#pic_center
R 1 R_1 R1
R 2 R^2 R2
目录
- 知识框架
- No.1 多层感知机
- 一、感知机
- 1、感知机
- 2、训练感知机
- 3、图形解释
- 4、收敛定理
- 5、XOR问题
- 6、总结
- 二、多层感知机
- 1、XOR
- 2、单隐藏层
- 3、单隐藏层-单分类
- 4、为什么需要非线性激活函数
- 5、Sigmoid函数
- 6、Tanh函数
- 7、ReLU函数
- 8、多类分类
- 9、多隐藏层
- 10、总结
- 三、D2L代码注意点
- 四、QA
- No.2 模型选择+过拟合和欠拟合
- 一、模型选择
- 1、预测谁会偿还贷款
- 2、发现
- 3、训练误差和泛化误差
- 4、验证数据集和测试数据集
- 5、K-折交叉验证
- 6、总结
- 二、过拟合和欠拟合
- 1、过拟合和欠拟合
- 2、模型容量
- 3、模型容量的影响
- 4、估计模型容量
- 5、VC维
- 6、VC维的用处
- 7、数据复杂度
- 8、总结
- 三、D2L注意点代码
- 四、QA
- No.3 权重衰退
- 一、权重衰退
- 1、权重衰退
- 2、使用均方范数作为硬性限制
- 3、使用均方范数作为柔性限制
- 4、演示对最优解的影响
- 5、参数更新法则
- 6、总结
- 二、D2L代码注意点
- 三、QA
- No.4 丢弃法
- 一、丢弃法
- 1、丢弃法
- 2、动机
- 3、无偏差的加入噪音
- 4、使用丢弃法
- 5、推理中的丢弃法
- 6、总结
- 二、D2L代码注意点
- 三、QA
- No.5 数值稳定性+模型初始化和激活函数
- 一、数值稳定性
- 1、神经网络的梯度
- 2、数值稳定性的常见两个问题
- 3、例子:MLP
- 4、梯度爆炸
- 5、梯度爆炸的问题
- 6、梯度消失
- 7、梯度消失
- 8、梯度消失的问题
- 9、总结
- 二、模型初始化和激活函数
- 1、让训练更稳定
- 2、让每层的方差是一个常数
- 3、权重初始化
- 4、例子MLP
- 5、正向方差
- 6、反向均值和方差
- 7、Xavier初始化
- 8、假设线性的激活函数
- 9、反向
- 10、检查常用激活函数
- 11、总结
- 三、QA
- No.6 实战:kaggle房价预测+加州2020年房价预测
- 一、kaggle房价预测
- 二、加州2020年房价预测
- 三、AQ
知识框架
No.1 多层感知机
一、感知机
1、感知机
-
让我们来讨论感知机。这是 1960 年代的一个原始感知机模型图,你可以看到它只有一条直线。因此,感知机是一个非常简单的模型。
-
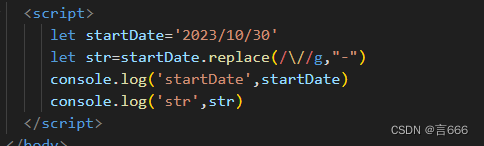
感知机是人工智能领域中最早的模型之一,已经有 70 年的历史。它实际上是一个非常基本的模型。给定输入 x(一个向量)、权重 w(也是一个向量)和偏差 b(一个标量),感知机的输出是 w 和 x 的内积,再加上 b,然后通过一个激活函数(通常是符号函数 Sigma)来得到最终输出。
-
在 Sigma 函数方面,有多种选择。一种常见的选择是,如果内积结果大于 0,则输出 1;如果小于等于 0,则输出 0。感知机通常用于二分类问题,其中大于 0 的输入对应于类别 1,小于等于 0 的输入对应于类别 0。当然,你也可以选择不同的输出值,例如改成 -1,或者是 0 和 1,这是可调的。
-
从图形上来看,感知机的输入是 x1 到 xd,其中 d 表示输入的维度。其输出是单一的元素,因此感知机通常用于二分类问题,与线性回归的输出不同,线性回归输出实数。此外,与 Softmax 不同,Softmax 用于多分类问题,它会输出多个元素,而感知机只输出一个元素,因此只能处理二分类问题。
2、训练感知机
-
"现在,让我们回顾一下感知机的训练过程,这是一个非常基础的算法。首先,我们将权重 w 初始化为 0,偏差 b 也初始化为 0,这不同于我们之前的方法,通常会将权重初始化为随机值。然后,我们遍历样本 i,从 0 到最后一个。
-
对于当前样本 i,我们首先计算其预测值,通过将权重向量 w 与输入向量 x 做内积,然后加上偏差 b。如果这个值小于等于 0,表示感知机对这个样本的分类错误,因为如果真实标签 yi 大于 0,意味着应该分类为正类,而小于等于 0 意味着应该分类为负类。如果分类错误,我们需要更新权重和偏差。
-
我们的权重更新规则是:w = w + yi * xi,其中 yi 是样本的真实标签,xi 是输入样本。偏差 b 更新为:b = b + yi。这个更新过程一直持续,直到所有样本都被正确分类。这也是一个停止条件,即当感知机正确分类所有样本时停止训练。
-
值得注意的是,这个算法等效于使用批量大小为 1 的梯度下降。每次只拿一个样本计算梯度并进行权重和偏差的更新。这不是随机梯度下降,因为感知机最初的模型是通过遍历数据一遍又一遍来学习的,没有随机性。
-
这个损失函数描述的是感知机的训练过程。感知机的损失函数可以表示为:
损失 = -yi * (w · xi + b)
其中,yi 是样本的真实标签,w 是权重向量,xi 是输入样本,b 是偏差。这个损失函数中的 Max 函数实际上对应于一个 if 语句,其作用是根据样本的分类结果来确定损失值。如果分类是正确的,那么这一项应该大于 0,因此 Max 函数的输出为 0,表示损失为 0,无需进行权重和偏差的更新。如果分类错误,这一项将为正数,然后我们进入 if 语句并执行权重和偏差的更新操作
这个损失函数的核心思想是,只有在分类错误时才计算梯度并进行更新,这是感知机算法的关键。感知机的名字部分受到神经网络的启发,因为它在某种程度上模仿了神经元的工作方式。
-
感知机算法是一种非常简单的线性分类模型,虽然在实践中已经被更复杂的模型所取代,但它在机器学习的历史中扮演了重要的角色,因为它是最早的学习算法之一,并帮助启发了更复杂的神经网络和深度学习模型的发展。

3、图形解释
-
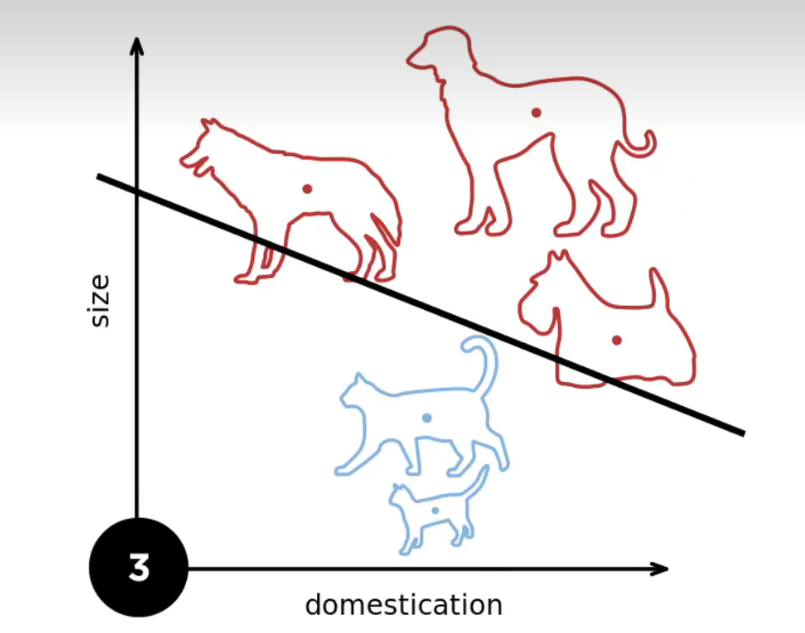
"接下来,我们来看一个示例。首先,我们假设有两个类别,需要对狗和猫进行分类。我们有两个轴,分别表示二元输入。假设我们有一只狗和一只猫。此时,我们的分类决策边界就是这条黑色线。
-
接着,假设出现一只新的狗。如果我们将之前的分类线仍然绘制在这里,那么通常情况下它可能会位于某个位置。然后,我们会发现它错误地将这只狗分类为另一类。因此,我们需要对我们的模型参数进行更新,将分类线下移一点点。这是因为狗位于下方,所以我们的分类边界需要向下调整,以更好地捕捉这只狗。
-
当我们引入更多的狗时,分类线将继续向下移动。如果我们引入了一只猫,它可能会将分类线稍微向上推移。我们需要不断重复这个过程,直到最终所有样本都被正确分类。这是感知机算法的一个奇特的停止条件,即确保所有类别都被正确分类。
-
感知机算法的核心思想是根据输入数据的权重和偏差来划分样本空间,通过不断调整这些参数来修正错误的分类,直到达到正确分类的目标。"
4、收敛定理
-
他的收敛定理是怎样的呢?所谓的收敛定理即是指何时能够停止,或者说我是否能够确保停止。感知机是一个非常简单的模型,因此它具有一个很好的收敛定理。让我们来看一下它的主要假设。
-
首先,我们假设我们的数据分布在一个半径为 r 的区域内。也就是说,这个区域的半径是 r。然后,我们还假设存在一个余量 ρ,这个余量使得存在一个分解面,该分解面的权重的 L2 范数之和小于等于 1,并能够正确分类所有的样本。请记住,正确分类要求这个值大于等于 0,即对所有样本都进行正确分类。此外,这个余量 ρ 存在,意味着我们可以稍微调整分类边界,即存在一个"margin",使我们可以将所有不同类别的样本分开。
-
在这种情况下,感知机可以确保找到最优解,并且它保证只会在不超过 r^2 加上 ρ 除以 r^2 之后停止。这里,r 表示数据的大小,也就是数据分布的范围。如果数据分布在一个大范围内,那么收敛可能会相对较慢。另外,ρ 表示余量,如果数据在分类面附近分布得更开,可能会导致更快的收敛速度。
-
需要注意的是,这里没有提供具体的证明,但感知机的收敛定理通常基于几何直观和相对简单的证明。如果您对如何证明感知机的收敛定理感兴趣,可以作为一个练习去查找相关资料或进行详细研究。这个定理的证明通常相对简单,可以在几行代码和公式中完成。
[感知机的收敛定理的证明](感知机模型(Perceptron)的收敛性解读 | 统计学习方法 - 知乎 (zhihu.com))

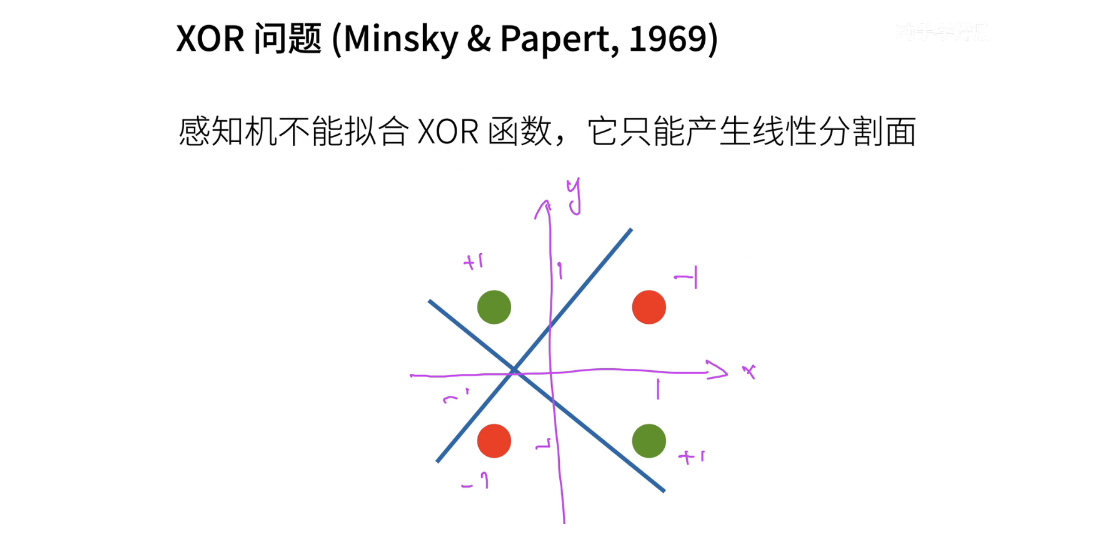
5、XOR问题
-
感知机不能拟合XOR函数。XOR代表“异或”操作,当输入 x 和 y 都相同时输出 -1(或 0),当它们不同时输出 +1(或 1)。在二维坐标系中,可以将它表示为:
-
点 (1, 1) 属于类别 -1(或 0)
-
点 (1, -1) 属于类别 +1(或 1)
-
点 (-1, 1) 属于类别 +1(或 1)
-
点 (-1, -1) 属于类别 -1(或 0)
-
-
感知机是一个线性分类模型,因此它只能创建一条直线来分割数据。无论如何划分,你都无法将整个数据正确分离。例如,如果你在某个地方进行划分,一类会被错误分类。如果你尝试不同的划分方式,另一类将被错误分类。这就是为什么感知机无法拟合XOR函数。
-
这个问题在 1969 年由 Minsky 和 Papert 提出,导致了第一个AI寒冬。人们开始怀疑感知机这种模型的能力,因为它甚至不能解决最简单的问题,比如 XOR。
-
后来,人们转向了其他方法,尤其是神经网络,以解决这个问题。在约 10 到 15 年后,人们才发现了一种解决方案,这就是多层感知机,或者称为深度神经网络。这些网络具有多个层次的非线性变换,可以解决XOR等更复杂的问题。这标志着神经网络的复兴,开创了深度学习的时代。
6、总结
- 感知机是一种二分类离散输出的模型,通常输出为1或0(或者1或-1)。它是最早的人工智能模型之一,并拥有自己的特定求解算法。从现代的角度来看,感知机的求解算法等效于批量大小为1的梯度下降。然而,由于感知机过于简单,它无法拟合XOR函数,这导致了第一个AI寒冬。这就是对感知机的简要总结。

二、多层感知机
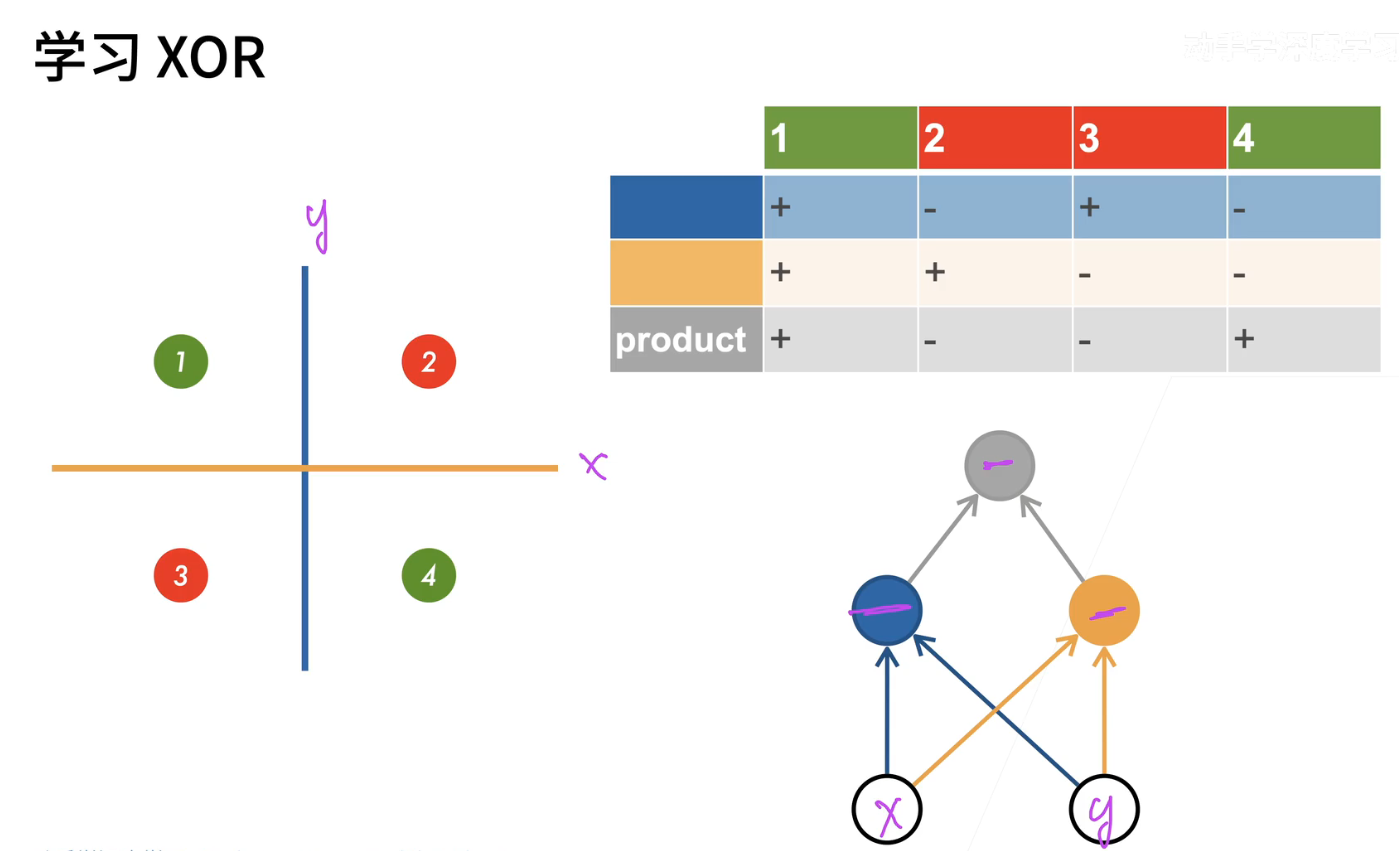
1、XOR
-
多层感知机,也称为MLP,是深度学习中经常使用的模型。在解决复杂问题时,单层感知机无法胜任。让我们回到XOR问题,我们需要完全分类这四个点,而单层线性模型无法胜任这个任务。
-
我们可以通过以下几个步骤来解决这个问题。首先,我们学习一个蓝色的线性分类器,它将在x=1时为正类,x<0时为负类。这是蓝色分类器的工作原理。它为1和4给出正值,为2和3给出负值。
-
接下来,我们学习一个黄色的线性分类器,它根据y的值分类。1和2得到正值,3和4得到负值。现在我们有了蓝色分类器和黄色分类器的结果。
-
然后,我们将这两个结果相乘,如果两者相同,结果为正,如果两者不同,结果为负。这就是我们的分类器。通过这种方式,我们可以将这些点正确分类。
-
图形化表示的话,x和y轴表示输入,我们首先进入蓝色分类器,然后进入黄色分类器,最后进入灰色感知机,我们就得到了正确的结果。这意味着,如果一次处理不了,我们可以先学习一个简单的函数,再学习另一个简单函数,然后将它们组合起来,这就是多层感知机所做的事情。
2、单隐藏层
-
简单来说,多层感知机可以用一个图形表示。首先,我们有四个输入:X1、X2、X3、X4。然后,我们引入一个或多个隐藏层。假设我们有五个隐藏层,那么每个输入从X1到X4都将经过计算并传递到第一个隐藏层H1,然后继续计算到H5。这个过程会将隐藏层的输出用作下一层的输入。隐藏层的大小是一个超参数,你可以自行选择。
-
为什么隐藏层的大小是一个超参数呢?因为你不能改变输入的大小,它由数据的维度决定。另一方面,输出的大小取决于你要解决的问题中的类别数。因此,唯一可以调整的参数就是隐藏层的大小,你可以根据具体情况来设置。

3、单隐藏层-单分类
记得结合上面那张图 进行;;
-
让我们详细讨论一下多层感知机(MLP)的结构和计算过程。我们将考虑一个单分类问题,并关注模型的各个组成部分。
-
首先,与以前一样,我们有一个输入向量,维度为n。接下来,我们引入隐藏层,假设隐藏层的大小为m。隐藏层包含一个权重矩阵W1,它的维度是m x n,以及一个偏置向量b1,维度为m。这些参数用于对输入进行线性组合和非线性变换。
-
隐藏层的输出,通常表示为向量a,具有长度m。这是通过将输入与权重矩阵相乘并添加偏置向量,然后通过激活函数σ(通常是ReLU或Sigmoid)进行计算的。
-
接下来,让我们关注输出层。因为我们在这里处理单分类问题,所以输出是一个标量。输出层有一个权重向量W2,维度为m,以及一个偏置项b2,是标量。
-
输出的计算过程类似于Softmax回归,我们将隐藏层的输出a乘以权重向量W2的转置,然后添加偏置项b2。这给出了一个标量,表示模型的输出。
-
关于Sigma函数,它是一个按元素运算的激活函数,通常是ReLU或Sigmoid。它将输入的每个元素应用于相应的输出元素,这有助于引入非线性性质,使模型能够捕捉更复杂的模式。
-
总之,多层感知机是通过多个层级的非线性转换来执行特定任务的深度学习模型。这些层级包括输入层、隐藏层和输出层,每个层级都包含权重和激活函数。计算过程涉及输入数据的线性组合、非线性变换和输出预测的计算。这个模型结构和计算过程可以根据不同任务进行调整和配置。

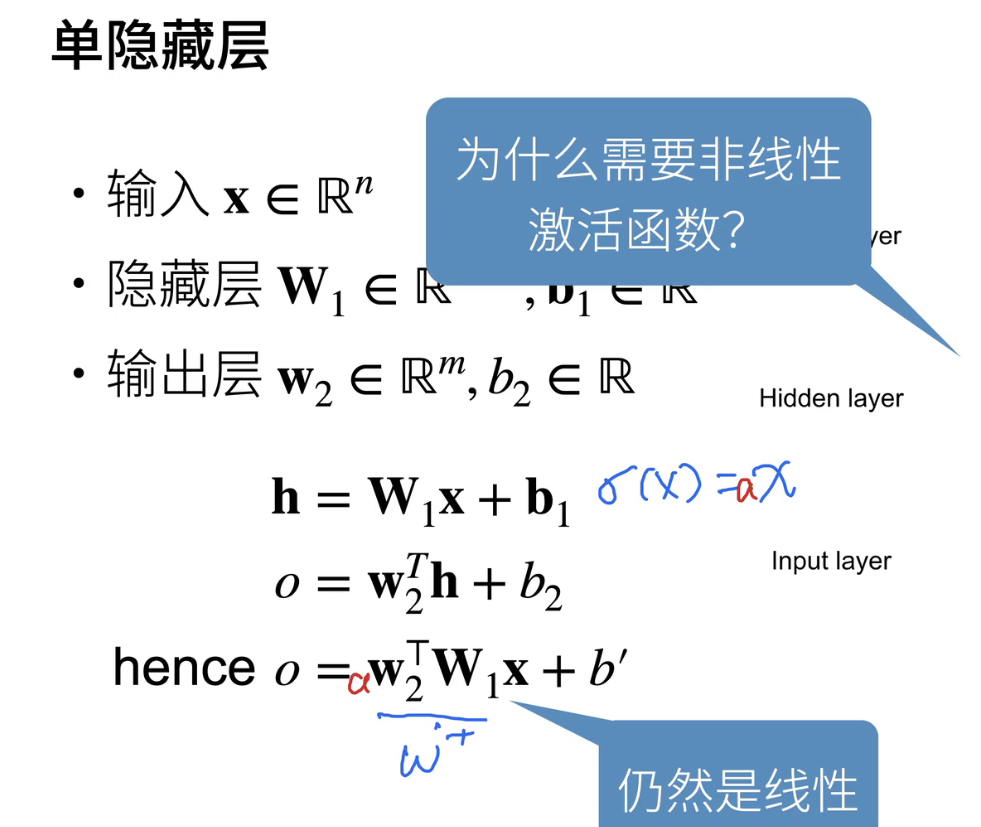
4、为什么需要非线性激活函数
-
为什么我们需要一个激活函数,而且这个激活函数必须是非线性的呢?不能简单地将σ(x)等于x或者等于n倍x。让我们来看一下原因。假设我们的激活函数就是恒等函数,即σ(x) = x。那么网络会变得怎么样呢?这意味着激活值 h 就等于输入值 x,也就是 h = x。
-
如果我们将 h 带入神经网络的前向传播过程,你会注意到以下情况:第一项将变成 W2 的转置矩阵乘以 W1 矩阵乘以 x,然后后面的项就不重要了,因为它们只是一些向量和标量的运算。实际上,假设 σ(x) = x,那么网络的输出就是一个线性函数。这是因为你的网络只是将输入数据进行线性变换,这就等价于一个简单的线性模型。即使你添加一个缩放因子 a,它仍然是一个线性函数。因此,我们需要确保激活函数是非线性的。
-
如果你的激活函数是线性的,你最终会得到一个仅包含线性变换的神经网络,这与单层感知机是等效的。这是在实际应用中经常犯的错误之一,如果不小心忘记添加激活函数,最终结果将还是一个线性模型。因此,我们通常需要使用非线性的激活函数来引入非线性性质,以便神经网络能够学习更加复杂的函数关系。
5、Sigmoid函数
-
最简单且经典的激活函数之一是Sigmoid函数。它将输入 x 投影到一个开区间 (0, 1) 内,可以视为一个S形曲线。回顾一下之前我们讨论的感知机,它的激活函数是一个阶跃函数,即如果 x 大于0,输出为1,否则为0。但是Sigmoid函数相对平滑,更容易处理。
-
Sigmoid函数的具体定义是:σ(x) = 1 / (1 + e^(-x))。
-
这个函数将负的 x 映射为一个正数,然后将其归一化到 (0, 1) 区间内。它是一个相对平滑的函数,因此更容易进行导数计算,相比于阶跃函数更易处理。这就是Sigmoid函数的特点。

6、Tanh函数
-
另一个常用的激活函数叫做双曲正切函数(Tanh)。Tanh函数的区别在于它将输入投影到一个区间 (-1, 1) 内,而其定义如下:Tanh(x) = (1 - e^(-2x)) / (1 + e^(-2x))。
-
Tanh函数类似于Sigmoid函数,但它将输出范围扩展到 (-1, 1) 区间,而不是 (0, 1) 区间。这个区间包括了正数和负数,使得Tanh函数在原点处的输出为0。
-
Tanh函数通常用于神经网络中,因为它是Sigmoid函数的一个平滑版本,而且可以将输入数据映射到更广的范围内。将激活函数的输出范围限制在 (-1, 1) 内可以有助于训练神经网络,因为它提供了更大的梯度,使训练过程更稳定。相比于将激活函数的输出硬性限制在 -1 到 1 之间,Tanh函数提供了更平滑的过渡,有助于减少训练中的梯度爆炸问题。

7、ReLU函数
-
Relu(Rectified Linear Unit)是另一个常用的激活函数。其实际定义是取输入 x 和 0 中的较大值,即 Relu(x) = max(0, x)。
-
深度学习领域经常对已有的概念重新命名,而实际上它们与之前的经典方法或模型有很多相似之处。深度学习在一定程度上是对之前方法的重新包装和利用。回溯传播(backpropagation)是一个自动求导领域的经典技术,而深度学习将其应用于神经网络中。
-
Relu函数非常简单,它在数学上表示为取 x 和 0 之间的最大值,这使得其函数图像看起来就像一条斜坡,正数部分的导数为1,而负数部分的导数为0。这使得 Relu 函数成为一个非常简单的激活函数。
-
Relu函数的特点是,它允许正值通过,将负值变为0。这个非线性性质是深度学习中的关键,因为它允许网络学习非线性函数,同时保持计算简单。 Relu 函数的引入使得神经网络更容易训练,避免了梯度消失问题,并在实际应用中取得了很好的效果。
-
Relu激活函数的主要优势之一是它的计算速度非常快,不需要进行指数运算。相比于某些其他激活函数,如Sigmoid和Tanh,它更加高效。回顾一下,以前在神经网络中使用Sigmoid或Tanh激活函数时,需要进行指数运算,这是计算上的昂贵操作。
-
在CPU上,一次指数运算的成本可能相当高,相当于进行大约100次乘法运算的成本。虽然GPU在进行指数运算方面要更高效一些,但仍然相对昂贵。相比之下,Relu只需要进行简单的比较和取最大值的运算,因此更加高效,特别适合大规模深度神经网络的训练。
-
因此,Relu之所以如此受欢迎,主要是因为它的简单性和高效性,使其成为深度学习中的首选激活函数之一。它不仅有助于解决梯度消失问题,还提高了训练的速度和效率。

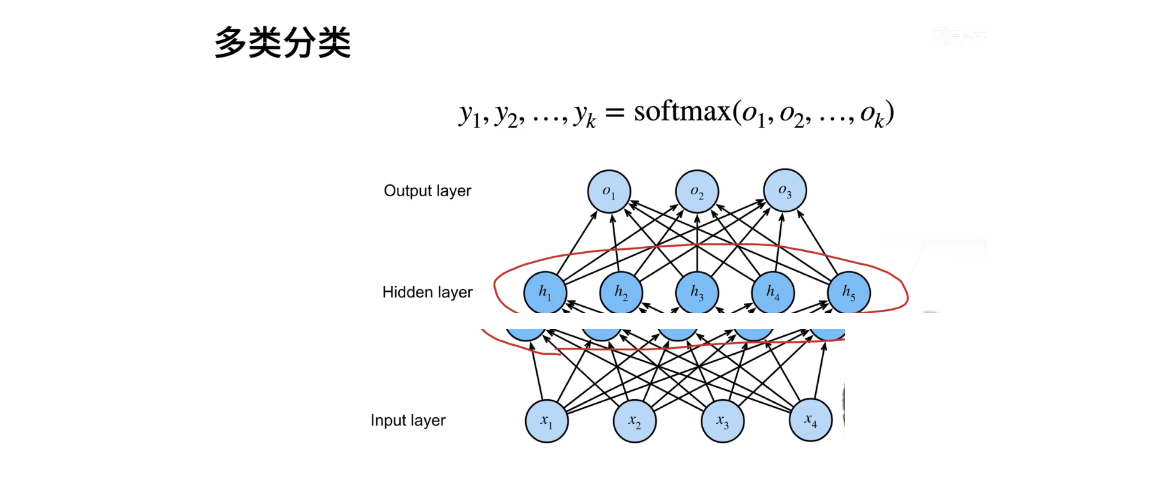
8、多类分类
-
多类分类问题在深度学习中通常使用Softmax函数来处理。Softmax回归与之前单类分类的Softmax没有本质区别,只是在输出层需要输出k个元素,其中k是类别的数量。然后,我们将这些输出通过Softmax操作,得到Y1到YK的置信度分数。Softmax的作用是将这些分数归一化到一个 (0, 1) 的区间内,使它们相加等于1,这样就可以解释为类别的概率。
-
多类分类与Softmax回归的区别通常在于中间的层,如果没有中间隐藏层,它就是最简单的Softmax回归。但如果引入一个或多个隐藏层,就会变成多层感知机(MLP)。多层感知机是一种更复杂的神经网络架构,它可以处理更复杂的非线性关系。
-
总的来说,多类分类问题在深度学习中通常使用Softmax函数来处理,只是具体的神经网络架构可能会包含中间隐藏层,这使得问题更复杂,可以处理更复杂的数据和关系。这些网络结构的变化主要表现在网络的深度和复杂度上。
-
多类分类问题中的多层感知机(MLP)与之前的定义基本相似,主要区别在于输出层的结构和Softmax的应用。以下是多类分类问题中多层感知机的一般定义:
-
假设输入层有 m 个特征,隐藏层有 h 个神经元,输出层有 k 个类别,那么多层感知机的定义如下:
-
输入层到隐藏层的权重矩阵:W1,大小为 m x h。
-
输入层到隐藏层的偏置向量:b1,大小为 h。
-
隐藏层到输出层的权重矩阵:W2,大小为 h x k。
-
隐藏层到输出层的偏置向量:b2,大小为 k。
-
-
最重要的区别在于输出层的结构。在多类分类问题中,输出层有 k 个单元,每个单元对应一个类别。而在输出之前,我们要应用Softmax函数,将这些输出分数归一化为概率分布。
-
具体的多层感知机架构包括输入层、一个或多个隐藏层以及输出层,通常输出层上会应用Softmax函数,以便将输出转化为类别的概率分布。这使得多层感知机能够处理多类分类问题,预测数据点属于不同类别的概率。

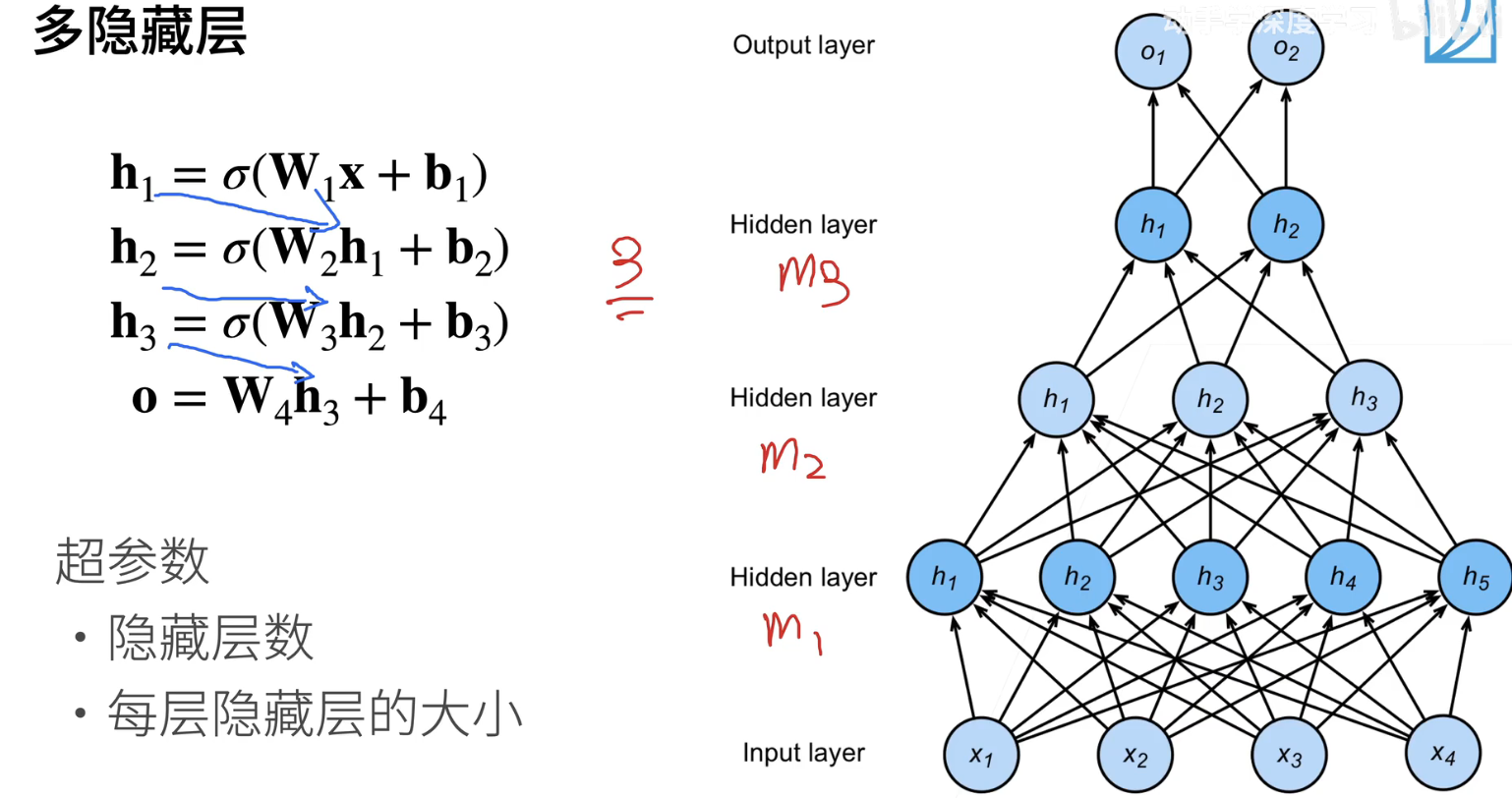
9、多隐藏层
-
可以考虑增加多个隐藏层,例如,单一层可能不足以满足需求。下面是一个简单的图示,用来说明可以使用多个隐藏层。输入层位于这里,接着是第一个隐藏层,第二个隐藏层,第三个隐藏层,最后是输出层。在数学上,每个隐藏层都有自己的权重(W)和偏移(b)。
-
首先,假设我们有第一层,记作W1和B1。其输出如下:(在这里应该有一个激活函数),H1表示第一个隐藏层的输出。H1然后作为第二个隐藏层的输入,同样,会与权重相乘,再加上偏移,再通过激活函数处理。需要注意,激活函数是必不可少的,如果省略了一个激活函数,层数将减少。同样的过程适用于第二隐藏层,其输出为H2,然后进入下一层,直到最后进入输出层。输出层通常不需要激活函数,因为激活函数的主要作用是避免层次退化。
-
关于超参数的选择,这取决于具体情况,超参数的设置需根据问题和数据的性质来确定。
-
首先,我们需要考虑两个关键因素:隐藏层的数量和每个隐藏层的大小。如果我们选择使用三个隐藏层,那么首先我们需要确定每个隐藏层的尺寸。一般来说,这个决策需要基于技术经验和数据特点。通常情况下,我们可以将第一个隐藏层(M1)设置得稍微大一些,这取决于数据的复杂性。较大的隐藏层会使模型更复杂,因此根据数据的复杂性来调整隐藏层的大小是重要的。
-
假设输入数据的维度为128,如果我们选择单隐藏层,我们可以将其大小设置为64、128或甚至256。然而,如果我们想使用多层感知机,有两个选择。一种选择是保持单隐藏层,但将其大小设置得稍微大一些,例如128。另一种选择是增加模型的深度,使用三个隐藏层,分别命名为M1、M2和M3。在这种情况下,我们应该调整每个隐藏层的大小,相对于单隐藏层模型来说,M1可以略小一些,M2比M1小一些,M3又比M2小一些。
-
综而言之,当决定隐藏层的数量和大小时,需要考虑数据复杂性和模型复杂性之间的平衡。如果数据较为复杂,可以考虑增加隐藏层的数量,但要小心不要使每个隐藏层过大,以避免模型过于复杂。
-
你可以理解这个操作的原因在于处理复杂数据和高维输入的情况。当你的数据具有较高的维度,比如128或256维,而你的输出相对较少,比如10个类别或者更少时,你需要将高维输入数据进行降维,以便模型能够有效地处理和学习这些数据。从本质上来说,机器学习可以看作是一种数据压缩的过程。你需要将复杂的输入数据,例如图像或其他数据,压缩到一个较简单的输出表示。
-
一种常见的做法是逐步进行数据降维,以逐渐减小维度,使数据更容易处理。例如,你可以将128维的输入首先降维到64维,然后再降维到32维,然后到16维,接着8维,最后到你的目标输出维度,比如5维。这个逐步的降维过程有助于模型更好地学习数据的特征,并减少计算复杂度。
-
总之,这个方法的目的是通过逐步降维,将高维复杂数据转换成一个更简单的表示,使机器学习模型能够更有效地处理和理解数据。这种方式有助于提高模型的性能和泛化能力。
-
这也是一个有效的方法。你可以不断对数据进行提炼,同时在最底层稍微扩充数据。例如,你可以将128维的数据先扩展到256维,然后再逐渐将其降回目标维度。这种方法可以让底层的表示稍微增加维度,这并不会对模型产生太大的负面影响。
-
然而,一般来说,你不太会选择先将数据压缩到一个非常低维度,然后再扩充。这是因为在压缩到非常低维度时,很可能会损失大量信息,这样在之后的还原过程中会变得更加困难。但在深度学习中,特别是卷积神经网络(CNN),我们常常会看到先压缩再扩张的模型结构。如果这种压缩和扩张过程被合理设计,可以避免模型过拟合(overfitting)的问题。
-
所以,多隐藏层的设计思路通常涉及到逐步降维和适度的扩充,以便在数据处理中保留关键信息并提高模型的性能。这种方法有助于防止模型过拟合,从而提高模型的泛化能力。
10、总结
-
多层感知机(MLP)是一种神经网络模型,它包括一个或多个隐藏层以及激活函数,用来构建非线性模型。它克服了感知机的局限性,因为感知机只能表示线性模型,无法解决像XOR这样的非线性问题。MLP通过引入一个或多个隐藏层以及非线性的激活函数,实现了非线性建模。
-
在多层感知机中,常用的激活函数包括Sigmoid、Tanh和ReLU(Rectified Linear Unit)。通常情况下,由于ReLU相对简单且计算效率高,因此它在实际应用中被广泛使用。当你需要解决多分类问题时,可以使用Softmax函数,这使得多层感知机类似于之前的Softmax回归,只不过在中间加入了隐藏层以提高模型的表达能力。
-
多层感知机的超参数包括隐藏层的数量和每个隐藏层的大小,即你需要确定网络有多少个隐藏层以及每个隐藏层的神经元数量。这些超参数的选择会影响模型的性能和复杂性,需要根据具体问题和数据来进行调整。
-
总的来说,多层感知机是一种强大的非线性建模工具,通过引入隐藏层和激活函数,可以处理各种复杂的问题,并在深度学习中扮演着重要的角色。

三、D2L代码注意点
无
四、QA
这里的σ函数并不是激活函数;仅仅是设置的 类似 softmax类型的函数;;是作用到输出层的;
输出层并不需要激活函数的;
问题一是说;x大于0 为什么输出是1;通过设计w和b吗;还是通过训练:?
x大于0的时候;就是说我;我不是说x大于0;是说那个σ;那个函数;然后我可以回到我们的;回到我们的那个;对于说哦不;这个x;和我们的输入x不是一个东西;就老师说;这个x是说这个函数的数x;和这个x本质上不是一个东西;它这个x;其实是说你这个整个这个的计算;所以大家可能;这里有一点点误会;所以是说;但是通过学习WB;使得你进入我们的σ;如果是大于0输出为一;我们分类正确;

第二个问题是说;请问神经网络中的一层网络;到底是指什么;是指一层神经元经过线性变化后;成为一层网络;还是说一层神经元通过线性变化;加非线性;成为一层?
一般来讲;我们是一层;是包括了那个激活函数的;我们回到我们的在这个;换一个比如说一层;通常的一层呢;我们是讲;带权重的一层;所以这里是有两层;所以我们写呢是写三层呢;但实际上呢;说你怎么看呢;看你怎么看都行;一个看法是说;我假设隐藏层;我把一层画在这个地方;就是这是一个layer;这个这个呢;又是一个layer;就是说输入层我就不算成了;因为它就是一个输入;就是没没什么东西;然后它里面包含什么呢;包含你会发;现每一个箭头;这里每一个箭头它就是一个w;一个;其实它每个箭头包括了就是一个;一个可以学习的一个权重;理解吗就是说我们这个隐藏层;因为你的输入是4;输出是5的话;那么它的权重它就是一个4乘以5;或者5乘4;反正正着写反着写都没关系;然后呢就是说;所以你每一个元素它;对呢是这里面的一根箭头;然后呢当然你这里还有一个SEG嘛;对吧你的SEG;你的h是在计划函数之后的;所以我所谓的一层;通常是说;你这个权重;加上你的激活函数;和它的计算是怎么做的;所以这个里面我们说我们要两层;就是意思是说;我们需要两层可以学习的;层里面带了权重了;但以后我们讲卷积成就网络;也是差不多是一个概念;就是一个层;输入层在这个定义里面;输入层我们就不算层了;反过来讲;你也可以说我可以把这个;这我可以把;那我可以把这个东西归入;输入层对吧;那我就是输输出;那我就是不算层;也可以;反正就是你这因为只要两个w在这里;所以你只要两层;OK;

另外一个问题;是说你的数据的区r是怎么测量;或者统计;ρ怎么定??
;实际中我们确实要找到数据分布的区;可以找到吗;所以呢;所以呢;这个这个就是统计和机器学习的区别;统计我们是不管的;从从统计的角度来讲;我的ρ是定义出;来东西你像数学;我数学我会记;关注你怎么计算吗;我不关注的;我都是假设数据怎么样;假设这个怎么样;所以我的收敛定理;从来都是一个统计上的一个东西;;收敛那一块东西整个是统计上的;统计机器;可以说统计学习吧;嗯但是机器学习呢;或者说深度学习;它可以认为是统计的一个计算面;如果统计;你可以认为是数学的一块的话;那么就是机器学习;对应的是统计的计算机的那一个分支;所以机器学习里面;我们当然就如果是计算;你如果是;学CS的话;你当然不知道ρ怎么算;ρ算起来很难;你当你会去想ρ怎么算;这个怎么算;实际上你算不出来;但我们可以做一点假设;我们可以做人工生成的数据;我是能生成的;但实际上是做不了的;这个只是一个收敛定理;这是一个统计上的一个数学;不能太指导你的实际生产;
问题四是说;请问;是说正是因为感知机只能产生XOR函数;所以人们才会使用SVM吗?
;嗯;其实感知机这个问题还不是SVM;是是上个世纪90年代出来的感知机;其实那一块;当年 60年代;70年代;基本上被冬天来说;SVM还中间还;其实还有几十年;大家其实后面是慢慢多层感知机应该是在SVM之前的;所以是说;但是呢;我们没有;我们这个课不讲SVM;你可认为是说SVM替代了感知机;不能说是SVM;是因为x叫感知机;多层感知机解决了感知机XOR的问题;但是呢之后没有流行;是因为两个问题;第一你得选;超参数你得选那个;嗯你得选那个;要多个隐藏层;每个隐藏层长多大;那个是老中医了;怎么怎么调这个东西;而且收敛也不好收敛;就是说;我们也知道要调各种学习率;才能收敛;然后呢SVM的好处就是说;它没有那么多超参数可以选;它对超成数不敏感;比如说基于科隆和的SVM;它对它你呢;调宽一点;调窄一点都没关系;第二个是说SVN它优化会;接起来比较容易一点点;相对来说不要;不需要用;SGD或者怎么样;第三个可能更重要的是说;对学术界来讲;假设你两个模型的效果差不多;SVM和多层感知机其实就是在现在;其实也是差不多的;就说我没有说多层感知机会比SVM好;没有了;就是说;如果两个模型在实际效果上都差不多;精度都差不多;可能神经网络还好一点点;就仔细调仔细调能调出来;但是呢SVM用起来更简单;就说不用调那么参数;第二个最重要的是说;SVM它的数学很好;现在之所以说我不建议大家用SVM;也没有说SVM不好;就是说你用MLP的话;你试一下;反正如果你想改成一个别的神经网络;你就是你就改一下模型就过去了;优化算法什么东西都不用变;什么东西都不用变;就是改几行就过去了;但是用SVM的话;整个优化都得换;什么东西都得重新学;所以就是说相对来说没那么容易;所以就是说我们这里只讲了MLP;没有;就是多层感知机没有讲SVM的原因;
另外一个是说;XOR函数有什么应用吗?
没有什么应用;就是我给你;就是我给你;举个反例;就是说是什么意思呢就是;就当年做感知机的一帮人说;我这个东西多多厉害对吧;我硬件给你搭出来了;就是你可以看到说;当年感知机我给你做了个硬件;和现在深度学习用GPU也好;做AI芯片也好;没本质区别;就是你的计算跟不上;我给你搭个硬件;所以呢就是说我们催催催;就跟现在深度学习一样的;就是说我可以给你催催催催催催;说我这个东西多好;但是突然有个人跑过来说;其实你这东西有局限性;我给你举个反例;XOR函数简单吧;你不能不能拟合对吧;就是会给你举个反例;让大家一下;就没人没兴没兴趣了;搞半天简单还是多;不能拟合;所以;但是之后你多层感知机你可以证明;是说只要是只要有一个隐藏层;你是可以拟合一个任意函数的;就理论上;你可以拟合任意函数;就是你和你可以一层感知机;能拟合整个世界;就是理论上;实际上做不到;因为优化算法解不了这实际的问题;
第六个问题;是说假设你的x;x轴是特征一;y轴是特征2;那么红蓝是它的label?
对的是这;样子的就是说这是一个x actor函数;就是你有个你可认为是有两个输入嘛;两个特征;所以它的红和蓝是它的label;就是XOR它的输出;所以它的每一个对应的是一条数据;对吧因为四个点;XOR就四个点就定义好了;对吧所以四个点每个点是一个数据;所以说;就是说;我的Excel函数会通过4个样本来一个;4个样本;每个样本是二维;输出是一个正义负义来给定;所以呢就是说;我对一个很简单的4个样本;两维特征的数;你都不能;拟合就说;所以就说;感知机的局限性;就是你理解是没错的;
第七个问题挺好的;就是说你;为什么神经网络要增加隐藏层的层数;而不是神经元的个数;是不是有些神经元万有近似性质吗?
就说这里是一个很好玩的一个东西;就是说;我回到让我来回到我们的slides;好我们回到这个地方;就是说你;我们刚刚讲过;是说你要两种可能;一个是说你变得很胖;就你变得很;就是说我换两个图;就说一个选择输入你的输入进来;我会用一个很胖的一个东西来学;然后输出;ou和in的话;再就是我做一个窄一点的;带胖一点的东西;我还有个选择;是说我同样的模型;我要达到同样差不多的;就是模型复杂度;我们没有讲模型复杂度;你可以认为简单;认为就是我的模型的能力;就是说我可以;可以说我可以做的;这样子做深一;点对吧;每一层搞小一点;就说这个是out;这个心;就说你有两种做法;一种是但是这两个的模型复杂度;其实可认为是可以几乎是等价的;就是说它的capacity;它几乎几乎认为是相等的;从理论上来讲;我们可以证明;它也可以通过合适的理论上相等;但是问题是这个模型不好训练;就是这哪个模型不好训;这个模型;不好训练;这个模型好训练一些;这就这个模型叫深度学习;这个东西叫深度学习;这个东西叫浅度学习;哈哈就那么点东西;就是说;为什么他好训练一些呢;是因为说这个东西;这个东西特别容易overfitting(过拟合);就特别容易过拟合;因为它就是说;就是说你可以认为;就是说我要一次性吃个胖子;在这个地方;因为他每个神经元是一个并行的东西;就说你说;我所有的并行学东西;每个神经元要协调好;一起大家一起合作;学个东西很难;就说理论上可以;但是我们做不了理论解;对吧实际操作特别难;所以他学习起来不好学;但这个东西呢;就好一点点;就怎么意思呢;就是说你要学一个东西;你要学一个很复杂的东西;你怎么学;你不能一开始就把哐哐哐就跳进去;对吧所以你先从简单开始学;比如说;这举一个十贯上例子;这个东西没有理论依;太多依据;我要学一个;比如说我把一只猫的图片;和一只狗的图片;猫猫猫;比如说这是猫狗;我要学一个猫和狗的一个图片;我最后学学;这是个猫;一个cat一个dog;我要把这个东西把一个;就是我要学一个函数;把它从转过去;我怎么转呢;我我不能一次性转;我先说;我先学一点点;学一点把耳朵学出来;学个嘴巴;耳朵可能学耳朵太难了;就学一点简单东西;然后再学个头;对吧学个头;那就是说每一次每一层;你可以把它;做一个简单点的任务;学一点点东西;然后慢慢慢慢的学的;学的学的;学的越来越好;最后学到我的东西去;就是说这是我们的一个;我们的一个;怎么说呢;就是我们觉得神经网络你应该怎么做;但实际上来说;确实深一点的话;他训练起来方便一点;容易更容易找到一个比较好的解;这就是;为什么叫深度学习;所以整个深度学习;你可认为在2004年之前;跟之前没区别;我们之后会讲到;他跟60年代70年代没本质区别;就是说只是做的更深了;那是因为他更深;所以导致他训练起来更容易;所以就是;效果更好;
来看一下;神经元和卷积核有什么关系;?
神经元和卷积核;我们下次讲;卷积我们;我们会讲卷积是怎么从我们现在的;这个多层感知机器;一直过去的;它其实很容易过去的;一个东西就没什么特别Fancy的;
就Relu为什么管用;它在大于0的部分也是一个线性变化;为什么能促进学习呢?;激活的本质是;什么不是引入非线性性吗?
Relu是一个非线性模型;非线性函数;不是一个线性函数;理解吗;比如说所谓的线性函数是一根线;relu它虽然是个直的;但它不是一根线;它是一个折线;折线不是线性函数;线性函数是;线性函数一定是FX等于ax加上b;这是线性函数;线性函数不管怎么样;它就是一根线;Relu虽然它是一根;它是一根直的;但它不是一根线;它是一个;它是一个这样子的东西;所以它不是一个线性函数;它它是很;它是一个peacewise Linear;它是一个分段线性函数;但它不是线性;所以加入Relu之后;对吧所以确实;激活函数的本质是引入非线性性;他不要干别的事情;就是我们之后会稍微解释一下;激活函数;你可以认为它本质就是把非线性打乱;你可以加一个别的模型;都没关系;就说你可以随便加一个;我可以设计任何东西都行;我可以写一点;可以对吧;哦这个斜线描画好;我可以这么写一点点对吧;我我我往上翘也可以;其实没本质区别;我可以我可以这么来这么去;都没关系都;其实都没关系;不要觉得它很玄乎;它唯一的有关系的是;在我们之后会讲;我们预告太多了;就在这个点的之后;梯度会有一点点影响;但是没本质关系;你可以随便选;
不同任务下的激活函数;是不是都不一样哎;是通过实验来确定的吗?
其实都差不多;哈哈你不要激活函数;我觉得就是说;激活函数;它远远没有选择隐藏层大小;那些超参数来的重量;所以大家就;就用Rule吧;就尽量不要用别的吧;就说就说;你可以选;但本质上没有太多区别;;
模型的深度和宽度哪一个更影响性呢;有理论指导吗;是不是加深哪个更有效;怎么根据输入空间;选择最右的深度和宽度?
确实是说理论上来讲没有区别;但实际上来说;深一点的会好一点点;最优这是个最优;最优就比较难了;没有最优;哈哈哈这个东西哪有最优;你可以我们;我们可能会;你可以我们会;我们会有;比赛大家来试一下;是真的要实际来我的;嗯个人的经验;那假设我有一个数据;嗯假设我有一个数据;我想要去做一个;多层感知机;就也叫MLP吧;multilayer perception;我做一个MLP的话;那我一开始肯定不会做很深;我也不会做很宽;假设我还是举个例子;我的数我的输入假设是128;我的输入假设是128;去简单一点;那么我第一步要干的事情是说;我先我先试一下线性的行不行;你就跑一下嘛;线性就没有隐藏层;接下来呢;我来做一个有隐藏层的;就是把一个隐藏加一个隐藏层;那么加个隐藏层;一开始我不会做很大;我做一个16;因为他是128-2嘛;那么16也不错;我换一下吧;我假设我要把128变到一个2; 128-2;我第一个;第一步我会就直接不要隐藏层;直接128-2直接过去;第二次呢我如果觉得我先试一下;第二次我会加一个隐藏的18;比如说老二我加一个16;然后呢 165会再试32;再试比如说再试64;再试128 都可以;那么这个是第二步;就单隐藏色;我会再去看一下;第三步第三步那么就128;假设我这假设;我是说;128效果不行;16也效果不行;这个太简单;这个太复杂;32-24还可以的话;那么第三次我会加一个两个隐藏层;比如说我还是我是用一个32再加一个8;就新加了一个8在这个地方对吧;比这个32稍微复杂一点;那我当然可以;这个也可以改成16对吧;我这个也可以改成64;我这个改成;我还是用回8176;就是说你可以去多试几次;比如说你没有;就是说你从简单开始;慢慢的把它变复杂;你可以通过加宽;加深都可以;就是说你最后去试一下;最后你就是写一个for loop来变一下;所有东西都训练一遍;就是就完事了;但是这个是你最早;你当然你没有什么想法;怎么做时候你就怎么做;如果你接下来;慢慢的有了一些直观上的理解;这个理解我我当然有一些我的理解;但是我不好直接说出来;因为一不好说出来就不好怎么总结;第二个是说过去获得直觉不一;定是对的;所以大家就是老中医;大家试一遍就有感觉了;OK我们还有挺多问题;
为什么多层感知机后面的W2;W3没有转置?
这个东西看你怎么定义啦;就看你定义是m乘n还是n乘m啦;就有我还没仔细看;也可能我数学是错的;写错了就是说转质没转质都没关系;就是说最后看你是W2是定义是从;顺则来还是竖则来;
第15怎么让感知机理和所有函数;又保持动态性能;就像泛化性能;要打造动态神经网络吗;;要不训练完参数是死永远是死的?
是的训练完之后参数是要固定的;就你不要做动态;为什么不要做动;所谓动态;我理解就是说我给一个新我;我给一个同样的样本;我每次做预测的结果会不一样;那就是动态吧;但是这个不行;那个这个东西会有问题;比如说;Google出过一个很大的事情;在很在很早以前;他的图片的分类;把一个黑人分成一个星星;这是一个非常大的问题;在美国所以说你叫种族歧视嘛;等于是你把你把我;我上传一个股图片的Google;你把我分类成一个新星;我把分类成金丝猴;对不对;那我就不高兴;你千万不能让神经网络在分类的时候;有Ren的;心脏里面有会出问题的;就是说你我;比如说我假设有动态性;那我实际测下来;我自己在自己测没问题;感觉每次都分类正确;但实际上deploy的时候;部署的时候发现有一定随机量;因为我可能长得跟金丝猴就是有点像;它本来两个指很像;但是有一定一定的抖动性;使得我变成金丝猴了怎么办;对吧所以;所以你最好是不要有动态性在里面;
但是反过来讲;你所谓的泛化性就是另外一个东西;就是说所谓的鲁棒性;是说我的假设;我我我我在这里我给我分类;分类正确是人;假设我换一下头或者抬一下头;就变成了金丝猴;那是不行的;这数据有变有干扰;有东西变化时候;我的输入应该是要保持比较稳定的;这个是;我觉得;这个就是要比较重要的一个事情;但这个东西;我们我们这个课不会讲稳定性;讲太多这是一个robustness;是一个比较重要的一个话题;我们会讲一些;就是我们整个神经网络设计都是有;要使得它更稳定;但是实际上稳稳定性是有专门的;现在有一个领域在研究;就还是挺新的一个领域;如果你是想做相关研究的话;我觉得是OK的;而且相对很多来医;医疗无人车稳定性都非常重要;就是说医疗你稳定性没搞好;出人命了;无人车你没搞好;出人命了;
在网络训练中;前几次迭代的训练准确率高于验证机;有什么可以解释的办法吗?
有的;我们会;明天会讲;
在设置隐藏层的时候;会人为固定评估特征的数量;然后再设置层数和单元数吗?
其实这个这个是这个;你会用一个验证数据集来做这个事情;你就说你你;你可以猜;猜完之后你得去试;你真的拿数据去遛一遛对吧;所以这个我们也会讲一下;大概你会怎么样做;调参这个就是调参呐;那调参就是整个是整个神经网络的;机器学习的;整个的一个;就是你数据科学家;80%实验在搞数据;80%实验在调参;
No.2 模型选择+过拟合和欠拟合
一、模型选择
1、预测谁会偿还贷款
-
首先,让我们探讨一下如何选择模型和调整超参数。我们将从一个简单的案例开始,以预测谁将会按时还款为例。假设你是一名银行雇员,负责评估贷款申请者的信用,你获得了100个贷款申请人的信息,包括他们的个人背景和贷款申请情况。
-
在这100个申请人中,你发现有5个人在过去的三年内没有按时还款,即他们违约了。你的任务是找出这5个违约者,因为银行不希望发放贷款给那些可能无法按时还款的人。你需要根据这100个申请人的信息进行评估和预测。

2、发现
-
发现有5个人都在面试时穿了蓝色的衬衫。在美国,蓝色的衬衫通常被视为蓝领工人的标志。不管你的模型是否已经察觉到这一明显的特征,这个问题都存在一定的复杂性。为什么呢?因为穿着不同颜色的衣服是否会影响到模型的决策结果?这看起来似乎是合理的,但仔细思考下来,这种特征其实是不合理的。
-
如果一个求职者在一次面试时穿蓝色衣服,而在下一次面试时穿红色衣服,模型会因此得出不同的结论,这显然不是一个合理的预测方式。模型无法意识到这种变化,并且容易被这种表面的特征所误导。
-
因此,这个问题提醒我们需要在特征选择和模型设计中谨慎考虑,避免让模型过于依赖表面特征,而应更注重深层次的特征和数据分析,以确保模型的鲁棒性和泛化能力。在机器学习中,数据预处理和特征工程是至关重要的步骤,以便更好地应对这类问题。

3、训练误差和泛化误差
-
在处理问题时,我们通常会考虑两种不同的误差:训练误差和泛化误差。这两种误差对于机器学习模型的性能评估非常重要。
-
第一种误差是训练误差,它表示模型在训练数据集上的误差。这个误差衡量了模型在已知标签的数据上的表现,但我们通常不会过于关注它,因为模型在训练数据上的表现并不一定能够很好地反映其在新数据上的表现。
-
第二种误差是泛化误差,它表示模型在新的、未见过的数据上的误差。泛化误差是我们真正关心的,因为我们希望模型能够在现实世界中的新数据上表现良好,而不仅仅是在已知训练数据上。
-
举个例子,如果你参加过高考模拟考试,你可能会根据模拟考试的成绩来预测未来的高考成绩。然而,模拟考试的成绩只是你在已知题目的情况下的表现,它并不一定能准确反映出你在真正高考中的表现。这是因为模拟考试的题目可能是你之前见过的,而真正的高考题目是全新的,你无法提前背答案。
-
如果有两个学生,一个学生(学生A)选择背答案,而另一个学生(学生B)理解题目的解决思路,它们都可能在模拟考试中取得很好的成绩。然而,在真正的考试中,学生A很可能表现不如学生B,因为学生B掌握了解决问题的方法,而不仅仅是死记硬背答案。
-
这个例子说明了训练误差和泛化误差之间的区别。训练误差是在已知的题目上取得的好成绩,而泛化误差是在新的、未知的题目上的表现。我们通常更关心模型在未知数据上的泛化能力,因此这两种误差不应混淆。确保模型在泛化误差方面表现出色是机器学习中的一个核心目标。

4、验证数据集和测试数据集
-
在计算训练误差和泛化误差时,通常会使用两种不同的数据集:验证数据集和测试数据集。这两个数据集的作用和用途经常会让人感到困惑,因此让我们来澄清一下:
-
验证数据集(Validation Dataset):验证数据集用于评估模型的性能和选择超参数。它通常是从训练数据集中分离出来的,用来验证模型在不同参数设置下的性能。例如,当选择多层感知机的大小或学习率时,你可以将一部分训练数据用作验证数据,然后在验证数据上测试不同参数组合的性能。验证数据集没有参与模型的训练过程,因此可以用来评估模型对新数据的泛化能力。
-
测试数据集(Test Dataset):测试数据集用于最终评估训练好的模型的性能。一旦你选择了最佳的模型和超参数,你可以使用测试数据集来评估模型在真实情况下的性能。测试数据集也是从训练数据中独立分离出来的,模型在训练和验证过程中都没有接触过这些数据。测试数据集的目的是模拟模型在实际应用中的表现,因此它是评估泛化误差的关键。
-
-
一个常见的错误是将验证数据集和训练数据集混在一起,这会导致模型在选择超参数时过度拟合验证数据集,从而无法准确评估模型的泛化性能。因此,验证数据集必须与训练数据集和测试数据集严格分开,以确保模型的性能评估是准确和可靠的。
-
总结来说,验证数据集用于选择最佳的模型和超参数,而测试数据集用于最终评估模型的泛化性能。这种分离可以帮助我们更好地理解模型在实际应用中的表现。
-
这里引入一个新的概念,即测试数据集,通常称为测试集。测试数据集在理论上只能使用一次,不能用于调整超参数。例如,可以将其类比为一次考试的成绩,一旦获得,成绩就确定了,不能再次参加考试或者以其他方式更改。另一个例子是在房价预测中,出价的房子的实际成交价格就构成了测试数据集,一旦成交发生,就不可更改。有时,在机器学习竞赛中,会存在私有排行榜数据集,其结果只在竞赛结束后才会公布,一旦公布,排行榜结果就不再改变。因此,测试数据集理论上只能使用一次,用过后不再用于任何调整或验证。之前我们提到将测试数据集用于验证数据集的情况是一个常见错误。
-
然而,实际上,我们通常没有真正的测试数据集,因此在代码中经常将其称为测试数据,但其实它更接近于验证数据集,即验证集。真正的测试数据集应该是全新的数据集,甚至你不知道其标签。我们需要明确这两个概念,尽管在编写代码时,有时会因方便而称其为测试数据,或者人们也常常称其为测试数据,但实际上它只是一个验证数据集。值得注意的是,验证数据集很可能也会导致过拟合,因为超参数通常是在验证数据集上进行调整的,从而验证数据集的性能不一定代表在新数据上的泛化性能。此外,提到在训练数据集上划分50%的数据用于训练,剩下的50%用于验证,但这也会引发一些问题。

5、K-折交叉验证
修改后的段落:
-
记录:一个常见问题是,我们通常没有足够多的训练数据。举例来说,考虑最初的银行贷款问题,假设我只有100个申请人的信息。如果我将其中的50个人用于验证,你可能会觉得效率不高,因为一半的数据都用于验证集了。在实际情况下,我们确实经常面临数据不足的情况。如果直接将一半的数据用作验证集而不参与模型训练,可能会感到浪费。
-
为解决这个问题,常见的做法是使用k折交叉验证算法。这个算法相对简单,首先将训练数据集随机打乱,然后将其分成k块,每块称为一个折叠。接下来,进行k次计算,每次将其中一个折叠作为验证数据集,其余的作为训练数据集。我用一些示意图来说明这个过程,比如我有一个数据集,要进行三折交叉验证,那么首先将其分成三份,然后依次选取一个折叠作为验证数据集,其余作为训练数据集。这样,我们可以获得三个验证精度或误差值,将它们平均即可得到k折交叉验证的误差。
-
通常我们取k等于5或10。这个方法的好处在于,至少使用了66%的数据用于训练,尽管验证集会变小,可能会引入一些误差,但通过多次交叉验证可以弥补。在极端情况下,可以进行n折交叉验证,即每次留一个样本作为验证数据集,剩下的用于训练,然后重复n次,最后取平均值。这种方法可以最大程度地利用数据,但计算代价较高。通常,我们选择k的值,需要权衡训练数据的数量和计算代价。如果数据较大,可以选择k=2或3,如果数据较小,可以选择k=10或更高。因此,k的选择是一个需要权衡的问题,涉及到使用多少数据作为训练集以及可以承受多少次训练的代价。这就是k折交叉验证,也是最常用来调整超参数的算法之一。

6、总结
-
记录:因此,我们在这里介绍了三个重要的概念。首先是训练数据集,这个数据集用于训练模型的参数。其次,我们有一个不参与训练的额外数据集,用于选择模型的超参数。在处理较大数据集时,我们通常采用一种叫做k折交叉验证的算法。这个算法将数据集分成k份,然后进行k次训练。每次将其中一份作为验证集,剩下的作为训练集,通过k次训练得到平均误差,用于评估超参数的好坏。
-
实际应用中,我们通常面临一个数据集,其中有多个不同的超参数需要选择,例如不同的隐藏层大小、学习率等。然后,我们采用5折交叉验证,对每个超参数进行评估,得到每种超参数的交叉验证平均精度。最后,我们选择最佳的精度作为要采用的超参数。这是我们常见的一种做法。这就是第一个概念。

二、过拟合和欠拟合
1、过拟合和欠拟合
- 第二个概念是我们常见的一个现象;叫做过拟合和欠拟合;英语上来就叫under fitting和over fitting;
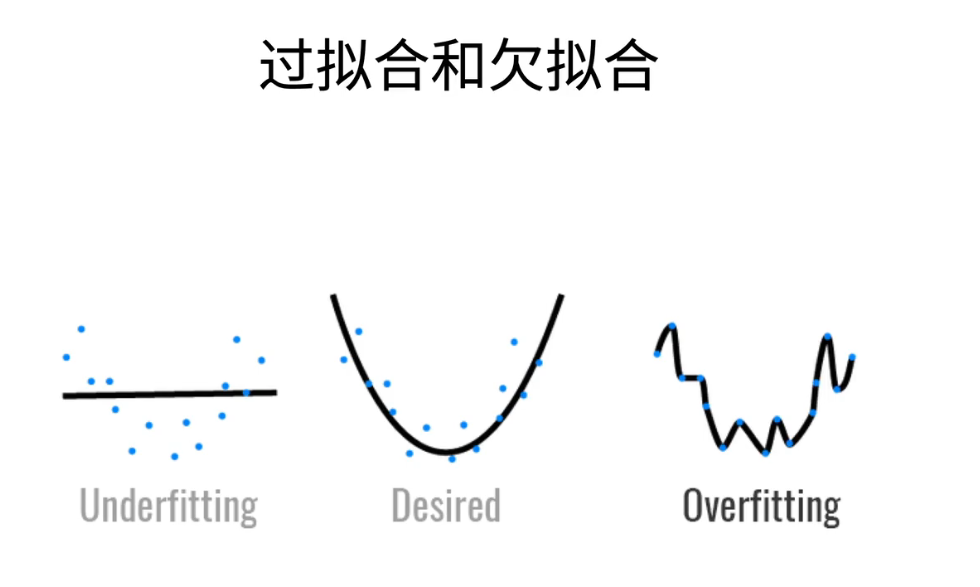
-
在计算机领域,过拟合和欠拟合是两个重要的概念。我们可以通过一个简单的表格来总结它们。
-
首先,模型的容量,也就是模型的复杂度,对过拟合和欠拟合起着关键作用。模型的容量决定了它可以学习的函数的复杂程度。简单来说,高容量的模型可以学习更复杂的函数,而低容量的模型则相对简单。举例来说,线性模型是相对简单的,而多层感知机则更为复杂。所以,模型容量可以分为低容量和高容量两种情况。
-
另一个因素是数据的复杂性。数据可以分为简单数据和复杂数据。例如,人工数据集通常被认为是简单的,而像Fashion MNIST 这样的数据集则介于简单和复杂之间。而像ImageNet这样的真实数据集则通常更复杂。
-
根据数据集的复杂性,我们应该选择相应容量的模型。如果数据相对简单,选择低容量的模型通常能够得到合理的结果。然而,如果数据复杂,使用低容量的模型可能会导致欠拟合,即模型无法很好地拟合数据。相反,当处理复杂数据时,应选择高容量的模型,以确保获得合理的性能。
-
总之,过拟合和欠拟合的关键因素是模型容量和数据复杂性。选择合适的模型容量对于获得良好的结果至关重要。这是模型容量的一个具体定义。

2、模型容量
- 模型的容量是指模型拟合各种函数的能力。低容量的模型在拟合训练数据时受到限制,而高容量的模型可以轻松地记住所有的训练数据。让我们通过一个例子来理解这个概念。假设我们有一些数据点,其中 x 轴表示输入,y 轴表示标签。如果我们要拟合这些数据,可以使用一个简单的线性回归模型,或者更准确地说,一元函数的回归。如果你的模型只是一条简单的直线,那么它无法很好地拟合这个函数,因为它只能表示为一根直线。
- 但如果你的模型容量足够高,你可以使用一个复杂的曲线来拟合这些数据,使模型完全适应数据的形状。然而,这两种情况都不是理想的。在第一种情况下,模型过于简单,不能捕捉数据的复杂性。在第二种情况下,模型过度拟合数据,形成一个不必要复杂的曲线。
- 理想情况下,我们希望模型容量能够恰到好处,以拟合数据的真实形状,如一个合理的二次曲线。因此,当你的模型过度复杂时,它可能会试图过度拟合数据,导致模型不够泛化。要避免这种情况,我们需要谨慎选择模型的容量,以便在拟合数据时取得适当的平衡。

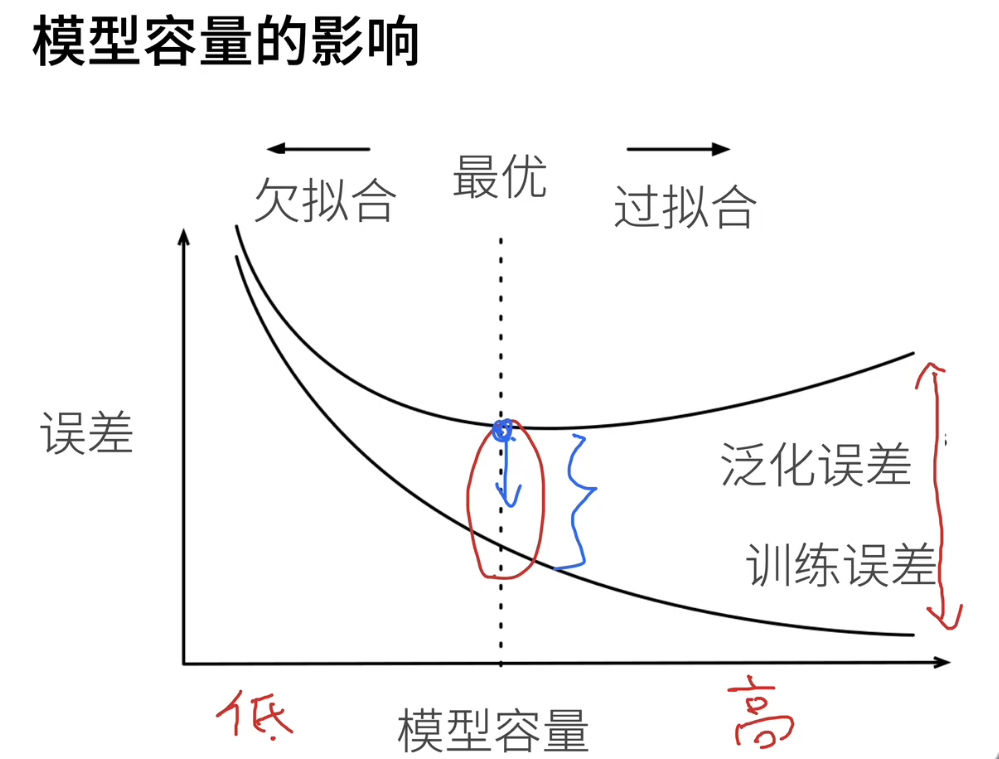
3、模型容量的影响
- 在这个背景下,一个有用的概念是模型容量与误差之间的关系。假设我们将模型的容量表示为 x 轴,其中低容量对应于左侧,高容量对应于右侧。而误差则表示为 y 轴,代表我们在模型训练中的误差,考虑一个中等规模的数据集。
- 在实践中,我们通常会从低容量的模型开始,逐渐增加容量,这也是一种常见的调参策略。当模型容量较低时,训练误差通常较高,因为模型过于简单,不能很好地拟合数据。这也导致了泛化误差的增加。
- 然而,随着模型容量的增加,训练误差逐渐下降,直到可能接近零。这是因为高容量的模型可以更好地适应训练数据,甚至过度拟合。但这并不一定是好事,因为过度拟合可能导致泛化误差增加,尤其当数据中存在噪音时。
- 我们真正关心的是泛化误差,即模型在新数据上的表现。通常,泛化误差会随着模型容量的增加而下降,但在某一点后开始缓慢上升。这是因为模型过度关注训练数据中的细节,导致在新数据上的表现不佳。
- 因此,我们希望找到一个平衡点,其中泛化误差达到最低值。这一点通常表示最佳模型容量。在这个点之前,我们可能会遇到欠拟合,而在这个点之后,我们可能会遇到过拟合。这个中间的差距通常用来衡量模型的拟合程度,即过拟合和欠拟合的程度。不同的问题可能需要不同的模型容量来达到最佳性能。
- 我们的核心任务可以总结为两点。首先,我们的目标是尽量将泛化误差最小化,这意味着我们要找到最佳的模型容量,使得泛化误差达到最低点。
- 第二个任务是要尽量避免模型容量过大,以免导致过度拟合。在实际应用中,有时我们不得不在降低泛化误差和控制模型容量之间寻找平衡。这也是深度学习的本质之一。实际上,过拟合并不一定是坏事。如果模型容量足够大,那么我们可以通过不同方法来控制它,以使最终达到最佳的泛化误差。
- 因此,核心思想是首先确保模型具有足够的容量,然后通过适当的手段来调整和控制容量,以使泛化误差最小化。这是深度学习的核心进程。
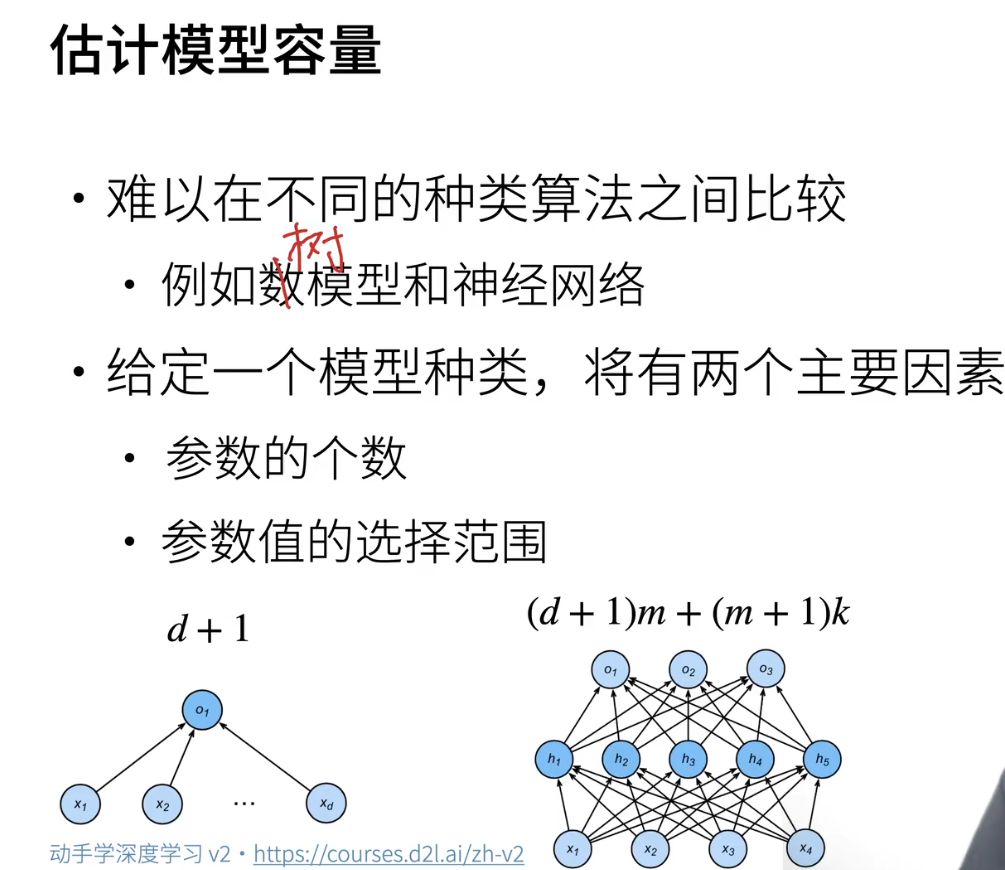
4、估计模型容量
- 实际上,我们可以对模型容量进行估计。然而,在不同种类的算法之间比较模型容量通常比较复杂,例如在树模型、随机森林和神经网络之间进行比较,因为这些模型之间存在显著差异。
- 但如果我们限定模型的类型,通常有两个主要因素可以用来估计模型容量。首先是模型参数的数量,也就是可以学习的参数的数量。以线性模型为例,如果有 d 个特征,就会有 d+1 个参数,其中一个是偏移。如果我们使用了一个单层的隐藏层,假设隐藏层有 m 个神经元,然后有 k 个输出类别,那么参数的数量会是 (d+1) * m + (m+1) * k。可以看出,如果 m 很大,单隐藏层感知机的参数数量肯定会大于线性模型。
- 第二个因素是参数值的选择范围。如果一个参数可以在广泛的值范围内选择,那么模型的复杂度会较高。如果参数只能在一个较小的范围内选择值,那么模型容量可认为较低。
- 总结而言,两个关键因素是参数数量和参数值的选择范围。我们将不断研究如何通过调整这两个属性来控制模型的复杂度。这些属性将在未来的讨论中起到重要的作用。
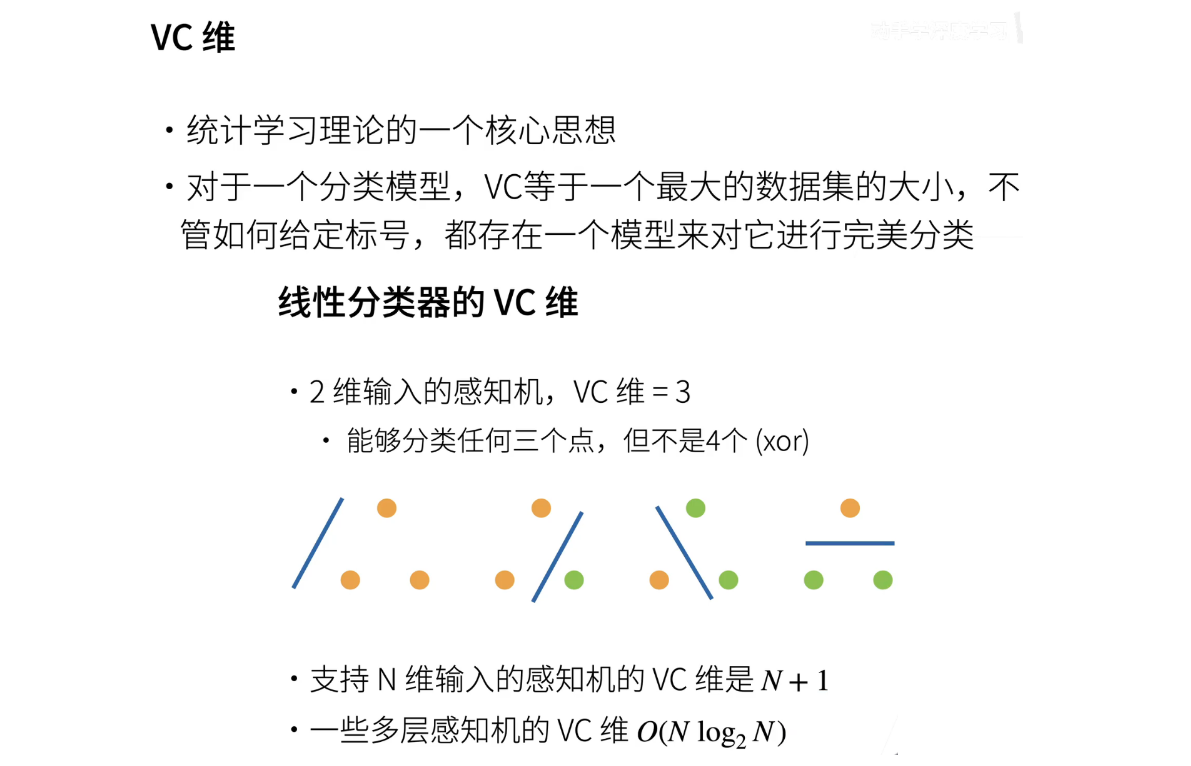
5、VC维
- 提到一些理论,虽然我们不会深入讨论太多理论。其中,我们简单提到了统计学习理论,其中一个核心思想是VC维度(VC dimension)。VC维度的缩写源自发现者的名字,即瓦普尼克。
- 对于分类模型来说,VC维度等同于一个模型能够完美分类的最大数据集的大小。直观地说,如果对于给定的数据集,无论如何标记数据,都存在一个模型和参数设置,可以完美分类这些数据,那么这个模型的VC维度就很高。举个例子,如果一个模型可以对一个包含100张图片的数据集进行完美分类,不论这些图片如何变化或标记,那么它的VC维度较高。与之相反,如果一个模型只能对包含10张图片的数据集进行完美分类,无论标记如何,那么它的VC维度较低。因此,VC维度实际上描述了一个模型能够完美记住多大的数据集。
- 让我们举几个简单的例子。对于具有二维输入的感知机,VC维度是3。这意味着它可以以任何方式分类平面上的两个点,无论它们如何标记。但对于异或运算(XOR),即四个点的情况,感知机无法进行分类,因为需要曲线而不是线性的决策边界。总体而言,支持 n 维输入的感知机的VC维度是 n+1,而多层感知机的VC维度大致为 n*log(n),比线性模型高。
6、VC维的用处
- VC维的好处在于它提供了一种理论基础,帮助我们判断一个模型的性能好坏,特别是通过衡量训练误差和泛化误差之间的间隔。然而,需要指出的是,在深度学习领域,VC维很少被使用,因为它在深度学习中的应用相对困难。这是因为VC维提供的衡量并不总是准确,它主要是一个下界(lower bound)。
- 此外,深度学习模型的VC维计算非常困难。虽然对于简单的感知机模型,在激活函数和结构都相对简单的情况下,我们可以计算VC维,但对于绝大多数常用的深度学习模型,我们实际上无法准确计算VC维。因此,VC维在深度学习中的应用相对有限。
- 总之,VC维是一个理论概念,虽然在一些情况下有用,但在深度学习领域的应用受到了限制,因为它的计算和准确性问题。了解这个概念对于深度学习的学习仍然是有益的。

7、数据复杂度
-
数据的复杂度是一个重要考量,虽然它相对难以精确测量,但我们可以从直观理解出发。数据的复杂度受到多个关键因素的影响:
-
样本数量:样本的数量对数据复杂度有显著影响。拥有100个样本和100万个样本的数据集显然具有不同的复杂度。
-
样本元素数量:每个样本的元素数量也是一个重要因素。数据可以是二维向量,也可以是大型图像,图像的大小会影响数据的复杂性。例如,我们在课程中使用的MNIST数据集是28x28像素的小图像,而ImageNet数据集则包含更大的256x256像素图像。
-
数据的结构:数据中是否存在复杂的空间或时间结构也会影响复杂性。空间结构涉及到图像等的空间排列,时间结构可能涉及到时间序列数据或股票市场预测等。某些数据同时具有时空结构,例如视频数据,具有时间轴和空间轴。
-
数据的多样性:数据的多样性是指数据集中的类别数量。数据集可能包含10个类别,也可能包含100个或1000个类别。这种多样性也会增加数据的复杂性。
-
-
总之,这些因素是衡量数据复杂度的一些关键因素,可以帮助我们大致评估数据的复杂性。然而,重要的是要认识到这些是相对概念。在实践中,通过不断处理真实数据并进行模型调整,您会逐渐获得对数据复杂度的直观理解。这是一个逐步建立的过程。

8、总结
- 最终总结一下,模型容量需要与数据的复杂度相匹配。如果不匹配,可能导致欠拟合或过拟合的问题。虽然统计学习理论提供了一些数学工具来衡量模型的复杂度,但在实际应用中,我们主要观察训练误差和验证误差之间的差异,以获得模型复杂度的实际感觉。这是一个重要的实践过程,帮助我们选择合适的模型容量以适应特定的数据集。


三、D2L注意点代码
后续再看
四、QA
第一个问题是说;感觉SVM从理论上来讲应该对分类;总体效果不错;和神经网络比缺点在哪里?
;SVM的它的一个缺点其实是;首先;SVM它是通过一个 核函数 来匹配我的;模型复杂度的;假设你是用了SVM的话;它其实算起来不容易;就是说SVM很难做到100万个数据集;但是对于多层感知机的话;我们通过随机梯度下降;很容易做到100万;1,000万就是说;就是说SVM当你数据不大的话;几万个点;几千个点;几万个点或10万个点都是可以做的;而且是比较容易解的;但是大的话;就挺难的;这就是SVM的一个主要的缺点;嗯;
另外一块就是SVM的缺点在;于是说他能调的东西不多;就是;反正就是一个很平滑的一个东西;就是说你可以调一些东西啦;比如说 “” 的那个;宽度;或者不同的“” ;但是实际上调来调去;大家觉得好像也没有太多效果;这也是他的;就说呃可调性不是很行;或者说或者反过来讲吧;就是说大家想了解它的缺点;或者;
你可以了解神经网络的优点是什么;神经网络的主要的优点对;我从我这里;这是一个很大的一个观点;我觉得神经网络比别的领域的优点在;于是说它是一个语言;就是说神经网络本身是一种语言;你通过它的语言来;那么也有一些语句;比如说不同的layer;它就是我的里面的一些小工具;然后不同的连起来;我可以写for loop;我可以把它一句一句写出来;就是说神经网络;通过神经网络这种语言;我们对它进行编程;来描述我们对整个物体整个世界;或者整个我们要解决问题的一种理解;这个里面很玄学;就是说它不是一个;不像编程语言一样的;真的就是;我一行一行写下来;很有逻辑性;就是说神经网络;其实是一个比较不那么直观的;但是呢他编程性特别好的一种框架;我可以做很灵活的编程;反正自动求导;把梯度求出来就行了;
所以你相对于说别的机器学习的模型;SVM也好它有很好的数学解释;但是它的可编程性会差很多;就SVM能解决的问题;它会比神经网络会少很多;但是如果纯从分类角度来讲;SVM确实问题不大;除了你scale不上去之外;就是说SVM做image net就很难很难;但神经网络;它确实可以做到很大的数据集;
另外一块我们会讲到;就是说神经网络会通过卷积;去做比较好的特征的提取;就说SVM你可以把它简单的看取;说SVM需要做特征的抽取;和SVM本身是个分类器;在神经网络;其实是说特征的提取和分类;它其实放在一起做了;就一起通过神经网络进行表达;可以做真正的原始数据集上的;一些and to and的一些训练;就我们不展开太多;我们慢慢的会给大家介绍;更复杂的神经网络;大家也会理解;他跟别的机器学习的算法;是什么样的区别;
就第二个问题;其实说我们除了权重衰退;dropout还能不能介绍BN;我们会介绍;BN是Bachelor azation;我们肯定会介绍;模型剪枝;我们distillation;模型剪枝和distillation;其实它你可认为它不是让你做;它其实不是真的给你做;规约就不是让你模型机动;介绍;只是说让你得到一个比较小的模型的;部署起来好一点;我们不会特别的讲部署;但是也许大家感兴趣的话;大家可以留言;
就说训练误差是training的;在training data set上的error;就泛化误差是在testing data set;这是没错的;但是你这个testing一定要解决;说我们经常说test data set;其实是一个validation;data set;就所谓的validation;我们是可以通过它;来去调我们的超参数;但是testing就是说;一定是用完一次就没了;就是我们打比赛;打比赛有一个;有一个;private的leader;leader board就是说大家不会公布成绩;到最后的最后大家一次性公布;然后就定了排行榜;这个是testing the asset或;者是说我训练一个模型;把它真正的部署到实际生产中;看明天的结果怎么样;这个是testing the asset;
所以;严格意义上说;泛化误差;是说在于未来;还没有;现在不在手上的ITA set上的泛化误差;
就是说我说训练;测试验证;三个数据集的划分的比例标准是什么?;如果是比赛的话;不知道测试数据集的分布;怎么设计验证集和验证数据集;有什么指导原则吗?
我们会有一个比赛;就是我们;可能在下周就来;就是我们;这个比赛我可以提前说一下;其其实是一个比较好玩的东西;是说;我给大家去预测我们的房价的卖的;房价的价格;然后呢;我是把2020年的房的湾区还是加州;我都忘了;应该是整个加州的房子给下了下来;然后呢在训练集;其实是应该是1月份到5月份的房子;验证集的;我们的测试集;应该是5月份以后的房子;然后呢我们一个公开的;公开出来的验证集;其实你可认为它就是一个;validation的site;就验证集了;就是应该是6月份到10月份;但是私有的数据集;也就是真正的测试集是后面的;就他确实会有一个分布;就说这里面涉及到一个事情;是说你的测试数据集;很有可能;跟你的验证数据的分布是不一样的;假设我是用过去的数据来训练模型;去预测明天的数据集的话;很有可能这个世界会发生变化;这是一个非常大的一个问题;我们这里没有特别去讲这个问题;会怎么样;这个叫Coverance shift;就说整个分布会发生变化;我们这里;很多时候;你就假设数据是一个独立;同分布的情况下;你的验证数据集;通常来说;就是够大就行了;就没有特别多的区别;比如说经常来说我有一些数据集;我可以选择30%作为测试数据;70%作为训练数据;在70%的数据集上做一个5折交叉验证;就说每一次就拿20%作为验证数据集;然后做5次;这是最常用的办法;
或者是说如果你数据够多的话;那么你可以砍一半;一半作为测试数据;一半作为训练数据;在训练数据上;我还是做k者交叉验证;或者是说;你说对于image net这种做法的是说;我说我有1,000类;我有1,000类;平均每一个类应该是;5,000张样本;还是多少张样本我不记得了;就他的验证数;他的测试数据级或者验证数据级;他的做法是说;对每个类我随机挑50张图片出来;然后这样子的话;那就是;最后得到一个5万的;一个1,000类的话;那就是一个5万大小的;一个验证数据集;剩下数据机全部做为测试;这也是另外一种做法;
问题六;不是用training set和testing set来看overfitting;underfitting吗?
我们等会儿会看一下;给大家演示一下;就是说你其实不应该还是不能;应该叫test set;应该叫validation set;就是说你是用validation来看一下overfitting;
就是说另外一个问题是说;如果持续上;对于持续上的数据集;如果有自相关性;怎么办好?
这是一个挺有意思的问题;就是说你你做股票的时候;你的验证集就持续序列的话;你要保证的是说;你的测试集一定是在去年级之后的;你不能在中间做;那是不行了;就是我要做股票预测;我不能说;我把过去一个月的数据拿出来;然后把中间随机采样一些点来;总结一些天来作为我的验证集;那肯定是不行的;你唯一能干的事情是说;过去一个月的数据;股票数据作为训练集;然后比如说;把中间切一块;就是前一个星期的作为验证集;这个星期以前的作为训练集;这是一般的持续序列的做法;
另外一个是说;验证数据集和训练数据集的数据清理;比如说异常处理;特征构造;是不是要放一起处理?
你应该是要看你怎么样吧;就两种就是说;最简单是说我要做标准化;标准化就是说;把这一数据减去它的均值;除以它的方差;就是你这个均值和方差怎么算;你有两种算法;
一种算法是说;我确实把训练集和测试集;所有的集都拿过来;放在一起;算均值和算方差;这个也问题不大;不大的是说;因为你没有看到标号;你只看到了一些的一些它的值;这很有可能在实际生产中是OK的;
另外一种做法是说;我确实是只在训练集上做;算精算均值;算误差;然后把这个均值和方差作用到我;的验证数据集去;就是说一般来说你后者会保险一点;实际情况下你可以做;你可以看;就是当然前前前面一种会好一点点;就说他对;分布的变化会更加鲁棒一点;所以实际情况;我觉得你应该去看你的实际的应用;假设你在你实际;你要训一个模型去部署的话;你看看你是不是能拿到验证数据;以上的数据;你标号我假设你拿不到;就是你看看能拿不到;能不能;能不能拿到这些验证数据的数据;如果你能拿到;你就可以做;统一做处理;如果你拿不到;那你只能用训练数据集;嗯;
第九个问题是说;深度学习一般训练集比较大;所以k者交叉验证是不是没什么用;训练成本太高?
这个对是是是这样子;就是说;k者交叉验证因为要做k次嘛;就是训练起来比较难;所以在在比较大的数据上;我们很少用;所以我我的前提是说;你做k者交叉验证;是说一定是你的数据集不够;就不够大的情况下你可以做;但是在于传统机器学习;我们一般是做的;
深度学习确实做的不多;因为比较比较贵;
就为什么cross validation会好呢;其实也没有解决数据来源的问题?
而cross validation只是给你选择;超超参数的;它不能解决别的问题;就是数据来源;当然你怎么采样数据;使得它的分布比较好;不要跟去年级和验证集;两个数据长得非常不一样;或者说你怎么采用比较好数据当;然不是cross validation干的事情;这个是整个这一块;是data science要去怎么样去弄数据;就一个data scientist;80%的时间都在都是在搞数据;我们也许也许可以讲一讲;怎么去排排数据;怎么样选择东西;但这里面其实挺挺大挺大一块;就是说可以理解是说;
一共有训练数据及验证数据集;和测试数据集;三种数据集嘛它?
就看你怎么理解;就是说所谓的三种数据集;是说我数据集;其实一个就是理论上说;比如说我做图片分类;我的所有的图片;我所有的图片在一起;比如说1万张;那就是我一个数据集;我会把数据集做分开;不同的数据做不同的事情
k是怎么确定;k最重要的一个;k的确定?
是说你在你的能承受的计算成本里面;你k越大;其实k越大效果越好了;但是你k越大的话;你的计算成本也是线性的增加;所以;你选一个你觉得还能承受的训练的;;代价就行了;
第13;是说模型的参数和超参数不一样吗?
不一样的;模型的参数是讲;w和b里面的那些元素的值;我们整个模型训练量给解决;解决了问题;超参数就是hyperpermeter;是讲你这个模型;我是选用;我是不是选线性模型;还是选我的多层感知机;如果是多层感知机的话;我是选多少层;每层有多大;我训练时候我的学习率选多少;所有那些选择别的就模型;就是说模型参数以外的所;有东西可以我们可以来选的;都是超参数;
cosvalidation;每一块训练时;获得的最终模型参数可能是不同的;;应该选哪个模型?
就其实你cosvalidation的话;你最后报告的是你的平均的进度;但它每一块告诉你的答案不一样;就是你取个平均;这个在统计上是有很多意义的;就大数定理吧;
问题 16是说;所以是出现了overfitting或者under fitting;才需要have a perimeter的training吧?
就是不是training;它其实不是这个意思;就是说;就说所谓的调参;就是要调一个比较好的参数;使得泛化进度比较好;这什么是不好的参数呢;overfitting不好的;underfitting也不好的;所以是说overfitting;underfitting是大概会告诉你说;哪个参数比较好;就是说你调总是要调的;就是说你一般你调一调;就是说;但是你不out;两次你其实你也无法看到;我们等会儿可以直接给大家讲一下;underfitting overfitting到底长什么样子;就是说不是说你出现了才会调;是说这个东西告诉你说;什么样的是好的;什么样是不好的;是这个意思;
如何有效的设计超;超参数是不是只能搜索;最好的搜索是贝叶斯还是网格;还是随机;有没有推荐?
这个是一个挺好的问题;;这个是一大块;就是automail里面有一个大块叫做;hypergrammet tuning叫HPO;我们;这这一块;我们这一堂课;这一节课没有去讲;我也许可以给大家补充一下这一块的;如果大家感兴趣的话;
就是说对面两件事情;一个是说你怎么设计超参数;就是说你到底要我要选;比如说我要10个里面选一个好的;那么这个10个长什么样子;我们昨天有讲过;我们MLP怎么设计;怎么宽一点窄一点;大概多少大;就这个是设计;第二个是说我给你10种;或者一般来;我说我可以给你是一几百;或者上千种做组合;我可以告诉你说;我的学习力可以在0.10.010.001三种选择;那么呢我的;我的MLP我可以一层两层3层三种选项;没乘的话;我可以说;3264128 然后最后你的你是一个乘的;就是说你是3乘以3乘以3;一直乘下去;你一个指数级的爆炸;就是你很有可能设计出一个;超限数的空间有100万种可能;那么说接下来一个问题是说;你不可能把每一个都遍历一次;而你能遍历一次就没问题了;你不能遍历的话;你怎么办;所有的网格就是所有的遍历一次;
随机的话;就是我不能遍历;那我随机的采样做一些东西;或还有可能是做一个在上面;在训练一个模型;我的我的;个人推荐;一个超参数的设计;靠靠专家;的就靠自己的经验;就我们会说;给定一个数据集;我觉得哪样子的模型会比较好;哪样子的超参数比较好;这一般是靠自己来设定;最好不要设太大;也不要太小;太大搜不出来;太小;你有可能错过了很多好的选择;所以这一块目前来看;没有特别好的选项;只有可能自己来设计;我们今后可能会做的好一点;第二个是说;如果怎么样选最好的;搜索有两种做法;一种是;我们昨天说过的;就是自己调吧;就自己试一个;看一看精度;然后再试下一个;然后根据我的上一个;一个是当前的结果;来判断下一个往哪边走;就有点;这老中医;或者是说;另外一个是说;大家我建议就用随机吧;如果你自己不想调的话;就随机随机的意思是说;每一次我随机的选取一个组合;去年一次;看一下;我的验证精度;然后随机个100次;然后最把最好的那一个超参数选出来;就行了这就随机;我推荐用随机;贝叶斯你也可以做;但贝叶斯的话;你得肯定是你得去年个100次;1,000次 1万次;贝叶斯的方法才会好一点;这一块其实很大的;一个一个领域;就HPO;大家可以有兴趣;大家可以再给我讲一讲;我们也许可以做一个专题;来给大家解释一下;
问题18假设我做一个off分类的问题;实际情况是1:9的比例;我的训练集的两个;我的训练集的两种类型;比例应该是1:1还是1:9?
就是说我理解你的意思是说你有个两;份的问题;一类是就是假设你有10个样本;一类是有9个样本;一类是一个样本就是非常不平衡;那你怎么做呢;;我觉得你的验证数据集肯定要保证;是其实都没关系;就是说no;看你多少数据了;假设你数据很多的话;你就是就随便了;就随机;就随便砍一刀都可以;假设你的数据集不那么大的话;那么我的建议是;你的验证数据集上最好是;两类都有差不多样数的多;嗯;原因是说;假设你是;;不然的话;你做的不好的话;那很容易是说;我就是;那我如果是因为这个对分类器来讲;我很容易是;我就怕你所有东西都给正类;假设正类是多的那一类;那我就所有的分类序;不管谁我都给你判正类;那我的精度是90%;那你可能就是从数值上来说哎;我这个我这个模型器90%精度挺好的;所以那么你对于那个小的那一类;你就会忽略掉很多事情;所以你把验证级;你把验证数据集把它平衡一下;那么你至少是50%的精度;对吧在验证数据集上;也也可以避免;是说;你的模型太偏好于多的那一类;你有很多种办法;你可以通过加权重来避免这个事情
问题19是个很好的问题;就是说;k者交叉验证的目的是确定超参数吗;而且用这个超参数再训练一次模;全数据吗
这个问题挺好的;就是说你有两种做法;一种做法是说我的k者交叉验证的;只有n种做法了;第一种是;怎么做呢;第一种;就是你说的那一种k者交叉验证;就是来确定一个超参数;确定好之后;我在整个数据集上;再全部重新训练一次;这个是;几乎是你最常见的一个做法;
第二个做法是说;我不再重新训练了;我就把k者叫他验证中的那一个;选定那个K3 选;选定好的那个超参数里面找出;随便找一个一折里面的那个模型;或者是说找出那个进度最好的那一折;我们的模型拿出来;那你的代价当然是说;你的训练的模型训练可以少一点点;要你的少看了一些训练集;
第三种还有种做法是怎么做呢;就是;你要是把k者交叉验证的k个模型;全部拿下来;然后真的做预测的时候;你把一个测试数据集;全部放到这个k歌模型;每一个都预测一次;然后把它的预测结果去均值;这个其实是一个不错的选择;但是他的代价是说你你的预测的时候;你的代价是变成k倍了;你之前你再过一遍;但现在你要过k遍;但是你的好处是说;这样子能增加你的一些模型的稳定性;因为你做了一个voting;
问题20:validation出现的误差是什么?
误差就是validation误差了;就是验证误差;
问题21为什么SVM打败了多层感知机;后来深度学习又打败了SVM呢;;
简单来讲就是说;它简单来讲它不是打败;是流行就是说你会;你会发现整个学术界;它其实是一个你可以认为是;一个时尚界大家都是赶时髦;然后SVM打败了多层感知机;是两个原因;一个原因它确实比较简单;但它比SVM的精度;并没有比多层感知机要好;但它不那么要调参;这是它的第一个好点;第二个是SVN;他有数学理论;有人推;就是大家就火了;然后深度学习又打败了SVM;就是深度学习打败了SVM;是那就是深度学说我没理论;没理论不要紧;我实实际效果很好;我在image net上拿第一了;我们会之后会讲;这个这个故事;就是说SVM你你;其实在之前image net的冠军都是用SVM的;然后深度学习说;Alex net出来把SVM进度高了很多;那就是实用性更好;另外一块就大家说;也不要太纠结这个事情;这个这个学术界嘛;就是一波又一波的;今天我们深度学习火;火了几年了吧;我们再讲深度学习;可能三年之后;五年之后说不定就不火了;
所有的验证数据上的loss;都是这种先下降后上升的吗?
所以这个这个是;我知道这个东西一定会很很很误解;就是说我们有讲过那一条线;就说验证数据集上的那个验证误差;是往下我给大家讲一下这个东西;我觉得挺挺容易;我讲的时候;我会觉得是;可能会大家会有一点点误解;就这个东西;这个东西首先;x轴是模型理解吗;;就这个东;西是一个模型;就每一个点是一个新的模型;不同的模型;这个比如说是MLP;呃这个比如说是一个MLP1;就是一个最简单的那个MLP;这个可能是一个很深很深的MLP了;这是一个简单MLP;所以我们网上的图;我们的记事本的图;这个图不一样;我们记事本的x;是我的数据的迭代次数;我是一个模型;就是我是一个;我们的网上图是这样子的;我是x是epoch;我数就是讲一个;我们的误差是一个这样子的;这是说我这个模;一个模型在通过不断的学习过程中;我会发现它的误差往下降;这一个点是表示;我给你换个线;这个点;最终这个点会对应到一个这样子的点;我还可以画一个别的;一个这样子的模型;对吧画一个点对到这个地方;就是每一个点是不同的;模型所以你就是;所以就是说你不同的模型;它会有不同的区别;是比较模型用的;它不是一个模型的;训练的那个进度的误差;OK;
模型的容量一般指的是什么?
模型容量就是;就是模型能够拟合函数的能力了;
随机森林在深度学习有常见的用吗?
深度学习有一些做随机森森林的东西;但是它不属于深度学习;我们一般来说特指神经网络这一块;确实是有把神;随机森林做到神经网络里面;但是它的最大的bug是说;随机森林的训练;它不是通过梯度下降的;所以你不好做joint training;所以我们用的也有用;就是说一般来说常见的应用是做enzomb;我给一个数据;我给一个数据;我训练一个随机森林的模型;我再训练一个别的模型;我再训练一个深度学习模型;n个模型;最后做;做average来投票;这是常见的做法;但是把随机森林结合进深度学习;做的比较少;主要是;你那个梯度不好传;
做KK则交叉验证的时候会训练k次;这样子;k次训练出来模型能不能融合在一起;会不会比单个模型有更好的表达能力?
有的;就是我们刚刚有讲过;就是说你有k个;然后做去做测试的时候;我进k个里面;就是5个里面进5个模型;然后把所有的预测的结果做平均;这样子;我的结果可能很有可能会好一点;;还有更更更奇葩的做法是说这个;其实Google他们经常干的事情;为了打比赛;我同样一个模型;然后记记不记得我们是我们;这个模型是有我们的权重的;初始是随机权重的;那我就把这个模型训练5遍;就每一次;用不同的随机值来初始化模型;就得到5个模型;最后做enzombo;就是做average;也效果也挺好的;
标号是什么;标注标号的标注是一个叫label;我经常我中文;其实我也不是那么清楚;反正我也经常混着用;标号标注;label哈哈;就是一个东西;
拥有无限维的算法是什么?
;无限维的算法多了去了;嗯;无限维;其实正常的深度学习的模型都是;都有可能;是无限维的;就是说;你如果不做;就说不做;它的限制不做;比如泛化呀;不做;正则化呀;不做;那些东西很有可能就是无限维的;
k者交叉验出;训训练出来k个模型;最后选择物;验证误差最小的模型嘛?
你也可以这么做吧;就是说我们有提过;你可以选择误差最小的;或者是说;你在整个数据上重新训练一遍;或者每个都做好都可以;
就VC衡量的好坏;没有听懂?
;这个东西我们不特别展开了;就说VC为;就尽量的简单认为是;说我一个模型;我能记住的最大的数据集长什么样子;就是说我给你一个 100;比如说100个样本数据集;每个数据集的样本是;1,000枚的话;那么假设我能记住这个数据集;而且不管你数据集怎么怎么怎么;里面的结果是什么样子;不管是怎么样子;我都能记住它;那么就VC维等于;正好是大于等于100吧;就是说;你就是说你判断一个模型的;capacity的大小的;就是说我能记住多复杂的数据几;就一个人的记忆能力的好坏;我能记住;比如说我记;举个不那么确信的例;确定的例子;就判断一个人的记忆力的好坏;那就解解释;你能记住;比如说圆周率能记100位还是记10位;假设你记100位;那你的VC咱们剩是100;假设你能记10位的话;只能记10万;那就是10;那么当然;记100的记忆力比你记10的好一点;或者是说你记单词你最多能记多少个;记1万个;那么你就with dimension one;那比只能记100个人的话;你的记忆当然会好一点;就可以简单这么理解;OK;我们在这里;我觉得这个就是一个概念上的东西;我们确实;多花点时间搞清楚是没问题的;还有那么多;
嗯k者交叉验证;是第一次放完后就确定分组了吗;如果每一次都随机打烂数据;取出k n分机做验证是另外一种方式;嗯有没有区别;还是说一般来说差不多呢?
就是说一般来说;我们是;做k者的话;一般就是给一个样本;随机打乱一次就把它切好;就不会下次不再切了;你可以说;你可以随机;你下一次可以随机打乱;打乱这个叫backing;它其实跟k者;驾校认证是有一点不一样的地方;就是你可以随意打乱;这个没关系;其实你做back in就是了;做back in的;大家一般做back in的这种做法是说;我就是为了真的;最后就是为了得到k个模型;这样子我做;平均预测;这是大家常见的一种做法;
就说神经网络是一种语言;它是利用神经网络对万事万物见为;就是它理论能力和所有的函数;其实我还不仅仅是讲这个东西;我其实讲的;嗯;我其实是说;理论上来说;你的单层;单隐藏层的MLP能拟合所有的函数;理论上它能拟合所有;不需要我们就基本上昨天就讲完了;理论上;实际上不是的;实际上你你训练不出来;就是说;就是说我觉得就是说;等于是说;我觉得我能做到这个事情;我觉得我;但是我就是实际上我就做不到;成绩做不到;对吧;所以说所有的神经网络;最后的最后;你去cn也好;RN也好什么东西都也好;他其实说我知道MLP能理和你;但是MMLP基本上训练不出来;那我要做一个比较好的结构;使得尽量帮助你来训练;比如说cn尽量的说帮助是你网络好OK;cn它本质上就是一个MLP;本质上没区别;我都给大家讲它是做了一些限制;就把一些等于是一些wait给你;固定住了;就是说我通过设计cn告诉你设计网络;说我觉得这个数据有空间信息;这样子呢;我来告诉你说;你去这样子去去处理这个空间信息;叫RNN也是一样的;我觉得这个数据叫持续信息;我告诉你说;这个东西这么走这么走;这么走来来做这个持续的信息;就是说;整个东西;就是说整个深度神经网络;就是说我是通过神经网络;尽量的去用它的秒的方法;来去描述这个;这个数据的特效;使得你训练起来更好;训练一些;就是你可以;那么是这个意思;就是说所谓的就是说;总结来讲;就是说我通过审计网络;来来描述我对这个问题的理解;但很多时候你就是试一下;很多时候;其实说白了就是你拍拍脑袋;拍5个脑袋;试一下;有发现一个想法不错;然后把它写出;来然后在上面再随便找个理由;但是真正的好的就是;你会发现很多这样子的经典的论文;他他确实效果很好;但是他一开始找的理由都是错的;就是说;所以说嗯;所以神经网络很多时候;扯远一点就是;
就是说;剪枝和蒸馏是可以提高模型性能吧?
;是;就是看你怎么说吧;比如说真正的destination;就是把一个复杂的一个网络;把它变小;使得他的能力跟复杂的网络经量一样;但你看你怎么说;就是说它比对你这个小模型;它比同样另外一个小模型;直接训练出来的小模型可能会效果好;是是提升精度;但很要对你对复杂;对你那个大的开始的复杂模型来说;你的小模型可能精度还会低一点;所以是说;你看你从哪个角度来讲是性能提升;;
就同样模型的结构;同样的训练集;为什么只是随机初始化不一样;最后的集成一定会很好?
所以因为就是说这里;这里要涉及到另外一个概念;一个很大的概念;一个叫统计学;一个叫做优化;就是说我的模型是一个统计学的模型;我的优化是一个数值优化;所以你最后的模型是统计模型;就是模型的定义;加上你怎么优化的结果;就假设模型一样;还就统计模型是一样的情况下;通过随机初始化不一样;最后得到的结果不一样;就是我随机出;就优化就是;反正我就是从一个随机点开始;往前走一走;走一走然后呢;你这个平面够复杂的话;就说你在一个很复杂的山里面;我把你随机丢在一些地方;你每次随机走一走;可能走的地方都不一样;对吧;但是说;所以你你这样子不一样的话;最后的集成都一定会好;不;就一般来说统计上来说会好一点;就是说你每个模型都有一定的;就说你模型都是个;就模型都是个偏的;就模型都是个假的;就模型都不能拟合真实的世界;就说模型都是有一个偏移;偏移是固定的;但他有个方差;就方差是我每次优化或者什么样之后;有一点噪音在里面;我通过做n个模型;把它做放在一起做;做均值我能降低这个方差;这样;你这个方差很有可能会提升你的精度;就他最后没有把模型的偏移给做掉;就是模型他就是不是那么好;就还是不是那么好;但是说每一次训练;因为我都没有拿到这个模型的最好解;就是一个随机减速;所以我做n次的话;我能够降低一些一些呃方差;
问题33数据集中的噪音比例多少;最好还是清清楚所有噪音;这个东西;你数据集的噪音;你当然希望越少越好;只是说我们现在是;我们现在是做人工数据集;就给你加一点噪音;所以当然是清除;实际数据来说能清除噪音最好;我们只是说给一点;我们现在是给点人工数据集;给大家演示一下;所以加一点噪音;如果训练是不平衡的话;是否先考虑测试机也是不平衡的;再是否决定使用一个平衡的验证机;;对;就是说但是你的我觉得正常情况;就是说;你可以不平衡;但是你应该让通过加权来使得它平衡;就是说假设我有两类;还是前面那个例子;假设一类有90%;相反一类就是10%;那么你要去看;你要去想的一个事情是说;一;我是不是真实的世界中;我就是90%的是这样子;10%是那样子;如果是的话;那么你就是应该把主流的做好;对吧把那90%的做好;10%的话尽量做好;所以如果是这样子的话;是没关系;反过来讲;如果你现在这个情况;只是因为你采样没采样好;就是说你觉得那个10%其实挺重要的;只是说你这个数据几;你没有把它那个东西都拿过来;这样子情况下;你就是应该把那个10%;那个小的那一个东西的权重提升;最简单说;你把那个10%的样本全部复制10遍;那就变成1:1了吧;复制9遍吧;变成1:1了吧;就说你你;你不复制的话;你可以通过在lost里面加权;使得他给他更大的权重;小的类给更大的权重;问题35;在训练的时候XOR是迭代次数;在验证数据级上;也会发生这种先下降后上升的;那不是错误;那就是过;敏核;那就是你;你的验证数据级会下降;再上升那就是发生过拟合
No.3 权重衰退
一、权重衰退
1、权重衰退
- 权重衰退;这个叫做weight decay;是我们最常见的来处理过拟合的一种方法
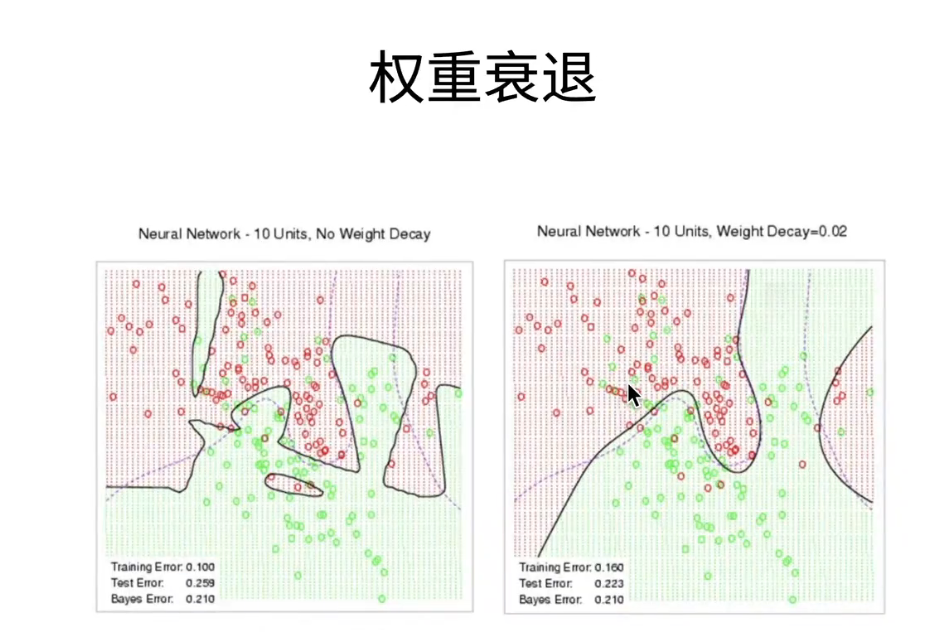
2、使用均方范数作为硬性限制
-
当需要控制模型的容量时,有两个主要方法:
-
减小模型大小:这意味着减少模型的参数数量。您可以通过减少网络层的大小或减小隐藏层中的单元数量来实现。减小模型大小有助于减小模型的复杂度,但可能会降低其性能。
-
权重衰减(Weight Decay):这是通过限制参数值的范围来控制模型容量的一种方法。通过引入正则化项,可以限制权重参数的范围,使其不会变得太大。这通常通过添加一个正则化损失项到损失函数中来实现。
- 具体来说,权重衰减通常是通过以下方式实现的:在最小化损失函数时,引入一个限制条件,使权重参数的L2范数小于某个特定的阈值(通常用θ表示)。这意味着每个权重参数的平方和都必须小于θ的平方根。通过选择较小的θ,可以增强正则化效果,从而限制权重的值,使其不会太大。
- 通常情况下,不会对偏移项b进行权重衰减,因为偏移项通常对数据的整体平移不敏感。在实际应用中,通常不限制偏移项b。如果需要,可以将b包括在权重衰减中,但通常对最终结果的影响较小。
- 需要注意的是,选择θ的值会影响正则化的强度。选择较小的θ将导致更强的正则化,而较大的θ将导致较弱的正则化。
-
总之,控制模型容量的方法包括减小模型大小和使用权重衰减来限制参数的范围。这些方法可以帮助防止模型过拟合,提高模型的泛化能力。

3、使用均方范数作为柔性限制
- 对于每一个θ(比如θ等于0.1、0.01等),我们都可以找到一个数,用以替代之前的目标函数。这新目标函数不再包含之前的限制项目,但在整个目标函数中添加了一个二分之一的数值。而且,我们对w进行了L2正则化。这一点可以通过拉格朗日乘子来证明。因此,可以证明,通过优化整个目标函数,与之前添加的硬性限制是等价的。
- 之前的硬性限制本质上将w限制在某个数值内。然而,通常情况下我们更常用如下形式的目标函数,即我们的原始损失函数加上一个新的项,通常称为惩罚项,以防止w变得过大。Lambda是一个超参数,控制了整个正则项的重要程度。当number等于0时,这个项实际上不起作用,等价于之前的θ等于无穷大。随着number逐渐趋向无穷大,等价于之前的θ趋向0,导致最优解w*逐渐趋向0。因此,如果要控制模型的复杂度较低,可以通过增加number来满足这一需求。这便是柔性限制的概念,与之前的硬性限制相对而言,更为平滑,有点类似于Photoshop中曲线的调整。

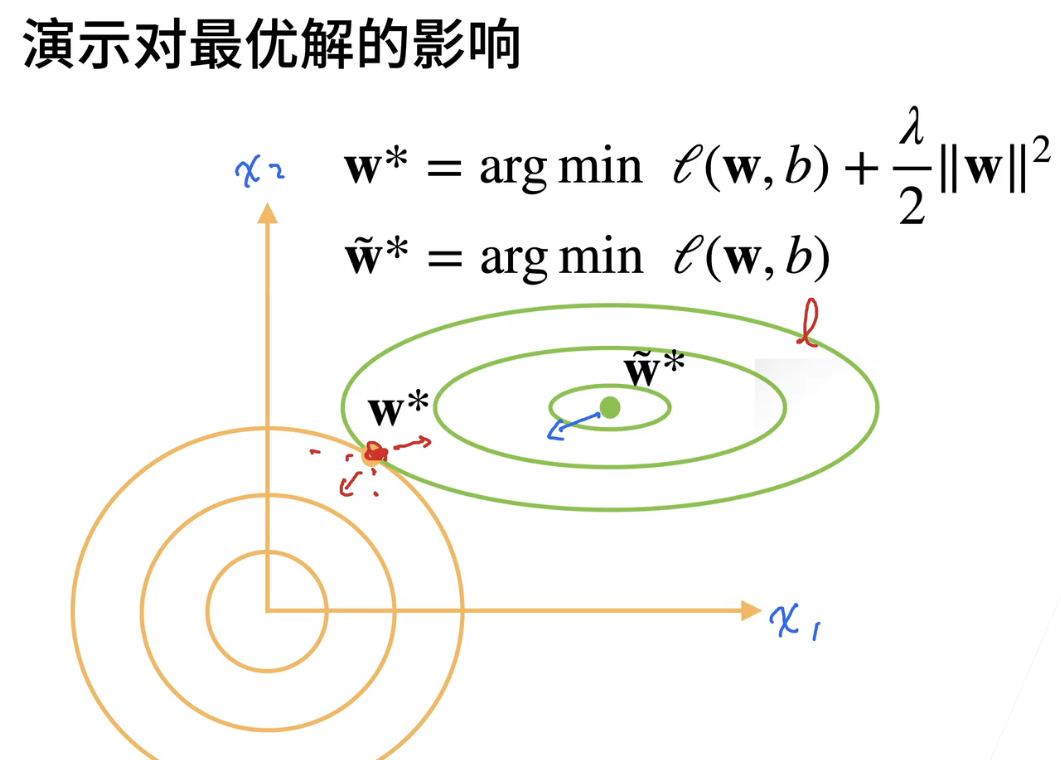
4、演示对最优解的影响
- 让我们来仔细分析一下。首先,我们假设有一个损失函数L,这里我用绿线表示损失函数的等高线。如果我们想要优化这个损失函数L,最优点位于W的波浪号形状附近。因为L是一个二次函数,所以它的最小值位于中心。
- 现在,如果我们添加一个二分之一的number项,这个项也是一个二次函数。在这个函数中,我们可以看到W有两个值,X1和X2。对于W的二次项,你可以认为它是以原点为中心的一个等高线,呈现出这种形状。
- 然后,我们观察一下原始的最优解点,这个点现在不再是一个特别好的解了,因为它在损失项L(用黄线表示)中的值变得非常大。如果我们沿着这个方向前进,损失项L的值会变大,但我们的number项值会变小。请记住,在损失函数L2的损失函数中,当我们在优化点附近时,梯度相对较小,所以对值的改变相对较小,但在远离原点的地方,梯度大,对值的改变较大。
- 因此,在这个点,number项对它的拉动作用会比L大,这意味着我们将它往下拉。例如,我们可能会拉到这个点,形成一个平衡点。如果你继续向下移动一点,损失项L会说:“你的减小项不足以弥补我的增加项。” 如果你向右移动,因为number项的增加项比L的损失项更大,那么在这个点会形成一个平衡点。总的来说,引入number项使得W向原点移动,对于值来说,这两个点的值会变小。一旦值减小,如果我们将number项往右拉,整个模型的复杂度就会降低。
- 这就是如何理解我们引入这个number项,它对整个损失的影响,尤其在柔性限制下,是如何影响的。
5、参数更新法则
- 接下来,我们来详细解释一下参数更新的法则,以了解为什么它被称为权重衰减。
- 我们回顾一下之前我们是如何计算梯度的。现在,我们有两个项,一个是损失项L,另一个是权重项。在这两个项中计算梯度时,首先我们对第一个损失项L计算梯度。接着,对权重项进行梯度计算,因为它是一个二次函数。所以,首先平方项被消除,只留下了一个W,然后2和2相互抵消,最终变成了一个number加上乘以W。现在,让我们理解在时间t的更新。这可以写为WT(时间t)等于WT(时间t-1)减去学习率at乘以这个W项。
- 接下来,让我们把这个公式代入。首先,这个项a乘以number和W会保留在这里。然后,a乘以number和W将合并在一起,变成1减去a乘以number。这是与以前的更新不同之处。唯一不同的地方在于多了一个这样的项。我们不希望将它画在减号上,因为那会让公式变得模糊。这个项是维度项,如果你没有引入二次项,这个项是不存在的。通常情况下,我们的λ(lambda)乘以学习率是小于1的,如果大于1,会导致抖动较大。一般来说,它会小于1。
- 所以,你可以看到与以前的区别在于,减去梯度的负方向乘以学习率没有变化。主要的变化发生在这个地方。每次更新时,我们首先将WT乘以一个小于1的常数,即将其值稍微降低一些,然后再朝着梯度的反方向前进一些。因此,为什么这被称为权重衰减呢?因为在每次更新时,由于引入了number项,我们会首先略微减小当前的权重,所以可以看作是一次衰减。这就是为什么我们称之为权重衰减的原因。

6、总结
- 这段文字总结了通过权重衰退来控制模型复杂度的概念。通过L2正则化政策,希望模型参数不会过大,从而限制模型的复杂度。在优化过程中,我们使用一个超参数来控制正则化的强度。这个超参数在每一次权重更新时都会将权重值缩小,因此它实际上导致了权重的衰退过程。Lambda是控制模型复杂度的超参数。

二、D2L代码注意点
三、QA
第一个问题是说;现在pyTORCH是不是支持复数;神经网络;也就是它的;都是复数;LOFT是一个复数到实数的映射?
这个我觉得应该是不支持的;复数我觉得应该是不支持;但是你复数的话;因为复数说白了就是两个;就是两个;把一个数变成两维嘛;你其实可以通过;把它做到两维;就加一个第二维来实现你要的效果;就是你必须一定要搞到复数;
第二个问题是说;如果;为什么参参数不大复杂度就低呢?
它其实不是说参数不大复杂度就低;就是说;我限制你整个模型在优化的时候;只在一个很小的范围里面去去参数;就说如果你在比较小的范围去参数;那么你的整个模型就不会;你的空间就会变小;举一个最简单例子;其实我们有一个画了一个很小的图;但我没有解释的一个图;就是这个图就这个图;那用笔;就是说如果你我要你和这些点的话;这些红色点的话;如果我可以允许我的模型;参数选的比较大;我可以做一个任何的;一个很复杂的一个曲线;使得他你和;就说在模型同样是二次模型;或者三次模型情况下;假设我的权重可以取得很大很小的话;那么;可以造成一个非常不平滑的一个曲线;那么现在是说;我限制你这个weight不能换太大;就是说;你只能在一些比较平滑的曲线里面选;我不让你学;我不让你去学;特别大的一些曲线;那么就意味着是说你的模型;复杂度就变低;就说你选不出特别复杂的模型;如果只要你选择比较简单的模型;是这个意思;
如果是用L1范数的话;如何更新权重?
如果是L1的话;其实你一样的更新;就是说;大家可以试一下;这个是一个很好的练习题;就是说;你就你就把那个之前那个呃;就是;这个地方;你就把它换成一个呃;换成一个touch ABS吧;对吧;然后就换了个东西;然后然后这个就不要除二了;那就当然你这个东西得改成l one penalty;对吧;就大家可以试一下这个;改一下这个东西;一定大家去试;你不要看到我试看;我试有什么用哎;你自己去试一下;看看效果怎么样;很有可能效果差不多;在这个在这个问题上;但是我绝对鼓励大家去;手动试;我只是给大家演示一下就正常怎么做;这里面代码是什么意思;但是说给大家看代码的主要的目的是;大家可以拿去自己玩;
对实际中的权重衰退一般取多少呢?
;其实一般取个一般是取;一;一般是取1 -3 1 -4;就是说;1 -2 1 -3 1 -4就0.010.0010.0001;就是那么几个选项;
之前在跑代码的时候;感觉权重衰退效果并那么好?
;其实群众衰退效果有一点点;但你不要太失望;我们会在之后再介绍更多的手段;给大家来做;模型复杂度控制;权重衰退;确实他就那么一点点效果;所以很有可能你稍微调一下体;一般来说你取个1;-3也就行了;就是你不要觉得;如果就是说如果你的模型真的很复杂;权重衰退它不;会给你带来特别特别好的效果;可能你;特别是对于什么MLP来讲;可能之后我们接下来我们要讲的;drop part可能效果还好一点;所以就是说大家;我就建议大家可以试1-21-3;或者说你就默认开着1-3也就行了;如果效果不好;你就换别的方法;
就是为什么损失函数正则项中的2;为什么使用的是上标而不是下标?
;就是说我在想;你所谓的上标;是讲我这个是怎么写的是吧就是说;就我其实就是说;你说我为什么用的这个地方;这个是个上标是吧;这个上标不是;这个上标是是个平方的意思;就说;其实理论上这里应该有一个下标;我就是偷懒没写了;就这才是l;l too long;就是表示你这是个l to的一个范数;但是呢l two是以默认的范数;所以对项链来讲;l two就是默认的;所以你这里不写是没关系的;就是我只是把它忽略掉了而已;这个平方呢;这个东西不是讲是l two的;项链是是个平方项;就是说我们这里用的是l to;就是l r的那个范数的平方;作为我的发;所以这个2是平方;不是l;to那个里面那个2;OK;
就为什么会要把w往小拉;如果最优解的w就是比较大的数;那么权重衰退是不是;有反作用?
这也是个挺好的问题;就是说;就我还是回到之前那个图;就是说大家一定要理解这个点;是说假设;假设我的;假设这是我的最优解;真的是我真正的最优解;就是说但是你实际上来说;你的数据是有噪音的;就实际上就是说实际你学的时候;你不会学到这个点;你学不到这个点;就这是你的假设;你是你真正最优点;但是你在学真的去学数据;学的时候;因为你没有噪音;所以你的;你学的东西;可能在这个地方可能学的特别大;就你可以看到我们之前那个代码;我们真正的最优解是0.01W;但我们如果不加l two的话;我们学到的是一个特别大的一个;我们的l two long大概是1112啦;那就是根本就学到一个过大了;那是因为;我们的算法看到的是造影;他试图去他;只要模型允许的话;我就会去不断的记住我的选一个;选一个权重;记住我所有的样本;那就是说;那就会尝试记住我的造影;记住那些抖动的东西;他就会学到一个特别大的地方;这就是你真正的学到的;如果没有的是学到的;然后呢;所以你的l初衷就会把这个东西;你如果没有它的往往回拉;就你要通过控制你这个number的大小;来控制number大小来说;你要往回拉多少;就是说假设你number过小;那么你可能就拉到这个地方;你拉到这个地方不够;还是太大了;就number太小;但是如果你number;太大的话;你有可能拉到这个地方;对吧number太大;所以这个地方是说你合适的那么大;可以把你拉到这个地方;所以就是说这里我们写的是最优解;数学的最优解;实际求解;我们求不到最优解的;因为你数学有噪音;所以是说number;就是说处理你的噪音;假设你没有噪音的话;那你就不需要number;你根你就不会;就不会去;overfit到一些奇怪的地方;但是因为实际有噪音;所以这个就是它的原原因;对就;
第七个问题;其实跟之前一样;就是说它是让w值变得更平均?
它其实也不是;它不会让你变得平均;就是往小里拉;就是说防止就当你没有number;你的学的的w是变得很大的情况下;加入这个东西;你就会往回拉;就它不也不是万能的;假设你没有;你的模型;没有去overfit的话;你那你老往回拉是没用;就为了DEK;一般有什么选择;就是反正之前讲过;就是你;1-3吧 1-2吧;1-4吧反正是这么三个选项;选选有效果就行;没效果换一个;换换别的方法;反正那个东西;试起来挺简单的;
就是说作为number达作为一个超参数;是怎么样;调优的那其实是说;就我们也讲过;上一次有讲过;就是说你用;验证集加上;比如说key者加查验证;就是说你去看;就是说;确实你你不知道什么时候是最有;比如说最简单的情况;你就是假设number等于0;你试一下;最最后的验证的精度长长什么样;或者你看一下我们之前那个曲线;我们之前那个代码;也多多少少有点调参的异味在里面;就你看一下你那个训练的线;和一个;测试获得验证者的那个嵌之间的差距;如果你发现那个差的比较大;那么你就把number的0的;如果说你发现差的比较大;那就把它往高调一点点;就调个1-3吧;一-3如果你确定有一定效果;你又渴了;你可以再往上调一点;调个一负2;如果没有效果;那就那就这样吧;那你就留在一-3没事;或者你就觉得一负3有一定效果;你不调了也没关系;就是说;那么呢反过来讲;就是说不会有特别特别大的用;但是呢;会有有那么一点点好处;
就说在解释噪音数据的时候;如果噪音越大;w就会比较大;这是经验所得还是可以证明;噪音越大的时候;你的你;这个可以试一下;这个是可以证明的;这个东西确实是可以证明的;但是我们这里就不讲;你可以试一下嘛;你就就很简单;就是你就是拿这个demo跑一下;你就把噪音调高一点;看看你学的w会不会变大嘛;对吧;;
No.4 丢弃法
一、丢弃法
1、丢弃法
- 接下来,我们要讨论另一个非常重要的概念,它被称为"丢弃法",又被称作"Dropout"。这个方法在深度学习的崛起中扮演了一个关键的角色,并且可能会比我们之前讨论的解决过拟合问题的方法更加有效。下面这张图是关于高中毕业率(dropout rate)的图示,这里的"dropout"指的是学生辍学的比率,与我们即将讨论的Dropout方法无关。

2、动机
-
丢弃法(Dropout)的动机如下:我们希望构建一个鲁棒性强的好模型,它能够应对输入数据的扰动。假设你看下面的这个图,里面的盔甲代表了你的模型,无论输入数据加入多少噪音,甚至噪音增加到最大时,你的模型依然能够清晰识别。人类对于这些噪音的抵抗能力也是相当强的,不受干扰。现在,将带噪音的数据用于训练等同于引入了一个正则项,通常称为"T正则"。正则化是一种方法,通过它我们约束权重不变得特别大,从而避免过拟合。所以在数据中引入噪音就相当于应用了正则化。不过,与之前加入固定噪音不同,现在我们添加的噪音是随机的,这就是丢弃法的思想。
-
丢弃法的具体操作是在网络的不同层之间引入噪音,而不是在输入数据上添加噪音。这就是丢弃法的核心思想。需要注意的是,丢弃法本质上也是一种正则化方法。

3、无偏差的加入噪音
-
在丢弃法(Dropout)的概念中,我们的目标是向输入数据 x 添加噪音,以获得新的数据 x’。尽管我们引入了噪音,但我们仍希望新的数据 x’ 的期望与原始数据 x 保持一致。这是我们唯一的要求。
-
具体而言,对于输入 x 中的每个元素 x_i,丢弃法将以概率 p(0 到 1之间的值)将其变为零,同时以概率(1 - p)将其除以(1 - p)。这样一来,以概率 p,元素 x_i 变为零,以概率(1 - p)变为 x_i / (1 - p)。这种变换使得数据 x’ 的期望仍然与原始数据 x 保持一致。为了更清晰地理解,我们可以计算期望。
-
首先,我们计算 x’ 的期望值。x’ 的期望值表示为 x’ 的每个元素 x_i’ 的期望值。由于 x’ 是通过将 x 中的每个元素以概率 p 变为零,以概率(1 - p)变为 x_i / (1 - p) 而得到的,因此 x_i’ 的期望值为:
-
E[x_i’] = p * 0 + (1 - p) * x_i / (1 - p)
-
在上式中,第一项表示元素 x_i 变为零的情况,第二项表示元素 x_i 保持不变的情况。我们可以简化上述表达式:
-
E[x_i’] = (1 - p) * x_i
-
这表明 x’ 的期望值等于原始输入 x 的期望值乘以(1 - p)。因此,丢弃法可以在引入噪音的同时保持数据期望不变,这是它的核心思想。

4、使用丢弃法
- 我们来看一下丢弃法用在什么地方。具体来说,它是如何运作的?回顾一下我们之前讨论过的内容。我们假设我们有一个神经网络的第一层,即输入层。在这一层,我们将输入乘以权重w_e,并加上偏移b_e,然后通过激活函数进行转换,得到第一个隐藏层的输出H1。接着,我们对第一个隐藏层应用了丢弃法,简而言之,就是将H1中的每个元素以概率p置零,以概率1-p保留,并且通过一个函数来调整概率p的大小。然后,我们继续前进到网络的第二层,这里假设我们有一个全连接的隐藏层。在第二层中,我们将H1经过权重w_two的变换,加上偏移B2,然后应用Softmax作为输出。可以看到,第二层的输入来自于前一层,但通过丢弃法,一些元素被置零,另一些被按比例缩放,从而影响了结果。
- 从图上来看,原始情况下,如果我们要构建一个具有5个隐藏层的神经网络,但使用了丢弃法,很可能会出现以下情况,其中一些元素被置零,从而被剔除。这将影响到下一层的输入。这个过程中,一些权重会被去掉,而另一些可能会增大。因为丢弃法是随机的,所以下一次运行可能会产生不同的结果。在下一次运行中,可能会选择去掉这两个元素,或者去掉三个,或者保留它们。这就是丢弃法的工作原理。

5、推理中的丢弃法
- 训练过程如下:在推理过程中,也就是在预测时,我不使用Dropout。这是因为Dropout是一种正则化方法,正则化只在训练中使用。无论是之前的L2正则化还是当前的正则化,都仅在训练时起作用,因为它仅对权重产生影响。在预测时,我们不需要对权重进行正则化,因此在推理中,不需要使用Dropout。这意味着在推理过程中,Dropout的输出与输入相同,不会执行任何舍弃或缩放操作。这确保了我们获得确定性的输出。这就是推理中的工作方式。
- 当然,相反地,当我们进行训练时,我们告诉模型Dropout是一种正则化方法。最初引入Dropout时,它的目的就是作为一种正则化方法。

6、总结
- 总结一下,Dropout(丢弃法)是一种正则化技术,它通过随机将一些输出项,特别是隐藏层的输出项,置零来控制模型的复杂度。
- 通常,它应用于多层感知机的隐藏层输出,而在全连接层的隐藏层输出上很少使用。在例如卷积神经网络(CNN)等模型中,我们稍后会进行详细说明。
- 丢弃的概率是一个超参数,用于控制模型的复杂度。如果丢弃概率为1,那么所有项都将被丢弃,权重w将等于0。如果丢弃概率等于0,那么不会进行任何控制操作。通常,丢弃概率p通常取0.5、0.9或0.1,这三个值最常见,它们也是用于控制模型复杂度的超参数。此外,Dropout的效果很可能比之前的L2正则化稍微好一些。这就是Dropout的概要。

二、D2L代码注意点
三、QA
、
第一个问题就是drop out;随机置0;对求梯度和反向梯度的影响是什么?
如果你被随机置0;那么你的梯度也会变成0;所以就是说;但是你没有支点的地方;你会乘了一个数对吧;梯度也会在相应的乘乘一个数;就说drop part;你可以认为这个函数对于求梯度;其实是差一个对称的一个函数;而且所以就意味着说等;就是你drop part的那一些;输出它对应的那些权重;它就这一轮就不会被更新;
丢弃法的丢弃依据是什么;如果丢弃不合理;对输出的结果会影响很大?
你可以简单认为它就是一个正则项;就跟我们之前的是一样的;就是说你丢;所谓的丢弃不合理;就是说你那个丢弃率没设好;要要么太小了;太小了就是说你对模型的;那个正则效果不好;不不大;不够所以你还是over feeling;就还是过拟合;就要么就太大了;那就是欠拟合;对吧就是合适比较好;所以就是一个超参数;就是你可以调;
问题13 drop out的随机丢弃;如何保证结果的正确性和可重复性?
哎这个是个正确性和可重复性;是两个问题;所谓的正确性;这没有正确;这是机器学习没有正确性;机器学效果好不好;哪有正确不正确;比如说;所以机器学习;特别是神经网络;因为他那个网络很复杂;稳呃用随机梯度下降;他的稳定性很好;所以;所以说假设你代码有bug;很有可能你是看不出来的;很有可能你你代码写错了一个;可能是个很大的bug;就是你的精度;可能会丢那么一个点;零点几个点;或一个点;所以;所以就是说你不知道结果的;你就算你代码没写错;或者就怕了怎么样;你也不知道结果是不是正确;所以没有没有;没有正确性可言;就说只有说;精度好不好;可以但;我是说从实际上来说;统计上来说就不一样了;但是统计这东西;你在实际上也验证不了;所以呢;所以你可能唯一注意的是可重复性;所谓的可重复性;就是说你下一次运行的时候;因为dropper的每次随机丢丢值嘛;你下次做的时候;你下次跑的时候;你结果就不一样了;所以这个是一个整个神经网络的;可重复性;一直就是一个非常难的事情;但job part还好一点;就job part它的bug不是那么明显;是说你只要固定你的随机种子;所谓的随机种子;大家可以去试一下;我固定住那个随机种子的话;我每一次我run 10次;就说我我就我那个函数就drop out;我就把那个random seat固定住;就是random的那个函数的;random seat固定住的话;那么我drop out 10次;然后我再重复的run 10次;结果是应该是一样的;所以就是说;如果你真的想重复性的话;你可以把你的随机总是固定住;就是说;你可以保证下一次应该是差不多了;当然了;但是你整个神经网络的随机性;也挺大的;你的权重的初始是随机的;对吧;如果你真的要做可重复的训练的话;你的随机种子得重复著;然后你的job part里面是要重复著;应该;这是两大主要的随机数的来源;第三大数就是你很难控制的;就是假设你用的是CODA的话;media的cool DN这个library就是;它是用来加速你整个矩阵运算的;你不用cool DN的话;基本上所有的主流函数;主流firework都是用了cool DN;但你可以禁掉它;就只要用了;用cool DN;会给你带来比如说50%或者80%的加速;你不用cool DN的话;你会慢一些;就GPU的话;但是cool DN它每次算的;矩算乘法算出来结果是不一样的;这个是涉及到一个;计算机体系结构的问题;就是说你把;n个数相加;加的顺序不一样;结果会不一样;理解吗就是因为你的精度不够;所以就是说你在codn;它就是尽量的要尽量好的做并行;一旦做并行的话;加的一些数相加的顺序不一样;导致的结果不一样;所以codn出来的结果随机性挺大的;几乎不能重复;所以如果你想可重复的话;要禁掉QDN;然后drop out和random seat的叫random;就是权重初随机;初始化那个seat;要将这个种子要固定住;应该就你可以可重复了;但反过来讲;你也没必要可重复;就是说最后的最后;就是说你只要保证我训练个100个100轮;或者多少一个EPOK之后;我的精度差不多在按那个范围就行了;就是说;这就是通常来说大家的做法;而且我们虽然有随机性;随机性它不是个坏事情;随机性让你更稳定;就是随机;它就是你可以认为随机这个事情;就是把你整个东西变得很平滑;就说你一旦随机性一高;你的稳定性也会增加;比如说你呀;你要这么想;我整个神经网络;我都能在你给我把所有东西都给我;里面东西全部置0;各种CG的情况下;我还能收留;我还能到这个地方;下次我也行;
就是这个问题;是说;丢弃法是在训练中把神经元丢弃后;训练在预测中神经元没有丢弃?
是的;就是说丢弃法只是在训练的时候;随机把一些隐藏层的;或者说或者说你把随机神经元;在这一轮不参加计算而不参加;更新但是在预测的时候;是大家一起的;
丢弃法;是每次迭代一次随机丢一次吗?
是的就每;就是说它是每一个层;在调用那个前项运算的时候;就随机丢一次;又会如果你有三个隐藏层;那你用了三个;Jopart layer的话;那么它会那就有要扩三次了;就是说;所以我觉得应该是;你所谓的每次迭代一次;就是一个batch;你要重新丢一次;
请问在用BN的时候;会有必要用job part吗?
我们还没讲BN;BN是之后我们接下来要讲的;也是一个;beyond有一点点;有一点点政策的意思在里面了;但是;beyond是作用在卷积神卷基层上的;就BN是给卷基层用的;dropod是给全链接层用的;不一样;所以dropod和BN没有太多相关性;所以我们现在还没讲CNR;所以我们也没讲BN;所以dropout;你可以认为它就是在全链接层用的;不会在剪卷基层我们是不会用dropod;
dropout会不会让训练loss的曲线;方差变大;不够平缓?
其实dropout会让曲线变得;看你怎么说;有可能是你就说有可能是不够平滑;你我觉得我大概理解你的意思;就是说看你怎么画这个曲线了;我们这个曲线画是;我们这个曲线画的是每一次;每一次;每一个数据扫完之后我算一个平均;它其实很平化的;但是你真正的做硬算的话;你扫一遍数据那么贵;所以你可能就每每算个10个bash;我就画一;下10个bash画一下;它就可能会让你的;如果你这么画的话;你会发现;整个曲线抖动很大;其实你不care;抖动大就抖动大呗;谁care所以;你不要担心曲线;它有可能让你曲线不平滑;有可能但我没有真正的去看过;但是我们不care这个事情;就是说曲线平不平滑;对最后的;就是说一开始平;就一开始不平滑;最后都得平滑;如果你最后不公平的话;就比较信你;收敛很麻烦;
问题18他叫推理的drop out;是直接返回输入吗?
为什么;这个对这个是drop out最大的一个;经常大家容易误解的地方就是;在做预测的时候;假设你预所谓的预测;就是不对我的权重做更新的时候;dropout是不用了;就不用dropout;为什么是因为dropout是一个正则项;正则项唯一的作用;是让你在更新你的权重的时候;让你的模型复杂度变低一点点;当你在做推理的时候;你不会更新你的模型复杂度;而不会更新你的模型;所以你是不需要drop out的;你可以用drop out也可以;但是可能对你;如果你用了job part;那就有随机性;所以;你要避免你随机预测的时候出问题;那你肯定得多算;多算几次;就我给一个样本过来;假设我开了;我在推理可以开;drop out你可以开;就是说;反正推理就是说对权重更新没影响嘛;但是你可以开cat;代价是说你因为你开了它;所以导致你预测的时候;我给你一;只猫的图片;第一次预测成猫;第二次预测成狗;对吧因为交付丢掉东西了嘛;就所以说你可能要得多算几次推理;做一下平均;才能使得把这个方差给降下来;但训练没问题;训练为什么没问题;因为训练我要跑很多很多次drop out;我就不断在跑drop out;我可能跑个;我们在这个地方就是;每一次我都跑了;对吧我跑个几十万次呢;所以在几十万次的随机的丢在里面;对整个系统的稳定性是没问题的;但是在推理的时候;如果就关心某一个样板他的结果的话;你可能做平均;就是在我们部署的时候;你拿张图片过来;我给你出了一个坏结果;怎么办对吧;我尽量不要出坏结果;但但是你如果反过来讲;如果你就是关心一个;在一个测试级上的;一个精度的话;可能开drop out不会给你带来很多影响;你可以试一下;很简单吧;你就把前面那个函数;把那个if圈里等于一;使用交叉的把它删掉不就行了吗;注掉不就注视掉就行了
drop out;函数返回值的表达是没有被丢弃的;输入值会因为分母的一减p而改变;而训练数的标签还是原来的值?
是的是的;就是说就抓怕的;就是说你要么就把那个输出变成0;不然的话要除一个一减p;这是为了保证我的就随;因为随机性;保证我的期望就我的;均值还是不会变的;但是标签还是原来的值;对标签我不改变;我们为job part唯;一改变的是我的job;我的隐藏层的那个输出;你可以改标签;改标签是别的算法;就是说你可以;你可以改标签;改标签也是一种正则化;我们我们这个客户一定会讲;就你可以改标签嘛;就你把;这改标签还是一个正常;挺常用的一个正传话;我在想有;说不定我可以给大家讲一讲;就是我可能会在最后讲CV的时候;给大家大概提一下;还真有就是说我可以把标签也改了;也是一个随机嘛;就是说我们之所以只讲drop out;就是它是最早最早的一个;在神经网络中间引入随机;向来做正则化的一个东西;但实际上在之后;在之后你大家发现drop out吗;我drop out隐藏成书;我什么都可以drop out;我可以drop out wait;我可以drop out我的;我我可以把我的输入给变上联;我可以把我的label变上联;就都可以;都可以没关系的比如说;最后在过去的;
是就是说训练时使用drop out;推理时不用;会不会导致推理输出结果翻倍了;比如说drop part等于0.5;推理的是输出式训练;是两个神技元叠加翻倍?
所以大家记得我们除了个一减p对吧;就是说假设你在训练的时候;你drop part等于0.5;就是说我把一半的神技元就成0;剩下的我要除以0.5;就乘了2;所以你输出和输入;就是说在训练时;你的方差是不会发生变化的;所以这就是为什么要除一个一减p;为什么我给大家算一下;说期望没有发生变化;就是说导致说你的;就是要避免你的输出的结果;是训练的时候f翻倍的结果;OK;
Drop out每次随机选几个子网络;最后做平均的做法;是不是类似于随机森林;多角色速度投票的思想?
是的就最早最早;Hinton就Hinton;大家应该知道;Hinton老爷子就是神经网络的;奠基人之一吧;就是最大的山头;他们做Drop out的时候确实就是这么说的;就说我Drop out的干嘛;我就是每次在训练的时候;随机踩了一个子网络训练一下;然后那我做预测的时候我也可以做;预测的时候我也可以说;那就是预测的时候我也可以用;Drop out嘛;就是做n下嘛;就是每一次;比如说预测的时候我就重复5次;然后每次踩一个姿网络做一下预测;然后做平均;就你可以这么说;就是说但是实际上像我没什么用;就是说实际上你就是说;你当然可以这么说了;但是;实际上大家发现他更像一个正则;像如果有兴趣;我就可以把那个那几有几篇paper;就是说去讲你Drop out是一个;你可以去;so Drop out is a regularization;就是这个;这个title应该就长这个样子;
请问丢弃的是前一层还是后一层》?
是怎么说呢;它就是都一样;就是说;你可认为它丢弃前一层的输出;和丢弃后一层的输入是一个东西;对吧本质的嘛;就他;或者你可以认为drop out它其实是一层;就是一个层;输入是一个东西;输出就丢掉一个东西了;dropout的和权重衰退都属于正则;为什么dropout的效果更好;而现在更常用呢;呃其实dropout没有权重衰退常用呢;就是权重衰退其实是说大家都在用;就是说一般都会用开权重衰退;这drop part主要是对于全连接层使用;那权重衰退这个东西;权重衰退对于卷基层;对于之后的transformer都可以用;就是说;大家是统一用;drop out为什么效果更好;drop out其实我觉得就是更好调参一点;就权重short这个number呀;这不是很好调;drop out好调一点;drop out很直观嘛;就我丢多少;我;丢一半就捉炮子;就三个值;0.50.10.9 就三个值;丢一半就表示就是说;就是说;你你可以这么简单这么觉得;我假设去年一个单隐藏城的全链接;MLP然后这个隐藏城大小是64;我劝了一下觉得还行;就说不用job part问题不大;觉得没那么过离合;那么接下来你可怎么办呢;接下来你就把它变成128;开job part等于0.5;对吧就等效;你感觉上等效就等于是;反正一半的丢掉了;就等效于是我的隐藏层被;减半嘛但很有可能128开job part的;等0.5 效果比你直接是64要好;就还是养深度学;就说我可以过礼盒;但是我通过别的来让你训练的时候;不要就我需要让模型够强我;然后通过我的正则来使得你不要学偏;就是说你跟小孩一样的;就是说我;我想你智商高一点没问题吧;你性格差一点不要紧;我我们想办法来;或者说你说大家;就一个人吧;你就说一个人的能力是你的;魔性复杂度;一个人的性格是你的;或者说;性格这种东西是你的;你容易学歪的一个东西;那么大家是愿意跟性格好的;能力不强的人做事情呢;还是跟性格差的;但是能力很强的人做事情呢;很有可能是性格好的;不性格差一点的;能力强一点的人;然后你尽量去废掉他的性格;对吧那最好的是说你能力有强;性格也好;当然是极少数了;我们也有这样子的模型;嗯但是;MLP不属于那种MLP;属于能力强性格不好的那种;所以现尽量也不要使用MLP;就是说一般大家用的越来越少;所以就为什么我们之后要讲CNN;讲叫Transformer;叫cn你可认为就是一个special的一个;一个特别的一个MLP;所以就是说;我就回答这个问题;我说;我觉得drop out主要是调起来比较方便;就是说你就;如果你就可以调个0.9;如果你觉得这个隐藏层特别大;模型特别复杂;我就搞高一点;搞个0.9就百分90;的丢掉就是强回归;如果是;小一点的话;我取个0.1就随便回归一点点;改标签是一种mask嘛;改标签;就是说我们之后会讲怎么改标签;也是一种常用的技巧;但是;也不是简简单单的就把随机改一下了;不是这样子改的;会有一点别的技术在里面;如果你强行改的话;可能效果不那么好;但有一些别的技巧可以让你更好;在同样的最后一个问题;在同样的我们事件差不多了;在同样的学习率下;dropout的介入会造成参数收敛更慢;需要比dropout情况适大调大linearate嘛;dropout;还有真有可能使得你收敛会变慢;这个是有可能的;因为你等于是说你每次权重就剃度;跟就说你更少的一些在更新梯度嘛;但是我好像没有听说过;说你因为有了job part;能力rate变大;因为从从期望上来讲它们是差不多的;就job part不改变期望;能力rate就学习率;主要是对那个期望会;期望和方差敏感一点点;嗯这我没有听说过;要适当调的;你可以调;但是我没有听说过;有大家说有;经验上总结说就是drop the;那我就把then ret改到两遍;没有听说过这个事情;但我觉得会瘦脸变慢是有可能的;
Transformer可以看作是一种特殊的MLP吗;目前还没有;目前还没有这么看;Transformer可以看作是一个connormation;就是一个合合方法;比如这个是可以;这个是大家可以看的;就是还没有看成是特殊;的一个MLP;;
No.5 数值稳定性+模型初始化和激活函数
一、数值稳定性
1、神经网络的梯度
-
数值的稳定性
-
这个是机器学习里面比较重要的一点;当你的神经网络变得很深的时候;你的数值非常容易不稳定;
-
假设有一个低层的神经网络;层记在t;就t不要搞成时间;之前也用t表示时间;这里表示层;
-
假设我的H(t-1);是第t-1层的隐藏层的输出;然后经过一个ft;得到我们的第t层的输出HT;
-
然后y可以表示成为;就是x进来第一层;一直到第d层最后一个损失函数;就是我们的预测的;我们要进行优化的那个目标函数;
-
但y这里不是预测;y还包括了损失函数;就是之前有讲过梯度怎么算;如果计算损失关于某一个乘Wt的一个梯度的话;先把它一直写开;有链式法则;
-
损失函数;对最后一层的求导,然后最后一层的隐藏层;对于倒数第二层的隐藏层求导;一直一直求;求求求到第一层的输出;第一层的输出;关于第一层的权重的求导;就是依次类积下来;
-
所有的h;都是一些向量;向量关于向量的导数是一个矩阵;所以这里的是一个(d-t)次的矩阵乘法;这里一共有(d-t)次的矩阵;所以我们是对它相乘;所以我们主要问题来自于这个地方;因为我们做了太多的矩阵乘法;

2、数值稳定性的常见两个问题
-
矩阵乘法带来的主要的两个问题是;一个叫做梯度爆炸;一个叫做梯度消失
-
梯度爆炸;假设我的梯度都是一些比1大一点的数;然后对1.5做100次;假如说有100层的话;做100次;就会得到一个4乘以10的17的一个数;当然这个数浮点是能表示的;但是很容易这个数字会带来我们的浮点的上限的一些问题;因为浮点其实是有一个合理的范围的;
-
同样的话;如果我的梯度的值是小于1的话;就算不会太小;就算是0.8;如果是100层的话;那么0.8的100次方;那也是2的-10次方;也是个非常非常小的数了;就表示说;这里基本上就梯度就不见了;

3、例子:MLP
-
MLP;就是一个多层感知机的模型来讲述(d-t)次的矩阵的形式
-
先假设就把那个偏移那个b给省略掉了;
-
这个是第t层的输入H(t-1);也就是t-1层的输出;然后这个函数;就会表示成一个第t层的权重;wt乘以输入H(t-1);然后假设省略掉偏移的话;就直接在输出上做激活函数;叫做Sigma;
-
链式法则进行求导:第t层的输出;关于输入的导数
-
然后求导;就是说首先要对激活函数进行求导;它是一个按元素的一个函数;它的求导其实很简单;因为他是一个对元素;而且是个向量的话;它就变成一个对角矩阵;
-
假设Sigma撇是Sigma的导数;就是这个激活函数的导数的话;那就是把它的输入放进来;它就输入这个向量;它的输出也是一个向量;然后把它做成一个对角矩阵;然后这个地方就是一个Wt;就是t还是说这个小t;小t是有那个层的意思;然后大T是它的转质;
-
然后回忆下前面;前面要对(d-t)次这样子的乘法;就是说要从最后一层开始一直乘乘乘;乘到当前层;如果把它累乘的话;会发现是说;那就是每一次就是一个对角矩阵乘以另外一个矩阵;然后做(d-t)次 这样子的乘法;所以我们知道;就是说;假设我们是一个多层感知机的话;我们会关于t层的导数是这样子的形状。

4、梯度爆炸
-
使用relu;作为激活函数;
-
relu回忆下就是一个Max(0,x);所以它的导数是说如果x大于0;那就是1;不然的话就是0;所以可以看到是说那么这里面;这里面就是一堆1或者0;所以一些1和0的一个对角圆;做成的对角矩阵;跟它相乘的话;那么就意味着说要么就把某一列给留住了;要么就是把它全变成0;
-
那么这个地方意味着是说;因为这个函数里面全是1和0;那么它的最后的值;就这个的值的一些元素;就是来自于;那些没有被变成0的那一些列的乘法;就是来自于你把这个所有的WI;就是第那一个当前层的;第i层的那个权重做导数;然后做乘法;就它的一些元素来自这里;当另外一些元素是0;
-
这里的问题是说如果d-t很大;就是这个网络比较深的话;那么它的值就会比较大;因为里面这里全部是一些w的元素;假设我每一个w的元素;都是大于1的话;而且层数比较大的话;那么这里面就会有非常非常大的值;这就是梯度爆炸;那剃度爆炸有什么问题呢

5、梯度爆炸的问题
-
存储问题
-
我的值可能太大了;如果值超过我的浮点运算的话;就变成了一个Infinity;就是个无穷大;对于16位浮点数尤为严重;
-
现在很多时候用GPU的时候;我们会使用16位浮点数;这样子通常来说;现在media的GPU在16位浮点数;比32位浮点数要快个两倍;所以很多时候我们会采用16位浮点数;16位浮点数的最大的问题是说;它的数值区间其实很低的;它就是一个6e负到6e正4的一个区间;那么就是说;意味着说我这个区间其实很小;如果你超出了我的值的区间;那我就变成了无穷大;所以就会给我带来问题;
-
对学习率敏感问题
-
假设是没有到无穷大;但是还是会有很多问题;最大的一个问题是说;对于学习率非常敏感;就是说如果我们的学习率调的太大;就稍微大一点点;那么就会带来比较大的参数的值;因为我每一步走的比较远;那么我对权重的更新;就会权重会变得比较大;那么权重一大;对应的记得我们那个梯度;就是我们的权重的乘法;那么就会带来更大的梯度;那么更大的梯度;会导致更大的参数值;那就一直一直也带个几回;你就会整个梯度就炸掉了;就变成无穷大了
-
假设学习率太小呢;问题是说你就训练就没有进展了;就说学习率太小;每一次对w的那个增加就比较小;再次导致我整个训练是跑不动了;
-
很有可能是说;需要在训练过程中不断地调整学习率;就是说在一开始;可能整个权重的比较小的时候;可能学习率要稍微大一点点;到后面的话可能学习率的减少;或者甚至你要做很动态的一些调整;根据你的当前的梯度来做;所以这个就是整个这一块就导致说;
-
假设你没要到infinity的话;不是说他真的完全就不能训练;只是说他会给你调学习率这个事情调的比较难调;就是你的大一点点就炸掉了;小一点点就不动;所以在一个很小的一个学习率;只有一个很小的范围是比较好的;这个给你之后的模型训练调参了带来很大的麻烦;这是剃度爆炸的问题;

6、梯度消失
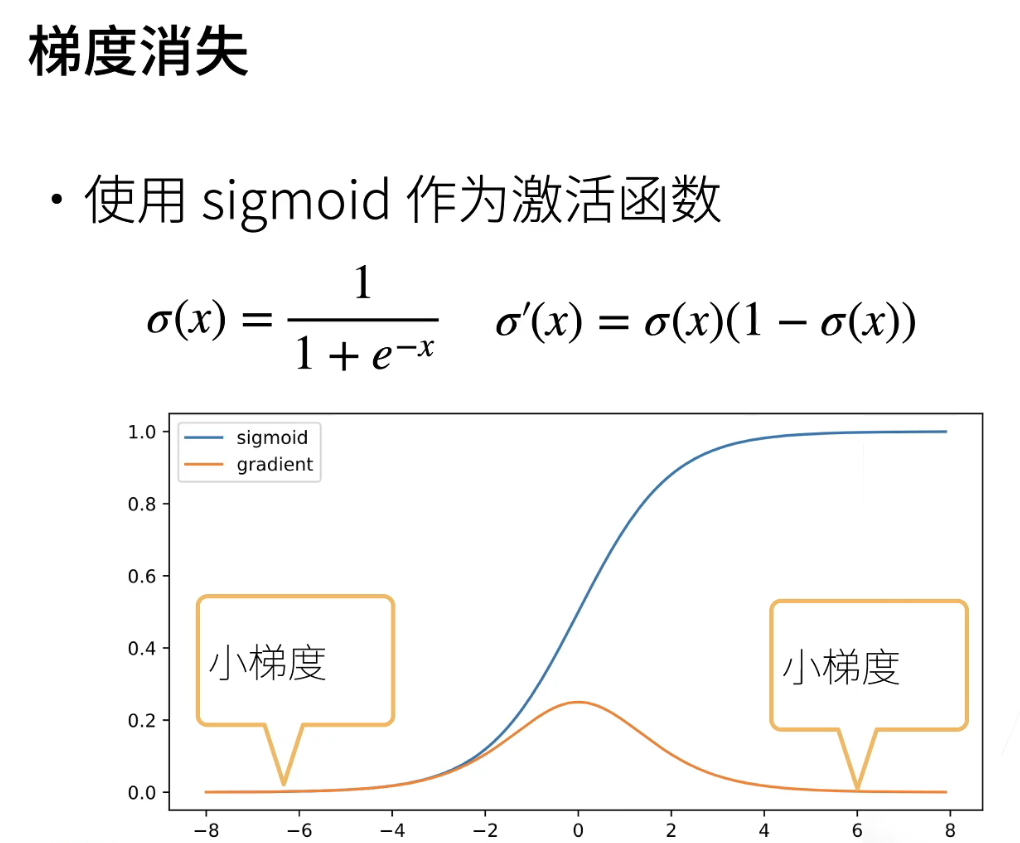
-
梯度如果会消失会怎么样;
-
举一个具体的例子;假设用sigmoid函数作为激活函数;那么它的导数可以算一下;就是这个地方;可以看到是说这个蓝色;是它的那个值的一个函数;就是说它是在0和1之间;
-
它的梯度是黄色这根线;可以看到是说当你这个值很大;就是说你的输入是6的话;它梯度就很小了;基本上是到0了对吧;那就是说当你的对于这个激活函数;当你的输入稍微大一点点的时候;那么它的输它的导数它就会变成0;再来看一下会什么问题
7、梯度消失
-
问题
-
如果这个输入;相对来说稍微大一点的话;那么这个东西就会变成0;那么就意味着说:这里面可能有;它也不是变成0;它就变成很小;那么这意味着说;
-
你可能会有d-t个小数值的乘积;就是说;那么每一个数可能都比较小的话;如果你的输入比较大;那么的梯度就变得很小;那么它的比如说之前讲过;就算是0.8做100次;那也变成2的-10次方;那么你的梯度就很小了;

8、梯度消失的问题
-
梯度值变成0;
-
因为16位浮点数;如果是小于一个;比如说51-4的话;那基本上可以把它当0了;就是就*0.0005的时候;那么你浮点数就基本上把它当0看;
-
如果梯度值变成0;那么不管怎么学;你的学习率都不会有进展;只是学习率不管趋居多多大;因为你的权重就是学习率乘以你的梯度;你的梯度已经是0的话;那么你就训练就不会有进展;(w基本不会变)
-
而且是说对于比较深的网络的时候;对底层的尤为严重;这是因为;当神经网络比较深的时候;记得做梯度翻转的时候;是从顶开始的;那么顶部因为有一些;比如说顶部第一层就是1次之间乘法;那么你的梯度可能是正常的;
-
越到下面那么你就一直乘乘乘;那么你的梯度会变得特别小;可能就是0;那么底部那些层;就是靠数据进的那些层;如果你的梯度是0的话;那你不管怎么样做学习率;你都不会有进展;那么这个意味着什么问题;意味着是说;不管把神经网络加的多深;底部那些层你跑不动;你就把顶部那些层训练好;那就意味着说;你跟一个很浅的神经网络;是没有本质区别的;这就是提速消失的问题

9、总结
-
====
-
当数值太大或者太小的时候;都会导致数值问题;这个常发生在深度神经网络里面;因为有很多层;你的梯度其实就是对n个层做累乘;
-
如果你的权重稍微大一点点;或者你的前向的输出稍微大一点点;那么就会导致梯度会炸掉;
-
如果你的那个值比较小;或者你激活函数;使得你的值变得比较小;那就变成n个很小的数做乘法;那就导致很小;
-
就是说这个是我们常见的两类问题;就是说我们要既要避免;我们的梯度不要太大;我们也要避免我们的梯度不能太小;

二、模型初始化和激活函数
1、让训练更稳定
-
一个核心问题是说;如何让训练更加稳定;就是梯度不要太大也不要太小;
-
乘法变加法
-
让训练更加稳定;目标是让我的梯度值在合理的范围里;可以说我尽量使梯度;在1-6到1-3这个区间里面;那么几个常见的方法是:
-
让乘法变加法;不管是在CNN里面使用的最多的现在Resnet;还是在RNN里面使用的最多的LSTM。
-
Resnet核心是说当你很多层的时候;那么会加入一些加法;就是说一些加法在里面;如果你很多层从乘法变成有加入加法进去;
-
LSTM也是一个持续的;如果你的持续序列很长的话;如果你的持续序列是100的话;就说输入一个长了100的一个句子;那么原始的持续神经网络;它就是对这个每一个持续做乘法;如果你太长就不行了;LSTM就是说把它这些乘法也变成加法;这样子的话;不管是Resnet还是LSTM;它都把100次的乘法变成100次加法;加法当然出问题的概率就很小了;所以这个是一个核心的思想;乘法变加法;
-
归一化和梯度剪裁
-
另外一个核心思想是说;把梯度变成一个比如均值为0;方差为1的一个数;所以不管有多大;都把你拉回来;
-
说梯度剪裁;就是clipping;就是说如果你的梯度大于5了;大于5我就把它变成5;如果你小于-5的话;我把你变成负;就是强行把你的梯度;减在一个范围里面;
-
本节笔记重点
-
第三个其实是今天要讲的;前面两个在之后会不断的去提及;如何做合理的权重的初始化;和使用合理的激活函数;我们看到;这两个对于我们的梯度;是有很大影响的;

2、让每层的方差是一个常数
-
====
-
其中一个想法是说;让每一层的输出和梯度;都可以看成是一个随机变量;假设一层输出100维的话;那么就是说;把它看成100个随机变量;如果让他那个随机变量;他的均值和方差;都能一直保持一致的话;那我就是会比较好;
-
举个例子就是说;第一层假设输出的话;如果把它当成一个均值为0;方差为1的一个随机变量;那就是整个值的区域就比较好;那么第二层;第二层;那就跟第一层保持一致;那一样的是一个均值为0;方差为1;如果不管有多深;都说最后一层和第一层都差不多;都是一个;均值为是为0;方差为某个特定值的话;那么不管加多深;都没有什么太多问题;我希望的话;我的输出和我的梯度;都在这个值区间里面;那就会比较好了;
-
如果数学上来讲;假设ht是t层的输出的话;i是我的第i个元素;所以它就是一个标量;我把它当做随机变量;所以我们正向的话;那就是说我的输出;那我们的期望为0;就均值为0;方差我们假设是a;就是一个常数;就不管你是对哪一样的t;对所有的i和t都是这样子;就是说;
-
对反向我们是一样的;我们希望我们的梯度;就是说这个是损失函数;关于我们第t层的输出的那一个;第i个元素的梯度;我一样的希望它的方差为0;均值为0;方差为b;
-
这里a和b都是一个常数;所以你不管哪一个层;你不管每一个层的哪一个输出;我希望你们都是a和b的话;那么我的不管你做多多多深;我这样子都可以保证我的;数值都在一个合理范围里面;这是我们的一个假设;我们希望设计我们的神经网络;使得我们满足这个性质;我们接下来看我们要满足什么样的条件使得可以达到这一个要求;

3、权重初始化
-
====
-
第一个是说权重初始化;怎么样通过合理的权重初始化;就这个想法是说;需要在一个合理的值区间里面;随机初始我们的参数;这是为什么呢;是因为在训练开始的时候;更容易有数值不稳定;
-
举一个简单例子;这个是一个画的例子;就说显示一下会怎么样子;就可以看到;是说最优解在这个地方对吧;这是最小值;就假设我们是随机初始的话;很有可能你不会运气好;刚好在最优解的附近;那你有可能在很远的地方;一般来说;很离比较远的地方;很有可能你的表面是不那么平滑的;就可能在一个比较复杂的一个地方;就在这个地方;那么你可以看到这个地方就比较陡;一陡会出什么问题;一陡就是说越陡的地方;你的梯度就越大;讲过梯度就指向最陡的方向;
-
而且在这个地方的话;如果你初始在这个地方;那么有可能你算出来梯度特别大;导致你就不断的;你的w就可能会变得更加大;然后就出问题;同样的话;如果在最优解附近的话;附近的话一般来说你会比较平;那这个例子;我们这我们这里画的例子就是比较;
-
也希望找到这样子平的地方;所以比较平的问题是什么;平的地方你的梯度就比较小;就比较变成0;我们之前一直有说;我们用一个正态分布均值为0;方差为0.01来随机出示我们的权重;它有可能对一个小网络是没问题的;但它对于很深的网络它确实不能保证;就是说它有可能这个值可能太小;或者有有可能这个值太大;这个是;我们不能保证的;所以我们要来看一下说;我们假设要使得满足我们之前的假设;所有的输出和梯度的均值和方差;都在一个常数的话;那我们应该怎么办;我们还是回到之前的这一个例子;

4、例子MLP
-
MLP的这个例子
-
假设我们的权重;是一个独立的同分布;你的权重第t层的第i行第j列;就是独立同分布;就可以又说;我们的均值那就等于0;我们的方差就每一个元素的方差就等于个伽玛T;T是你的层数;
-
那么接下来是说我的这一层的输入;h i t减1;它也是独立于我当前的权重;我的当前层的权重;和我的当前层的输入;是一个独立的一个事件;
-
那么假设我们没有激活函数会怎么样;首先看一下;假设我们没有激活函数的话;那么的HT那就等于w t乘以h t减1;这里我们的WT是一个;当前层的输出的维度是NT;输入维度是NT减1;
-
那我们来看一下;我们做了这些假设之后;我们的计算是怎么样子的;
-
我们的HTi它的均值就等于;可以把它展开;就第二个;第二第二个元素;就等于是说我的第一行乘以我的输入;就是对于j;然后求和;就是w i j乘以h j对j进行求和;那我们知道;WT和HT减一是一个独立的;随随机变量;那么我们这个乘法我们就是;一可以写进去;首先均值对于加法是可以累加的;然后因为它是独立的;所以它我可以把它直接写开;那就是对于;他的均值就等于是他的;均值乘以他的均值;然后再求和;我们知道说;之前我们假设这两个均值都是0;所以我的输出都是0的;这个是没问题的;

5、正向方差
-
关于方差的计算,我们可以继续进行。方差在计算机领域非常重要,你可以将它理解为一个数值集合的分散程度。方差的计算方法是将每个数据点与均值的差值平方,然后对这些平方项取平均,这个平均值减去均值的平方。在这个特定的情况中,我们的均值已经是0,因此只需考虑平方项的均值。
-
所以,方差可以表示为以下公式:方差 = Σ(W^T_ij * h_t-1_j * h_t-1_j) - (Σ(W^T_ij * h_t-1_j))^2
-
这里,有一项平方项,它包括n个项的和。我们可以将它展开,写成每个项的平方再加上交叉项。交叉项表示对于不同的j和k,我们有i j和i k。然而,由于这些项都是独立分布的,它们的期望值都等于0,所以这一项可以化简为0。
-
我们知道期望是可加的,所以我们可以将期望写入公式中,得到:
-
方差 = Σ(W^T_ij * h_t-1_j * h_t-1_j) - (Σ(W^T_ij * h_t-1_j))^2
-
这一项等于权重W的方差。同样,这一项等于第t层输入的方差。我们需要对j进行求和,这个和是n-1项,因为我们知道这个项等于大t的n-1倍,即n-1 * Σ(W^T_ij * h_t-1_j)。如果我们的目标是输入和输出的方差相等,那么我们可以得出一个条件,即n-1 * γ_t = 1,其中γ_t是我们可以选择的方差。
-
这意味着这一项是不能改变的,它代表了输入的维度。我们需要满足这个条件,以确保输入和输出的方差相等。

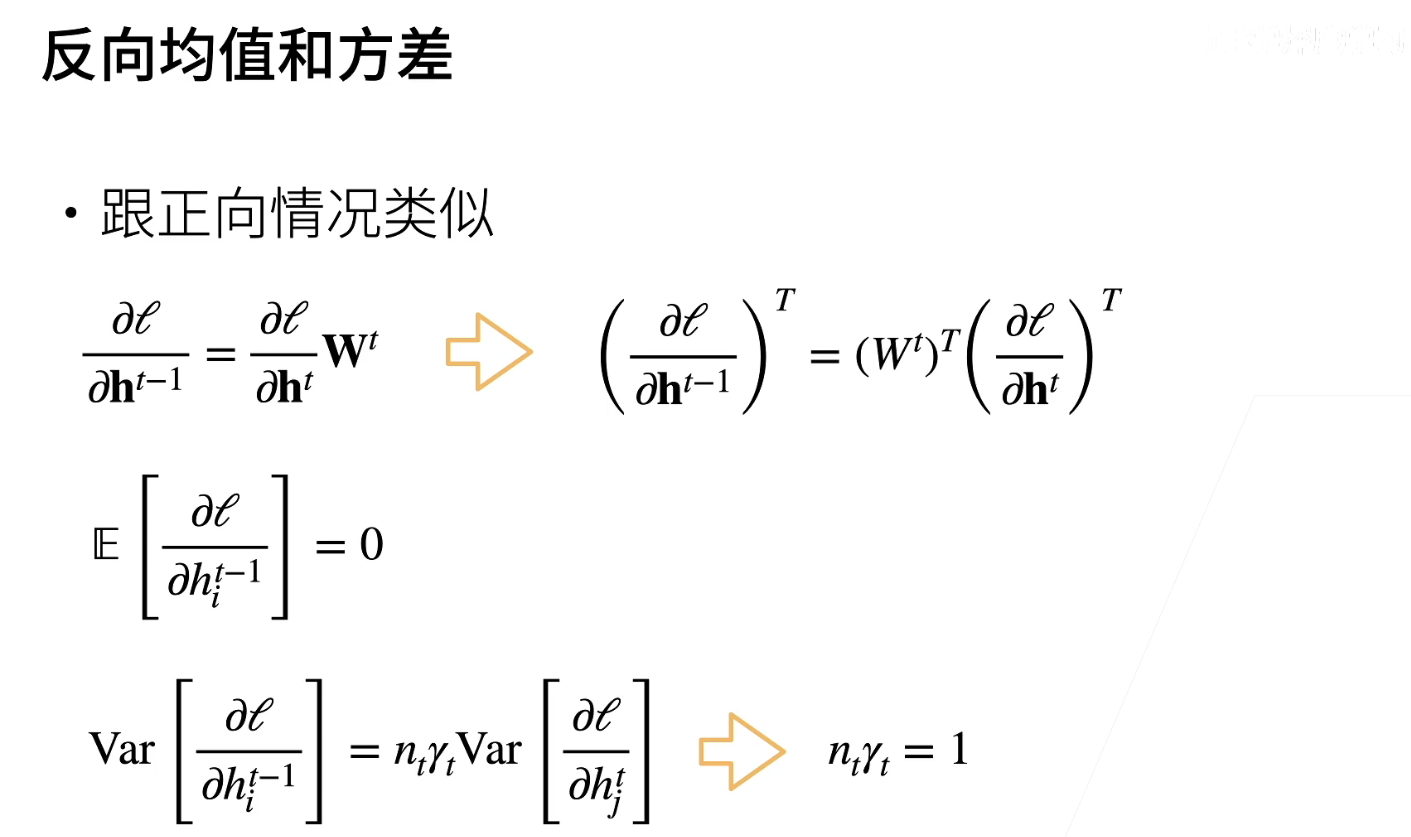
6、反向均值和方差
-
关于反向传播,它与正向传播类似,因为可以看到,反向传播中的这一项可以写成WT的转置。非常容易理解,因为它的转置等于WT的转置乘以它。这是因为梯度反向传播时与正向传播是相似的,都涉及乘以权重W。
-
因为我们的前提条件已经满足了期望等于0,所以同样,如果我们希望方差相等,我们需要满足一个类似的条件。具体来说,我们的要求是n_t乘以γ_t等于1,其中n_t代表第t层的输出的维度。这是因为我们的假设导致了均值都等于0,但如果我们要求方差相等,我们需要满足这两个条件。
7、Xavier初始化
-
第一个条件是要求前向传播输出的方差是一致的,第二个条件是要求梯度是一致的。然而,同时满足这两个条件确实非常困难。
-
这是因为NT减一和NT通常是我们无法控制的,NT减一是第t层的输入维度,而NT是输出的维度。除非输入和输出的维度刚好相等,否则很难同时满足这两个条件。因此,这是一个复杂的问题,需要仔细权衡和处理,以便在深度学习中实现稳定的训练和梯度传播。
-
对于权重初始化的问题,我们可以采用一种称为Xavier初始化的方法,这种方法可以在满足一些平衡条件的前提下,使权重初始化更合理。
-
Xavier初始化的思想是在权衡输入和输出维度的情况下,选择合适的初始权重方差。具体来说,我们选择γ_t,即第t层的权重的方差,以满足以下条件:γ_t = 2 / (输入维度 + 输出维度),并且保证γ_t等于1。这意味着,根据当前层的输入和输出的大小,我们可以确定权重应该具有的初始方差大小。
-
如何使用这个值呢?在权重初始化时,我们可以采用正态分布或均匀分布。如果选择正态分布,均值通常设为0,而方差不再是常见的0.01,而是根据输入和输出维度的总和除以2,然后取平方根。这个值是可以计算出来的。
-
对于均匀分布,如果取在负a到a之间,那么方差将等于a的平方除以3。这是一种均匀分布的性质。
-
Xavier初始化是一种常用的权重初始化方法,它可以根据输入和输出的维度来适配权重的初始形状,特别适用于输入和输出差异较大或网络结构变化较大的情况。它有助于确保梯度和输出方差在一个稳定的范围内。因此,Xavier初始化通常是一种常用的权重初始化方法。

8、假设线性的激活函数
-
在考虑激活函数的情况下,我们首先假设了一个线性激活函数,即f(x) = x + β。尽管线性激活函数不常用,因为它不引入非线性,但为了理论分析的方便,我们考虑它。
-
对于线性激活函数,我们分析其期望和方差。首先,期望值等于β,因为我们已经假设输入的均值为0,所以α乘以0等于0。所以,为了使期望等于0,我们必须有β等于0。
-
接下来,分析方差,我们可以展开方差的表达式,最终得到方差等于α^2 * 方差(输入)。这意味着激活函数会将输入的方差放大α2倍。如果我们想要激活函数不改变输入输出的方差,那么唯一的选择是α2等于1,即α等于1。
-
所以,为了使前向传播的输出均值和方差都保持为0和固定值,我们的线性激活函数必须满足β等于0和α等于1。
-
同样的原理也适用于反向传播。总的来说,线性激活函数在深度学习中不常使用,因为它无法引入非线性变换,而非线性激活函数如ReLU等更常见,能够更好地捕捉数据中的复杂关系。

9、反向
-
对于反向传播,你可以得出与前向传播相似的结论。反向传播的推导过程基本上与前向传播类似,因此最终的结论也是一样的。如果你希望梯度的均值为0且方差固定,那么你的α和β必须满足一定条件。
-
具体而言,为了满足梯度均值为0,β必须等于0,这与前向传播的结论相同。而为了使梯度的方差固定,α必须等于1。这意味着,如果你想保持反向传播的梯度均值为0和方差固定,你的激活函数必须满足α等于1和β等于0的条件。
-
这个结论强调了激活函数在深度学习中的重要性,选择适当的激活函数有助于保持梯度的稳定性,从而更好地训练深度神经网络。
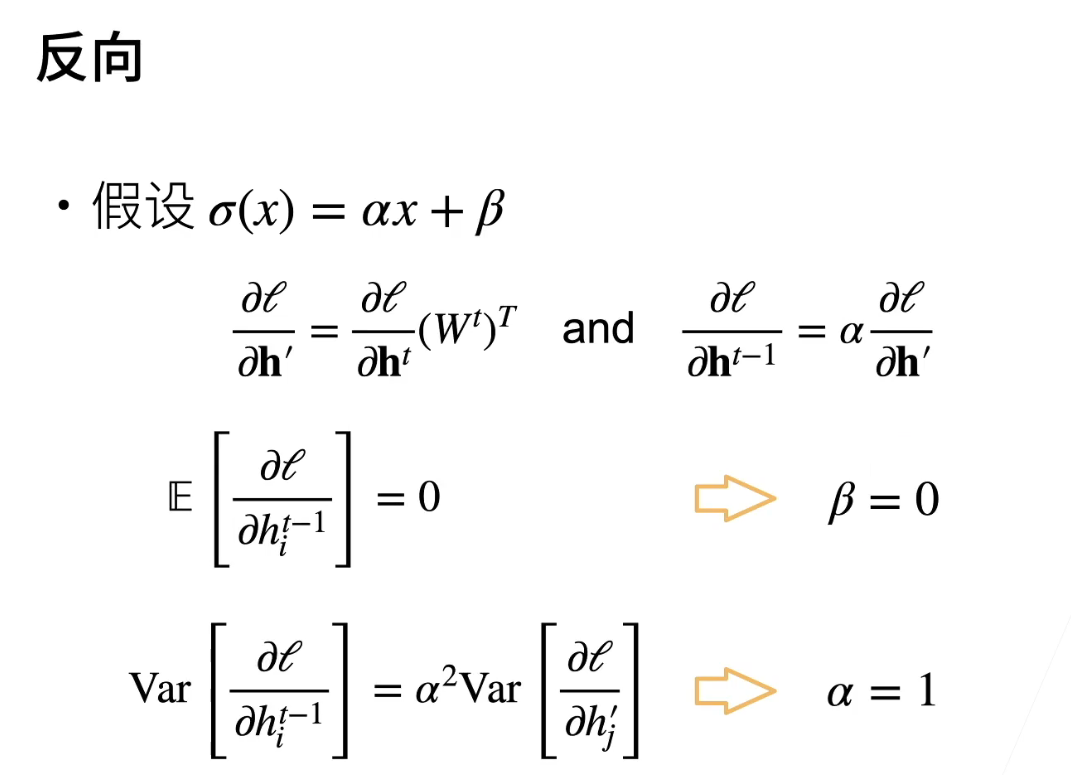
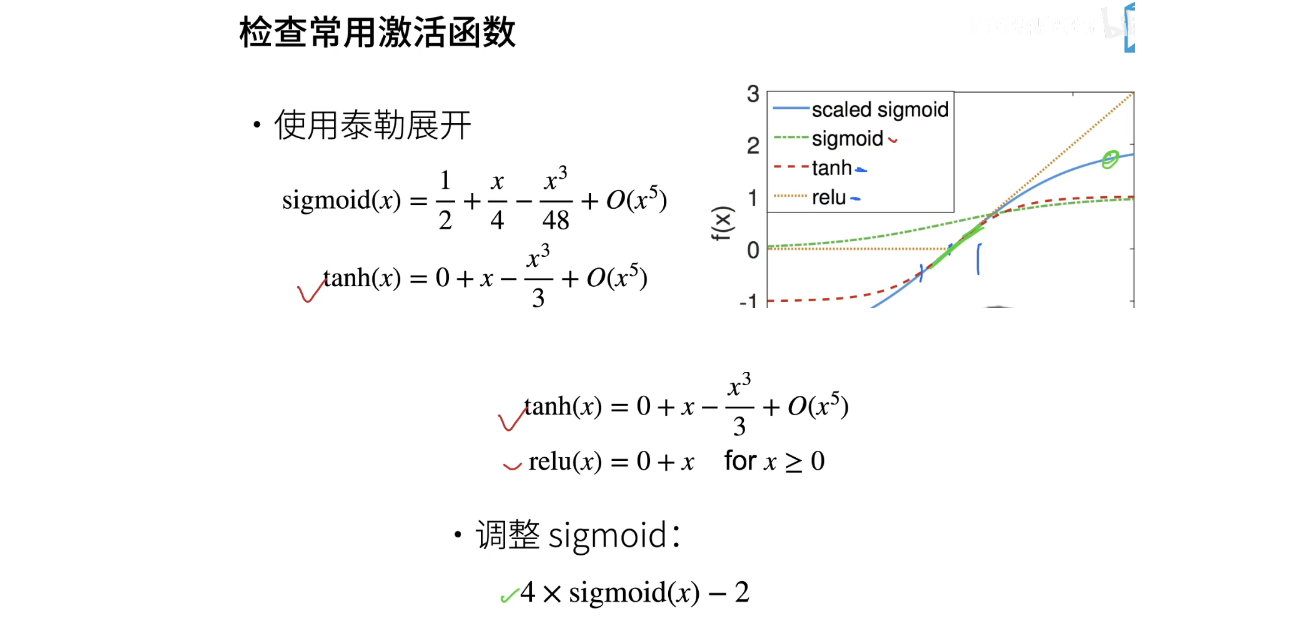
10、检查常用激活函数
-
这意味着激活函数必须是f(x) = x。现在让我们来检查一下不同的激活函数,并使用泰勒展开进行分析。泰勒展开是一种逐项逼近函数的方法,它对于深度学习中的激活函数分析非常有用。
-
首先,我们来看Sigmoid函数。它在零点附近无法近似为f(x) = x,因为Sigmoid函数的泰勒展开会得到1/2 + 4x - 4x^3 + …,而不是f(x) = x。然而,我们可以调整Sigmoid函数,将其乘以4然后减去2,这将使它在零点附近近似为f(x) = x。这种调整后的Sigmoid函数在实际问题中可以更好地解决一些问题。
-
对于tanh和ReLU激活函数,它们在零点附近可以近似为f(x) = x,因此满足了我们的要求。而且,神经网络中的权重通常接近零,所以这两个函数在数值稳定性方面表现良好。
-
总结来说,为了使神经网络的数值稳定性更好,选择合适的激活函数非常重要。不同的激活函数在不同情况下可能更适用,因此需要根据具体问题进行实验和调整来选择最合适的激活函数。
11、总结
-
====
-
可以合理的对权重;初始值和激活函数的选取;来提升我们的数值稳定性
-
具体来说;我们使得我们的每一层的输出;和我们每一层的梯度;它都是一个均值;为0;方差为一个固定数的一个随机位量;
-
在这个目标下;我们可以说;权重初始的话可以使用XV;然后激活函数的话;你选relu或者选T h都没有问题
-
如果你选sigmoi的话;你可以对它做一下;重新变化也会;解决掉sigmoi的以前带来的很多问题;

三、QA
-
第一个问题是说;可以讲一下;nan和Infinity是怎么产生的;以及怎么解决的吗
-
一般来说;Infinity大家好理解;就是说你就是太大了;通常来说;Infinity;通常是你学习率调的太大了造成的;或者你的权重初始的时候;你还没更新呢;你权重初始的时候那些值太大了;就导致你基本上就炸掉了;
-
nan是怎么出现的;nan一般就是除0;就把一个数除以一个0;那就是通常来就是说你;比如说你的梯度已经是很小了;然后你把梯度除了一个0;所以产生not number;
-
以及怎么解决解决的问题;其实怎么说呢;他要解决的话;一般来说;就通过我们今天介绍的一些技术有合理的初始化你的权重;然后你的激活函数你也不要选错;然后你的学习率也不要选太大;或一般来说你的学习率不要选太大;所以你如果碰到这个问题;你其实我建议最简单的做法是说;你把学习率调到比较小;一直往下调;直到你的infinity;或者nan不出现了;
-
第二个是说;你可以看一下你的权重的初始;不要选择那个;均值当然是等于0嘛;不要方差那个区间取的比较小一点;你一直往小走;走到你能够正确的出一些值;然后再慢慢的把它调大;使得它有训练有进展;
-
问题2∶使用ReLU激活函数是如何做到拟合x平方或者三次方这种曲线的?
-
其实我们不是用Relue来拟合一个东西;是Relu加上我们那些可以学的权重;来拟合平方或三次曲线;Relu唯一的干的事情;就是把线性给破坏掉了;大家可以去比如说B站上;重新看一下;我们在讲MLP的时候;多层感知机的时候讲过的;
-
问题3:老师,如果训练一开始,在验证集上准确率在提升,但是训着两个epoch之后,突然验证集上准确率就变成50%左右了之后稳定在50%,这是为什么呢?
-
一般是你的权重就坏掉了;就是说基本上50%就是权重;可能里面都是一些乱七八糟的词了;一般来说;你的就是数值稳定性出了问题;你怎么办呢;你可以尝试把学习率变小一点;但我觉得可能更本质的问题;如果你不能通过调学习率来解决;把学习率调小一点;不能通过解决问题的话;通常这个模型数值稳定性不行;很容易就跑歪了;就说我们之后会讲大量的模型;怎么样来使得更稳定;就是说大家说大家为什么用Resnet;为什么用为什么要这个;为什么要那个;其实绝大部分的;就是让你的训练更加稳定;就不会出现这个情况;
-
问题4∶老师,在训练的过程中,如果网络层的输出的中间层特征元素的值突然变成nan了,是发生了梯度爆炸了吗?还是有什么可能的原因?
-
对一般来说;lotter number就是因为梯度太大造成的;如果你去太小的话;就保证你根根本就称不动;就是发现就会平的;就没什么进展;所以一般;是一般是梯度的问题;
-
问题5:老师您好,我是初学者,当遇到一些复杂的数学公式,看文字描述也没有什么感觉,这个怎么突破一下呢?
-
这是个好问题;就是说;就深度学习的好处;就是说让你不要懂数学;也能够用很多东西;传统的机器学习像SVM也好;像别的也好;就是你需要有很多数学优化也好;有很多数学;深度学习说;你不用数学;你神经网络;反正可导就行了;可导我都可以给你求解;但是反过来讲;我觉得;虽然深度学习对数学要求低了;但是我觉得这东西你还是得学的;就是说你可以打个比方;你把人的数学能力和代码能力;代码能力就是说你深度学习你能调参会调;写代码很快;实现搞数据很快;做事情很快;就我们把这个称为代码能力的话;那么你的数学能力就是你的理解能力;
-
问题6∶老师,为什么对16位浮点影响严重? 32位或者64位就好了吗?那就是说所有通过fp16加速或者减小模型的方法都存在容易梯度爆炸或者消失的风险?
-
那就是说通过对是说你32位就会好一些;64位当然就更好了;所以传统的高性能计算;他们都是用64位的;就像Python;它的默认的数据类型是64位;32位是大家常用的;但是就说这是一个权衡
-
问题7︰梯度消失可以说是因为使用了sigmoid激活函数引起的对吗?所以我们可以用ReLU替换sigmoid解决梯度消失的问题?
-
sigmoid容易引起梯度消失;Relu确实对于这个东西解决比较好;但是;梯度消失不一定是指由sigmoid产生的;梯度消失可能有别的地方产生的;就是说sigmoid能引起但是它是一个;不是一个;充分必要的关系;tigmoid不仅仅是有sigmoid;可以让剃度消失的概率变低;但是我无法说;你一定是可以解决这个问题;
-
问题8:梯度爆炸式由什么激活函数引起的?
-
爆炸不会有激活函数。激活函数相对来说具有平滑的梯度,因为它是一个平滑的曲线,所以梯度问题通常不会太大。梯度爆炸一般是由于每一层的输出值太大,这可能导致梯度爆炸。
-
问题9:LSTM这里乘法变加法,这里乘法说的是梯度的更新的时候用的梯度的乘法是吗?
-
就LSTM里面;就是说LSTM通过指数和log和这种;这种操作单元;使得里面的;不不再是一个累成的一个东西了;my成我们之后会讲这个;这个东西;大家不一定要我就提到这个事情;我们之后肯定会讲;为什么会这样子;
-
问题10∶老师,为什么乘法变加法可以让训练更稳定?乘法本质上不就是多个加法么?以及如果加法能起作用,我们需要怎么做?训练用的网络就是resnet。。
-
这里提到乘法变成加法是指为什么将乘法操作替换为加法操作可以让训练过程更加稳定。这是因为乘法操作在数值上具有一些特性,当多个较大的数相乘时,它们的结果可能变得非常大,或者当多个较小的数相乘时,它们的结果可能变得非常小,这可能导致数值不稳定性。
举例来说,假设有100个数,每个数都是1.5,如果使用乘法将它们相乘,梯度可能会变得非常大或非常小,这可能导致训练问题。而如果将它们相加,结果将保持在较小的范围内,例如150,这会使数值更加稳定。
使用加法而不是乘法在计算机中也更容易处理,因为加法操作更加稳定,而且不容易出现数值溢出或下溢的问题。
因此,将乘法操作替换为加法操作可以在深度学习中提高数值稳定性,从而更好地支持训练过程。
-
问题11:老师,让每层方差是一个常数的方法,您指的是batch normalization吗?想问一下bn层为什么要有伽马和贝塔?去掉可以吗?
让每层的方差是一个常数;是;跟Bachelor没有太多关系;Bachelor sound what能够做一点东西;但是确实;我们之后会讲到;Bachelon到底是怎么回事;Bachelon可以让你的输出;它确实变成一个均值为0;方差为一个差不多;是有固定值的东西;但是它;我想想它不一定能保证你的梯度;所以Bachelon就是说;大家没有从这个角度来看过;Bachelor是干是不是干这个事情;我们之后讲到Bachelor时候;我们再回过头来看这个事情;就输出或者参数符合正态分布;有利学习;其实其实不是说;你需要是一个正态分布;从纯粹是说;我需要你的输出值;它在一个合理的区间里面;就说怎么你模拟怎么去;就怎么样去使得我的输出好去;用公式推理呢;就是我假设它是一个正态;我假设它是一个随机分布;随机分布比较容易算;均值和期望;所以我们就是说;假设你是个随机分布;但是你不一定是要正态;没关系就说只要你的;均值为0;方差为一个固定值就行了;就随便什么分布都行;大家之所以用正态分布;或者均匀分布的话;纯粹是因为;那个东西算起来比较容易;数学做比较容易;但实际上来说;你用什么都没关系;就随机初始化;XVA是一个不错的方案;不能说是最好;但是确实是很常用的方案;就说你;我不知道有最好或者最推荐的是什么;但我觉得大家如果没有更好的想法的;时候就用XVA就行了;梯度规划不是batch normalization;这个其实是不一样的东西;我们之后可以去再来讲这个事情;问题15是说;我们这个等高线;是不是可以可视化;哎这个东西也是个很好玩的问题;就是说对一个损失函数;可视化它那个面积是一个很难的问题;确实真的有research来做这个事情;大家如果感兴趣的话;可以就是早一点这个paper;但我确实没看到;特别特别好的方法;真的能把一个很复杂的一个函数;给你画出来;最简单情况下;我们就能画一个二维输入你;三维输入;你就就比较难画了;对吧你高维就没戏了;这是第一点;所以;这一块没有特别特别好的方法;但是确实有一些工研究工作;来可视化你这个损失函数的;一个一个等高线曲线;大家可以去搜一下;但是也还还比较原始;对就是说为;问题16是说;为什么我们要假设独立同分布;哎没没;就简单一点;就是为了简单起见;就是说如果你不是独立统分部;会怎么样;会不会相互影响;对不是独立同分布的话;一般来说还真的是;嗯;就是说它是条件;独立同分布;还真的可以这么假设;这个地方;虽然你就是说;内部协变量偏移;当然是说你其实之间有一定关系;但我觉得没必要在这个简单情况下;没必要做这个假设;反过来说一句就是bachelorminization;其实是说;就是有一个;他就是想说oh what;里面神经;网络里面有一个类;就是说类变的;有一个偶像性;我想把你解偶;就是Bachelor要干的事情;为什么假设每一层的权重是一个俯冲;一个独立统分布呢;因为这个是我们初始化;就我们其实说白了;刚刚说的;就是说;我在权重一开始的时候应该怎么做;就假设;我是觉得我这个是手动初始化出来的;结果就是说;刚刚那个分析;只能分析到在权重一开始的时候;怎么样;中间当然是不能;不能说是一个;独立统分布了;正态分布的假设有什么缺陷;为什么看上去是万能的;也不是万能的吧;正态分布做推导比较容易点;就这么点事情还写大数定理嘛;对吧大数定理;最后一切的一切都变成一个正态分布;就是说有另外问题20是说;有用一些很复杂的算法来进行;初始化权重或预值;其实我不知道;我不知道这个是什么样东西;就你可以研究嘛;这一块有很多工作;就我们就不这一展开了;就是说问题21是说;强制使得每一层的输出均值为0;方差为一;是不是损失了网络的表达能力;改变了数据的特征;降低了科学系的准确率;而这也没也没有;要其实也没有;就是说数值;就是说是一个区间;你把他拉到什么地方都没关系;就是说理解吗;就是说我的一个神经网络;我想让就是说;我只是让那个数值;在一个合理的区间里面表达;使数嘛;反正你你压小一点压大一点都没关系;这个区间是;使得我这个硬件处理起来比较容易;就是合适硬件的区间;从数学上来讲;我不管用什么区间;我做任何变化;都不会影响我的算;我的模型的课表达性;问题22为什么它可以;这个变化可以提高稳定性;它和就它其实没有它;其实是说做完这个变化之后;在零点附近;它近似于它的曲线;近似于呃;f x等于x这个函数;我们来另外一个;是要具体讲解下XV的初始化;针对于;这个是个好问题;这个这个是说你;其实我我理解你是想说;我们要实现一下这个函数吧;我今天肯定没有空来实现;我可以考虑一下;哪一天我们来回过头来讲一下我们;这个怎么实现;就反过来讲;如果我们就算不实现;你可以去看一下实;框架的实验;其实挺简单;就这么几句话;24激活函数有什么选择;那激活函数你叫redo吧;就是简单;一般权重是在每个epoch之后更新的嘛;权重是每一次迭代;每一个batch要更新;每个iterate要更新;epoch是说每次扫完数据;那个是已经更新过很多次了;我用的是Resnat;为什么还是会出;还是会出现数值稳定性问题;当然会出现了;就是说所有的这些技术是来缓解它;从来不是解决;就是resonator;你把能力read调到很大;一样的会出问题;因为我们有很多很多的方法;来缓解数字文的性能问题;你可认为整个深度学习这个进展都;;都是在让;数值更加稳定;你可以从这个很简单的;观点来考虑;所以;Resnet没有解决数值稳定性的问题;只是说;它确实比别的稳定性要好一点点;就是27是说;数值稳定性可能是模型结构引起的;如果觉得孪盛网络;孪盛网络什么;是那个two tower那个嘛;就两个嘛;两路输入不一样;会不会引起数值稳定性;会的就是说这也是个很好问题;我们没讲;就是说你有两类不一样的数据;然后呢你一类;比如说文本加图片嘛;文本进一个升级网络;图片进另外一个升级网络;最后我们要把它合起来;这里这里面最容易的;你是说你的文本和图片;你的数值区间不一样;你怎么做对吧;可能文本的输出很大数;图片输出很小;这时候你有很多种办法;bashlong是我们可以做的事情;但是确实这一块;通常来做的方法是通过于;两个两头通过一个权重;就说这一个的权重加一个权重;就说文本乘一个权重;加上图片;可能图片就不用权重;没关系然后调这个权重;使得这两块比较一样;我们可能会在呃style transformation;就是那个样式迁移里面会大概会讲到;这一块就是它里面也是有两步输入;强输入的话;一般是通过一个权重来使得每两类;两路的那个数值都在差不多的范围里;里面;问题28是说;我们主要做的是算法移植这种工程化;怎么样在模型设计和模型精度方面;有所突破呢;模型设计和模型精度;嗯;就我觉得模型的精;设计这是一个很大的问题;我觉得我在这里肯定是解决不了;讲不了太多事情;然后嗯我们来;嗯;我们今后会来;讲就是说不同的;这个这个很大的问题;我们只能说今后再碰到实际的;我们再讲;Resnat呀讲Transformer;讲RN也好;就说我们尽量去解释;他背后的设设计思路会怎么样;就尽量去解释;但是说;希望给大家会带来一些想法;但是说你问我说要要要怎么设计;这个太大了;我觉得这里回答不了;就是说;问题29;把每一层的输入的均值方差作限制;是不是可以理解成;限制各层输入值;出现极大或极小的异常值;他其实你也可以这么认为;就是说我把均值和方差做限值;可以理解成;如果你的方差;确实在一个很小的区间里面;那么出现几大值的概率就会变低;但是还是会有;但是会贬低;通常这些一两额外出现的极大致;不会影响太多;确实可以这么认为;;