisher和Tippett证明了极值分布只有三种形式,分别是
| I型 | G 1 ( x ) = exp ( − e − x ) G_1(x)=\exp(-e^{-x}) G1(x)=exp(−e−x) | Gumbel分布 |
| II型 | G 2 ( x ) = exp ( − x − α ) , x > 0 , α > 0 G_2(x)=\exp(-x^{-\alpha}), x>0, \alpha>0 G2(x)=exp(−x−α),x>0,α>0 | Fréchet分布 |
| III型 | G 3 ( x ) = exp ( − ( − x ) α ) , x < 0 , α > 0 G_3(x)=\exp(-(-x)^\alpha), x<0, \alpha>0 G3(x)=exp(−(−x)α),x<0,α>0 | Weibull分布 |
Numpy中的Gumbel分布和Logistic分布
Python威布尔分布