嗨喽,大家好呀~这里是爱看美女的茜茜呐

环境使用:
首先我们先来安装一下写代码的软件(对没安装的小白说)
-
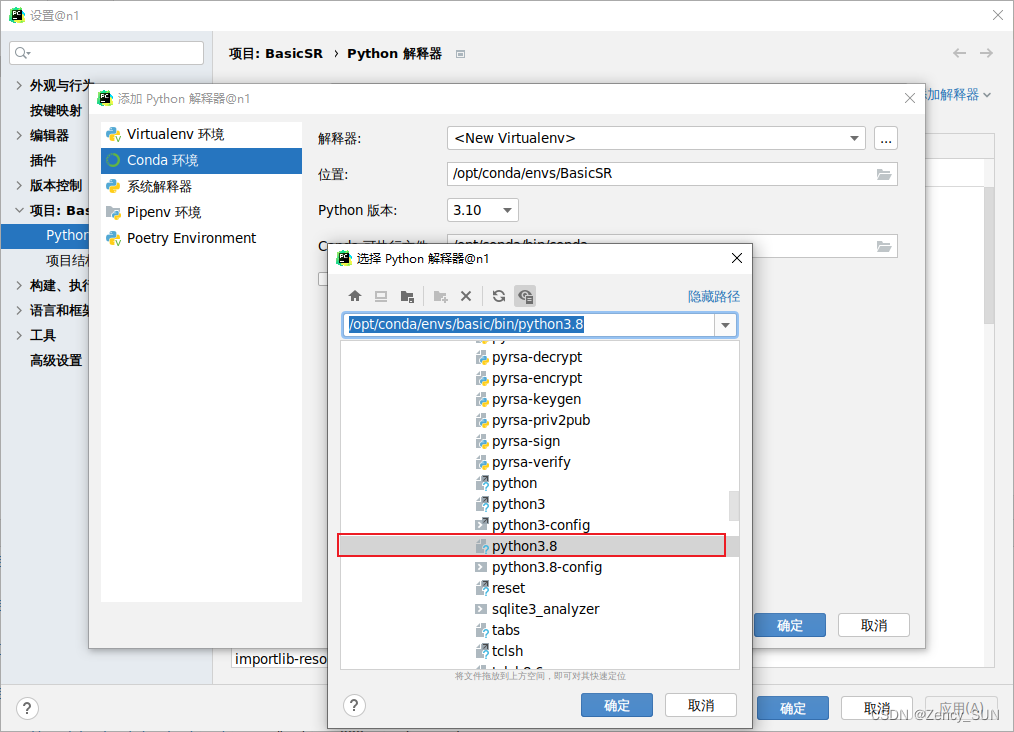
Python 3.8 / 编译器
-
Pycharm 2021.2版本 / 编辑器
-
专业版是付费的 <文章下方名片可获取魔法永久用~>
-
社区版是免费的
-
模块使用:
-
json (内置模块,直接导入,无需安装)
-
requests --> pip install requests
-
execjs --> pip install PyExecJS
python第三方模块安装:
-
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
-
在pycharm中点击Terminal(终端) 输入安装命令
(如果你觉得安装速度比较慢, 你可以切换国内镜像源)
👇 👇 👇 更多精彩机密、教程,尽在下方,赶紧点击了解吧~
python源码、视频教程、插件安装教程、资料我都准备好了,直接在文末名片自取就可
基本流程思路: <适用于任何网站数据采集>
一. 数据来源分析
-
明确需求: 明确采集的网站以及数据内容
-
网址: https://jzsc.mohurd.gov.cn/data/company
-
数据: 企业信息
-
-
抓包分析: 通过浏览器去分析, 我们需要数据具体在那个链接中
- 静态网页: 刷新网页查看数据包内
-
动态网页: 点击到下一页数据内容 / 下滑到下一页的数据内容
-
打开开发者工具: F12
-
点击第二页数据内容
加密数据: https://jzsc.mohurd.gov.cn/APi/webApi/dataservice/query/comp/list?pg=1&pgsz=15&total=450
-
二. 代码实现步骤:
-
发送请求 -> 模拟浏览器对于url地址发送请求
url地址: 通过抓包分析找到链接地址
-
获取数据 -> 获取服务器返回响应数据
开发者工具: response 响应
-
解析数据 -> 获取加密数据内容
-
保存数据 -> 通过解密, 还原明文数据 保存表格文件中
-
发送请求 -> 模拟浏览器对于url地址发送请求
代码展示
数据采集保存
导入模块
'''
python资料获取看这里噢!! 小编 V:Pytho8987(记得好友验证备注:6 否则可能不通过)
即可获取:文章源码/教程/资料/解答等福利,还有不错的视频学习教程和PDF电子书!
'''
# 导入数据请求模块 -> 第三方模块, 是需要安装的
import requests
# 导入模块
import execjs
# 导入json模块
import json
# 导入csv模块
import csv
创建文件对象
csv_file = open('data.csv', mode='w', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(csv_file, fieldnames=[
'企业名称',
'统一社会信用代码',
'法人',
'注册属地省份',
'注册属地城市',
])
csv_writer.writeheader()
模拟浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'
}
多页数码
for page in range(30):
请求链接
url = f'https://jzsc.mohurd.gov.cn/APi/webApi/dataservice/query/comp/list?pg={page}&pgsz=15&total=450'
发送请求 关键字传参, 指定参数传入到那个位置
response = requests.get(url=url, headers=headers)
2. 获取响应数据 --> 加密数据
data = response.text
3. 解密数据 -> 把密文转成明文 通过python代码调用JS代码
f = open('建筑平台.js', mode='r', encoding='utf-8').read()
编译js文件
js_code = execjs.compile(f)
调用js代码的函数 data->密文数据
result = js_code.call('m', data)
把json字符串数据, 转成json字典数据
json_data = json.loads(result)
for 循环遍历
'''
python资料获取看这里噢!! 小编 V:Pytho8987(记得好友验证备注:6 否则可能不通过)
即可获取:文章源码/教程/资料/解答等福利,还有不错的视频学习教程和PDF电子书!
'''
for index in json_data['data']['list']:
try:
info = index['QY_REGION_NAME'].split('-')
if len(info) == 2:
area_1 = info[0] # 省份
area_2 = info[1] # 城市
else:
area_1 = info[0] # 省份
area_2 = '未知'
dit = {
'企业名称': index['QY_NAME'],
'统一社会信用代码': index['QY_ORG_CODE'],
'法人': index['QY_FR_NAME'],
'注册属地省份': area_1,
'注册属地城市': area_2,
}
csv_writer.writerow(dit)
print(dit)
except:
pass
一个小小的数据可视化
'''
python资料获取看这里噢!! 小编 V:Pytho8987(记得好友验证备注:6 否则可能不通过)
即可获取:文章源码/教程/资料/解答等福利,还有不错的视频学习教程和PDF电子书!
'''
import pandas as pd
from pyecharts import options as opts # 配置项
from pyecharts.charts import Pie # 导入饼图
# 读取文件
df = pd.read_csv('data.csv')
print(df.head())
info = df['注册属地省份'].value_counts().index.to_list() # 数据类目
num = df['注册属地省份'].value_counts().to_list() # 数据数量
print(info)
print(num)
c = (
Pie()
.add(
"",
[list(z) for z in zip(info,num,)],
center=["40%", "50%"],
)
.set_global_opts(
# 设置标题
title_opts=opts.TitleOpts(title="注册省份占比分布"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# 保存html文件
.render("注册省份占比分布.html")
)
一些小知识点
-
模拟浏览器: 请求头
cookie: 用户信息
host: 域名
referer: 防盗链
User-Agent: 浏览器信息
-
为什么使用requests.get():
get/post 请求方式
原因: 浏览器中显示请求方法是GET
-
获取响应数据三种情况:
response.text 获取响应文本数据
response.json() 获取响应json数据 <必须是完整的json数据格式>
response.content 获取响应二进制数据 音频 视频 图片 特定格式文件…
常用于保存数据 -
响应数据加密/请求参数加密/请求头参数加密
通过找加密规则 <分析加密内容是如何生成出来的>
尾语
感谢你观看我的文章呐~本次航班到这里就结束啦 🛬
希望本篇文章有对你带来帮助 🎉,有学习到一点知识~
躲起来的星星🍥也在努力发光,你也要努力加油(让我们一起努力叭)。