
思维导图:


5.6.1 TCP可靠传输的实现笔记概述
在TCP/IP模型中,第5.6节讨论了TCP如何通过滑动窗口机制来实现可靠传输。以下是对本节内容的笔记概括,以及关键点的简化解释:
滑动窗口(Sliding Window)
-
基本概念:滑动窗口是TCP实现流量控制和可靠传输的关键机制,确保了发送方不会溢出接收方的缓冲区。
-
单向传输简化:为了讲解方便,我们假设数据传输只在A到B的单个方向上进行。
-
字节序号:每个字节都有序号,窗口的大小和位置决定了可以发送或确认的字节范围。
发送方A的发送窗口
-
窗口大小:由接收方B的确认和窗口通知决定,限制了A可以发送但尚未得到确认的数据量。
-
序号和确认:A根据B的确认移动窗口。窗口后沿不后移,因为确认不能撤销。
-
窗口移动:发送新数据或收到确认时窗口向前滑动,增加新的发送空间。
接收方B的接收窗口
-
窗口大小:B通过窗口大小告诉A,它有多少空间可用来接收数据。
-
序号确认:B只对按序到达的最高序号进行确认。
-
窗口移动:当B按序收到数据并交付给上层应用后,接收窗口向前滑动,可以接收新的数据。
重点和注意事项:
-
发送窗口:
- 后沿:已确认的数据,可以清除缓存。
- 前沿:标记了还可以发送的数据的结束位置。
- 不能收缩:标准不建议发送窗口前沿向后移动。
-
接收窗口:
- 按序接收:只有按序接收的数据可以确认和交付。
- 非序到达:先到的非序数据需要缓存,直到缺失数据到达。
-
窗口更新:
- 发送窗口更新:根据接收到的确认号和窗口大小更新。
- 接收窗口更新:按序接收数据后更新确认号和窗口位置。
-
三个指针(P1, P2, P3):
- P1:指向已确认数据的后一位。
- P2:指向已发送但未确认数据的后一位。
- P3:指向可发送但尚未发送数据的后一位。
-
有效窗口(P3-P1):当前可以发送的总字节数。
-
已发送但未确认(P2-P1):需要维持缓存以便可能的重传。
-
待发送空间(P3-P2):当前还可发送但尚未发送的字节数。
-
确认和窗口大小的动态变化:确认号和窗口大小会随着数据的接收和处理而动态改变。
通过上述笔记的精炼和简化,我们可以更清楚地掌握TCP可靠传输机制的工作原理。这是网络通信中确保数据正确传输的核心部分,理解它对于网络编程和故障排查至关重要。
我的理解:
-
滑动窗口机制:
- 滑动窗口是TCP实现流量控制和可靠传输的关键技术。
- 它允许发送方在停顿等待接收方确认之前连续发送多个数据包。
- 窗口大小决定了无需等待确认就可以发送的数据量,是动态调整的。
-
发送方和接收方的窗口:
- 发送方窗口:指示发送方基于接收方确认的数据和自身状态,可以发送的数据量。
- 接收方窗口:指示接收方当前能够接收并处理的数据量。
- 窗口大小会随着确认的接收而滑动,也就是“滑动窗口”。
-
字节序号:
- TCP为每一个字节分配一个序号。
- 序号用于保证数据的有序性和完整性。
- 发送方需维护已发送数据的序号,接收方用序号确认已接收数据。
-
发送窗口的位置和大小:
- 窗口位置由窗口的前沿和后沿确定。
- 窗口大小反映了在一定时间内,发送方能够发送但不需要接收方确认的数据量。
-
确认ACK:
- 接收方通过发送ACK(确认)报文,告诉发送方已经成功接收到的数据。
- ACK携带的确认号表示接收方期待接收的下一个序列号。
-
可用窗口或有效窗口:
- 指的是发送窗口内尚未发送的部分。
- 这部分数据是发送方在当前可以发送,但还没有发送的数据。
-
超时重传:
- 如果发送方没有在预定的超时时间内接收到确认,它会重传那些数据。
-
窗口的滑动:
- 窗口滑动是一个动态过程,随着数据的发送和确认,窗口会向前移动。
- 窗口向前滑动是为了给新的数据腾出空间,同时保证流量控制和数据的有序性。
-
网络拥塞和窗口调整:
- 发送窗口的大小不仅受接收方窗口大小的影响,还要考虑当前网络的拥塞状况。
- 网络拥塞可能会导致发送窗口减小,以减轻网络负担。
形象的解释:
-
滑动窗口机制: 比喻:想象一条河流(数据流)和河上的一座桥(网络连接)。桥上有一系列的闸门(滑动窗口)。闸门打开,河水可以流过;闸门关闭,河水停止。随着河水(数据)的流动,闸门会逐渐打开(窗口滑动),允许更多的河水通过。这个流程就像TCP控制数据包的发送一样。
-
发送方和接收方的窗口: 类比:可以将其看作是快递公司的发货和收货区。发货区(发送方窗口)决定了可以一次性打包多少个快递包裹发送出去;收货区(接收方窗口)决定了一次性可以接收和处理多少个包裹。
-
字节序号: 类比:给每本书(数据包)编号,这样即使在图书馆(网络)中乱放,也能重新按照顺序排列好。
-
发送窗口的位置和大小: 比喻:类似于你的视线(发送窗口)聚焦在一本书的一段文字(数据)。你的视线可以移动(窗口滑动),也可以变宽或变窄(窗口大小调整),让你一次看更多或更少的文字。
-
确认ACK: 类比:如果你发了一条信息给朋友,朋友的“已读”标记(ACK)就是确认,告诉你信息已被接收,你可以继续发送下一条信息。
-
可用窗口或有效窗口: 比喻:想象你的工作桌(发送窗口)上有一堆文件(数据)。其中只有桌子上的一部分文件是你即将处理的(可用窗口),其他的还在等待处理。
-
超时重传: 类比:如果你给朋友发短信,长时间没收到回复,你可能会再发一次,以确保朋友收到。这就像TCP重发一个数据包。
-
窗口的滑动: 比喻:想象你在观看电影剧照(数据)放在一个可移动的框架(窗口)里。当你移动框架来查看下一组剧照时,就像发送窗口随着确认的收到而滑动。
-
网络拥塞和窗口调整: 类比:如果道路(网络)上的车辆太多(数据过载),交通信号灯(TCP控制机制)会调整绿灯时间(窗口大小),让车辆更慢地通过,以防止交通堵塞。

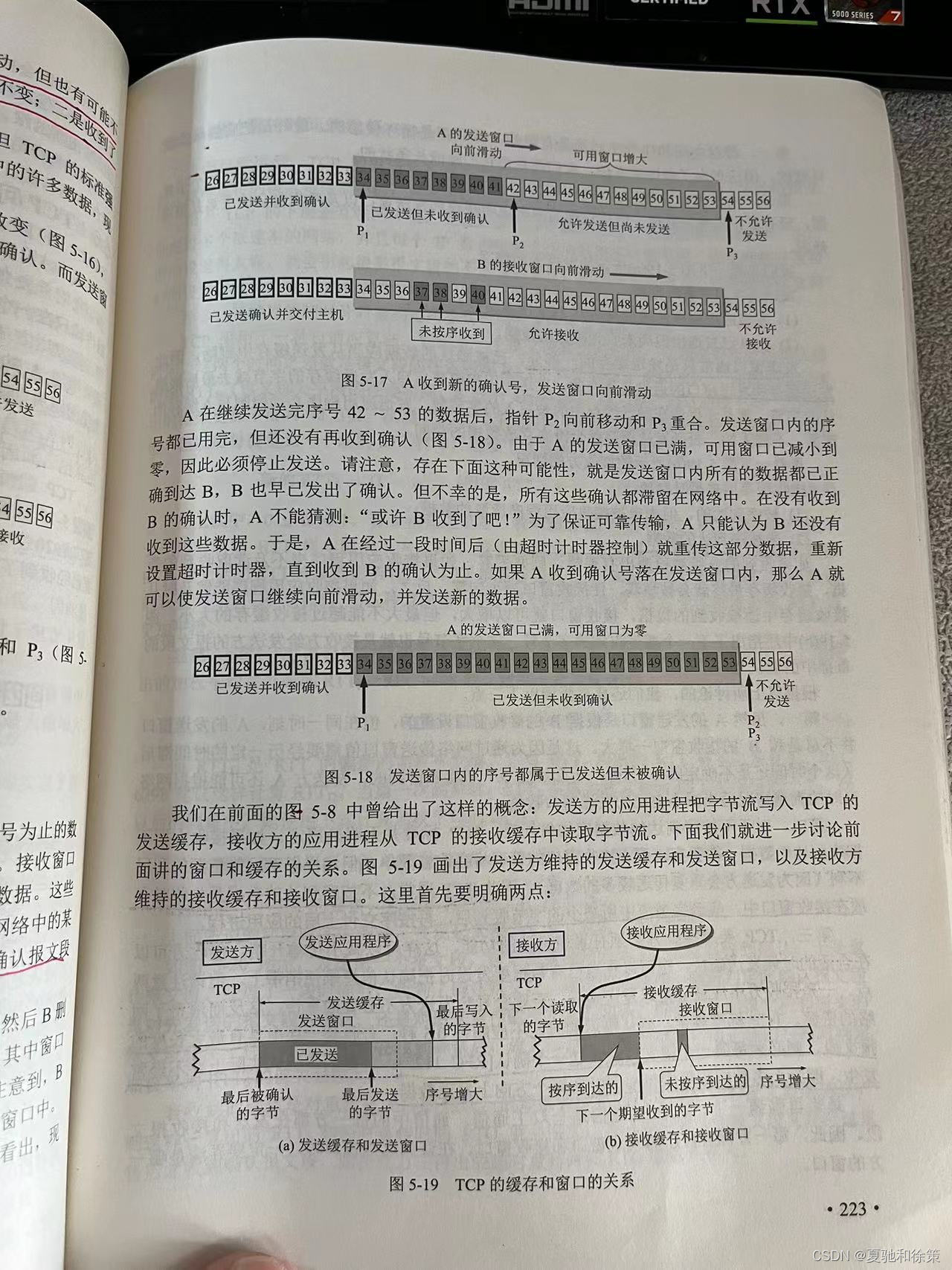
A的发送窗口和滑动
-
发送窗口的作用:
- 控制已发送但未收到确认的数据量,确保可靠传输。
- 滑动机制允许发送新的数据,同时等待老数据的确认。
-
窗口滑动的条件:
- 当A接收到B的确认号后,可以向前滑动发送窗口。
-
发送窗口满时的处理:
- 若未收到确认,窗口满意味着A必须停止发送新数据。
- 超时后,A将重传未确认的数据。
B的接收窗口和滑动
-
接收窗口的作用:
- 暂存已接收的数据,直到应用程序读取。
- 控制发送方的数据流,避免接收缓冲区溢出。
-
接收窗口的滑动:
- 当应用程序读取数据后,B的接收窗口向前滑动,可以接收更多数据。
TCP缓存和窗口关系
-
发送缓存:
- 存放由发送应用程序给TCP的待发送数据。
- 存放已发送但未收到确认的数据。
-
接收缓存:
- 存放已按序到达的数据。
- 存放未按序到达的数据。
其他要点
-
窗口大小的不一致性:
- A的发送窗口大小和B的接收窗口大小不总是一样的,受到网络延迟和拥塞控制的影响。
-
不按序数据的处理:
- TCP通常不会立即丢弃不按序的数据,而是等待缺失的数据到达后再一起传递给上层应用。
-
累积确认:
- 减少开销,但应避免延迟确认导致不必要的重传。
-
双向通信:
- TCP是全双工通信,每个方向都有发送和接收窗口。
我的理解:
-
发送窗口(Sliding Window):
- 这是TCP协议用来控制发送端发送数据的一种机制。
- 发送窗口的大小取决于接收端的接收能力(接收窗口告知的)和网络的拥塞情况。
- 窗口满意味着发送方已发送的数据达到了未被确认的极限,必须停止发送新数据直到收到确认。
- 发送窗口的向前滑动表示部分数据已被确认,可以发送新的数据。
-
接收窗口:
- 控制接收端可以接收的数据量,以避免接收缓冲区溢出。
- 接收窗口向前滑动表示数据已被应用程序读取,新的空间被释放用于接收更多数据。
-
TCP缓存:
- 发送缓存存储了待发送的数据以及已发送但未被确认的数据。
- 接收缓存则暂存已按序到达的数据和未按序到达的数据。
-
不按序数据处理:
- TCP不会立即丢弃乱序到达的数据,而是会缓存起来,直到缺失的数据到达,再整体顺序交付给应用程序。
-
累积确认:
- 为了减少网络传输开销,接收端不需要对每一个收到的数据包都立即发送确认,而是可以累积一定数据后再发送确认。
-
全双工通信:
- TCP支持数据在两个方向上同时传输,因此每个方向上都有自己的发送和接收窗口。
更加形象的理解:
-
发送窗口(Sliding Window):
- 想象一家快递公司,它的配送车辆容量有限,这个容量就像是TCP的发送窗口。配送车可以一次装载多少快递(数据包),就取决于车辆的容量(窗口大小)。如果配送车已经装满了还没有收到收件人的确认(数据包的确认),它就不能再装载更多快递,需要等待收件人确认收货后,车上空出位置来再装载新的快递。
-
接收窗口:
- 类比上面的例子,接收窗口就像收件人的仓库大小。如果仓库空间足够大,配送车可以连续送来更多的快递。如果仓库小或者满了,就需要告诉配送车暂时不要送来新的快递,等仓库中的快递被取走,仓库有了空间,才能接收新的快递。
-
TCP缓存:
- 发送缓存就像是配送中心的仓库,里面存放着待发的快递包裹以及已经发出但还没有确认送达的包裹。
- 接收缓存则像是收件人的待取区域,这里暂时存放着刚送到的快递,等待收件人从这里把快递取走。
-
不按序数据处理:
- 如果快递包裹不是按顺序到达的,比如收件人预期的是先到达编号为1、2、3的包裹,但实际上先到的是编号为3的包裹。收件人不会拒收编号为3的包裹,而是会先存起来,等编号为1和2的包裹到齐了,再一起处理。
-
累积确认:
- 收件人不需要每收到一个包裹就打电话确认,而是可以等积累了几个包裹后,再一次性确认收货,这样就减少了打电话的次数。
-
全双工通信:
- 在电话通话中,全双工通信就像两个人可以同时说话和听对方说话,没有必要等一个人说完另一个人才能说。在TCP通信中,数据的发送和接收也是这样,可以同时进行,而每一端都有自己的“说话”(发送窗口)和“听话”(接收窗口)能力。
5.6.2 超时重传时间的选择
核心概念:
- TCP重传机制:TCP发送方未在规定时间内收到确认会触发重传。
- 超时时间选择问题:关键在于平衡网络负载和传输效率,既不能过短也不能过长。
TCP自适应算法:
- 往返时间(RTT):报文段发出到确认收到的时间差。
- 平滑往返时间(RTTg):加权平均RTT,平滑因加权而更稳定。
- 超时重传时间(RTO):应略大于RTTg,考虑偏差。
重要公式:
-
加权平均RTT计算:新RTTs = (1-α) × 旧RTTs + α × 新RTT样本 (式 5-4)
- α推荐值:1/8,用于决定新旧RTT样本的影响程度。
-
超时重传时间计算:RTO = RTTg + 4 × RTTp (式 5-5)
- RTTp:RTT的偏差加权平均,考虑RTTs与新样本的差距。
-
RTT偏差加权平均计算:新RTTp = (1-β) × 旧RTTp + β × |RTTs - 新RTT样本| (式 5-6)
- β推荐值:1/4,用于平滑偏差。
实施复杂性:
- 无法直接判断确认报文是对原始报文段还是重传报文段的确认。
- 错误判断会导致RTTg和RTO偏差。
Karn算法:
- 对重传的报文段不采用其RTT样本进行RTTs计算。
- 若报文段重传,则翻倍RTO,直到传输稳定再根据式 5-5 计算。
- 此算法有助于区分有效与无效的RTT样本,改善估算。
结论: Karn算法的采纳改进了RTT估算,提高了超时重传时间的准确性和网络的整体效率
我的理解:
在TCP/IP网络通信中,"超时重传时间的选择"这个概念是指如何确定一个数据包(TCP报文段)从发送出去到判断为丢失(即超时)并进行重传的时间界限。正确地设置这个超时时间对于网络的性能至关重要,因为它直接影响到数据传输的效率和网络的负载。
理解这个概念的关键点包括:
-
动态网络条件:互联网上的数据传输可能会受到各种因素的影响,比如网络拥堵、路由变化、链路质量的波动等。因此,理想的超时重传时间应该能够适应这些动态变化的网络条件。
-
往返时间(RTT):RTT指的是一个数据包从发送到被接收方确认的时间。它是动态变化的,并且对于不同的网络路径可能差异很大。
-
过早超时和过晚超时的问题:
- 如果超时重传时间设置得太短,那么即使数据包只是稍微延迟,发送方也可能错误地认为它丢失了,从而进行不必要的重传,这会导致网络拥塞和资源浪费。
- 如果设置得太长,那么在数据包真正丢失的情况下,发送方等待的时间会过长,导致整体传输效率低下。
-
自适应算法:TCP使用自适应算法来动态调整超时重传时间。这个算法会根据最近的RTT测量值来调整预期的RTT,以及根据测量到的RTT波动来设置超时时间。
-
平滑往返时间(Smoothed RTT, RTTg)和RTT偏差(RTTp):为了更精确地估计RTT,TCP保留了RTT的加权平均值(RTTg)和其变化量(偏差RTTp)。这两个值被用来计算超时重传时间,以适应网络条件的变化。
-
Karn算法:这是一种特定的算法,它解决了在一个报文段被重传后如何正确计算RTT的问题。简而言之,当一个报文段经历了重传,它的RTT样本不会被用来更新加权平均RTT,这是因为重传报文段的确认不能准确反映网络的当前状态。
综上所述,"超时重传时间的选择"涉及到基于当前网络状况和过去的经验来预测最佳的重传时间点,以此优化TCP网络性能。这个选择需要在减少不必要重传(增加网络拥塞)和减少等待时间(提高效率)之间找到一个平衡点。

SACK笔记 - 5.6.3 选择确认(SACK)
问题引入:
- 在TCP通信中,如果接收方收到的数据包序号不连续,即数据流中缺少某些序号的数据包,我们怎么只重传这些丢失的数据包,而不是所有已接收的数据包?
SACK的目的:
- 优化数据重传过程,减少不必要的网络负担。
- 确保只有丢失的数据包被重传,而不是所有按顺序排列之后的数据包。
工作原理:
- 当接收方收到不连续的数据时,它会通过SACK选项告知发送方哪些数据已经收到。
- 接收方在确认响应中指明已收到数据块的边界,即使这些数据块之间存在缺失的数据包。
- SACK允许接收方精确地告诉发送方哪些数据需要被重传。
实际例子:
- 如图5-21所示,接收方可能收到序号为1~1000的数据块,然后是1501~3000,再然后是3501~4500,但中间的1001~1500和3001~3500的数据块没有收到。
- 接收方将通过确认号(如确认号=1001)和SACK选项报告已接收的数据块边界(如L₁=1501, R₁=3001; L₂=3501, R₂=4501)。
TCP头部的SACK选项:
- 在TCP连接建立时,需要在TCP头部选项中添加“允许SACK”的选项。
- SACK选项会随后在TCP报文段中携带,报告不连续的数据块边界。
- 由于TCP头部选项字段长度限制,最多只能报告4个不连续的数据块边界。
注意点:
- SACK并没有具体指明发送方如何响应,所以不同的TCP实现可能有不同的处理方式。
- 通常实现会选择只重传确实丢失的数据块,但有些实现可能会重传所有未被确认的数据块。
限制:
- TCP头部选项字段长度最多40字节,每个边界需要4字节。
- 因此,如果超出这个长度限制,不可能报告超过4个数据块的边界信息。
参考标准:
- RFC 2018定义了SACK选项的格式和行为规范。
我的理解:
选择确认(Selective Acknowledgement,简称SACK)是TCP协议中的一个重要特性,它允许接收方明确告知发送方哪些数据已经被成功接收。在没有SACK的情况下,TCP使用累积确认(Cumulative Acknowledgement),其中的确认号指向的是到目前为止接收方已连续收到的最高字节序号加一。这意味着如果中间有数据丢失,即使之后的数据包已经到达,接收方也不能确认这些数据包,导致发送方不得不重传所有之后的数据,即便有些数据其实是已经成功接收的。
SACK的工作原理,可以这样理解:
-
TCP报文段的接收:接收方接收到发送方的数据报文段,但是这些报文段是不连续的。也就是说,一些数据报文段由于网络问题等原因没有到达接收方。
-
发送SACK选项:在确认回复中,接收方不仅发送下一个期望字节的序号(也就是缺失数据块的起始序号),还通过SACK选项指出它已经接收到的不连续的数据块的边界信息。
-
报文段的重传:发送方根据接收到的SACK信息了解到中间丢失的数据块,并且只重传那些未被确认接收的数据块,而不是重传所有的数据。
这样的机制显著提高了网络效率,尤其是在高延迟或丢包率高的网络环境下。然而,正如你所引用的文本中提到的,SACK只是指明了哪些数据被成功接收了,并没有具体指明发送方应该如何响应SACK信息。因此,不同的TCP实现可能会有不同的策略来响应SACK。一些实现可能会优化重传策略,只发送那些确实丢失的数据块,而有些实现可能仍然会发送所有尚未确认的数据。
此外,由于TCP头部选项字段的长度限制,SACK可以报告的不连续数据块边界信息是有限的。如果有多个不连续的数据块,SACK可能不能报告所有的边界信息,因此通常会报告最近的几个数据块。
RFC 2018为SACK的格式和行为提供了规范,但在实践中,如何有效利用SACK信息取决于TCP的具体实现。



总结:
重点:
-
序号和确认号:每个TCP段都有序号,它确认了数据的顺序,并确保数据能够按序到达和重组。
-
重传机制:当确认应答超时未到或接收到重复段时,TCP会重传丢失或错误的数据段。
-
流量控制:通过滑动窗口机制,接收方可以控制发送方的发送速度,避免接收方缓冲区溢出。
-
拥塞控制:TCP通过慢启动、拥塞避免、快重传和快恢复算法来控制网络拥塞。
-
选择性确认(SACK):SACK允许接收方告知发送方哪些数据是已经收到的,使得发送方只需要重传真正丢失的数据段。
-
有序重传:确保即使在网络条件不理想的情况下,数据也以正确的顺序被交付给应用层。
难点:
-
窗口大小的动态调整:如何根据网络状况(如延迟、带宽)调整滑动窗口的大小。
-
超时计时器的设定:选择合适的重传超时时间,既要避免过早重传,也要避免过晚重传。
-
拥塞控制算法的理解和实现:理解慢启动、拥塞避免、快重传等算法的细微差别及其在各种网络情况下的表现。
-
SACK的实现和优化:在SACK的帮助下准确地重传那些实际上丢失的数据包。
易错点:
-
滑动窗口的错误处理:错误地管理滑动窗口可能导致数据流失序或重复。
-
超时和重传策略:设置不恰当的重传计时器会导致性能问题。
-
SACK的误用:在SACK的实现不当时,可能会误告发送方哪些数据被接收,导致不必要的重传。
-
拥塞窗口的管理:在拥塞控制时,错误地增加或减少拥塞窗口大小,会导致网络利用率下降或过度拥塞。
-
忽略网络变化:在拥塞控制中,如果没有根据网络状态变化动态调整策略,可能会导致性能不稳定。






![[概述] 获取点云数据的仪器](https://img-blog.csdnimg.cn/a2782c674f8146d4b7e58c4c1c2e9acd.png)



