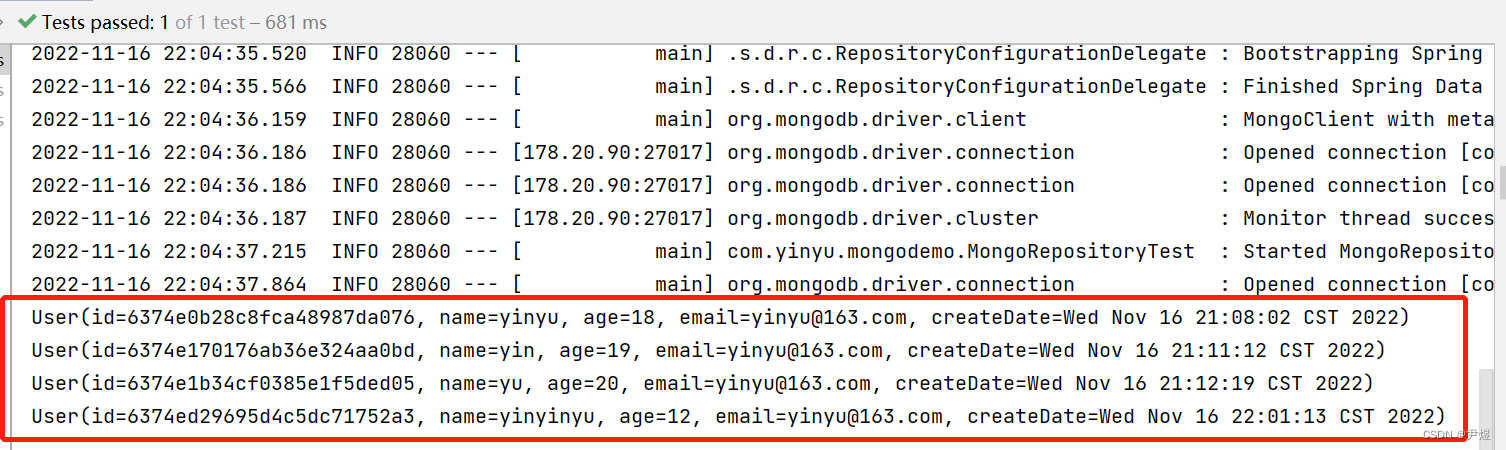
人工智能-第三阶段-k近邻算法1-算法理论、kd树、鸢尾花数据
人工智能–k近邻算法2-归一化、交叉验证、网格搜索、数据分割方法总结、两案例实现
1.7 特征工程-特征值预处理
1.7.1 介绍
通过一些转换函数奖特征数据转换为更加适合算法模型的特征数据过程
为什么要进行归一化/标准化?
特征的单位或者大小相差很大,或者某特征的方差比其他特征要大出几个量级,容易影响目标结果
例如如下数据: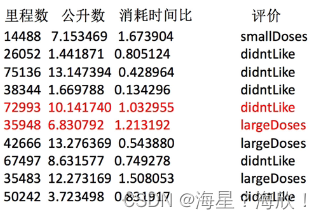
1.7.2 归一化
x1 = (x-min)/(max-min)
1,实例化
2,转换
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
#归一化
def minmax_demo():
data = pd.read_csv('./data/dating.txt')#路径-读取
print(data)
#1,实例化
transfer = MinMaxScaler(feature_range=(3,5)) #归一化到3-5之间
#2,转换,调用fit_transform
ret_data= transfer.fit_transform(data[['milage','Liters','Consumtime']]) #转换data中的这几列
#二维数据,所以两个中括号
print('归一化之后的数据为:\n',ret_data)
minmax_demo() #调用归一化函数
问题:如果异常值过多,怎么办?
归一化容易受到异常点的影响,所以归一化的鲁棒性(确定性,稳定性)较差,只适合传统精确小数据场景。
1.7.3 标准化
x1 = (x-mean)/标准差
归一化:出现异常点,影响较大
标准化:由于异常点的个数少量,对平均值的影响并不大,从而方差改变较小

import pandas as pd
from sklearn.preprocessing import StandardScaler
#标准化
def stand_demo():
data = pd.read_csv('./data/dating.txt')#路径-读取
print(data)
#1,实例化
transfer = StandardScaler() #默认归一化到均值0,方差1
#2,转换,调用fit_transform
ret_data= transfer.fit_transform(data[['milage','Liters','Consumtime']]) #转换data中的这几列
#二维数据,所以两个中括号
print('标准化之后的数据为:\n',ret_data)
print('每一列的方差为:\n',transfer.var_)
print('每一列的平均值为:\n',transfer.mean_)
stand_demo() #调用标准化函数
1.8 案例1:鸢尾花种类预测-流程实现
k近邻的API:

利用鸢尾花数据进行预测的完整代码:
from sklearn.datasets import load_iris #导数据
from sklearnmodel_selection import train_test_split #分割数据
from sklearn.preprocessing import StandardScaler #标准化
from sklearn.neighbors import KNeighborsClassifier #K近邻
#1,获取数据
iris = load_iris()
#2,数据基本处理
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size = 0.2,random_state = 22)
#3,特征工程-特征预处理
transfer = StandarScaler()
x_train = transfer.fit_transform(x_train) #对训练集标准化
x_test = transfer.transform(x_test) #对测试集标准化
#4,机器学习-kNN
#4.1 实例化一个估计器
estimator = KNeighborsClassifier(n_neighbors = 5) #邻居数选为5
#4.2 模型训练
estimator.fit(x_train,y_train)
#5,模型评估
#5.1 预测值结果输出
y_pre = estimator.predict(x_test)
print('预测值是:\n',y_pre)
print('预测值和真实值的对比是:\n',y_pre==y_test)
#5.2 准确率计算
score = estimator.score(x_test,y_test)
print('准确率为:\n',score)
导库包—读取数据—数据预处理(划分训练与预测)—特征工程(标准化)–模型训练—模型评估
1.9 K-近邻算法总结
欧式距离
k值的选择
kd树的构建
K近邻算法
优点:简单有效、重新训练的代价低、适合类域交叉样本、适合大样本自动分类
缺点:惰性学习、类别划分不是规格化、输出可解释性不强、对不均衡的样本不擅长、计算量较大
类域交叉样本:

1.10 交叉验证,网格搜索
1.10.1 交叉验证
四折交叉验证:

交叉验证的最后准确率是每次验证的准确值后的平均值
交叉验证的目的:没法提高模型预测的精度,但能让被评估的模型更加可信可靠
1.10.2 网格搜索
超参数:机器学习中需要手动指定的参数(例如k近邻中的K值)
网格搜索:对于超参数,采用交叉验证对各种可能 的取值进行评估,返回最优的参数组合。通过选定最优的超参数,来提高模型的精确性

代码在上面那段上改,增加了4.2与5.3
from sklearn.datasets import load_iris #导数据
from sklearnmodel_selection import train_test_split #分割数据
from sklearn.preprocessing import StandardScaler #标准化
from sklearn.neighbors import KNeighborsClassifier #K近邻
#1,获取数据
iris = load_iris()
#2,数据基本处理
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size = 0.2,random_state = 22)
#3,特征工程-特征预处理
transfer = StandarScaler()
x_train = transfer.fit_transform(x_train) #对训练集标准化
x_test = transfer.transform(x_test) #对测试集标准化
#4,机器学习-kNN
#4.1 实例化一个估计器
estimator = KNeighborsClassifier()
#4.2 模型调优--交叉验证,网格搜索
param_grid = {'n_neighbors':[1,3,5,7]} #邻居数试1,3,5,7
estimator = GridSearchCV(estimator,para_grid=param_grid,cv=5)#交叉5次
#4.3 模型训练
estimator.fit(x_train,y_train)
#5,模型评估
#5.1 预测值结果输出
y_pre = estimator.predict(x_test)
print('预测值是:\n',y_pre)
print('预测值和真实值的对比是:\n',y_pre==y_test)
#5.2 准确率计算
score = estimator.score(x_test,y_test)
print('准确率为:\n',score)
#5.3 查看交叉验证,网格搜索的一些属性
print('在交叉验证中,得到的最好结果是:\n',estimator.best_score_) #测试集上的分数
print('在交叉验证中,得到的最好模型是:\n',estimator.best_estimator_) #在训练集上的分数
print('在交叉验证中,得到的模型结果是:\n',estimator.cv_results_)
1.11 案例2 预测facebook签到位置
目的:预测一个人将要签到的地方。根据用户的位置,准确性和时间戳等预测用户下一次的签到位置。
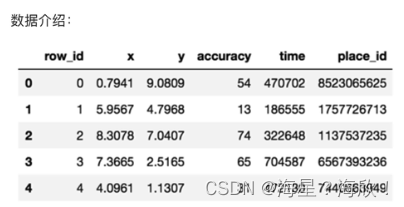

import pandas as pd
data = pd.read_csv('./data/train.csv')
data.head()
data.describe()
步骤:
1,获取数据集
2,基本数据处理
2.1缩小数据集范围 ---- 为了演示方便,节省时间
2.2选取有用的时间特征
2.3将签到数量少于n个的签到位置删除
2.4 确定特征值和目标值
2.5 分割数据集
3,特征工程
4,机器学习 – knn
5,模型评估
from pandas as pd
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
#1,获取数据集
data = pd.read_csv('./data/train.csv')
data.head()
data.describe()
data.shape
#2,基本数据处理
#2.1缩小数据集范围 ---- 为了演示方便,节省时间
partial_data=data.query('x>2.0 & x<2.5 & y>2.0 & y<2.5')
partial_data.head()
partial_data.shape
#2.2选取有用的时间特征
partial_data['time'].head()
#to_datetime转换时间戳为时间形式
time = pd.to_datetime(partial_data['time'],unit='s')
time.head()

#time.hour #此时会报错,time类型还不是时间类型
time = pd.DatetimeIndex(time)
partial_data['hour']=time.hour
partial_data['day']=time.day
partial_data['weekday']=time.weekday
#2.3 将签到数量少于n个的签到位置删除
#例如:用于广告投入,更关注人流量多的地方
place_count = partial_data.groupby('place_id').count() #先分组后聚合
place_count.head()
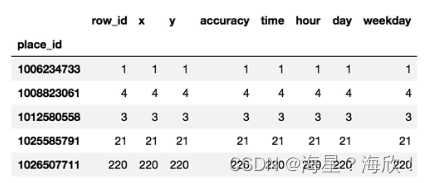
place_count = place_count[place_count['row_id']>3]
place_count.head()
#partial_data['place_id'].isin(place_count.index)--返回是一堆ture或者false
#用isin进行判断,partial_data['place_id']与place_count进行对比
partial_data = partial_data[partial_data['place_id'].isin(place_count.index)]
partial_data.shape
# 2.4 确定特征值和目标值
x = partial_data[['x','y','accuracy','hour','day','weekday']]
y = partial_data['place_id']
#2.5 分割数据集
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=2,test_size=0.25)
#3,特征工程--特征预处理(标准化)
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
#4,机器学习 -- knn+cv
#4.1 实例化一个训练器
estimator = KNeighborsClassifier()
#4.2 交叉验证,网格搜索实现
param_grid = {'n_neighbors':[3,5,7,9]}
estimator = GridSearchCV(estimator = estimator,param_grid = param_grid,cv=3,n_jobs = 4)#n_jobs是控制运行的CPU个数,设置为-1即让所有CPU跑(满负荷)
#4.3 模型训练
estimator.fit(x_train,y_train)
#5,模型评估
#5.1 准确率输出
score_ret = estimator.score(x_test,y_test)
print('准确率为:\n',ascore_ret)
#5.2 预测结果
y_pre = estimator.predict(x_test)
print('预测值是:\n',y_pre)
print('预测值和真实值的对比是:\n',y_pre==y_test)
#5.3 其他结果输出
print('在交叉验证中,得到的最好结果是:\n',estimator.best_score_) #测试集上的分数
print('在交叉验证中,得到的最好模型是:\n',estimator.best_estimator_) #在训练集上的分数
print('在交叉验证中,得到的模型结果是:\n',estimator.cv_results_)
1.12 知识补充 : 再议论数据分割
测试样本最好不出现在训练集中—避免模型泛化能力差
分割数据的方法:留出法、交叉验证法、自助法
1.12.1 留出法:分层采样,train_test_split
分层采样可以缓解留出法中带来的数据分割后分布不一致的问题
from sklearn.model_selection import train_test_split
train_x,test_x,train_y,test_y = train_test_split(x,y,test_size=0.2,random_state = 2)
如果数据量太小,采用:留一法
from sklearn.model_selection import LeaveOneOut
#留一法
data = [1,2,3,4]
loo = LeaveOneOut() #实例化对象
for train,test in loo.split(data):
print('%s %s'%(train,test))


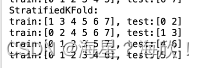
1.12.2 交叉验证法
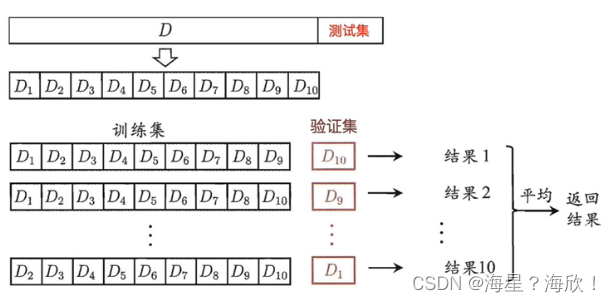
交叉验证法:除了GridSearchCV 外,还有KFold与StratifiedKFold
区别:
KFold并没有考虑到正反样本的比例,是随机的。对应地,StratifiedKFold是分层采用,所以更推荐StratifiedKFold。

import numpy as np
from sklearn.model_selection import KFold,StratifiedKFold
#交叉验证法--KFold与StratifiedKFold
x = np.array([
[1,2,3,4],
[11,12,13,14],
[21,12,23,45],
[31,32,13,14],
[31,32,23,45],
[41,42,13,14],
[31,52,23,45],
[31,22,13,15]])
y = np.array([1,1,0,0,1,1,0,0])
folder = KFold(n_splits =4,random_state=0,shuffle=False)
sfolder = StratifiedKFold(n_splits =4,random_state=0,shuffle=False)
#KFold
print('KFold')
for train,test in folder.split(data):
print('train:%s,test:%s'%(train,test))
#返回的是下标

#StratifiedKFold
print('StratifiedKFold')
for train,test in sfolder.split(data):
print('train:%s,test:%s'%(train,test))
#返回的是下标
1.12.3 自助法

1.12.4 总结
- 数据量充足–留出法简单省时,在牺牲很小的准确度情况下,换取计算的简便
- 数据量较小–交叉验证发,因为此时划分样本集会使得训练集过少
- 数据量特别少–留一法