验证链(CoVE)降低LLM中的幻觉
- 摘要
- 1 引言
- 2 相关工作
- 3 验证链(Chain-of-Verification)
- 3.1 生成基准回答
- 3.2 计划验证
- 3.3 执行验证
- 3.4 最终验证的回答
- 4 实验(直译)
- 4.1 任务
- 4.1.1 WIKIDATA
- 4.1.2 WIKI-CATEGORY LIST
- 4.1.3 MULTISPANQA
- 4.1.4 生物传记的长篇生成
- 4.2 基准

摘要
在大型语言模型中,生成看似正确但实际上是错误的事实信息,即所谓的幻觉,是一个尚未解决的问题。本文研究了语言模型在给出回答时进行自我纠正的能力。开发了一种称为“验证链”(COVE)的方法,通过该方法,模型首先
(i)起草一个初始回答;
(ii)计划验证问题,对其起草的回答进行事实核查;(iii)独立回答这些问题,以避免答案受其他回答的偏见影响
(iv)生成经过验证的最终回答。
在实验证明中,展示了COVE在各种任务中减少了幻觉的发生,包括基于维基数据的基于列表的问题、闭卷的MultiSpanQA和长篇文本生成等任务。
1 引言
大型语言模型(LLM)是在包含数十亿个标记的文本文档的大型语料库上进行训练的。研究表明,随着模型参数的增加,像闭卷QA这样的任务的性能在准确性上有所提高,而更大的模型可以生成更多正确的事实陈述。然而,即使是最大的模型仍然可能失败,特别是在较少人知的中等和尾部分布的事实上,即在训练语料库中相对罕见的事实。在模型错误的情况下,它们会生成一个通常看起来合理的替代性回答(例如,一个类似的实体,但是错误的实体)。这些事实上的错误生成被称为幻觉。此外,在生成多个句子或段落的长篇任务中,由于暴露偏差的问题,幻觉问题可能会加剧。
当前的语言建模研究超越了“下一个词预测”,并专注于它们的推理能力。
通过鼓励语言模型首先生成内部思考或推理链,然后再进行回答,可以提高推理任务的性能,以及通过自我批评来更新初始回答。
在这项工作中,沿着这一研究方向,研究基于语言模型的推理如何减少幻觉的生成。开发了一种称为“验证链”(CoVe)的方法,根据初始草稿回答,
(1)计划验证问题以检查其工作,
(2)系统地回答这些问题,
(3)生成改进的修订回答。
由此发现,独立的验证问题往往提供比原始长篇答案更准确的事实,并因此提高了整体回答的正确性。
假设有以下对话:
用户:请问巴黎是法国的首都吗?
模型:是的,巴黎是法国的首都。
在CoVe方法中,模型会生成一个初始回答,然后计划一系列独立验证问题来核查回答的准确性。在这个例子中,可能会生成以下验证问题:
1.巴黎是哪个国家的首都?
2.法国的首都是哪个城市?
3.巴黎是法国的首都吗?
模型会独立回答这些问题,例如:
1.巴黎是法国的首都。
2.法国的首都是巴黎。
3.是的,巴黎是法国的首都。
本文研究了在各种任务中对这种方法的变化:从基于列表的问题,闭卷QA到长篇文本生成。
- 提出了一种从左到右生成整个验证链的联合方法,与基线语言模型相比,它提高了性能并减少了幻觉。
- 注意到自己生成的上下文中现有的幻觉的模型往往会重复这些幻觉。因此,还引入了进一步的改进,
- 采用分解变体将验证链步骤分开,从而确定要关注的上下文。展示了这些分解变体如何在考虑的所有三个任务中进一步提高性能。
2 相关工作
幻觉是语言模型生成中的一个普遍问题,出现在许多任务中,包括摘要生成和开放域对话,简单地增加训练数据或模型大小并不能解决这个问题。减少幻觉的方法大致可以分为三类:
- 训练时纠正、
- 生成时纠正
- 辅助工具(增强)。
在训练时纠正的方法中,通过训练或调整模型权重来减少幻觉生成的概率,以改善编码器-解码器或仅解码器语言模型的原始从左到右生成结果。这包括使用强化学习、对比学习和其他方法。
在生成时纠正方法中,一个常见的主题是在基础语言模型的基础上进行推理决策,以使其更可靠。例如,通过考虑生成标记的概率。在Manakul等人的研究中,从模型中抽取多个样本来检测幻觉。在Varshney等人的研究中,通过低置信度分数识别幻觉,并通过验证过程进行修正,然后继续生成。利用置信度分数的替代方法是利用语言模型输出的不一致性来检测幻觉。Agrawal等人的研究使用多个样本和一致性检测来进行直接和间接查询,以检查幻觉引用。Cohen等人的研究引入了一种称为“LM vs LM”的方法,模拟了两个语言模型之间的交互设置,其中一个语言模型充当检查员,并通过反复交叉审查来测试输出是否一致。Cohen等人的研究表明,在QA任务中使用不一致性来检测幻觉可以胜过使用置信度分数。CoVe方法也采用了类似的自一致性方法,但没有多代理(多个语言模型)辩论的概念。
第三种方法是使用外部工具来帮助减少幻觉,而不仅仅依靠语言模型本身的能力。例如,通过使用事实文档进行基础的检索增强生成或思维链验证。其他方法包括使用事实检查工具或与外部文档的链接和归因。
还有一些相关的工作致力于改善逻辑和数学任务的推理,即使它们没有明确解决减少幻觉的问题。一些方法已经显示出通过系统进行扩展推理步骤可以改善结果,例如思维链、演绎验证和自我验证。后者试图根据答案预测(被屏蔽的)问题,并将其作为证据表明这是正确的解感谢提供的文本。根据提供的信息,许多方法被用来减少语言模型生成中的幻觉问题。这些方法可以分为三类:
- 训练时纠正方法:通过训练或调整模型权重来减少幻觉生成的概率。这包括使用强化学习、对比学习和其他方法。
- 生成时纠正方法:在生成过程中对基础语言模型进行推理决策,以提高生成结果的可靠性。例如,考虑生成标记的概率,从模型中抽取多个样本来检测幻觉,使用置信度分数识别幻觉并进行修正,以及利用不一致性来检测幻觉。
- 辅助工具方法:使用外部工具来帮助减少幻觉。例如,通过检索基于事实的文档或进行思维链验证,使用事实检查工具或链接外部文档来降低幻觉的发生。
这些方法的目标是提高语言模型生成的准确性并减少幻觉的出现。此外,还有一些与逻辑和数学任务相关的方法,虽然它们没有明确解决幻觉问题,但可以改善推理结果。
3 验证链(Chain-of-Verification)
本文的方法假设有一个基础语言模型(LLM),尽管可能容易产生幻觉,但可以通过一些样本或零样本方式进行通用指令提示。一个关键假设是,当适当地提示时,这个语言模型能够生成和执行一个验证自身的计划,以检查自己的工作,并将这个分析结果融入到改进后的回答中。
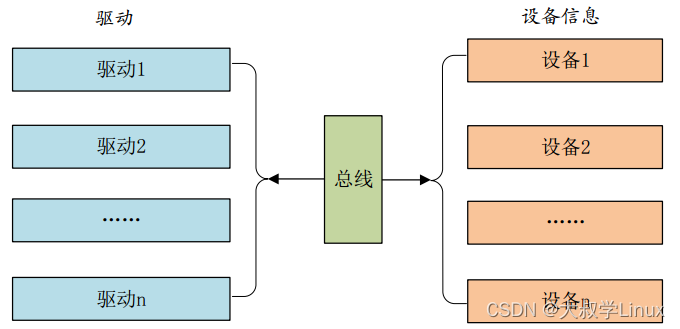
整体过程被称为验证链(CoVe),包括以下四个核心步骤:
- 生成基准回答:给定一个查询,使用基础语言模型生成回答。
- 计划验证:根据查询和基准回答,生成一系列验证问题,这些问题可以帮助自我分析原始回答是否存在错误。
- 执行验证:依次回答每个验证问题,并将答案与原始回答进行对比,以检查是否存在不一致或错误。
- 生成最终验证回答:根据发现的不一致性(如果有),生成一个修订后的回答,将验证结果纳入其中。
每个步骤都通过以不同方式提示相同的语言模型来实现所需的回答。步骤(1)、(2)和(4)可以使用单个提示调用,而本文研究了步骤(3)的多种变体,包括联合、两步和分解版本。这些变体可能涉及单个提示、两个提示或每个问题独立的提示,更复杂的分解可以获得改进的结果。
下面更详细地描述了这些步骤。方法的概述如图1所示,并在附录的图3中有示意图。

3.1 生成基准回答
给定一个查询,像通常一样使用基础语言模型(LLM)进行从左到右的生成,没有特殊技巧。虽然这是CoVe流程中的第一步,但它也作为在实验中希望改进的基准(即,将直接将这个基准回答与我们整体方法的最终验证回答进行比较)。
由于这样的基准生成通常容易产生幻觉,CoVe试图在接下来的步骤中识别和纠正这些幻觉。
3.2 计划验证
在给定原始查询和基准回答的条件下,模型被提示生成一系列验证问题,以测试原始基准回答中的事实性陈述。例如,如果一个长文回答的一部分包含了这样的陈述:
“墨西哥-美国战争是美国和墨西哥之间的武装冲突,发生在1846年至1848年”,
那么一个可能的验证问题来检查这些日期的准确性可能是:
“墨西哥-美国战争是在什么时候开始和结束的?”
由此可以发现,验证问题并不是模板化的,语言模型可以以任何形式来表述这些问题,而且它们也不必与原始文本的措辞非常相似。
在实验中,通过向LLM提供(回答,验证)的几个示范来执行这样的验证计划。有关实验中将使用的几个示范,请参阅第8节。注意到,如果有一个足够高效的指令跟随LLM,也可以进行零样本的验证计划。
3.3 执行验证
给定计划好的验证问题,下一步是 回答这些问题以评估是否存在幻觉 。虽然在这个过程中可以使用检索增强等技术,比如通过搜索引擎进行验证,但在这项工作中没有探索工具的使用。相反,只考虑在CoVe的所有步骤中仅使用LLM本身,因此模型用于检查自己的工作。研究了几种验证执行的变体,包括联合方法、两步法、分解法和分解+修订法。
联合方法: 在联合方法中,计划和执行(步骤2和3)通过使用单个LLM提示完成,即少样本示范包括验证问题和问题后紧接着的答案。在这种方法中,不需要单独的提示。
两步法: 联合方法的一个潜在劣势是,由于验证问题必须在LLM上下文中以基准回答为条件,而且方法是联合的,验证答案也必须以初始回答为条件。这可能增加了重复的可能性,这是现代LLM的另一个已知问题。这意味着验证问题可能会产生类似于原始基准回答的幻觉,这与目标相悖。因此,将计划和执行分为两个独立的步骤,每个步骤都有自己的LLM提示。第一步的计划提示以基准回答为条件。从计划中生成的验证问题在第二步中回答,关键是LLM提示给出的上下文只包含问题,而不包含原始基准回答,因此不能直接重复那些答案。
分解法: 另一种更复杂的方法是独立地回答所有问题,作为单独的提示。同样重要的是,这些提示不包含原始基准回答,因此不容易简单地复制或重复它。分解法进一步的优点是不仅消除了基准回答的潜在干扰,而且消除了答案上下文之间的任何潜在干扰,这与Radhakrishnan等人最近的(同时进行的)子问题回答工作有一定的关联,因此我们采用了他们的命名方法。它还可以通过它们不必都适应相同的单一上下文来处理更多的验证问题。虽然这可能计算上更昂贵,需要执行更多的LLM提示,但它们可以并行运行,因此可以进行批处理。为了做到这一点,我们首先需要将3.2节生成的问题集合解析成单独的问题,这是一个相对容易的任务,因为我们提供的少样本示范表明它们应该以逗号分隔的列表形式生成。然后我们可以将它们拆分成单独的LLM提示。
分解+修订法: 在回答验证问题之后,整个CoVe流程需要隐式或显式地交叉检查这些答案是否与原始回答存在不一致。在分解+修订法中,我们通过额外的LLM提示将这一步骤作为一个有意识的步骤来执行,这可能使最终系统更容易显式地推理这一步骤。与回答验证问题不同,交叉检查阶段需要同时以基准回答和验证问题及其答案为条件。因此,我们将其作为单独的LLM提示来执行,每个问题都有一个“交叉检查”提示,其中包含一组少样本示范,显示所需的输出。例如,如果原始基准回答包含了短语“紧随美国在1845年吞并德克萨斯之后……”,而CoVe生成了一个验证问题“德克萨斯何时脱离墨西哥?”并以1836年回答,那么这一步骤应该检测到不一致性。
3.4 最终验证的回答
最后,生成考虑验证的改进回答。这通过一个最终的少样本提示来执行,在这个提示中,上下文考虑了所有之前的推理步骤、基准回答和验证问题答案对,以便进行修正。如果使用了3.3节中的分解+修订法,那么交叉检查不一致性检测的输出也会被提供。
4 实验(直译)
使用各种实验基准来衡量CoVe在减少幻觉方面的效果,并与多个基准进行比较。
4.1 任务
使用的基准涵盖了从基于列表的问题(需要的答案是一组实体)到需要生成多个自由形式句子的长篇生成问题。
4.1.1 WIKIDATA
首先在使用Wikidata API生成的一组问题上测试CoVe。创建了形式为“在[城市]出生的一些[职业]是谁?”的列表问题。例如,“在波士顿出生的一些政治家是谁?”。这些问题的答案是一组实体,其中金标列表来自Wikidata知识库。这样,得到了一个包含56个测试问题的数据集,每个问题通常包含大约600个已知的金标实体,但通常一个LLM会生成一个更短的列表。然后,使用精确度度量(微平均)来衡量性能,并报告生成的正面实体和负面实体的平均数。
4.1.2 WIKI-CATEGORY LIST
然后,转向一个更难的集合生成任务。使用了使用维基百科类别列表创建的QUEST数据集。通过简单地在类别名称前加上“列出一些”来将这些类别名称转换为问题。由于问题的多样性,例如“列出一些墨西哥的动画恐怖电影”或“列出一些越南的特有兰花”,我们认为这个任务可能更具挑战性。收集了数据集中不需要逻辑操作的所有示例,每个问题都有8个答案。与Wikidata任务类似,使用精确度度量(微平均)来衡量性能,并报告生成的正面实体和负面实体的平均数。
4.1.3 MULTISPANQA
接下来,我们在阅读理解基准测试MultiSpanQA(Li等人,2022)上测试我们的方法。MultiSpanQA包括具有多个独立答案的问题(这些答案来自文本中一系列不连续的跨度,问题最初来自自然问题数据集)。我们考虑了一个闭卷设置,在这种情况下,我们不提供支持文档,并且因此考虑了一部分基于事实的问题,这样我们的基准LLM更有可能能够回答这些问题。因此,我们使用了一个包含418个问题的测试集,每个跨度的答案较短(每个项目最多3个标记)。例如,Q: 谁发明了第一台印刷机,并在哪一年? A: 约翰内斯·古腾堡,1450年。
4.1.4 生物传记的长篇生成
接下来,我们验证CoVe在长篇文本生成方面的性能。在这个设置中,我们采用了Min等人(2023)提出的基准测试方法,评估我们的方法在生成传记方面的表现。在这里,模型只需使用提示“告诉我一个关于<实体>的传记”来生成所选实体的传记。我们使用Min等人(2023)在该工作中开发的FACTSCORE度量标准来评估我们方法的有效性,该度量标准使用了一个检索增强语言模型(Instruct-Llama,“Llama + Retrieval + NP”)来对生成的回答进行事实检查,他们证明这与人类判断密切相关。
4.2 基准
使用Llama 65B作为我们的基准LLM模型,并对所有模型使用贪婪解码。由于Llama 65B没有进行指令微调,针对每个任务使用了少样本示例来衡量性能。这作为我们的主要基准,CoVe试图在此基础上进行改进。CoVe使用相同的Llama 65B基准模型,但在相同的少样本示例上,包括验证问题的演示和最终验证的回答,遵循图1和第3节的步骤。因此,我们衡量改进相同LLM的原始基准响应的能力。对于CoVe,我们比较了不同的变体,特别是在所有任务上的联合和分解版本。
还将其与进行了指令微调的Llama模型进行了比较,其中我们使用了Llama 2(Touvron等人,2023b)。我们在任务上衡量了零样本性能,或者在零样本提示中添加“让我们逐步思考”的链式思维。我们发现,当查询时,经过指令微调的模型往往会生成多余的内容。这对于基于列表的任务尤其成问题。为了解决这个问题,我们在提示中添加了额外的一行:“仅列出以逗号分隔的答案”。我们还添加了另一层后处理,通过使用现成的命名实体识别(NER)模型来提取答案,以进一步避免这个问题。然而,我们仍然期望少样本方法能够改进这一点,特别是对于像Multi-Span-QA这样的任务,其中答案不全是命名实体,并且少样本示例有效地展示了任务的领域。
对于生物传记的长篇生成,我们还与Min等人(2023)中报告的几个现有模型结果进行了比较,特别是InstructGPT(Ouyang等人,2022)、ChatGPT 2和PerplexityAI 3。