文章目录
- 1、最短路径
- 2、单源最短路径——Dijkstra算法(正权值)
- 3、单源最短路径——BellmanFord算法
- 1、BF优化:SPFA
- 2、BF算法解决不了带负权回路的问题,实际上哪一个算法都无法求出来
- 4、多源最短路径——Floyd-Warshall算法
1、最短路径
最短路径是在有向图中,找一个顶点到另一个顶点的最短路径,也就是边的权值和最小。
2、单源最短路径——Dijkstra算法(正权值)
单源指的是只有一个起点,求到图中其它所有点的最短路径。这个算法要求边的权值为正数才行。
D算法用的是局部贪心。分为两个集合S和Q,放起点s到S中,从Q中拿出一个点q,假设从头开始遍历,找到从s到q的最小边,找到就把q从Q中删除,放到S中,然后对u的每一个相邻节点v做松弛操作:看s到v的最小权值,和s到u,u到v的权值和谁更小,哪个小就更新为s到v的最小权值。
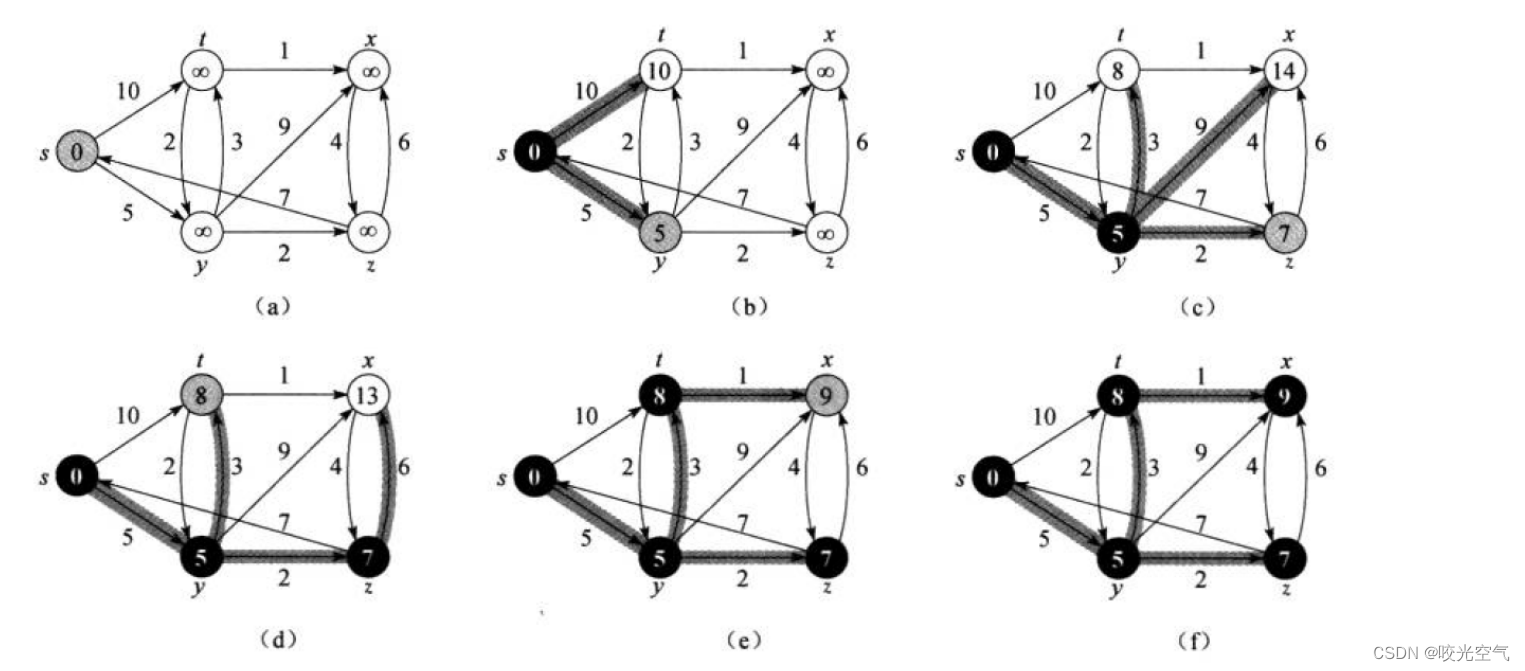
这个算法的贪心还体现在,s更新了t和y位置的值后,y的值比t小,它就选择从y继续走,更新下一个点,从y走,走到下一个点,下一点再和刚才一样的操作,更新它连接的所有顶点,再找到最小的那个走。这个最小是所有点位置的值中最小的。
对于每个位置的更新,可以想象一个数组,每个顶点对应一个下标,起点位置就是0位置处,其它位置都是无穷,第一次s更新完t和y的值后,这两点的下标位置处就填充为数字10和5,然后一步步变更所有位置的数值。
但路径的存储比较麻烦,D算法的解决办法是用一个一维数组,存储父节点,也就是路径上前一个顶点下标。最一开始,s和t,y直接相连,那么t和y位置就填上s的下标,也就是0,下一步,更新了s到x,通过y,那么x就存y的下标,一步步变更数字,最后得到的就是一整个路径。
void Dijkstra(const V& src, vector<W>& dist, vector<int>& pPath)
{
size_t srci = GetVertexIndex(src);
size_t n = _vertexs.size();
dist.resize(n, MAX_W);
pPath.resize(n, -1);
dist[srci] = 0;
pPath[srci] = srci;
vector<bool> S(n, false);//已经确定最短路径的集合
for(size_t j = 0; j < n; ++j)
{
//选最短路径顶点且不在S,更新其它路径
int u = 0;
W min = MAX_W;
for (size_t i = 0; i < n; ++i)
{
if (S[i] == false && dist[i] < min)
{
u = i;
min = dist[i];
}
}
S[u] = true;
//松弛 srci -> u , u ->其它顶点:srci -> 其它顶点
for (size_t v = 0; v < n; ++v)
{
//已经更新过的就不用更新了。
if (S[v] == false && _matrix[u][v] != MAX_W && dist[u] + _matrix[u][v] < dist[v])
{
dist[v] = dist[u] + _matrix[u][v];
pPath[v] = u;
}
}
}
}
测试代码
void TestGraphDijkstra()
{
const char* str = "syztx";
Graph<char, int, INT_MAX, true> g(str, strlen(str));
g.AddEdge('s', 't', 10);
g.AddEdge('s', 'y', 5);
g.AddEdge('y', 't', 3);
g.AddEdge('y', 'x', 9);
g.AddEdge('y', 'z', 2);
g.AddEdge('z', 's', 7);
g.AddEdge('z', 'x', 6);
g.AddEdge('t', 'y', 2);
g.AddEdge('t', 'x', 1);
g.AddEdge('x', 'z', 4);
vector<int> dist;
vector<int> parentPath;
g.Dijkstra('s', dist, parentPath);
}
打印函数。我们需要像并查集那样一点点往上寻找节点,这里找到后把它存入一个数组中,然后逆序整个数组,就是路径了
void PrintShortPath(const V& src, const vector<W>& dist, const vector<int>& pPath)
{
size_t srci = GetVertexIndex(src);
size_t n = _vertexs.size();
for (size_t i = 0; i < n; ++i)
{
if (i != srci)
{
//找出i顶点的路径
vector<int> path;
size_t parent = i;
while (parent != srci)
{
path.push_back(parent);
parent = pPath[parent];//变成当前节点的父节点
}
path.push_back(srci);
reverse(path.begin(), path.end());
for (auto e : path)
{
cout << _vertexs[e] << " -> ";
}
cout << "权值和: " << dist[i] << endl;
}
}
}
//测试代码最后加上这行
g.PrintShortPath('s', dist, parentPath);
3、单源最短路径——BellmanFord算法
这个算法其实是一个暴力更新算法。效率比D算法低,但是可以求负权值,而D只能求正权值的图。BF算法的时间复杂度是n * 边数,如果是稠密图,BF算法时间消耗不小。
先初始化
void BellmanFord(const V& src, vector<W>& dist, vector<int>& pPath)
{
//初始化
size_t srci = GetVertexIndex(src);
size_t n = _vertexs.size();
dist.resize(N, MAX_W);
parentPath.resize(N, -1);
dist[srci] = W();//缺省值
假设起点s和其它点集合V,要么是直接相连,要么是多条边连接。BF注重的是终止边,比如s - i - j,s和j之间也有直接相连,找到s到i的最短边,i到j的最短边,然后相加和s - j直接相连的边比较,谁更小谁就是s到j的最短路径。
bool BellmanFord(const V& src, vector<W>& dist, vector<int>& pPath)
{
//初始化
size_t srci = GetVertexIndex(src);
size_t n = _vertexs.size();
dist.resize(n, MAX_W);
pPath.resize(n, -1);
dist[srci] = W();//缺省值
//i -> j
cout << "更新边: " << endl;
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
//srci -> i + i -> j < src -> j
if (_matrix[i][j] != MAX_W && dist[i] + _matrix[i][j] < dist[j])
{
cout << _vertexs[i] << " -> " << _vertexs[j] << ":" << _matrix[i][j] << endl;
dist[j] = dist[i] + _matrix[i][j];
pPath[j] = i;
}
}
}
cout << " " << endl;
return true;//下面会写明这个true的意义
}
测试代码
void TestGraphBellmanFord()
{
const char* str = "syztx";
Graph<char, int, INT_MAX, true> g(str, strlen(str));
g.AddEdge('s', 't', 6);
g.AddEdge('s', 'y', 7);
g.AddEdge('y', 'z', 9);
g.AddEdge('y', 'x', -3);
g.AddEdge('z', 's', 2);
g.AddEdge('z', 'x', 7);
g.AddEdge('t', 'x', 5);
g.AddEdge('t', 'y', 8);
g.AddEdge('t', 'z', -4);
g.AddEdge('x', 't', -2);
vector<int> dist;
vector<int> parentPath;
if (g.BellmanFord('s', dist, parentPath))
{
g.PrintShortPath('s', dist, parentPath);
}
else
{
cout << "存在负权回路" << endl;
}
}

我们看一下结果。最一开始dist里都是无穷大,除了起点位置,第一次更新的是s到y,代码中也就是dist[y] = dist[s] + _matrix[s][y],s就是0位置处,这里相当于s到y更新为s到s + s到y,然后pPath数组中y位置就填0,也就是s点所在的位置,dist[y]就是7,接下来更新s到t,也是一样,pPath中t位置处填0,dist[t] = 6。更新y到z,那么pPath里z位置就填y的下标,dist[z] = 7 + 9。更新y到x,dist[x] = 7 - 3,更新t到z,此时z就填的不是y的下标,而是t的下标了,dist[z] = 6 - 4。
到了x->t,从s到t的路径就是s x t,前面s到x的路径已经更新了值,那么dist[t] = 7 - 3 - 2 = 2,此前是6,但是这个点更新就错误了,因为之前用t更新了z,s t z,dist[z] = 2,然后下一步更新x到t,dist[t]更新成了2,那么t再到z,应当是2 - 4 = -2。这个问题就是负权回路问题。
负权回路可以有个很暴力的解决方案,既然一次更新会出这样的问题,那就更新n次,因为可能再次更新还会有别的路径受影响,而更新n次就没有问题,在外面再嵌套一个循环。不过不是每次都会更新,得控制一下如果没有更新的了就结束。
bool BellmanFord(const V& src, vector<W>& dist, vector<int>& pPath)
{
//初始化
size_t srci = GetVertexIndex(src);
size_t n = _vertexs.size();
dist.resize(n, MAX_W);
pPath.resize(n, -1);
dist[srci] = W();//缺省值
//i -> j
for (size_t k = 1; k <= n; ++k)
{
bool update = false;
cout << "更新第" << k << "轮" << endl;
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
//srci -> i + i -> j < src -> j
if (_matrix[i][j] != MAX_W && dist[i] + _matrix[i][j] < dist[j])
{
update = true;
cout << _vertexs[i] << " -> " << _vertexs[j] << ":" << _matrix[i][j] << endl;
dist[j] = dist[i] + _matrix[i][j];
pPath[j] = i;
}
}
}
if (!update)//如果这一轮没有更新,就不需要继续了
{
cout << "没有更新,程序结束" << endl;
cout << " " << endl;
break;
}
cout << " " << endl;
}
return true;
}
但是这样每次的更新所有边都参与,都需要去判断,应当改善为只更新需要更新的。
1、BF优化:SPFA
这个优化叫SPFA函数,用队列去优化。除了第一轮所有的边都入队列外,后面的轮次都只更新更短路径的边,让出现更短路径的边入队列。最好的情况是O(N ^ 2),最坏的情况是O(n ^ 3)。
2、BF算法解决不了带负权回路的问题,实际上哪一个算法都无法求出来
看下面的带负权回路的测试代码
const char* str = "syztx";
Graph<char, int, INT_MAX, true> g(str, strlen(str));
g.AddEdge('s', 't', 6);
g.AddEdge('s', 'y', 7);
g.AddEdge('y', 'x', -3);
g.AddEdge('y', 'z', 9);
g.AddEdge('y', 'x', -3);
g.AddEdge('y', 's', 1); // 新增
g.AddEdge('z', 's', 2);
g.AddEdge('z', 'x', 7);
g.AddEdge('t', 'x', 5);
g.AddEdge('t', 'y', -8); // 更改
g.AddEdge('t', 'z', -4);
g.AddEdge('x', 't', -2);
vector<int> dist;
vector<int> parentPath;
if (g.BellmanFord('s', dist, parentPath))
{
g.PrintShortPath('s', dist, parentPath);
}
else
{
cout << "存在负权回路" << endl;
}
这样就会导致不断地更新,每次更新都需要更新所有边,无法确定最终答案。可以在原代码上加个判断,如果更新n次后,还可以更新,那就是负权回路。
bool BellmanFord(const V& src, vector<W>& dist, vector<int>& pPath)
{
//初始化
size_t srci = GetVertexIndex(src);
size_t n = _vertexs.size();
dist.resize(n, MAX_W);
pPath.resize(n, -1);
dist[srci] = W();//缺省值
//i -> j
for (size_t k = 1; k <= n; ++k)
{
bool update = false;
cout << "更新第" << k << "轮" << endl;
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
//srci -> i + i -> j < src -> j
if (_matrix[i][j] != MAX_W && dist[i] + _matrix[i][j] < dist[j])
{
update = true;
cout << _vertexs[i] << " -> " << _vertexs[j] << ":" << _matrix[i][j] << endl;
dist[j] = dist[i] + _matrix[i][j];
pPath[j] = i;
}
}
}
if (!update)//如果这一轮没有更新,就不需要继续了
{
cout << "没有更新,程序结束" << endl;
cout << " " << endl;
break;
}
cout << " " << endl;
}
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
if (_matrix[i][j] != MAX_W && dist[i] + _matrix[i][j] < dist[j])
{
return false;
}
}
}
return true;//返回真就说明不是负权回路
}
4、多源最短路径——Floyd-Warshall算法
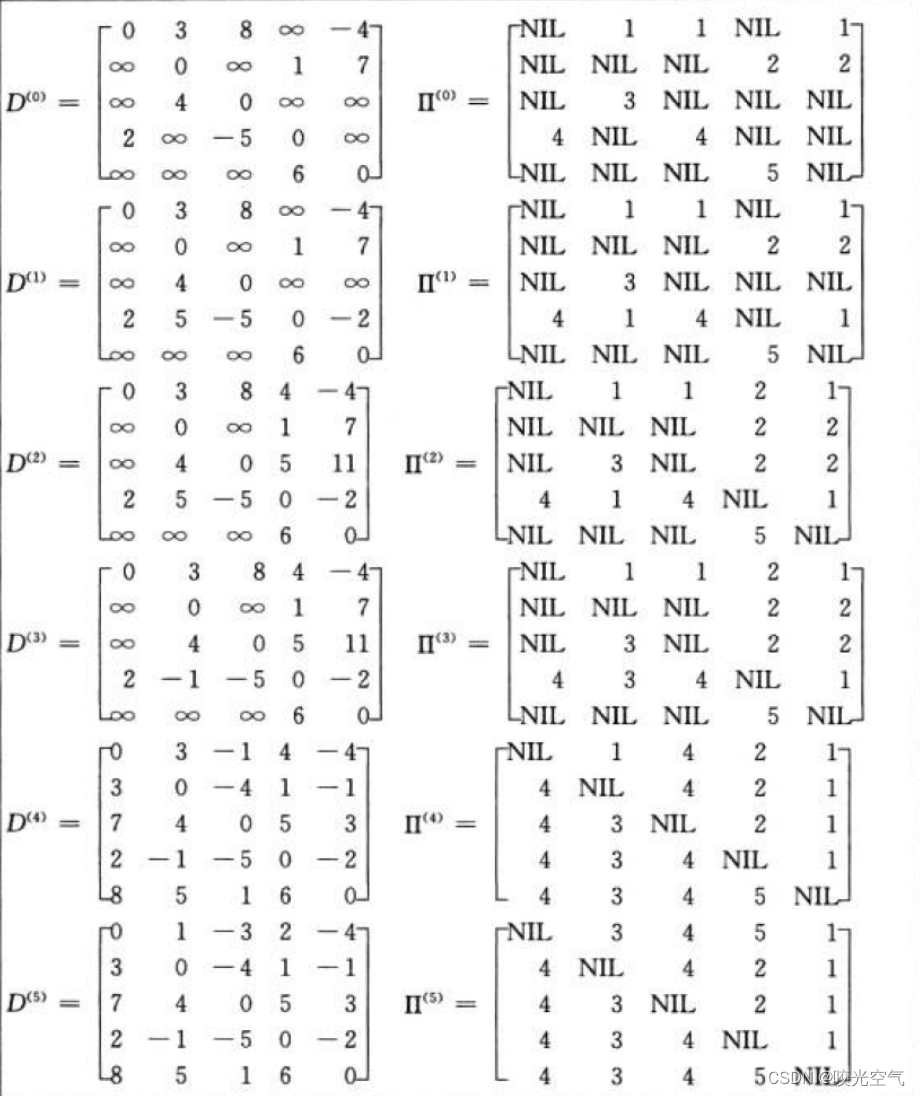
F算法可以解决负权值问题,用来求任意两点之间的最短路径问题,用动态规划。它以所有点为源点,也可以求出任意两点之间的最短路径。
既然是多源,那么一维数组就不行了,dist和pPath都得是二维数组。之前的算法中,到i位置的最短路径存在dist[i]中,有可能不是直接相连的,而是间接。在二维数组中,两个位置下标就直接表示了两点之间最短路径。假设有n个顶点,i到j的最短路径中,最多经过n - 2个点。
假设i到j之间有1这个点,2这个点,…,k这个点,用三维数组来想象

经过点k了,那么这个有k个点的集合就变成k - 1个,i到j被分为i到k和k到j,i到k就有k - 1个点,k到j也同样有k - 1个点,但这k - 1个点不一样,这里就想象为i到k有k个点,去掉k,就是k - 1;k到j有k个点,去掉k,就是k - 1,所以这就是为什么叫集合。这里分出来的两部分其实和i到j的分析一样,只是点不同了,经过的点也不同了,i到k之间有k - 1个点,i到k的最短路径经过k - 1这个点,k到j有k - 1个点,k到j的最短路径有k - 1这个点。
如果不经过k点,那也去掉,这时候i到j就有k - 1个点,那么此时结果就取决于是否经过k - 1这个点。
上图可以发现,这个算法用到了动规,我们可以把三维压缩为二维数组来实现。
bool Floyd_Warshall(vector<vector<W>>& vvDist, vector<vector<int>>& vvpPath)
{
size_t n = _vertexs.size();
vvDist.resize(n);
vvpPath.resize(n);
//初始化权值和父路径矩阵
for (size_t i = 0; i < n; ++i)
{
vvDist[i].resize(n, MAX_W);
vvpPath[i].resize(n, -1);
}
//直接相连的边更新
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
if (_matrix[i][j] != MAX_W)
{
vvDist[i][j] = _matrix[i][j];
vvpPath[i][j] = i;//因为直接相连,所以j的父节点是i
}
if (i == j) vvDist[i][j] = 0;//只是自己规定的,也可以不加这个,这样对角线位置就是_matrix[i][j]的值
}
}
//更新最短路径
//i -> {其它顶点} -> j,k作为ij的中间点,可能是ij之间任意一个点
size_t k;
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
//按照公式更新
if (vvDist[i][k] != MAX_W && vvDist[k][j] != MAX_W
&& vvDist[i][k] + vvDist[k][j] < vvDist[i][j])//首先得是i到k,k到j之间有路径
{
vvDist[i][j] = vvDist[i][k] + vvDist[k][j];
//ij之间经过k,要更新j的上一个邻接顶点,也就是上一个顶点
//如果kj直接相连,那j上一个点就是k,vvpPath[k][j]存的就是k
//如果kj没有直接相连,kj之间还有点,vvpPath[k][j]存的就是这个点
vvpPath[i][j] = vvpPath[k][j];
}
}
}
}
仔细理解上面代码后,上面的k是我们自己选的k,但实际上有很多个顶点都需要去判断,所以k也得循环取一遍。
//更新最短路径
//i -> {其它顶点} -> j,k作为ij的中间点,可能是ij之间任意一个点
for (size_t k = 0; k < n; ++k)
{
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
//按照公式更新
if (vvDist[i][k] != MAX_W && vvDist[k][j] != MAX_W
&& vvDist[i][k] + vvDist[k][j] < vvDist[i][j])//首先得是i到k,k到j之间有路径
{
vvDist[i][j] = vvDist[i][k] + vvDist[k][j];
//ij之间经过k,要更新j的上一个邻接顶点,也就是上一个顶点
//如果kj直接相连,那j上一个点就是k,vvpPath[k][j]存的就是k
//如果kj没有直接相连,kj之间还有点,vvpPath[k][j]存的就是这个点
vvpPath[i][j] = vvpPath[k][j];
}
}
}
}
测试代码
void TestFloydWarshall()
{
const char* str = "12345";
Graph<char, int, INT_MAX, true> g(str, strlen(str));
g.AddEdge('1', '2', 3);
g.AddEdge('1', '3', 8);
g.AddEdge('1', '5', -4);
g.AddEdge('2', '4', 1);
g.AddEdge('2', '5', 7);
g.AddEdge('3', '2', 4);
g.AddEdge('4', '1', 2);
g.AddEdge('4', '3', -5);
g.AddEdge('5', '4', 6);
vector<vector<int>> vvDist;
vector<vector<int>> vvParentPath;
g.Floyd_Warshall(vvDist, vvParentPath);
// 打印任意两点之间的最短路径
/*for (size_t i = 0; i < strlen(str); ++i)
{
g.PrintShortPath(str[i], vvDist[i], vvParentPath[i]);
cout << endl;
}*/
}
这里的打印函数这样实现
//打印权值和路径矩阵观察数据
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
if (vvDist[i][j] == MAX_W)
{
printf("%3c", '*');
}
else
{
printf("%3d", vvDist[i][j]);
}
}
printf("\n");
}
printf("\n");
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
printf("%3d", vvpPath[i][j]);
}
printf("\n");
}
printf("=================================\n");
并且要放到k循环中
void Floyd_Warshall(vector<vector<W>>& vvDist, vector<vector<int>>& vvpPath)
{
size_t n = _vertexs.size();
vvDist.resize(n);
vvpPath.resize(n);
//初始化权值和父路径矩阵
for (size_t i = 0; i < n; ++i)
{
vvDist[i].resize(n, MAX_W);
vvpPath[i].resize(n, -1);
}
//直接相连的边更新
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
if (_matrix[i][j] != MAX_W)
{
vvDist[i][j] = _matrix[i][j];
vvpPath[i][j] = i;//因为直接相连,所以j的父节点是i
}
if (i == j) vvDist[i][j] = 0;//只是自己规定的,也可以不加这个,这样对角线位置就是_matrix[i][j]的值
}
}
//更新最短路径
//i -> {其它顶点} -> j,k作为ij的中间点,可能是ij之间任意一个点
for (size_t k = 0; k < n; ++k)
{
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
//按照公式更新
if (vvDist[i][k] != MAX_W && vvDist[k][j] != MAX_W
&& vvDist[i][k] + vvDist[k][j] < vvDist[i][j])//首先得是i到k,k到j之间有路径
{
vvDist[i][j] = vvDist[i][k] + vvDist[k][j];
//ij之间经过k,要更新j的上一个邻接顶点,也就是上一个顶点
//如果kj直接相连,那j上一个点就是k,vvpPath[k][j]存的就是k
//如果kj没有直接相连,kj之间还有点,vvpPath[k][j]存的就是这个点
vvpPath[i][j] = vvpPath[k][j];
}
}
}
//打印权值和路径矩阵观察数据
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
if (vvDist[i][j] == MAX_W)
{
printf("%3c", '*');
}
else
{
printf("%3d", vvDist[i][j]);
}
}
printf("\n");
}
printf("\n");
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
printf("%3d", vvpPath[i][j]);
}
printf("\n");
}
printf("=================================\n");
}
}
打印是从第一次更新后开始打印的,和上面的图对照起来要从第二行开始。不过图中显示的是整数,我们打印的下标。整体的实现方法是没有问题的。最后打印出来的两个表就是dist和pPath表,看最后的就能知道每两个点之间最短路径通过哪个点。
也可以加上最短路径的打印函数
//......
g.Floyd_Warshall(vvDist, vvParentPath);
// 打印任意两点之间的最短路径
for (size_t i = 0; i < strlen(str); ++i)
{
g.PrintShortPath(str[i], vvDist[i], vvParentPath[i]);
cout << endl;
}
void PrintShortPath(const V& src, const vector<W>& dist, const vector<int>& pPath)
{
size_t srci = GetVertexIndex(src);
size_t n = _vertexs.size();
for (size_t i = 0; i < n; ++i)
{
if (i != srci)
{
//找出i顶点的路径
vector<int> path;
size_t parent = i;
while (parent != srci)
{
path.push_back(parent);
parent = pPath[parent];//变成当前节点的父节点
}
path.push_back(srci);
reverse(path.begin(), path.end());
for (auto e : path)
{
cout << _vertexs[e] << " -> ";
}
cout << "权值和: " << dist[i] << endl;
}
}
}
最后的代码里改了些printf和cout的打印,主要集中在Print函数。
本篇gitee
结束。