Segmind 稳定扩散模型 (SSD-1B) 是稳定扩散 XL (SDXL) 缩小 50% 的精简版本,可提供 60% 的加速,同时保持高质量的文本到图像生成功能。 它已经过各种数据集的训练,包括 Grit 和 Midjourney scrap 数据,以增强其根据文本提示创建各种视觉内容的能力。
SSD-1B模型采用知识蒸馏策略,连续利用多个专家模型(包括 SDXL、ZavyChromaXL 和 JuggernautXL)的教学,结合它们的优势并产生令人印象深刻的视觉输出。
图像比较(SDXL-1.0 与 SSD-1B):

在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 3D场景编辑器
1、SSD-1B使用方法
该模型可以通过 🧨 Diffusers 库使用。
确保通过运行从源码安装Diffusers:
pip install git+https://github.com/huggingface/diffusers
另外,请安装transformers、safetensors和accelerate:
pip install transformers accelerate safetensors
要使用该模型,你可以运行以下命令:
from diffusers import StableDiffusionXLPipeline
import torch
pipe = StableDiffusionXLPipeline.from_pretrained("segmind/SSD-1B", torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
pipe.to("cuda")
# if using torch < 2.0
# pipe.enable_xformers_memory_efficient_attention()
prompt = "An astronaut riding a green horse" # Your prompt here
neg_prompt = "ugly, blurry, poor quality" # Negative prompt here
image = pipe(prompt=prompt, negative_prompt=neg_prompt).images[0]
SSD-1B模型现在应该可以在 ComfyUI 中使用。
请务必使用负面提示和 9.0 左右的 CFG 以获得最佳质量!
2、SSD-1B模型说明
- 开发者:Segmind
- 开发商:Yatharth Gupta 和 Vishnu Jaddipal。
- 模型类型:基于扩散的文本到图像生成模型
- 许可证:Apache 2.0
- 蒸馏自 stableai/stable-diffusion-xl-base-1.0
SSD-1B的主要特性如下:
- 文本到图像生成:该模型擅长根据文本提示生成图像,从而实现广泛的创意应用。
- 精炼加速:该模型专为提高效率而设计,可提供 60% 的加速,使其成为实时应用程序和需要快速生成图像的场景的实用选择。
- 多样化的训练数据:模型经过多样化的数据集训练,可以处理各种文本提示并有效生成相应的图像。
- 知识蒸馏:通过从多个专家模型中蒸馏知识,Segmind 稳定扩散模型结合了它们的优点并最大限度地减少了它们的局限性,从而提高了性能。
3、SSD-1B模型架构
SSD-1B 模型是 1.3B 参数模型,从基本 SDXL 模型中删除了多个层:
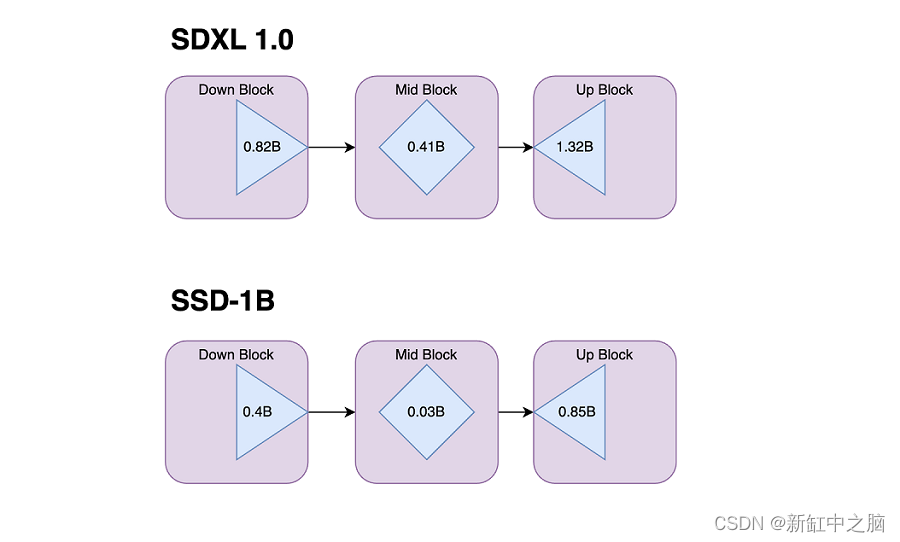
4、多分辨率支持

SSD-1B可支持以下输出分辨率。
- 1024 x 1024(1:1 正方形)
- 1152 x 896 (9:7)
- 896 x 1152 (7:9)
- 1216 x 832 (19:13)
- 832 x 1216 (13:19)
- 1344 x 768(7:4 水平)
- 768 x 1344(4:7 垂直)
- 1536 x 640(12:5 水平)
- 640 x 1536(5:12 垂直)
5、SSD-1B速度比较
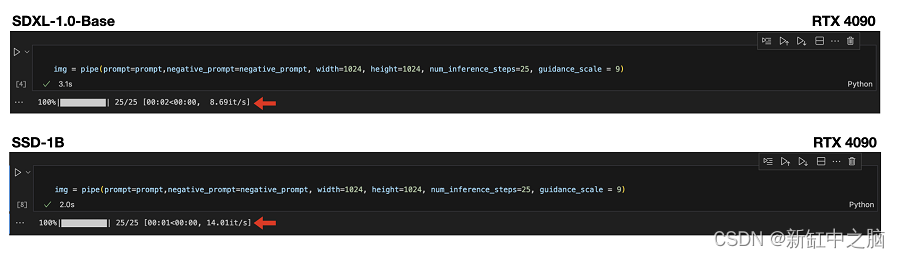
我们观察到 SSD-1B 比 Base SDXL 型号快 60%。 以下是 A100 80GB 的比较。
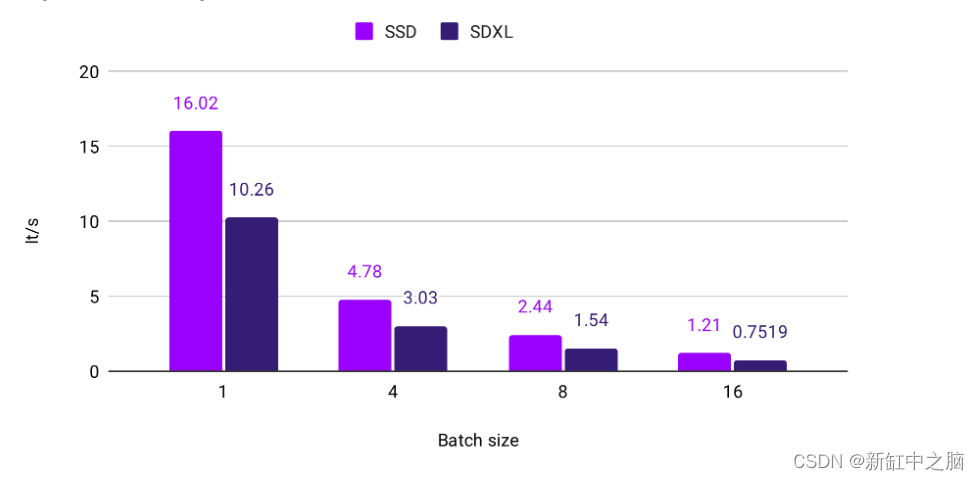
以下是 RTX 4090 GPU 的加速指标:
6、SSD-1B的潜在用途
SSD-1B 模型不适合创建人物、事件或现实世界信息的事实或准确表示。 它不适用于需要高精度和准确度的任务。
直接使用。Segmind 稳定扩散模型适用于各个领域的研究和实际应用,包括:
- 艺术与设计:它可用于生成艺术品、设计和其他创意内容,提供灵感并增强创意过程。
- 教育:该模型可应用于教育工具,以创建用于教学和学习目的的视觉内容。
- 研究:研究人员可以使用该模型来探索生成模型,评估其性能,并突破文本到图像生成的界限。
- 安全内容生成:它提供了一种安全且受控的内容生成方式,降低了有害或不当输出的风险。
- 偏差和局限性分析:研究人员和开发人员可以使用该模型来探究其局限性和偏差,从而有助于更好地理解生成模型的行为。
下游使用。Segmind 稳定扩散模型还可以直接与 🧨 Diffusers 库训练脚本一起使用进行进一步训练,包括:
- 微调:
export MODEL_NAME="segmind/SSD-1B"
export VAE_NAME="madebyollin/sdxl-vae-fp16-fix"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch train_text_to_image_lora_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--pretrained_vae_model_name_or_path=$VAE_NAME \
--dataset_name=$DATASET_NAME --caption_column="text" \
--resolution=1024 --random_flip \
--train_batch_size=1 \
--num_train_epochs=2 --checkpointing_steps=500 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--mixed_precision="fp16" \
--seed=42 \
--output_dir="sd-pokemon-model-lora-sdxl" \
--validation_prompt="cute dragon creature" --report_to="wandb" \
--push_to_hub
- LoRA:
export MODEL_NAME="segmind/SSD-1B"
export VAE_NAME="madebyollin/sdxl-vae-fp16-fix"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch train_text_to_image_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--pretrained_vae_model_name_or_path=$VAE_NAME \
--dataset_name=$DATASET_NAME \
--enable_xformers_memory_efficient_attention \
--resolution=512 --center_crop --random_flip \
--proportion_empty_prompts=0.2 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=10000 \
--use_8bit_adam \
--learning_rate=1e-06 --lr_scheduler="constant" --lr_warmup_steps=0 \
--mixed_precision="fp16" \
--report_to="wandb" \
--validation_prompt="a cute Sundar Pichai creature" --validation_epochs 5 \
--checkpointing_steps=5000 \
--output_dir="sdxl-pokemon-model" \
--push_to_hub
- Dreambooth LoRA:
export MODEL_NAME="segmind/SSD-1B"
export INSTANCE_DIR="dog"
export OUTPUT_DIR="lora-trained-xl"
export VAE_PATH="madebyollin/sdxl-vae-fp16-fix"
accelerate launch train_dreambooth_lora_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--pretrained_vae_model_name_or_path=$VAE_PATH \
--output_dir=$OUTPUT_DIR \
--mixed_precision="fp16" \
--instance_prompt="a photo of sks dog" \
--resolution=1024 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--learning_rate=1e-5 \
--report_to="wandb" \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=500 \
--validation_prompt="A photo of sks dog in a bucket" \
--validation_epochs=25 \
--seed="0" \
--push_to_hub
原文链接:Segmind SSD-1B — BimAnt