0. 简介
强化学习在自动驾驶中的应用已经日渐普及,虽然由于一些伦理问题,目前真正的使用这种强化学习的还不是很多,但是目前已经有很多应用在自动驾驶中的强化学习的工作,但是我们发现这类方法基本都是将卷积编码器与策略网络一起训练,然而,这种范式将导致环境表示与下游任务不一致,从而可能导致次优的性能。而《RLAD: Reinforcement Learning from Pixels for Autonomous Driving in Urban Environments》一文提出了若干技术来增强RLfP算法在该领域的性能,包括:i)利用图像增强和自适应局部信号混合(A-LIX)层的图像编码器;ii)WayConv1D是一种路径点编码器,其使用1D卷积来利用路径点的2D几何信息;iii)辅助损失来增加交通信号灯在环境的隐层表示中的重要性。下面我们来详细看一下。
1. 主要贡献
本文的主要贡献总结如下:
1)本文提出了RLAD,这是首个在基于视觉的城市自动驾驶(AD)领域中使用增强学习(RL)同时学习编码器和驾驶策略网络的方法。本文还表明RLAD在该领域中显著优于所有最先进的RLfP方法;
2)本文引入了一种图像编码器,该编码器利用图像增强和自适应局部信号混合(ALIX)层来最小化编码器的严重过拟合;
3)本文提出了WayConv1D,它是一种路径点编码器,使用2x2内核的1D卷积来利用路径点的2D几何信息,这显著提高了驾驶的稳定性;
4)本文对基于视觉的城市自动驾驶(AD)领域中最先进的RLfP进行了全面的分析,其中我们表明主要的挑战之一为遵守交通信号灯。为了解决这一限制,在图像的隐层表示中加入专门针对交通信号灯信息的辅助损失,从而增强了其重要性。
2. RLAD综述
RLAD是首个应用于城市自动驾驶领域的RLfP方法。其主要目的是从传感器数据中推导出一个与驾驶任务完全对齐的特征表示,同时学习驾驶策略。RLAD的核心基于DrQ [11]构建,但进行了几处修改。首先,在图像增强的基础上,我们还在图像编码器的每个卷积层末尾添加了一个正则化层,称为自适应局部信号混合(ALIX)[12](更多细节见第4节),这显著提高了训练的稳定性和效率。其次,我们对最佳超参数进行了广泛研究,发现DrQ的某些超参数并不适用于AD领域。最后,我们使用了额外的交通信号灯分类损失,以指导图像的潜在表示( i ‾ \overline{i} i)包含有关交通信号灯的信息。
3. 学习环境
学习环境被定义为部分可观察的马尔可夫决策过程(POMDP)。该环境是通过使用CARLA驾驶模拟器(版本0.9.10.1)[27]构建的。 a)状态空间: S S S由CARLA定义,包含有关世界的真实信息。代理无法访问环境状态。
b)观察空间:在每个步骤中,状态 s t ∈ S s_t ∈ S st∈S生成相应的观察 o t ∈ O o_t ∈ O ot∈O,并传递给代理。一个观察是最后K个时间步长的 K = 3 K = 3 K=3个张量集的堆叠。具体来说, o t = { ( I , W , V ) k } k = 0 2 o_t = \{(I,W,V)_k\}^2_{k=0} ot={(I,W,V)k}k=02,其中: I I I是一个3×256×256的图像, W W W对应于与车辆相关的2D坐标,用于从CARLA提供的全局规划器中提供的下一个 N = 10 N = 10 N=10个路标, V V V对应于包含当前速度和车辆转向的二维向量。
c)动作空间: A A A由三个连续动作组成:油门,范围从0到1;刹车,范围从0到1;和转向,范围从-1到1。
d)奖励函数:我们使用[28]中定义的奖励函数,因为已经证明它可以准确地指导AD训练。
e)训练:我们以10 FPS的速度使用CARLA。类似于[28],在每个场景的开始,起始和目标位置是随机生成的,并使用全局规划器计算所需的路线。当到达目标位置时,会计算一个新的随机目标位置。如果满足以下任何条件之一,则终止该场景:碰撞、闯红灯、阻塞或达到预定义的超时。
4. 代理架构(重点内容)
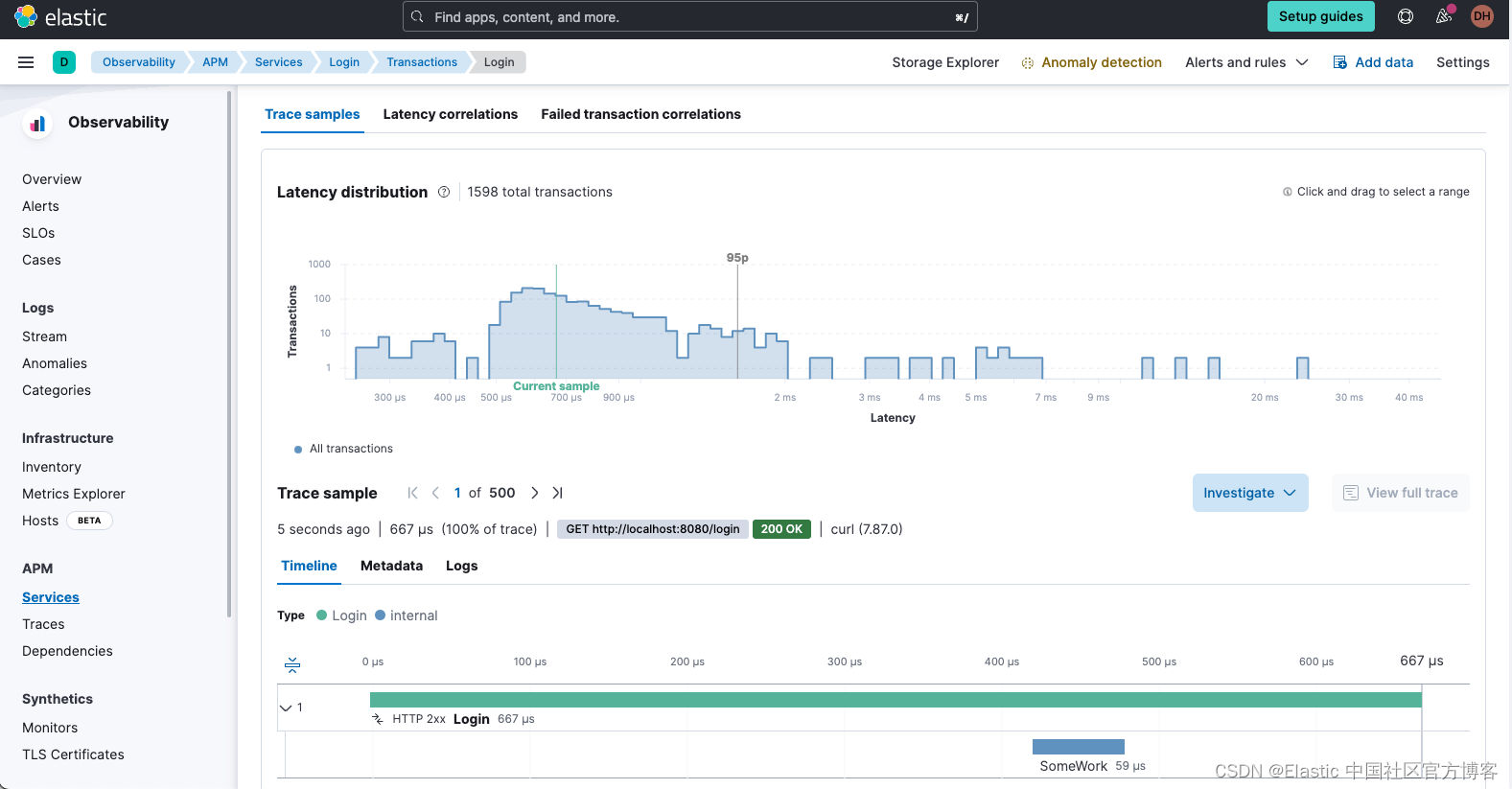
RLAD的架构如图1所示。一般来说,我们的系统有三个主要组件:编码器(第4.1节),强化学习算法(第4.2节)和辅助损失(第4.3节)。为了简化纵向控制并确保平稳控制,我们重新参数化节流阀和刹车指令,使用目标速度。因此,在actor网络的末端附加了一个PID控制器,它产生相应的节流阀和刹车指令,以匹配预测的目标速度。
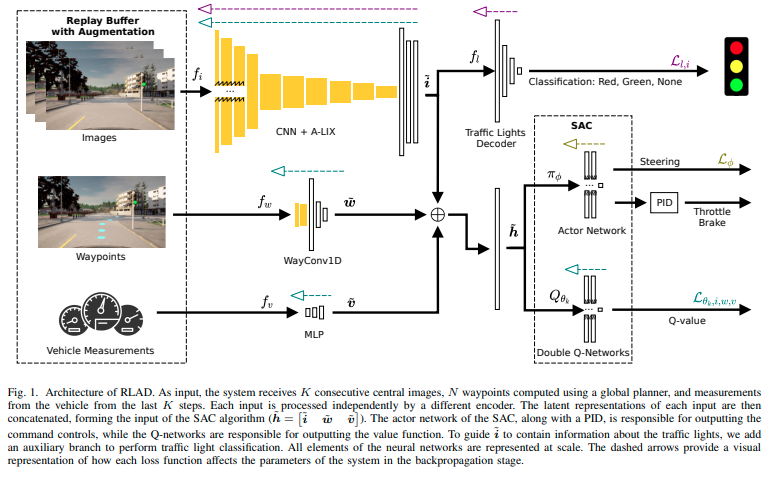
图1. RLAD的架构。系统接收K个连续的中心图像、使用全局规划器计算的N个航点以及车辆在最近K个步骤中的测量作为输入。每个输入都由不同的编码器独立处理。然后将每个输入的潜在表示连接起来,形成SAC算法的输入 ( h ~ = i ~ w ~ v ~ ) (\tilde{h} =\tilde{i} \tilde{w} \tilde{v}) (h~=i~w~v~)。SAC的演员网络以及PID负责输出命令控制,而Q网络负责输出价值函数。为了指导 i ~ \tilde{i} i~包含关于交通信号灯的信息,我们添加了一个辅助分支来执行交通信号灯分类。神经网络的所有元素都以比例表示。虚线箭头提供了每个损失函数如何影响系统参数的可视化表示,在反向传播阶段。
4.1编码器:
编码器负责将传感器数据( o t o_t ot)转换为低维特征向量( h ‾ t \overline{h}_t ht),以供强化学习算法处理。
a)图像编码器:正如在[11]中展示的那样,图像编码器的大小是RLfP方法中的关键要素。由于RL损失的信号较弱,常用于AD方法的编码器,如ResNet50 [29](约25M参数)或Inception V3 [30](约27M参数),不可行。另一方面,针对较小复杂度场景设计的小型编码器,如IMPALA [31](约0.22M参数),无法产生足够准确的环境表示,从而限制了驾驶代理的性能。对于城市AD,我们的研究结果表明,最佳配置涉及大型网络和小型网络之间的权衡,大型网络不适合使用RL进行训练,而小型网络无法准确感知环境。所提出的图像编码器的架构如表I所示,包含约1M个参数。与DrQ和DrQ-V2类似,我们利用简单的图像增强技术来规范化价值函数[11],[25]。首先,我们对256×256图像的每一侧应用填充,重复8个边界像素,然后选择256×256的随机裁剪。与[25]一样,我们发现在裁剪的图像上应用双线性插值很有用。除了图像增强技术之外,我们还发现,在每个卷积层的末端附加A-LIX层[12]可以提高代理的性能,可能是通过防止一种称为灾难性自我过拟合的现象(导致反向传播中梯度不连续的空间不一致的特征图)来实现的。A-LIX应用于卷积层产生的特征 a ∈ R C × H × W a ∈ \mathbb{R}^{C×H×W} a∈RC×H×W,随机混合每个组件 a c i j a_{cij} acij与属于同一特征图的其邻居。因此,A-LIX的输出与输入具有相同的维度,但不同之处在于计算图最小程度地干扰每个特征 a c i j a_{cij} acij的信息,同时在反向传播期间平滑不连续的梯度信号的组件。因此,该技术的工作原理是强制图像编码器生成具有空间一致性的特征图,从而最小化灾难性的自我过拟合现象的影响。这个过程可以简洁地总结为 i ‾ t = f i ( a u g ( [ { I t − k } k = 0 2 ] ) ) \overline{i}_t = f_i(aug([\{I_{t−k}\}^2_{k=0}])) it=fi(aug([{It−k}k=02])),其中 f i f_i fi 是图像编码器,aug 对应于应用的数据增强,而 i ‾ t \overline{i}_t it 对应于三个连续图像 ( { I t − k } k = 0 2 ) (\{I_{t−k}\}^2_{k=0}) ({It−k}k=02)的潜在表示。
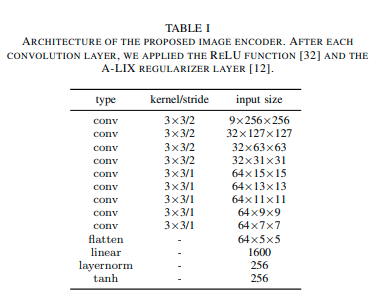
所提出的图像编码器的架构。在每个卷积层之后,我们应用了RELU函数[32]和A-LIX正则化层[12]。
b) Waypoint Encoder: 通常,waypoint编码器由使用当前agent姿态和下一个 N N N 个waypoints [9]之间的平均方向,或将waypoints的2D坐标展平为向量并应用MLP [33]组成。在我们看来,两种方法都有严重的局限性。前一种方法通过将所有waypoint坐标编码为单个值,明显过于简化问题。这种方法仅适用于较小的N值,因为随着 N N N的增加,waypoints变得更加分散,因此平均方向不再是可靠的指标。虽然后一种方法适用于所有 N N N值,但通过将2D waypoint坐标展平为向量,未使用2D几何信息。为了克服这两个局限性,我们提出了WayConv1D,一种waypoint编码器,它通过在下一个N个waypoints的2D坐标上应用2×2内核的1D卷积来利用输入的2D几何结构。 1D卷积的输出然后被展平并通过MLP进行处理。这个过程可以总结为 w ~ t = f w ( W t ) \tilde{w}_t = f_w(W_t) w~t=fw(Wt),其中 f w f_w fw对应于WayConv1D, w ~ t \tilde{w}_t w~t对应于当前步骤( W t W_t Wt)的waypoints的潜在表示。我们发现,使用WayConv1D,agent学习更有效地跟随轨迹,而不会在车道中心附近振荡。这是在城市AD领域中利用RL时遇到的常见问题,正如在以前的研究中所记录的[6],[28]。
c)车辆测量编码器:与[33]类似,我们对车辆测量应用一个多层感知器(MLP): v ~ t = f v ( [ { V t − k } k = 0 2 ] ) \tilde{v}_t = f_v([\{V_{t−k}\}^2_{k=0}]) v~t=fv([{Vt−k}k=02]),其中 f v f_v fv是MLP, v ~ t \tilde{v}_t v~t对应于车辆测量在三个步骤中的串联的潜在表示 ( [ { V t − k } k = 0 2 ] ) ([\{V_{t−k}\}^2_{k=0}]) ([{Vt−k}k=02])。