文章目录
- SWin-Transformer解读
-
- 1.基础介绍
- 关于Shifted Window based Self-Attention
-
- 相对位置偏置
- 网络整体结构和层级特征
欢迎访问个人网络日志🌹🌹知行空间🌹🌹
SWin-Transformer解读
1.基础介绍
Swin-Transformer是2021年03月微软亚洲研究院提交的论文中提出的,比ViT晚了半年左右,相对于ViT而言,Swin-Transformer的改进,使transformer能作为新的视觉任务backbone,用于分类分割和检测,姿态估计等任务。
论文:https://arxiv.org/abs/2103.14030
代码:https://github.com/microsoft/Swin-Transformer
Swin-Transformer是Shifted Window Transformer,作者指出了将transformer应用到视觉任务中需要解决的两个问题,
一个是在ViT中就已经提到的计算self attension时 Q K T d k V \frac{QK^T}{\sqrt{d_k}}V dkQKTV复杂度是序列长度L(在视觉任务中是image size)的平方,着限制了transformer处理大分辨率图像的能力。
另一个,对于像语义分割/目标检测这些任务,最好能输出层级的金字塔型的特征,以增加模型处理不同scale对象的能力,同时也更利于使用过去研究中已验证有效果的trick。
Swin-Transformer中作者针对上述两个问题提出的方法分别是Shifted Window based Self-Attention和随着网络的深度合并图像patch来生成层级特征图。
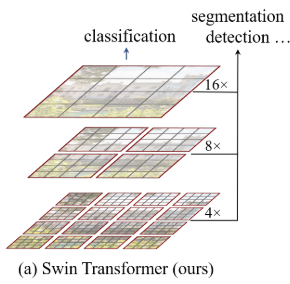
关于Shifted Window based Self-Attention
先来看transformer中的常规全局Multi-Head Self Attention(MSA)的计算复杂度,
Q=K=V,shape为(L, C) L对应的是序列的长度对于 h × w h\times w h×w的图像等同于 L = h × w L=h\times w L=h×w,C是模型的通道数等同于hidden_dims, W i Q , W i K , W i V W_i^Q,W_i^K,W_i^V WiQ,WiK,WiV对应的shape都为(C,C),MSA输出的通道数也是C,则 W O W^O WO的shape为(C,C)。那么,对于全局注意力机制的计算包括 Q W i Q QW_i^Q QWiQ, K W i K KW_i^K KWiK, V W i V VW_i^V VWiV, Q K T QK^T QKT, S V SV SV, A W O AW^O AWO这几部分,其中 S = s o f t m a x ( Q K T C ) S=softmax(\frac{QK^T}{\sqrt{C}}) S=softmax(C














![[MySQL]索引](https://img-blog.csdnimg.cn/f38a31b2abad424db1354583f0186437.png)