JVM部分热点问题
Hi,我是阿昌,今天学习JVM部分热点问题的内容。
1、字符串常量不是在java8中已经被放入到堆中了吗,应该不在方法区中了,咋一些图中还在方法区中?
JVM 的内存模型只是一个规范,方法区也是一个规范,一个逻辑分区,并不是一个物理空间,这里说的字符串常量放在堆内存空间中,是指实际的物理空间。
2、JDK1.8中类的元数据是放在元数据区还是方法区呢?
元空间是属于方法区的,方法区只是一个逻辑分区,而元空间是具体实现。
所以类的元数据是存放在元空间,逻辑上属于方法区。
3、栈上分配这里,对局部变量对象的大小是否有要求,毕竟栈的内存比较小?
目前 Hotspot 虚拟机暂时不支持栈上分配对象。
这其实是因为由于HotSpot虚拟机目前的实现导致栈上分配实现比较复杂。
栈上分配影响:
- java只有值传递,跨方法的局部变量在栈上分配的话,在现有栈实现上
会影响栈的回收。 - 栈属于线程所有,实现栈上分配,会消耗更多的内存。让java的多线程更
吃内存。 - 如果实现栈上分配,还需要GC作用会弱化很多吧。
- 基类型栈上分配+引用类型堆分配
->全栈上分配。这么实现的话hotspot全推翻了。
4、G1 是如何实现更好的 GC 性能的吗?
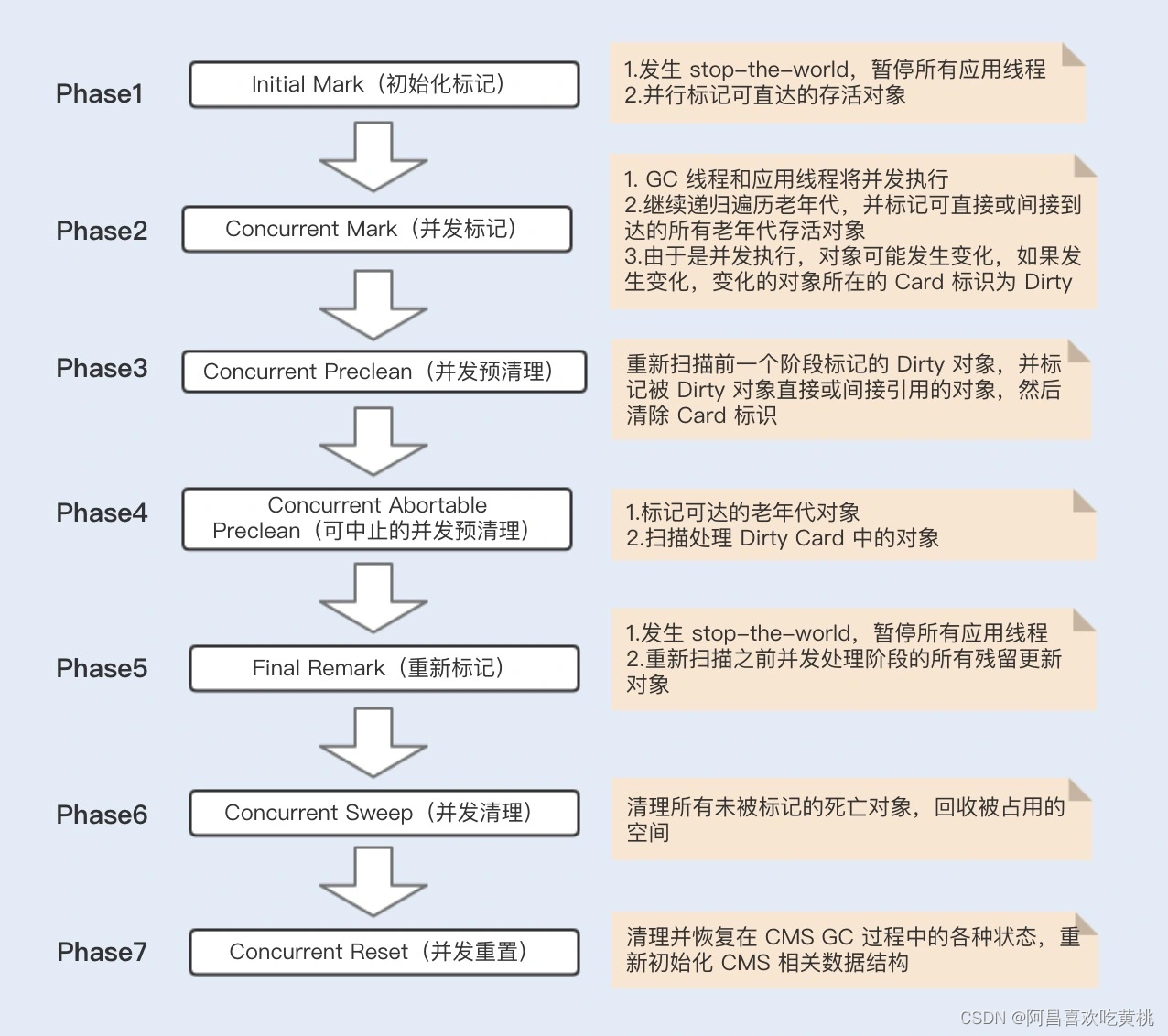
CMS 垃圾收集器是基于标记清除算法实现的,目前主要用于老年代垃圾回收。
CMS 收集器的 GC 周期主要由 7 个阶段组成,其中有两个阶段会发生 stop-the-world,其它阶段都是并发执行的。
G1 垃圾收集器是基于标记整理算法实现的,是一个分代垃圾收集器,既负责年轻代,也负责老年代的垃圾回收。
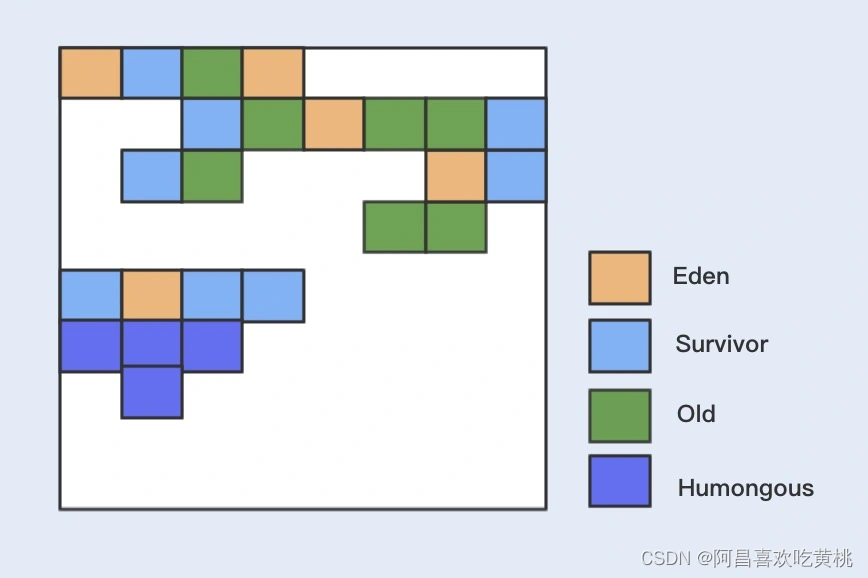
跟之前各个分代使用连续的虚拟内存地址不一样,G1 使用了一种 Region 方式对堆内存进行了划分,同样也分年轻代、老年代,但每一代使用的是 N 个不连续的 Region 内存块,每个 Region 占用一块连续的虚拟内存地址。
在 G1 中,还有一种叫 Humongous 区域,用于存储特别大的对象。
G1 内部做了一个优化,一旦发现没有引用指向巨型对象,则可直接在年轻代的 YoungGC 中被回收掉。
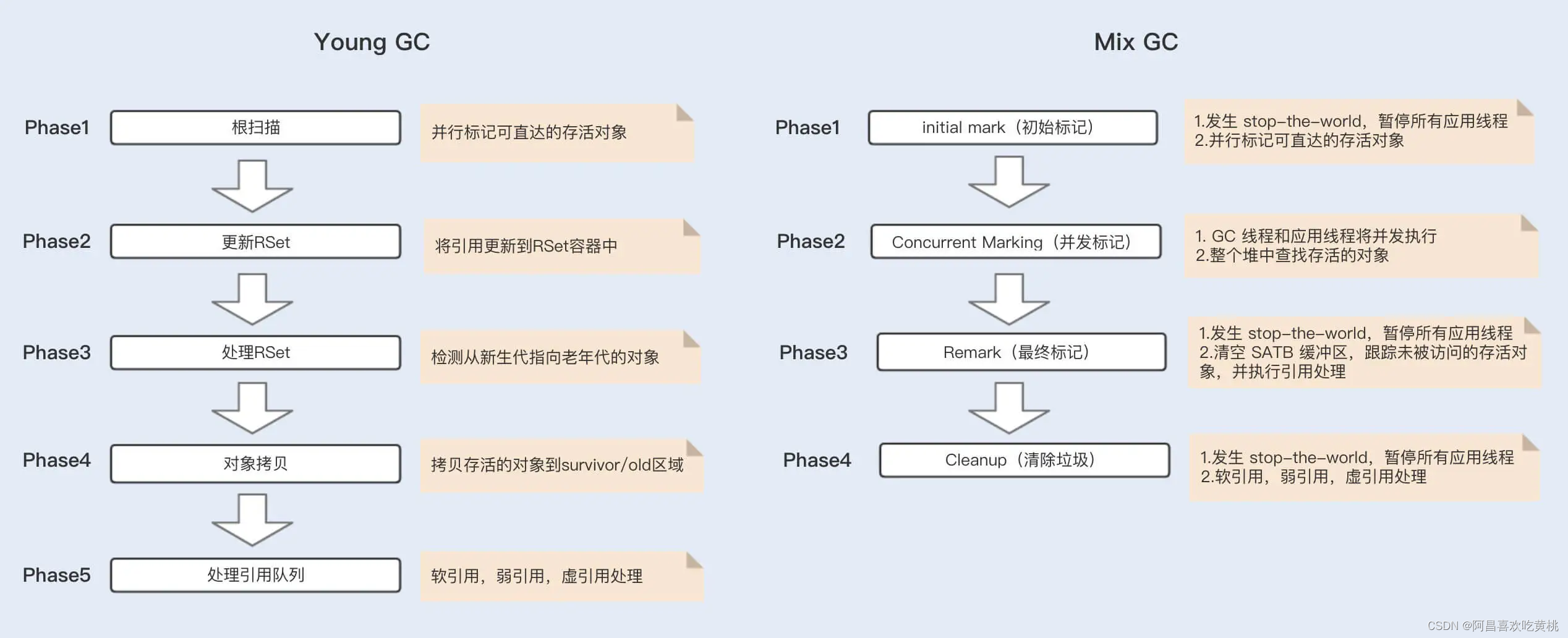
G1 分为 Young GC、Mix GC 以及 Full GC。G1 Young GC 主要是在 Eden 区进行,当 Eden 区空间不足时,则会触发一次 Young GC。
将 Eden 区数据移到 Survivor 空间时,如果 Survivor 空间不足,则会直接晋升到老年代。此时 Survivor 的数据也会晋升到老年代。Young GC 的执行是并行的,期间会发生 STW。
当堆空间的占用率达到一定阈值后会触发 G1 Mix GC(阈值由命令参数 -XX:InitiatingHeapOccupancyPercent 设定,默认值 45),Mix GC 主要包括了四个阶段,其中只有并发标记阶段不会发生 STW,其它阶段均会发生 STW。
G1 和 CMS 主要的区别在于:
- CMS 主要集中在老年代的回收,而 G1 集中在分代回收,包括了年轻代的 Young GC 以及老年代的 Mix GC;
- G1 使用了 Region 方式对堆内存进行了划分,且基于标记整理算法实现,整体减少了垃圾碎片的产生;
- 在初始化标记阶段,搜索可达对象使用到的 Card Table,其实现方式不一样。
Card Table,在垃圾回收的时候都是从 Root 开始搜索,这会先经过年轻代再到老年代,也有可能老年代引用到年轻代对象,如果发生 Young GC,除了从年轻代扫描根对象之外,还需要再从老年代扫描根对象,确认引用年轻代对象的情况。这种属于跨代处理,非常消耗性能。为了避免在回收年轻代时跨代扫描整个老年代,CMS 和 G1 都用到了 Card Table 来记录这些引用关系。
只是 G1 在 Card Table 的基础上引入了 RSet,每个 Region 初始化时,都会初始化一个 RSet,RSet 记录了其它 Region 中的对象引用本 Region 对象的关系。除此之外,CMS 和 G1 在解决并发标记时漏标的方式也不一样,CMS 使用的是 Incremental Update 算法,而 G1 使用的是 SATB 算法。
首先,要了解在并发标记中,G1 和 CMS 都是基于三色标记算法来实现的:
- 黑色:根对象,或者对象和对象中的子对象都被扫描;
- 灰色:对象本身被扫描,但还没扫描对象中的子对象;
- 白色:不可达对象。
基于这种标记有一个漏标的问题,也就是说,当一个白色标记对象,在垃圾回收被清理掉时,正好有一个对象引用了该白色标记对象,此时由于被回收掉了,就会出现对象丢失的问题。
为了避免上述问题,CMS 采用了 Incremental Update 算法,只要在写屏障(write barrier)里发现一个白对象的引用被赋值到一个黑对象的字段里,那就把这个白对象变成灰色的。而在 G1 中,采用的是 SATB 算法,该算法认为开始时所有能遍历到的对象都是需要标记的,即认为都是活的。
G1 具备 Pause Prediction Model ,即停顿预测模型。用户可以设定整个 GC 过程中期望的停顿时间,用参数 -XX:MaxGCPauseMillis 可以指定一个 G1 收集过程的目标停顿时间,默认值 200ms。
G1 会根据这个模型统计出来的历史数据,来预测一次垃圾回收所需要的 Region 数量,通过控制 Region 数来控制目标停顿时间的实现。
5、minor gc是否会导致stop the world?
不管什么 GC,都会发送 stop-the-world,区别是发生的时间长短。
而这个时间跟垃圾收集器又有关系,Serial、PartNew、Parallel Scavenge 收集器无论是串行还是并行,都会挂起用户线程,而 CMS 和 G1 在并发标记时,是不会挂起用户线程的,但其它时候一样会挂起用户线程,stop the world 的时间相对来说就小很多了。
6、major gc什么时候会发生,它和full gc的区别是什么?
Major Gc 在很多参考资料中是等价于 Full GC 的,我们也可以发现很多性能监测工具中只有 Minor GC 和 Full GC。一般情况下,一次 Full GC 将会对年轻代、老年代、元空间以及堆外内存进行垃圾回收。
触发 Full GC 的原因:
- 当年轻代晋升到老年代的对象大小,并比目前老年代剩余的空间大小还要大时,会触发 Full GC;
- 当老年代的空间使用率超过某阈值时,会触发 Full GC;
- 当元空间不足时(JDK1.7 永久代不足),也会触发 Full GC;
- 当调用 System.gc() 也会安排一次 Full GC。
7、minor gc回收之后eden区存活对象的多少
jmap-heap pid在图中只能看年轻代parallel gc看不到老年代的是什么垃圾回收器对于提问cms垃圾回收器还是分老年代和年轻代回收分多个阶段有和程序并行的阶段也有stop the world阶段回收一整块老年代时间比较久,而gc把年轻代和老年代也有划分,不过拆成一个region了,对region的回收成本低,而且会判断那些region回收的对象更多,而且cms要经过多次full gc才可能把不用的内存归还给操作系统而g1只需要一次full gc就可以可以通过 jstat -gc pid interval 查看每次 GC 之后,具体每一个分区的内存使用率变化情况。
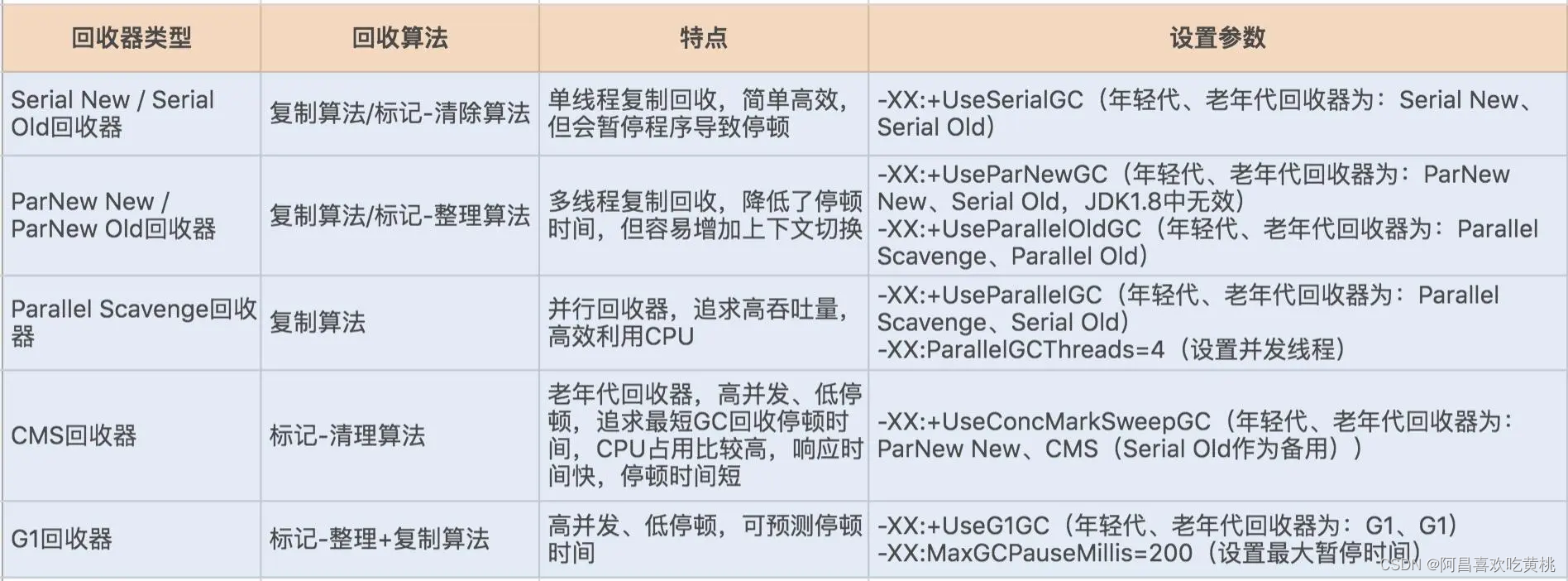
可以通过 JVM 的设置参数,来查看垃圾收集器的具体设置参数,使用的方式有很多,例如 jcmd pid VM.flags 就可以查看到相关的设置参数。

各个设置参数对应的垃圾收集器图表。
8、当第一次创建对象的时候eden空间不足会进行一次minor gc把存活的对象放到from s区。如果这个时候from s放不下。会发生一次担保进入老年代吗?当一次创建对象的时候eden空间不足进入from s区。当第二次创建对象的时候eden空间又不足了,这个时候会把,eden和第一次存在from s区的对象进行gc存活的放在tos区,tos区空间不足,进行担保放入老年代?
前提是老年代有足够接受这些对象的空间,才会进行分配担保。
如果老年代剩余空间小于每次 Minor GC 晋升到老年代的平均值,则会发起一次 Full GC。
10、AdaptiveSizePolicy这个参数是不是不太智能啊?我项目4G内存默认开启的AdaptiveSizePolicy。发现只给年轻代分配了136M内存。平时运行到没啥问题,没到定时任务的点就频繁FGC。每次定时任务执行完,都会往老年代推40多M,一天会堆300多M到老年代,也不见它把年轻代调大。用的parNew+CMS。后来把年轻代调整到1G(单次YGC耗时从20ms增加到了40ms),每天老年代内存涨20M左右。
创建对象占用的内存使用率,合理分配内存,并不仅仅考虑对象晋升的问题,还会综合考虑回收停顿时间等因素。针对某些特殊场景,可以手动来调优配置。
11、如何避免threadLocal内存池泄漏呢
ThreadLocal 是基于 ThreadLocalMap 实现的,这个 Map 的 Entry 继承了 WeakReference,而 Entry 对象中的 key 使用了 WeakReference 封装,也就是说 Entry 中的 key 是一个弱引用类型,而弱引用类型只能存活在下次 GC 之前。
如果一个线程调用 ThreadLocal 的 set 设置变量,当前 ThreadLocalMap 则会新增一条记录,但由于发生了一次垃圾回收,此时的 key 值就会被回收,而 value 值依然存在内存中,由于当前线程一直存在,所以 value 值将一直被引用。
这些被垃圾回收掉的 key 就会一直存在一条引用链的关系:Thread --> ThreadLocalMap–>Entry–>Value。
这条引用链会导致 Entry 不会被回收,Value 也不会被回收,但 Entry 中的 key 却已经被回收的情况发生,从而造成内存泄漏。我们只需要在使用完该 key 值之后,将 value 值通过 remove 方法 remove 掉,就可以防止内存泄漏了。
12、请问一下老师内存泄露和内存溢出具体有啥区别
内存泄漏是指不再使用的对象无法得到及时的回收,持续占用内存空间,从而造成内存空间的浪费。例如,Java6 中 substring 方法就可能会导致内存泄漏。当调用 substring 方法时会调用 new string 构造函数,此时会复用原来字符串的 char 数组,而如果我们仅仅是用 substring 获取一小段字符,而在原本 string 字符串非常大的情况下,substring 的对象如果一直被引用,由于 substring 里的 char 数组仍然指向原字符串,此时 string 字符串也无法回收,从而导致内存泄露。
内存溢出则是发生了 OutOfMemoryException,内存溢出的情况有很多,例如堆内存空间不足,栈空间不足,还有方法区空间不足等都会导致内存溢出。内存泄漏与内存溢出的关系:内存泄漏很容易导致内存溢出,但内存溢出不一定是内存泄漏导致的。