linux I/O 读写方式
Linux提供了轮询、I/O中断以及DMA传输这3种磁盘与主存之间的数据传输机制。
轮询方式是基于死循环对 I/O 端口进行不断检测。
I/O中断方式
I/O 中断方式是指当数据到达时,磁盘主动向 CPU 发起中断请求,由 CPU 自身负责数据的传输过程。
在DMA技术出现之前,应用程序与磁盘之间的I/O操作都是通过CPU的中断完成的。每次用户进程读取磁盘数据是,都需要CPU中断,然后发起I/O请求等待数据读取和拷贝完成,每次的I/O中断都会导致CPU的上下文切换。
计算机程序访问磁盘上的数据IO过程如下:
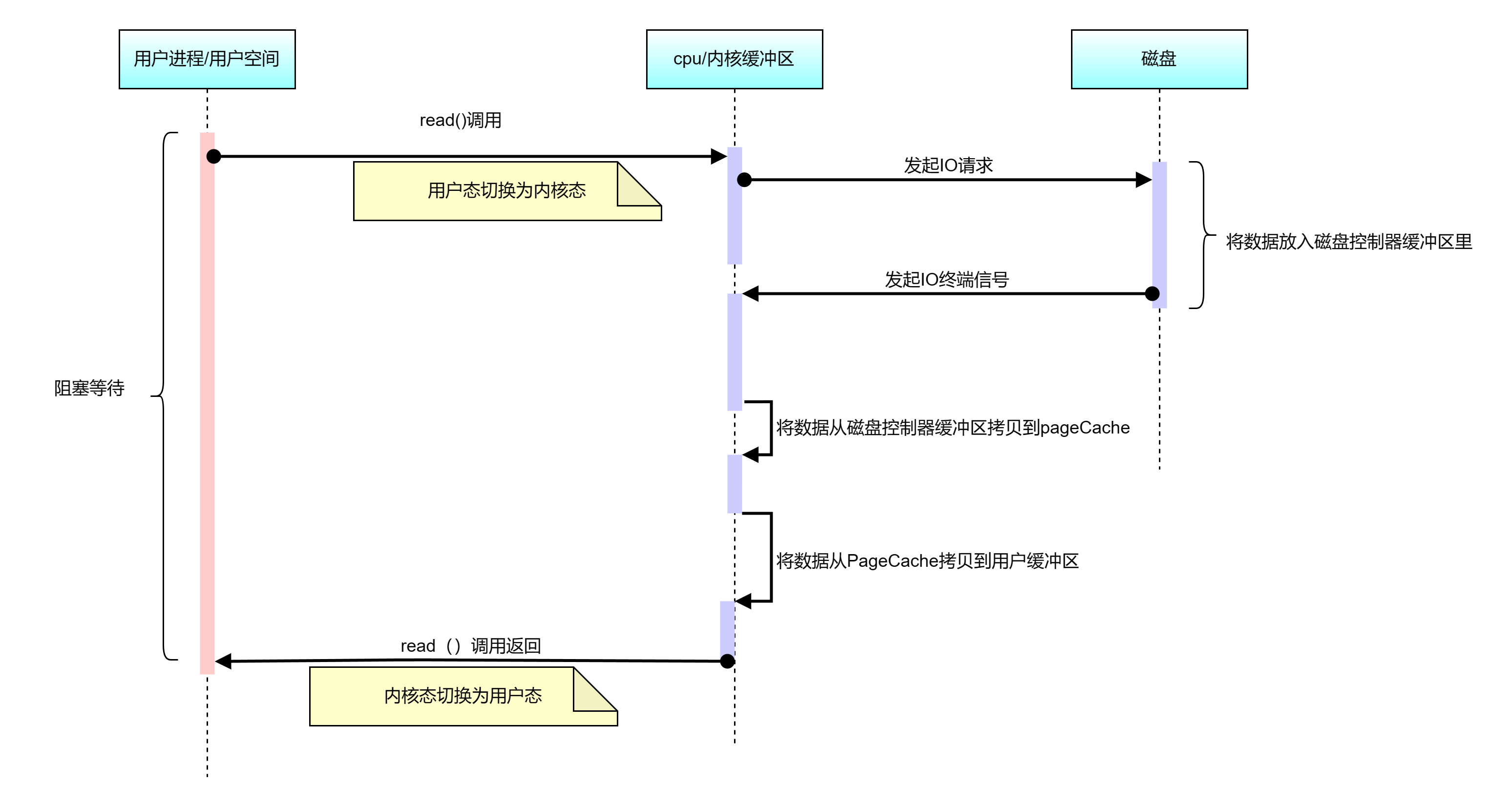
(1)CPU 先发出读指令给磁盘控制器(发出一个系统调用),然后返回;
(2)磁盘控制器接受到指令,开始准备数据,把数据拷贝到磁盘控制器的内部缓冲区中,然后产生一个中断;
(3)CPU 收到中断信号后,让出CPU资源,把磁盘控制器的缓冲区的数据一次一个字节地拷贝进自己的寄存器,然后再把寄存器里的数据拷贝到内存,而在数据传输的期间 CPU 是无法执行其他任务的。
从这3个步骤可以看到2个问题:
(1)数据在不同介质之间被拷贝了很多次,
(2)每个过程都要需要 CPU 亲自参与,在这个过程,在数据拷贝没有完成前,CPU 是不能做额外事情的,被IO独占。
为了解决cpu被持续占用的问题,提出了DMA技术,即(Direct Memory Access,DMA)。
DMA传输原理
直接内存访问(Direct Memory Access,DMA)是现代计算机所采用的IO设备数据交换模式,它允许不同速度的硬件装置来沟通,而不需要依赖于CPU的大量中断负载。在DMA模式下,CPU只须向DMA控制器下达指令,让DMA控制器来处理数据的传送,数据传送完毕再把信息反馈给CPU,这样就很大程度上减轻了CPU资源占有率,可以大大节省系统资源。
DMA 传输则在 I/O 中断的基础上引入了 DMA 磁盘控制器,由 DMA 磁盘控制器负责数据的传输,降低了 I/O 中断操作对 CPU 资源的大量消耗。
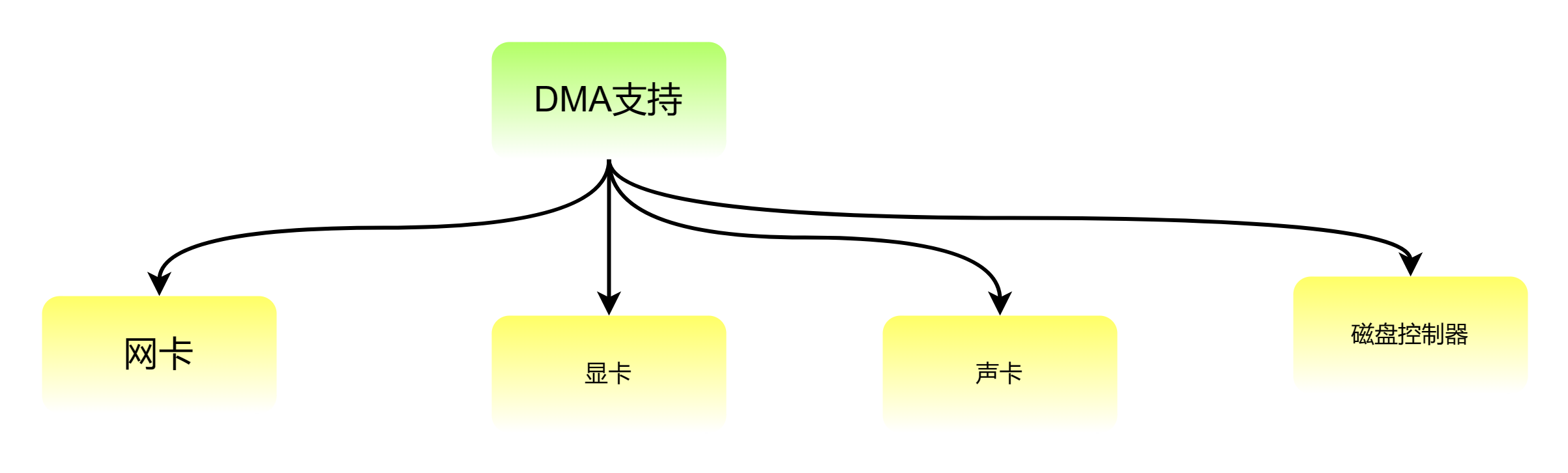
目前支持DMA的硬件主要是网卡、声卡、显卡、磁盘控制器:
有了DMA 后数据读取过程如下:
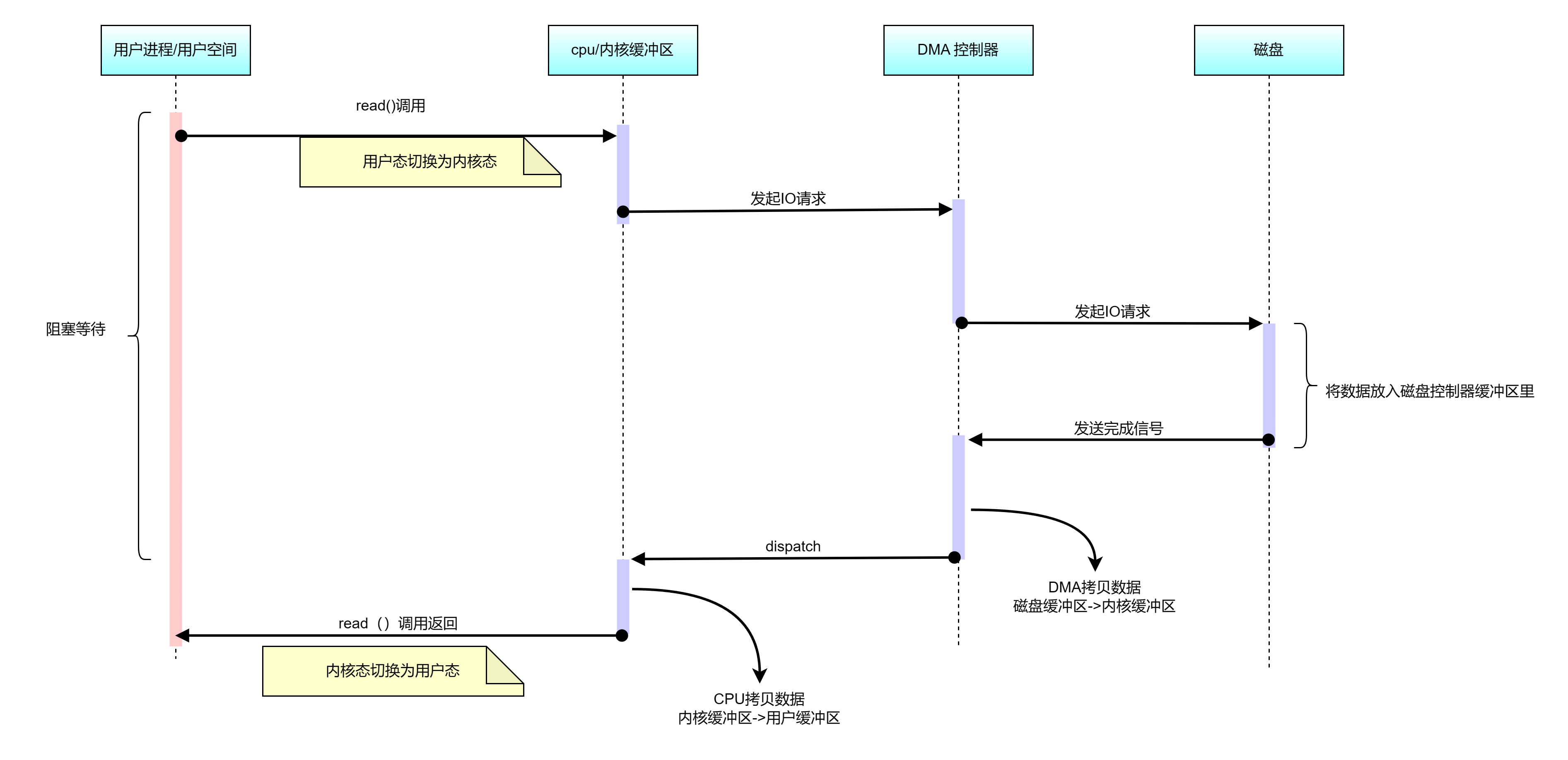
(1)用户进程a调用系统调用read 方法,向OS内核(资源总管)发出 I/O 请求,请求读取数据到自己的内存缓冲区中,进程进入阻塞状态;
(2)OS内核收到请求后,进一步将 I/O 请求发送 DMA,然后让 CPU 执行其他任务;
(3)DMA 再将 I/O 请求发送给磁盘控制器;
(4)磁盘控制器收到 DMA 的 I/O 请求,把数据从磁盘拷贝到磁盘控制器的缓冲区中,当磁盘控制器的缓冲区被写满后,它向 DMA 发起中断信号,告知自己缓冲区已满;
(5)DMA 收到磁盘的中断信号后,将磁盘控制器缓冲区中的数据拷贝到内核缓冲区中,此时不占用 CPU,CPU 可以执行其他任务;
(6)当 DMA 读取了一个固定buffer的数据,就会发送中断信号给 CPU;
(7)CPU 收到 DMA 的信号,知道数据已经Ready,于是将数据从内核拷贝到用户空间,结束系统调用;
DMA技术释放了CPU的占用时间,它只做事件通知,数据拷贝由DMA完成。虽然DMA优化了CPU的利用率,但是并没有提高数据读取的性能。
为了减少数据在2种状态之间的切换次数,因为状态切换是一个非常、非常、非常繁重的工作。为此,大佬们就提了零拷贝技术。
传统IO 方式
为了更好的理解零拷贝解决的问题,我们首先来了解一下传统I/O方式存在的问题。
首先,我们来看一个示例:在java开发中,从某台机器将一份数据通过网络传输到另一台机器,其写入代码如下:
public static void main(String[] args) {
String host = "127.0.0.1";
int port = 8989;
try {
Socket client = new Socket(host,port);
InputStream inputStream = new FileInputStream(FILE_PATH);
OutputStream outputStream = new DataOutputStream(socket.getOutputStream());
byte[] buffer = new byte[4096];
while (inputStream.read(buffer) >= 0) {
outputStream.write(buffer);
}
outputStream.close();
client.close();
inputStream.close();
}catch (IOException e){
e.printStackTrace();
}
}
代码看起来比较简单,但是深入到操作系统层面,其实际的微观操作更复杂,其操作流程图如下:
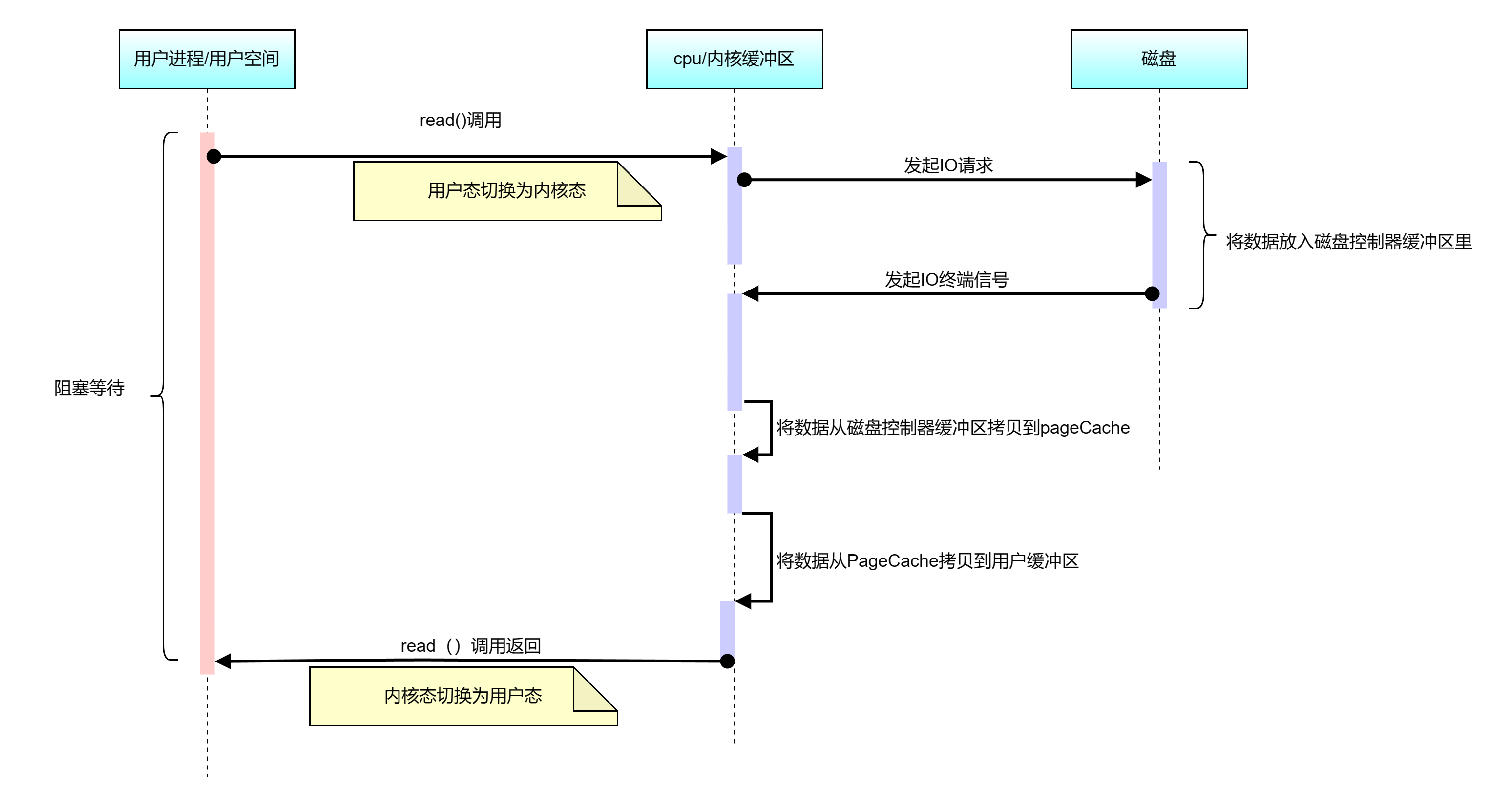
(1)用户进程向OS发出read()系统调用,触发上下文切换,从用户态转换到内核态;
(2)CPU发起IO请求。通过直接内存访问(DMA)从磁盘读取文件内容,复制到内核缓冲区PageCache中;
(3)将内核缓冲区数据,拷贝到用户空间缓冲区,触发上下文切换,从内核态转换到用户态;
(4)用户进程向OS发起write系统调用,触发上下文切换,从用户态切换到内核态;
(5)将数据从用户缓冲区拷贝到内核中与目的地Socket关联的缓冲区;
(6)数据最终经由Socket通过DMA传送到硬件(网卡)缓冲区,write()系统调用返回,并从内核态切换回用户态。
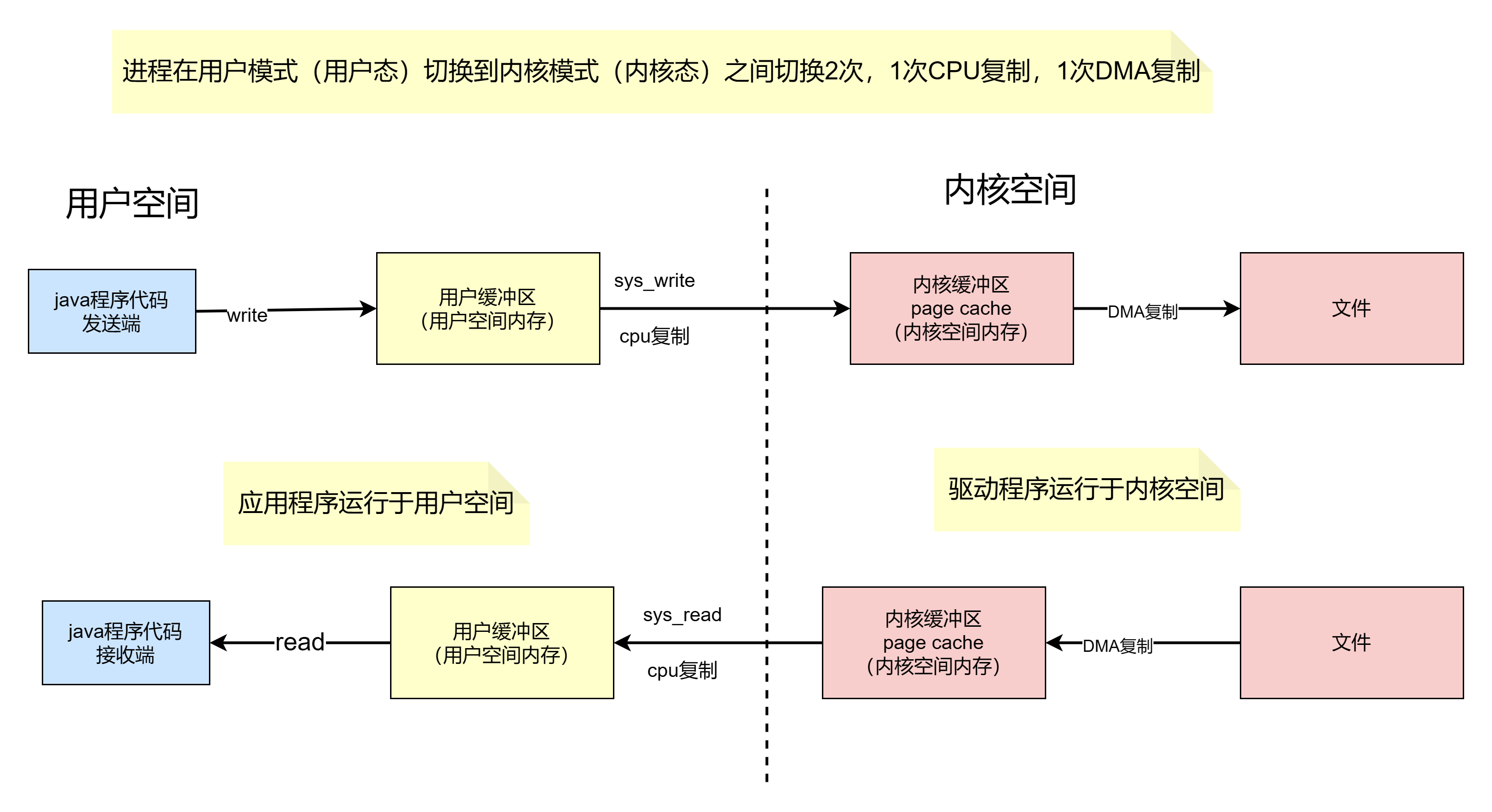
从示例中我们可以知道,在linux系统中,传统的访问方式是通过write()和read()两个系统调用实现的,通过read()函数读取文件到缓冲区中,然后通过 write() 方法把缓存中的数据输出到网络端口。
其整个过程涉及到2次CPU拷贝、2次DMA拷贝,一共4次拷贝以及4次上下文切换,如下图所示:
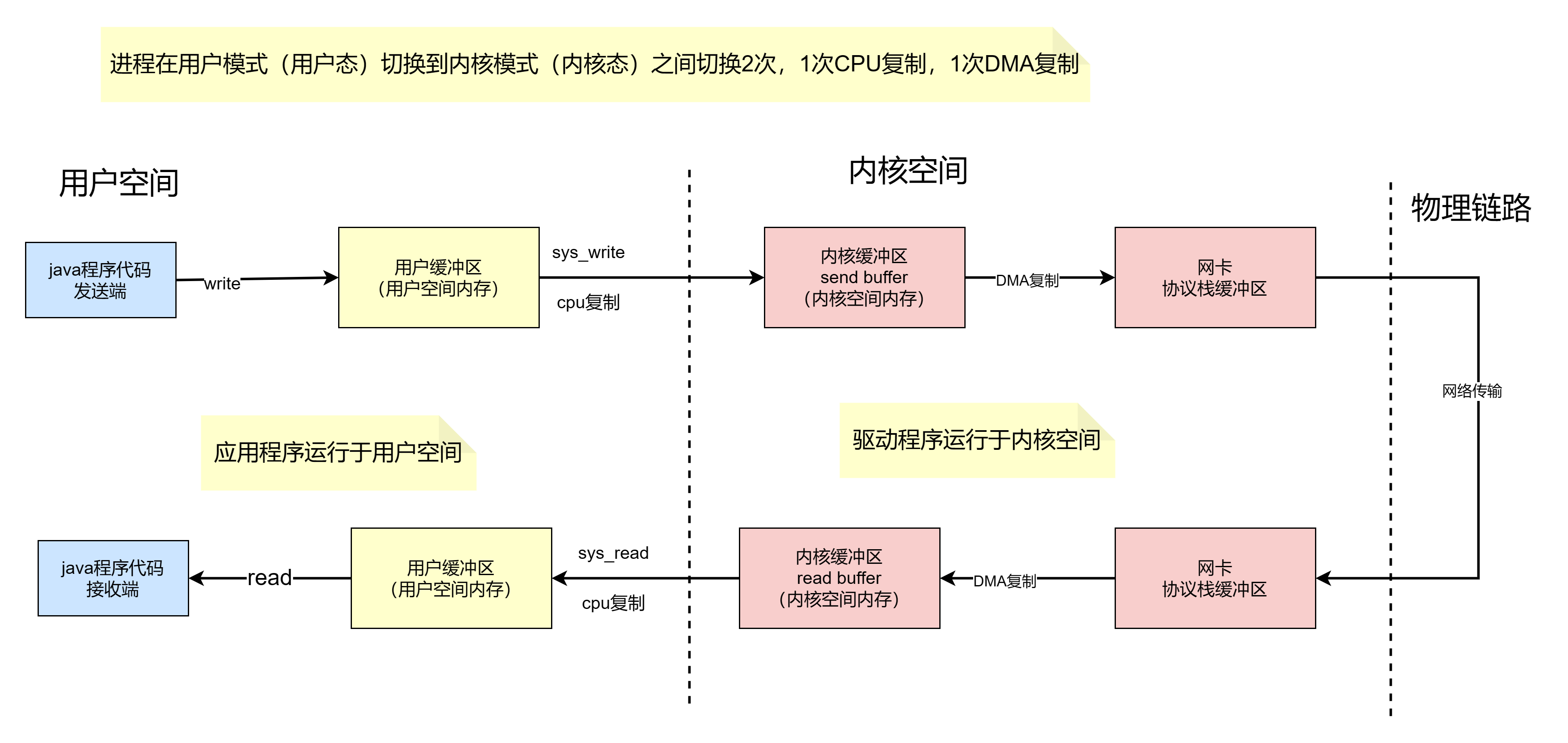
传统读操作
当应用程序执行 read 系统调用读取一块数据的时候,如果这块数据已经存在于用户进程的页内存中,就直接从内存中读取数据;如果数据不存在,则先将数据从磁盘加载数据到内核空间的读缓存(read buffer)中,再从读缓存拷贝到用户进程的页内存中。
read(file_fd, tmp_buf, len);
基于传统的 I/O 读取方式,read 系统调用会触发 2 次上下文切换,1 次 DMA 拷贝和 1 次 CPU 拷贝,发起数据读取的流程如下:
(1)用户进程通过 read() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space);
(2)CPU利用DMA控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer);
(3)CPU将读缓冲区(read buffer)中的数据拷贝到用户空间(user space)的用户缓冲区(user buffer);
(4)上下文从内核态(kernel space)切换回用户态(user space),read 调用执行返回。
传统写操作
当应用程序准备好数据,执行 write 系统调用发送网络数据时,先将数据从用户空间的页缓存拷贝到内核空间的网络缓冲区(socket buffer)中,然后再将写缓存中的数据拷贝到网卡设备完成数据发送。
write(socket_fd, tmp_buf, len);
基于传统的 I/O 写入方式,write() 系统调用会触发 2 次上下文切换,1 次 CPU 拷贝和 1 次 DMA 拷贝,用户程序发送网络数据的流程如下:
(1)用户进程通过 write() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
(2)CPU 将用户缓冲区(user buffer)中的数据拷贝到内核空间(kernel space)的网络缓冲区(socket buffer)。
(3)CPU 利用 DMA 控制器将数据从网络缓冲区(socket buffer)拷贝到网卡进行数据传输。
(4)上下文从内核态(kernel space)切换回用户态(user space),write 系统调用执行返回。
内核空间和用户空间
在上述传统IO的示例中空间切换主要是用户空间和内核空间的切换。接下来我们来看下用户态和内核态之间是如何控制数据传输的。
物理内存和虚拟内存
由于操作系统的进程与进程之间的共享CPU和内存资源的,因此需要一套完整的内存管理机制防止进程之间内存泄漏的问题。为了更加有效管理内存并减少出错,现代操作系统提供了一种对主存的抽象概念,即是虚拟内存(Virtual Memory)。虚拟内存为每个进程提供了一个一致的、私有的地址空间,它让每个进程产生了一种自己在独享主存的错觉(每个进程拥有一片连续完整的内存空间)。
物理内存
物理内存(Physical memory)是相对于虚拟内存(Virtual Memory)而言的。物理内存指通过物理内存条而获得的内存空间,而虚拟内存则是指将硬盘的一块区域划分来作为内存。内存主要作用是在计算机运行时为操作系统和各种程序提供临时储存。
在应用中,自然是顾名思义,物理上,真实存在的插在主板内存槽上的内存条的容量的大小。
虚拟内存
虚拟内存是计算机系统内存管理的一种技术。 它使得应用程序认为它拥有连续的可用的内存(一个连续完整的地址空间)。
而实际上,虚拟内存通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换,加载到物理内存中来。
目前,大多数操作系统都使用了虚拟内存,如 Windows 系统的虚拟内存、Linux 系统的交换空间等等。
虚拟内存地址和用户进程紧密相关,一般来说不同进程里的同一个虚拟地址指向的物理地址是不一样的,所以离开进程谈虚拟内存没有任何意义。
每个进程所能使用的虚拟地址大小和 CPU 位数有关。在 32 位的系统上,虚拟地址空间大小是 2 ^ 32 = 4G,在 64位系统上,虚拟地址空间大小是 2 ^ 64= 2 ^ 34G,而实际的物理内存可能远远小于虚拟内存的大小。
每个用户进程维护了一个单独的页表(Page Table),虚拟内存和物理内存就是通过这个页表实现地址空间的映射的。
当进程执行一个程序时,需要先从内存中读取该进程的指令进行执行,获取指令时用到的就是虚拟地址。这个虚拟地址是程序链接时确定的(内核加载并初始化进程时会调整动态库的地址范围)。为了获取到实际的数据,CPU 需要将虚拟地址转换成物理地址,CPU 转换地址时需要用到进程的页表(Page Table),而页表(Page Table)里面的数据由操作系统维护。
其中页表(Page Table)可以简单的理解为单个内存映射(Memory Mapping)的链表(当然实际结构很复杂),里面的每个内存映射(Memory Mapping)都将一块虚拟地址映射到一个特定的地址空间(物理内存或者磁盘存储空间)。每个进程拥有自己的页表(Page Table),和其它进程的页表(Page Table)没有关系。
**用户进程申请并访问物理内存(或磁盘存储空间)**的过程总结如下:
(1)用户进程向操作系统发出内存申请请求;
(2)系统会检查进程的虚拟地址空间是否被用完,如果有剩余,给进程分配虚拟地址;
(3)系统为这块虚拟地址创建内存映射(Memory Mapping),并将它放进该进程的页表(Page Table);
(4)系统返回虚拟地址给用户进程,用户进程开始访问该虚拟地址;
(5)CPU 根据虚拟地址在此进程的页表(Page Table)中找到了相应的内存映射(Memory Mapping),但是这个内存映射(Memory Mapping)没有和物理内存关联,于是产生缺页中断;
(6)操作系统收到缺页中断后,分配真正的物理内存并将它关联到页表相应的内存映射(Memory Mapping)。中断处理完成后 CPU 就可以访问内存了;
(7)当然缺页中断不是每次都会发生,只有系统觉得有必要延迟分配内存的时候才用的着,也即很多时候在上面的第 3 步系统会分配真正的物理内存并和内存映射(Memory Mapping)进行关联。
在用户进程和物理内存(磁盘存储器)之间引入虚拟内存的优点如下:
- 地址空间:提供更大的地址空间,并且地址空间是连续的,使得程序编写、链接更加简单;
- 进程隔离:不同进程的虚拟地址之间没有关系,所以一个进程的操作不会对其它进程造成影响;
- 数据保护:每块虚拟内存都有相应的读写属性,这样就能保护程序的代码段不被修改,数据块不能被执行等,增加了系统的安全性;
- 内存映射:有了虚拟内存之后,可以直接映射磁盘上的文件(可执行文件或动态库)到虚拟地址空间。这样可以做到物理内存延时分配,只有在需要读相应的文件的时候,才将它真正的从磁盘上加载到内存中来,而在内存吃紧的时候又可以将这部分内存清空掉,提高物理内存利用效率,并且所有这些对应用程序是都透明的;
- 共享内存:比如动态库只需要在内存中存储一份,然后将它映射到不同进程的虚拟地址空间中,让进程觉得自己独占了这个文件。进程间的内存共享也可以通过映射同一块物理内存到进程的不同虚拟地址空间来实现共享;
- 物理内存管理:物理地址空间全部由操作系统管理,进程无法直接分配和回收,从而系统可以更好的利用内存,平衡进程间对内存的需求;
内核空间和用户空间、内核态与用户态
操作系统将内存(虚拟内存)划分为内核空间(Kernel-Space)和用户空间(User-Space),划分的目的是为了避免为了避免用户进程直接操作内核,保证内核安全。
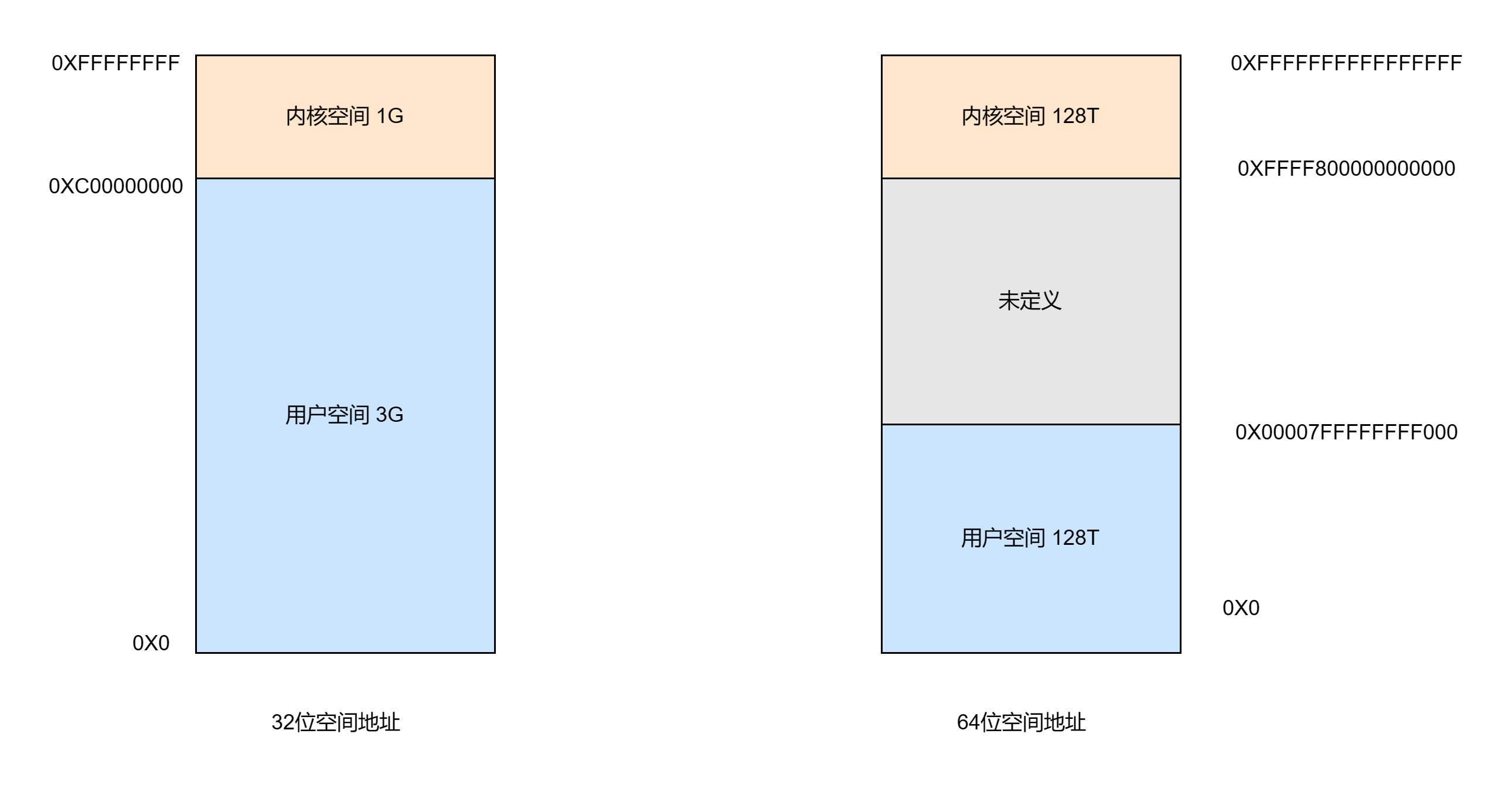
32 位系统的内核空间占用 1G,位于最高处,剩下的 3G 是用户空间;64 位系统的内核空间和用户空间都是 128T,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的。
操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内核空间,也有访问底层硬件设备的权限。内核空间总是驻留在内存中,它是为操作系统的内内核空间总是驻留在内存中,它是为操作系统的内核保留的,应用程序是不允许直接在内核空间区域进行读写,也是不容许直接调用内核代码定义的函数的。内核模块运行在内核空间,对应的进程处于内核态,内核态进程可以执行任意命令,调用系统的一切资源。
每个应用程序进程都有一个单独的用户空间,对应的进程处于用户态,用户态进程不能访问内核空间中的数据,也不能直接调用内核函数的。用户态进程只能执行简单的运算,不能直接调用系统资源。
从用户态切换到内核态可以通过以下三种方式:
(1)系统调用:其实系统调用本身就是中断,但是软件中断,跟硬中断不同
(2)异常:如果当前进程运行在用户态,如果这个时候发生了异常事件,就会触发切换。例如:缺页异常。
(3)外设中断:当外设完成用户的请求时,会向CPU发送中断信号。
在了解内核空间和用户空间、内核态和用户态后,接下来我们来看下用户态和内核态之间是如何传输数据。
示例: 当计算机A上的进程要把一个文件传输到计算机B的进程空间中,在当前的计算机系统架构下,它的I/O路径如下:
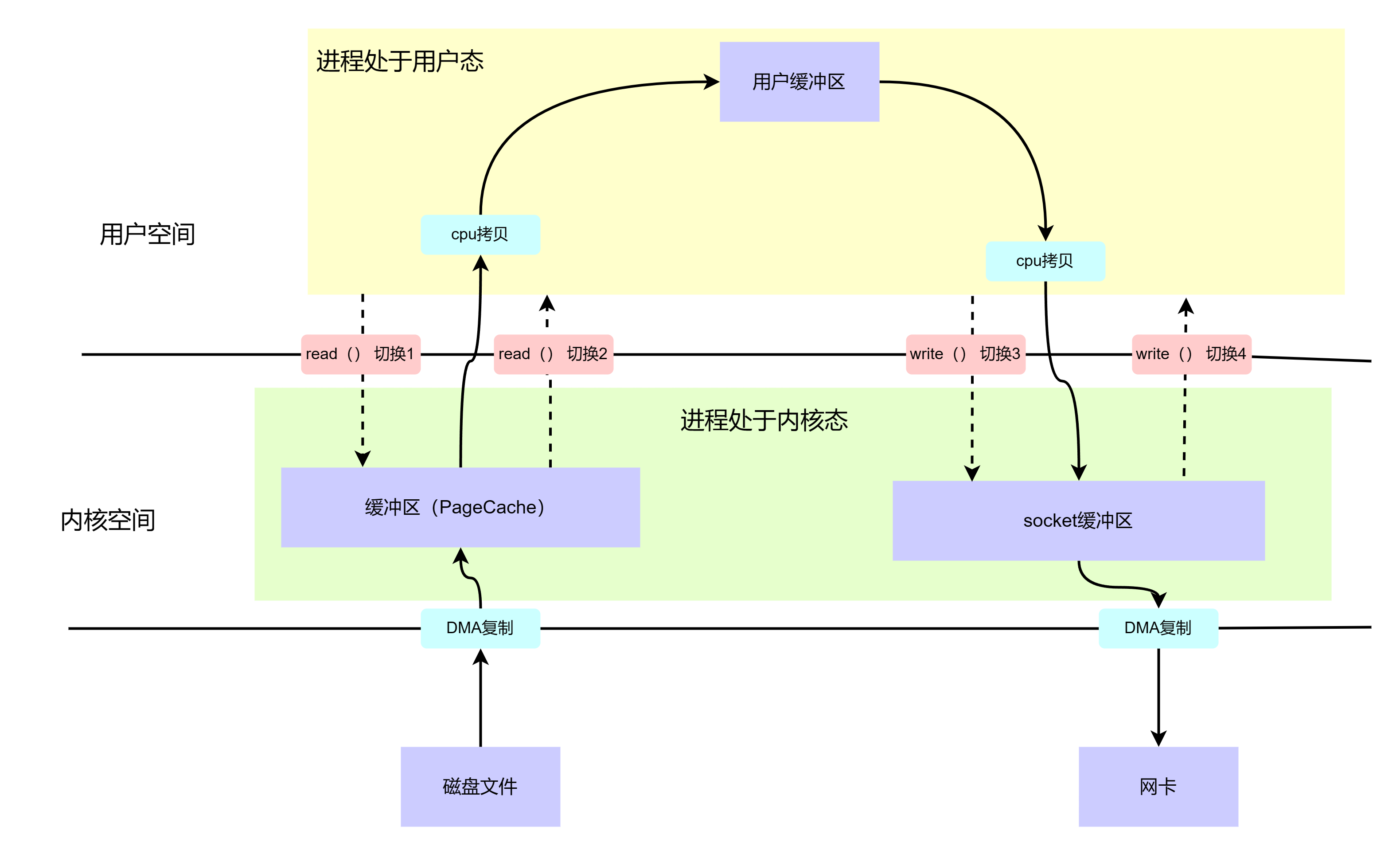
(1)计算机A的进程a先要通过系统调用Read(内核态)打开一个磁盘上的文件,这个时候就要把数据copy一次到内核态的PageCache中,进入了内核态;
(2)进程a负责将数据从内核空间的 Page Cache 搬运到用户空间的缓冲区,进入用户态;
(3)进程a负责将数据从用户空间的缓冲区搬运到内核空间的 Socket(资源由内核管控) 缓冲区中,进入内核态。
(4)进程a负责将数据从内核空间的 Socket 缓冲区搬运到的网络中,进入用户态;
在这4个步骤中,由于用户态无法控制磁盘和网路资源,需要在用户态和内核态之间来回的切换,一个发送文件的过程产生了4次上下文切换:
(1)read 系统调用读磁盘上的文件时:用户态切换到内核态;
(2)read 系统调用完毕:内核态切换回用户态;
(3)write 系统调用写到socket时:用户态切换到内核态;
(4)write 系统调用完毕:内核态切换回用户态。
CPU 全程负责内存内的数据拷贝,参考磁盘介质的读写性能,这个操作是可以接受的,但是如果要让内存的数据和磁盘来回拷贝,这个时间消耗是非常巨大,因为磁盘、网卡的速度远小于内存,内存又远远小于 CPU;所以4 次 copy + 4 次上下文切换,代价太高。这个时候零拷贝技术就尤其重要了。
接下来我们来看下什么是零拷贝,以及可以用哪些技术来实现零拷贝。
什么是零拷贝
零拷贝(zero-copy)技术指在计算机执行操作时,CPU 不需要先将数据从一个内存区域复制到另一个内存区域,从而可以减少上下文切换以及 CPU 的拷贝时间。它的作用是在数据报从网络设备到用户程序空间传递的过程中,减少数据拷贝次数,减少系统调用,实现 CPU 的零参与,彻底消除 CPU 在这方面的负载。实现零拷贝用到的最主要技术是 DMA 数据传输技术和内存区域映射技术。
如下图所示:
传统的网络数据报处理,需要经过网络设备到操作系统内存空间,系统内存空间到用户应用程序空间这两次拷贝,同时还需要经历用户向系统发出的系统调用。
零拷贝技术则首先利用DMA技术将网络数据报直接传递到系统内核预先分配的地址空间中,避免CPU的参与;同时,将系统内核中存储数据报的内存区域映射到检测程序的应用程序空间(还有一种方式是在用户空间建立一缓存,并将其映射到内核空间,类似于linux系统下的kiobuf技术),检测程序直接对这块内存进行访问,从而减少了系统内核向用户空间的内存拷贝,同时减少了系统调用的开销,实现了真正的“零拷贝”。
简单来说,零拷贝就是一种避免CPU将数据从一块存储考别到另一块存储的技术。
针对操作系统中的设备驱动程序、文件系统以及网络协议堆栈而出现的各种零拷贝技术极大地提升了特定应用程序的性能,并且使得这些应用程序可以更加有效地利用系统资源。这种性能的提升就是通过在数据拷贝进行的同时,允许 CPU 执行其他的任务来实现的。
零拷贝技术可以减少数据拷贝和共享总线操作的次数,消除传输数据在存储器之间不必要的中间拷贝次数,从而有效地提高数据传输效率。零拷贝技术减少了用户应用程序地址空间和操作系统内核地址空间之间因为上下文切换而带来的开销。
进行大量的数据拷贝操作其实是一件简单的任务,从操作系统的角度来说,如果 CPU 一直被占用着去执行这项简单的任务,那么这将会是很浪费资源的;如果有其他比较简单的系统部件可以代劳这件事情,从而使得 CPU 解脱出来可以做别的事情,那么系统资源的利用则会更加有效。
对于高速网络来说,零拷贝技术是非常重要的。这是因为高速网络的网络链接能力与 CPU 的处理能力接近,甚至会超过 CPU 的处理能力。
而零拷贝技术在不同的层面有不同的含义,主要是在以下三个层面
(1)java堆内和堆外之间的零拷贝
(2)数据在用户空间和内核空间的零拷贝
(3)处理分段的数据,拼接、切片的零拷贝
java堆内和堆外之间的零拷贝
我们先来回顾以下liunx进程内存布局,下图是一张经典的linux进程内存布局图:
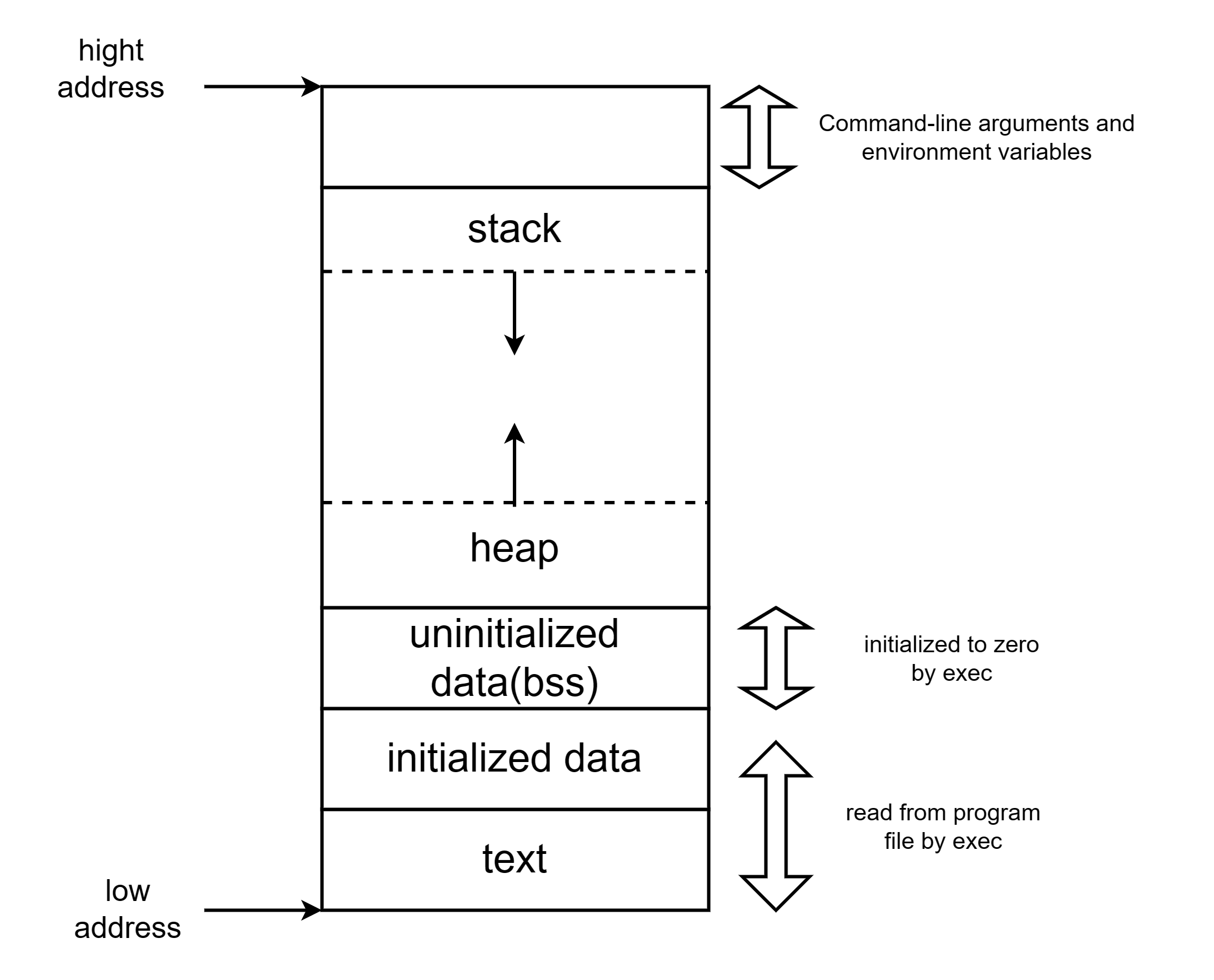
JVM虚拟机是由C++语言编写的,对操作系统来说只是一个普通的C++程序,所以除了Java的内存模型外,JVM整体使用的内存也符合C语言的堆栈区分配。
对于JVM的堆我们暂且叫做:Java Heap,之外的堆叫做C Heap。
对应的,ByteBuffer有allocate方法用来申请堆内和堆外缓冲区。
java heap 和C heap 差别不大,两个都是由malloc申请来的内存,可以理解为Java Heap属于C Heap的一部分,所以两者的读写效率肯定没什么差别。
但Java Heap有一个很重要的特性就是GC,在堆内GC的时候可能会移动其中的对象。这点很关键,因为这意味着我们的Java对象的内存地址并不是固定的。
那么,为什么堆内外之间发生数据拷贝呢?
这是由于jvm只是一个普通的用户程序,所以涉及到系统功能是jvm必须把功能委托给操作系统提供的系统调用执行。系统调用就涉及到IO的read函数和write函数,我们来看下:
由于JVM GC其间会移动对象的地址,包括byte[],而内核无法感知到内存的移动,很可能会导致数据错误。这是因为JNI方法访问的内存区域是一个已经确定了的内存区域地质,那么该内存地址指向的是Java堆内内存的话,那么如果在操作系统正在访问这个内存地址的时候,Java在这个时候进行了GC操作,而GC操作会涉及到数据的移动操作。
GC经常会进行先标志再压缩的操作。即将可回收的空间做标志,然后清空标志位置的内存,然后会进行一个压缩,压缩就会涉及到对象的移动,移动的目的是为了腾出一块更加完整、连续的内存空间,以容纳更大的新对象,数据的移动会使对象的地址发生变化。
所以我们在以byte[]的形式写入数据时必须先把数据拷贝到不受JVM堆控制的堆外内存中,这部分就是我们说的C heap,而DirectByteBuffer正处于这片区域。
同样的,read的时候,我们也要保证在系统往缓冲区写入的时候我们不能gc移动内存,否则数据不知道写到了哪里,所以也会导致拷贝发生。
堆内外之间发生数据拷贝减少的方案就是直接使用堆外内存,如DirectByteBuffer。这种方式是直接在对外分配一个内存(即,native memory)来存储数,程序通过JNI直接将数据读/写到堆外内存中。
因为数据直接写入到堆外内存中,所以这种方式就不会再在JVM管控的堆内再分配内存来存储数据
了,也就不存在堆内内存和堆外内存数据拷贝的操作了。
这样在进行I/O操作时,只需要将这个堆外内存地址传给JNI的I/O的函数就好了。
数据在用户空间和内核空间的零拷贝
为什么要发生拷贝
用户空间是绝对无法直接访问内核空间的,但是内核空间可以直接访问用户空间或者说任意一块物理内存。
系统调用会涉及到特权等级的切换(由用户态到内核态),内核需要为其开辟新的堆栈空间,然后将参数复制到内核堆栈,交给内核处理。参数的复制很简单也很好理解,因为两者不能共享栈,复制速度也都很快,但为什么要参数中指针指向的缓冲区数据也要复制呢?
这块儿其实很复杂,和安全性有关,但主要的原因应该是:用户空间的内存可能并不指向物理内存,直接访问时可能产生缺页异常。但是Linux内核禁止在中断时产生缺页异常,否则会产生打印oops错误。这就要求我们用户的缓冲区数据必须要存在内存中,而这个实际上很难控制,所以就会直接把数据复制到内核缓冲区中。
零拷贝技术分类
零拷贝技术的发展很多样化,现有的零拷贝技术种类也非常多,而当前并没有一个适合于所有场景的零拷贝技术的出现。针对这些零拷贝技术所适用的不同场景对它们进行了划分。概括起来,Linux 中的零拷贝技术主要有下面这三种:
(1)直接I/O:对于这种数据传输方式来说,应用程序可以直接访问硬件存储,操作系统内核只是辅助数据传输:这类零拷贝技术针对的是操作系统内核并不需要对数据进行直接处理的情况,数据可以在应用程序地址空间的缓冲区和磁盘之间直接进行传输,完全不需要 Linux 操作系统内核提供的页缓存的支持。
(2)较少数据拷贝次数:在数据传输的过程中,避免数据在操作系统内核地址空间的缓冲区和用户应用程序地址空间的缓冲区之间进行拷贝。有的时候,应用程序在数据进行传输的过程中不需要对数据进行访问,那么,将数据从 Linux 的页缓存拷贝到用户进程的缓冲区中就可以完全避免,传输的数据在页缓存中就可以得到处理。在某些特殊的情况下,这种零拷贝技术可以获得较好的性能。常用的系统调用技术 mmap(),sendfile() 以及 splice()。
(3)写时复制技术:对数据在 Linux 的页缓存和用户进程的缓冲区之间的传输过程进行优化。该零拷贝技术侧重于灵活地处理数据在用户进程的缓冲区和操作系统的页缓存之间的拷贝操作。这种方法延续了传统的通信方式,但是更加灵活。
(1)和(2)的目的主要是为了避免应用程序地址空间和操作系统内核地址空间之间的缓冲区拷贝操作。这两个拷贝技术通常适用在某些特殊的情况下,比如要传送的数据不需要经过操作系统内核的处理 或者不需要经过应用程序的处理。
零拷贝技术(3)继承了传统的应用程序地址空间和操作系统内核地址空间之间数据传输的概念,进而针对数据传输本身进行优化。其目的是为了可以有效地改善数据在用户地址空间和操作系统内核地址空间之间传递的效率。
linux的零拷贝技术
从传统io方式我们可以得知:如果应用程序不对数据做修改,从内核缓冲区到用户缓冲区,再从用户缓冲区到内核缓冲区。两次数据拷贝都需要CPU的参与,并且涉及用户态与内核态的多次切换,加重了CPU负担。
我们需要降低冗余数据拷贝、释放CPU,就需要零拷贝技术(Zero-Copy)。
零拷贝技术的几个实现手段包括:
mmap
mmap是Linux提供的一种内存映射文件的机制,它实现了将内核中读缓冲区地址与用户空间缓冲区地址进行映射,从而实现内核缓冲区与用户缓冲区的共享。
使用 mmap 的目的是将内核中读缓冲区(read buffer)的地址与用户空间的缓冲区(user buffer)进行映射,从而实现内核缓冲区与应用程序内存的共享,省去了将数据从内核读缓冲区(read buffer)拷贝到用户缓冲区(user buffer)的过程,然而内核读缓冲区(read buffer)仍需将数据到内核写缓冲区(socket buffer),大致的流程如下图所示:
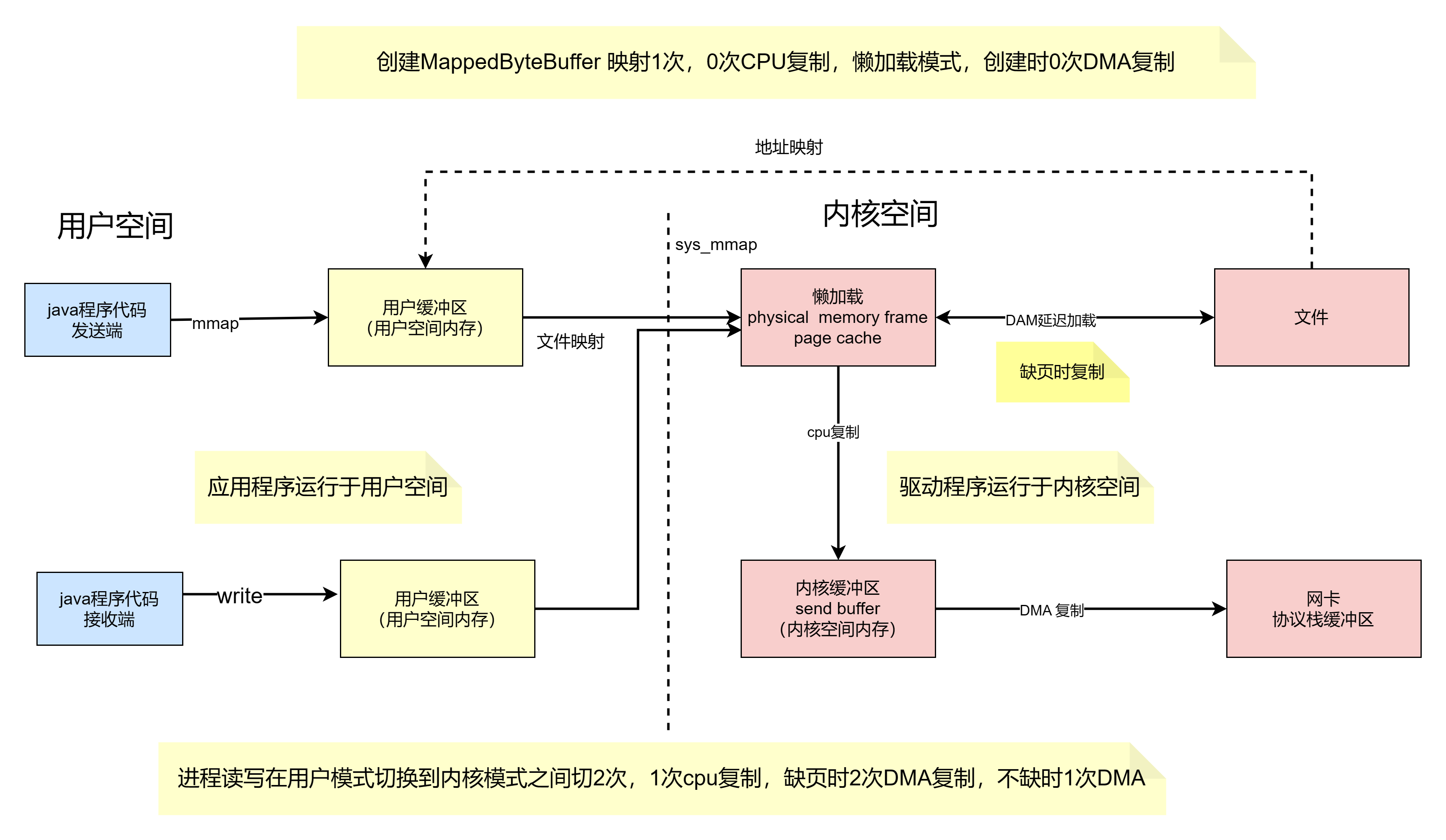
基于 mmap + write 系统调用的零拷贝方式,整个拷贝过程会发生 4 次上下文切换,1 次 CPU 拷贝和 2 次 DMA 拷贝,用户程序读写数据的流程如下:
(1)用户进程通过 mmap() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
(2)将用户进程的内核空间的读缓冲区(read buffer)与用户空间的缓存区(user buffer)进行内存地址映射。
(3)CPU利用DMA控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
(4)上下文从内核态(kernel space)切换回用户态(user space),mmap 系统调用执行返回。
(5)用户进程通过 write() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
(6)CPU将读缓冲区(read buffer)中的数据拷贝到的网络缓冲区(socket buffer)。
(7)CPU利用DMA控制器将数据从网络缓冲区(socket buffer)拷贝到网卡进行数据传输。
(8)上下文从内核态(kernel space)切换回用户态(user space),write 系统调用执行返回。
mmap 主要的用处是提高 I/O 性能,特别是针对大文件。对于小文件,内存映射文件反而会导致碎片空间的浪费,因为内存映射总是要对齐页边界,最小单位是 4 KB,一个 5 KB 的文件将会映射占用 8 KB 内存,也就会浪费 3 KB 内存。
mmap 的拷贝虽然减少了 1 次拷贝,提升了效率,但也存在一些隐藏的问题。当 mmap 一个文件时,如果这个文件被另一个进程所截获,那么 write 系统调用会因为访问非法地址被 SIGBUS 信号终止,SIGBUS 默认会杀死进程并产生一个 coredump,服务器可能因此被终止。。
sendfile
sendfile系统调用是在 Linux 内核2.1版本中被引入,它建立了两个文件之间的传输通道。
sendfile(socket, file, len);
sendfile方式只使用一个函数就可以完成之前的read+write 和 mmap+write的功能,通过 sendfile 系统调用,数据可以直接在内核空间内部进行 I/O 传输,从而省去了数据在用户空间和内核空间之间的来回拷贝。
与 mmap 内存映射方式不同的是, sendfile 调用中 I/O 数据对用户空间是完全不可见的。也就是说,这是一次完全意义上的数据传输过程。

基于 sendfile 系统调用的零拷贝方式,整个拷贝过程会发生 2 次上下文切换,1 次 CPU 拷贝和 2 次 DMA 拷贝,用户程序读写数据的流程如下:
(1)用户进程通过 sendfile() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
(2)CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
(3)CPU 将读缓冲区(read buffer)中的数据拷贝到的网络缓冲区(socket buffer)。
(4)CPU 利用 DMA 控制器将数据从网络缓冲区(socket buffer)拷贝到网卡进行数据传输。
(5)上下文从内核态(kernel space)切换回用户态(user space),sendfile 系统调用执行返回。
相比较于 mmap 内存映射的方式,sendfile 少了 2 次上下文切换,但是仍然有 1 次 CPU 拷贝操作。sendfile 存在的问题是用户程序不能对数据进行修改,而只是单纯地完成了一次数据传输过程。
sendfile+DMA收集
Linux2.4内核进行了优化,提供了gather操作,这个操作可以把最后一次CPU Copy去除,
Linux Kernel 2.4 改进了 sendfile(),但是调用接口没有变化。
其原理是在内核空间Read Buffer和Socket Buffer不做数据复制,而是将Read Buffer的内存地址、偏移量记录到相应的Socket Buffer中,这样就不需要复制(其实本质就是和虚拟内存的解决方法思路一样,就是内存地址的记录)。
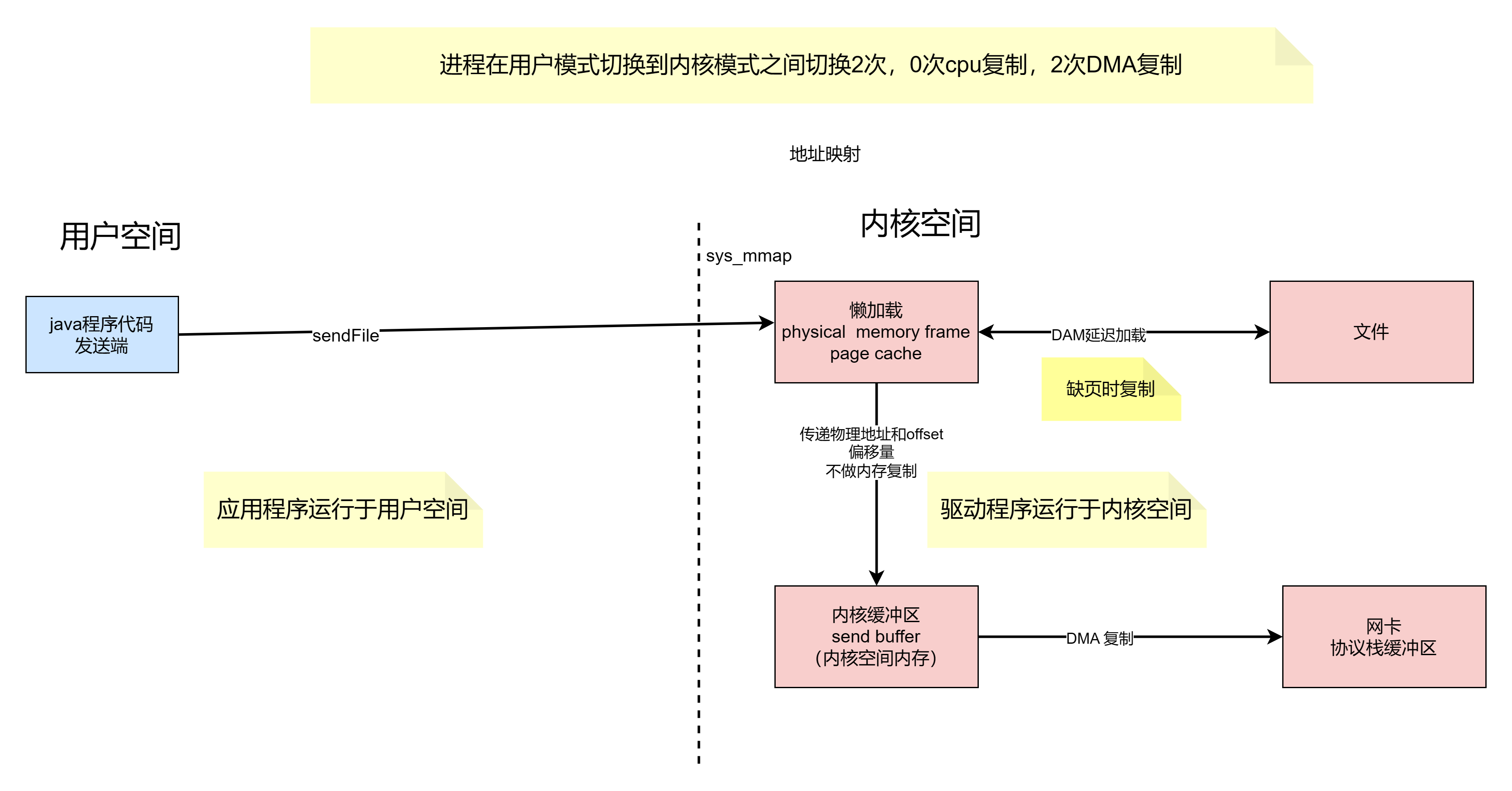
基于 sendfile + DMA gather copy 系统调用的零拷贝方式,整个拷贝过程会发生 2 次上下文切换、0 次 CPU 拷贝以及 2 次 DMA 拷贝,用户程序读写数据的流程如下:
(1)用户进程通过 sendfile() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
(2)CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
(3)CPU 把读缓冲区(read buffer)的文件描述符(file descriptor)和数据长度拷贝到网络缓冲区(socket buffer)。
(4)基于已拷贝的文件描述符(file descriptor)和数据长度,CPU 利用 DMA 控制器的 gather/scatter 操作直接批量地将数据从内核的读缓冲区(read buffer)拷贝到网卡进行数据传输。
(5)上下文从内核态(kernel space)切换回用户态(user space),sendfile 系统调用执行返回。
sendfile + DMA gather copy 拷贝方式同样存在用户程序不能对数据进行修改的问题,而且本身需要硬件的支持,它只适用于将数据从文件拷贝到 socket 套接字上的传输过程。
在许多 http server 中,都引入了 sendfile 的机制,如 nginx、lighttpd 等,它们正是利用 sendfile() 这个特性来实现高性能的文件发送的。kafka也使用 sendfile() 发送文件。
splice 方式
由于sendfile 只适用于将数据从文件拷贝到 socket 套接字上,同时需要硬件的支持,这也限定了它的使用范围。
splice系统调用在Linux 在 2.6 版本引入的,其不需要硬件支持,并且不再限定于socket上,实现两个普通文件之间的数据零拷贝。
splice 系统调用可以在内核空间的读缓冲区(read buffer)和网络缓冲区(socket buffer)之间建立管道(pipeline),从而避免了两者之间的 CPU 拷贝操作。
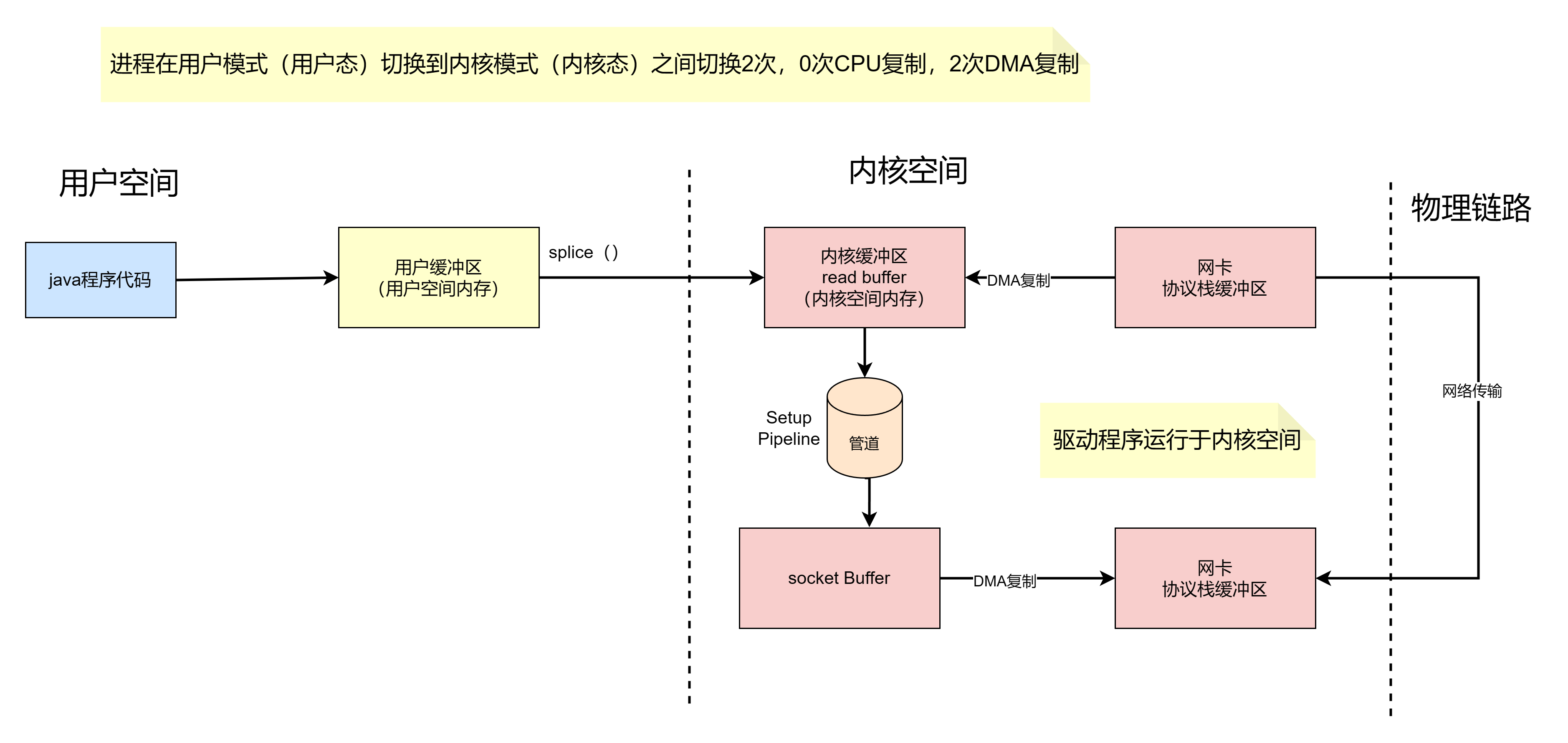
基于 splice 系统调用的零拷贝方式,整个拷贝过程会发生 2 次上下文切换,0 次 CPU 拷贝以及 2 次 DMA 拷贝,用户程序读写数据的流程如下
(1)用户进程通过 splice() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
(2)CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
(3)CPU 在内核空间的读缓冲区(read buffer)和网络缓冲区(socket buffer)之间建立管道(pipeline)。
(4)CPU 利用 DMA 控制器将数据从网络缓冲区(socket buffer)拷贝到网卡进行数据传输。
(5)上下文从内核态(kernel space)切换回用户态(user space),splice 系统调用执行返回。
splice 拷贝方式也同样存在用户程序不能对数据进行修改的问题。除此之外,它使用了 Linux 的管道缓冲机制,可以用于任意两个文件描述符中传输数据,但是它的两个文件描述符参数中有一个必须是管道设备。
linux 零拷贝对比
无论是传统I/O拷贝方式还是引入零拷贝的方式,2次DMA Copy是都不少了的。因为2次DMA都是依赖硬件完成的。
| 拷贝方式 | cpu拷贝 | DMA拷贝 | 系统调用 | 上下文切换 |
|---|---|---|---|---|
| 传统方式(read+write) | 2 | 2 | read/write | 4 |
| 内存映射(mmap+write) | 1 | 2 | mmap/write | 4 |
| sendFile | 1 | 2 | sendfile | 2 |
| sendFile+DMA gather copy | 0 | 2 | sendfile | 2 |
| splice | 0 | 2 | splice | 2 |
java 零拷贝实现
Nio 零复制实现
在java NIO 中的通道(Channel)就相当于操作系统的内核空间(kernel space)的缓冲区,而缓冲区(Buffer)对应的相当于操作系统的用户空间(user space)中的用户缓冲区(user buffer)。
- 通道(Channel) 是双向传输的,它即可能是读缓冲区(read buffer),也可能是网络缓冲区(socket buffer)。
- 缓冲区(Buffer)分为堆内存(HeapBuffer)和堆外内存(DirectBuffer),这是通过 malloc() 分配出来的用户态内存。
直接内存(DirectBuffer)在使用后需要应用程序手动回收,而堆内存(HeapBuffer)的数据在 GC 时可能会被自动回收。因此,在使用 HeapBuffer 读写数据时,为了避免缓冲区数据因为 GC 而丢失,NIO 会先把 HeapBuffer 内部的数据拷贝到一个临时的 DirectBuffer 中的本地内存(native memory)。最后,将临时生成的 DirectBuffer 内部的数据的内存地址传给 I/O 调用函数,这样就避免了再去访问 Java 对象处理 I/O 读写。
MappedByteBuffer
MappedByteBuffer 是 NIO 基于内存映射(mmap)这种零拷贝方式的提供的一种实现,它继承自 ByteBuffer。
FileChannel 定义了一个 map() 方法,它可以把一个文件从 position 位置开始的 size 大小的区域映射为内存映像文件。抽象方法 map() 方法在 FileChannel 中的定义如下:
public abstract MappedByteBuffer map(MapMode mode,long position, long size) throws IOException;
利用 MappedByteBuffer 对文件进行读写的使用示例如下:
(1) 写文件数据
打开文件通道 fileChannel 并提供读权限、写权限和数据清空权限,通过 fileChannel 映射到一个可写的内存缓冲区 mappedByteBuffer,将目标数据写入 mappedByteBuffer,通过 force() 方法把缓冲区更改的内容强制写入本地文件。
@Test
public void writeToFileByMappedByteBuffer() {
Path path = Paths.get(getClass().getResource(FILE_NAME).getPath());
byte[] bytes = CONTENT.getBytes(Charset.forName(CHARSET));
try (FileChannel fileChannel = FileChannel.open(path, StandardOpenOption.READ,StandardOpenOption.WRITE, StandardOpenOption.TRUNCATE_EXISTING)) {
MappedByteBuffer mappedByteBuffer = fileChannel.map(READ_WRITE, 0, bytes.length);
if (mappedByteBuffer != null) {
mappedByteBuffer.put(bytes);
mappedByteBuffer.force();
}
} catch (IOException e) {
e.printStackTrace();
}
}
(2)读文件数据
打开文件通道 fileChannel 并提供只读权限,通过 fileChannel 映射到一个只可读的内存缓冲区 mappedByteBuffer,读取 mappedByteBuffer 中的字节数组即可得到文件数据。
@Test
public void readFromFileByMappedByteBuffer() {
Path path = Paths.get(getClass().getResource(FILE_NAME).getPath());
int length = CONTENT.getBytes(Charset.forName(CHARSET)).length;
try (FileChannel fileChannel = FileChannel.open(path, StandardOpenOption.READ)) {
MappedByteBuffer mappedByteBuffer = fileChannel.map(READ_ONLY, 0, length);
if (mappedByteBuffer != null) {
byte[] bytes = new byte[length];
mappedByteBuffer.get(bytes);
String content = new String(bytes, StandardCharsets.UTF_8);
}
} catch (IOException e) {
e.printStackTrace();
}
}
map()方法由子类 sun.nio.ch.FileChannelImpl.java 实现,下面是和内存映射相关的核心代码:
public MappedByteBuffer map(MapMode mode, long position, long size)
throws IOException
{
try {
......
pagePosition = (int)(position % allocationGranularity);
long mapPosition = position - pagePosition;
mapSize = size + pagePosition;
try {
// If map0 did not throw an exception, the address is valid
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError x) {
// An OutOfMemoryError may indicate that we've exhausted
// memory so force gc and re-attempt map
System.gc();
try {
Thread.sleep(100);
} catch (InterruptedException y) {
Thread.currentThread().interrupt();
}
try {
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError y) {
// After a second OOME, fail
throw new IOException("Map failed", y);
}
}
} // synchronized
// On Windows, and potentially other platforms, we need an open
// file descriptor for some mapping operations.
FileDescriptor mfd;
try {
mfd = nd.duplicateForMapping(fd);
} catch (IOException ioe) {
unmap0(addr, mapSize);
throw ioe;
}
assert (IOStatus.checkAll(addr));
assert (addr % allocationGranularity == 0);
int isize = (int)size;
Unmapper um = new Unmapper(addr, mapSize, isize, mfd);
if ((!writable) || (imode == MAP_RO)) {
return Util.newMappedByteBufferR(isize,
addr + pagePosition,
mfd,
um);
} else {
return Util.newMappedByteBuffer(isize,
addr + pagePosition,
mfd,
um);
}
} finally {
threads.remove(ti);
endBlocking(IOStatus.checkAll(addr));
}
}
map() 方法通过本地方法 map0() 为文件分配一块虚拟内存,map0() 函数通过 mmap64() 函数对 Linux 底层内核发出内存映射的调用,作为它的内存映射区域,然后返回这块内存映射区域的起始地址。
文件映射需要在 Java 堆中创建一个 MappedByteBuffer 的实例。如果第一次文件映射导致 OOM,则手动触发垃圾回收,休眠 100ms 后再尝试映射,如果失败则抛出异常。
通过 Util 的 newMappedByteBuffer (可读可写)方法或者 newMappedByteBufferR(仅读) 方法方法反射创建一个 DirectByteBuffer 实例,其中 DirectByteBuffer 是 MappedByteBuffer 的子类。
map() 方法返回的是内存映射区域的起始地址,通过(起始地址 + 偏移量)就可以获取指定内存的数据。这样一定程度上替代了 read() 或 write() 方法,底层直接采用 sun.misc.Unsafe 类的 getByte() 和 putByte() 方法对数据进行读写。
MappedByteBuffer 的特点和不足之处:
(1)MappedByteBuffer 使用是堆外的虚拟内存,因此分配(map)的内存大小不受 JVM 的 -Xmx 参数限制,但是也是有大小限制的。
(2)如果当文件超出 Integer.MAX_VALUE 字节限制时,可以通过 position 参数重新 map 文件后面的内容。
(3)MappedByteBuffer 在处理大文件时性能的确很高,但也存内存占用、文件关闭不确定等问题,被其打开的文件只有在垃圾回收的才会被关闭,而且这个时间点是不确定的。
(4)MappedByteBuffer 提供了文件映射内存的 mmap() 方法,也提供了释放映射内存的 unmap() 方法。然而 unmap() 是 FileChannelImpl 中的私有方法,无法直接显示调用。因此,用户程序需要通过 Java 反射的调用 sun.misc.Cleaner 类的 clean() 方法手动释放映射占用的内存区域。
DirectByteBuffer
DirectByteBuffer 的对象引用位于 Java 内存模型的堆里面,JVM 可以对DirectByteBuffer 的对象进行内存分配和回收管理,一般使用 DirectByteBuffer 的静态方法 allocateDirect() 创建 DirectByteBuffer 实例并分配内存。
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
DirectByteBuffer 内部的字节缓冲区位在于堆外的(用户态)直接内存,它是通过 Unsafe 的本地方法 allocateMemory() 进行内存分配,底层调用的是操作系统的 malloc() 函数。
DirectByteBuffer(int cap) { // package-private
//step1:根据页对齐和pageSize来确定本次的要分配内存实际大小
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
//step2:实际分配内存,并记录分配的直接内存大小
base = UNSAFE.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
//step3:声明一个cleaner对象用于清理DirectBuffer内存
UNSAFE.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
//清理对象
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
初始化 DirectByteBuffer 时还会创建一个 Deallocator 线程,并通过 Cleaner 的 freeMemory() 方法来对直接内存进行回收操作,freeMemory() 底层调用的是操作系统的 free() 函数。
由于使用 DirectByteBuffer 分配的是系统本地的内存,不在 JVM 的管控范围之内,因此直接内存的回收和堆内存的回收不同,直接内存如果使用不当,很容易造成 OutOfMemoryError。
DirectByteBuffer 是 MappedByteBuffer 的具体实现类。实际上,Util.newMappedByteBuffer() 方法通过反射机制获取 DirectByteBuffer 的构造器,然后创建一个 DirectByteBuffer 的实例,对应的是一个单独用于内存映射的构造方法:
// For duplicates and slices
//
DirectByteBuffer(DirectBuffer db, // package-private
int mark, int pos, int lim, int cap,
int off)
{
super(mark, pos, lim, cap);
address = db.address() + off;
cleaner = null;
att = db;
}
DirectByteBuffer允许分配操作系统的直接内存以外,其本身也具有文件内存映射的功能。DirectByteBuffer 在 MappedByteBuffer 的基础上提供了内存映像文件的随机读取 get() 和写入 write() 的操作。
(1)内存映像文件的随机读操作
public byte get() {
return ((unsafe.getByte(ix(nextGetIndex()))));
}
public byte get(int i) {
return ((unsafe.getByte(ix(checkIndex(i)))));
}
(2)内存映像文件的随机写操作
public ByteBuffer put(byte x) {
unsafe.putByte(ix(nextPutIndex()), ((x)));
return this;
}
public ByteBuffer put(int i, byte x) {
unsafe.putByte(ix(checkIndex(i)), ((x)));
return this;
}
内存映像文件的随机读写都是借助 ix() 方法实现定位的, ix() 方法通过内存映射空间的内存首地址(address)和给定偏移量 i 计算出指针地址,然后由 unsafe 类的 get() 和 put() 方法和对指针指向的数据进行读取或写入。
private long ix(int i) {
return address + ((long)i << 0);
}
FileChannel
FileChannel 是一个用于文件读写、映射和操作的通道,同时它在并发环境下是线程安全的,基于 FileInputStream、FileOutputStream 或者 RandomAccessFile 的 getChannel() 方法可以创建并打开一个文件通道。FileChannel 定义了
transferFrom() 和 transferTo() 两个抽象方法,它通过在通道和通道之间建立连接实现数据传输的。
- transferTo():通过 FileChannel 把文件里面的源数据写入一个WritableByteChannel 的目的通道。
- transferFrom():把一个源通道 ReadableByteChannel 中的数据读取到当前 FileChannel 的文件里面。
对于 transferTo() 方法而言,目的通道 toChannel 可以是任意的单向字节写通道 WritableByteChannel;
而对于 transferFrom() 方法而言,源通道 fromChannel 可以是任意的单向字节读通道 ReadableByteChannel。
其中,FileChannel、SocketChannel 和 DatagramChannel 等通道实现了 WritableByteChannel 和 ReadableByteChannel 接口,都是同时支持读写的双向通道。
transferTo() 和 transferFrom() 方法是 java.nio.channels.FileChannel 的抽象方法,由子类 sun.nio.ch.FileChannelImpl.java 实现。transferTo() 和 transferFrom() 底层都是基于 sendfile 实现数据传输的,其中 FileChannelImpl.java 定义了 3 个常量,用于标示当前操作系统的内核是否支持 sendfile 以及 sendfile 的相关特性。
//用于标记当前的系统内核是否支持 sendfile() 调用,默认为 true
private static volatile boolean transferSupported = true;
//用于标记当前的系统内核是否支持文件描述符(fd)基于管道(pipe)的 sendfile() 调用,默认为 true
private static volatile boolean pipeSupported = true;
//用于标记当前的系统内核是否支持文件描述符(fd)基于文件(file)的 sendfile() 调用,默认为 true
private static volatile boolean fileSupported = true;
transferTo() 的源码实现如下:
public long transferTo(long position, long count, WritableByteChannel target)
throws IOException {
// 计算文件的大小
long sz = size();
// 校验起始位置
if (position > sz)
return 0;
int icount = (int)Math.min(count, Integer.MAX_VALUE);
// 校验偏移量
if ((sz - position) < icount)
icount = (int)(sz - position);
long n;
if ((n = transferToDirectly(position, icount, target)) >= 0)
return n;
if ((n = transferToTrustedChannel(position, icount, target)) >= 0)
return n;
return transferToArbitraryChannel(position, icount, target);
}
FileChannelImpl 首先执行 transferToDirectly() 方法,以 sendfile 的零拷贝方式尝试数据拷贝。如果系统内核不支持 sendfile,进一步执行 transferToTrustedChannel() 方法,以 mmap 的零拷贝方式进行内存映射,这种情况下目的通道必须是 FileChannelImpl 或者 SelChImpl 类型。如果以上两步都失败了,则执行 transferToArbitraryChannel() 方法,基于传统的 I/O 方式完成读写,具体步骤是初始化一个临时的 DirectBuffer,将源通道 FileChannel 的数据读取到 DirectBuffer,再写入目的通道 WritableByteChannel 里面。
transferToDirectly() 方法的实现,也就是 transferTo() 通过 sendfile 实现零拷贝的精髓所在,采用的是SendFile +DMA收集的方式实现零复制的。可以看到,transferToDirectlyInternal() 方法先获取到目的通道 WritableByteChannel 的文件描述符 targetFD,获取同步锁然后执行 transferToDirectlyInternal() 方法。
private long transferToDirectly(long position, int icount, WritableByteChannel target)
throws IOException {
// 省略从target获取targetFD的过程
if (nd.transferToDirectlyNeedsPositionLock()) {
synchronized (positionLock) {
long pos = position();
try {
return transferToDirectlyInternal(position, icount,
target, targetFD);
} finally {
position(pos);
}
}
} else {
return transferToDirectlyInternal(position, icount, target, targetFD);
}
}
最终由 transferToDirectlyInternal() 调用本地方法 transferTo0() ,尝试以 sendfile 的方式进行数据传输。如果系统内核完全不支持 sendfile,比如 Windows 操作系统,则返回 UNSUPPORTED 并把 transferSupported 标识为 false。如果系统内核不支持 sendfile 的一些特性,比如说低版本的 Linux 内核不支持 DMA gather copy 操作,则返回 UNSUPPORTED_CASE 并把 pipeSupported 或者 fileSupported 标识为 false。
private long transferToDirectlyInternal(long position, int icount,
WritableByteChannel target,
FileDescriptor targetFD) throws IOException {
assert !nd.transferToDirectlyNeedsPositionLock() ||
Thread.holdsLock(positionLock);
long n = -1;
int ti = -1;
try {
begin();
ti = threads.add();
if (!isOpen())
return -1;
do {
n = transferTo0(fd, position, icount, targetFD);
} while ((n == IOStatus.INTERRUPTED) && isOpen());
if (n == IOStatus.UNSUPPORTED_CASE) {
if (target instanceof SinkChannelImpl)
pipeSupported = false;
if (target instanceof FileChannelImpl)
fileSupported = false;
return IOStatus.UNSUPPORTED_CASE;
}
if (n == IOStatus.UNSUPPORTED) {
transferSupported = false;
return IOStatus.UNSUPPORTED;
}
return IOStatus.normalize(n);
} finally {
threads.remove(ti);
end (n > -1);
}
}
本地方法(native method)transferTo0() 通过 JNI(Java Native Interface)调用底层 C 的函数;对 Linux、Solaris 以及 Apple 系统而言,transferTo0() 函数底层会执行 sendfile64 这个系统调用完成零拷贝操作。
netty的零复制实现
大部分的场景下,Netty 的接收和发送 ByteBuffer 的过程中,一般来说会使用直接内存进行 Socket 通道读写,使用 JV M 的堆内存进行业务处理,会涉及到直接内存、堆内存之间的数据复制。但是,内存的数据复制,其实是效率非常低的。
NettyNetty提供了多种方法,帮助应用提供了多种方法,帮助应用程序减少内存的复制。程序减少内存的复制。主要是一下五方面:
(1)Netty 提供 CompositeByteBuf 组合缓冲区类 , 可以将多个 ByteBuf 合并为一个逻辑上的 ByteBuf, 避免了各个 ByteBuf 之间的拷贝。
(2)Netty 提供了 ByteBuf 的浅层复制操作( slice 、 duplicate ),可以将 ByteBuf 分解为多个共享同一个存储区域的 Byte Buf, 避免内存的拷贝。
(3)在使用 Netty 进行文件传输时,可以调用 FileRegion 包装的 transferTo 方法,直接将文件缓冲区的数据发送到目标 Channel ,避免普通的循环读取文件数据和写入通道所导致的内存拷贝问题。
(4)在将一个 byte 数组转换为一个 ByteBuf 对象的场景, Netty 提供了一系列的包装类,避免了转换过程中的内存拷贝。
(5)中会多出一次缓冲区的内存拷贝。所以,在发送 ByteBuffer 到 Socket 时,尽量使用直接内存。
Rocket 的零复制实现
在消息发送方面,RocketMQ采用了DirectByteBuffer来实现零拷贝。当消息发送到Broker时,Broker会将消息写入到内存映射文件中,然后通过DirectByteBuffer将消息发送到网络协议栈中,最后发送到网络设备中。这样就避免了数据的多次拷贝,提高了消息发送的效率。
在消息消费方面,RocketMQ采用了FileChannel来实现零拷贝。当消费者从Broker中拉取消息时,Broker会将消息从内存映射文件中读取出来,然后通过FileChannel将消息发送到消费者的内存中。这样就避免了数据的多次拷贝,提高了消息消费的效率。
kafka 的零复制实现
Kafka两个重要过程都使用了零拷贝技术,且都是操作系统层面的狭义零拷贝:
(1)Producer生产的数据持久化到broker,采用mmap文件映射,实现顺序的快速写入。
(2)Customer从broker读取数据,采用sendfile,将磁盘文件读到OS内核缓冲区后,直接转到socket buffer进行网络发送。