openGauss-向量化执行引擎系列-VecUnique算子
openGauss实现了向量化执行引擎,达到算子级别的并行。也就是说在执行器火山模型基础上,一次处理一批数据,而不是一次一个元组。这样可以充分利用SIMD指令进行优化,达到指令级别并行。前期我们介绍了PgSQL Unique算子的实现机制,本文接着介绍openGauss是如何实现Unique算子向量化的。
简单来说,openGauss的VecUnique算子更多的是为了实现执行器整体性的向量化,减少算子之间因为向量化和非向量化算子之间的兼容而进行的VecToRow和RowToVec算子进行的行与向量之间的转换而完成的。实际上VecUnique算子进行唯一值挑选的时候,仍旧是一个一个值比较的,只不过从子节点拿上来一批值VectorBatch,然后从VectorBatch里面一个值一个值的比较。当然,这样做的优点:减少子节点算子函数调用次数。
1、VecUniqueState
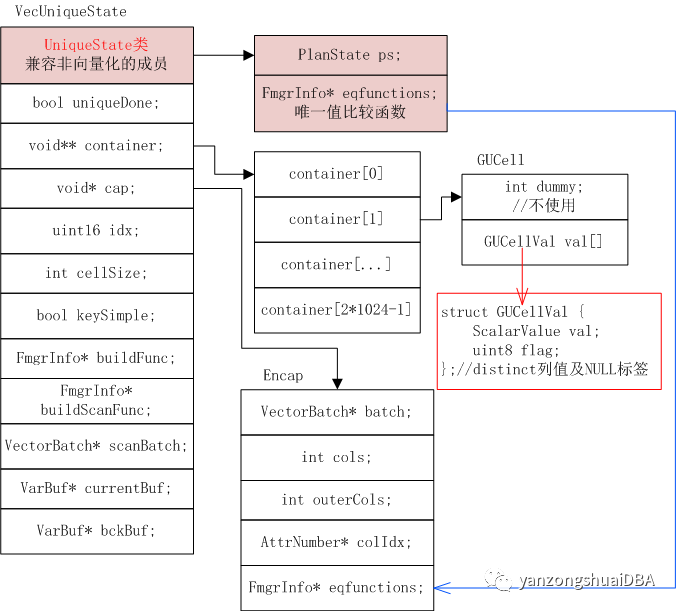
完成VecUnique算子的主要成员变量:
1)uniqueDone:标记VecUnique算子是否执行完
2)container[]数组:数组大小为2个batch大小即2+1024,存储GUCell结构,即唯一值及其NULL标签
3)cap:即Encap结构,封装VectorBatch、cols和colIdx,减少传递参数个数
4)idx:container[]数组中存储的唯一值个数,即GUCell个数
5)cellSize:GUCell大小
6)keySimple:distinct列是否是8字节以内,若8字节以内,则为true表示可以直接进行值比较;若大于8字节则需要通过函数进行比较了
7)buildFunc:用于从VectorBatch中挑出唯一值,存储到container[]数组
8)buildScanFunc:从container[]数组中取出1024条,组成一个VectorBatch输出
2、buildFunc

这里关注buildScanFunc和buildFunc两个函数。
为什么*idx >=1024才进行处理呢?这都已经有1025条,已超过VectorBatch最大大小了。
这针对的是跨batch的场景:

batch1中最后一个是10,batch2中第一个是10,假设batch1中的都是不同值,则需要将batch2的第一个值10也存入container[1025]数组后才进入构建scanBatch的逻辑,这样仅输出1024行,将container[1025]以到container[0],然后才将container[1025]置为NULL。这样才能在下一轮有值可比较。否则由于batch2的10是第一个值,没比较的值,就将其也当作唯一值输出了。
BuildFunc
1)针对子节点取的VectorBatch batch,对每一行进行处理
2)第一轮batch第一行取出,作为唯一值存储到container[i],i=0;
3)后续的值和container[i]进行比较,若相等,则继续batch下一条进行比较,否则作为唯一值存入container[++i]
4)当container[]存入了1025条时,切换currentBuf和bckBuf,以便ExecVecUnique下个迭代可以重置bckBuf回收内存
buildScanFunc
这个函数就比较简单了,从container[]数组取出1024条,构建到scanBatch中,然后进行输出即可。