建议大家写在Linux上搭建好Hadoop的完全分布式集群环境和Spark集群环境,以下在IDEA中搭建的环境仅仅是在window系统上进行spark程序的开发学习,在window系统上可以不用安装hadoop和spark,spark程序可以通过pom.xml的文件配置,添加spark-core依赖,可以直接在IDEA中编写spark程序并运行结果。
一、相关软件的下载及环境配置
1.jdk的下载安装及环境变量配置(我选择的版本是jdk8.0(即jdk1.8),建议不要使用太高版本的,不然配置pom.xml容易报错)
链接:https://pan.baidu.com/s/1deXf6pgMiRca1O724fUOxg
提取码:sxuy
双击安装包,一直“Next”即可,最好不要安装到C盘,中间修改一下安装路径即可,最后点击“Finish”。我将jdk1.8安装在了D盘目录下的soft文件夹,bin路径如下:

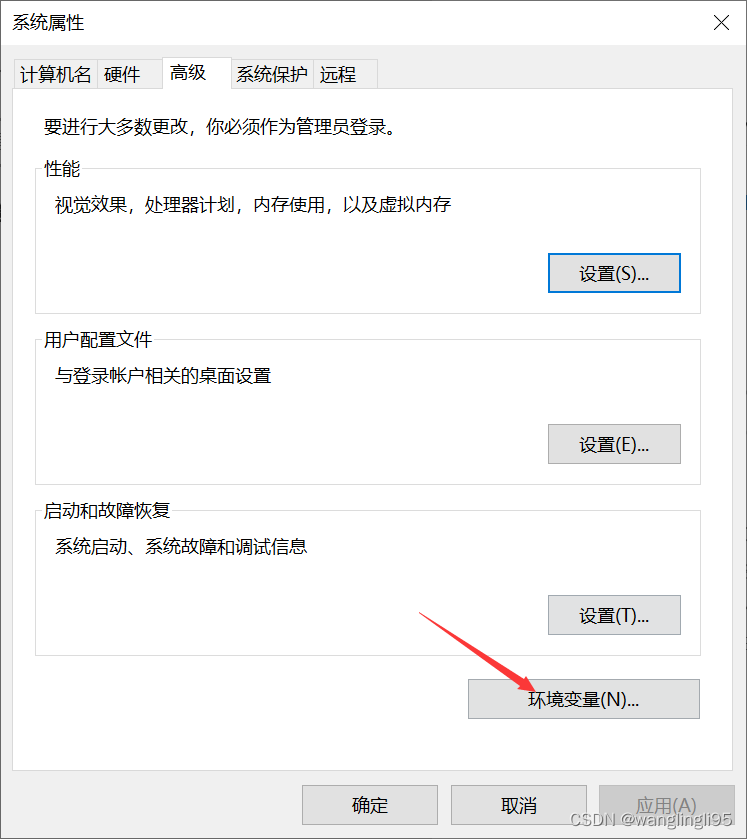
配置环境变量:

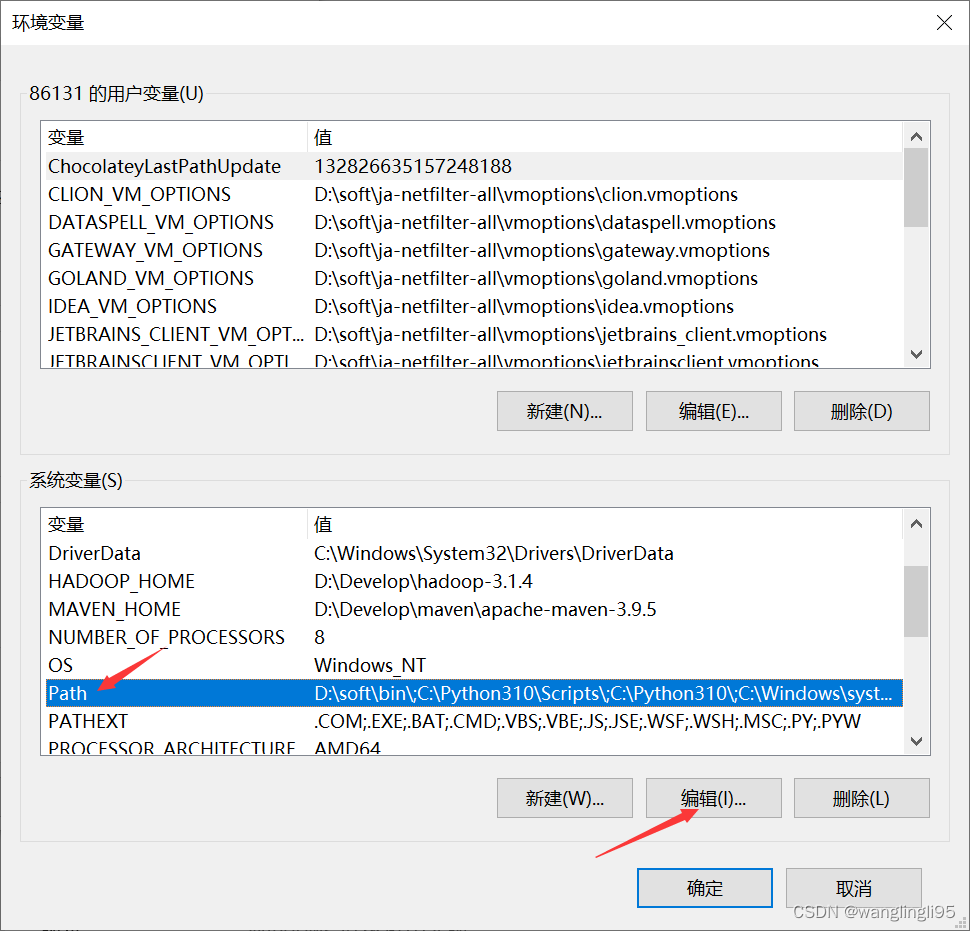

win+R打开命令窗口输入:javac -verison ,进行检测是否成功配置环境变量:

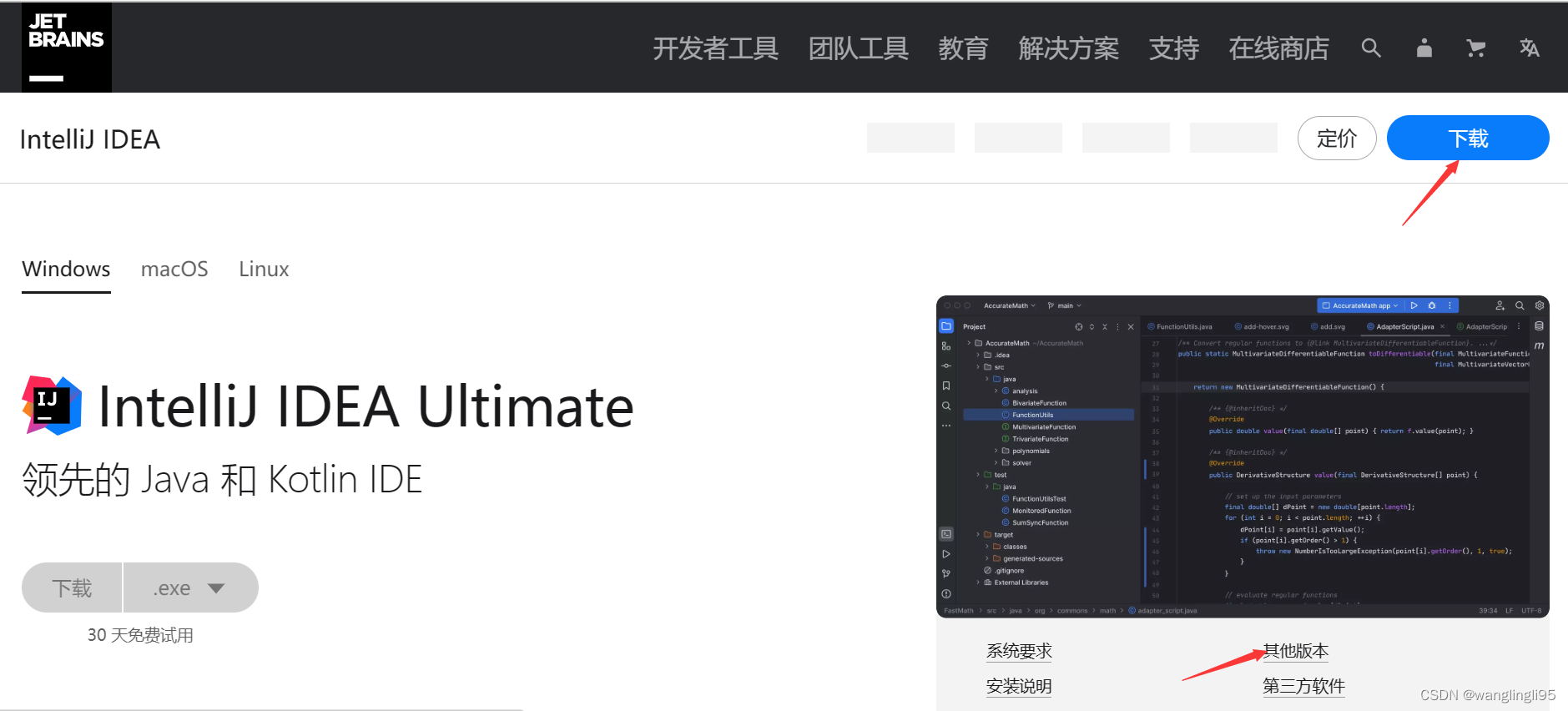
2.IDEA的下载安装(我选择的版本是2019.2.3,建议选择低版本的IDEA)
官网下载地址:IntelliJ IDEA – 领先的 Java 和 Kotlin IDE (jetbrains.com.cn)
3.scala的下载(我选择的版本是2.12.15)安装及环境变量的配置
官网下载地址:The Scala Programming Language (scala-lang.org)
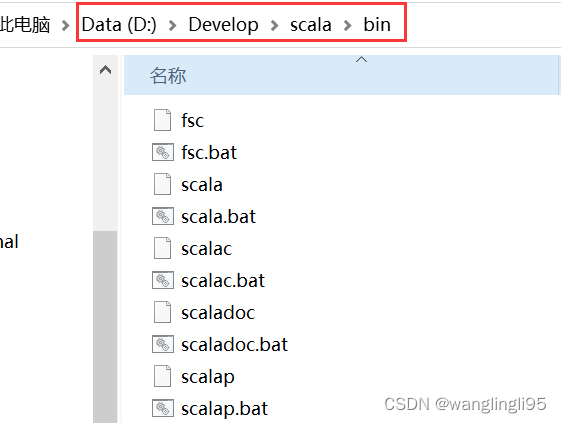
双击打开下载好的安装程序,一直“Next”即可,最好不要安装到C盘,中间修改一下安装路径即可,最后点击“Finish”。我将scala软件安装在了D盘目录下的Develop文件夹,bin路径如下:
配置scala的系统环境变量,将scala安装的bin目录路径加入到系统环境变量path中:

win+R打开命令窗口输入:scala -verison ,进行检测是否成功配置环境变量:

4.scala插件(版本要与IDEA版本保持一致,下载2019.2.3版本)的下载安装
官网地址:Scala - IntelliJ IDEs Plugin | Marketplace
下载完成后,将下载的压缩包解压到IDEA安装目录下的plugins目录下:
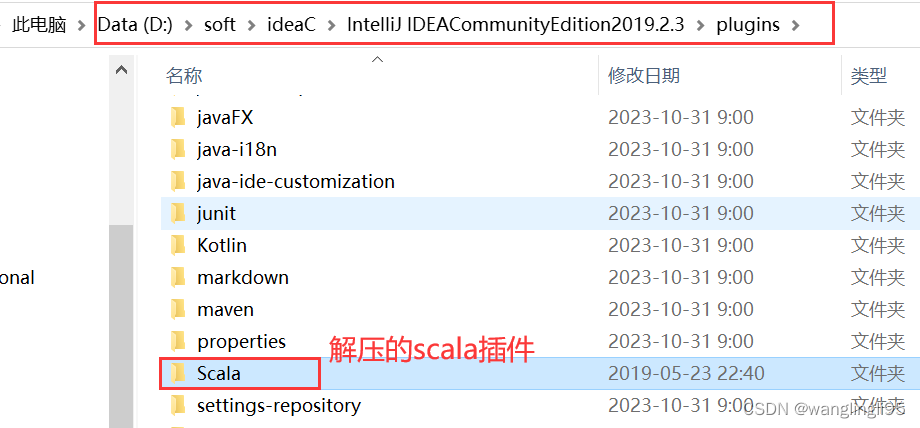
5.maven的下载(我选择的版本是3.5.4)与安装,系统环境变量的配置
官网地址:Maven – Download Apache Maven
将对应版本的压缩包下载到本地,并新建一个文件夹Localwarehouse,用来保存下载的依赖文件

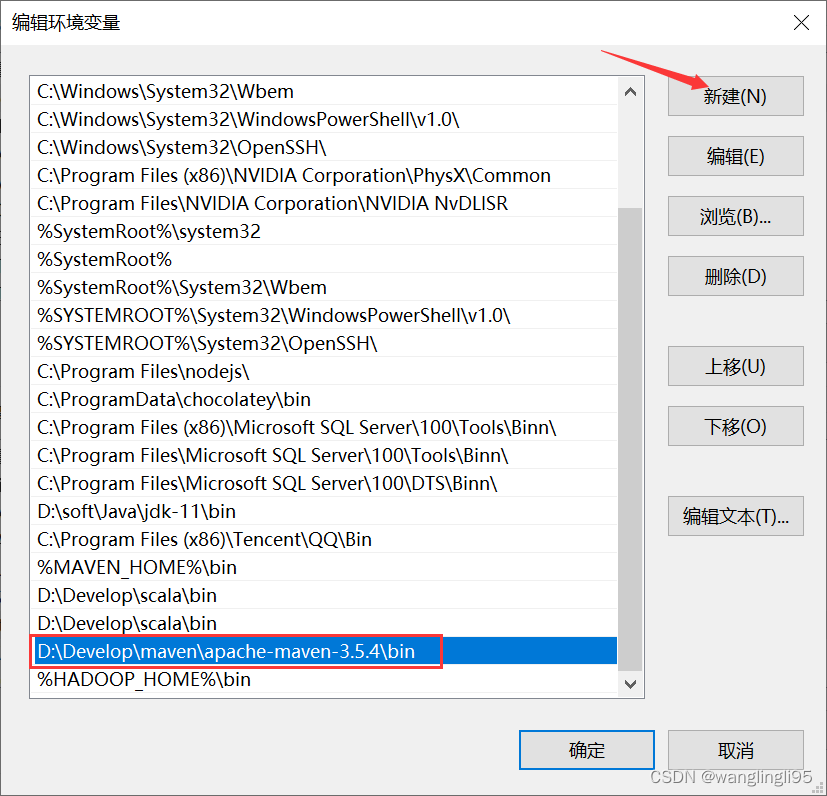
配置maven的系统环境配置,跟以上配置的方法一样,将bin目录地址写入path环境变量:

打开maven安装包下的conf文件夹下面的settings.xml,添加如下代码:
<localRepository>D:\\Develop\\maven\\Localwarehouse</localRepository>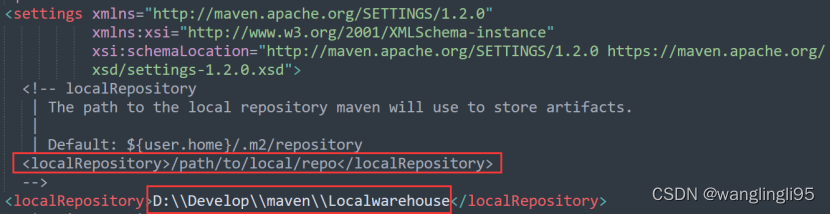
添加如下代码用来配置jdk版本:
<profile>
<id>jdk-1.8.0</id>
<activation>
<activeByDefault>true</activeByDefault>
<jdk>1.8.0</jdk>
</activation>
<properties>
<maven.compiler.source>1.8.0</maven.compiler.source>
<maven.compiler.target>1.8.0</maven.compiler.target>
<maven.compiler.compilerVersion>1.8.0</maven.compiler.compilerVersion>
</properties>
</profile>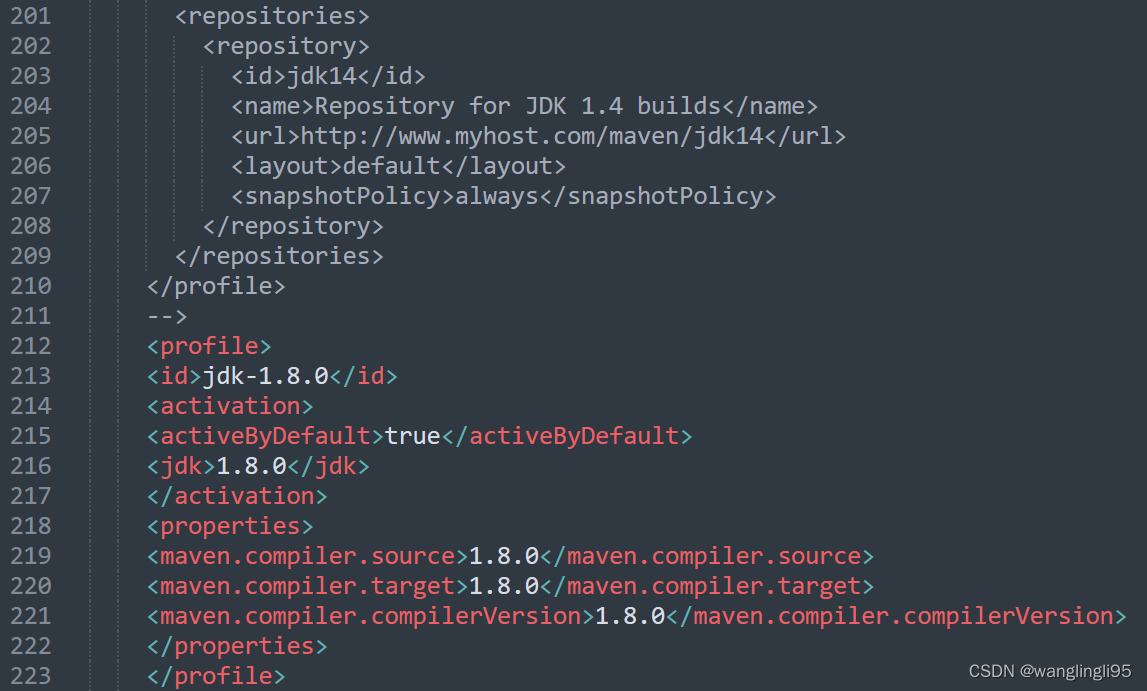
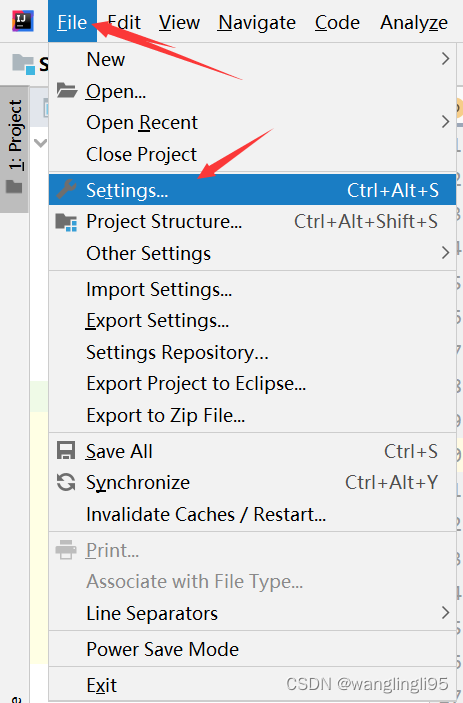
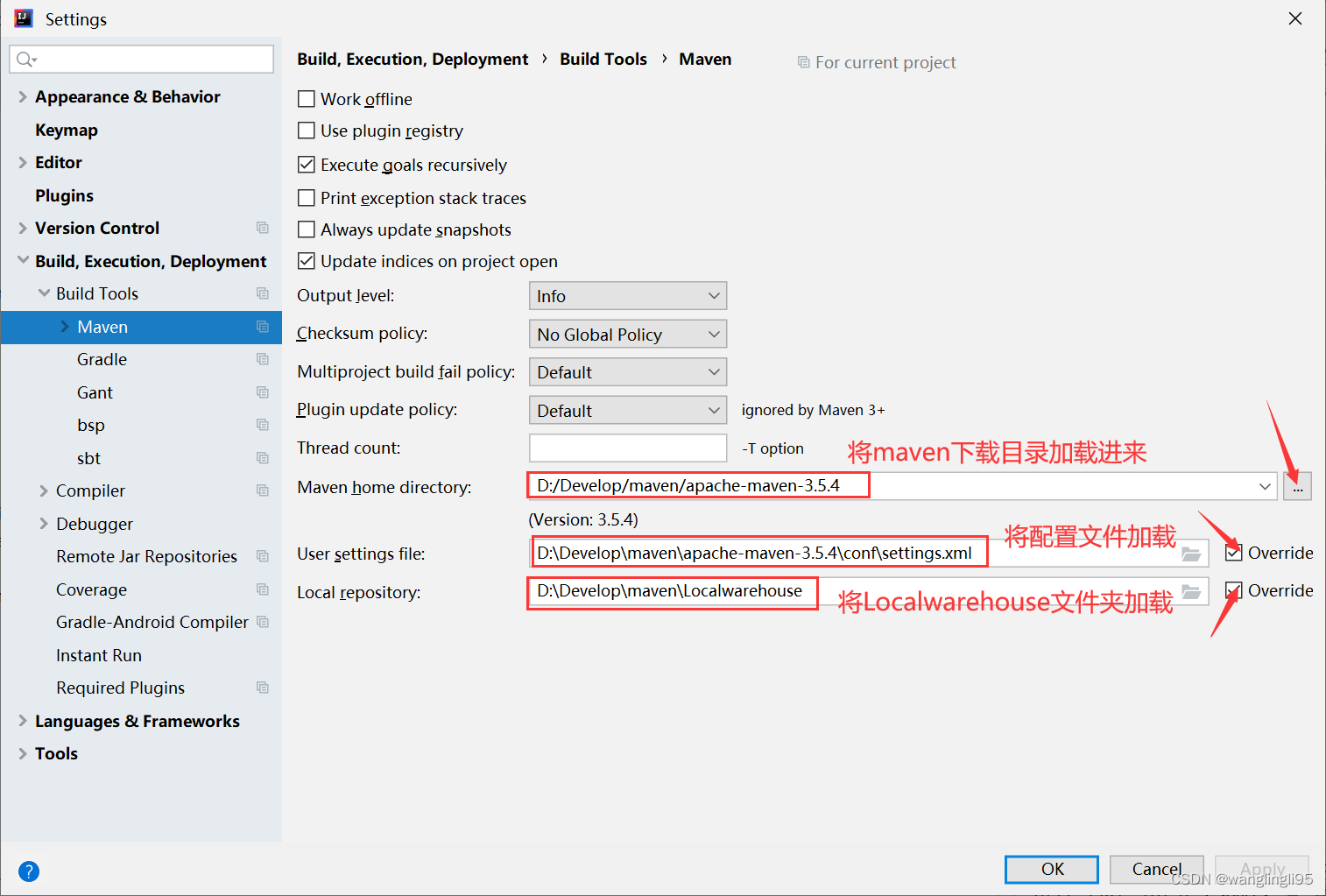
二、将maven加载到IDEA中
三、检测scala插件是否在IDEA中已经安装成功
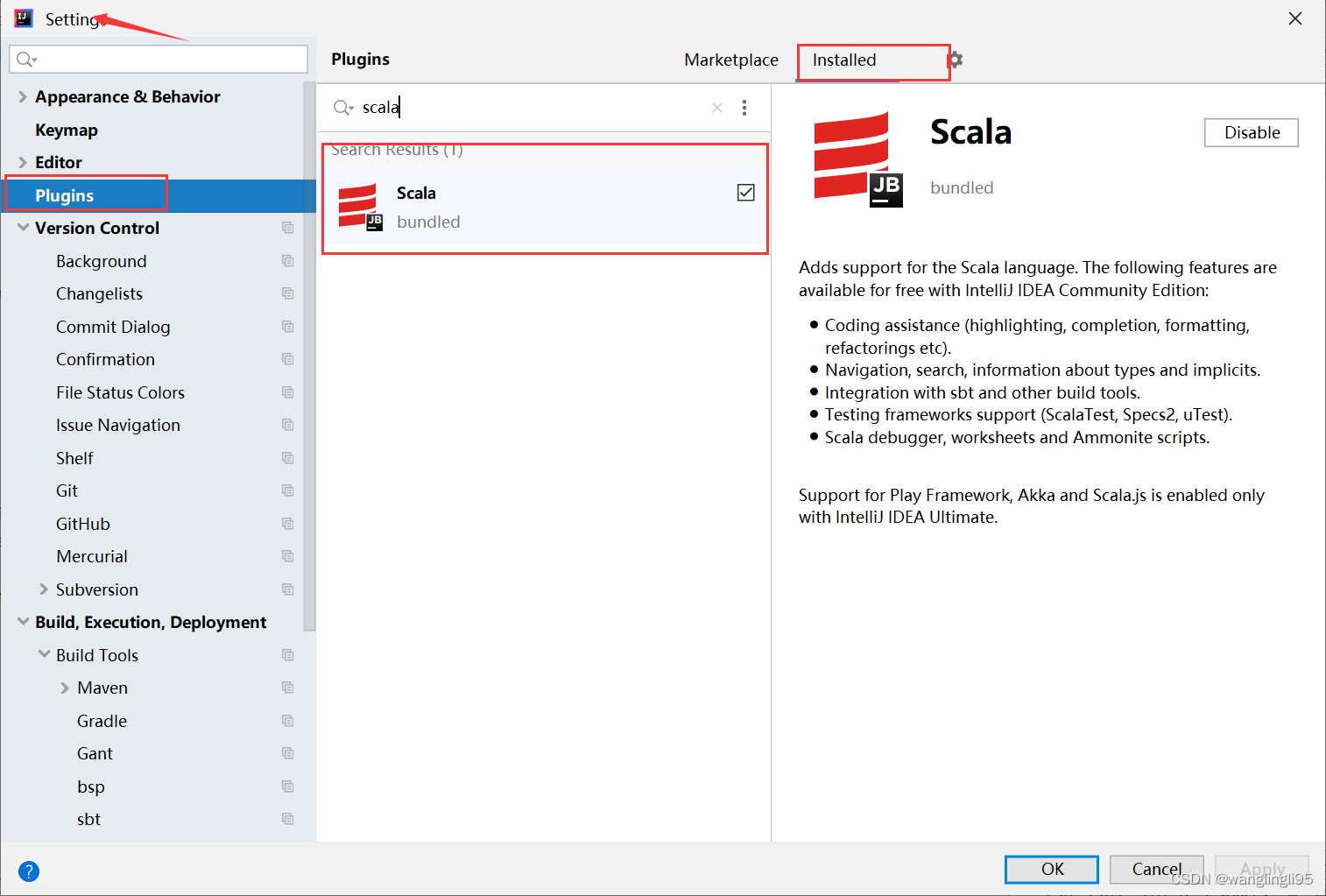
四、用maven新建一个工程项目
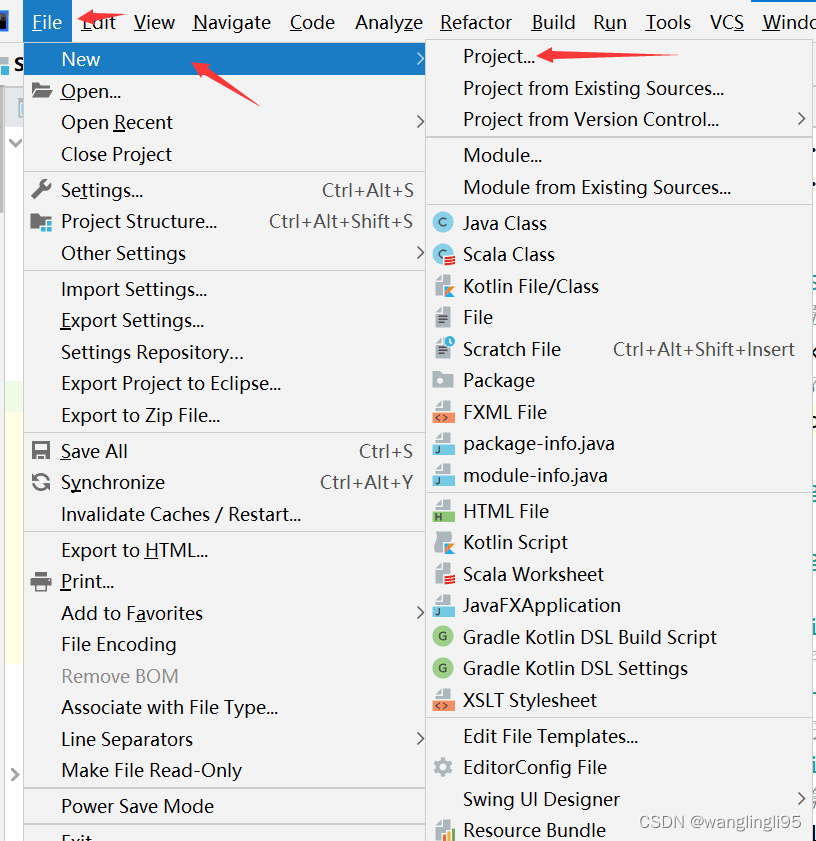



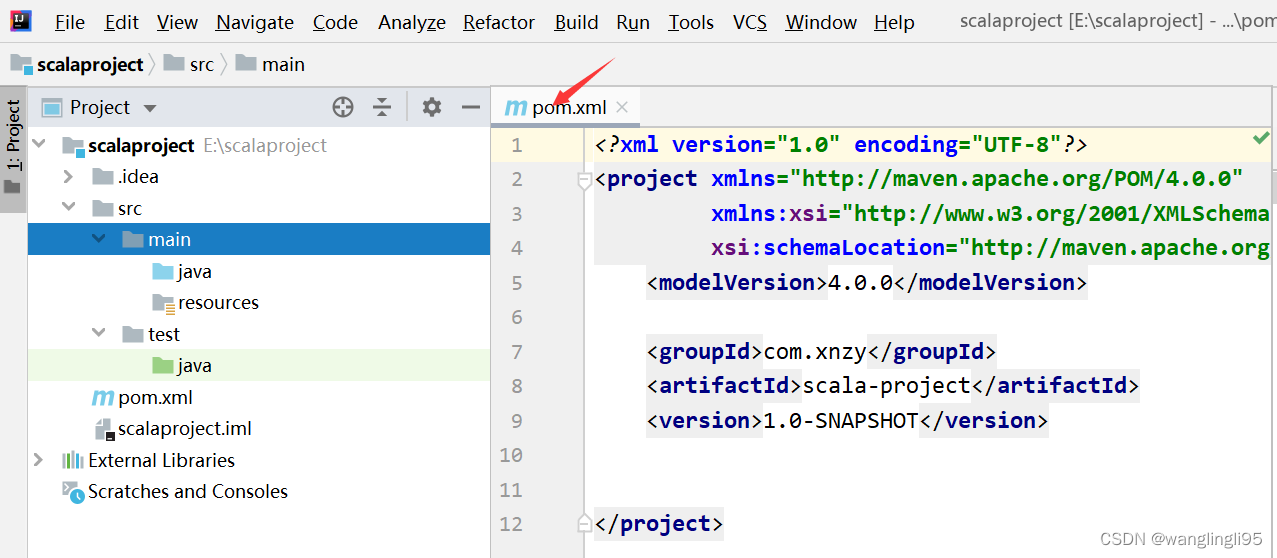
五、配置pom.xml文件
1.如果只需要在本地运行spark程序,则只需要添加scala-library、spark-core、spark-sql、spark-streaming等依赖,添加代码如下:
<properties>
<!-- 声明scala的版本 -->
<scala.version>2.12.15</scala.version>
<!-- 声明linux集群搭建的spark版本,如果没有搭建则不用写 -->
<spark.version>3.2.1</spark.version>
<!-- 声明linux集群搭建的Hadoop版本 ,如果没有搭建则不用写-->
<hadoop.version>3.1.4</hadoop.version>
</properties>
<dependencies>
<!--scala-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.2.1</version>
<scope>provided</scope>
</dependency>
</dependencies>六、新建scala类文件编写代码
当你右键发现无法新建scala类,需要将scala SDK添加到当前项目中。

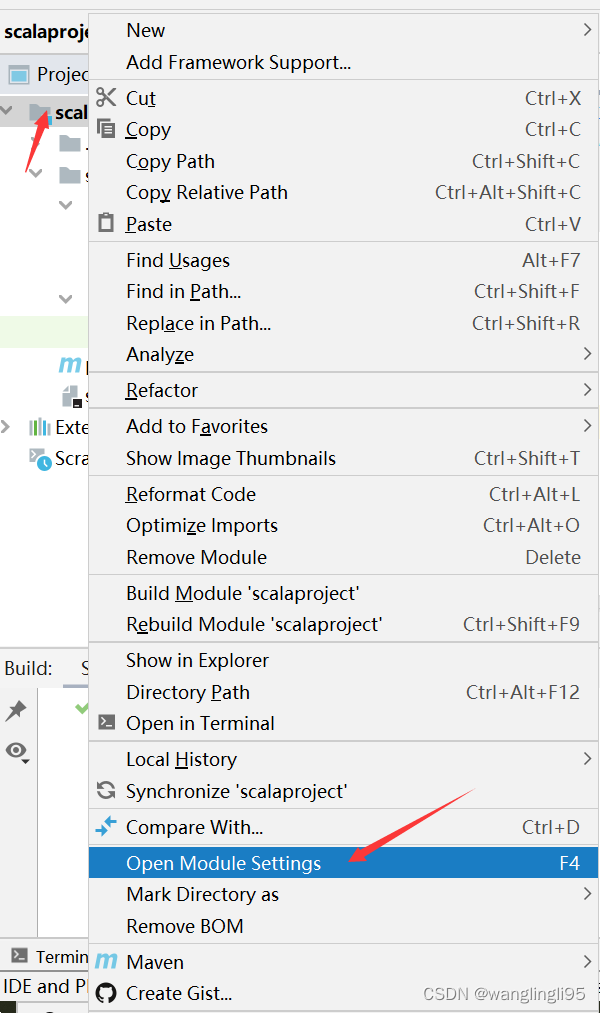

鼠标点击java文件夹,右键new--->Scala Class

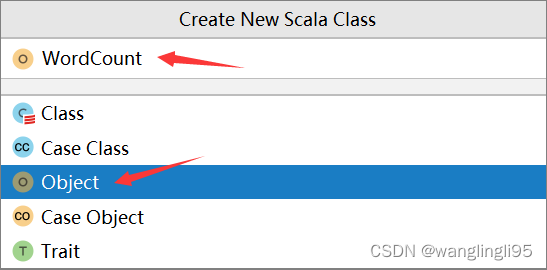
在WordCount文件中编写如下代码:
import org.apache.spark.sql.SparkSession
object WordCount {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local[*]")
.appName("word count")
.getOrCreate()
val sc = spark.sparkContext
val rdd = sc.textFile("data/input/words.txt")
val counts = rdd.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
counts.collect().foreach(println)
println("全部的单词数:"+counts.count())
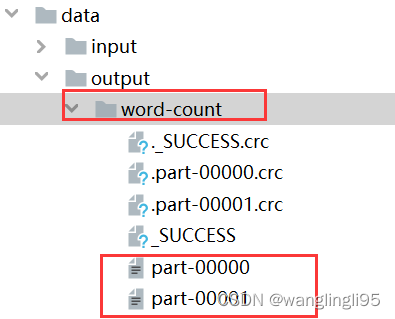
counts.saveAsTextFile("data/output/word-count")
}
}准备好测试文件words.txt,将文件存放在scalaproject-->data-->input-->words.txt
hello me you her
hello me you
hello me
hello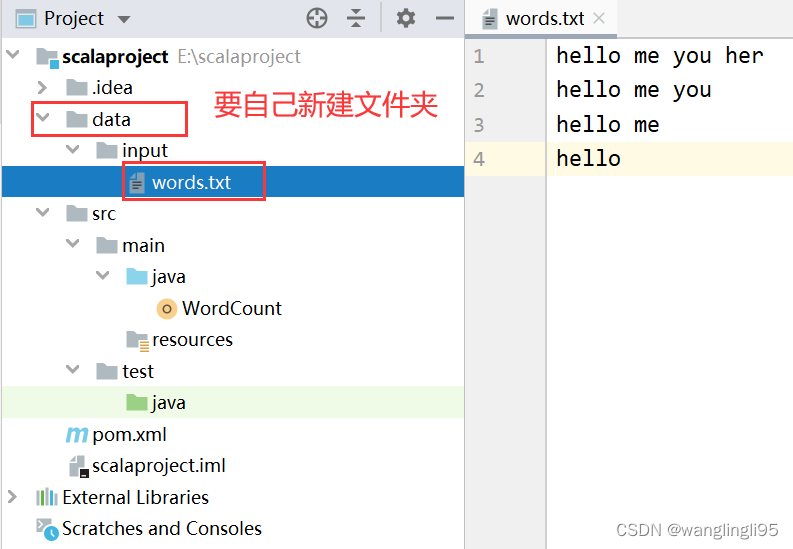
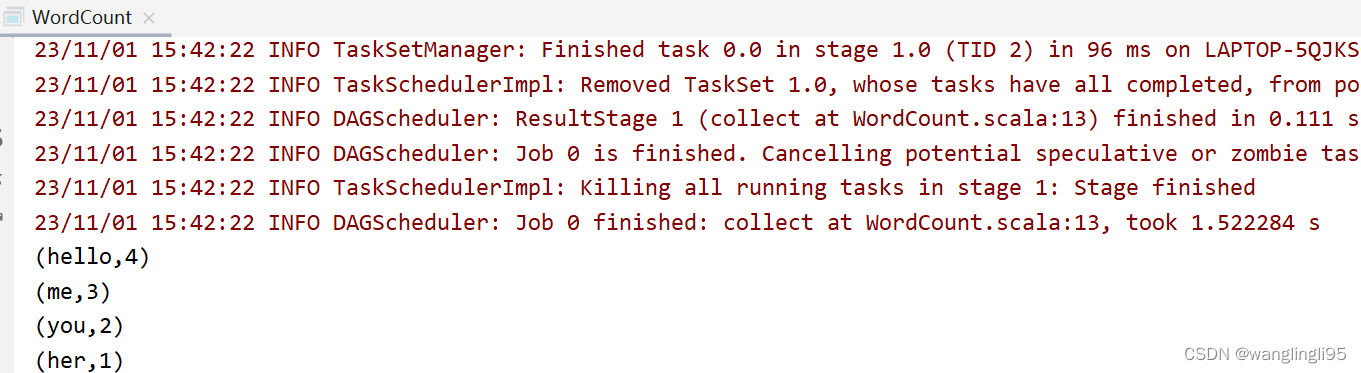
运行WordCount程序

运行结果: