文章目录
- 前置知识
- redis的单线程架构
前置知识
type命令实际返回的就是当前键的数据结构类型,它们分别是:string(字符串)、list(列表)、hash(哈希)、set(集合)、zset(有序集合),但这些只是Redis对外的数据结构
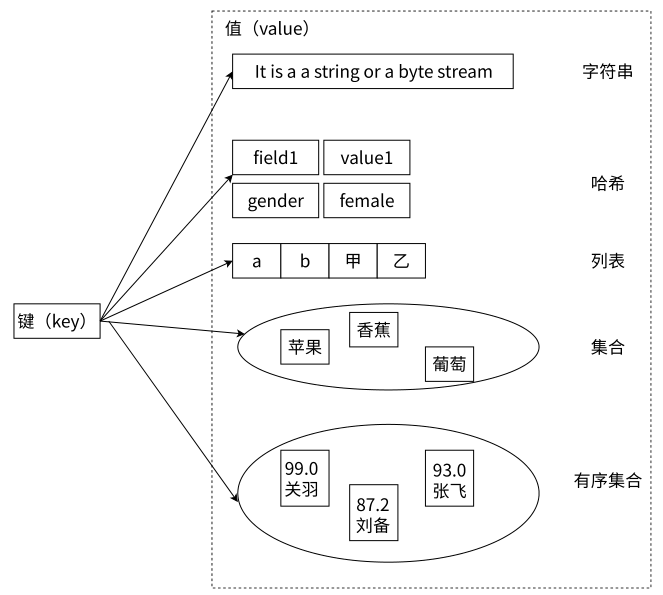
实际上Redis针对每种数据结构都有⾃⼰的底层内部编码实现,⽽且是多种实现,这样Redis会在合适的场景选择合适的内部编码
string内部编码

raw:最基本的字符串,底层就是char类型的数组
int:redis通常可以实现计数的功能,当value是一个整数的时候,此时可能redis会直接使用int来进行保存,此时占用空间更少,可以支持算术运算
embstr:针对短字符串进行特殊优化
hash内部编码

hashtable:最基本的哈希表
ziplist:在哈希表里面元素比较少的时候,可能就优化成ziplist(压缩列表),能够节省空间,占用的内存更小
list内部编码

linkedlist:链表 ziplist:压缩列表
但是从redis3.2开始,引入了新的实现方式:quicklist,同时兼顾了上述两个的优点。
quicklist是一个链表,每个元素又是一个ziplist,将空间和效率都兼顾到,类似C++当中的queue
set内部编码

- intset:集合当中存的都是整数
zset内部编码

- skiplist:跳表也是链表,但是每个节点上有多个指针域,巧妙的搭配这些指针域的指向,可以做到从跳表上查询元素的时间复杂度是 O ( l o g N ) O(logN) O(logN)
可以看到每种数据结构都有⾄少两种以上的内部编码实现,比如list数据结构,包含了linkedlist和ziplist两种内部编码,可以通过:object encoding命令查询内部编码,redis会根据当前的实际情况选择内部的编码方式,自动进行适应
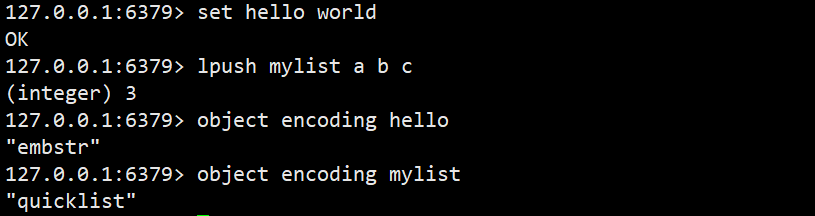
redis这样设计的好处:
- 1)可以改进内部编码,⽽对外的数据结构和命令没有任何影响,这样⼀旦开发出更优秀的内部编码,⽆需改动外部数据结构和命令,例如Redis3.2提供了quicklist,结合了ziplist和linkedlist两者的优势,为列表类型提供了⼀种更为优秀的内部编码实现,⽽对⽤⼾来说基本⽆感知
- 2)多种内部编码实现可以在不同场景下发挥各⾃的优势,例如ziplist⽐较节省内存,但是在列表元素⽐较多的情况下,性能会下降,这时候Redis会根据配置选项将列表类型的内部实现转换为linkedlist,整个过程⽤⼾同样⽆感知
redis的单线程架构
Redis使⽤了单线程架构来实现⾼性能的内存数据库服务,例如:宏观上,三个客户端同时请求redis服务,微观上:客⼾端是有前后次序的,虽然顺序不确定
正是因为redis服务器是单线程模型,所以保证了收到的多个请求是串行执行的,多个请求到达redis服务器,需要先在队列当中排队,在等待redis服务器一个一个的取出里面的命令再执行(串行+顺序的执行)
为什么单线程也能这么快
1)纯内存访问。Redis将所有数据放在内存中,内存的响应时⻓⼤约为100纳秒,这是Redis达到每秒万级别访问的重要基础
2)⾮阻塞IO。Redis使⽤epoll作为I/O多路复⽤技术的实现,再加上Redis⾃⾝的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不在⽹络I/O上浪费过多的时间,网络IO由eoll负责
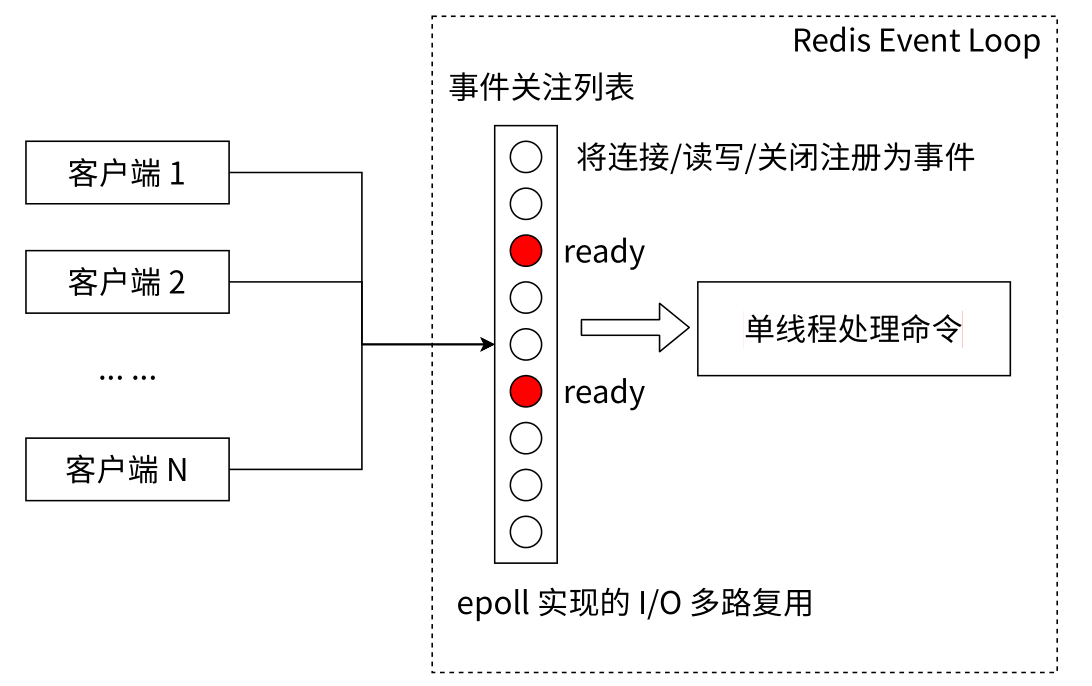
3)单线程避免了线程切换和竞态产⽣的消耗。单线程可以简化数据结构和算法的实现,让程序模型更简单;其次多线程避免了在线程竞争同⼀份共享数据时带来的切换和等待消耗
缺陷
对于单个命令的执⾏时间都是有要求的。如果某个命令执⾏过⻓,会导致其他命令全部处于等待队列中,迟迟等不到响应,造成客⼾端的阻塞,对于Redis这种⾼性能的服务来说是⾮常严重的,所以Redis的核心业务逻辑是⾯向快速执⾏场景的