2023年10月30日此次是我最后一次在国内发布纠错算法的测试程序,这个算法2018年左右就出来了第一个版本,部分网络上也能下载到测试程序,尽管以前的版本效率跟不上,而且码率比较固定只能支持0.63。通过几年的努力,我这次把高效率的版本库发布出来,部分功能可以自己设置里面的参数,根据码长可以设置0.25到0.63的码率。4dB以上实现数据帧的100%纠错,至于运算效率,在CPU上遍历那么多可能性运算效率是比较低的。另外,不是0dB的无法纠错,而是您愿意花多大的代价运算。在没有科研经费支持的私人企业,我需要一个团队来实现FPGA多线程、GPU上跑纠错算法,这基本上是不可能的。所以我和股东都商量好了,决定将论文发表,将整个纠错算法所有知识产权全部出售,不分国内外企业。如果被国外企业看中了,请不要骂也不要喷,因为我该想的办法都想过了,比如贷款,融资、以及请求政府支持等等。我将纠错技术卖掉也是为了让公司活下去,让团队得以保全。
本次发布的杰林码纠错算法,是我国百分之百原创的数学算法,如果你玩过LDPC、Turbo、Polar以及汉明码、RS以及 BCH等码的就能发现区别,没玩过请路过!不懂的可以看看我写的书《杰林码原理及应用》。是不是比LDPC、Turbo、Polar好,可以在同等码率下自行测试一下。
需要申明的是:我们不仅仅的发现了理论,也发明了算法,还优化到了可产品化和芯片化的步骤。
一、理论模型
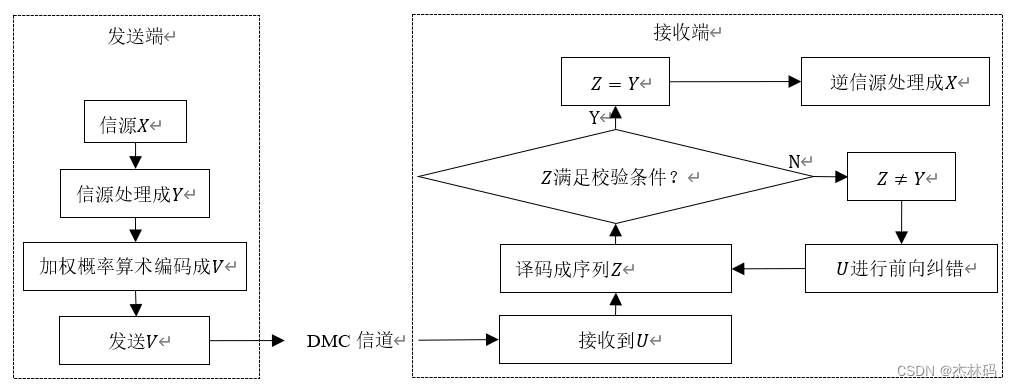
详细请参看我写的书、专利,或我发表的论文。
二、SDK下载和h文件的说明
下载地址为>>:杰林码纠错算法库(lib、dll)以及AWGN信道BPSK信号下的仿真程序(C/C++)
SDK中包含了lib和dll,以及WJLErrRecoveryCore.h文件,其中WJLErrRecoveryCore.h配置纠错的关键,相关的参数说明已经有备注。在SDK中特意保留了打印功能,无论是想把test.c中的编码、信道仿真和纠错译码分属于不同设备,还是在同一个设备上运行,都可以自行开发即可。
/******************************************************************************************
基于杰林码纠错算法理论,并基于方法二的信源处理方法:
1、根据《杰林码原理及应用》的方案二:序列X中的符号0替换为101,且将符号1替换为01,从码率的角度上来讲方案一的码率才是最大的,但是纠错能力却是最弱的
2、采用位翻转的纠错方案,从效率上做了优化,效率提高相比之前版本提高了百万倍以上;
3、最大支持0dB的纠错,由于是CPU的编程,并未实现多线程的纠错,如果基于GPU或NPU效率能最大程度的提升;
4、输入字节越长则码率越高,理论编码码率为-1/log_2(1/3) = 0.630929;
5、可通过设置参数实现不同程度的纠错,START_LIMIT、END_LIMIT、COMPARE_LIMIT和ERRBITS_LIMIT;
6、DECODER_LIST_SIZE参数建议不要设置的太低,不得小于START_LIMIT + END_LIMIT + 1
理论:《杰林码原理及应用》
作者:王杰林
描述:基于加权概率模型的纠错算法,是全新的纠错算法
时间:20231030
版本:5.0.0
******************************************************************************************/
#ifndef _WJLERRRECOVERYCORE_H
#define _WJLERRRECOVERYCORE_H
// 解码对象的缓存列表大小,一般设置为28,需要注意DECODER_LIST_SIZE必须大于(START_LIMIT + END_LIMIT + 1) * 2
#define DECODER_LIST_SIZE 48
// 由于本算法在纠正末尾几个字节时存在校验长度不足的问题,所以这里提供一个参数,在编码时多编码一定数量的0xFF用来校验,根据实际情况进行调整即可
// 一般来讲信噪比值越小,MAX_NUMBER_OF_0xFF的值越大,取值2,不建议取1或大于2的值,会出现末尾最后几个自己不确定的错误
#define MAX_NUMBER_OF_0xFF 2
// 杰林码纠错译码过程,会自动定位错误位置(即不满足“每个符号0被一个或两个1隔开”自动中止),定位错误位置后
// 通过设置START_LIMIT和END_LIMIT来确定纠错字节的范围,越大纠错能力越强,同时需要运算的时间也越长
// 根据杰林码的理论START_LIMIT取值范围为5到12,对应的纠错能力也不一样,最大值为12,根据理论得出最大前向纠错范围为12个字节
#define START_LIMIT 10
// 为保障纠错验证的正确概率,向后放宽一定的数量,当错误在END_LIMIT的基础上错误定位在COMPARE_LIMIT之后,则说明首个错误已经纠正
// 可以根据实际信噪比和信道要求设置纠错范围
#define END_LIMIT 8
// 判定首个字节被纠正的参照值,满足COMPARE_LIMIT被判定为纠错正确,一般设置为1-6的值,意思是译码校验发现下一个错误的位置已经越过了END_LIMIT
// 于是认为START_LIMIT到END_LIMIT中首个错误字节已经纠正
#define FIRST_ERR_COMPARE_LIMIT 1
// 判定当前块被纠正的参照值,一般是FIRST_ERR_COMPARE_LIMIT的基础上加上BLOCK_ERR_COMPARE_LIMIT,可以为0-8的值
#define BLOCK_ERR_COMPARE_LIMIT 2
// 限制错误比特的个数,即在START_LIMIT到END_LIMIT个字节范围内错误比特的个数,暂时仅支持10(含)个比特以下的差错,越多需要遍历的可能性也越多
// 在算力足够的情况下,完全可以采用并行验证的方案实现成倍的效率提升,比如GPU、NPU或其他硬件化,本库只考虑在CPU环境下的方案
#define ERRBITS_LIMIT 8
// 本算法“AB串”问题容易造成算法出现死循环,满足最大似然的MAXIMUM_TRAVERSAL_TIMES组可能性中挑选出最大可能的一组数据,也可以是一组数据
#define MAXIMUM_TRAVERSAL_TIMES 4
// 根据杰林码纠错算法,译码判断条件“每个符号0被一个或两个符号1隔开”,不满足该条件的都是错误的
typedef enum
{
KEEPBACK_NULL = 0, // 前面无符号
KEEPBACK_ZERO, // 前面有符号0
KEEPBACK_ONE, // 前面有符号1
KEEPBACK_ONEZERO // 前面有符号1和符号0
}KEEPBACK_SYMBOL;
// 杰林码纠错编码结构体
typedef struct
{
// 输入
unsigned char* InBytesArray; // 输入字节缓存数组
unsigned int InBytesLength; // 输入字节的总长度
unsigned int InBytesIndex; // InBytesArray的下标
// 输出
unsigned char* OutBytesArray; // 输出字节缓存数组
unsigned int OutBytesLength; // 输出字节的总长度
unsigned int OutBytesIndex; // OutBytesArray的下标
// 运算变量,其中Li和Ri的运算参考《杰林码原理及应用》一书
unsigned int Li;
unsigned int Ri;
unsigned int DelayDigits;
unsigned int CumulativeDelayDigits;
unsigned char abandon; // 用于标记哪些字节需要丢弃
}WJL_ERRRECOVERY_ENCODER;
// 纠错完毕后也需要解码器
typedef struct
{
// 输入
unsigned char* InBytesArray; // 输入字节缓存数组
unsigned int InBytesLength; // 输入字节的总长度
unsigned int InBytesIndex; // InBytesArray的下标
// 输出
unsigned char* OutBytesArray; // 输出字节缓存数组
unsigned int OutBytesLength; // 输出字节的总长度
unsigned int OutBytesIndex; // OutBytesArray的下标
unsigned int Li;
unsigned int Ri;
unsigned int value; // 解码时用来保存输入编码(接收端为U)
unsigned char mask; // 字节轮值,8个比特组合成一个字节
unsigned char outbyte; // 输出的字节
unsigned char full; // 按照比特译码,输出是否满足一个字节
unsigned char abandon; // 用于标记哪些字节需要丢弃
unsigned char status; // 状态,0x01表示译码状态,0x00表示纠错状态,会影响到对象队列的缓存
KEEPBACK_SYMBOL keepBackSymbol; // 用于信源处理方法判断的结构体
unsigned char *BytesArray; // 缓存尚未纠错的字节块
unsigned char *InBytesArraySection; // 缓存最大可能性的字节块
}WJL_ERRRECOVERY_DECODER;
/******************************************************************************************
纠错编码函数
******************************************************************************************/
int WJLErrRecoveryEncoder(WJL_ERRRECOVERY_ENCODER* coder);
/******************************************************************************************
纠错译码函数,也是核心的纠错译码函数
WJL_ERRRECOVERY_DECODER** list 用来缓存DECODER_LIST_SIZE个coder
int cumulativeZerosLimit 是通过连续译码0的个数来判定当前的错误是否完成纠错
******************************************************************************************/
int WJLErrRecoveryDecoder(WJL_ERRRECOVERY_DECODER* coder, WJL_ERRRECOVERY_DECODER** list);
#endif
三、AWGN信道BPSK信号下的仿真程序
仿真程序也是亲自写的,里面要是有公式不对,请指正。部分地方我都是引用了论文的公式,要么你就怪中国的审稿太水了。仿真程序分为三个文件分别为test.h、test.c和main.c如下。尤其是test.c,里面为什么要标注误码后与原数据的差异,是为了方便大家看到纠错过程打印的信息进行对照,如果拿原始数据复制过来,那么只能说你太菜了,因为我给出了库,就可以将编码和译码分开不同的设备上运行,仿真过程也可以。想植入到matlab或python的,请调用库尝试。
// test.h
#ifndef _TEST_H
#define _TEST_H
#ifdef __cplusplus
extern "C" {
#endif
// 生成随机数
int randEx();
// 输入信噪比,计算出理论BER
double AWGN_BPSK_BER(double EbN0_dB);
int BERByBytesArrayLength(unsigned int Length, double BER, int FirstErrBytePos, int printIt);
#ifdef __cplusplus
}
#endif
#endif
// test.c
#include "test.h"
#include "WJLErrRecoveryCore.h"
#include <math.h>
#include <time.h>
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <windows.h>
unsigned char bitOfByteTable[256][8] =
{
{0,0,0,0,0,0,0,0},{0,0,0,0,0,0,0,1},{0,0,0,0,0,0,1,0},{0,0,0,0,0,0,1,1},{0,0,0,0,0,1,0,0},{0,0,0,0,0,1,0,1},{0,0,0,0,0,1,1,0},{0,0,0,0,0,1,1,1}, //0~7
{0,0,0,0,1,0,0,0},{0,0,0,0,1,0,0,1},{0,0,0,0,1,0,1,0},{0,0,0,0,1,0,1,1},{0,0,0,0,1,1,0,0},{0,0,0,0,1,1,0,1},{0,0,0,0,1,1,1,0},{0,0,0,0,1,1,1,1}, //8~15
{0,0,0,1,0,0,0,0},{0,0,0,1,0,0,0,1},{0,0,0,1,0,0,1,0},{0,0,0,1,0,0,1,1},{0,0,0,1,0,1,0,0},{0,0,0,1,0,1,0,1},{0,0,0,1,0,1,1,0},{0,0,0,1,0,1,1,1}, //16~23
{0,0,0,1,1,0,0,0},{0,0,0,1,1,0,0,1},{0,0,0,1,1,0,1,0},{0,0,0,1,1,0,1,1},{0,0,0,1,1,1,0,0},{0,0,0,1,1,1,0,1},{0,0,0,1,1,1,1,0},{0,0,0,1,1,1,1,1}, //24~31
{0,0,1,0,0,0,0,0},{0,0,1,0,0,0,0,1},{0,0,1,0,0,0,1,0},{0,0,1,0,0,0,1,1},{0,0,1,0,0,1,0,0},{0,0,1,0,0,1,0,1},{0,0,1,0,0,1,1,0},{0,0,1,0,0,1,1,1}, //32~39
{0,0,1,0,1,0,0,0},{0,0,1,0,1,0,0,1},{0,0,1,0,1,0,1,0},{0,0,1,0,1,0,1,1},{0,0,1,0,1,1,0,0},{0,0,1,0,1,1,0,1},{0,0,1,0,1,1,1,0},{0,0,1,0,1,1,1,1}, //40~47
{0,0,1,1,0,0,0,0},{0,0,1,1,0,0,0,1},{0,0,1,1,0,0,1,0},{0,0,1,1,0,0,1,1},{0,0,1,1,0,1,0,0},{0,0,1,1,0,1,0,1},{0,0,1,1,0,1,1,0},{0,0,1,1,0,1,1,1}, //48~55
{0,0,1,1,1,0,0,0},{0,0,1,1,1,0,0,1},{0,0,1,1,1,0,1,0},{0,0,1,1,1,0,1,1},{0,0,1,1,1,1,0,0},{0,0,1,1,1,1,0,1},{0,0,1,1,1,1,1,0},{0,0,1,1,1,1,1,1}, //56~63
{0,1,0,0,0,0,0,0},{0,1,0,0,0,0,0,1},{0,1,0,0,0,0,1,0},{0,1,0,0,0,0,1,1},{0,1,0,0,0,1,0,0},{0,1,0,0,0,1,0,1},{0,1,0,0,0,1,1,0},{0,1,0,0,0,1,1,1}, //64~71
{0,1,0,0,1,0,0,0},{0,1,0,0,1,0,0,1},{0,1,0,0,1,0,1,0},{0,1,0,0,1,0,1,1},{0,1,0,0,1,1,0,0},{0,1,0,0,1,1,0,1},{0,1,0,0,1,1,1,0},{0,1,0,0,1,1,1,1}, //72~79
{0,1,0,1,0,0,0,0},{0,1,0,1,0,0,0,1},{0,1,0,1,0,0,1,0},{0,1,0,1,0,0,1,1},{0,1,0,1,0,1,0,0},{0,1,0,1,0,1,0,1},{0,1,0,1,0,1,1,0},{0,1,0,1,0,1,1,1}, //80~87
{0,1,0,1,1,0,0,0},{0,1,0,1,1,0,0,1},{0,1,0,1,1,0,1,0},{0,1,0,1,1,0,1,1},{0,1,0,1,1,1,0,0},{0,1,0,1,1,1,0,1},{0,1,0,1,1,1,1,0},{0,1,0,1,1,1,1,1}, //88~95
{0,1,1,0,0,0,0,0},{0,1,1,0,0,0,0,1},{0,1,1,0,0,0,1,0},{0,1,1,0,0,0,1,1},{0,1,1,0,0,1,0,0},{0,1,1,0,0,1,0,1},{0,1,1,0,0,1,1,0},{0,1,1,0,0,1,1,1}, //96~103
{0,1,1,0,1,0,0,0},{0,1,1,0,1,0,0,1},{0,1,1,0,1,0,1,0},{0,1,1,0,1,0,1,1},{0,1,1,0,1,1,0,0},{0,1,1,0,1,1,0,1},{0,1,1,0,1,1,1,0},{0,1,1,0,1,1,1,1}, //104~111
{0,1,1,1,0,0,0,0},{0,1,1,1,0,0,0,1},{0,1,1,1,0,0,1,0},{0,1,1,1,0,0,1,1},{0,1,1,1,0,1,0,0},{0,1,1,1,0,1,0,1},{0,1,1,1,0,1,1,0},{0,1,1,1,0,1,1,1}, //112~119
{0,1,1,1,1,0,0,0},{0,1,1,1,1,0,0,1},{0,1,1,1,1,0,1,0},{0,1,1,1,1,0,1,1},{0,1,1,1,1,1,0,0},{0,1,1,1,1,1,0,1},{0,1,1,1,1,1,1,0},{0,1,1,1,1,1,1,1}, //120~127
{1,0,0,0,0,0,0,0},{1,0,0,0,0,0,0,1},{1,0,0,0,0,0,1,0},{1,0,0,0,0,0,1,1},{1,0,0,0,0,1,0,0},{1,0,0,0,0,1,0,1},{1,0,0,0,0,1,1,0},{1,0,0,0,0,1,1,1}, //128~135
{1,0,0,0,1,0,0,0},{1,0,0,0,1,0,0,1},{1,0,0,0,1,0,1,0},{1,0,0,0,1,0,1,1},{1,0,0,0,1,1,0,0},{1,0,0,0,1,1,0,1},{1,0,0,0,1,1,1,0},{1,0,0,0,1,1,1,1}, //136~143
{1,0,0,1,0,0,0,0},{1,0,0,1,0,0,0,1},{1,0,0,1,0,0,1,0},{1,0,0,1,0,0,1,1},{1,0,0,1,0,1,0,0},{1,0,0,1,0,1,0,1},{1,0,0,1,0,1,1,0},{1,0,0,1,0,1,1,1}, //144~151
{1,0,0,1,1,0,0,0},{1,0,0,1,1,0,0,1},{1,0,0,1,1,0,1,0},{1,0,0,1,1,0,1,1},{1,0,0,1,1,1,0,0},{1,0,0,1,1,1,0,1},{1,0,0,1,1,1,1,0},{1,0,0,1,1,1,1,1}, //152~159
{1,0,1,0,0,0,0,0},{1,0,1,0,0,0,0,1},{1,0,1,0,0,0,1,0},{1,0,1,0,0,0,1,1},{1,0,1,0,0,1,0,0},{1,0,1,0,0,1,0,1},{1,0,1,0,0,1,1,0},{1,0,1,0,0,1,1,1}, //160~167
{1,0,1,0,1,0,0,0},{1,0,1,0,1,0,0,1},{1,0,1,0,1,0,1,0},{1,0,1,0,1,0,1,1},{1,0,1,0,1,1,0,0},{1,0,1,0,1,1,0,1},{1,0,1,0,1,1,1,0},{1,0,1,0,1,1,1,1}, //168~175
{1,0,1,1,0,0,0,0},{1,0,1,1,0,0,0,1},{1,0,1,1,0,0,1,0},{1,0,1,1,0,0,1,1},{1,0,1,1,0,1,0,0},{1,0,1,1,0,1,0,1},{1,0,1,1,0,1,1,0},{1,0,1,1,0,1,1,1}, //176~183
{1,0,1,1,1,0,0,0},{1,0,1,1,1,0,0,1},{1,0,1,1,1,0,1,0},{1,0,1,1,1,0,1,1},{1,0,1,1,1,1,0,0},{1,0,1,1,1,1,0,1},{1,0,1,1,1,1,1,0},{1,0,1,1,1,1,1,1}, //184~191
{1,1,0,0,0,0,0,0},{1,1,0,0,0,0,0,1},{1,1,0,0,0,0,1,0},{1,1,0,0,0,0,1,1},{1,1,0,0,0,1,0,0},{1,1,0,0,0,1,0,1},{1,1,0,0,0,1,1,0},{1,1,0,0,0,1,1,1}, //192~199
{1,1,0,0,1,0,0,0},{1,1,0,0,1,0,0,1},{1,1,0,0,1,0,1,0},{1,1,0,0,1,0,1,1},{1,1,0,0,1,1,0,0},{1,1,0,0,1,1,0,1},{1,1,0,0,1,1,1,0},{1,1,0,0,1,1,1,1}, //200~207
{1,1,0,1,0,0,0,0},{1,1,0,1,0,0,0,1},{1,1,0,1,0,0,1,0},{1,1,0,1,0,0,1,1},{1,1,0,1,0,1,0,0},{1,1,0,1,0,1,0,1},{1,1,0,1,0,1,1,0},{1,1,0,1,0,1,1,1}, //208~215
{1,1,0,1,1,0,0,0},{1,1,0,1,1,0,0,1},{1,1,0,1,1,0,1,0},{1,1,0,1,1,0,1,1},{1,1,0,1,1,1,0,0},{1,1,0,1,1,1,0,1},{1,1,0,1,1,1,1,0},{1,1,0,1,1,1,1,1}, //216~223
{1,1,1,0,0,0,0,0},{1,1,1,0,0,0,0,1},{1,1,1,0,0,0,1,0},{1,1,1,0,0,0,1,1},{1,1,1,0,0,1,0,0},{1,1,1,0,0,1,0,1},{1,1,1,0,0,1,1,0},{1,1,1,0,0,1,1,1}, //224~231
{1,1,1,0,1,0,0,0},{1,1,1,0,1,0,0,1},{1,1,1,0,1,0,1,0},{1,1,1,0,1,0,1,1},{1,1,1,0,1,1,0,0},{1,1,1,0,1,1,0,1},{1,1,1,0,1,1,1,0},{1,1,1,0,1,1,1,1}, //232~239
{1,1,1,1,0,0,0,0},{1,1,1,1,0,0,0,1},{1,1,1,1,0,0,1,0},{1,1,1,1,0,0,1,1},{1,1,1,1,0,1,0,0},{1,1,1,1,0,1,0,1},{1,1,1,1,0,1,1,0},{1,1,1,1,0,1,1,1}, //240~247
{1,1,1,1,1,0,0,0},{1,1,1,1,1,0,0,1},{1,1,1,1,1,0,1,0},{1,1,1,1,1,0,1,1},{1,1,1,1,1,1,0,0},{1,1,1,1,1,1,0,1},{1,1,1,1,1,1,1,0},{1,1,1,1,1,1,1,1} //248~255
};
// 以毫秒为单位的随机数,确保数据的误比特绝对的随机状况下
int randEx()
{
LARGE_INTEGER seed;
QueryPerformanceFrequency(&seed);
QueryPerformanceCounter(&seed);
srand(seed.QuadPart);
return rand();
}
// Q函数
double Q(double EbN0)
{
return 0.5 * erfc(sqrt(2 * EbN0) / sqrt(2.0));
}
//------------------------------------------------------------------------------------------------------
// 下面的几个函数主要是针对不同的系统进行仿真,主要是基于不同的信道类型,输入不同的信噪比计算出对应的BER
// BPSK是一个公式
double AWGN_BPSK_BER(double EbN0_dB)
{
// 参考文献:丁凯. AWGN信道中BPSK误码率仿真分析[J]. 微处理机,2021,42(3):23-26. DOI:10.3969/j.issn.1002-2279.2021.03.006.
double EbN0 = pow(10, EbN0_dB / 10);
// 计算误比特率
return 0.5 * erfc(sqrt(EbN0));
//return Q(EbN0);
}
// 判断两个字节中差异比特个数
int ErrBits(unsigned char byte1, unsigned char byte2)
{
int i, j = 0;
unsigned char tmpbyte = byte1 ^ byte2;
// 统计差异个数
for (i = 7; i >= 0; --i) {
if ((tmpbyte >> i) & 0x01) {
j++;
}
}
return j;
}
// 存在错误的数据编译码
int BERByBytesArrayLength(unsigned int Length, double BER, int FirstErrBytePos, int printIt)
{
int i = 0, j = 0, Limit, RandDigit, count = 0, errbits = 0, maxErrbits = 0, tj = 0;
unsigned char tmpByte = 0x00;
double R;
WJL_ERRRECOVERY_ENCODER* encoder = NULL;
WJL_ERRRECOVERY_DECODER* decoder = NULL;
WJL_ERRRECOVERY_ENCODER** list = NULL;
// 开辟缓存
encoder = (WJL_ERRRECOVERY_ENCODER*)malloc(sizeof(WJL_ERRRECOVERY_ENCODER));
decoder = (WJL_ERRRECOVERY_DECODER*)malloc(sizeof(WJL_ERRRECOVERY_DECODER));
list = (WJL_ERRRECOVERY_DECODER**)malloc(DECODER_LIST_SIZE * sizeof(WJL_ERRRECOVERY_DECODER*));
if (encoder == NULL || decoder == NULL || list == NULL) {
goto Err;
}
// 直接开辟DECODER_LIST_SIZE个list
for (i = 0; i < DECODER_LIST_SIZE; ++i) {
list[i] = (WJL_ERRRECOVERY_DECODER*)malloc(sizeof(WJL_ERRRECOVERY_DECODER));
if (list[i] == NULL) {
goto Err;
}
}
// 默认会在当前数据编码前,先编码两个0x00,所以在实际应用中这里必须加上2
encoder->InBytesLength = Length;
decoder->OutBytesLength = Length;
// 输出缓存尽量放的大一些,因为根据不同的SUBSECTION码率是不一样的,为了支持0.25的码率,需要设置四倍长度
encoder->OutBytesLength = (unsigned int)(encoder->InBytesLength * 4);
// 编码的缓存
encoder->InBytesArray = (unsigned char*)malloc(encoder->InBytesLength);
encoder->OutBytesArray = (unsigned char*)malloc(encoder->OutBytesLength);
// 译码的缓存
decoder->InBytesArray = (unsigned char*)malloc(encoder->OutBytesLength);
decoder->OutBytesArray = (unsigned char*)malloc(encoder->InBytesLength);
decoder->BytesArray = (unsigned char*)malloc(DECODER_LIST_SIZE);
decoder->InBytesArraySection = (unsigned char*)malloc(DECODER_LIST_SIZE);
if (encoder->InBytesArray == NULL || encoder->OutBytesArray == NULL || decoder->InBytesArray == NULL || decoder->OutBytesArray == NULL || decoder->BytesArray == NULL || decoder->InBytesArraySection == NULL) {
goto Err;
}
if (Length <= 1024) {
if (printIt) printf("随机生成的原始数据:%d\n", encoder->InBytesLength);
// 产生随机数据
for (i = 0; i < Length; ++i) {
encoder->InBytesArray[i] = randEx() % 256; //rand() % 256; // Set_In_BUFF[i];
if (printIt) printf("%03d->%02X,", i, encoder->InBytesArray[i]);
}
if (printIt)printf("\n");
}
else {
// 产生随机数据
for (i = 0; i < Length; ++i) {
encoder->InBytesArray[i] = randEx() % 256; //rand() % 256; // Set_In_BUFF[i];
}
}
/********************编码译码部分**********************/
WJLErrRecoveryEncoder(encoder);
// encoder->OutBytesIndex为实际输出的字节长度,把encoder->OutBytesArray中的字节复制给decoder->InBytesArray
memcpy(decoder->InBytesArray, encoder->OutBytesArray, encoder->OutBytesIndex);
decoder->InBytesLength = encoder->OutBytesIndex;
// 实际编码码率
R = (double)encoder->InBytesLength / (double)encoder->OutBytesIndex;
if (printIt) {
if (Length <= 1024) {
printf("编码后的字节:%d\n", encoder->OutBytesIndex);
for (i = 0; i < decoder->InBytesLength; ++i) {
printf("%03d->%02X,", i, decoder->InBytesArray[i]);
}
printf("\n");
printf("编码前:%d, 编码后:%d,实际码率R = %1.6f, 理论编码码率R=-1/log2(1/3)=1/1.5849625=0.63092975\n", encoder->InBytesLength, encoder->OutBytesIndex, R);
printf("\n");
}
else {
printf("编码前:%d, 编码后:%d,实际码率R = %1.6f, 理论编码码率R=-1/log2(1/3)=1/1.5849625=0.63092975\n", encoder->InBytesLength, encoder->OutBytesIndex, R);
printf("\n");
}
}
// 计算上限
Limit = (int)(BER * 100000000.0);
// 让部分数据出现错误
for (i = 0; i < decoder->InBytesLength; ++i) {
tmpByte = 0x00;
tj = 0;
if (i >= FirstErrBytePos) { // 让错误出现在FirstErrBytePos(含)个字节以后
for (j = 0; j < 8; ++j) {
tmpByte <<= 1;
// 随机生成0 - 100000000.0的数字
RandDigit = (int)((double)rand((unsigned int)time(NULL)) / ((double)RAND_MAX + 1) * 100000000.0);
// 根据误比特率进行比特翻转
if (RandDigit <= Limit) {
// 让比特出现错误
if (bitOfByteTable[decoder->InBytesArray[i]][j] == 0) {
tmpByte |= 0x01;
}
else {
tmpByte |= 0x00;
}
// 累计错误比特的个数
count++;
tj++;
}
else {
if (tj > maxErrbits) maxErrbits = tj;
tmpByte |= bitOfByteTable[decoder->InBytesArray[i]][j];
}
}
// 把tmpByte回填给decoder->InBytesArray[i]
decoder->InBytesArray[i] = tmpByte;
}
}
if (printIt) {
if (Length <= 1024) {
printf("信道仿真传输得到的字节:%d\n", encoder->OutBytesIndex);
for (i = 0; i < encoder->OutBytesIndex; ++i) {
if (encoder->OutBytesArray[i] != decoder->InBytesArray[i]) {
errbits = ErrBits(encoder->OutBytesArray[i], decoder->InBytesArray[i]);
printf("%03d->%02X-*%02X-%d,", i, decoder->InBytesArray[i], encoder->OutBytesArray[i], errbits);
//printf("*%02X-%02X %d,", decoder->InBytesArray[i], encoder->OutBytesArray[i], errbits);
//printf("%03d->%02X,", i, decoder->InBytesArray[i]);
}
else {
printf("%03d->%02X,", i, decoder->InBytesArray[i]);
//printf("%02X,", decoder->InBytesArray[i]);
}
}
printf("\n");
printf("实际误比特率:%1.6f, 连续8个比特最多出现错误比特的个数:%d\n", (double)count / ((double)decoder->InBytesLength * 8.0), maxErrbits);
printf("\n");
}
else {
printf("实际误比特率:%1.6f, 连续8个比特最多出现错误比特的个数:%d\n", (double)count / ((double)decoder->InBytesLength * 8.0), maxErrbits);
printf("\n");
}
}
/********************纠错译码部分**********************/
WJLErrRecoveryDecoder(decoder, list);
if (printIt) {
if (Length <= 1024) {
printf("译码后的字节:%d\n", decoder->OutBytesIndex - 1);
for (i = 0; i < Length; ++i) {
printf("%03d->%02X,", i, decoder->OutBytesArray[i]);
}
printf("\n");
}
}
// 检查是否有错误
for (i = 0; i < Length; ++i) {
if (encoder->InBytesArray[i] != decoder->OutBytesArray[i]) {
printf("*******************错误位置:%d\n", i);
goto Err;
}
}
// 释放资源
if (encoder) {
if (encoder->InBytesArray)free(encoder->InBytesArray);
if (encoder->OutBytesArray)free(encoder->OutBytesArray);
free(encoder);
}
if (decoder) {
if (decoder->InBytesArray)free(decoder->InBytesArray);
if (decoder->OutBytesArray)free(decoder->OutBytesArray);
if (decoder->BytesArray)free(decoder->BytesArray);
if (decoder->InBytesArraySection)free(decoder->InBytesArraySection);
free(decoder);
}
if (list) {
for (i = 0; i < DECODER_LIST_SIZE; ++i) if (list[i]) free(list[i]);
free(list);
}
printf("所有错误已经纠正,并且译码正确!\n");
return 1;
Err:
// 释放资源
if (encoder) {
if (encoder->InBytesArray)free(encoder->InBytesArray);
if (encoder->OutBytesArray)free(encoder->OutBytesArray);
free(encoder);
}
if (decoder) {
if (decoder->InBytesArray)free(decoder->InBytesArray);
if (decoder->OutBytesArray)free(decoder->OutBytesArray);
if (decoder->BytesArray)free(decoder->BytesArray);
if (decoder->InBytesArraySection)free(decoder->InBytesArraySection);
free(decoder);
}
if (list) {
for (i = 0; i < DECODER_LIST_SIZE; ++i) if (list[i]) free(list[i]);
free(list);
}
printf("\n译码错误!\n");
return 0;
}
// main.c
#include "test.h"
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <windows.h>
#include <time.h>
#include <math.h>
#ifdef WIN32
#define inline __inline
#endif // WIN32
// 带信噪比下的错误数据纠错实验
int main() { // 2
int i, size = 1, count = 0, inputerr = 0, printSign = 0;
double ber, EbN0_dB = 0.0;
int bytes = 1;
STEP1:
printf("请输入随机帧的字节长度(不得小于1):\n");
inputerr = scanf_s("%d", &bytes);
// 验证是否合法
if (bytes < 1) {
printf("字节长度错误!\n");
goto STEP1;
}
STEP2:
printf("请输入需要测试帧的数量(不得小于1):\n");
inputerr = scanf_s("%d", &size);
if (size < 1) {
printf("帧数至少为1个!\n");
goto STEP2;
}
printf("请输入AWGN_BPSK信噪比Eb/N0(dB)(等于等于100视为无误传输):\n");
inputerr = scanf_s("%lf", &EbN0_dB);
if (EbN0_dB >= 100) {
ber = 0;
}
else {
// 根据AWGN信道BPSK信号计算对应码率下的误比特率
ber = AWGN_BPSK_BER(EbN0_dB);
printf("EbN0_dB = %1.6f, AWGN_BPSK理论误比特率:%1.8f\n", EbN0_dB, ber);
}
printf("请输入是否打印随机数(0不打印,1打印):\n");
inputerr = scanf_s("%d", &printSign);
// 可以通过for进行10万、100万组随机数据的实测
for (i = 0; i < size; ++i) {
printf("-----------------------------------------------------------------------------------------------------\n");
printf("第%d帧随机测试,累计正确译码帧数%d,FER为:%1.6f:", i, count, ((double)i - (double)count)/ (double)i);
if (BERByBytesArrayLength(bytes, ber, 0, printSign)) {
count++;
}
}
printf("全部%d帧测试结束,最终正确译码帧数%d,最终FER为:%1.6f:", size, count, ((double)i - (double)count) / (double)i);
system("pause");
return 0;
}
四、实验效果
参数设置,注意不同的参数纠错效果是不同的,可以根据不同的信道要求测试。
START_LIMIT = 12
END_LIMIT = 10
FIRST_ERR_COMPARE_LIMIT = 1
BLOCK_ERR_COMPARE_LIMIT = 2
ERRBITS_LIMIT = 8
MAXIMUM_TRAVERSAL_TIMES = 12
实验中5dB以上效率还不错,10万帧分别为32字节、64字节、以及256字节均能纠错。0dB到3dB就是慢,毕竟需要遍历的可能性不少,大家有时间的可以自己测试。如下图:
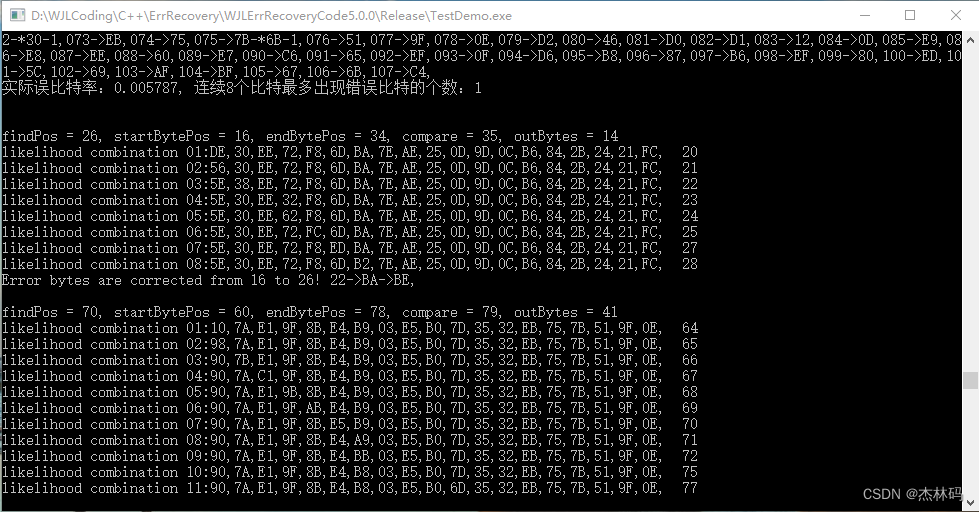
不同的参数对应不同的纠错效果。偶尔会感觉上是停顿了,通过打印找出当前停顿是因为出现了多个比特差错,所以一直在纠错遍历可能性。MAXIMUM_TRAVERSAL_TIMES 参数的目的就是利用最大似然的方案,不让遍历进入太多的循环,同样START_LIMIT 和END_LIMIT 越小,纠错速度越快,但是存在很小的概率使得译码错误。