文章目录
- 1. 安装Hive(最小化部署)
- 2. MySQL安装
- 3. Hive元数据配置到MySQL
- 4. HiveServer2服务
- 5. Metastore服务运行模式
- 6. 编写脚本来管理hive的metastore/hiveserver2服务的启动和停止
- 1.7 Hive常用命令
- 7. Hive参数配置方式
- 7.1 Hive常见的几个属性配置
- 安装Hive的前提是先安装Hadoop集群,并且hive只需要在Hadoop的namenode节点中安装即可,可以不再datanode节点上安装
1. 安装Hive(最小化部署)
-
在s1服务器解压缩hive的安装包至/opt/module 目录下,并改名为hive-3.1.2
[gaochuchu@s1 softs]$ tar -zxvf /opt/softs/apache-hive-3.1.2-bin.tar.gz -C /opt/module/ [gaochuchu@s1 module]$ mv apache-hive-3.1.2-bin/ hive-3.1.2 -
配置环境变量,在/etc/profile.d/my_env.sh中添加环境变量
[gaochuchu@s1 module]$ sudo vim /etc/profile.d/my_env.sh #HIVE_HOME export HIVE_HOME=/opt/module/hive-3.1.2 export PATH=$PATH:$HIVE_HOME/bin source /etc/profile -
初始化元数据库,此时默认为derby数据库
[gaochuchu@s1 hive-3.1.2] bin/schematool -dbType derby -initSchema -
启动Hive和简单使用Hive
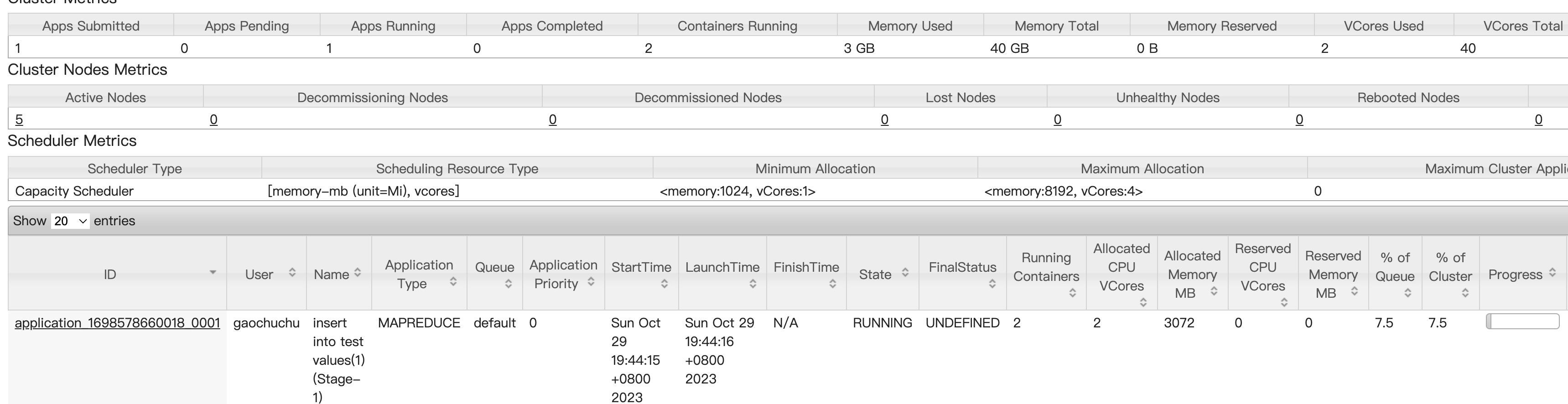
[gaochuchu@s1 hive-3.1.2]$ bin/hive hive> show databases; hive> show tables; hive> create table test(id int); hive> insert into test values(1); hive> select * from test;-
注意hive是存储在hdfs之上,因此默认hive的所有表都存在hdfs中的hive的默认目录/user/hive/warehouse

-
并且所有的hiveQL语句会转换成mapreduce任务,例如上述插入一条数据的例子,会转为mapreduce任务
-
-
退出hive客户端
hive>quit; -
使用默认derby数据库的弊端
-
原因在于 Hive 默认使用的元数据库为 derby,开启 Hive 之后就会占用元数据库,且不与其他客户端共享数据,所以一次只能开启一个hive客户端,开启两个的时候,我们动态监测/tmp/gaochuhcu/hive.log数据库就会发现报错

-
所以我们需要将 Hive 的元数据地址改为 MySQL。
-
2. MySQL安装
-
因为Hive中主要还是用MySQL作为元数据库,首先卸载数据库中已有的mariadb
[gaochuchu@s1 ~]$ sudo rpm -e --nodeps mariadb-libs [gaochuchu@s1 ~]$ sudo rpm -e --nodeps mariadb-devel -
如果服务器已经安装了8.0版本的mysql,可以安装如下示例安装mysql5.7实例,原先8.0版本的mysql实例仍然保留
-
解压缩mysql5.7到/opt/module目录下
-
并在该mysql目录下创建数据目录/opt/module/mysql57/data
-
在/opt/module/mysql57/目录下添加配置文件my.cnf
[gaochuchu@s1 mysql57]$ vim my.cnf port=3308 datadir=/opt/module/mysql57/data socket=/opt/module/mysql57/data/mysql.sock log-error=/opt/module/mysql57/data/mysqld.log pid-file=/opt/module/mysql57/data/mysqld.pid -
安装mysql
[gaochuchu@s1 mysql57]$ bin/mysqld \ --defaults-file=/opt/module/mysql57/my.cnf \ --initialize \ --user=gaochuchu \ --basedir=/opt/module/mysql57 \ --datadir=/opt/module/mysql57/data -
启动mysql
bin/mysqld_safe \ --defaults-file=/opt/module/mysql57/my.cnf \ --user=gaochuchu & -
查看初始化密码
grep "password" /var/log/mysqld.log -
利用初始化密码进入mysql,并且修改数据库密码
[gaochuchu@s1 data]$ mysql -S /opt/module/mysql57/data/mysql.sock -P 3308 -uroot -p #这里设置新密码为gcc2022 mysql> set password=password("gcc2022"); #开启远程访问 mysql> use mysql; mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'gcc2022'; mysql> flush privileges; -
停止mysql
[gaochuchu@s1 ~]$ ps -aux|grep mysqld #通过kill 命令停止
3. Hive元数据配置到MySQL
-
将MYSQL的JDBC驱动拷贝到Hive的lib目录下
[gaochuchu@s1 mysql57]$ cp /opt/softs/mysql-connector-java-5.1.27-bin.jar $HIVE_HOME/lib -
在mysql数据库中创建名为metastore的hive元数据的数据库
-
在$HIVE_HOME/conf目录下新建hive-site.xml文件,配置和连接mysql元数据库相关的内容
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- jdbc 连接的 URL --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://s1:3308/metastore?useSSL=false</value> </property> <!-- jdbc 连接的 Driver--> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <!-- jdbc 连接的 username--> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <!-- jdbc 连接的 password --> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>gcc2022</value> </property> <!-- Hive 元数据存储版本的验证 --> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <!--元数据存储授权--> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> <!-- Hive 默认在 HDFS 的工作目录 --> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> </configuration> -
初始化Hive元数据库(修改为MySQL存储元数据)
[gaochuchu@s1 hive-3.1.2]$ bin/schematool -initSchema -dbType mysql -verbose -
启动Hive
gaochuchu@s1 hive-3.1.2]$ bin/hive -
使用hive
hive> show databases; hive> show tables; hive> create table test (id int); hive> insert into test values(1); hive> select * from test;4. HiveServer2服务
-
为用户提供远程访问Hive数据的功能,因此Hive的hiveserver2服务的作用是提供jdbc/odbc接口
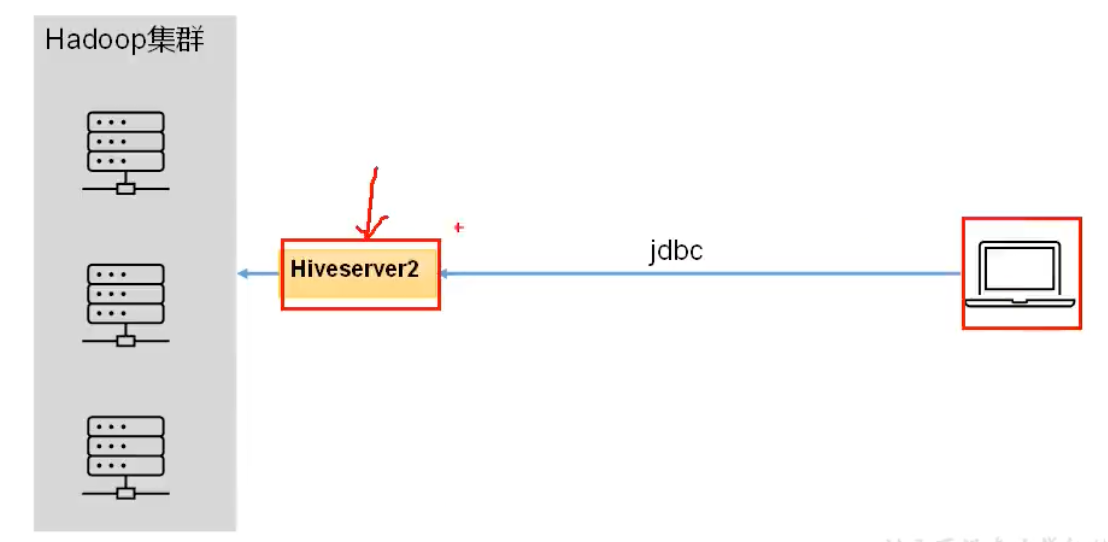
远程访问Hive数据库时,客户端并未直接访问Hadoop集群,而是由HiveServer2代理访问。
-
Hadoop端配置
hivesever2的模拟用户功能,依赖于Hadoop提供的proxy user(代理用户功能),只有Hadoop中的代理用户才能模拟其他用户的身份访问Hadoop集群。因此,需要将hiveserver2的启动用户设置Hadoop的代理用户,增加配置文件core-site.xml并分发<!--配置所有节点的gaochuchu用户都可作为代理用户--> <property> <name>hadoop.proxyuser.gaochuchu.hosts</name> <value>*</value> </property> <!--配置gaochuchu用户能够代理的用户组为任意组--> <property> <name>hadoop.proxyuser.gaochuchu.groups</name> <value>*</value> </property> <!--配置gaochuchu用户能够代理的用户为任意用户--> <property> <name>hadoop.proxyuser.gaochuchu.users</name> <value>*</value> </property> -
Hive端口配置
-
修hive-site.xml配置文件,增加配置信息
<!-- 指定hiveserver2连接的host --> <property> <name>hive.server2.thrift.bind.host</name> <value>s1</value> </property> <!-- 指定hiveserver2连接的端口号 --> <property> <name>hive.server2.thrift.port</name> <value>10000</value> </property>
-
-
启动hiveserver2
[gaochuchu@s1 hive-3.1.2]$ bin/hive --service hiveserver2 -
使用beeline客户端
[gaochuchu@s1 hive-3.1.2]$ bin/beeline -u jdbc:hive2://s1:10000 -n gaochuchu #退出beeline客户端 0: jdbc:hive2://s1:10000> !quit
-
关于Hive的图形化客户端
DBeaver(免费)
DataGrip(付费):可以支持多种数据库,而且学生根据校园邮箱免费使用正版Datagrip
-
试用了一下其可视化数据编辑器非常好用,而且代码导航,代码提示能力很强。
-
5. Metastore服务运行模式
-
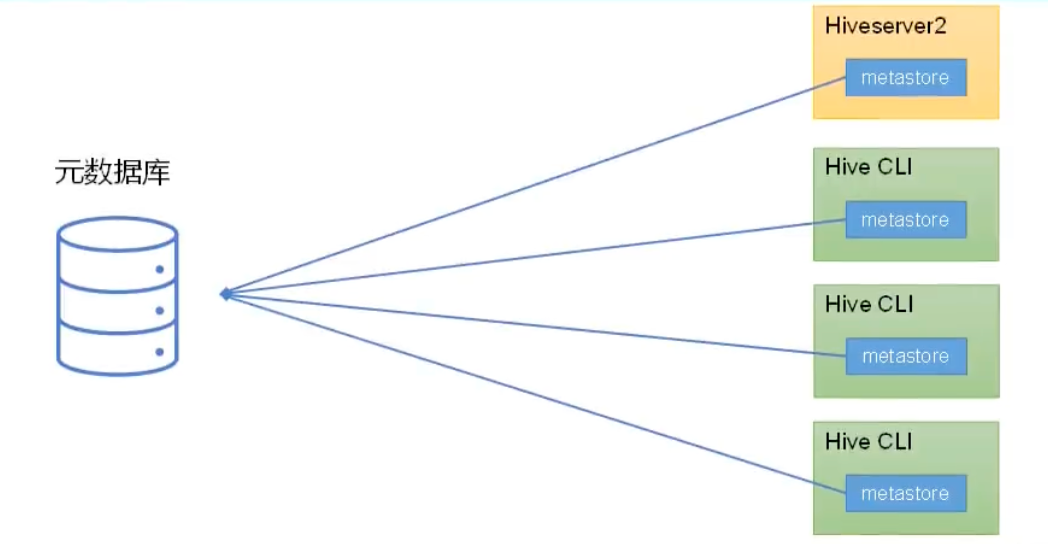
嵌入式模式
将metastore看作一个依赖嵌入到Hiveserver2和每一个HiveCLI客户端进程,使得Hiveserver2和HiveCLI客户端直接连接访问数据库。
-
独立服务模式
把metastore服务独立出来单独启动,Hiveserver2和Hive命令行客户端都访问metastore服务,然后再由metastore访问元数据库。
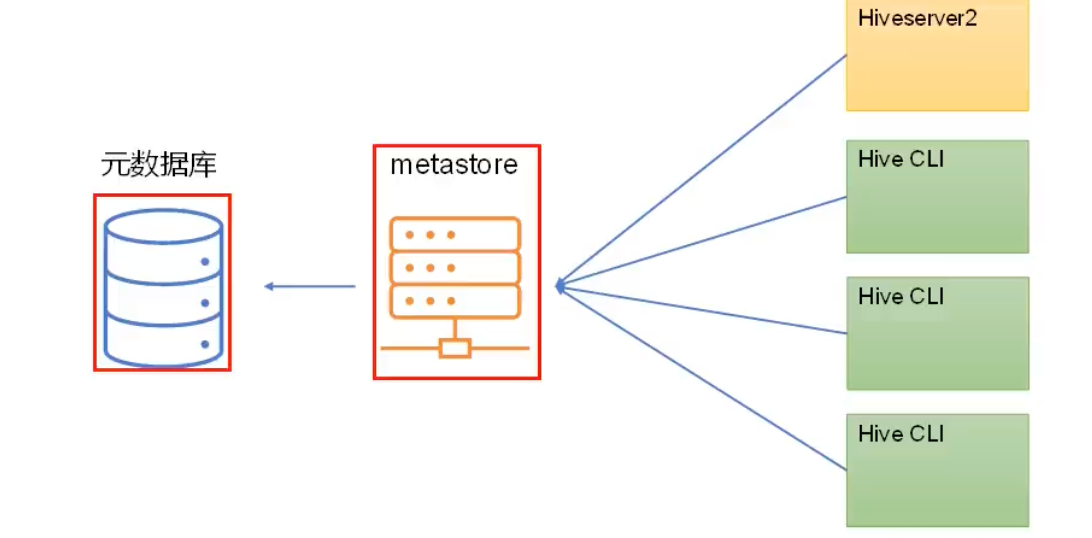
- metastore服务不负责存储元数据,只负责提供访问元数据的接口。
生产环境中,不推荐使用嵌入式模式。因为其存在以下两个问题:
(i)嵌入式模式下,每个Hive CLI都需要直接连接元数据库,当Hive CLI较多时,数据库压力会比较大。
(ii)每个客户端都需要用户元数据库的读写权限,元数据库的安全得不到很好的保证。 -
独立服务模式会在s1上的hive-site.xml中配置jdbc服务,其他节点如果是hive客户端,则在hive-site.xml中删除jdbc有关的配置
并配置如下:
<!-- 指定存储元数据要连接的地址 --> <property> <name>hive.metastore.uris</name> <value>thrift://s1:9083</value> </property> -
实例测试:
-
s1配置metastore,s2上配置客户端
-
s1启动metastore
[gaochuchu@s1 hive-3.1.2]$ hive --service metastore 使用nohup 命令可以让其后台运行 [gaochuchu@s1 hive-3.1.2]$ nohup hive --service metastore & -
s2的/opt/module/hive-3.1.2/conf/,配置hive-site.xml,删除jdbc的相关参数,添加配置:
<property> <name>hive.metastore.uris</name> <value>thrift://s1:9083</value> </property> -
s2节点上启动客户端
[gaochuchu@s2 hive-3.1.2]$ bin/hive报错:
Exception in thread "main" java.lang.RuntimeException: java.net.ConnectException: Call From s2/...84 to s1:9000 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:651) at org.apache.hadoop.hive.ql.session.SessionState.beginStart(SessionState.java:591) at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:747) at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:683) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.util.RunJar.run(RunJar.java:318) at org.apache.hadoop.util.RunJar.main(RunJar.java:232)
解决:
- 查看了hadoop的配置,NameNode的内部通信端口设置的是8020,但是hive中连接却是9000,说明hadoop中配置的相关端口信息未同步到hive
- 将
/opt/module/hadoop-3.1.3/etc/hadoop/的core-site.xml以及hdfs-site.xml文件放在/opt/module/hive-3.1.2/conf/目录下
-
6. 编写脚本来管理hive的metastore/hiveserver2服务的启动和停止
-
在
/opt/module/hive-3.1.2/bin/创建脚本文件hiveservices.sh[gaochuchu@s1 hive-3.1.2]$ sudo chmod +x /bin/hiveservices.sh #启动metastore/hiveserver2 hiveservices.sh start #停止metastore/hiveserver2 hiveservices.sh stop #重启metastore/hiveserver2 hiveservices.sh restart #查看状态metastore/hiveserver2 hiveservices.sh status1.7 Hive常用命令
[gaochuchu@s1 hive-3.1.2]$ bin/hive -help Hive Session ID = cf0fbd78-e8f7-46dd-ab83-a8fcbf2b58e1 usage: hive -d,--define <key=value> Variable substitution to apply to Hive commands. e.g. -d A=B or --define A=B --database <databasename> Specify the database to use -e <quoted-query-string> SQL from command line -f <filename> SQL from files -H,--help Print help information --hiveconf <property=value> Use value for given property --hivevar <key=value> Variable substitution to apply to Hive commands. e.g. --hivevar A=B -i <filename> Initialization SQL file -S,--silent Silent mode in interactive shell -v,--verbose Verbose mode (echo executed SQL to the console) -
-e 不进入hive的交互窗口执行sql语句
[gaochuchu@s1 hive-3.1.2]$ hive -e "select * from stu;" -
-f 执行脚本中的sql语句
[gaochuchu@s1 hive-3.1.2]$ hive -f test.sql -
退出hive窗口
hive(default)>exit; hive(default)>quit; -
Hive客户端查看hdfs文件系统
hive(default)>dfs -ls /; -
查看在hive中输入的所有历史命令
#在当前用户的根目录下 [gaochuchu@s1 ~]$ cat .hivehistory
7. Hive参数配置方式
-
配置文件方式
默认配置文件:hive-default.xml
用户自定义配置文件:hive-site.xml
注意:用户自定义配置会覆盖默认配置。另外,Hive 也会读入 Hadoop 的配置,因为 Hive是作为 Hadoop 的客户端启动的,Hive 的配置会覆盖 Hadoop 的配置。配置文件的设定对本机启动的所有 Hive 进程都有效。
-
命令行参数方式
启动 Hive 时,可以在命令行添加-hiveconf param=value 来设定参数。
[gaochuchu@s1 hive-3.1.2] bin/hive -hiveconf mapred.reduce.tasks=10;仅仅对本次hive启动有效
-
参数声明方式
可以在 HQL 中使用 SET 关键字设定参数
例如:
hive (default)> set mapred.reduce.tasks=100;注意:仅对本次 hive 启动有效。
-
查看参数设置
hive (default)> set mapred.reduce.tasks;
上述三种设定方式的优先级依次递增。即配置文件<命令行参数<参数声明。注意某些系
统级的参数,例如 log4j 相关的设定,必须用前两种方式设定,因为那些参数的读取在会话
建立以前已经完成了。
7.1 Hive常见的几个属性配置
-
Hive客户端显示当前库和表头:在hive-sites.xml配置文件中增加配置
<property> <name>hive.cli.print.header</name> <value>true</value> </property> <property> <name>hive.cli.print.current.db</name> <value>true</value> </property> -
Hive的运行日志信息配置
-
Hive的log默认存放在/tmp/gaochuchu/hive.log 目录下(当前用户名)
-
修改hive的log日志存在到/opt/module/hive-3.1.2/logs
#修改hive-log4j2.properties.template 文件名为/hive-log4j2.properties [gaochuchu@s1 conf]$ mv hive-log4j2.properties.template hive-log4j2.properties #在/hive-log4j2.properties中修改log的存放位置 [gaochuchu@s1 conf]$ vim hive-log4j2.properties #property.hive.log.dir = ${sys:java.io.tmpdir}/${sys:user.name} 改为: property.hive.log.dir = /opt/module/hive-3.1.2/logs
-
-
Hive的JVM对内存设置
新版本的Hive启动的时候,默认申请的JVM堆内存大小为256M,JVM堆内存申请太小,导致后期开启本地模式,执行复杂SQL时经常会报错:
java.lang.OutOfMemoryError:Java Heap space。
因此最好提前调整一个HADOOP_HEAPSIZE这个参数
#修改hive-env.sh.tmplate 文件名为hive-env.sh [gaochuchu@s1 conf]$ mv hive-env.sh.template hive-env.sh #将hive-env.shi其中的参数export HADOOP_HEAPSIZE修改为2048 export HADOOP_HEAPSIZE=2048

![[量化投资-学习笔记004]Python+TDengine从零开始搭建量化分析平台-EMA均线](https://img-blog.csdnimg.cn/121922a3d4ab4ee995287691798885aa.png#pic_center)