目录
- 一、Azure环境准备
- 二、计算目标设置
- 三、试验设置
- 四、直观呈现输入数据
- 五、上传数据并创建 MLTable
- 六、配置物体检测试验
- 适用于图像任务的自动超参数扫描 (AutoMode)
- 适用于图像任务的手动超参数扫描
- 作业限制
- 七、注册和部署模型
- 获取最佳试用版
- 注册模型
- 配置联机终结点
- 创建终结点
- 配置联机部署
- 创建部署
- 更新流量
- 八、测试部署
- 九、直观呈现检测结果
- 十、清理资源
本教程介绍如何通过 Azure 机器学习 Python SDK v2 使用 Azure 机器学习自动化 ML 训练物体检测模型。 此物体检测模型可识别图像是否包含对象(如罐、纸箱、奶瓶或水瓶)。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

一、Azure环境准备
-
若要使用 Azure 机器学习,你首先需要一个工作区。 如果没有工作区,请完成创建开始使用所需的资源以创建工作区并详细了解如何使用它。
-
此功能支持 Python 3.6 或 3.7
-
下载并解压缩 odFridgeObjects.zip 数据文件*。 数据集以 Pascal VOC 格式进行注释,其中每个图像对应一个 xml 文件。 每个 xml 文件都包含有关其对应图像文件所在位置的信息,还包含有关边界框和对象标签的信息。 若要使用此数据,首先需要将其转换为所需的 JSONL 格式,如笔记本的将下载的数据转换为 JSONL 部分中所示。
-
使用计算实例来学习本教程,无需安装其他软件。 (请参阅如何创建计算实例。)或者安装 CLI/SDK 以使用你自己的本地环境。
-
适用于:Python SDK azure-ai-ml v2(当前版本)
使用以下命令安装 Azure 机器学习 Python SDK v2:
卸载以前的预览版:
pip uninstall azure-ai-ml
安装 Azure 机器学习 Python SDK v2:
pip install azure-ai-ml azure-identity
二、计算目标设置
首先需要设置用于自动化 ML 模型训练的计算目标。 用于图像任务的自动化 ML 模型需要 GPU SKU。
本教程将使用 NCsv3 系列(具有 V100 GPU),因为此类计算目标会使用多个 GPU 来加速训练。 此外,还可以设置多个节点,以在优化模型的超参数时利用并行度。
以下代码创建一个大小为 Standard_NC24s_v3 的 GPU 计算,其中包含四个节点。
from azure.ai.ml.entities import AmlCompute
compute_name = "gpu-cluster"
cluster_basic = AmlCompute(
name=compute_name,
type="amlcompute",
size="Standard_NC24s_v3",
min_instances=0,
max_instances=4,
idle_time_before_scale_down=120,
)
ml_client.begin_create_or_update(cluster_basic)
稍后在创建特定于任务的 automl 作业时会用到此计算。
三、试验设置
可以使用试验来跟踪模型训练作业。
稍后在创建特定于任务的 automl 作业时会用到此试验名称。
exp_name = "dpv2-image-object-detection-experiment"
四、直观呈现输入数据
以 JSONL(JSON 行)格式准备好输入图像数据后,就可以直观呈现图像的地面实况边界框。 若要执行此操作,请确保你已安装 matplotlib。
%pip install --upgrade matplotlib
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import matplotlib.patches as patches
from PIL import Image as pil_image
import numpy as np
import json
import os
def plot_ground_truth_boxes(image_file, ground_truth_boxes):
# Display the image
plt.figure()
img_np = mpimg.imread(image_file)
img = pil_image.fromarray(img_np.astype("uint8"), "RGB")
img_w, img_h = img.size
fig,ax = plt.subplots(figsize=(12, 16))
ax.imshow(img_np)
ax.axis("off")
label_to_color_mapping = {}
for gt in ground_truth_boxes:
label = gt["label"]
xmin, ymin, xmax, ymax = gt["topX"], gt["topY"], gt["bottomX"], gt["bottomY"]
topleft_x, topleft_y = img_w * xmin, img_h * ymin
width, height = img_w * (xmax - xmin), img_h * (ymax - ymin)
if label in label_to_color_mapping:
color = label_to_color_mapping[label]
else:
# Generate a random color. If you want to use a specific color, you can use something like "red".
color = np.random.rand(3)
label_to_color_mapping[label] = color
# Display bounding box
rect = patches.Rectangle((topleft_x, topleft_y), width, height,
linewidth=2, edgecolor=color, facecolor="none")
ax.add_patch(rect)
# Display label
ax.text(topleft_x, topleft_y - 10, label, color=color, fontsize=20)
plt.show()
def plot_ground_truth_boxes_jsonl(image_file, jsonl_file):
image_base_name = os.path.basename(image_file)
ground_truth_data_found = False
with open(jsonl_file) as fp:
for line in fp.readlines():
line_json = json.loads(line)
filename = line_json["image_url"]
if image_base_name in filename:
ground_truth_data_found = True
plot_ground_truth_boxes(image_file, line_json["label"])
break
if not ground_truth_data_found:
print("Unable to find ground truth information for image: {}".format(image_file))
对于任何给定的图像,利用上述帮助程序函数,可以运行以下代码来显示边界框。
image_file = "./odFridgeObjects/images/31.jpg"
jsonl_file = "./odFridgeObjects/train_annotations.jsonl"
plot_ground_truth_boxes_jsonl(image_file, jsonl_file)
五、上传数据并创建 MLTable
为了将数据用于训练,请将数据上传到 Azure 机器学习工作区的默认 Blob 存储并将其注册为资产。 注册数据的好处包括:
- 便于与团队其他成员共享
- 对元数据(位置、描述等)进行版本控制
- 世系跟踪
# Uploading image files by creating a 'data asset URI FOLDER':
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import Input
my_data = Data(
path=dataset_dir,
type=AssetTypes.URI_FOLDER,
description="Fridge-items images Object detection",
name="fridge-items-images-object-detection",
)
uri_folder_data_asset = ml_client.data.create_or_update(my_data)
print(uri_folder_data_asset)
print("")
print("Path to folder in Blob Storage:")
print(uri_folder_data_asset.path)
下一步是使用 jsonl 格式的数据创建 MLTable,如下所示。 MLtable 会将数据打包为一个可供训练使用的对象。
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
可以使用以下代码从训练和验证 MLTable 创建数据输入:
# Training MLTable defined locally, with local data to be uploaded
my_training_data_input = Input(type=AssetTypes.MLTABLE, path=training_mltable_path)
# Validation MLTable defined locally, with local data to be uploaded
my_validation_data_input = Input(type=AssetTypes.MLTABLE, path=validation_mltable_path)
# WITH REMOTE PATH: If available already in the cloud/workspace-blob-store
# my_training_data_input = Input(type=AssetTypes.MLTABLE, path="azureml://datastores/workspaceblobstore/paths/vision-classification/train")
# my_validation_data_input = Input(type=AssetTypes.MLTABLE, path="azureml://datastores/workspaceblobstore/paths/vision-classification/valid")
六、配置物体检测试验
若要为图像相关任务配置自动化 ML 作业,请创建特定于任务的 AutoML 作业。
# Create the AutoML job with the related factory-function.
image_object_detection_job = automl.image_object_detection(
compute=compute_name,
experiment_name=exp_name,
training_data=my_training_data_input,
validation_data=my_validation_data_input,
target_column_name="label",
primary_metric=ObjectDetectionPrimaryMetrics.MEAN_AVERAGE_PRECISION,
tags={"my_custom_tag": "My custom value"},
)
适用于图像任务的自动超参数扫描 (AutoMode)
在 AutoML 作业中,可以执行自动超参数扫描,以查找最佳模型(我们将此功能称为 AutoMode)。 你将仅指定试用次数;不需要超参数搜索空间、采样方法和提前终止策略。 系统会自动根据试用次数确定要扫描的超参数空间的区域。 介于 10 到 20 之间的值可能适用于许多数据集。
然后,你可以提交作业来训练图像模型。
将 AutoML 作业配置为所需的设置后,就可以提交作业了。
# Submit the AutoML job
returned_job = ml_client.jobs.create_or_update(
image_object_detection_job
) # submit the job to the backend
print(f"Created job: {returned_job}")
适用于图像任务的手动超参数扫描
在 AutoML 作业中,可以使用 model_name 参数指定模型体系结构,并配置设置以对定义的搜索空间执行超参数扫描,以查找最佳模型。
在本示例中,我们将使用 yolov5 和 fasterrcnn_resnet50_fpn 训练一个物体检测模型,这两者都在 COCO 上预先进行了训练,COCO 是一个大规模物体检测、分段和字幕数据集,其中包含 80 多个标签类别的数千个带标签的图像。
可以对已定义的搜索空间执行超参数扫描,以查找最佳模型。
作业限制
可以通过在限制设置中为作业指定 timeout_minutes``max_trials 和 max_concurrent_trials 来控制 AutoML 映像训练作业上花费的资源。 请参阅有关作业限制参数的详细说明。
# Set limits
image_object_detection_job.set_limits(
timeout_minutes=60,
max_trials=10,
max_concurrent_trials=2,
)
以下代码定义了搜索空间,准备对每个已定义的体系结构 yolov5 和 fasterrcnn_resnet50_fpn 进行超参数扫描。 在搜索空间中,指定 learning_rate、optimizer、lr_scheduler 等的值范围,以便 AutoML 在尝试生成具有最佳主要指标的模型时从中进行选择。 如果未指定超参数值,则对每个体系结构使用默认值。
对于优化设置,通过使用 random sampling_algorithm,借助随机抽样从此参数空间中选取样本。 上面配置的作业限制可以让自动化 ML 尝试使用这些不同样本总共进行 10 次试验,在使用四个节点进行设置的计算目标上一次运行两次试验。 搜索空间的参数越多,查找最佳模型所需的试验次数就越多。
还使用了“Bandit 提前终止”策略。 此策略将终止性能不佳的试用;也就是那些与最佳性能试用版相差不在 20% 容许范围内的试用版,这样可显著节省计算资源。
# Configure sweep settings
image_object_detection_job.set_sweep(
sampling_algorithm="random",
early_termination=BanditPolicy(
evaluation_interval=2, slack_factor=0.2, delay_evaluation=6
),
)
# Define search space
image_object_detection_job.extend_search_space(
[
SearchSpace(
model_name=Choice(["yolov5"]),
learning_rate=Uniform(0.0001, 0.01),
model_size=Choice(["small", "medium"]), # model-specific
# image_size=Choice(640, 704, 768), # model-specific; might need GPU with large memory
),
SearchSpace(
model_name=Choice(["fasterrcnn_resnet50_fpn"]),
learning_rate=Uniform(0.0001, 0.001),
optimizer=Choice(["sgd", "adam", "adamw"]),
min_size=Choice([600, 800]), # model-specific
# warmup_cosine_lr_warmup_epochs=Choice([0, 3]),
),
]
)
定义搜索空间和扫描设置后,便可以提交作业以使用训练数据集训练图像模型。
将 AutoML 作业配置为所需的设置后,就可以提交作业了。
# Submit the AutoML job
returned_job = ml_client.jobs.create_or_update(
image_object_detection_job
) # submit the job to the backend
print(f"Created job: {returned_job}")
执行超参数扫描时,使用 HyperDrive UI 直观呈现所尝试的不同试用版会很有用。 可以导航到此 UI,方法是从上级(即 HyperDrive 父作业)转到主 automl_image_job 的 UI 中的“子作业”选项卡。 然后,可以转到此项的“子作业”选项卡。
也可在下面直接查看 HyperDrive 父作业,然后导航到其“子作业”选项卡:
七、注册和部署模型
作业完成后,可以注册从最佳试用(产生了最佳主要指标的配置)创建的模型。 可在下载后注册模型,也可通过指定具有相应 jobid 的 azureml 路径进行注册。
获取最佳试用版
# Get the best model's child run
best_child_run_id = mlflow_parent_run.data.tags["automl_best_child_run_id"]
print(f"Found best child run id: {best_child_run_id}")
best_run = mlflow_client.get_run(best_child_run_id)
print("Best child run: ")
print(best_run)
# Create local folder
local_dir = "./artifact_downloads"
if not os.path.exists(local_dir):
os.mkdir(local_dir)
# Download run's artifacts/outputs
local_path = mlflow_client.download_artifacts(
best_run.info.run_id, "outputs", local_dir
)
print(f"Artifacts downloaded in: {local_path}")
print(f"Artifacts: {os.listdir(local_path)}")
注册模型
使用 azureml 路径或本地下载的路径注册模型。
model_name = "od-fridge-items-mlflow-model"
model = Model(
path=f"azureml://jobs/{best_run.info.run_id}/outputs/artifacts/outputs/mlflow-model/",
name=model_name,
description="my sample object detection model",
type=AssetTypes.MLFLOW_MODEL,
)
# for downloaded file
# model = Model(
# path=mlflow_model_dir,
# name=model_name,
# description="my sample object detection model",
# type=AssetTypes.MLFLOW_MODEL,
# )
registered_model = ml_client.models.create_or_update(model)
注册要使用的模型后,可以使用托管联机终结点 deploy-managed-online-endpoint 进行部署
配置联机终结点
# Creating a unique endpoint name with current datetime to avoid conflicts
import datetime
online_endpoint_name = "od-fridge-items-" + datetime.datetime.now().strftime(
"%m%d%H%M%f"
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is a sample online endpoint for deploying model",
auth_mode="key",
tags={"foo": "bar"},
)
print(online_endpoint_name)
创建终结点
使用之前创建的 MLClient,我们现在将在工作区中创建终结点。 此命令会启动终结点创建操作,并在终结点创建操作继续时返回确认响应。
ml_client.begin_create_or_update(endpoint).result()
还可以创建一个批处理终结点,用于针对一段时间内的大量数据执行批量推理。 签出用于使用批处理终结点执行批量推理的物体检测批处理评分笔记本。
配置联机部署
部署是一组资源,用于承载执行实际推理的模型。 我们将使用 ManagedOnlineDeployment 类为终结点创建一个部署。 可为部署群集使用 GPU 或 CPU VM SKU。
deployment = ManagedOnlineDeployment(
name="od-fridge-items-mlflow-deploy",
endpoint_name=online_endpoint_name,
model=registered_model.id,
instance_type="Standard_DS4_V2",
instance_count=1,
request_settings=req_timeout,
liveness_probe=ProbeSettings(
failure_threshold=30,
success_threshold=1,
timeout=2,
period=10,
initial_delay=2000,
),
readiness_probe=ProbeSettings(
failure_threshold=10,
success_threshold=1,
timeout=10,
period=10,
initial_delay=2000,
),
)
创建部署
使用前面创建的 MLClient,我们将在工作区中创建部署。 此命令将启动部署创建操作,并在部署创建操作继续时返回确认响应。
ml_client.online_deployments.begin_create_or_update(deployment).result()
更新流量
默认情况下,当前部署设置为接收 0% 的流量。 可以设置当前部署应接收的流量百分比。 使用一个终结点的所有部署接收的流量百分比总和不应超过 100%。
# od fridge items deployment to take 100% traffic
endpoint.traffic = {"od-fridge-items-mlflow-deploy": 100}
ml_client.begin_create_or_update(endpoint).result()
八、测试部署
# Create request json
import base64
sample_image = os.path.join(dataset_dir, "images", "1.jpg")
def read_image(image_path):
with open(image_path, "rb") as f:
return f.read()
request_json = {
"input_data": {
"columns": ["image"],
"data": [base64.encodebytes(read_image(sample_image)).decode("utf-8")],
}
}
import json
request_file_name = "sample_request_data.json"
with open(request_file_name, "w") as request_file:
json.dump(request_json, request_file)
resp = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name=deployment.name,
request_file=request_file_name,
)
九、直观呈现检测结果
为测试图像评分后,可以直观呈现此图像的边界框。 若要执行此操作,请确保已安装 matplotlib。
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import matplotlib.patches as patches
from PIL import Image
import numpy as np
import json
IMAGE_SIZE = (18, 12)
plt.figure(figsize=IMAGE_SIZE)
img_np = mpimg.imread(sample_image)
img = Image.fromarray(img_np.astype("uint8"), "RGB")
x, y = img.size
fig, ax = plt.subplots(1, figsize=(15, 15))
# Display the image
ax.imshow(img_np)
# draw box and label for each detection
detections = json.loads(resp)
for detect in detections[0]["boxes"]:
label = detect["label"]
box = detect["box"]
conf_score = detect["score"]
if conf_score > 0.6:
ymin, xmin, ymax, xmax = (
box["topY"],
box["topX"],
box["bottomY"],
box["bottomX"],
)
topleft_x, topleft_y = x * xmin, y * ymin
width, height = x * (xmax - xmin), y * (ymax - ymin)
print(
f"{detect['label']}: [{round(topleft_x, 3)}, {round(topleft_y, 3)}, "
f"{round(width, 3)}, {round(height, 3)}], {round(conf_score, 3)}"
)
color = np.random.rand(3) #'red'
rect = patches.Rectangle(
(topleft_x, topleft_y),
width,
height,
linewidth=3,
edgecolor=color,
facecolor="none",
)
ax.add_patch(rect)
plt.text(topleft_x, topleft_y - 10, label, color=color, fontsize=20)
plt.show()
十、清理资源
如果打算运行其他 Azure 机器学习教程,请不要完成本部分。
如果不打算使用已创建的资源,请删除它们,以免产生任何费用。
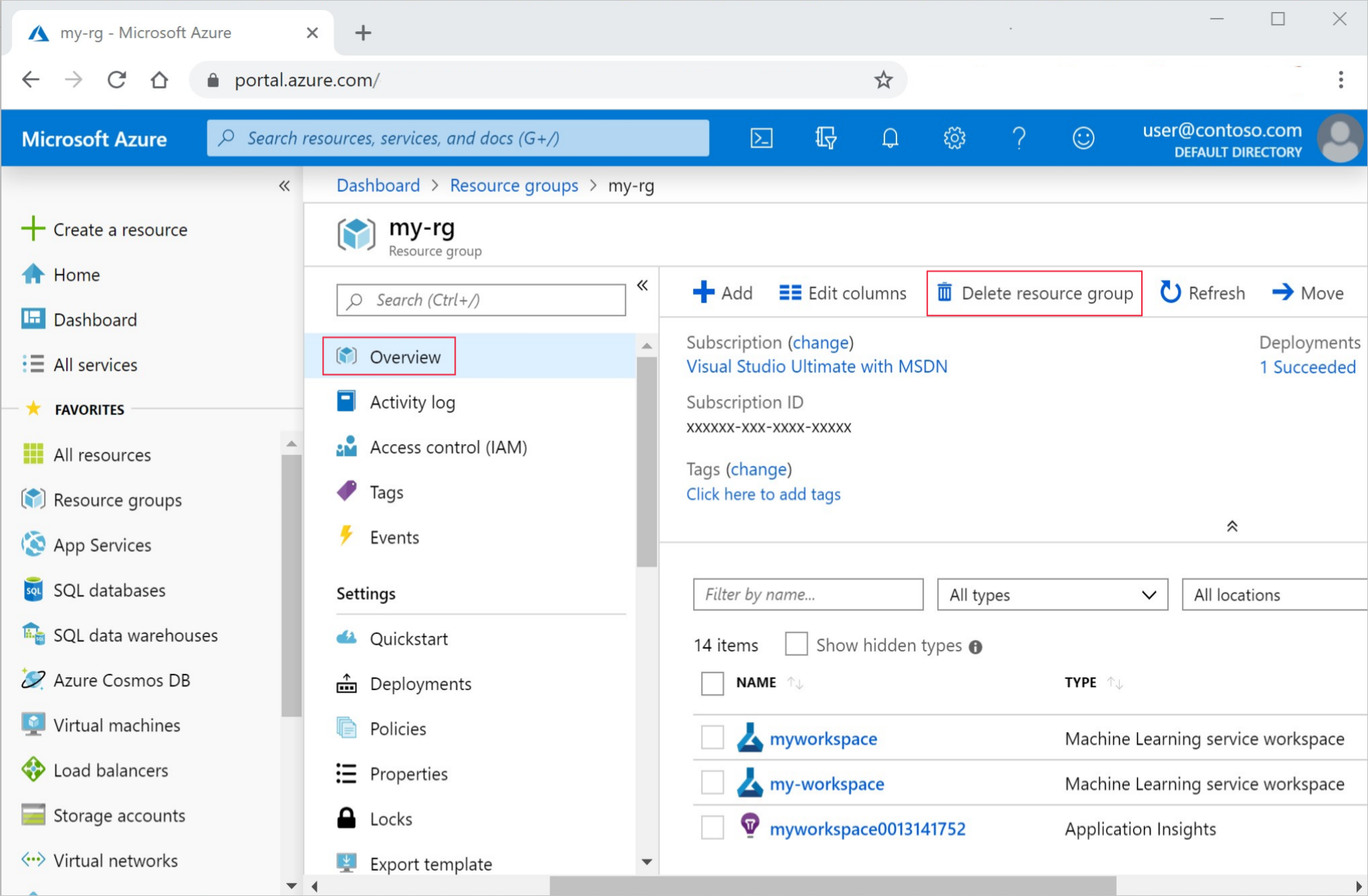
- 在 Azure 门户中,选择最左侧的“资源组”。
- 从列表中选择已创建的资源组。
- 选择“删除资源组”。
- 输入资源组名称。 然后选择“删除”。
还可保留资源组,但请删除单个工作区。 显示工作区属性,然后选择“删除”。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。



![[SpringCloud | Linux] CentOS7 部署 SpringCloud 微服务](https://img-blog.csdnimg.cn/562f1cb3090c4a60b9e7f61e27533274.png)