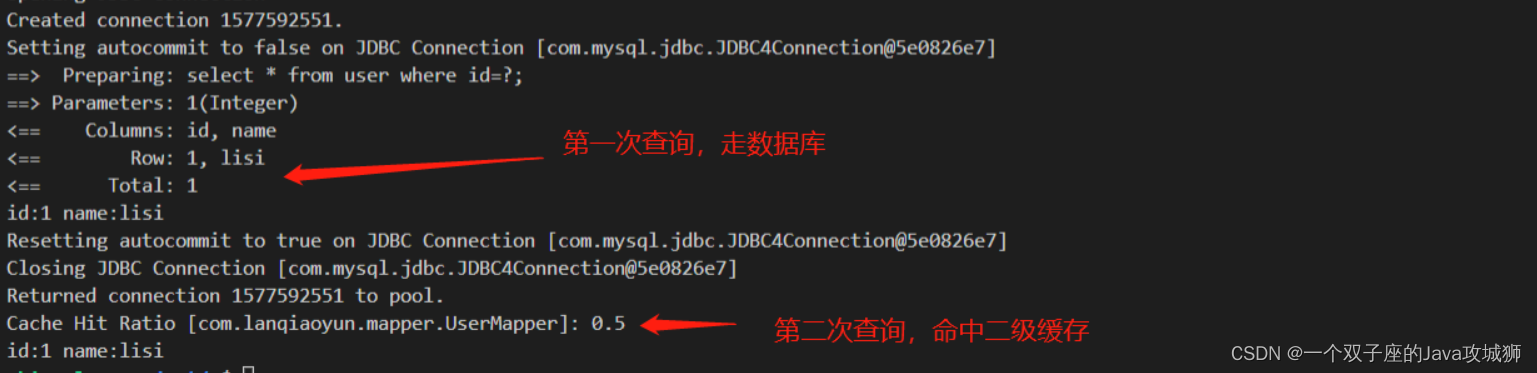
在用Python进行时间序列分析时,我们可能经常需要计算历史的一些特征。一般会使用rolling()函数,这里介绍一下计算包括当前行的历史特征和不包括当前行的历史特征
1. 包括当前行
这里先简单介绍一下rolling()函数
pandas.DataFrame.rolling官方文档
DataFrame.rolling(window, min_periods=None, center=False, win_type=None, on=None, axis=0, closed=None, step=None, method=‘single’)
常用参数解释:
- window: 时间窗大小,一般为整数,表示向前观测n个数据
- min_periods: 最小需要有值的观测点的数量
- center: 是否使用当前行作为窗口的中间行
- on: 对于多列的DataFrame, 用on指定使用哪列
- axis: 0→行,1→列
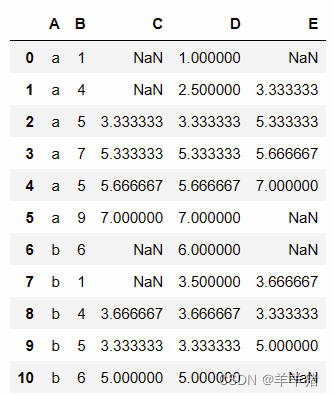
举个例子
data = {'A': ['a','a','a','a','a','a','b','b','b','b','b'],
'B': [1,4,5,7,5,9,6,1,4,5,6]}
df = pd.DataFrame(data)

获取每组当前行和上面两行(一共3行)的均值
# 这里可以对比一下前3个常用参数的区别
# mean()可以改成自己需要的公式
df['C'] = df.groupby(['A'])['B'].apply(lambda x: x.rolling(3).mean())
# df['C'] = df.groupby(['A'],as_index=False)['B'].rolling(3).mean()[['B']]
df['D'] = df.groupby(['A'])['B'].apply(lambda x: x.rolling(3,min_periods=1).mean())
df['E'] = df.groupby(['A'])['B'].apply(lambda x: x.rolling(3, center=True).mean())
2. 不包括当前行
但在使用rolling()获取前几行的数值进行计算时,都会包括当前行。如果我们的计算不想包括当前行的数值,我们还需要额外使用bfill()和shift()进行计算
bfill()用于向后填充数值,相当于fillna(method='bfill')
pandas.DataFrame.bfill官方文档
shift()用于上下/左右移动数据
pandas.DataFrame.shift官方文档
继续用刚才的例子
# 向下移动
df['C'] = df.groupby(['A'])['B'].apply(lambda x: x.shift(1))
# 向上移动
df['D'] = df.groupby(['A'])['B'].apply(lambda x: x.shift(-1))
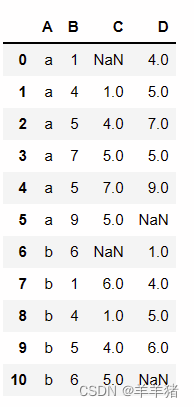
如果我们想计算不包括当前行的前面几行数据的均值,我们可以先计算当前行的下一行开始rolling()的均值,然后再往上移一行
# 先计算后面一行的rolling(3).mean()
df['C'] = df.groupby(['A'])['B'].apply(lambda x: x.rolling(3,1).mean().shift())
# 向上一行填充
df['final'] = df.groupby(['A'])['B'].apply(lambda x: x.rolling(3,1).mean().shift().bfill())
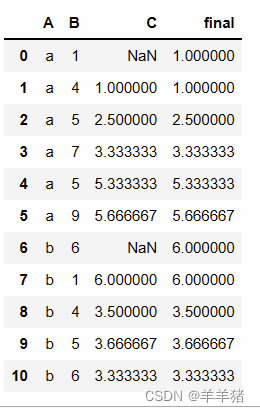
final那列就是我们计算不包括当前行的前三行的平均值
参考来源:
pandas groupby shift rank rolling 等用法详解
Pandas -计算组的滚动平均值,不包括当前行