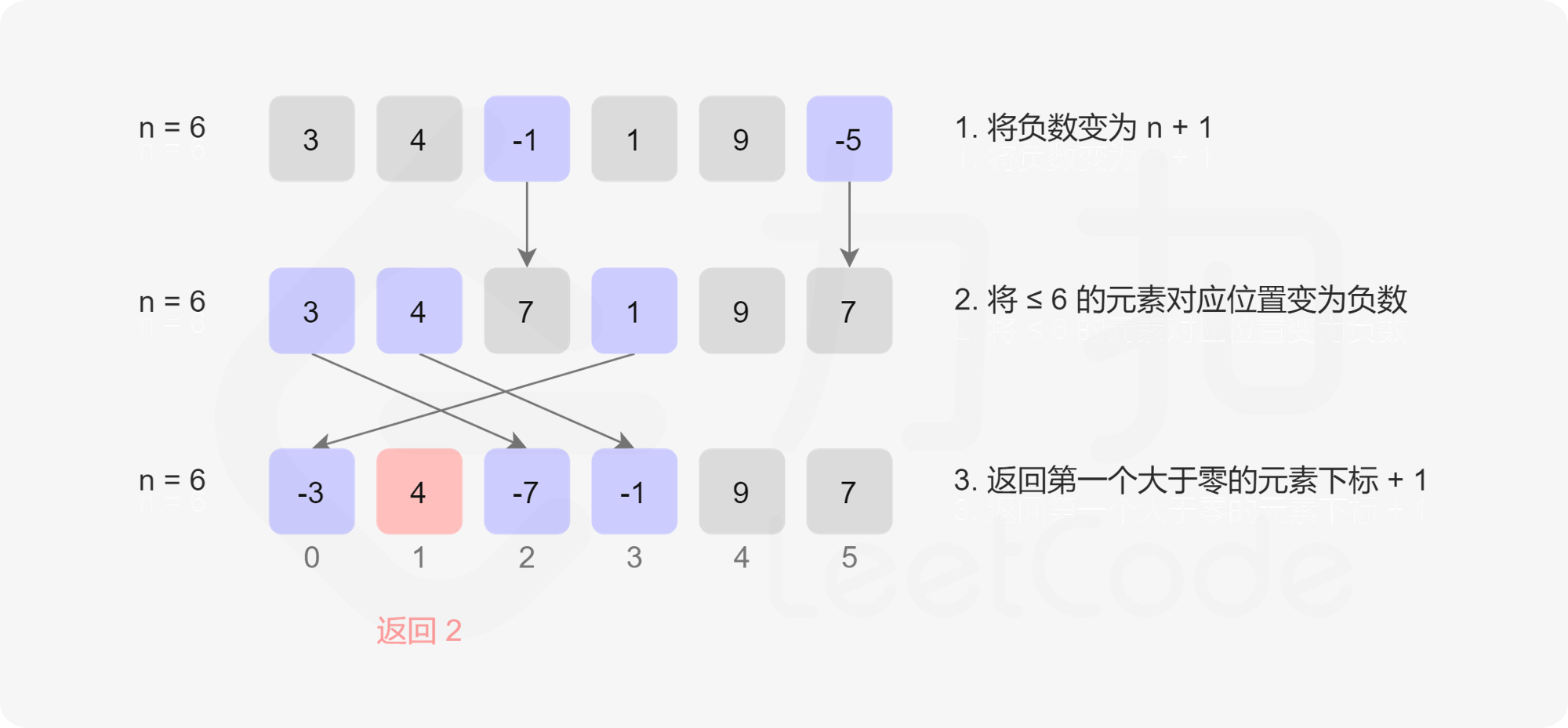
理解扩散模型的微调Fine-tuning和引导Guidance
- 1. 环境准备
- 2. 加载预训练过的管线
- 3. DDIM——更快的采样过程
- 4. 微调
- 5. 引导
- 6. CLIP引导
- 参考资料
微调(Fine-tuning)指的是在预先训练好的模型上进行进一步训练,以适应特定任务或领域的过程。这个过程在机器学习和深度学习领域中常常被使用。
通过微调,可以使用先前在大规模数据集上训练好的模型来学习新数据的特定特征,以完成特定的任务。微调的关键在于利用已经学到的通用特征,通过在特定任务数据集上进行少量训练,使模型适应新的任务。
引导(Guidance)通常指的是在某种领域或任务中,给予模型特定的指导、提示或信息,以帮助模型更好地学习和完成特定任务。这可能包括提供额外的信息、特定的特征选择,或者对模型进行优化的技巧和方法。
微调和引导是两种不同但相关的概念,都涉及在模型训练过程中提供额外的指导信息或训练方式,以使模型更适应特定任务或领域。简而言之:
- 微调:在新的数据集上重新训练已有的模型,以改变原有的输出类型。
- 引导:在推理阶段引导现有模型的生成过程,以获取额外的控制。
- 条件生成:在训练过程中产生的额外信息,导入到模型中进行预测,通过输入相关信息作为条件来控制模型的生成。
将条件信息输入模型的方法:
- 将条件信息作为额外的通道输入UNet模型。这种情况下,条件信息通常与图像具有相同的形状。
- 将条件信息转换成embedding,然后将embedding通过投影层映射来改变其通道数,从而可以对齐模型中间层的输出通道,最后将embedding加到中间层的输出上。通常情况下,这是将时间步当作条件时的做法。
- 添加带有交叉注意力(cross-attention)机制的网络层。这种方法在条件是某种形式的文本时最有效。
1. 环境准备
安装一些依赖库:
!pip install -qq diffusers datasets accelerate wandb open-clip-torch
注意,这里用到了Weights and Biases功能以记录训练日志。
使用一个具有写权限的访问令牌登录HuggingFace Hub:
from huggingface_hub import notebook_login
notebook_login()
导入需要使用的库,并查看当前设备:
import numpy as np
import torch
import torch.nn.functional as F
import torchvision
from datasets import load_dataset
from diffusers import DDIMScheduler, DDPMPipeline
from matplotlib import pyplot as plt
from PIL import Image
from torchvision import transforms
from tqdm.auto import tqdm
device = ("mps" if torch.backends.mps.is_available() else "cuda" if torch.cuda.is_available() else "cpu")
device
2. 加载预训练过的管线
首先加载一个现有的管线:
生成图片:
images = image_pipe().images
images[0]

3. DDIM——更快的采样过程
在生成图像的每一步中,模型都会接收一个带有噪声的输入,并且需要预测这个噪声,以此来估计没有噪声的完整图像是什么。但是当步骤很多的时候,就需要引入采样。在Diffusers库中,这些采样方法是通过调度器进行控制的,每次更新则是由step()函数来完成的。
Song J, Meng C, Ermon S. Denoising diffusion implicit models[J]. arXiv preprint arXiv:2010.02502, 2020.
去噪扩散概率模型(DDPM)在不需要对抗性训练的情况下实现了高质量的图像生成,但在生成样本时需要对马尔可夫链进行多步模拟。为了加快采样速度,我们提出了一种去噪扩散隐式模型(DDIM) ,这是一类更有效的迭代隐式概率模型,其训练过程与 DDPM 相同。在 DDPM 中,生成过程被定义为马尔可夫扩散过程的逆过程。我们构造了一类非马尔可夫扩散过程,它导致相同的训练目标,但其反向过程可以更快地从样本。实验结果表明,与 DDPM 相比,DDIM 可以更快地生成10 ~ 50倍的高质量样本,并且可以在潜在空间中直接进行语义有意义的图像插值。
为了生成图像,从随机噪声开始,在每个时间步都将带有噪声的输入送入模型,并将模型的预测结果再次输入step()函数,其实整个过程是从高噪声到低噪声。

使用4幅随机噪声图像进行循环采样,并观察每一步的输入图像与预测结果的去噪版本:
# batch_size为4,三通道,长,宽均为256像素的一组图像
x = torch.randn(4, 3, 256, 256).to(device)
# 循环时间步
for i, t in tqdm(enumerate(scheduler.timesteps)):
# 准备模型输入,给带噪图像加上时间步信息
model_input = scheduler.scale_model_input(x, t)
# 预测噪声
with torch.no_grad():
noise_pred = image_pipe.unet(model_input, t)["sample"]
# 使用调度器计算更新后的样本应该是什么样子
scheduler_output = scheduler.step(noise_pred, t, x)
# 更新输入图像
x = scheduler_output.prev_sample
# 绘制输入图像和预测的去噪图像
if i%10==0 or i==len(scheduler.timesteps)-1:
fig, axs = plt.subplots(1,2, figsize=(12,5))
grid = torchvision.utils.make_grid(x, nrow=4).permute(1, 2, 0)
axs[0].imshow(grid.cpu().clip(-1, 1) * 0.5 + 0.5)
axs[0].set_title(f"Current x (step {i})")
pred_x0 = scheduler_output.pred_original_sample
grid = torchvision.utils.make_grid(pred_x0, nrow=4).permute(1, 2, 0)
axs[1].imshow(grid.cpu().clip(-1, 1) * 0.5 + 0.5)
axs[1].set_title(f"Predicted denoised images (step {i})")
plt.show()





显然,随着过程的推进,预测图像的效果逐步得到改善。
直接使用新的调度器替换原有管线中的调度器,然后进行采样:
image_pipe.scheduler = scheduler
images = image_pipe(num_inference_steps=40).images
images[0]

4. 微调
首先,使用蝴蝶图像集创建data_loader:

image_size = 256
batch_size = 4
preprocess = transforms.Compose(
[
transforms.Resize((image_size, image_size)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
def transform(examples):
images = [preprocess(image.convert("RGB")) for image in examples["image"]]
return {"images": images}
dataset.set_transform(transform)
train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
输出4幅蝴蝶图像:
print("Previewing batch:")
batch = next(iter(train_dataloader))
grid = torchvision.utils.make_grid(batch["images"], nrow=4)
plt.imshow(grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5);

注意:要权衡好batch size和图像尺寸,以适应GPU显存。
接下来是训练循环。首先把想要优化的目标参数设定为image_pipe.unet.parameters(),以更新预训练过的模型的权重:
绘制损失曲线:
plt.plot(losses)
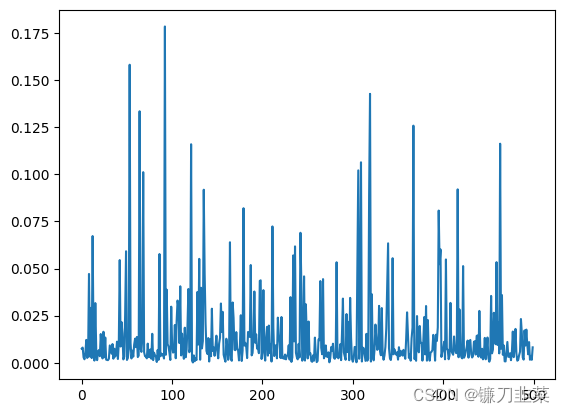
显然,损失曲线非常混乱。这是因为每次迭代只使用了4个训练样本,并且添加到它们的噪声水平也都是随机的。一种弥补措施是使用一个非常小的学习率,以限制每次更新的幅度。另一种更好的方法是进行梯度累计(gradient accumulation),这样既能得到与使用更大batch size一样的收益,又不会造成内存溢出。
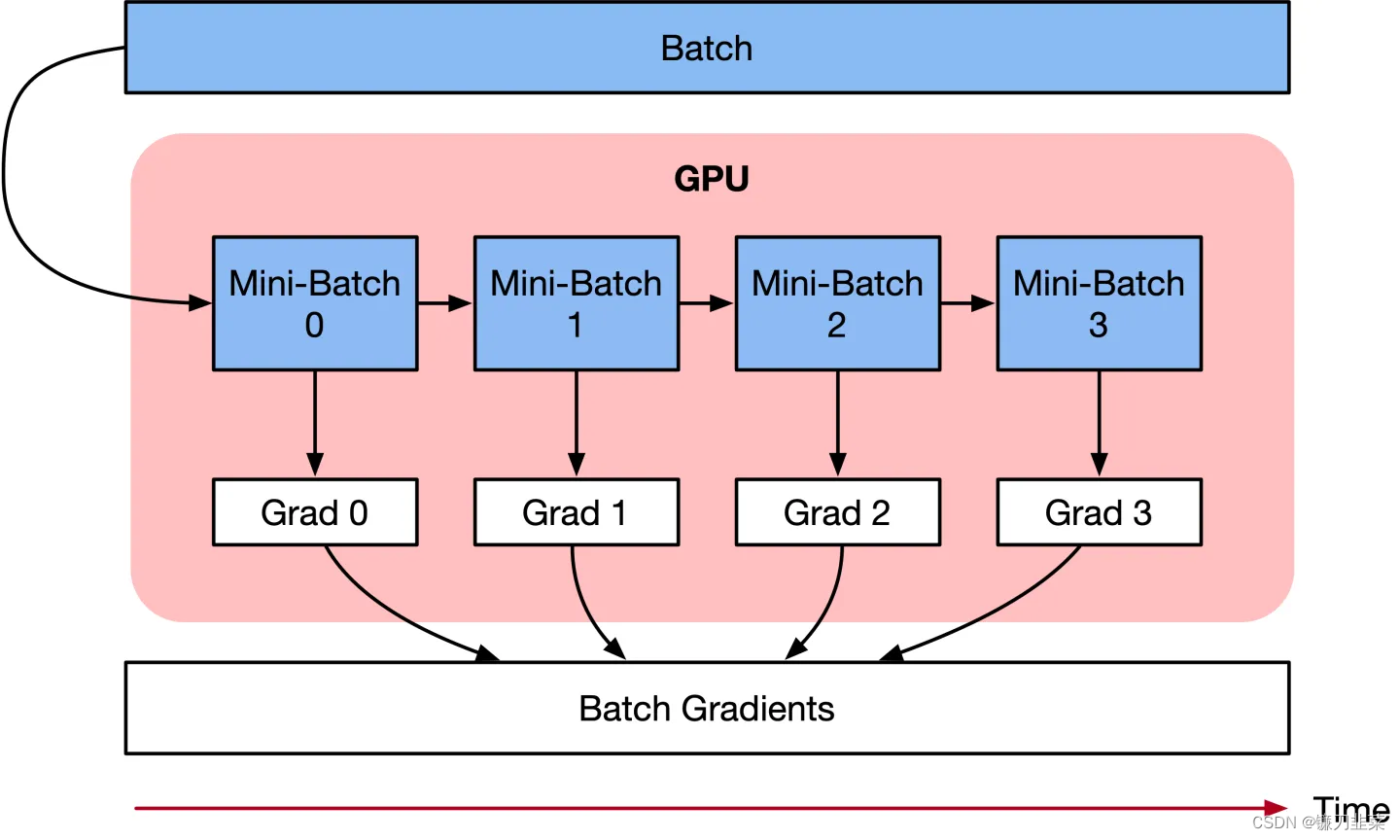
梯度累计的具体做法是:多运行几次loss.backward()再调用optimizer.step()和optimizer.zero_grad()。这样PyTorch就会累积(即求和)梯度并将多批次数据产生的梯度高效地融合在一起,从而生成一个单一的(更好的)梯度估计值用于参数更新。这种做法可以减少参数更新的次数,效果相当于使用更大的batch size进行训练。
那么问题来了,是否可以把梯度累计加到训练循环中呢?如果可以,具体该怎么做?
单卡梯度累积:
- 获取loss: 输入图像和标签,通过计算得到预测值,计算损失函数;
- loss.backward()反向传播,计算当前梯度;
- 多次循环步骤 1-2, 不清空梯度,使梯度累加在已有梯度上;
- 梯度累加一定次数后,先optimizer.step()根据累积的梯度更新网络参数,然后optimizer.zero_grad()清空过往梯度,为下一波梯度累加做准备;
for i, (images, target) in enumerate(train_loader):
# 1. input output
images = images.cuda(non_blocking=True)
target = torch.from_numpy(np.array(target)).float().cuda(non_blocking=True)
outputs = model(images) # 前向传播
loss = criterion(outputs, target) # 计算损失
# 2. backward
loss.backward() # 反向传播,计算当前梯度
# 3. update parameters of net
if ((i+1)%accumulation)==0:
# optimizer the net
optimizer.step() # 更新网络参数
optimizer.zero_grad() # reset grdient # 清空过往梯度
DistributedDataParallel 的梯度累积:
DistributedDataParallel(DDP)在module级别实现数据并行性。其使用torch.distributed包communication collectives来同步梯度,参数和缓冲区。并行性在单个进程内部和跨进程均有用。在这种情况下,虽然gradient accumulation 也一样可以应用,但是为了提高效率,需要做相应的调整。
model = DDP(model)
for data in enumerate(train_loader # 每次梯度累加循环
optimizer.zero_grad()
for _ in range(K-1):# 前K-1个step 不进行梯度同步(累积梯度)。
with model.no_sync(): # 这里实施“不操作”
prediction = model(data / K)
loss = loss_fn(prediction, label) / K
loss.backward() # 积累梯度,不应用梯度改变
prediction = model(data / K)
loss = loss_fn(prediction, label) / K
loss.backward() # 第K个step 进行梯度同步(累积梯度)
optimizer.step() # 应用梯度更新,更新网络参数
从上面的代码输出可知,训练程序每遍历完一次数据集,才输出一行更新信息,这样的频率不足以及时反映训练进展,因此可以采取以下两个步骤:
(1)在训练过程中,时不时地生成一些图片样本,以供检查模型性能
(2)在训练过程中,将损失值、生成的图像样本等信息记录到日志中,可使用Weights and Biases,TensorBoard等功能或工具。
这里可以参考diffusion-models-class/unit2/finetune_model.py
import wandb # 引入Weights and Biases包
import numpy as np
import torch, torchvision
import torch.nn.functional as F
from PIL import Image
from tqdm.auto import tqdm
from fastcore.script import call_parse
from torchvision import transforms
from diffusers import DDPMPipeline
from diffusers import DDIMScheduler
from datasets import load_dataset
from matplotlib import pyplot as plt
@call_parse
def train(
image_size = 256,
batch_size = 16,
grad_accumulation_steps = 2,
num_epochs = 1,
start_model = "google/ddpm-bedroom-256",
dataset_name = "huggan/wikiart",
device = 'cuda',
model_save_name = 'wikiart_1e',
wandb_project = 'dm_finetune',
log_samples_every = 250,
save_model_every = 2500,
):
# 初始化wandb以进行日志记录
wandb.init(project=wandb_project, config=locals())
# 使用DDPMPipeline管线加载预训练过的模型
image_pipe = DDPMPipeline.from_pretrained(start_model);
image_pipe.to(device)
# 创建一个调度器,以执行时间步采样
sampling_scheduler = DDIMScheduler.from_config(start_model)
sampling_scheduler.set_timesteps(num_inference_steps=50)
# 加载数据集
dataset = load_dataset(dataset_name, split="train")
preprocess = transforms.Compose(
[
transforms.Resize((image_size, image_size)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
def transform(examples):
images = [preprocess(image.convert("RGB")) for image in examples["image"]]
return {"images": images}
dataset.set_transform(transform)
train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 梯度优化器 & 学习率调度器
optimizer = torch.optim.AdamW(image_pipe.unet.parameters(), lr=1e-5)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
for epoch in range(num_epochs):
for step, batch in tqdm(enumerate(train_dataloader), total=len(train_dataloader)):
# 得到一张干净的图片
clean_images = batch['images'].to(device)
# 随机采样噪声并将其加入到干净的图片中
noise = torch.randn(clean_images.shape).to(clean_images.device)
bs = clean_images.shape[0]
# 为每个图像采样一个随机的时间步长
timesteps = torch.randint(0, image_pipe.scheduler.num_train_timesteps, (bs,), device=clean_images.device).long()
# 根据每个时间步长的噪声大小,将噪声添加到干净的图像中
# (这是正向扩散过程)
noisy_images = image_pipe.scheduler.add_noise(clean_images, noise, timesteps)
# 获取噪声的模型预测
noise_pred = image_pipe.unet(noisy_images, timesteps, return_dict=False)[0]
# 将预测结果与实际噪声进行比较:
loss = F.mse_loss(noise_pred, noise)
# 记录损失
wandb.log({'loss':loss.item()})
# 计算梯度
loss.backward()
# 梯度累积:仅更新每个grad_accumulation_steps
if (step+1)%grad_accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
# 偶尔记录样本
if (step+1)%log_samples_every == 0:
x = torch.randn(8, 3, 256, 256).to(device) # Batch of 8
for i, t in tqdm(enumerate(sampling_scheduler.timesteps)):
model_input = sampling_scheduler.scale_model_input(x, t)
with torch.no_grad():
noise_pred = image_pipe.unet(model_input, t)["sample"]
x = sampling_scheduler.step(noise_pred, t, x).prev_sample
grid = torchvision.utils.make_grid(x, nrow=4)
im = grid.permute(1, 2, 0).cpu().clip(-1, 1)*0.5 + 0.5
im = Image.fromarray(np.array(im*255).astype(np.uint8))
wandb.log({'Sample generations': wandb.Image(im)})
# 偶尔保存模型
if (step+1)%save_model_every == 0:
image_pipe.save_pretrained(model_save_name+f'step_{step+1}')
# 更新下一个epoch的学习率
scheduler.step()
# 最后一次保存pipeline
image_pipe.save_pretrained(model_save_name)
# 结束运行
wandb.finish()
执行finetune_model.py文件:
# 运行脚本,在Vintage Face数据集上训练脚本
!python finetune_model.py \
--image_size 256 --batch_size 2 --num_epochs 8 \
--grad_accumulation_steps 2 --start_model "google/ddpm-celebahq-256" \
--dataset_name "Norod78/Vintage-Faces-FFHQAligned" \
--wandb_project $WANDB_PROJECT \
--log_samples_every 100 --save_model_every 1000 \
--model_save_name 'vintageface'
保存训练之后的模型:

接下来使用模型生成一些图像样本:
x = torch.randn(8, 3, 256, 256).to(device)
for i, t in tqdm(enumerate(scheduler.timesteps)):
model_input = scheduler.scale_model_input(x, t)
with torch.no_grad():
noise_pred = image_pipe.unet(model_input, t)["sample"]
x = scheduler.step(noise_pred, t, x).prev_sample
grid = torchvision.utils.make_grid(x, nrow=4)
plt.imshow(grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5);

将模型上传到Hugging Face Hub:
# 将模型上传到Hugging Face
from huggingface_hub import HfApi, ModelCard, create_repo, get_full_repo_name
# 配置Hugging Face Hub,上传文件
model_name = "ddpm-celebahq-finetuned-butterflies-2epochs"
local_folder_name = "my-finetuned-model"
description = "Describe your model here"
hub_model_id = get_full_repo_name(model_name)
create_repo(hub_model_id)
api = HfApi()
api.upload_folder(
folder_path=f"{local_folder_name}/scheduler", path_in_repo="", repo_id=hub_model_id
)
api.upload_folder(
folder_path=f"{local_folder_name}/unet", path_in_repo="", repo_id=hub_model_id
)
api.upload_file(
path_or_fileobj=f"{local_folder_name}/model_index.json",
path_in_repo="model_index.json",
repo_id=hub_model_id,
)
# 添加一个模型卡片
content = f"""
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Example Fine-Tuned Model for Unit 2 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
{description}
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('{hub_model_id}')
image = pipeline().images[0]
image
``\`
"""
card = ModelCard(content)
card.push_to_hub(hub_model_id)
5. 引导
为了方便,我们使用LSUM bedrooms数据集上训练并在WikiArt数据集上进行一轮微调的新模型。

使用DDIM调度器,仅用40步生成一些图片:
scheduler = DDIMScheduler.from_pretrained(pipeline_name)
scheduler.set_timesteps(num_inference_steps=40)
将随机噪声作为出发点:
x = torch.randn(8, 3, 256, 256).to(device)
使用一个最简单的采样循环
for i, t in tqdm(enumerate(scheduler.timesteps)):
model_input = scheduler.scale_model_input(x, t)
with torch.no_grad():
noise_pred = image_pipe.unet(model_input, t)["sample"]
x = scheduler.step(noise_pred, t, x).prev_sample
查看生成结果:
grid = torchvision.utils.make_grid(x, nrow=4)
plt.imshow(grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5);

问题:==如果想要对生成的样本施加控制,要怎么做呢?==比如:让生成的图片偏向某种颜色。
答:可以利用引导(guidance),在采样过程中额外施加的控制。
首先创建一个函数,用于定义希望优化的指标(损失值):
def color_loss(images, target_color=(0.1, 0.9, 0.5)):
"""给定一个RGB值,返回一个损失值,用于衡量图片的像素值与目标颜色相差多少
这里的目标颜色是一种浅蓝绿色,对应的RGB值为(0.1, 0.9, 0.5)"""
target = (torch.tensor(target_color).to(images.device)*2-1) # 首先对target_color进行归一化,使它的取值区间为(-1,1)
target = target[None,:,None, None] # 将所生成目标张量的形状改为(b.c.h.w),以适配输入图像images的张量形状
error = torch.abs(images - target).mean() # 计算图片的像素值以及目标颜色的均方误差
return error
然后,修改采样循环并执行以下过程:
(1)创建新的输入图像x,将它的requires_grad属性设置为true
(2)计算去噪后的图像
x
0
x_0
x0
(3)将去噪后的图像
x
0
x_0
x0传递给损失函数。
(4)计算损失函数对输入图像x的梯度
(5)在使用调度器之前,先用计算出来的梯度修改输入图像x,使输入图像x朝着减少损失值的方向改进。
实现的方法有两种:
①从UNet中获取噪声预测,并将其设置为输入图像
x
x
x的requires_grad属性,这样就可以更高效地使用内存了(因为不需要通过扩散模型追踪梯度),但是这样会导致梯度的精度降低。
②先将输入图像
x
x
x的requires_grad属性设置为True,然后传递给UNet并计算去噪后的图像
x
0
x_0
x0
第一种方法:
# guidance_loss_scale用于决定引导的强度有多大
guidance_loss_scale = 40 # 可设置为5~100的任意数字
x = torch.randn(8, 3, 256, 256).to(device)
for i, t in tqdm(enumerate(scheduler.timesteps)):
# 准备模型输入
model_input = scheduler.scale_model_input(x, t)
# 预测噪声
with torch.no_grad():
noise_pred = image_pipe.unet(model_input, t)["sample"]
# 设置x.requires_grad为True
x = x.detach().requires_grad_()
# 得到去噪后的图像
x0 = scheduler.step(noise_pred, t, x).pred_original_sample
# 计算损失值
loss = color_loss(x0)*guidance_loss_scale
if i%10==0:
print(i, "loss:", loss.item())
# 获取梯度
cond_grad = -torch.autograd.grad(loss, x)[0]
# 使用梯度更新x
x = x.detach() + cond_grad
# 使用调度器更新x
x = scheduler.step(noise_pred, t, x).prev_sample
查看结果:
grid = torchvision.utils.make_grid(x, nrow=4)
im = grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5
Image.fromarray(np.array(im * 255).astype(np.uint8))

第一种方法:
guidance_loss_scale=40
x = torch.randn(4, 3, 256, 256).to(device)
for i, t in tqdm(enumerate(scheduler.timesteps)):
# 设置requires_grad
x = x.detach().requires_grad_()
model_input = scheduler.scale_model_input(x, t)
# 预测
noise_pred = image_pipe.unet(model_input, t)['sample']
# 得到去噪后的图像
x0 = scheduler.step(noise_pred, t, x).pred_original_sample
loss = color_loss(x0) * guidance_loss_scale
if i%10 == 0:
print(i, "loss:", loss.item())
# 获取梯度
cond_grad = -torch.autograd.grad(loss, x)[0]
# 更新x
x = x.detach() + cond_grad
# 使用调度器更新x
x = scheduler.step(noise_pred, t, x).prev_sample
grid = torchvision.utils.make_grid(x, nrow=4)
im = grid.permute(1, 2, 0).cpu().clip(-1, 1)*0.5 + 0.5
Image.fromarray(np.array(im*255).astype(np.uint8))

第二种方法对GPU的显存更好了,但颜色迁移的效果减弱了,可以通过增大guidance_loss_scale来增强颜色迁移的效果。
6. CLIP引导
CLIP是一个由OpenAI开发的模型,它使得能够对图片和文字说明进行比较。它能让我们量化一张图和一句提示语的匹配程度。另外,这个过程是可微分的,可以将其作为损失函数来引导扩散模型。
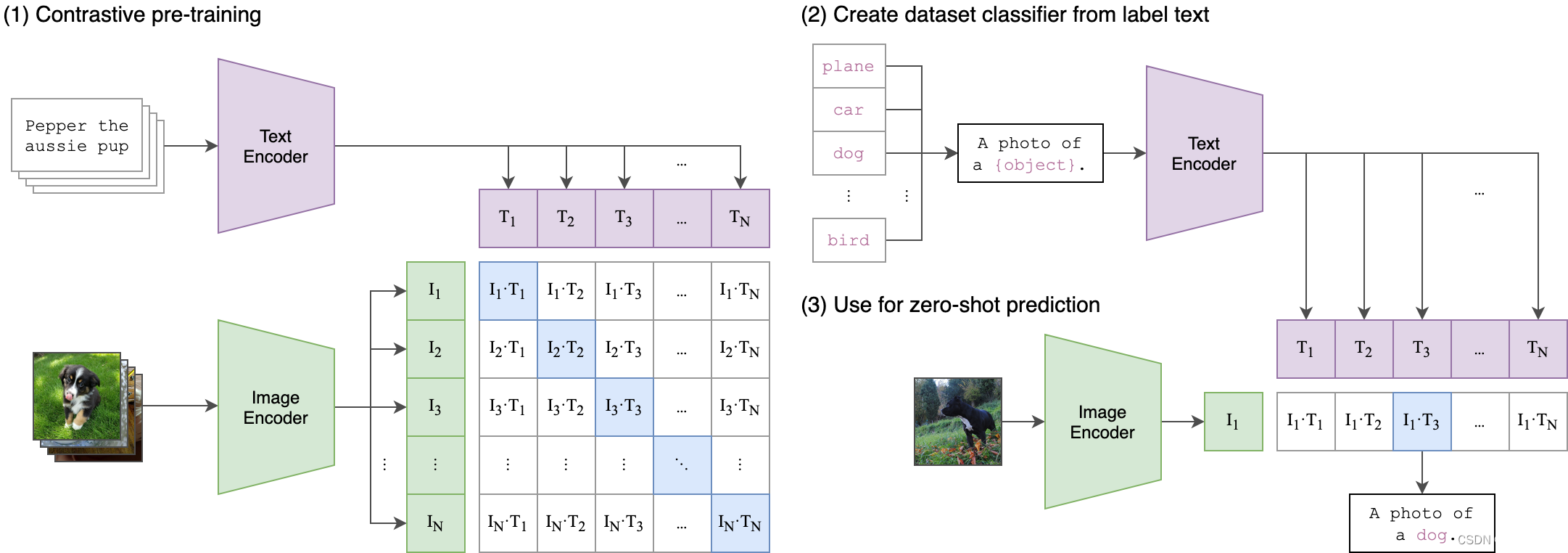
CLIP(对比语言图像预训练)是一种在各种(图像、文本)对上训练的神经网络。它可以用自然语言指示在给定图像的情况下预测最相关的文本片段,而无需直接优化任务,类似于GPT-2和3的零样本功能。我们发现CLIP与ImageNet“零样本”上的原始ResNet50的性能相匹配,而不使用任何原始1.28M标记的示例,克服了计算机视觉中的几个主要挑战。
基本流程:
- 对文本提示语进行
embedding,为 CLIP 获取一个512维的embedding。 - 在扩散模型的生成过程中的每一步进行如下操作:
- 制作多个不同版本的预测出来的“去噪”图片。
- 对预测出来的每一张“去噪”图片,用CLIP给图片做embedding,并对图片和文字的embedding做对比。
- 计算损失对于当前“带噪”的输入 x x x的梯度,在使用调度器更新 x x x之前先用这个梯度修改它。
示例:载入一个CLIP模型
import open_clip
clip_model, _, preprocess = open_clip.create_model_and_transforms("ViT-B-32", pretrained="openai")
clip_model.to(device)
# 图像变换:用于修改图像尺寸和增广数据,同时归一化数据,以使数据能够适配CLIP模型
tfms = torchvision.transforms.Compose(
[
torchvision.transforms.RandomResizedCrop(224), # 随机裁剪
torchvision.transforms.RandomAffine(5), # 随机扭曲图片
torchvision.transforms.RandomHorizontalFlip(), # 随机左右镜像
torchvision.transforms.Normalize(
mean=(0.48145466, 0.4578275, 0.40821073),
std=(0.26862954, 0.26130258, 0.27577711),
),
]
)
# 定义一个损失函数,用于获取图片的特征,然后与提示文字的特征进行对比
def clip_loss(image, text_features):
image_features = clip_model.encode_image(tfms(image)) # 注意施加上面定义好的变换
input_normed = torch.nn.functional.normalize(image_features.unsqueeze(1), dim=2)
embed_normed = torch.nn.functional.normalize(text_features.unsqueeze(0), dim=2)
# 使用Squared Great Circle Distance计算距离
dists = (input_normed.sub(embed_normed).norm(dim=2).div(2).arcsin().pow(2).mul(2))
return dists.mean()
CLIP引导代码:
prompt = "Red Rose (still life), red flower painting"
guidance_scale = 8
n_cuts = 4
scheduler.set_timesteps(50)
# 使用CLIP从提示文字中提取特征
text = open_clip.tokenize([prompt]).to(device)
with torch.no_grad(), torch.cuda.amp.autocast():
text_features = clip_model.encode_text(text)
x = torch.randn(4, 3, 256, 256).to(device)
for i, t in tqdm(enumerate(scheduler.timesteps)):
model_input = scheduler.scale_model_input(x, t)
# 预测噪声
with torch.no_grad():
noise_pred = image_pipe.unet(model_input, t)["sample"]
cond_grad = 0
for cut in range(n_cuts):
# 设置输入图像的requires_grad属性为True
x = x.detach().requires_grad_()
# 获取“去噪”后的图像
x0 = scheduler.step(noise_pred, t, x).pred_original_sample
# 计算损失值
loss = clip_loss(x0, text_features) * guidance_scale
# 获取梯度并使用n_cuts平均
cond_grad -= torch.autograd.grad(loss, x)[0] / n_cuts
if i % 25 == 0:
print("Step:", i, ", Guidance loss:", loss.item())
# 根据这个梯度更新x
alpha_bar = scheduler.alphas_cumprod[i]
x = x.detach() + cond_grad * alpha_bar.sqrt() # 注意这里的缩放因子
# 使用调度器更新x
x = scheduler.step(noise_pred, t, x).prev_sample
grid = torchvision.utils.make_grid(x.detach(), nrow=4)
im = grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5
Image.fromarray(np.array(im * 255).astype(np.uint8))
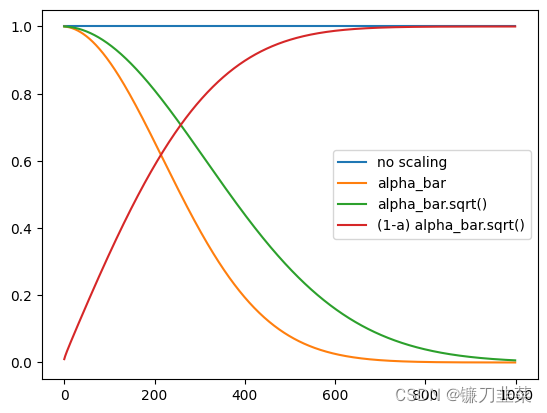
代码中使用alpha_bar.sqrt()作为因子来缩放梯度。CLIP引导的初步效果:
Step: 0 , Guidance loss: 7.406642913818359
Step: 25 , Guidance loss: 7.050115585327148

不同梯度缩放带来的影响:
plt.plot([1 for a in scheduler.alphas_cumprod], label="no scaling")
plt.plot([a for a in scheduler.alphas_cumprod], label="alpha_bar")
plt.plot([a.sqrt() for a in scheduler.alphas_cumprod], label="alpha_bar.sqrt()")
plt.plot([(1-a).sqrt() for a in scheduler.alphas_cumprod], label="(1-a) alpha_bar.sqrt()")
plt.legend()
使用更优的随机图像裁剪选取规则以及更多样的损失函数变体等,来获得更好的性能。
核心要点是:借助引导和CLIP惊人的能力,可以给一个没有条件约束的扩散模型施加文本级的控制。
参考资料
- Weights & Biases
- Gradient Accumulation in PyTorch
- Denoising Diffusion Implicit Models
- Denoising Diffusion Implicit Models (DDIM) Sampling
- 聊聊梯度累加(Gradient Accumulation)
- 梯度累积原理与实现
- CLIP github