文章目录
- 摘要和结论
- 引言
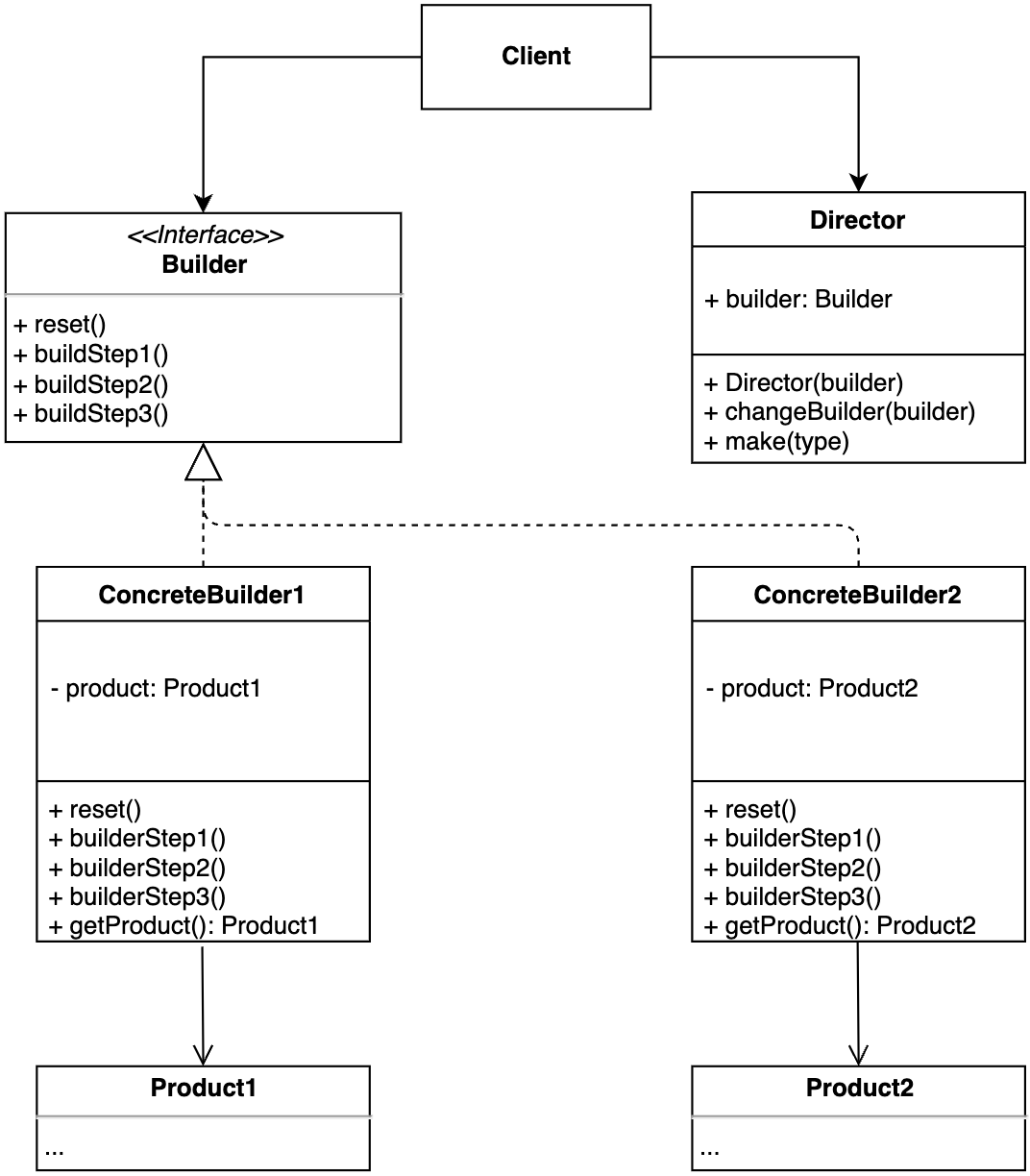
- 模型框架
- Vision Encoder
- Tubelet Decoder(factorise Queries CA MHSA)
- Training objective
- Matching
摘要和结论
- e2e,纯基于Transformer的模型,输入视频输出tubelets。
- 无论是 对单个帧的稀疏边界框监督 还是 完整的小管注释。在这两种情况下,它都会预测连贯的tubelets作为输出。
- 此外,我们的端到端模型不需要以建议的形式进行额外的预处理,或者在非最大抑制方面进行后处理。(DETR)
引言
该模型的初始阶段是一个视觉编码器。接下来是一个解码器,它处理学习到的潜在查询,这些查询代表视频中的每个参与者,进入输出小管——输入视频剪辑每个时间步的边界框和动作类序列。
我们的模型是通用的,因为我们可以使用完全标记的管注释或稀疏关键帧注释(当只标记有限数量的关键帧时)来训练它。在后一种情况下,我们的网络仍然预测小管道,并在没有明确监督的情况下,学会将演员的检测从一帧关联到下一帧。我们的因子分解query、解码器架构和损失中的小管道匹配的公式促进了这种行为,这些都包含时间归纳偏差。
模型框架
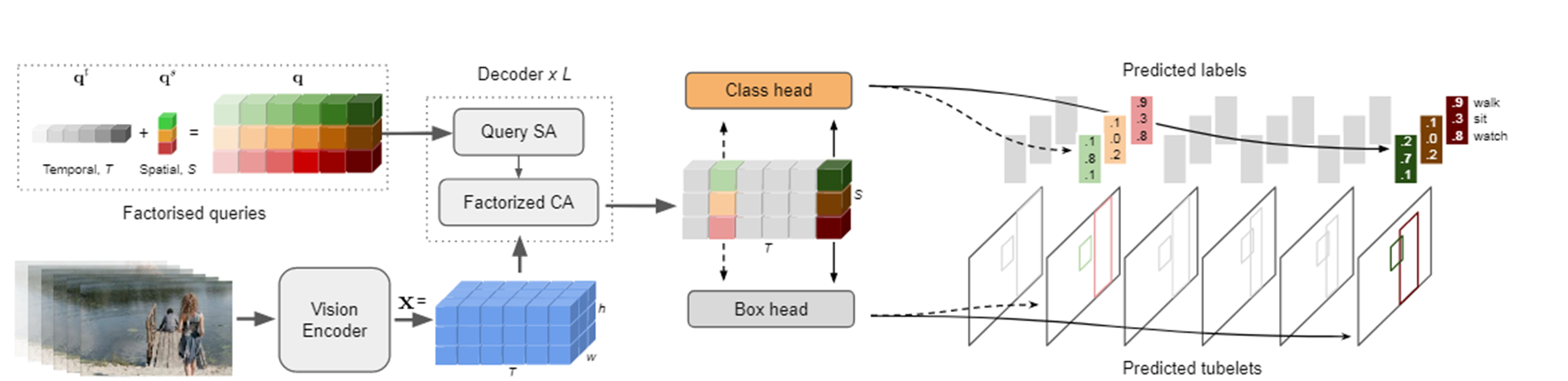
我们的模型由一个视觉编码器组成,然后是一个解码器,该解码器将学习到的查询令牌处理为输出小管道。我们在解码器中加入了时间归纳偏差,以在较弱的监督下提高准确性和小管道预测。
Vision Encoder

将X处理为x。移除时空聚合步骤,同时如果时间的patch的尺寸大于1,则双线性插值来维持时间的分辨率。
Tubelet Decoder(factorise Queries CA MHSA)

解码器由L层组成,每个层对查询query执行一系列自注意操作,并在查询和编码器输出之间进行交叉注意。我们修改了时空定位场景的查询、自注意和交叉注意操作。 以包括额外的时间归纳偏差,并提高准确性,具体如下:
-
Queries: q ∈ R_T ×S×d,factorise the queries分解query到时间和空间(qs ∈ R_S×d,qt ∈ R_T×d)。我们只需在所有帧上重复空间查询,并将它们添加到每个位置对应的时间嵌入中。(在每个位置,将查询向量与对应的时间嵌入相加。)

-
Decoder layer: factorise the self- and cross-attention layers across space and time respectively.分别分解空间和时间上的自我注意层和交叉注意层。具体来说,在MHSA中,Q K V 分别在时间和空间维度上独立计算两次。类似地,我们修改了交叉关注操作,以便只有来自同一时间索引的tubelet查询和主干功能相互关注。
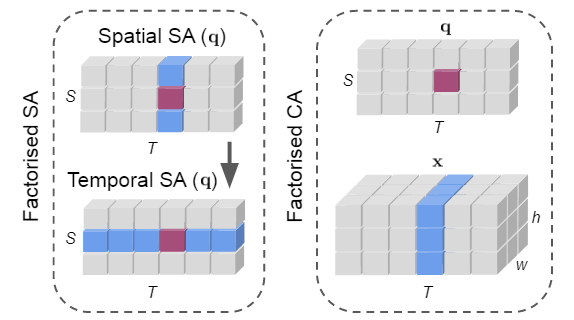
我们的解码器层由因子分解的自注意(SA)(左)和交叉注意(CA)(右)操作组成,旨在提供时空归纳偏差并减少计算。这两种操作都将注意力限制在与查询令牌相同的空间和时间切片上,如给定查询令牌(品红色)的感受野(蓝色)所示 -
Localisation and classification heads:
我们通过将一个小的前馈网络应用于解码器 z 的输出来获得网络 y = (b, a) 的最终预测,遵循 DETR。边界框序列 b 使用 3 层 MLP 获得,并由 Tubelet 中每一帧的框中心、宽度和高度参数化。单层线性投影用于获取类 logits a。当我们预测每帧固定数量的 S 个边界框时,S 大于帧中地面实况实例的最大数量,我们还包括一个额外的类标签 ∅,它表示没有动作类别的小管可以分配给的“背景”类。
Training objective
我们的模型预测输入视频的每一帧的边界框和动作类。然而,许多数据集,如AVA[18],只在视频的选定关键帧上稀疏注释。为了利用可用的注释,我们在将预测与基本事实匹配后,仅在视频的带注释的帧上计算训练损失 Eq. 4。这表示为
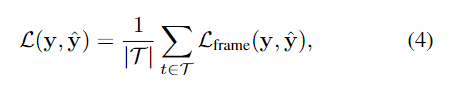
其中 T 是标记帧的集合; y 和 ^y 表示匹配后的基本事实和预测的小管。

Matching
基于集合的检测模型,如DETR,可以以任何顺序进行预测,这就是为什么在计算训练损失之前,预测需要与GT匹配的原因。
我们考虑的第一种匹配形式是在每一帧独立执行二部匹配,在计算损失之前将模型的预测与地面真实(或∅背景类)对齐。
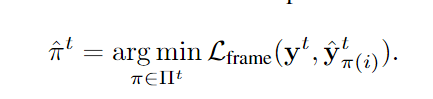
另一种方法是执行 Tubelet 匹配,其中所有具有相同空间索引 qs 的查询都必须与输入视频的所有帧中的相同地面实况注释相匹配。这里的排列是在S个元素上获得的
从直觉上讲,当我们有完整的tubelet注释可用时,tubelet匹配提供了更强的监督。请注意,无论我们执行何种类型的匹配,损失计算和整个模型架构都保持不变。请注意,我们没有在等式中对项进行加权。5,为了简化匹配和损失计算,并避免具有额外的超参数,也如[37]中所做的那样。