前言
List、Set、HashMap作为Java中常用的集合,需要深入认识其原理和特性。
本篇博客介绍常见的关于Java中Set集合的面试问题,结合源码分析题目背后的知识点。
关于List的博客文章如下:
- Java进阶(List)——面试时List常见问题解读 & 结合源码分析
其他相关的Set的文章如下:
- Java学数据结构(3)——树Tree & B树 & 红黑树 & Java标准库中的集合Set与映射Map & 使用多个映射Map的案例
目录
- 前言
- 引出
- 1. 描述一下HashSet的底层原理?
- 构造方法
- add方法
- 2. map.put方法,静态常量PRESENT
- 3. map.remove key方法,PRESENT进行比较
- 4. HashSet的去重原理?
- 5. 如何选择HashSet 或 TreeSet?
- 6. 如何得到一个线程安全的Set集合?
- 总结
引出
1.特点:无序,去重,非线程安全;
2.底层:HashMap的Key值实现的;
3.map.put方法,静态常量PRESENT,新值替换旧值;
4.map.remove key方法,如果KEY不存在时,则返回的是null,如果KEY存在时,返回的就是e.value,即PRESENT,返回true成功,返回false不成功;
5.去重原理:先判断hash值,再通过==或者equals判断,整体如果返回true,则为重复元素;
6.无序的则采用HashSet ,有序的则采用TreeSet;
7.线程安全的set:Collections.synchronizedSet(new HashSet<>());
1. 描述一下HashSet的底层原理?
- HashSet的特点:无序,去重,非线程安全;
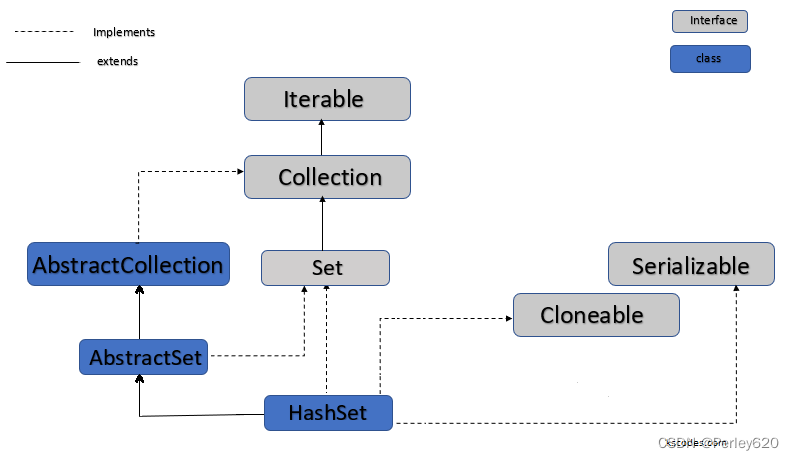
- HashSet 底层是用HashMap的Key值实现的,也有上面的3大特征;
构造方法
无参和代参构造方法都会初始化这个HashMap
无参的构造方法,调用了HashMap方法
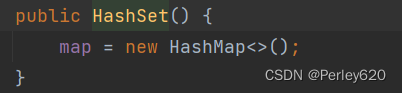
有参的构造方法也是,调用了HashMap方法


add方法

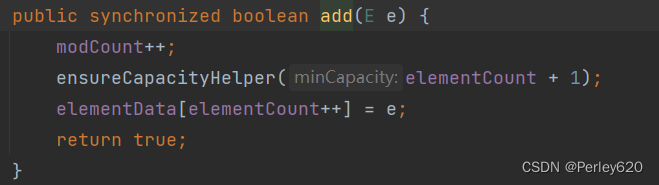
add方法中可以看出调用HashMap的put方法,key为放入元素,值为常量PRESENT

2. map.put方法,静态常量PRESENT
既然hashset基于hashmap实现,你说一下 hashset的add方法中,为什么要在map.put的val上放上一个Object类型的静态常量PRESENT?
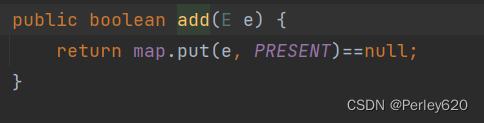
HashSet底层调用了map的put方法,传入了存储的对象和PRESENT常量,那我们进入put方法继续查看

put方法内调用了putVal方法,PRESENT常量为形参value,继续进入查看
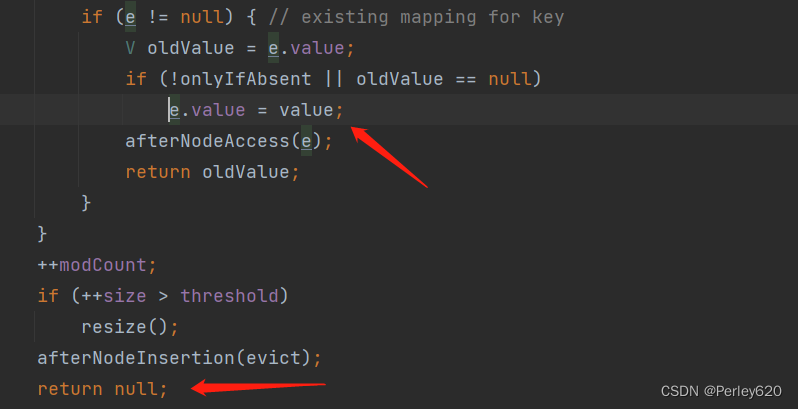
if (e != null) { // existing mapping for key
//把旧数据存储到oldValue
V oldValue = e.value;
//如果说存储的位置上已经有元素了
if (!onlyIfAbsent || oldValue == null)
//新元素会替代旧元素 新KEY替代KEY
e.value = value;
afterNodeAccess(e);
//返回旧元素数据
return oldValue;
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
//如果说上面的if结构没有执行,那么就说明这个位置上没有元素,则新增成功,返回null
return null;
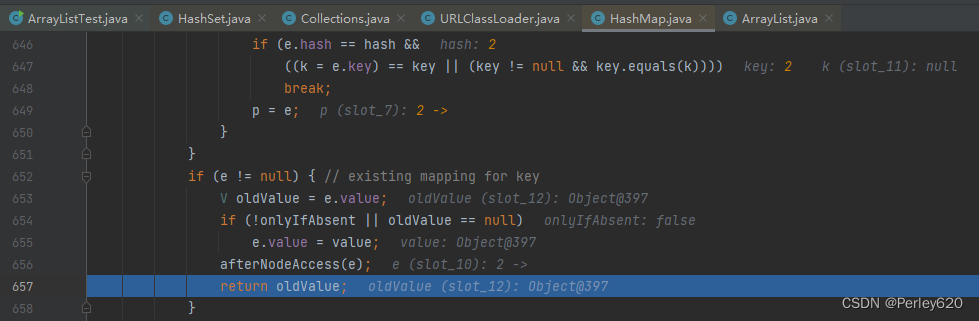
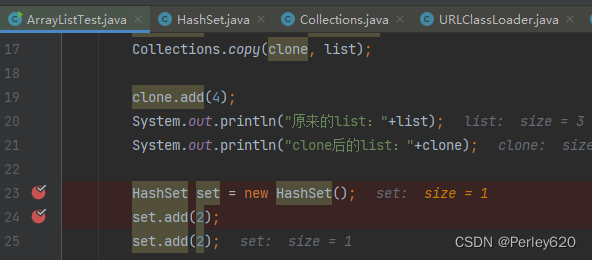
public boolean add(E e) {
//上面的方法返回值决定了HashSet的add方法到底返回true还是false
return map.put(e, PRESENT)==null;
}
- 此方法内部明确箭头标处的原理,value就是PRESENT,如果进入这个if结构,则说明这个位置上已经存在该key,则会用value替换之前的旧值,然后返回旧值oldValue,否则会返回null;
- 至此,我们可以看出此方法的返回值是PRESENT或者是null,如果为PRESENT则说明KEY已存在,则add方法就会返回false(此处元素put还是成功的,只是新值替换旧值),返回null则add返回true,此KEY不存在,代表存储新的KEY-VALUE;
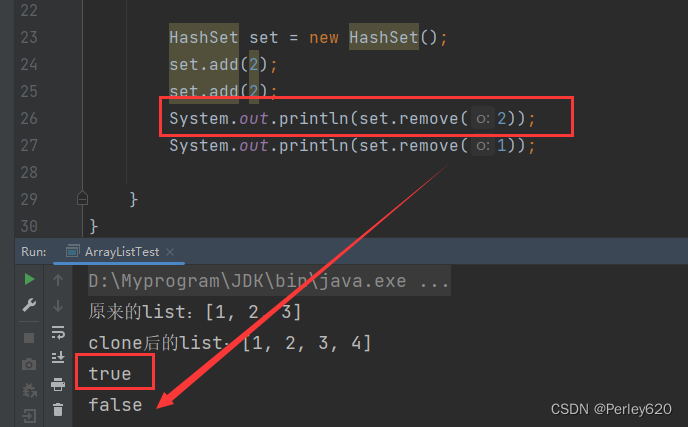
3. map.remove key方法,PRESENT进行比较
既然hashset基于hashmap实现,你说一下 hashset的remove方法中,为什么要在map.remove key 完了之后要和PRESENT进行一个等值比较呢?
- 从HashMap的remove方法中可以看出,方法返回的是e.value或者null,与add方法中的原理一起联想,则会明白,如果KEY不存在时,则返回的是null,如果KEY存在时,返回的就是e.value,即PRESENT;
- 所以在HashSet在判断此返回值==PRESENT,如果相等则返回true,说明此KEY是存在的,删除成功返回true,如果返回值是null,那么null=PRESENT则返回的肯定是false,那么代表此KEY不存在,删除自然不成功,返回false;
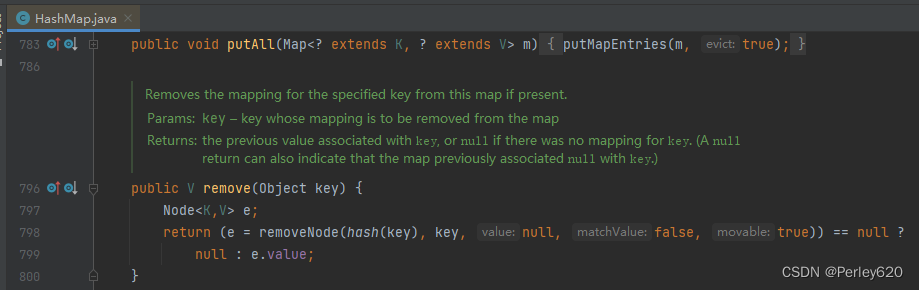
public V remove(Object key) {
Node<K,V> e;
//判断了一下,如果removeNode删除得到的是null,说明此KEY不存在,方法返回null
return (e = removeNode(hash(key), key, null, false, true)) == null ?
//否则返回e.value 就是 PRESENT
null : e.value;
}
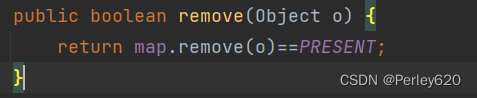
public boolean remove(Object o) {
//因为HashMap删除成功返回的是PRESENT , ==PRESENT 则结果为true 代表删除成功
//否则返回的是null , 返回false 删除失败
return map.remove(o)==PRESENT;
}
4. HashSet的去重原理?
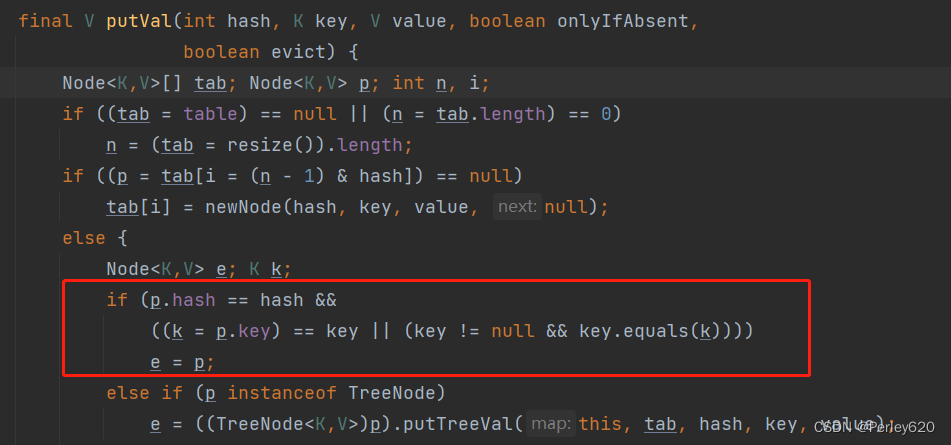
- HashMap中putVal方法中有这么一段代码判断,去重原理在于hashcode的判断和equals方法的判断
- 先判断hash值,再通过==或者equals判断,整体如果返回true,则为重复元素
5. 如何选择HashSet 或 TreeSet?
无序的则采用HashSet ,有序的则采用TreeSet
6. 如何得到一个线程安全的Set集合?
Set datas = Collections.synchronizedSet(new HashSet<>());
总结
1.特点:无序,去重,非线程安全;
2.底层:HashMap的Key值实现的;
3.map.put方法,静态常量PRESENT,新值替换旧值;
4.map.remove key方法,如果KEY不存在时,则返回的是null,如果KEY存在时,返回的就是e.value,即PRESENT,返回true成功,返回false不成功;
5.去重原理:先判断hash值,再通过==或者equals判断,整体如果返回true,则为重复元素;
6.无序的则采用HashSet ,有序的则采用TreeSet;
7.线程安全的set:Collections.synchronizedSet(new HashSet<>());