目录
概念解释
作用/优点
缺点
适用场景
索引的创建,删除与查看
系统对索引的自动创建
索引建立的时机
索引存储的数据结构
选择B+树的原因
B树的原理
查询流程
优点
B+树
与B树的区别
优点
概念解释
索引就像是一本字典的目录,我们可以根据目录快速定位到我们想要查找的字词
作用/优点
在数据库中,索引起到的作用是:
- 提升了数据库中查询数据的效率
- 降低数据库IO的成本(通过B+数来实现)
缺点
- 索引的创建是需要花费额外的空间
- 建立索引后,对于数据库中数据的增,删,改可能会增加耗费的成本,因为除了对数据库中数据的更改还要对索引进行调整.导致了效率的降低.
适用场景
根据上面的优点和缺点,可以看出索引的适用场景为:
频繁的进行查询操作,但不常对数据的增,删,改操作的表.
索引的创建,删除与查看
create index 索引名 on 表名(字段名); //创建普通索引
drop index 索引名 on 表名; //删除索引
show index from 表名; //查看索引系统对索引的自动创建
对于表中的主键,外键和被unique修饰的属性,系统会自动创建出对应的索引.
- 因为主键是大多数情况下对数据进行定位的属性,需要频繁查询.
- 而外键是与其他表进行连接查询的属性,也需要频繁的查询.
- unique则是在插入或修改数据的时候,需要先对表进行扫描一遍,查看unique修饰的属性是否有与即将插入的字符一致的数据
系统建立的索引我们是删除不掉的噢
索引建立的时机
索引的建立应当在初期(没有数据,或数据较少的时期)设计数据库表的时期一同设计,因为当表中已经存在了较多的数据的时候建立索引,就会消耗巨大的时间成本.
因为索引相当于给每一个数据都建立了一个定位,数据太多的画就要一遍一遍的对已存在的数据进行描扫.而且与此同时,在建立索引的时候,整个数据库其实是处于一种封锁的状态,并不能进行其他的操作.
如果在初期数据还没有存储或数据较少的时候建立起索引,消耗的时间成本就会非常小.以后每次新增添数据的时候再顺带的放入索引,相当于将时间均摊到每一条对数据的操作语句上.就比较容易让人接受
索引存储的数据结构
B+树
选择B+树的原因
1.hash
只能进行准确的定位,并不能满足于MySQL中的模糊查询(like),与范围查询
2.红黑树
虽然能满足模糊查询与范围查询,但是由于红黑树是一颗二叉树,存储数据会容易导致树的高度过高.在查询数据的时候可能会频繁的对磁盘进行读取,使得IO次数增加
所以一种专门为数据库量身定做的数据结构,B树被开发出来了.而B+树是B树的一种变形.
B树的原理
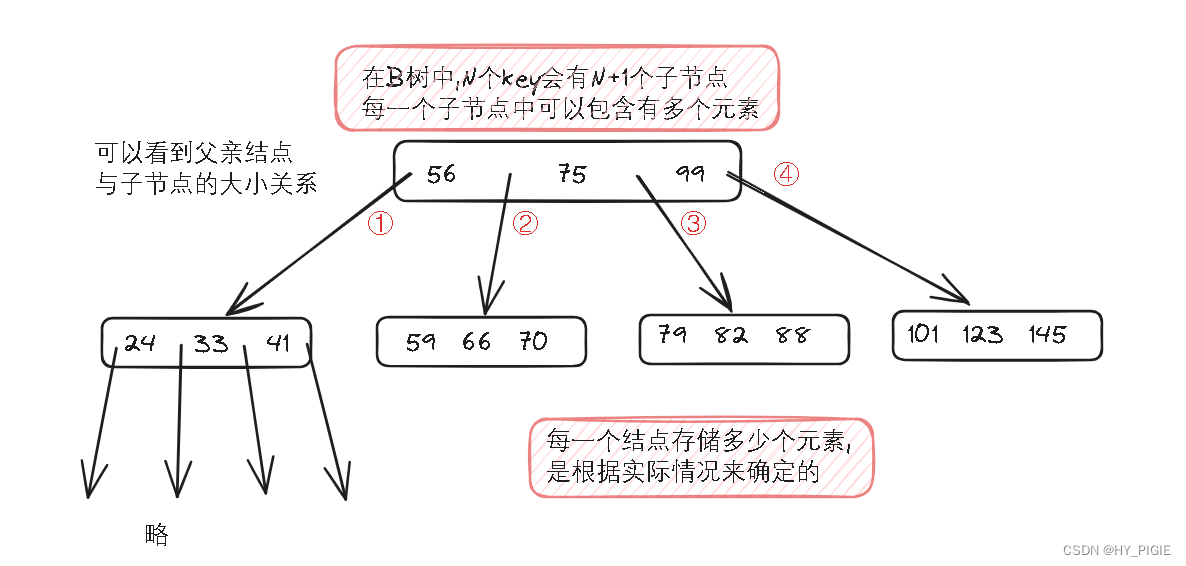
B树是一种N叉搜索树
结点中N个key会有N+1个key结点
查询流程
从根结点出发 -> 查看目标是否存在此结点,
如果不存在,就看元素是落在此结点的哪一个区间内,根据区间继续往下面的子树找.
如果存在,则返回.
优点
1.由于B树是N叉搜索树,且一个结点可以存放多个数据.对于总的元素个数来说,B树的高度会远小于二叉树.
2.树高度的减少,就会相应的降低了从磁盘中读取数据的次数,降低了IO的成本
B+树
与B树的区别
-
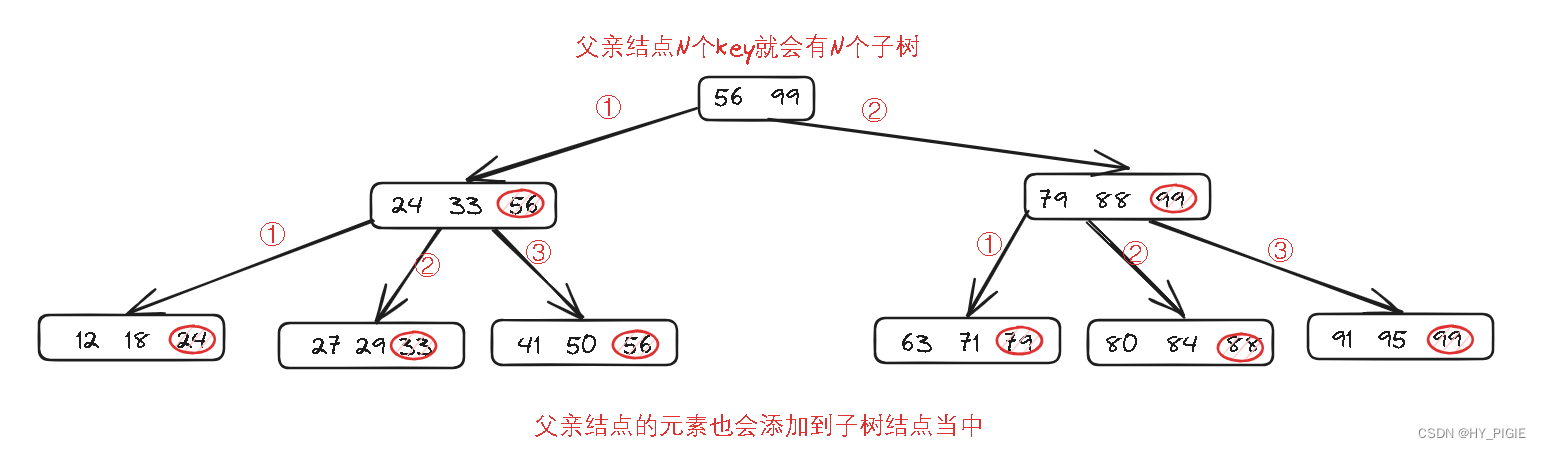
- 与B树不同的点是,B+树一个结点N个key只会有N个子树.
- 且B+树的子结点会包含有父亲结点中区间内最大的元素.
优点
可以看到B+树的叶子结点中,包含了整棵树的所有结点,是一个全集.此时再帮叶子结点建立链接,就像链表一样.
1.因为这个特性,B+树就特别擅长范围查找.

2.只有叶子结点储存行单元,非叶子结点存储行单元的主键.
节省了存储的空间,B+树就会变得特别小,可以直接放在存储空间中.又提升了读取数据的效率(B树的叶子结点不是全集,每一个结点的元素都是一个行单元)
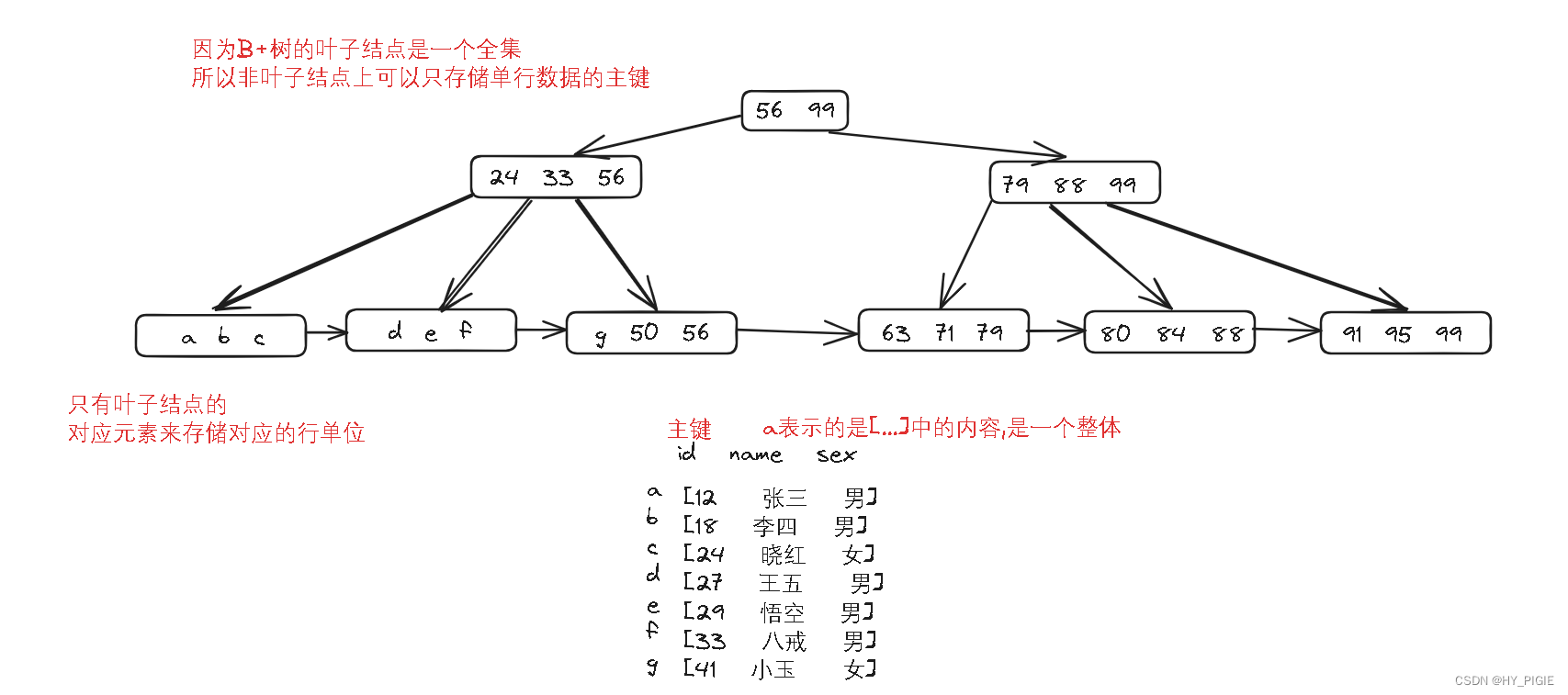
3.N叉树的特性,树高度不高,减少了IO次数

![[黑马程序员Pandas教程]——Pandas快速体验](https://img-blog.csdnimg.cn/703e7543f468482f92ecdad2b4c485b1.png)

![[SHCTF 2023 校外赛道] reverse](https://img-blog.csdnimg.cn/c18e59a2b01f4c7884f77238f5ac05de.png)