目录
一、前言
二、hive 常用数据存储格式
2.1 文件格式-TextFile
2.1.1 操作演示
2.2 文件格式 - SequenceFile
2.2.1 操作演示
2.3 文件格式 -Parquet
2.3.1 Parquet简介
2.3.2 操作演示
2.4 文件格式-ORC
2.4.1 ORC介绍
2.4.2 操作演示
三、hive 存储数据压缩优化
3.1 数据压缩-概述
3.2 数据压缩的优缺点
3.2.1 压缩的优点
3.2.2 压缩的缺点
3.3 常用压缩格式和压缩算法
3.3.1 Hadoop中各种压缩算法性能对比
3.3.2 压缩参数设置
3.3 操作演示
3.3.1 设置压缩参数
3.3.2 创建表,指定为textfile格式
3.3.3 创建表,指定为orc格式
四、hive 存储优化
4.1 避免小文件生成
4.2 ORC文件索引
4.2.1 Row Group Index
4.2.2 核心参数设置
4.2.3 操作演示
4.2.4 Bloom Filter Index
4.2.5 操作演示
4.3 ORC矢量化查询
五、写在文末
一、前言
通过之前的学习了解到,hive本身并不存储数据,其数据存储的本质还是HDFS,所有的数据读写都基于HDFS的文件来实现,因此对于hive表数据的优化可以归结为对hdfs上面存储数据相关的优化,比如数据存储格式的选择等。
二、hive 常用数据存储格式
为了提高对HDFS文件读写的性能,Hive提供了多种文件存储格式:TextFile、SequenceFile、ORC、Parquet等,不同的文件存储格式具有不同的存储特点,有的可以降低存储空间,有的可以提高查询性能。
Hive的文件格式在建表时指定,默认是TextFile,在hive的建表语法树中,在 [STORED AS file_format] 这一项中可以进行指定;

2.1 文件格式-TextFile
TextFile是Hive中默认的文件格式,存储形式为按行存储。工作中最常见的数据文件格式就是TextFile文件,几乎所有的原始数据生成都是TextFile格式,所以Hive设计时考虑到为了避免各种编码及数据错乱的问题,选用了TextFile作为默认的格式。建表时如果不指定存储格式即为TextFile,导入数据时把数据文件拷贝至HDFS不进行处理。
TextFile格式优缺点对比:
| 优点 | 缺点 | 应用场景 |
| 1、最简单的数据格式,可以直接查看 2、可以使用任意的分隔符进行分割 3、便于和其他工具共享数据 4、可以搭配压缩一起使用 | 1、耗费存储空间,I/O性能较低 2、结合压缩时Hive不进行数据切分合并,不能进行并行操作,查询效率低 3、按行存储,读取列的性能差 | 1、适合于小量数据的存储查询 2、一般用于做第一层数据加载和测试使用 |
2.1.1 操作演示
在本地有一个2K大小的文件

建表并加载数据
create table tb_sogou_source(
stime string,
userid string,
keyword string,
clickorder string,
url string
)
row format delimited fields terminated by '\t';
load data local inpath '/usr/local/soft/data/sogo.reduced' into table tb_sogou_source;执行过程
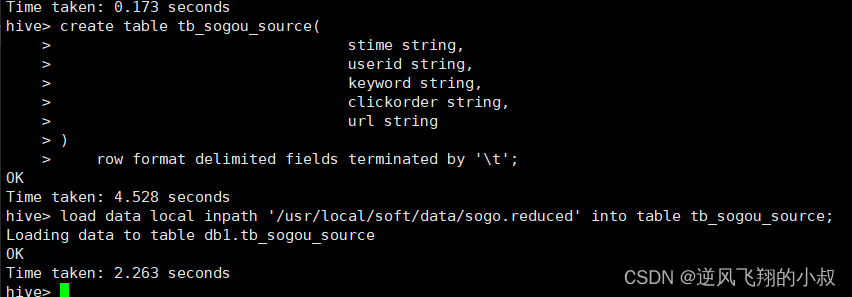
TextFile这种格式的文件的典型特征是,数据在hdfs上面文件大小与原文件保存不变,同时可以直接查看;

2.2 文件格式 - SequenceFile
SequenceFile是Hadoop里用来存储序列化的键值对即二进制的一种文件格式。SequenceFile文件也可以作为MapReduce作业的输入和输出,hive也支持这种格式。
| 优点 | 缺点 | 使用场景 |
| 1、以二进制的KV形式存储数据; 2、与底层交互更加友好,性能更快; 3、可压缩、可分割,优化磁盘利用率和I/O; 4、可并行操作数据,查询效率高; 5、也可以用于存储多个小文件 | 1、存储空间消耗最大; 2、与非Hadoop生态系统之外的工具不兼容; 3、构建SequenceFile需要通过TextFile文件转化加载 | 适合于小量数据,但是查询列比较多的场景 |
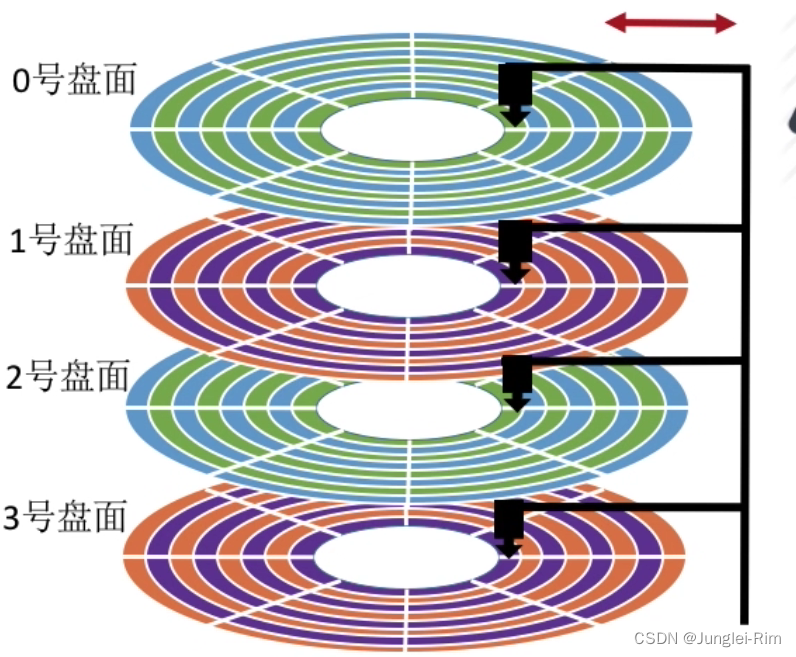
SequenceFile 底层存储架构图

2.2.1 操作演示
建表并加载数据
create table tb_sogou_seq(
stime string,
userid string,
keyword string,
clickorder string,
url string
)
row format delimited fields terminated by '\t'
stored as sequencefile;
insert into table tb_sogou_seq
select * from tb_sogou_source;执行过程
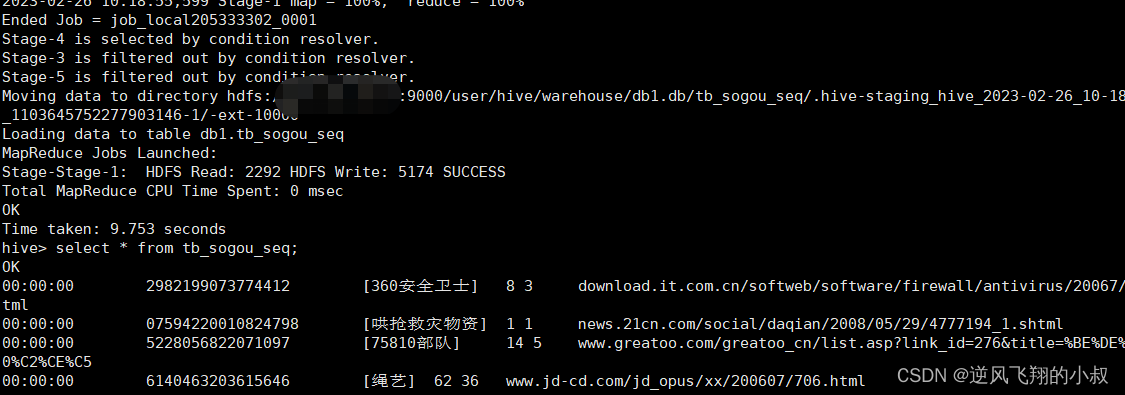
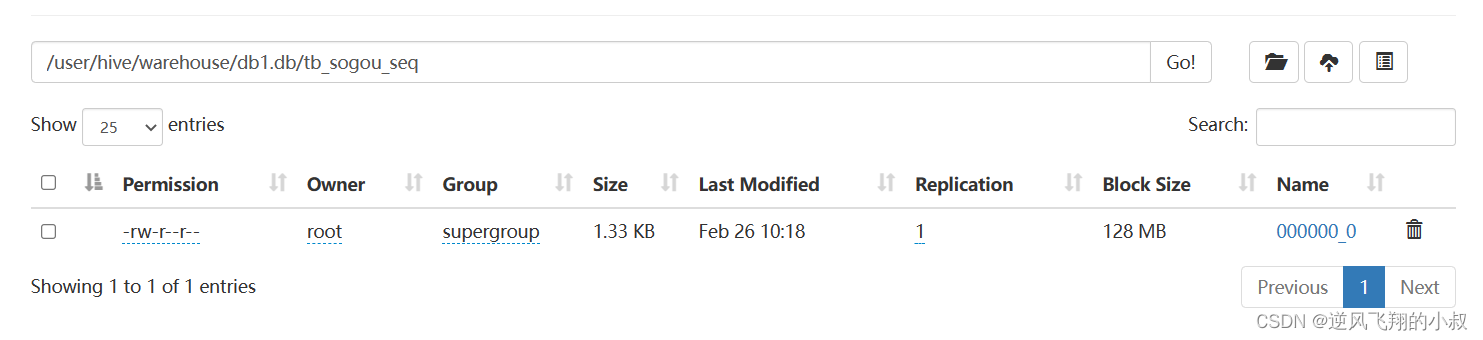
从文件大小来说,略有减小,但是这种文件下载之后是二进制格式的;
2.3 文件格式 -Parquet
2.3.1 Parquet简介
- Parquet是一种支持嵌套结构的列式存储文件格式,最早是由Twitter和Cloudera合作开发,2015年5月从Apache孵化器里毕业成为Apache顶级项目;
- 是一种支持嵌套数据模型对的列式存储系统,作为大数据系统中OLAP查询的优化方案,它已经被多种查询引擎原生支持,并且部分高性能引擎将其作为默认的文件存储格式;
- 通过数据编码和压缩,以及映射下推和谓词下推功能,Parquet的性能也较之其它文件格式有所提升;
优缺点对比
| 优点 | 缺点 | 使用场景 |
| 1、更高效的压缩和编码可压缩、可分割,优化磁盘利用率和I/O; 2、可用于多种数据处理框架 | 不支持update, insert, delete, ACID | 适用于字段数非常多,无更新,只取部分列的查询 |
2.3.2 操作演示
建表并加载数据
create table tb_sogou_parquet(
stime string,
userid string,
keyword string,
clickorder string,
url string
)
row format delimited fields terminated by '\t'
stored as parquet;
insert into table tb_sogou_parquet
select * from tb_sogou_source;执行过程
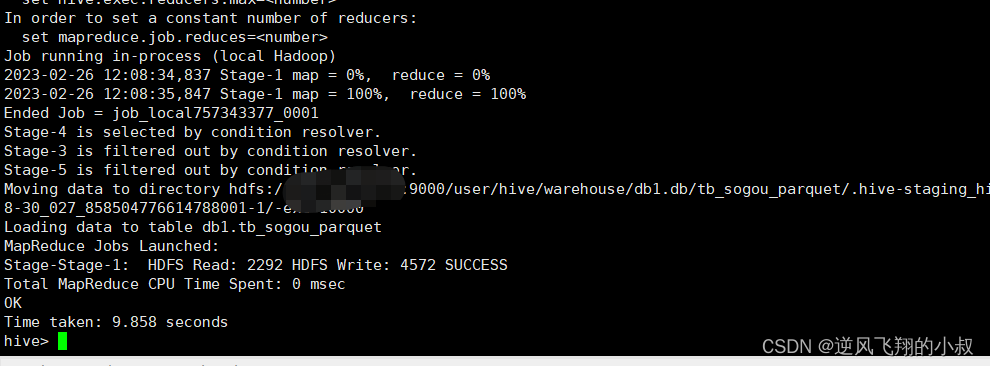
执行完成后,检查hdfs文件目录,对比原始文件可以看到这个压缩的比率还是很高的;

2.4 文件格式-ORC
2.4.1 ORC介绍
- ORC(OptimizedRC File)文件格式也是一种Hadoop生态圈中的列式存储格式;
- 它的产生早在2013年初,最初产生自Apache Hive,用于降低Hadoop数据存储空间和加速Hive查询速度;
- 2015年ORC项目被Apache项目基金会提升为Apache顶级项目;
- ORC不是一个单纯的列式存储格式,仍然是首先根据行组分割整个表,在每一个行组内进行按列存储;
- ORC文件是自描述的,它的元数据使用Protocol Buffers序列化,并且文件中的数据尽可能的压缩以降低存储空间的消耗,目前也被Hive、Spark SQL、Presto等查询引擎支持;
优缺点:
| 优点 | 缺点 | 应用场景 |
| 1、列式存储,存储效率非常高; 2、可压缩,高效的列存取; 3、查询效率较高,支持索引; 4、支持矢量化查询 | 1、加载时性能消耗较大; 2、需要通过text文件转化生成; 3、读取全量数据时性能较差 | 适用于Hive中大型的存储、查询 |
2.4.2 操作演示
建表并加载数据
create table tb_sogou_orc(
stime string,
userid string,
keyword string,
clickorder string,
url string
)
row format delimited fields terminated by '\t'
stored as orc;
insert into table tb_sogou_orc
select * from tb_sogou_source;执行过程
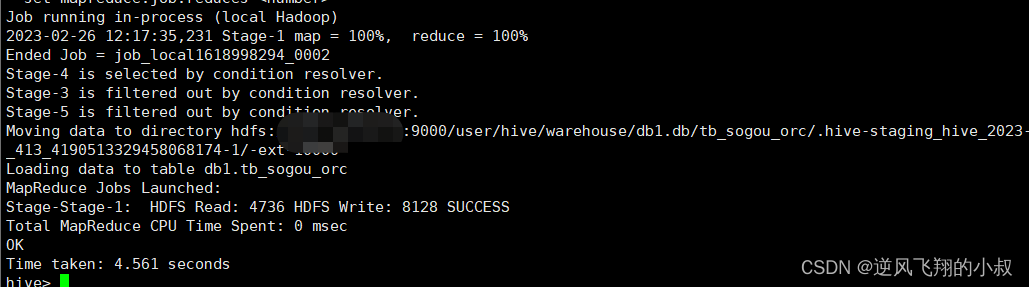
从hdfs文件目录下的数据来看,orc格式下文件仍然可以得到较大的压缩,使得存储空间大大降低;

三、hive 存储数据压缩优化
3.1 数据压缩-概述
Hive底层运行MapReduce程序时,磁盘I/O操作、网络数据传输、shuffle和merge要花大量的时间,尤其是数据规模很大和工作负载密集的情况下。鉴于磁盘I/O和网络带宽是Hadoop的宝贵资源,数据压缩对于节省资源、最小化磁盘I/O和网络传输非常有帮助。
Hive压缩实际上说的就是MapReduce的压缩。
下图是hive在运行MR任务时数据压缩过程的运行架构图
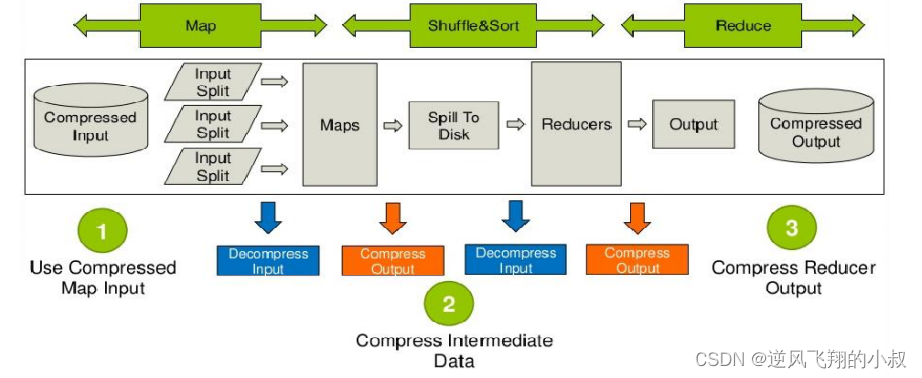
3.2 数据压缩的优缺点
3.2.1 压缩的优点
- 减小文件存储所占空间;
- 加快文件传输效率,从而提高系统的处理速度;
- 降低IO读写的次数;
3.2.2 压缩的缺点
使用数据时需要先对文件解压,加重CPU负荷,压缩算法越复杂,解压时间越长
3.3 常用压缩格式和压缩算法
Hive中的压缩就是使用了Hadoop中的压缩实现的,所以Hadoop中支持的压缩在Hive中都可以直接使用。Hadoop中支持的压缩算法:
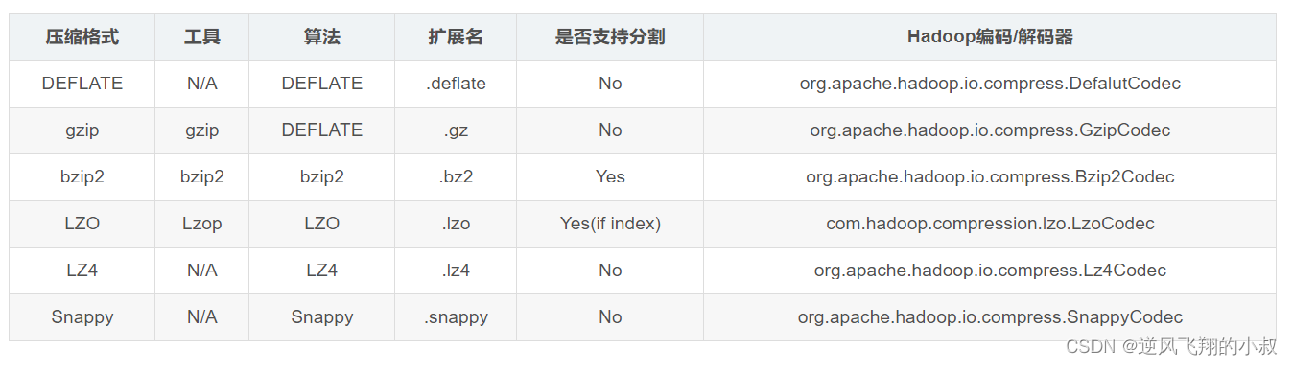
要想在Hive中使用压缩,需要对MapReduce和Hive进行相应的配置
3.3.1 Hadoop中各种压缩算法性能对比

3.3.2 压缩参数设置
--开启hive中间传输数据压缩功能
--1)开启hive中间传输数据压缩功能
set hive.exec.compress.intermediate=true;
--2)开启mapreduce中map输出压缩功能
set mapreduce.map.output.compress=true;
--3)设置mapreduce中map输出数据的压缩方式
set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec;
--开启Reduce输出阶段压缩
--1)开启hive最终输出数据压缩功能
set hive.exec.compress.output=true;
--2)开启mapreduce最终输出数据压缩
set mapreduce.output.fileoutputformat.compress=true;
--3)设置mapreduce最终数据输出压缩方式
set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
--4)设置mapreduce最终数据输出压缩为块压缩
set mapreduce.output.fileoutputformat.compress.type=BLOCK;3.3 操作演示
3.3.1 设置压缩参数
使用上面的压缩参数

3.3.2 创建表,指定为textfile格式
指定为textfile格式,并使用snappy压缩
drop table tb_sogou_snappy;
create table tb_sogou_snappy
stored as textfile
as select * from tb_sogou_source;执行过程
3.3.3 创建表,指定为orc格式
指定为orc格式,并使用snappy压缩
create table tb_sogou_orc_snappy
stored as orc tblproperties ("orc.compress"="SNAPPY")
as select * from tb_sogou_source;执行过程
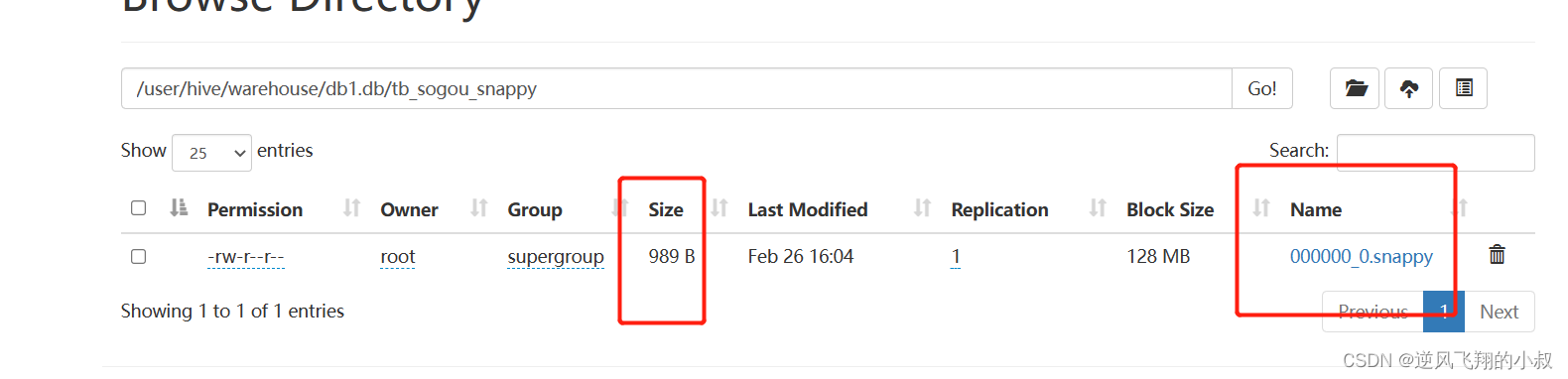
创建完成后,检查hdfs表的数据目录,可以发现数据目录的结尾会带有snappy,同时这个数据压缩比起上文更夸张了;
四、hive 存储优化
4.1 避免小文件生成
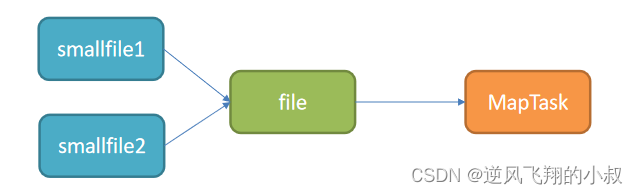
Hive的存储本质还是HDFS,HDFS是不利于小文件存储的,因为每个小文件会产生一条元数据信息,并且不利用MapReduce的处理,MapReduce中每个小文件会启动一个MapTask计算处理,导致资源的浪费,所以在使用Hive进行处理分析时,要尽量避免小文件的生成。
Hive中提供了一个特殊的机制,可以自动的判断是否是小文件,如果是小文件可以自动将小文件进行合并。
如下配置参数
-- 如果hive的程序,只有maptask,将MapTask产生的所有小文件进行合并
set hive.merge.mapfiles=true;
-- 如果hive的程序,有Map和ReduceTask,将ReduceTask产生的所有小文件进行合并
set hive.merge.mapredfiles=true;
-- 每一个合并的文件的大小(244M)
set hive.merge.size.per.task=256000000;
-- 平均每个文件的大小,如果小于这个值就会进行合并(15M)
set hive.merge.smallfiles.avgsize=16000000;
如果遇到数据处理的输入是小文件的情况,怎么解决呢?Hive中也提供一种输入类CombineHiveInputFormat,用于将小文件合并以后,再进行处理。
设置Hive中底层MapReduce读取数据的输入类:将所有文件合并为一个大文件作为输入
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
4.2 ORC文件索引
在使用ORC文件时,为了加快读取ORC文件中的数据内容,ORC提供了两种索引机制:Row Group Index 和 Bloom Filter Index可以帮助提高查询ORC文件的性能;当用户写入数据时,可以指定构建索引,当用户查询数据时,可以根据索引提前对数据进行过滤,避免不必要的数据扫描。

4.2.1 Row Group Index
- 一个ORC文件包含一个或多个stripes(groups of row data),每个stripe中包含了每个column的min/max值的索引数据;
- 当查询中有大于等于小于的操作时,会根据min/max值,跳过扫描不包含的stripes;
- 而其中为每个stripe建立的包含min/max值的索引,就称为Row Group Index行组索引,也叫min-max Index大小对比索引,或者Storage Index;
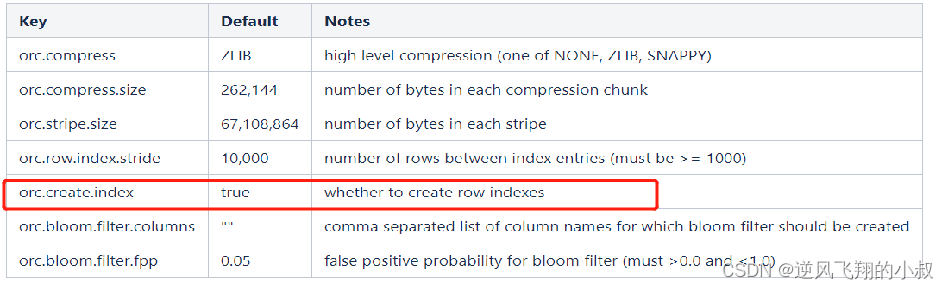
Row Group Index 补充说明
1、建立ORC格式表时,指定表参数’orc.create.index’=’true’之后,便会建立Row Group Index;
2、为了使Row Group Index有效利用,向表中加载数据时,必须对需要使用索引的字段进行排序;
4.2.2 核心参数设置
--1、开启索引配置
set hive.optimize.index.filter=true;
--2、创建表并制定构建索引
create table tb_sogou_orc_index
stored as orc tblproperties ("orc.create.index"="true")
as select * from tb_sogou_source
distribute by stime
sort by stime;
--3、当进行范围或者等值查询(<,>,=)时就可以基于构建的索引进行查询
select count(*) from tb_sogou_orc_index where stime > '12:00:00' and stime < '18:00:00';4.2.3 操作演示
开启索引配置
set hive.optimize.index.filter=true;
创建表并制定构建索引
create table tb_sogou_orc_index
stored as orc tblproperties ("orc.create.index"="true")
as select * from tb_sogou_source
distribute by stime
sort by stime;当进行范围或者等值查询(<,>,=)时就可以基于构建的索引进行查询
select count(*) from tb_sogou_orc_index where stime > '12:00:00' and stime < '18:00:00';执行结果
4.2.4 Bloom Filter Index
俗称布隆过滤器索引
- 建表时候通过表参数”orc.bloom.filter.columns”=”columnName……”来指定为哪些字段建立BloomFilter索引,在生成数据的时候,会在每个stripe中,为该字段建立BloomFilter的数据结构;
- 当查询条件中包含对该字段的等值过滤时候,先从BloomFilter中获取以下是否包含该值,如果不包含,则跳过该stripe;
4.2.5 操作演示
创建表指定创建布隆索引
create table tb_sogou_orc_bloom
stored as orc tblproperties ("orc.create.index"="true","orc.bloom.filter.columns"="stime,userid")
as select * from tb_sogou_source
distribute by stime
sort by stime;stime的范围过滤可以走row group index,userid的过滤可以走bloom filter index
select
count(*)
from tb_sogou_orc_index
where stime > '12:00:00' and stime < '18:00:00'
and userid = '3933365481995287' ;执行结果

4.3 ORC矢量化查询
Hive的默认查询执行引擎一次处理一行,而矢量化查询执行是一种Hive针对ORC文件操作的特性,目的是按照每批1024行读取数据,并且一次性对整个记录整合(而不是对单条记录)应用操作,提升了像过滤, 联合, 聚合等等操作的性能。
注意:要使用矢量化查询执行,就必须以ORC格式存储数据。
开启矢量化查询参数
set hive.vectorized.execution.enabled = true;
set hive.vectorized.execution.reduce.enabled = true;
五、写在文末
本文通过大量案例详细探讨了Hive中表的常用优化策略,希望对看到的小伙伴有用哦,本篇到此结束,感谢观看。