文章目录
- 前言
- 一、希尔排序的演示图例
- 二、希尔排序:插入排序的优化版本
- ☆三、核心算法思路
- 四、算法思路步骤
- (一)预排序 gap>1
- (二)gap=1 插入排序 完成排序收尾
- 五、码源详解
- (1)ShellSort1 —— gap组 轮完一组再接下一组
- (2)ShellSort2 —— 多组并排
- 【关于gap幅度的选择】
- 六、效率分析
- (1)时间复杂度 O(N^ 1.3)(和O(N*logN)是一个量级的,可能O(N^ 1.3)会略差于O(N*logN))
- 稳定性:不稳定
前言
前面我们学习了直接插入排序,我们可知道一个特点:当插排接近有序时,会非常的高效 。因此希尔研究出的希尔排序,令插排前面的数据更接近有序,就更高效。效率远超预期。
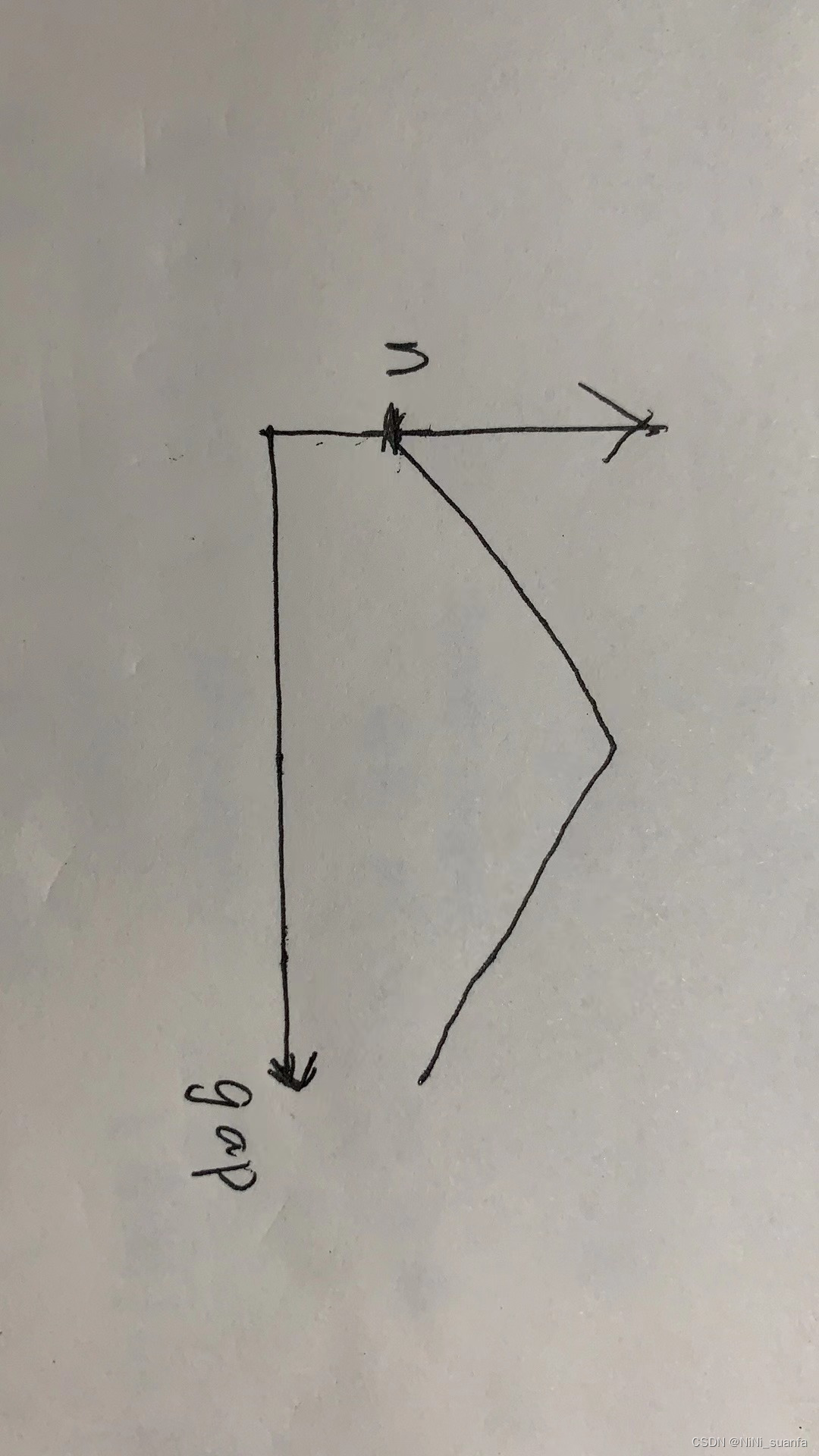
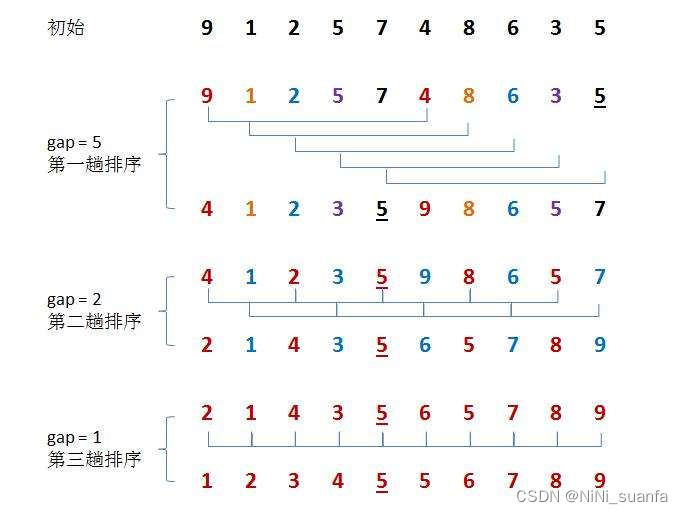
一、希尔排序的演示图例
二、希尔排序:插入排序的优化版本
希尔排序(Shell Sort)是一种排序算法,由美国计算机科学家Donald Shell于1959年提出。希尔排序是插入排序的一种改进版本,Shell从插入排序中感悟到了插入排序只要保持 要调整待插入的数据的前面的数据越有序,排序的效率就越高,旨在减少插入排序的交换操作和比较次数,从而提高排序效率。这个算法的名字是以发明者的名字命名的,虽然它也被称为 “递减增量排序” 。
☆三、核心算法思路
希尔排序法 又称 缩小增量法 。
- 基本思路:
先选定一个整数 gap(间距),把待排序文件中所有记录分成gap个组,所有距离为gap的记录分在同一组内,并对每一组内的记录进行排序。然后,取gap=gap/2 或 gap=gap/3+1 ( 增量逐渐递减 ),重复上述分组和排序的工作。当gap到达=1时,所有记录在统一组内排好序(=插入排序)。
旨在通过 将间距为gap的数据之间的插入排序
将大的数据通过 间距gap的插入排序 更快的甩到后面去,小的数据甩到前面来
使待排序的序列在gap增量递减到1之前 [也就是在真正的插入排序之前] ,使数据更接近有序,让最后一次gap==1时的插入排序实现高效排序。
四、算法思路步骤
(一)预排序 gap>1
- 分组排,间距为 gap 的数据都分为一组 ,共有 gap 组(gap的间隔中,就是分好的组数)
- 间距为 gap 的数据都分为一组,每组数据进行单趟间距为gap的插入排序。(和插入排序的思路一样,但能让大的数据通过间距gap更快的甩到后面去,小的数据更快的到前面来)
- 增量递减 gap=gap/2 或 gap=gap/3+1(一般取这个) [ gap随n变化 ],进行多次预排序【gap递减的幅度也是有讲究的,请看下文 】
- gap越大,跳的越快,越不接近有序;gap越小越慢,越接近有序一点。
多次预排的意义:让大的数据更快的到后面去,让小的数更快的到前面来。
(二)gap=1 插入排序 完成排序收尾
当 gap==1 时,就是插入排序。完成全部数据的排序。这时的数据已经非常接近有序了,这时的插入排序将会非常高效!
五、码源详解
(1)ShellSort1 —— gap组 轮完一组再接下一组
运用两层循环:
- 外层循环控制轮到的组号
- 内层循环控制一组内间隔为gap之间数据的比较
//希尔排序 —— 一组一组轮
void ShellSort(DataType* a, int n) {
int gap = n;
while (gap > 1) {
//gap = gap / 2;
gap = gap / 3 + 1; //+1确保除到最后gap=1 //gap根据n的大小进行变化 //gap也能取n/2(最终除出来一定为1)
//将 数组中 间隔为gap的数分为一组,共分为gap组,(间隔的数据中间的个数,便是所有已经分好的组数)
//一组一组遍历
for (int j = 0; j < gap; j++) {
//每组进行遍历
for (int i = j; i< n - gap; i += gap) {
int end = i;
int tmp = a[end + gap]; //先将要移的数先保存起来,前面发生挪动会将其覆盖
while (end >= 0) { //向前遍历完
if (tmp < a[end]) { //比tmp大就往后移
a[end + gap] = a[end];
end -= gap; //再继续向前比较
}
else {
break;
}
a[end + gap] = tmp;
}
}
}
}
}
注意:边界问题建议大家套值进去试,不容易出错。
(2)ShellSort2 —— 多组并排
一组排完第一个gap,就跳到另一组排另一组的第一个gap(每组都一部分一部分地排)
//希尔排序 —— 多组并排
void ShellSort(DataType* a, int n) {
int gap = n;
while (gap > 1) {
//gap = gap / 2; //gap也能取n/2(最终除出来一定为1)
gap = gap / 3 + 1; //+1确保除到最后gap=1 //gap根据n的大小进行变化
for (int i = 0; i < n - gap; i++) {
int end = i;
int tmp = a[end + gap];
while (end >= 0) {
if (tmp < a[end]) {
a[end + gap] = a[end];
end -= gap; //希尔排序的本质还是插入排序(end从前往后,每个end都向前遍历一次,遍历与其间隔gap的数),只不过是先通过gap分组来排出个相对有序,然后实现更高效的插入排序
}
else {
break;
}
a[end + gap] = tmp; //若发生了值的交换, end-=gap后 再加上gap 就是现在end的位置,就是将小的tmp值换到现在end的位置
//若当前没有发生值的交换,则让tmp储存下一个相距gap的值 a[end+gap],让下一个值再进行 向前比较遍历
}
}
}
}
【关于gap幅度的选择】
 《数据结构-用面相对象方法与C++描述》— 殷人昆
《数据结构-用面相对象方法与C++描述》— 殷人昆
gap越大,跳的越快,越不接近有序,gap越大能让大和小数据更快地到两边。
gap越小越慢,越接近有序一点。
相比之下,gap=gap / 3 + 1 是比较适合的大小
int gap = n;
while (gap > 1) {
//gap = gap / 2;
gap = gap / 3 + 1; //+1确保除到最后gap=1 //gap根据n的大小进行变化 //gap也能取n/2(最终除出来一定为1)
六、效率分析
(1)时间复杂度 O(N^ 1.3)(和O(NlogN)是一个量级的,可能O(N^ 1.3)会略差于O(NlogN))
希尔排序的时间复杂度不好计算,因为gap的取值方法很多,导致很难去计算,因此在好些树中给出的希尔排序的时间复杂度都不固定:
《数据结构(C语言版)》— 严蔚敏

《数据结构-用面相对象方法与C++描述》— 殷人昆

因为咋们的gap是按照Knuth提出的方式取值的,而且Knuth进行了大量的试验统计,我们暂时就按照O(n^1.25)到 O(1.6* n^1.25) 来算。
结论:O(N^ 1.3)
以 gap=N / 3 为例,有N/3组数据,每组里有3个数据进行比较,每组比3次 => 一个gap 比较(N/3 * 3 = N)次,但其中并不是都要交换 => N^2 => N^1.3 (N*logN).
稳定性:不稳定
呈如图这样的趋势:先增大,中间性能增大,再回复到小。
是个数学问题 " 复变函数 "
图中的变化参数 大概为 log2 N(底数为2)