前言
之前使用scikit 进行一些基础模型的选择(SVM支持向量机,LR算法,KNN,SGD,Bays贝叶斯,决策树,随机森林),创建,训练(测试集+验证集)(分类规则-基尼划分标准,熵划分标准->交叉验证),和调参(主要在决策树和随机森林上面试了下)。多多少少了解了一点模型的由来。但是始终不太了解数据是从何而来,需要如何清洗,需要如何正则化,归一化之类的。于是就有了以下的文章。以下都是本人看了别人的文章或者敲了一些代码后对数据的一些认知,本人对python不是很熟,所以很多时候可能理解得不对。有错误麻烦指出来,谢谢!
条件
lianjia.json
格式如下

json数据先转换成csv文件
# 将json数据转换成csv数据,方便后面进行数据的运算
import json
import csv
import os
def jsonToCsv(jsonFile, csvFile):
# 查看当前的路径
path = os.getcwd()
print(path)
# 1,读取json数据 读取csv文件
# json_fp = open(jsonFile, "r", encoding='utf-8')
csv_fp = open(csvFile, "w", encoding='utf-8', newline='', )
writer = csv.writer(csv_fp)
with open(jsonFile, 'r', encoding='utf-8') as json_fp:
isTitle = True;
# 2,提取出表头和表的内容
for line in json_fp.readlines():
lineStr = json.loads(line) # 将每一条数据读取出来
print(lineStr)
if isTitle:
sheet_title = lineStr.keys()
print(sheet_title)
isTitle = False
writer.writerow(sheet_title)
else:
content = lineStr.values()
writer.writerow(content)
# 6,关闭两个文件
json_fp.close()
csv_fp.close()
jsonToCsv(jsonFile='H:\pythonFunction\jsonToCsv\lianjia.json', csvFile='H:\pythonFunction\jsonToCsv\zufang.csv')得到以下数据:

开始对数据进行处理
因为数据里面有分号",",而内容里面也有分号。怕出其他幺蛾子,于是直接得到的csv重新使用"|"划分。
# 找出数据缺失的部分
import pandas as pd
import csv
# 读取文件
# df = pd.read_csv('zufang1.csv', sep='|') # 这个需要添加分隔符参数,是因为我们使用的"|"不是默认分隔符
df = pd.read_csv('zufang.csv') # 这里不需要添加分隔符参数,是因为这个csv文件使用的时候默认分隔符 ","
# # 这个是因为看到分隔符里面有相同的“,”,所以怕转换成excel的时候出错,所以将分隔符转换成“|”
df.to_csv('zufang1.csv', sep='|')
# # 查看每一列是否有NaN
# print(df.isnull().any(axis=0))
#
# # 查看每一行是否有NaN
# print(df.isnull().any(axis=1))
#
# # 查看所有数据中心是否有NaN最快的,没有输出False,反之输出True
# print(df.isnull().values.any())
#
# # 查看每一列是否有缺失
# print(df.isna().any(axis=0))
#
# # 查看每一行是否有缺失
# print(df.isna().any(axis=1))
#
# # 查看所有数据中心是否有缺失最快的,没有输出False,反之输出True
# print(df.isna().values.any())
# 输出含有NaN的数据行
# print(df[df.isnull().values==True])
print('=====================================')
# 输出含有缺失的数据行
# print(df[df.isna().values==True])
df.info() # 从这里可以看到每一行总共的数据,可以查出
print('=====================================')
for columnname in df.columns:
if df[columnname].count() != len(df):
loc = df[columnname][df[columnname].isnull().values==True].index.tolist()
print('列名: “{}”,第{}行位置有缺失值'.format(columnname, loc))
其中df.info指令指出了哪个列总共缺失了多少值
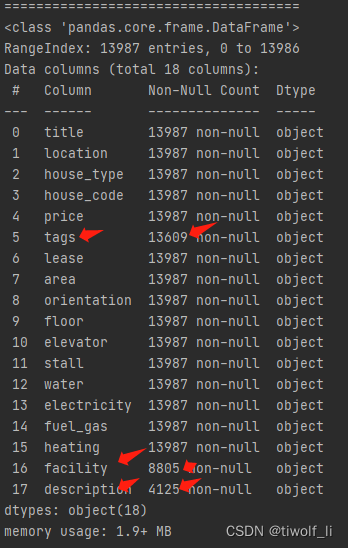
对比其他列都是13987个数据,tags,facility,description分别只有13609,8805,4125个数据。分别少了13987-13609=378个,13987-8805=4882个,13987-4125=9862个。

这部分内容则指出了数据缺失的具体位置,如下图

以上即为当前学到的。