前言
整体的思路:首先息肉数据集分为三类:
1.正常细胞
2. 增生性息肉
3. 肿瘤
要想完成这个任务,首先重中之重是分割任务,分割结果的好坏, 当分割结果达到一定的准确度后,开始对分割后的结果进行下游分类任务处理。最后在进行两个网络的分类结果的综合处理,从而达到想要的目的和结果。
分割网络的实现
分割网络我们常见的是UNet、Unet++、以及各种Unet的魔改版,这是因为Unet强大的泛化性,以及它能在分割的大部分领域表现出良好的性能所决定的,本次项目的实现并未选择Unet进行实现,而是选择了ESFPNet进行任务分割。这里是关于这个网络的代码,有兴趣的同学可以搜索查看 。
关于ESFP网络结构的介绍
from Encoder import mit
from Decoder import mlp
from mmcv.cnn import ConvModule
class ESFPNetStructure(nn.Module):
def __init__(self, embedding_dim = 160):
super(ESFPNetStructure, self).__init__()
# Backbone
if model_type == 'B0':
self.backbone = mit.mit_b0()
if model_type == 'B1':
self.backbone = mit.mit_b1()
if model_type == 'B2':
self.backbone = mit.mit_b2()
if model_type == 'B3':
self.backbone = mit.mit_b3()
if model_type == 'B4':
self.backbone = mit.mit_b4()
if model_type == 'B5':
self.backbone = mit.mit_b5()
self._init_weights() # load pretrain
# LP Header
self.LP_1 = mlp.LP(input_dim = self.backbone.embed_dims[0], embed_dim = self.backbone.embed_dims[0])
self.LP_2 = mlp.LP(input_dim = self.backbone.embed_dims[1], embed_dim = self.backbone.embed_dims[1])
self.LP_3 = mlp.LP(input_dim = self.backbone.embed_dims[2], embed_dim = self.backbone.embed_dims[2])
self.LP_4 = mlp.LP(input_dim = self.backbone.embed_dims[3], embed_dim = self.backbone.embed_dims[3])
# Linear Fuse
self.linear_fuse34 = ConvModule(in_channels=(self.backbone.embed_dims[2] + self.backbone.embed_dims[3]), out_channels=self.backbone.embed_dims[2], kernel_size=1,norm_cfg=dict(type='BN', requires_grad=True))
self.linear_fuse23 = ConvModule(in_channels=(self.backbone.embed_dims[1] + self.backbone.embed_dims[2]), out_channels=self.backbone.embed_dims[1], kernel_size=1,norm_cfg=dict(type='BN', requires_grad=True))
self.linear_fuse12 = ConvModule(in_channels=(self.backbone.embed_dims[0] + self.backbone.embed_dims[1]), out_channels=self.backbone.embed_dims[0], kernel_size=1,norm_cfg=dict(type='BN', requires_grad=True))
# Fused LP Header
self.LP_12 = mlp.LP(input_dim = self.backbone.embed_dims[0], embed_dim = self.backbone.embed_dims[0])
self.LP_23 = mlp.LP(input_dim = self.backbone.embed_dims[1], embed_dim = self.backbone.embed_dims[1])
self.LP_34 = mlp.LP(input_dim = self.backbone.embed_dims[2], embed_dim = self.backbone.embed_dims[2])
# Final Linear Prediction
self.linear_pred = nn.Conv2d((self.backbone.embed_dims[0] + self.backbone.embed_dims[1] + self.backbone.embed_dims[2] + self.backbone.embed_dims[3]), 1, kernel_size=1)
def _init_weights(self):
if model_type == 'B0':
pretrained_dict = torch.load('./Pretrained/mit_b0.pth')
if model_type == 'B1':
pretrained_dict = torch.load('./Pretrained/mit_b1.pth')
if model_type == 'B2':
pretrained_dict = torch.load('./Pretrained/mit_b2.pth')
if model_type == 'B3':
pretrained_dict = torch.load('./Pretrained/mit_b3.pth')
if model_type == 'B4':
pretrained_dict = torch.load('./Pretrained/mit_b4.pth')
if model_type == 'B5':
pretrained_dict = torch.load('./Pretrained/mit_b5.pth')
model_dict = self.backbone.state_dict()
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
model_dict.update(pretrained_dict)
self.backbone.load_state_dict(model_dict)
print("successfully loaded!!!!")
def forward(self, x):
# 这段代码是一个模型的前向传递过程。该模型首先通过backbone网络,
# 对输入的x进行特征提取,得到4个不同分辨率的特征图。
# 然后将这些特征图送入LP Header网络进行处理,融合不同层次的特征。
# 接着通过上采样(interpolation)将处理后的特征图进行恢复到原始输入图像尺寸大小,
# 并最终送入线性预测器(linear_pred)获得输出结果。
################## Go through backbone ###################
B = x.shape[0]
#stage 1
out_1, H, W = self.backbone.patch_embed1(x)
for i, blk in enumerate(self.backbone.block1):
out_1 = blk(out_1, H, W)
out_1 = self.backbone.norm1(out_1)
#将输入特征图out_1从形状(Batch_Size, N, W, H)变形为(Batch_Size, H, W, N)
#其中-1表示自动计算N的值。接着使用permute函数将特征维度N和高宽维度H、W交换位置
#变成(Batch_Size, N, H, W)的形状
out_1 = out_1.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() #(Batch_Size, self.backbone.embed_dims[0], 88, 88)
# stage 2
out_2, H, W = self.backbone.patch_embed2(out_1)
for i, blk in enumerate(self.backbone.block2):
out_2 = blk(out_2, H, W)
out_2 = self.backbone.norm2(out_2)
out_2 = out_2.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() #(Batch_Size, self.backbone.embed_dims[1], 44, 44)
# stage 3
out_3, H, W = self.backbone.patch_embed3(out_2)
for i, blk in enumerate(self.backbone.block3):
out_3 = blk(out_3, H, W)
out_3 = self.backbone.norm3(out_3)
out_3 = out_3.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() #(Batch_Size, self.backbone.embed_dims[2], 22, 22)
# stage 4
out_4, H, W = self.backbone.patch_embed4(out_3)
for i, blk in enumerate(self.backbone.block4):
out_4 = blk(out_4, H, W)
out_4 = self.backbone.norm4(out_4)
out_4 = out_4.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() #(Batch_Size, self.backbone.embed_dims[3], 11, 11)
# go through LP Header
lp_1 = self.LP_1(out_1)
lp_2 = self.LP_2(out_2)
lp_3 = self.LP_3(out_3)
lp_4 = self.LP_4(out_4)
# linear fuse and go pass LP Header 上采样并拼接
lp_34 = self.LP_34(self.linear_fuse34(torch.cat([lp_3, F.interpolate(lp_4,scale_factor=2,mode='bilinear', align_corners=False)], dim=1)))
lp_23 = self.LP_23(self.linear_fuse23(torch.cat([lp_2, F.interpolate(lp_34,scale_factor=2,mode='bilinear', align_corners=False)], dim=1)))
lp_12 = self.LP_12(self.linear_fuse12(torch.cat([lp_1, F.interpolate(lp_23,scale_factor=2,mode='bilinear', align_corners=False)], dim=1)))
# get the final output
lp4_resized = F.interpolate(lp_4,scale_factor=8,mode='bilinear', align_corners=False)
lp3_resized = F.interpolate(lp_34,scale_factor=4,mode='bilinear', align_corners=False)
lp2_resized = F.interpolate(lp_23,scale_factor=2,mode='bilinear', align_corners=False)
lp1_resized = lp_12
out = self.linear_pred(torch.cat([lp1_resized, lp2_resized, lp3_resized, lp4_resized], dim=1))
out_resized = F.interpolate(out,scale_factor=4,mode='bilinear', align_corners=True)
return out_resized
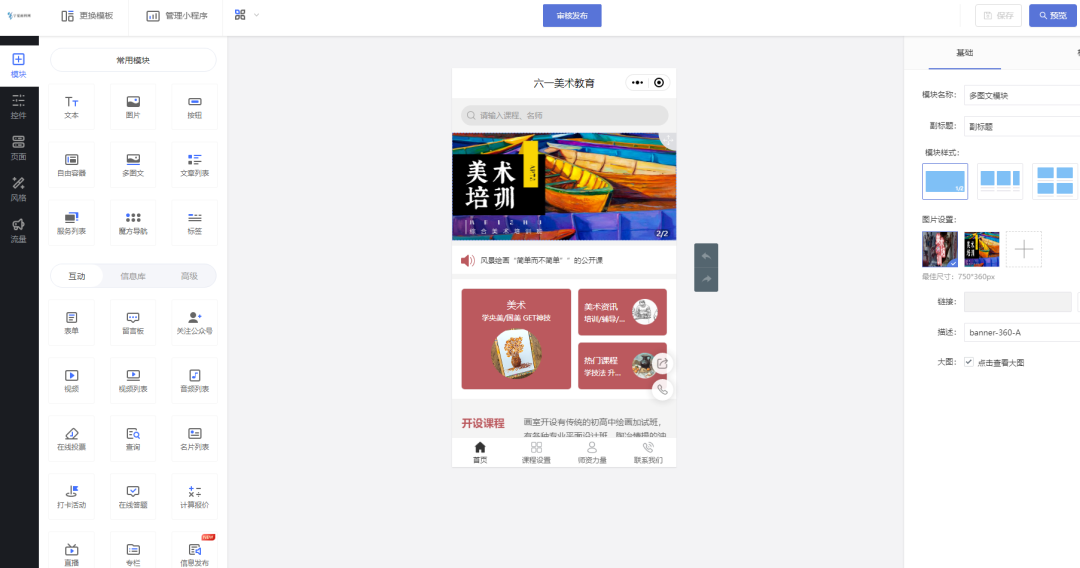
上述图片和代码是关于ESFP核心网络的编写,下面就来详细介绍一下这个网络。
backbone(部分引用于原论文)
- 使用model_type来加载预训练模型,这里有5个参数可选。通过指定的预训练权重来初始化backbone网络。
- Mix Transformer编码器(MiT)是一个模块,它利用了ViT网络的思想,并在四个阶段中使用四个重叠的路径合并模块和自注意力预测。
- transformer使用的自注意力层缺乏局部归纳偏差(图像像素是局部相关的,其相关图是平移不变的概念),会导致数据饥饿问题。
- 为了缓解受小数据集限制的应用面临的数据饥饿挑战,可以利用广泛使用的迁移学习的概念。MiT的编码器利用了这个想法,在大型ImageNet数据库上进行了预训练对于我们的ESPFNet架构,将这些预训练的MiT编码器集成为骨干,并用初始化的解码器再次训练它们。
- 这是一种直接的方法,可以在小型特定任务数据集表现良好性能,同时也能够超过最先进的CNN模型的性能。
Efficient stage-wise feature pyramid(ESFP)
- 高层(全局)特征比低层(局部)特征对整体分割性能的贡献更大。ESFP首先对每个阶段的输出进行线性预测(有效的是连接通道的数量),然后将这些预处理的特征从全局到局部线性融合。这些中间聚合特征被连接起来,并相互协作产生最终的分割。
- 在训练之前,将输入调整为352 × 352像素,并将其归一化以进行分割。我们还使用随机翻转、旋转和亮度变化作为输入的数据增强操作。损失函数结合了加权交联(IoU)损失和加权二元交叉熵(BCE)损失:
实现细节
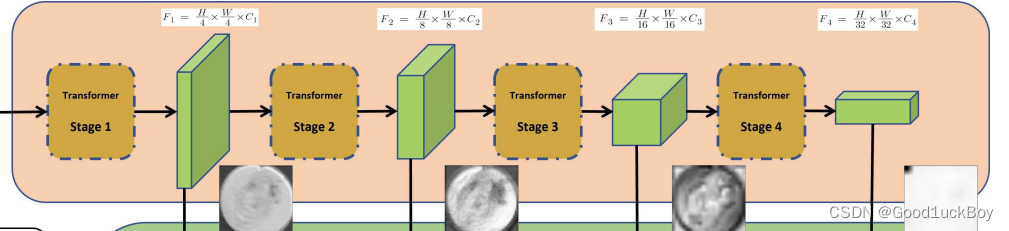
这一部分是关于MIt 编码器对图像进行编码的操作。
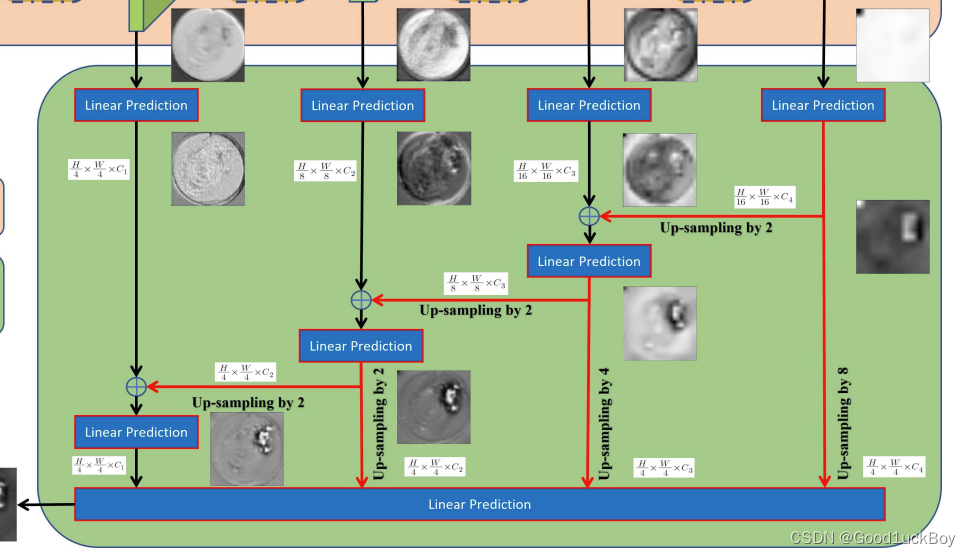
这一部分则是ESFP对网络进行解码的过程。
LP Header
# LP Header
self.LP_1 = mlp.LP(input_dim = self.backbone.embed_dims[0], embed_dim = self.backbone.embed_dims[0])
self.LP_2 = mlp.LP(input_dim = self.backbone.embed_dims[1], embed_dim = self.backbone.embed_dims[1])
self.LP_3 = mlp.LP(input_dim = self.backbone.embed_dims[2], embed_dim = self.backbone.embed_dims[2])
self.LP_4 = mlp.LP(input_dim = self.backbone.embed_dims[3], embed_dim = self.backbone.embed_dims[3])
- self.backbone.embed_dims[0] [1] [2] [3]、 获取到相应分辨率的特征图通道数,在这里输入和输出通道是相同的维度数。
- LP Header用于对不同分辨率的特征图进行进一步的处理和提取,以获得更加有用的信息,为后续的特征融合和预测操作做准备。
Linear Fuse(线性融合)
# Linear Fuse
self.linear_fuse34 = ConvModule(in_channels=(self.backbone.embed_dims[2] + self.backbone.embed_dims[3]), out_channels=self.backbone.embed_dims[2], kernel_size=1,norm_cfg=dict(type='BN', requires_grad=True))
self.linear_fuse23 = ConvModule(in_channels=(self.backbone.embed_dims[1] + self.backbone.embed_dims[2]), out_channels=self.backbone.embed_dims[1], kernel_size=1,norm_cfg=dict(type='BN', requires_grad=True))
self.linear_fuse12 = ConvModule(in_channels=(self.backbone.embed_dims[0] + self.backbone.embed_dims[1]), out_channels=self.backbone.embed_dims[0], kernel_size=1,norm_cfg=dict(type='BN', requires_grad=True))
- 通过上述的网络结构图可以看出,我们需要3个线性融合层。
- 通过ConvModule来定义Linear Fuse层,其中in_channels表示Linear Fuse的输入通道数,由两个特征图的通道数相加得到。out_channels表示Linear Fuse的输出通道数,与对应层次的特征图通道数相同。
- 通过这些Linear Fuse层的操作,可以将不同分辨率的特征图进行融合,从而提高特征的表达能力和多尺度信息的利用效果
Fused LP Header(融合的LP Header)
# Fused LP Header
self.LP_12 = mlp.LP(input_dim = self.backbone.embed_dims[0], embed_dim = self.backbone.embed_dims[0])
self.LP_23 = mlp.LP(input_dim = self.backbone.embed_dims[1], embed_dim = self.backbone.embed_dims[1])
self.LP_34 = mlp.LP(input_dim = self.backbone.embed_dims[2], embed_dim = self.backbone.embed_dims[2])
- 将融合后的特征图的通道数变换为与backbone的对应层次的特征图通道数相同的维度。
- 用于对线性融合后的特征图进行进一步的特征提取和转换,以获得更加有用的信息,并为最终的预测操作做准备
Final Linear Prediction(最终线性预测)
# Final Linear Prediction
self.linear_pred = nn.Conv2d((self.backbone.embed_dims[0] + self.backbone.embed_dims[1] + self.backbone.embed_dims[2] + self.backbone.embed_dims[3]), 1, kernel_size=1)
- n.Conv2d用于定义一个二维卷积层,其中的输入通道数为融合后的特征图的通道数总和。
- 输入通道是各个分辨率维度的总和,输出通道为1,表示进行目标检测的预测结果。
- 这个最终的线性预测层将融合后的特征图映射到一维的通道上,以输出目标检测的预测结果。这样,通过特征融合与转换后的特征图,可以进行最终的目标检测操作并得到预测结果。
前向传播
B = x.shape[0]
#stage 1
out_1, H, W = self.backbone.patch_embed1(x)
for i, blk in enumerate(self.backbone.block1):
out_1 = blk(out_1, H, W)
out_1 = self.backbone.norm1(out_1)
#将输入特征图out_1从形状(Batch_Size, N, W, H)变形为(Batch_Size, H, W, N)
#其中-1表示自动计算N的值。接着使用permute函数将特征维度N和高宽维度H、W交换位置
#变成(Batch_Size, N, H, W)的形状
out_1 = out_1.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() #(Batch_Size, self.backbone.embed_dims[0], 88, 88)
# stage 2
out_2, H, W = self.backbone.patch_embed2(out_1)
for i, blk in enumerate(self.backbone.block2):
out_2 = blk(out_2, H, W)
out_2 = self.backbone.norm2(out_2)
out_2 = out_2.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() #(Batch_Size, self.backbone.embed_dims[1], 44, 44)
# stage 3
out_3, H, W = self.backbone.patch_embed3(out_2)
for i, blk in enumerate(self.backbone.block3):
out_3 = blk(out_3, H, W)
out_3 = self.backbone.norm3(out_3)
out_3 = out_3.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() #(Batch_Size, self.backbone.embed_dims[2], 22, 22)
# stage 4
out_4, H, W = self.backbone.patch_embed4(out_3)
for i, blk in enumerate(self.backbone.block4):
out_4 = blk(out_4, H, W)
out_4 = self.backbone.norm4(out_4)
out_4 = out_4.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() #(Batch_Size, self.backbone.embed_dims[3], 11, 11)
# go through LP Header
lp_1 = self.LP_1(out_1)
lp_2 = self.LP_2(out_2)
lp_3 = self.LP_3(out_3)
lp_4 = self.LP_4(out_4)
# linear fuse and go pass LP Header 上采样并拼接
lp_34 = self.LP_34(self.linear_fuse34(torch.cat([lp_3, F.interpolate(lp_4,scale_factor=2,mode='bilinear', align_corners=False)], dim=1)))
lp_23 = self.LP_23(self.linear_fuse23(torch.cat([lp_2, F.interpolate(lp_34,scale_factor=2,mode='bilinear', align_corners=False)], dim=1)))
lp_12 = self.LP_12(self.linear_fuse12(torch.cat([lp_1, F.interpolate(lp_23,scale_factor=2,mode='bilinear', align_corners=False)], dim=1)))
# get the final output
lp4_resized = F.interpolate(lp_4,scale_factor=8,mode='bilinear', align_corners=False)
lp3_resized = F.interpolate(lp_34,scale_factor=4,mode='bilinear', align_corners=False)
lp2_resized = F.interpolate(lp_23,scale_factor=2,mode='bilinear', align_corners=False)
lp1_resized = lp_12
out = self.linear_pred(torch.cat([lp1_resized, lp2_resized, lp3_resized, lp4_resized], dim=1))
out_resized = F.interpolate(out,scale_factor=4,mode='bilinear', align_corners=True)
前向传播的过程,就是将结果中的完整过程串联起来,进行完整的预测。输入x的形状为(Batch_Size, C, H, W),其中B表示批量大小,C表示通道数,H和W分别表示输入特征图的高度和宽度
阶段1
out_1, H, W = self.backbone.patch_embed1(x)
for i, blk in enumerate(self.backbone.block1):
out_1 = blk(out_1, H, W)
out_1 = self.backbone.norm1(out_1)
out_1 = out_1.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
- 通过self.backbone.patch_embed1对输入特征图进行分块嵌入操作,得到输出特征图out_1和新的高度H和宽度W
- 进行self.backbone.block1中的一系列残差块操作,对输出特征图out_1进行特征提取。
- 对out_1进行归一化处理,得到归一化后的特征图out_1。
- 将输入特征图out_1从形状(Batch_Size,H,W)变形为(Batch_Size,N, H, W),通过reshape进行N维度的计算,-1表示自动计算N的值。接着使用permute函数将特征维度N和高宽维度H、W交换位置,变成(Batch_Size, N, H, W)的形状
阶段2、3、4
与上述阶段一的操作大致相同,也就是图中最上面一层,backbone网络的操作。
LP Header
# go through LP Header
lp_1 = self.LP_1(out_1)
lp_2 = self.LP_2(out_2)
lp_3 = self.LP_3(out_3)
lp_4 = self.LP_4(out_4)
将out_1、out_2、out_3、out_4分别输入到对应的LP模块中(LP_1、LP_2、LP_3、LP_4),得到相应的低层级特征表示lp_1、lp_2、lp_3、lp_4。
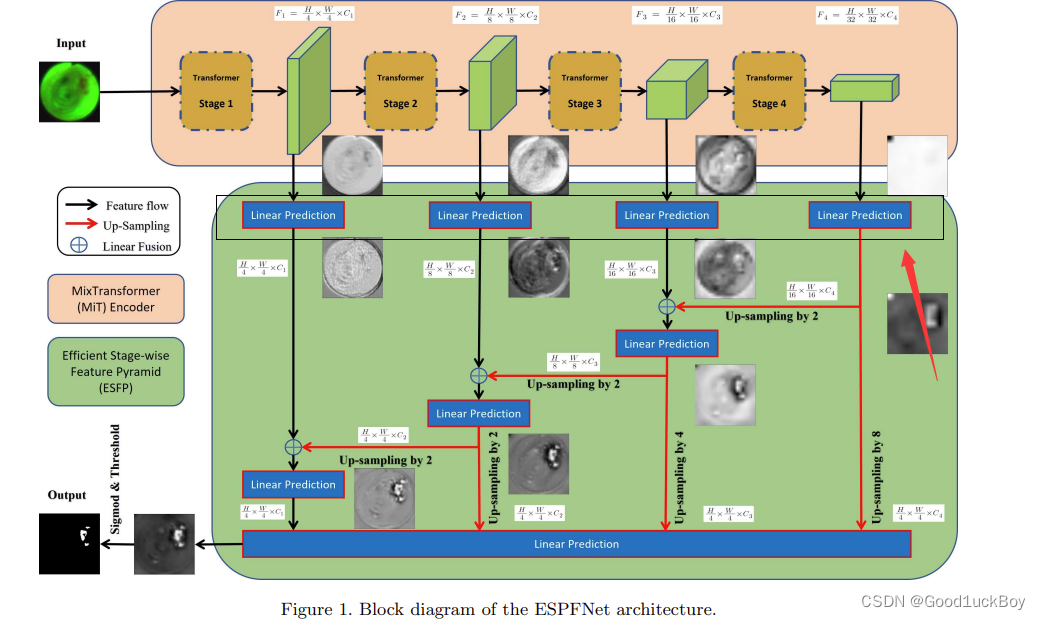
也就是黑色框中所做的事情。
线性融合与上采样:
# linear fuse and go pass LP Header 上采样并拼接
lp_34 = self.LP_34(self.linear_fuse34(torch.cat([lp_3, F.interpolate(lp_4,scale_factor=2,mode='bilinear', align_corners=False)], dim=1)))
lp_23 = self.LP_23(self.linear_fuse23(torch.cat([lp_2, F.interpolate(lp_34,scale_factor=2,mode='bilinear', align_corners=False)], dim=1)))
lp_12 = self.LP_12(self.linear_fuse12(torch.cat([lp_1, F.interpolate(lp_23,scale_factor=2,mode='bilinear', align_corners=False)], dim=1)))
- 使用torch.cat函数将lp_3与经过上采样后的lp_4拼接起来,然后通过self.linear_fuse34和LP_34模块进行线性融合,得到lp_34。
- 类似地,通过拼接和线性融合操作得到lp_23和lp_12。
最终上采样
# get the final output
lp4_resized = F.interpolate(lp_4,scale_factor=8,mode='bilinear', align_corners=False)
lp3_resized = F.interpolate(lp_34,scale_factor=4,mode='bilinear', align_corners=False)
lp2_resized = F.interpolate(lp_23,scale_factor=2,mode='bilinear', align_corners=False)
lp1_resized = lp_12
- 对lp_4进行上采样操作,得到lp4_resized,上采样因子为8;
- 对lp_34进行上采样操作,得到lp3_resized,上采样因子为4;
- 对lp_23进行上采样操作,得到lp2_resized,上采样因子为2;
- lp_12不进行上采样。
最终输出
out = self.linear_pred(torch.cat([lp1_resized, lp2_resized, lp3_resized, lp4_resized], dim=1))
out_resized = F.interpolate(out,scale_factor=4,mode='bilinear', align_corners=True)
- 使用torch.cat函数将lp1_resized、lp2_resized、lp3_resized和lp4_resized进行拼接,得到形状为(B, N, H, W)的特征图。
- 将拼接后的特征图通过self.linear_pred和线性预测模块进行特征转换,得到最终的输出特征图out。
- 对out进行上采样操作,得到out_resized,上采样因子为4。
- 最后对结果进行 Sigmod和Threshold便可以得到分割后的Output。、
分类网络介绍
分割任务完成了,那分类任务则是在分割任务的基础上,再做下游的分类任务。分类网络结构如下
self.conv_layers = nn.Sequential(
nn.Conv2d(4, 128, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.fc_layers = nn.Sequential(
nn.Flatten(),
nn.Linear(16**2*512, 512), # 调整大小以适应您的需求
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(512, 256), # 调整大小以适应您的需求
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(256, 3),
nn.LogSoftmax(dim=1)
)
首先对其进行4次卷积和3次最大池化进行下采样和特征提取。随后定义一个全连接层让通道数最终降到我们所需要的分类数,最后再做一次Softmax。
前向传播过程
前向传播过程则是将我们之前做好的分割结果,和原图进行通道维度cat连接后,再进行一最大池化操作,然后进行分类操作。我们对不同种类的数据做了one-hot类别编码。
以上就是大致总统思路,后续代码会上传到github

![BUUCTF_练[CISCN2019 华北赛区 Day1 Web5]CyberPunk](https://img-blog.csdnimg.cn/img_convert/b32feae4f2b6f6686af7cbc770a59e13.png)