自动驾驶高效预训练--降低落地成本的新思路
- 1. 引言
- 定义高效预训练
- 2. ReSimAD
- 2.1引言
- 2.2 主要贡献
- 1.发布大规模ReSimAD数据
- 2.ReSimAD pipeline
- 2.3 实验
- 上海人工智能实验室
1. 引言
高效的预训练,是大模型的第一步
大模型的两种能力
- 海量数据分布–未知场景泛化:
- 带有差异性的语料库,因此对未知场景的泛化能力强
- 涌现能力(Emergent Ability):
- 不同与大模型的基础任务(文字接龙) ,经过instruction-tuning的模型会表现出很强的涌现能力,如:In-Context Learning(ICL), Chain-of-Thought(CoT)能力
- 视觉领域:SegGPT
为什么3D场景下没有形成通用感知大模型(3D点云)
- 相比于2D/语言场景,3D场景之间感知模型的迁移难!
- 实验表明在不同Domain(不同相机/采集地/天气)下性能下降很明显

- 实验表明在不同Domain(不同相机/采集地/天气)下性能下降很明显
- 相比于2D/语言场景,3D场景之间数据集的复用难!
- 类别定义不一样:
- waymo用地面的车当作一个类别
- 采集环境不一样
- 类别定义不一样:
定义高效预训练
高效3D预训练–降低模型对3D数据依赖的新思路
高效预训练的特点:
- 提升基线模型的Capacity
- 1.Capacity模型训到收敛,通过调参没办法提升,但是通过上游提升精度,这样的模型的Capacity理解为提升了
- 2.更快的收敛速度
- 3.更少的数据需求
- Zero-shot Setting --ReSimAD
- Label-efficiency Setting --SPOT
Real-to-Sim:
利用好了源域知识,可以做到zero-shot目标域感知
- 源域重建,目标域仿真
如果预训练的方式正确,海量数据预训练可以提升模型本身的Capacity
达到上游预训练数据增加,会不断提升下游预训练后的任务指标提升
2. ReSimAD
采用源域重建+目标域仿真
- https://arxiv.org/pdf/2309.05527.pdf
- https://github.com/PJLab-ADG/3DTrans/blob/master/README.md
2.1引言
域迁移的三个范式:
- 1.CARLA仿真:代价低,多样性差
- 没有真实的背景数据
- 2.厂商采集新设备数据,新标注/无标签学习:代价高,多样性强
- 3.原域数据的背景加入CARLA:代价低,多样性强
- 也就是这篇论文的方法
2.2 主要贡献
1.发布大规模ReSimAD数据
https://github.com/PJLab-ADG/3DTrans/blob/master/README.md
-
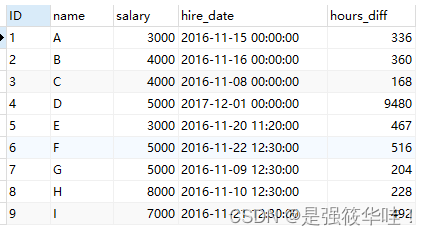
重建waymo的背景后,分别方针KITTI、NuScenes、ONCE等传感器setting去采集,达到28k帧
-
不同数据集的车辆不变尺寸(长宽高)不一样,对应做一下映射匹配

-
大规模ReSimAD数据集下载地址:https://openxlab.org.cn/datasets?lang=zh-CN
2.ReSimAD pipeline
- 重建方法:基于相机的重建、基于雷达的重建(区别:输入传感器的数据不一样)
- 因为用全量waymo数据集做重建,环境(阴天、雨天)影响相机比较大 ,所以采用基于雷达重建的方式
- 多帧拼接:对运动物体做动态补偿
- 运动物体分刚体和非刚体,非刚体比较难
- 纯lidar的大场景重建
- 对比了柏松重建、VDBFusion重建、纯lidar的重建 ,最终采用纯lidar的重建
主体部分

Point-to-Mesh Reconstrucrion模块
- 静态背景纯lidar隐式重建、动态物体显式重建混合式
Mesh-to-Point Simulation模块——获得跨域的点云数据
- PCSim
2.3 实验
ReSimAD对比的基线模型:
- CARLA-default:Zero-shot方法,前景、背景都是CARLA仿真
- Sensor-like:Zero-shot方法,仿真目标场景的传感器(第二套采集装备),产生仿真样本,但是背景信息是CARLA-Default的
- ST3D:属于UDA方法,其假设模型可以接触到目标域的样本(真实样本),但是是无标注

比CARLA更加真实