精华置顶
墙裂推荐!小白如何1个月系统学习CV核心知识:链接
点击@CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
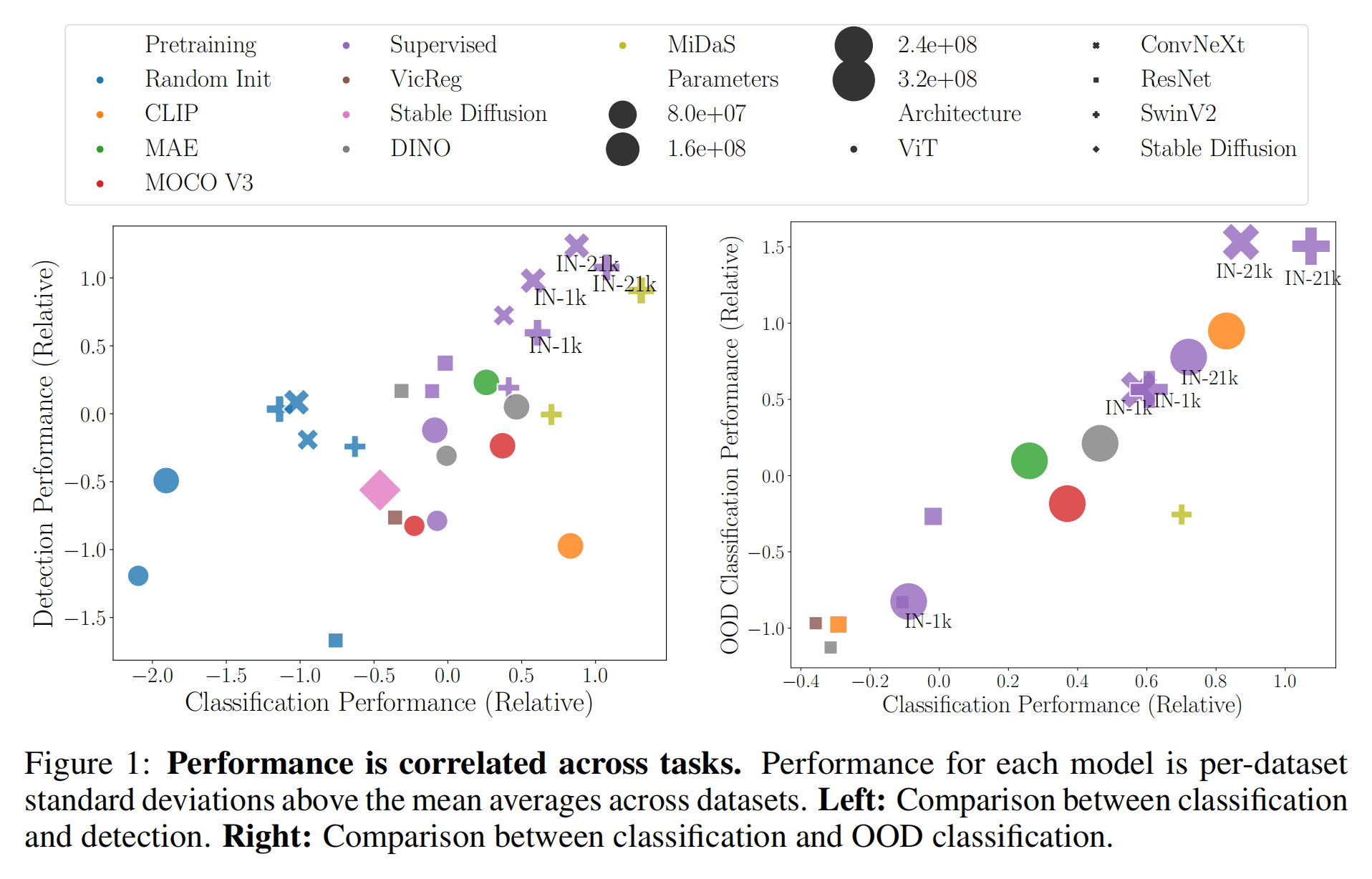
1.【基础网络架构】Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks
-
论文地址:https://arxiv.org//pdf/2310.19909
-
开源代码:GitHub - hsouri/Battle-of-the-Backbones
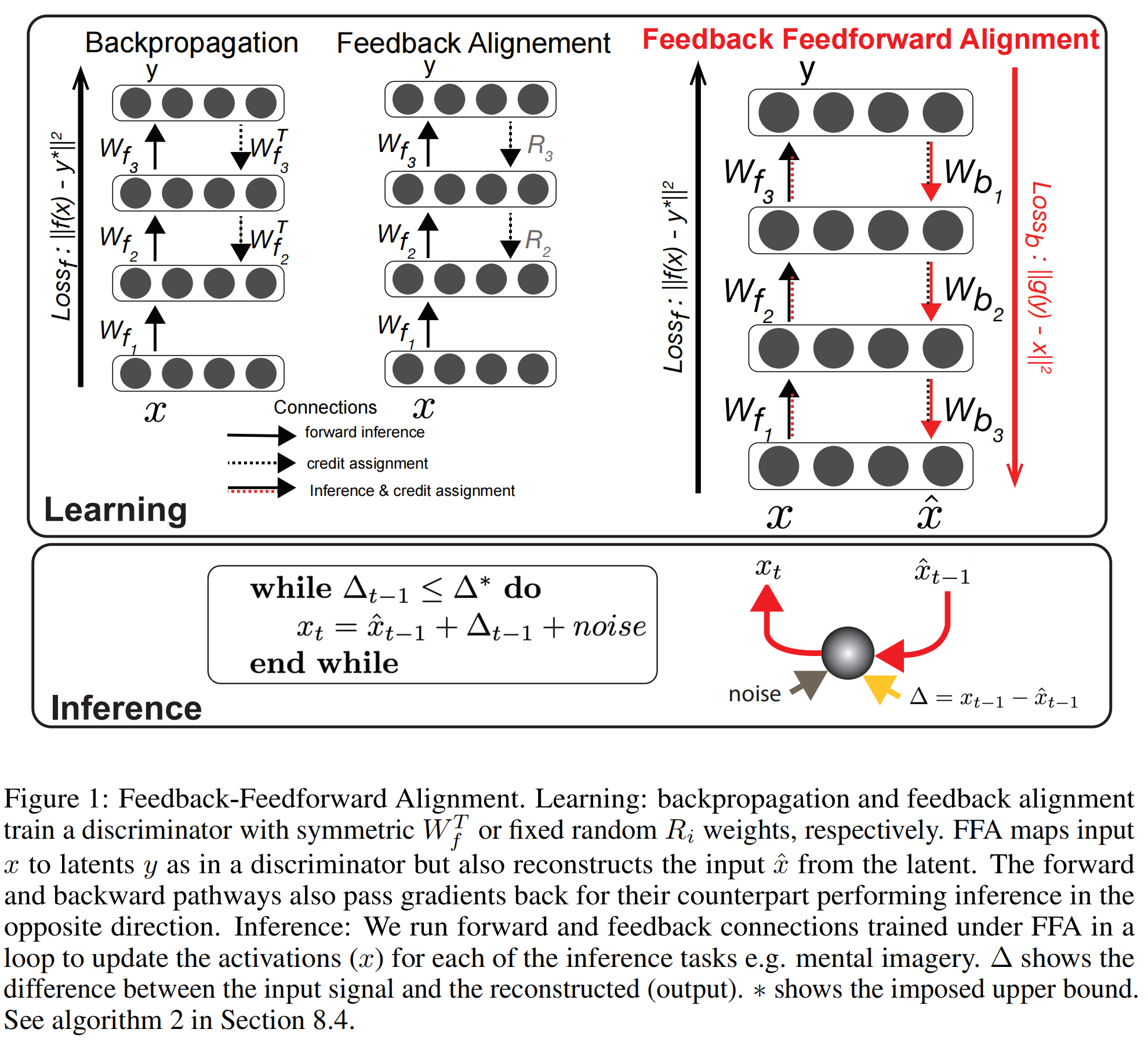
2.【基础网络架构】(NeurIPS2023)Brain-like Flexible Visual Inference by Harnessing Feedback-Feedforward Alignment
-
论文地址:https://arxiv.org//pdf/2310.20599
-
开源代码:https://github.com/toosi/Feedback_Feedforward_Alignment
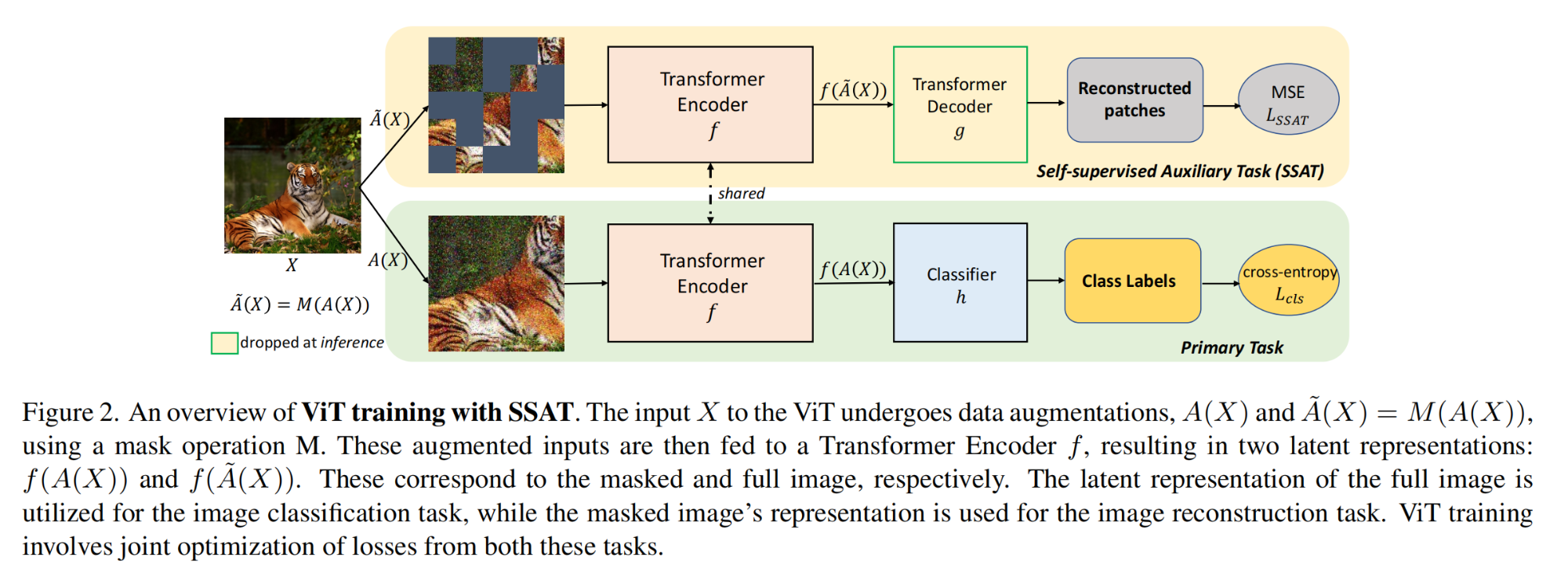
3.【基础网络架构:Transformer】(WACV2024)Limited Data, Unlimited Potential: A Study on ViTs Augmented by Masked Autoencoders
-
论文地址:https://arxiv.org//pdf/2310.20704
-
开源代码(即将开源):https://github.com/dominickrei/Limited-data-vits
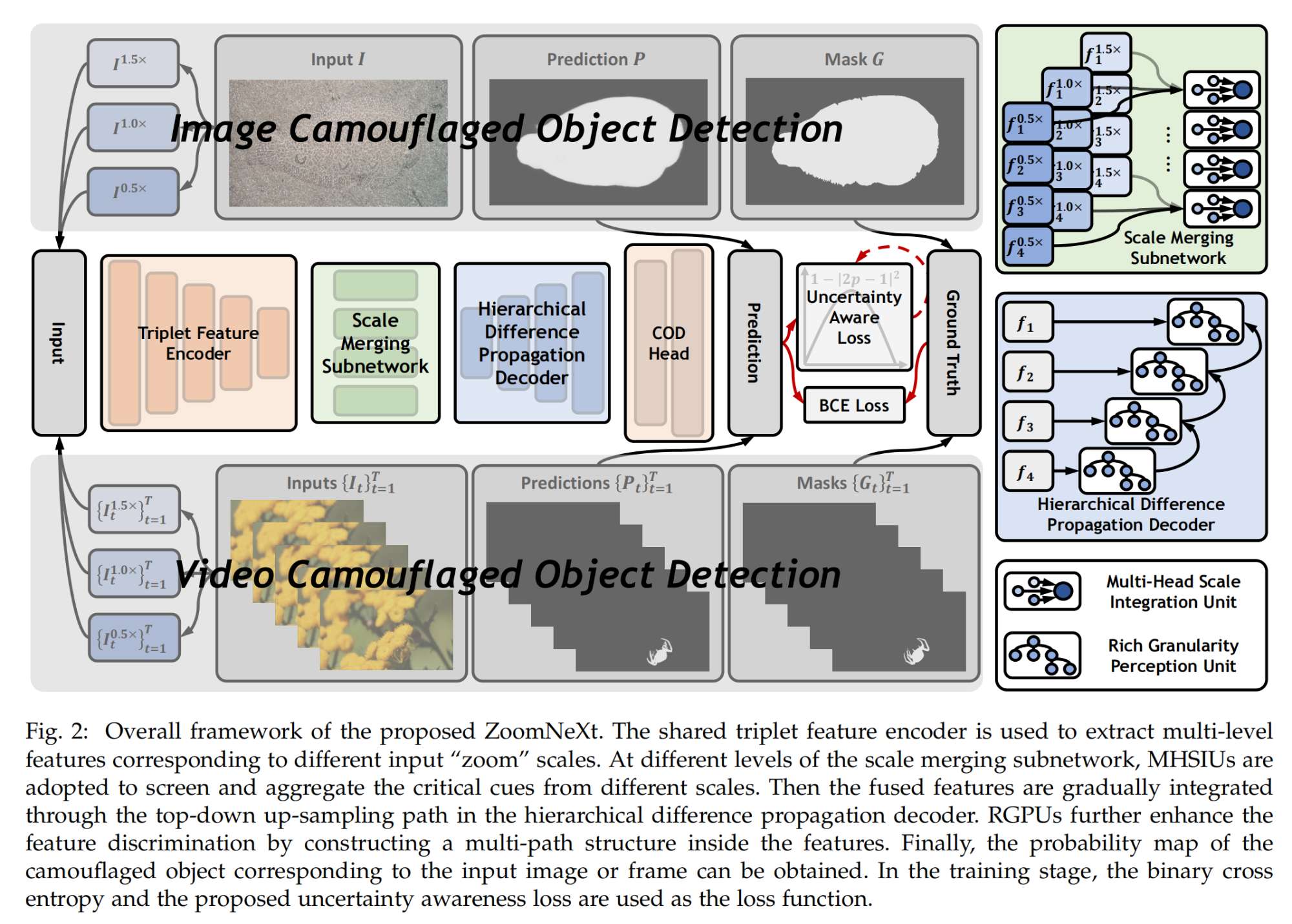
4.【目标检测:伪装目标】ZoomNeXt: A Unified Collaborative Pyramid Network for Camouflaged Object Detection
-
论文地址:https://arxiv.org//pdf/2310.20208
-
开源代码(即将开源):https://github.com/lartpang/ZoomNeXt
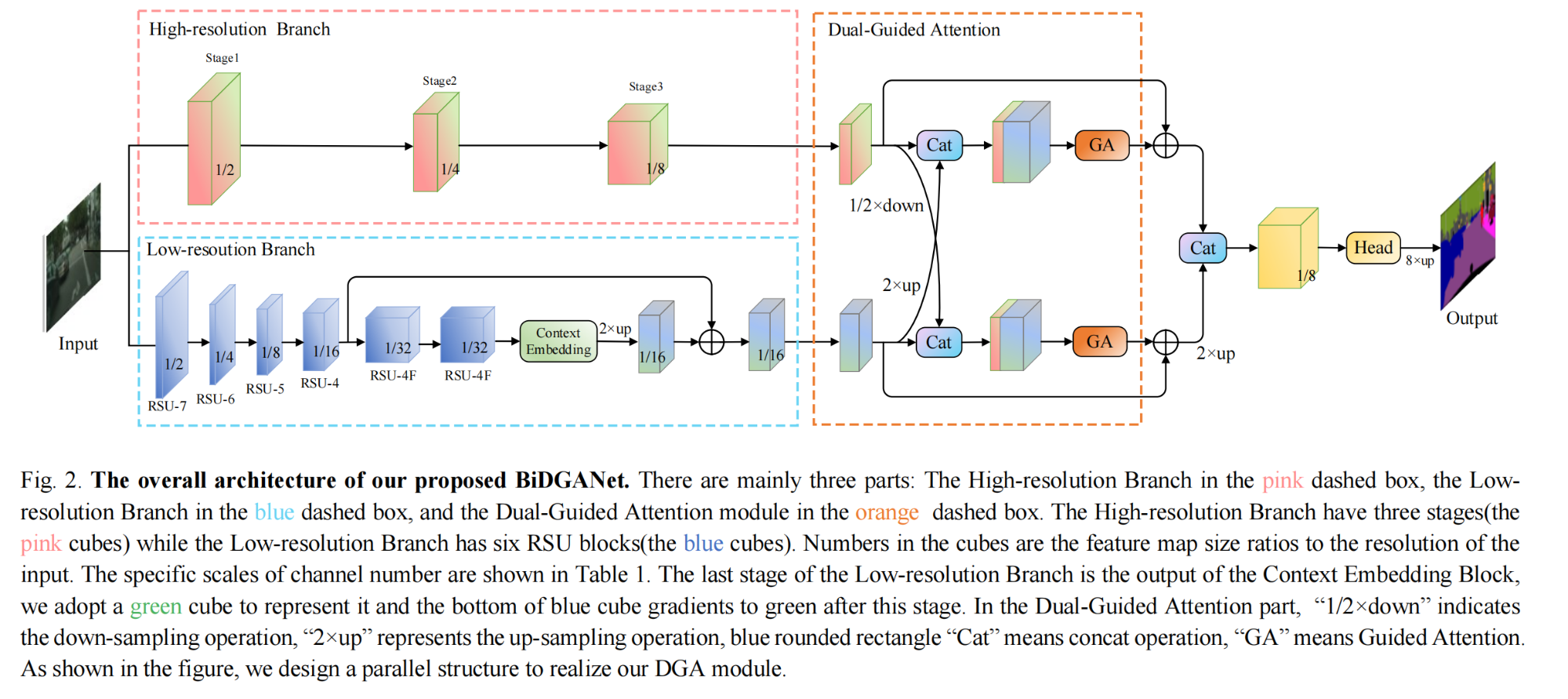
5.【语义分割】(CAC2023)Bilateral Network with Residual U-blocks and Dual-Guided Attention for Real-time Semantic Segmentation
-
论文地址:https://arxiv.org//pdf/2310.20305
-
开源代码(即将开源):GitHub - LikeLidoA/BiDGANet: [CAC2023] Bilateral Network with Residual U-blocks and Dual-Guided Attention for Real-time Semantic Segmentation
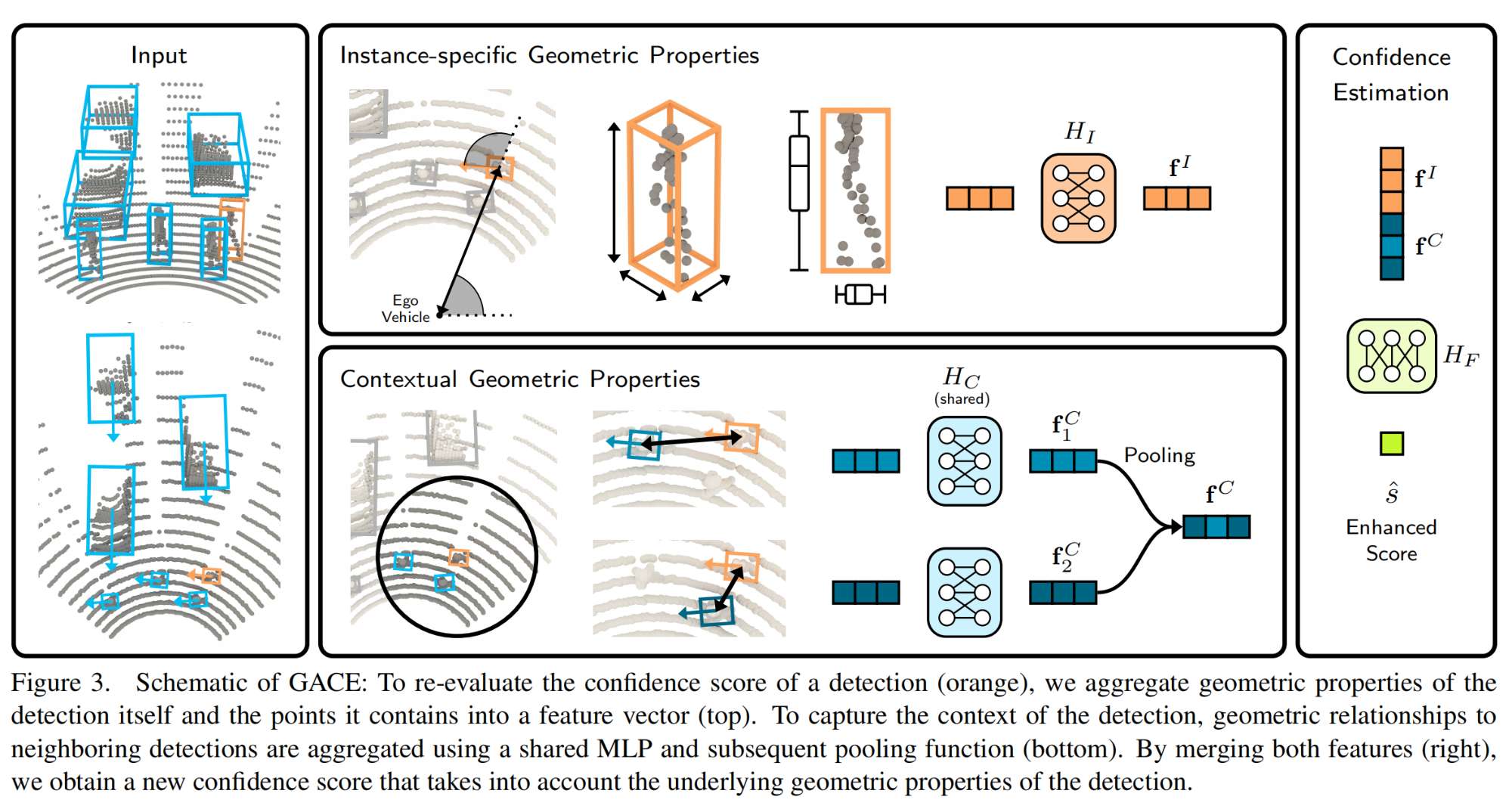
6.【点云3D目标检测】(ICCV2023)GACE: Geometry Aware Confidence Enhancement for Black-Box 3D Object Detectors on LiDAR-Data
-
论文地址:https://arxiv.org//pdf/2310.20319
-
开源代码:https://github.com/dschinagl/gace
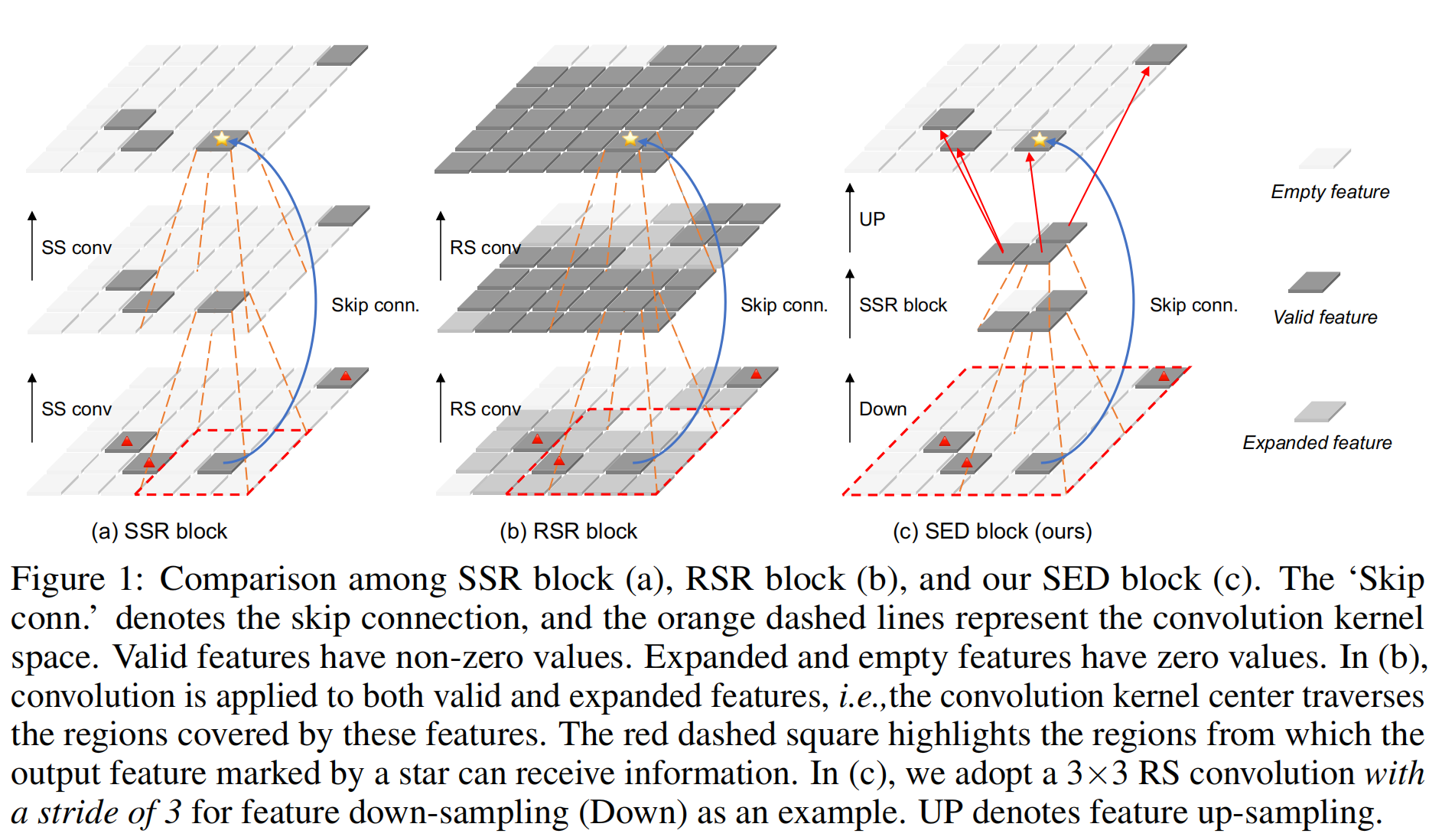
7.【点云3D目标检测】HEDNet: A Hierarchical Encoder-Decoder Network for 3D Object Detection in Point Clouds
-
论文地址:https://arxiv.org//pdf/2310.20234
-
开源代码(即将开源):https://github.com/zhanggang001/HEDNet
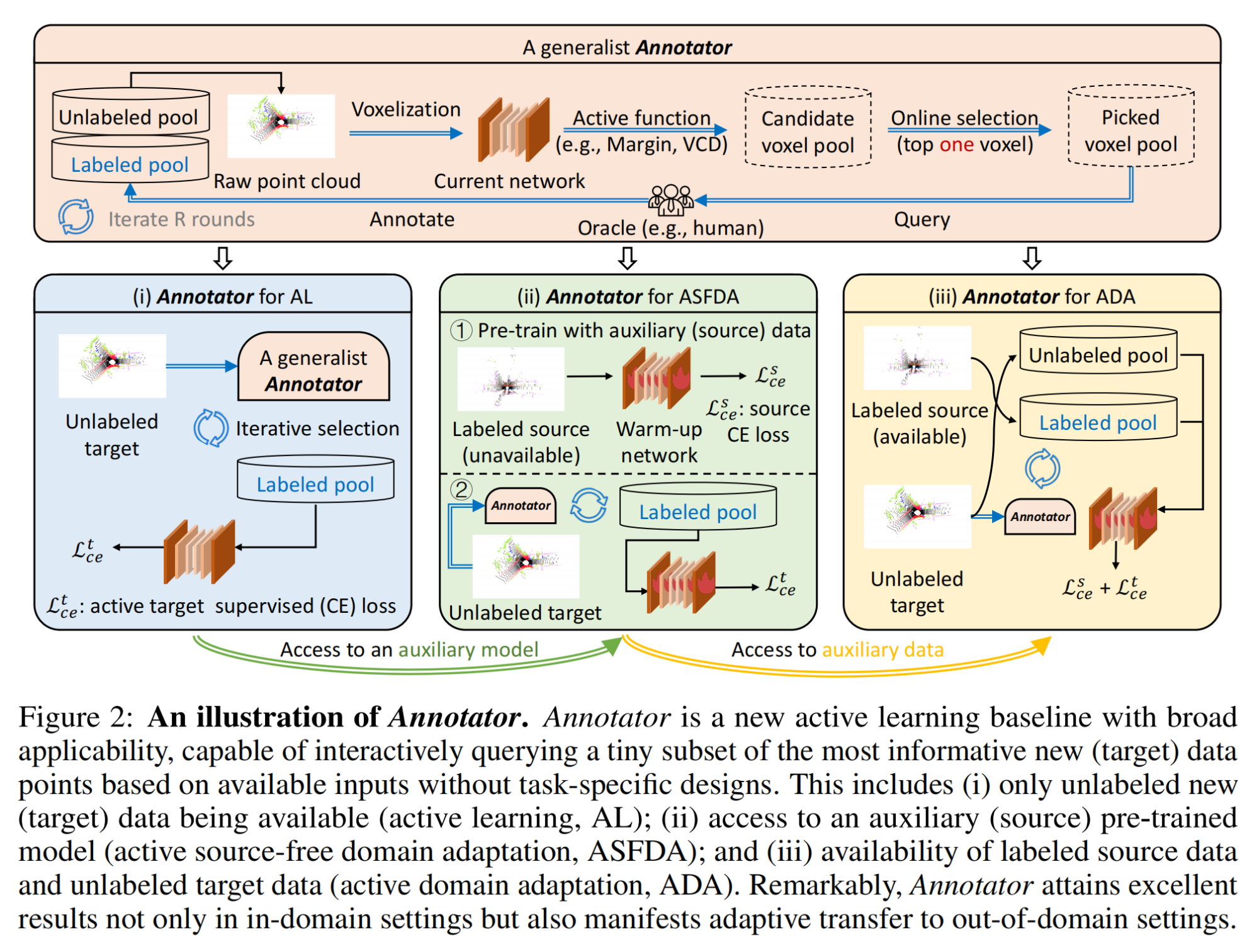
8.【点云语义分割】(NeurIPS2023)Annotator: A Generic Active Learning Baseline for LiDAR Semantic Segmentation
-
论文地址:https://arxiv.org//pdf/2310.20293
-
工程主页:Annotator: A Generic Active Learning Baseline for LiDAR Semantic Segmentation
-
开源代码(即将开源):https://github.com/BIT-DA/Annotator
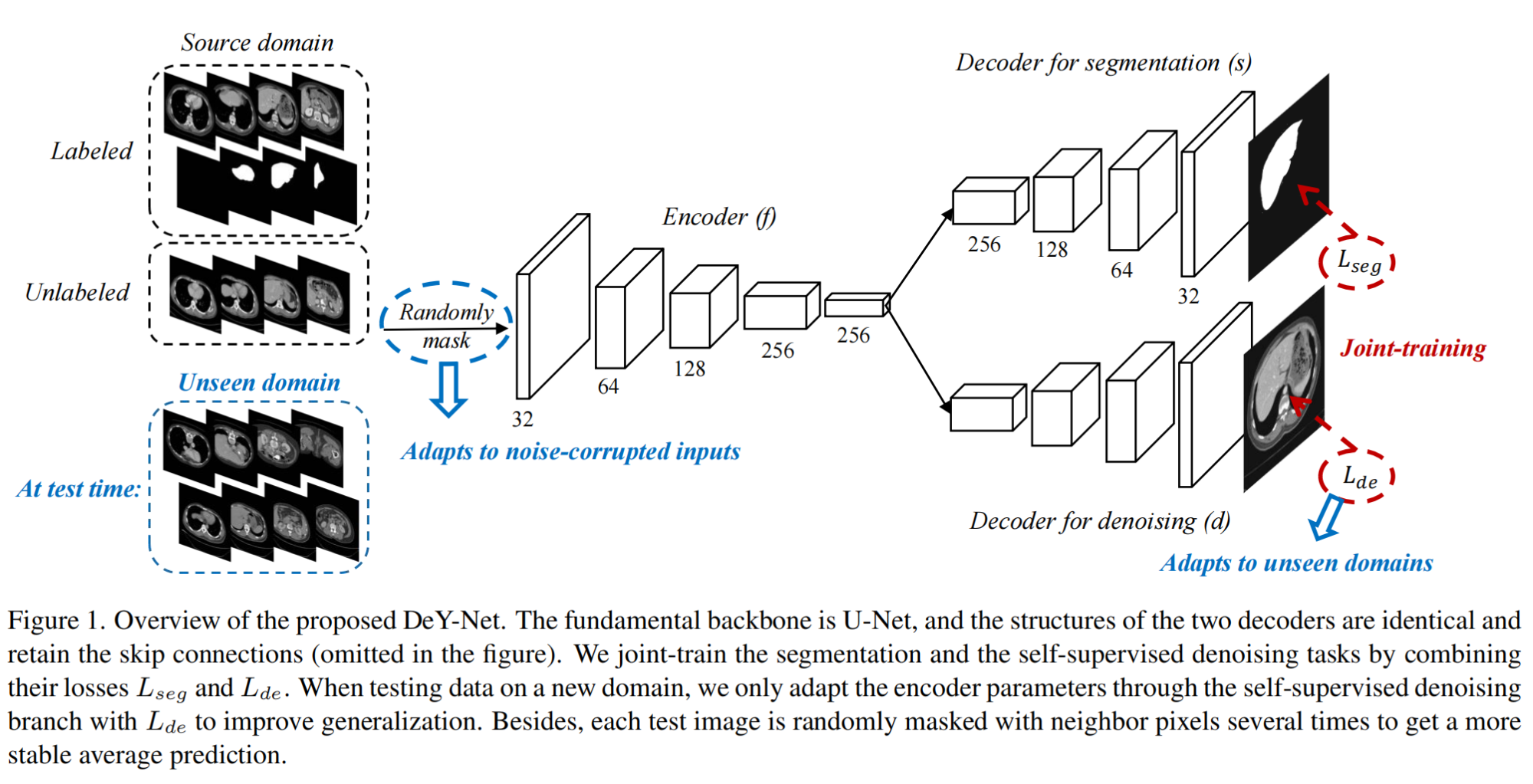
9.【医学图像分割】From Denoising Training to Test-Time Adaptation: Enhancing Domain Generalization for Medical Image Segmentation
-
论文地址:https://arxiv.org//pdf/2310.20271
-
开源代码:https://github.com/WenRuxue/DeTTA
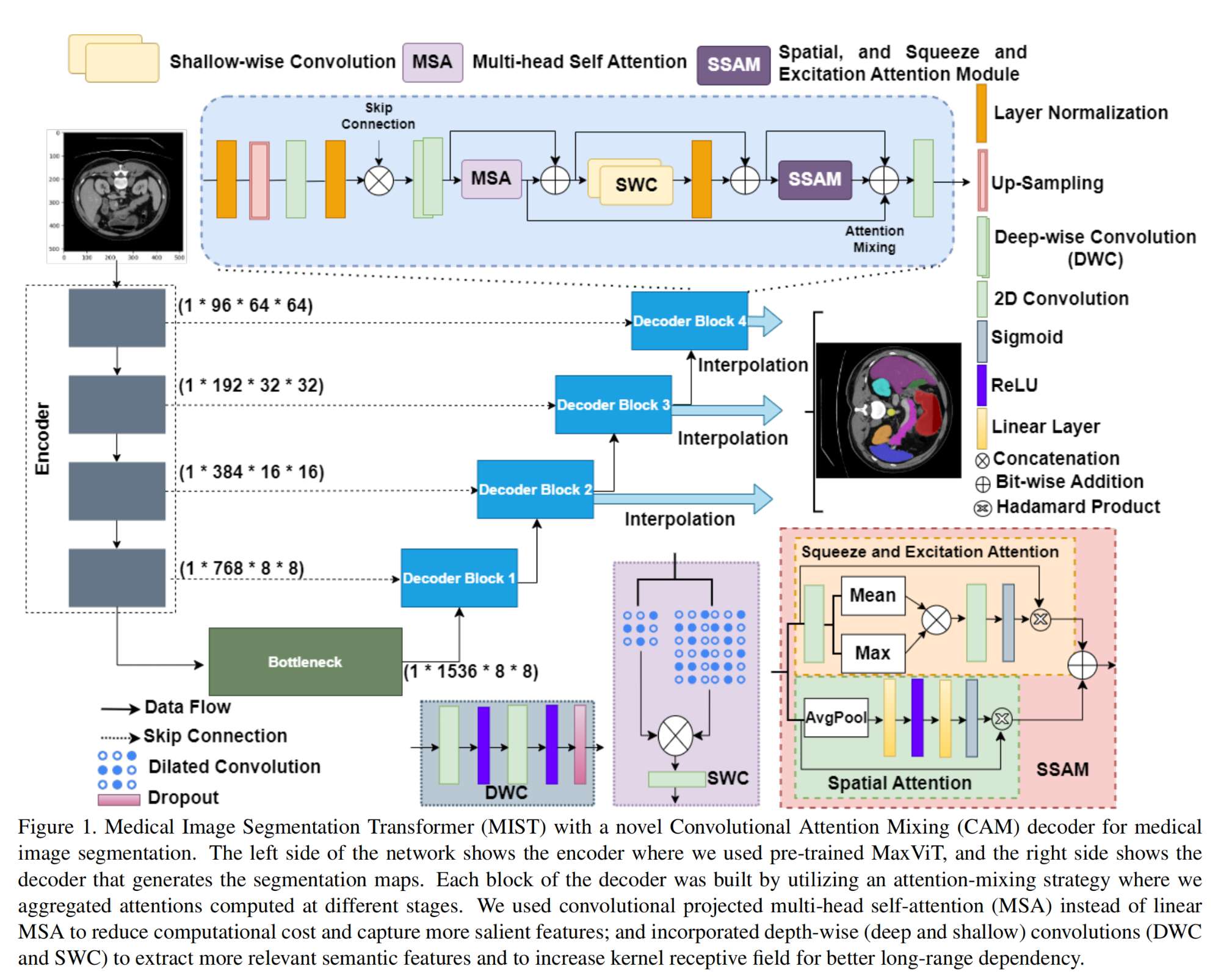
10.【医学图像分割】MIST: Medical Image Segmentation Transformer with Convolutional Attention Mixing (CAM) Decoder
-
论文地址:https://arxiv.org//pdf/2310.19898
-
开源代码(即将开源):GitHub - Rahman-Motiur/MIST: Medical Image Segmentation Transformer with Convolutional Attention Mixing (CAM) Decoder
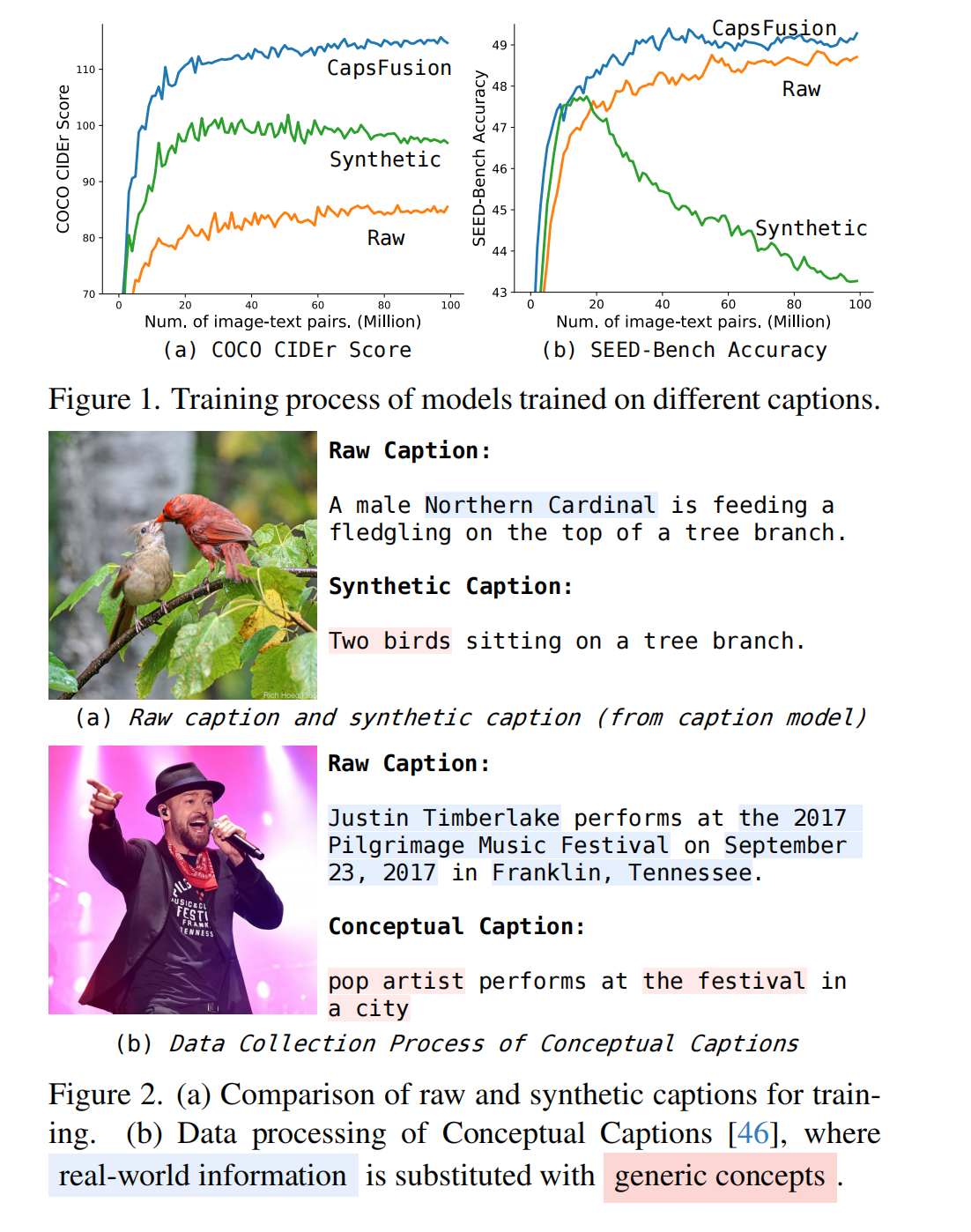
11.【多模态】CapsFusion: Rethinking Image-Text Data at Scale
-
论文地址:https://arxiv.org//pdf/2310.20550
-
开源代码(即将开源):https://github.com/baaivision/CapsFusion
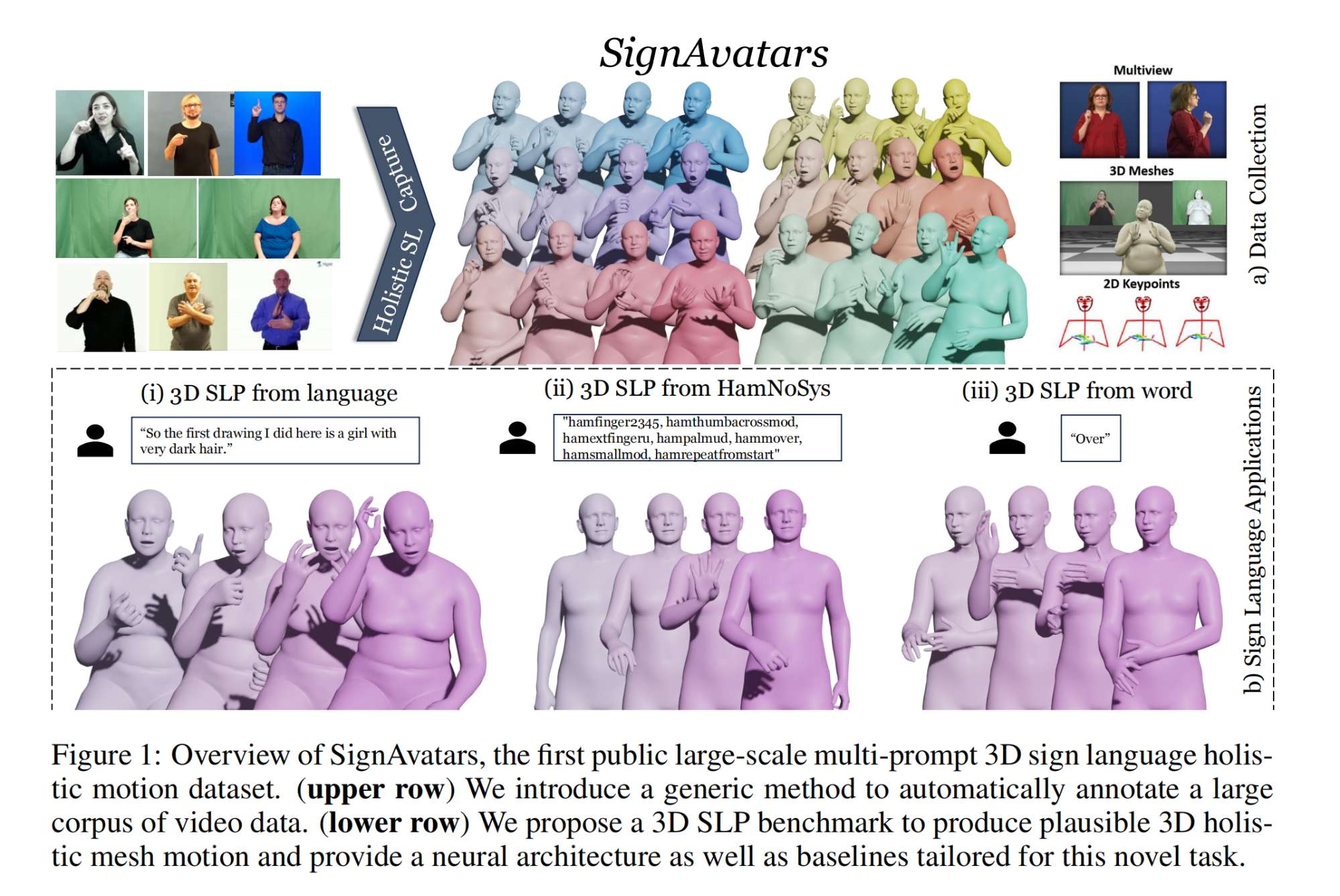
12.【数字人】SignAvatars: A Large-scale 3D Sign Language Holistic Motion Dataset and Benchmark
-
论文地址:https://arxiv.org//pdf/2310.20436
-
工程主页:SignAvatars: A Large-scale 3D Sign Language Holistic Motion Dataset and Benchmark
-
代码即将开源
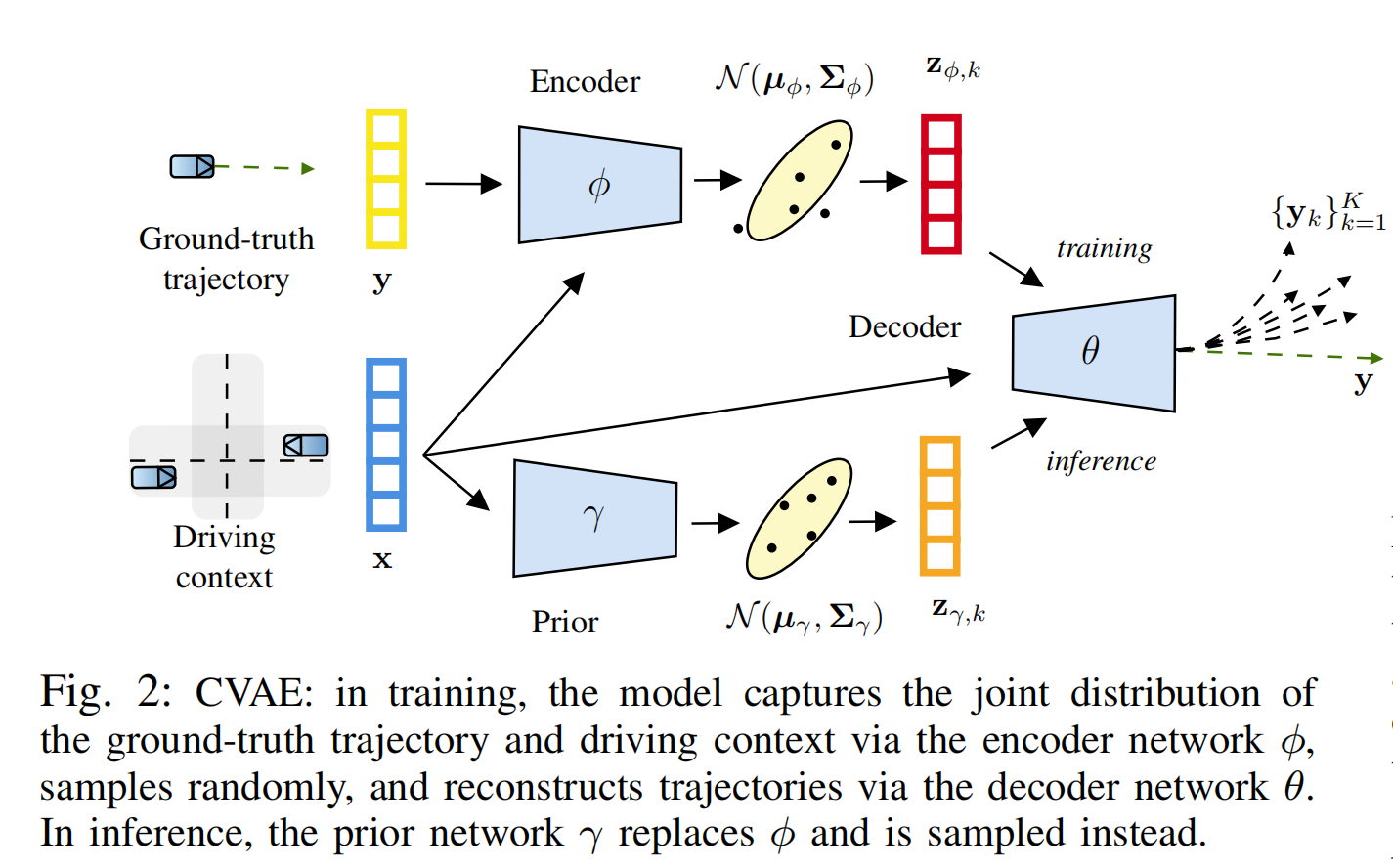
13.【自动驾驶:轨迹预测】(ICRA2024)Conditional Unscented Autoencoders for Trajectory Prediction
-
论文地址:https://arxiv.org//pdf/2310.19944
-
开源代码(即将开源):GitHub - boschresearch/cuae-prediction: Accompanying code for the ICRA'24 paper submission titled: "Conditional Unscented Autoencoders for Trajectory Prediction". Coming soon...
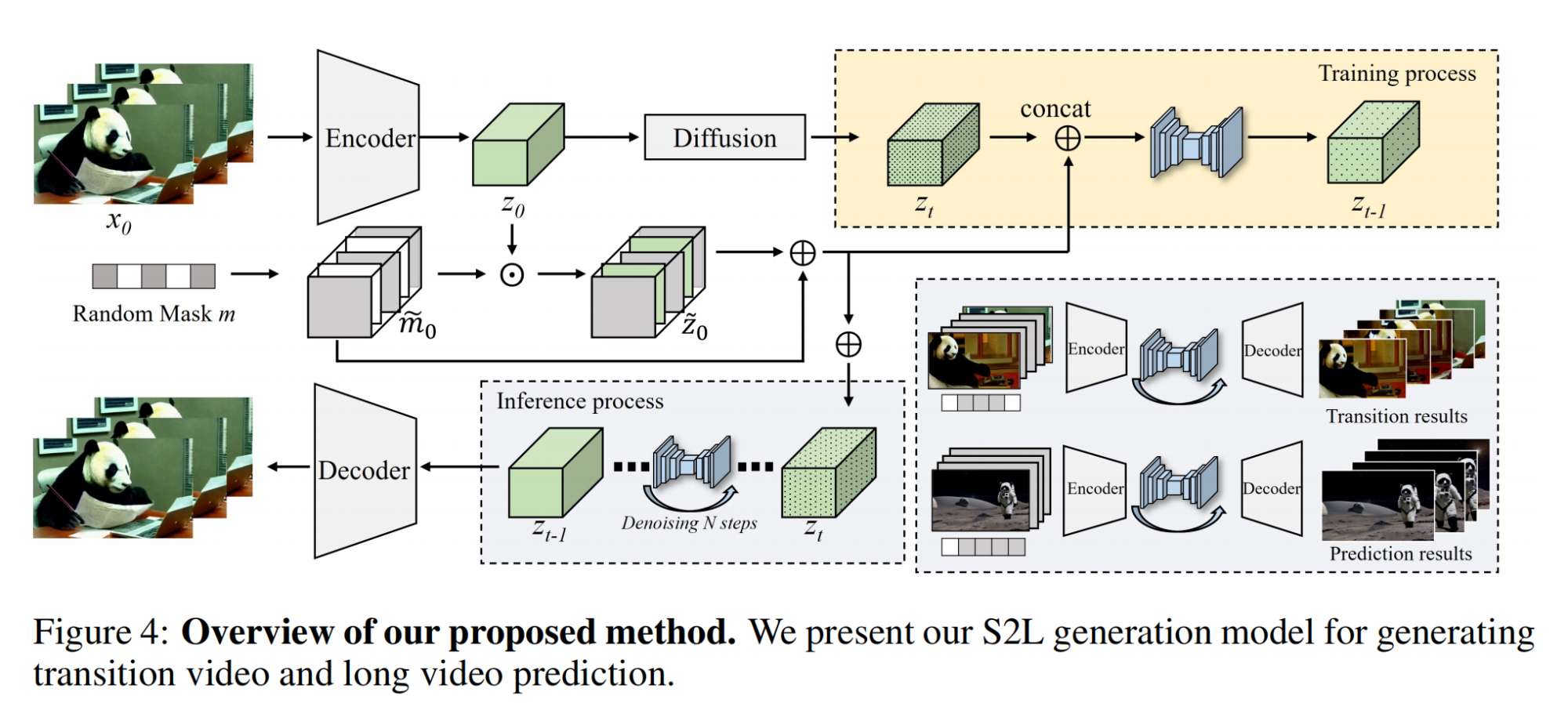
14.【Diffusion】SEINE: Short-to-Long Video Diffusion Model for Generative Transition and Prediction
-
论文地址:https://arxiv.org//pdf/2310.20700
-
工程主页:SEINE: Short-to-Long Vidoes Diffusion Model for Generative Transition and Prediction
-
开源代码(即将开源):https://github.com/Vchitect/SEINE
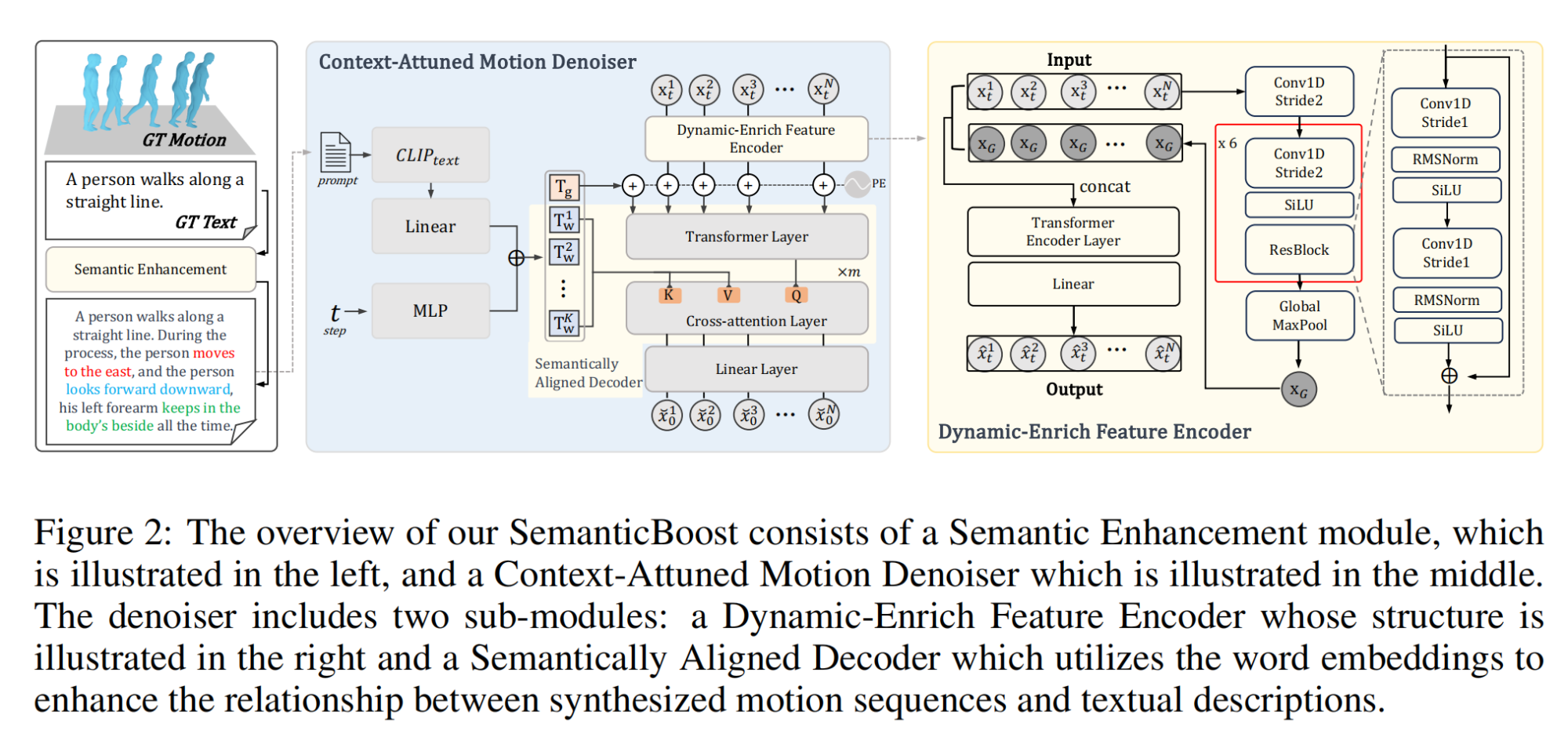
15.【人体运动生成】SemanticBoost: Elevating Motion Generation with Augmented Textual Cues
-
论文地址:https://arxiv.org//pdf/2310.20323
-
工程主页:SemanticBoost
-
开源代码:https://github.com/blackgold3/SemanticBoost
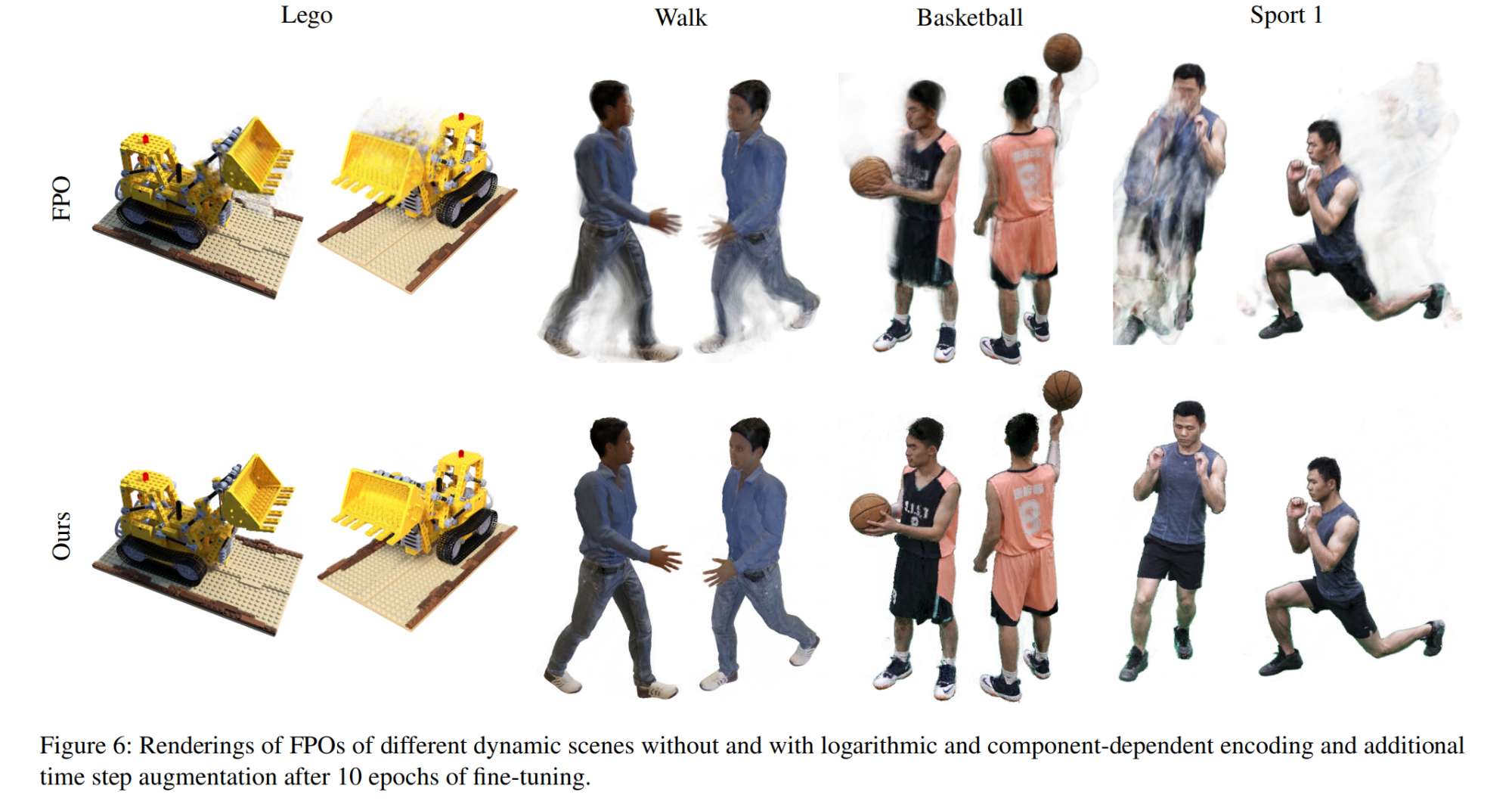
16.【NeRF】FPO++: Efficient Encoding and Rendering of Dynamic Neural Radiance Fields by Analyzing and Enhancing Fourier PlenOctrees
-
论文地址:https://arxiv.org//pdf/2310.20710
-
开源代码(即将开源):https://github.com/SaskiaRabich/FPOplusplus
17.【NeRF】(NeurIPS2023)NeRF Revisited: Fixing Quadrature Instability in Volume Rendering
-
论文地址:https://arxiv.org//pdf/2310.20685
-
工程主页:PL-NeRF
-
开源代码:https://github.com/mikacuy/PL-NeRF
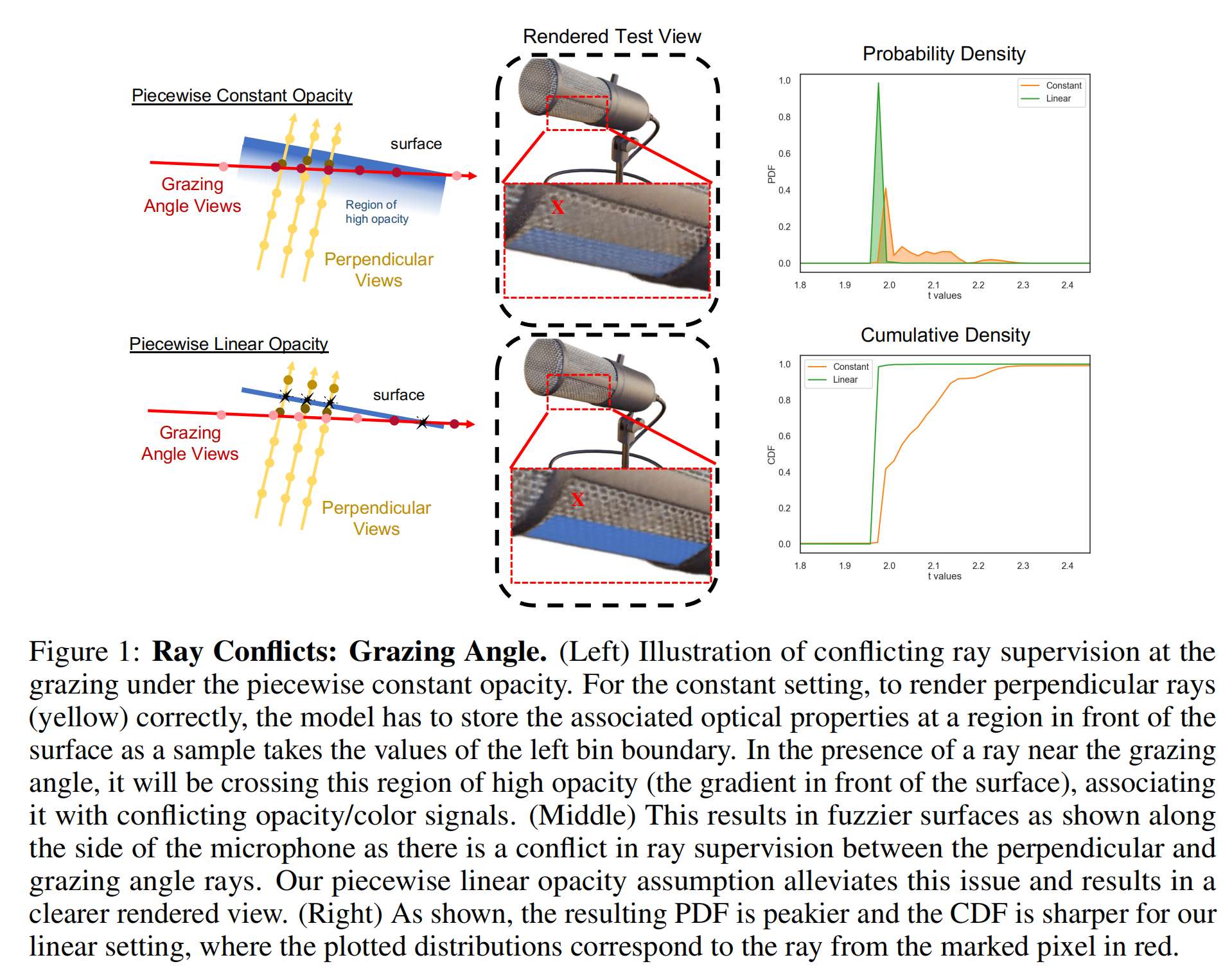
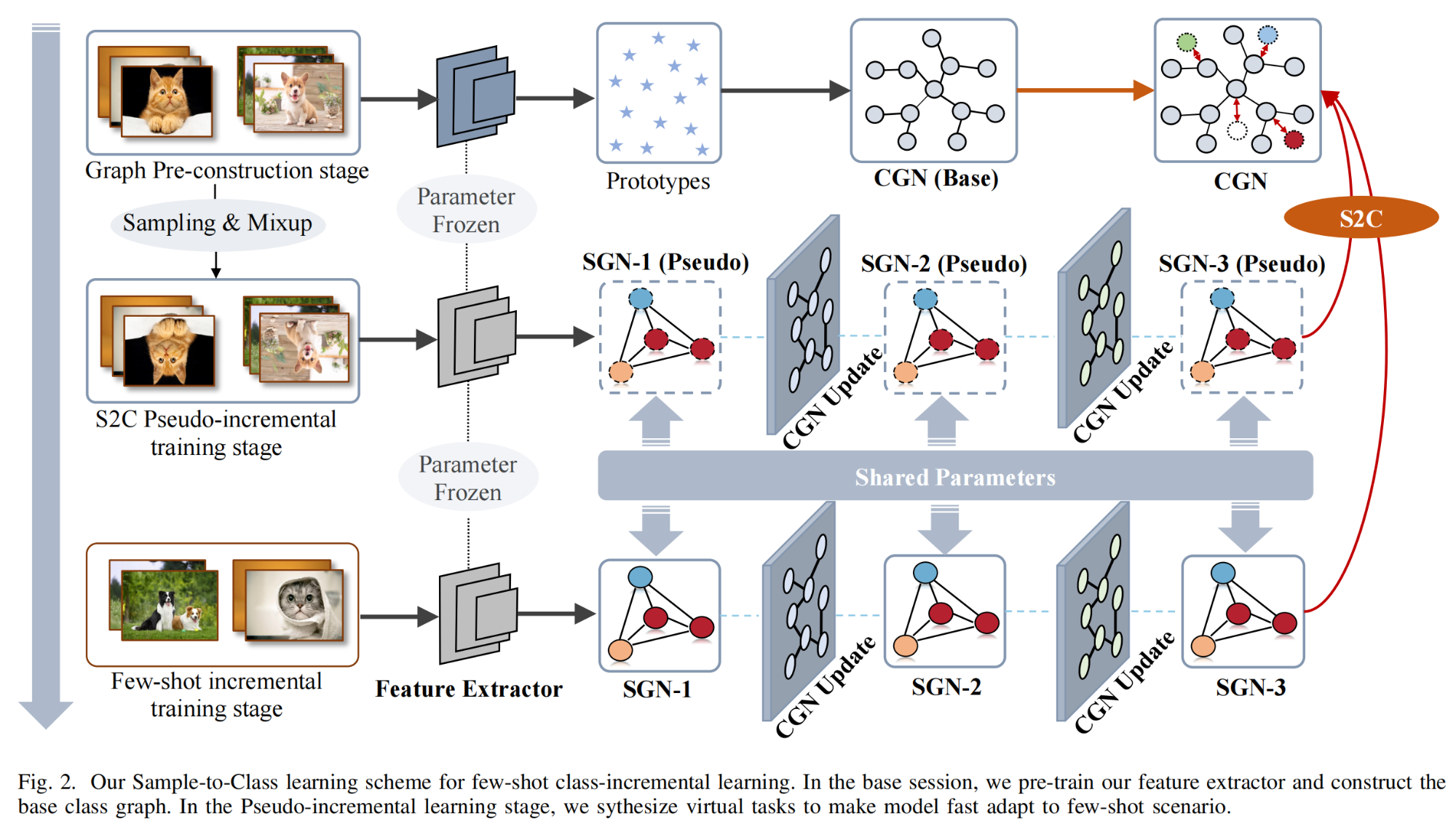
18.【类别增量学习】Constructing Sample-to-Class Graph for Few-Shot Class-Incremental Learning
-
论文地址:https://arxiv.org//pdf/2310.20268
-
开源代码(即将开源):https://github.com/DemonJianZ/S2C
19.【Visual Question Answering】Language Guided Visual Question Answering: Elevate Your Multimodal Language Model Using Knowledge-Enriched Prompts
-
论文地址:https://arxiv.org//pdf/2310.20159
-
开源代码(即将开源):https://github.com/declare-lab/LG-VQA

论文已打包,下载链接
CV计算机视觉交流群
群内包含目标检测、图像分割、目标跟踪、Transformer、多模态、NeRF、GAN、缺陷检测、显著目标检测、关键点检测、超分辨率重建、SLAM、人脸、OCR、生物医学图像、三维重建、姿态估计、自动驾驶感知、深度估计、视频理解、行为识别、图像去雾、图像去雨、图像修复、图像检索、车道线检测、点云目标检测、点云分割、图像压缩、运动预测、神经网络量化、网络部署等多个领域的大佬,不定期分享技术知识、面试技巧和内推招聘信息。
想进群的同学请添加微信号联系管理员:PingShanHai666。添加好友时请备注:学校/公司+研究方向+昵称。
推荐阅读:
CV计算机视觉每日开源代码Paper with code速览-2023.10.31