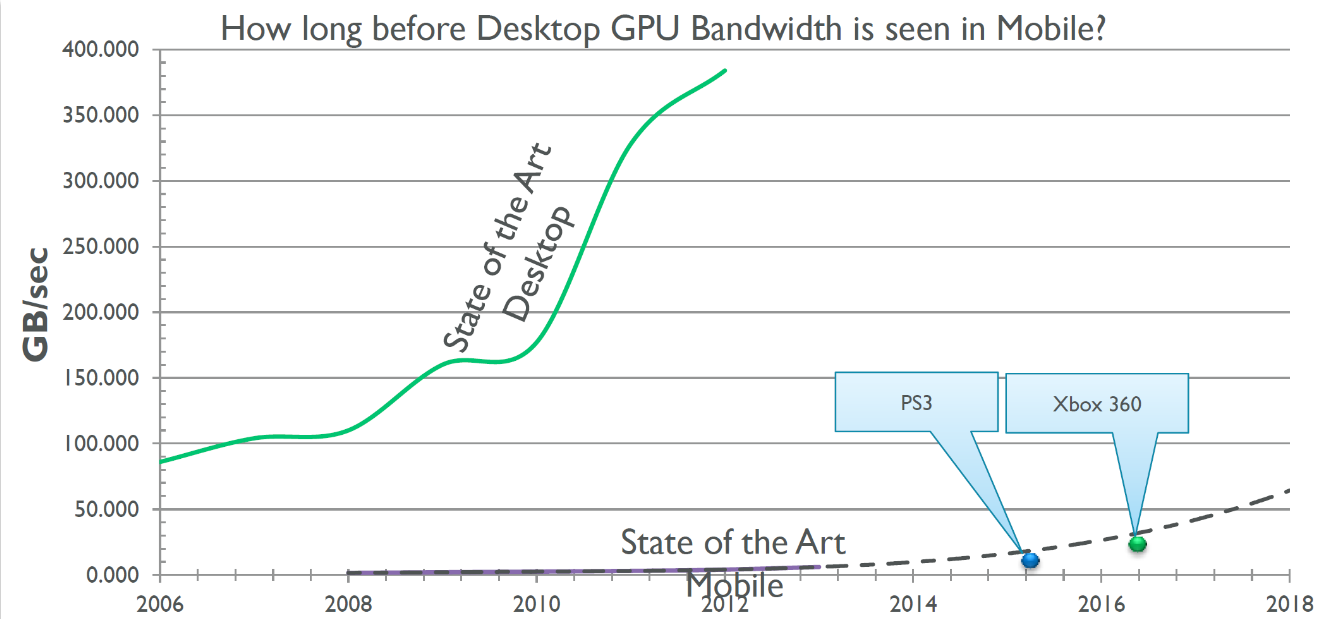
一、各类电子设备功耗对比
- 桌面级主流性能平台,功耗一般为300W(R7/I7+X60级别显卡),游戏主机150-200W
- 入门和旗舰游戏本平台功耗为100W
- 主流笔记本为50-60W,超极本为15-25W,
- 旗舰平板为8-15W
- 旗舰手机为5-8W,主流手机为3-5W。
桌面和移动端带宽比较
二、名词解释
- Soc(System on Chip)
-
- Soc是把CPU、GPU、内存、通信基带、GPS模块等等整合在一起的芯片的称呼。常见有A系Soc(苹果),骁龙Soc(高通),麒麟Soc(华为),联发科Soc,猎户座Soc(三星),去年苹果推出的M系Soc,暂用于Mac,但这说明手机、笔记本和PC的通用芯片已经出现了。
- 物理内存
-
- Soc中GPU和CPU共用一块LPDDR物理内存,就是我们常说的手机内存,也叫System Memory,大概几个G。此外CPU和GPU还分别有自己的高速SRAM的Cache缓存,也叫On-chip Memory,一般几百K~几M。不同距离的内存访问存在不同的时间消耗,距离越近消耗越低,读取System Memory的时间消耗大概是On-chip Memory的几倍到几十倍。
- On-Chip Buffer
-
- 在TB(D)R架构下会存储Tile的颜色、深度和模板缓冲,读写修改都非常快。如果Load/Store指令中缓冲需要被Preserve,将会被写入一份到System Memory中。
- Stall
-
- 当一个GPU核心的两次计算结果之间有依赖关系而必须串行时,等待的过程便是Stall。
- FillRate
-
- 像素填充率 = ROP运行的始终频率 * ROP的个数 * 每个始终ROP可以处理的像素个数。
- TBR(Tile-Based(Deferred)Rendering)是目前主流的移动GPU渲染架构,对应一般PC上的GPU渲染架构则是IMR(Immediate Mode Rendering)。
- TBR:VS-Defer-RS-PS
- TBDR : VS - Defer - RS - Defer - PS
三、IMR(Immediate Mode Rendering)
参考3.4作业

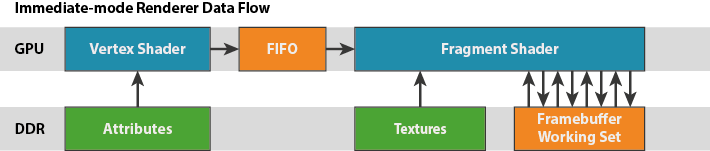
IMR流程图:
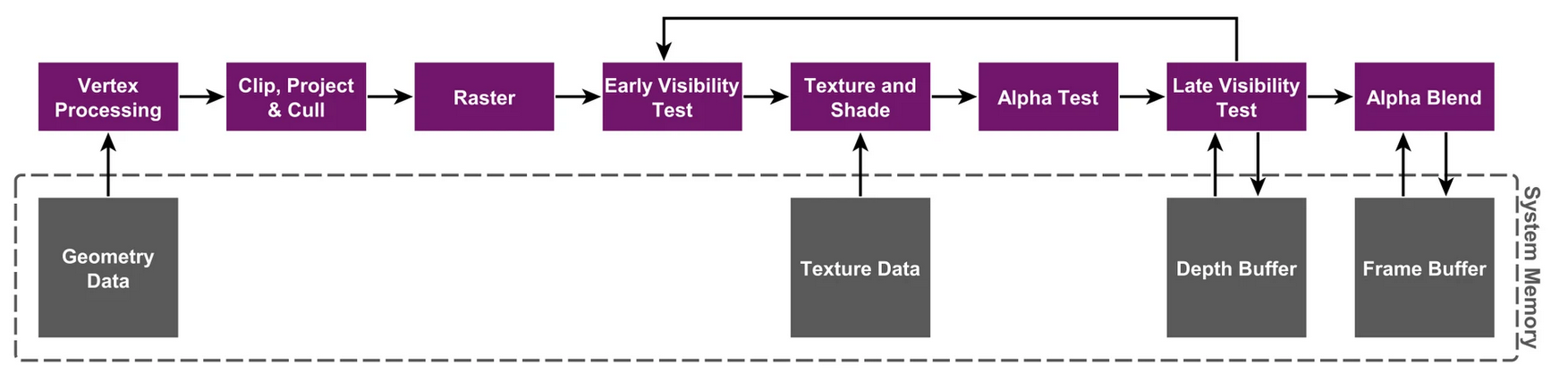
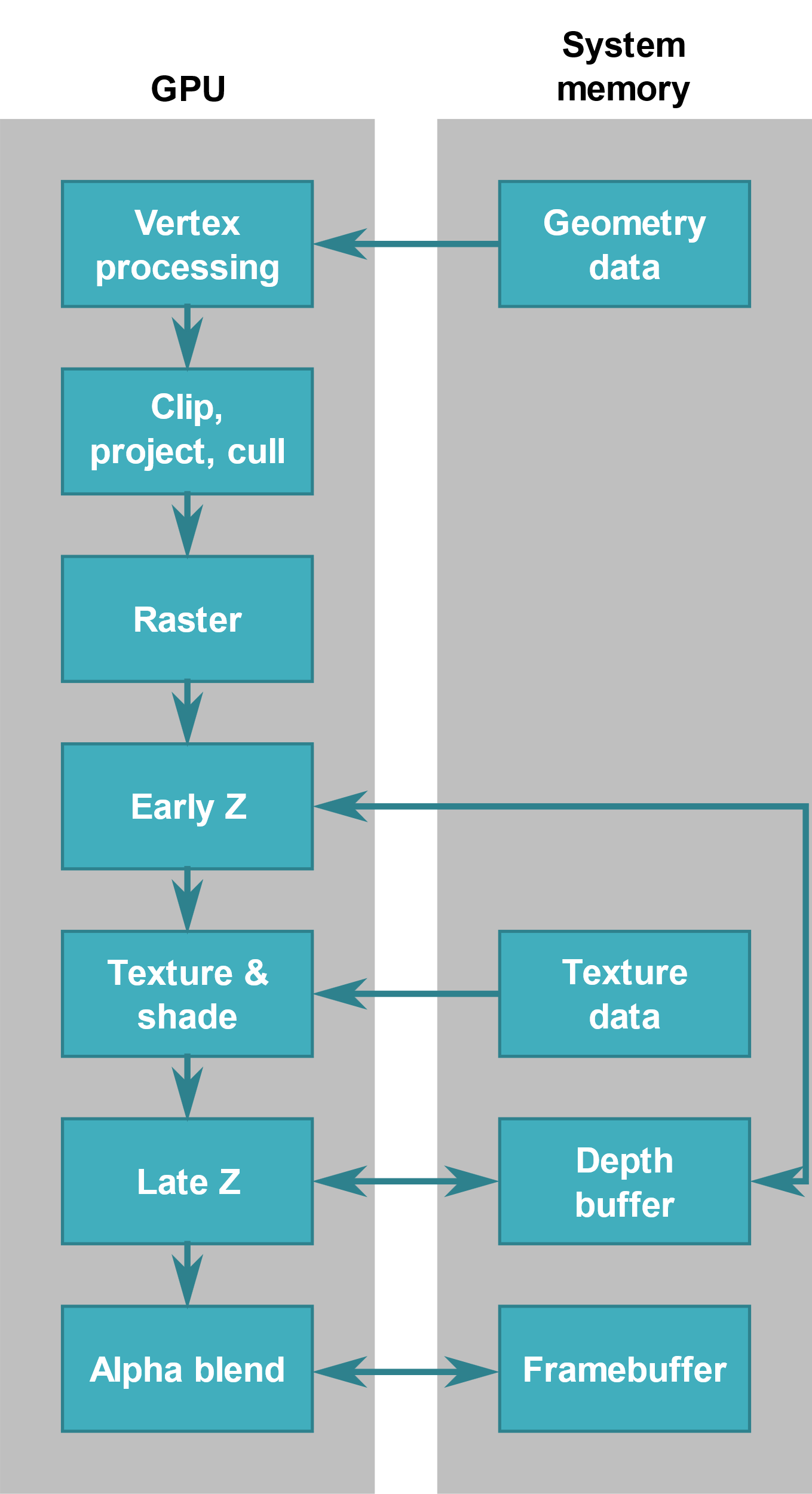
四、TBR & TBDR
参考3.4作业
TB(D)R 宏观上总共分2个阶段
- 第一阶段,执行所有与集合相关的处理,并生成Primitive List(图元列表),并且确定每个tile上面有哪些primitive。
- 第二阶段,将逐块执行光栅化及其后续处理,并在完成后将Frame Buffer协会到System Memory中。

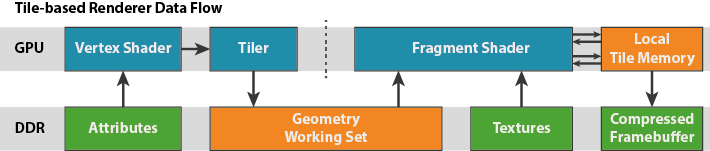
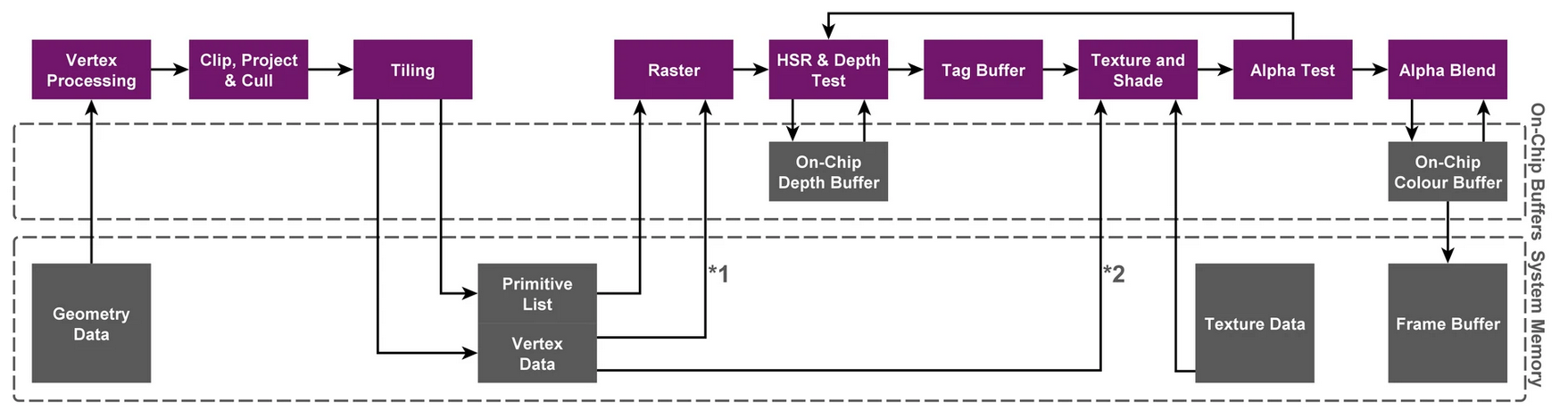
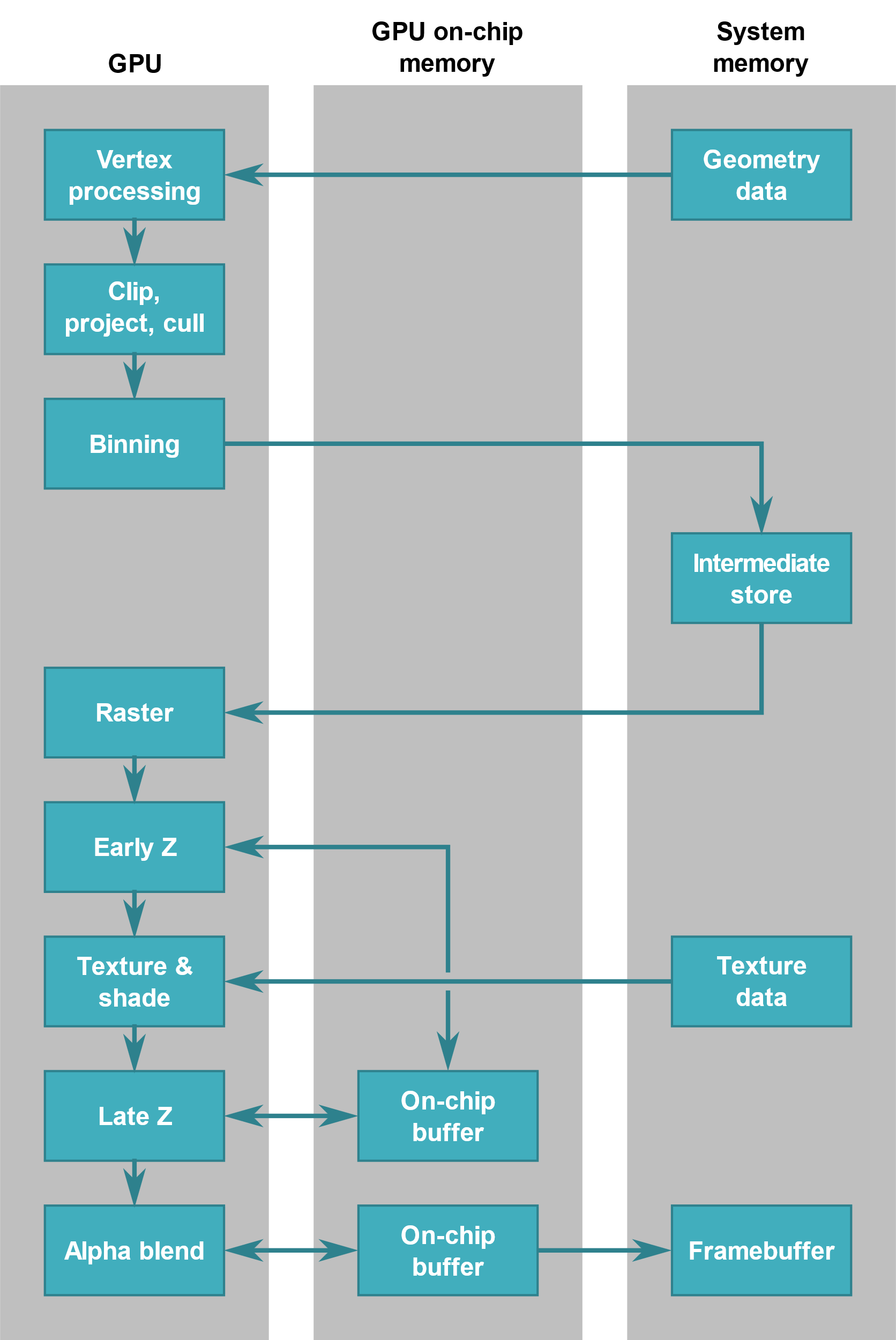
TBR简化版示意图:
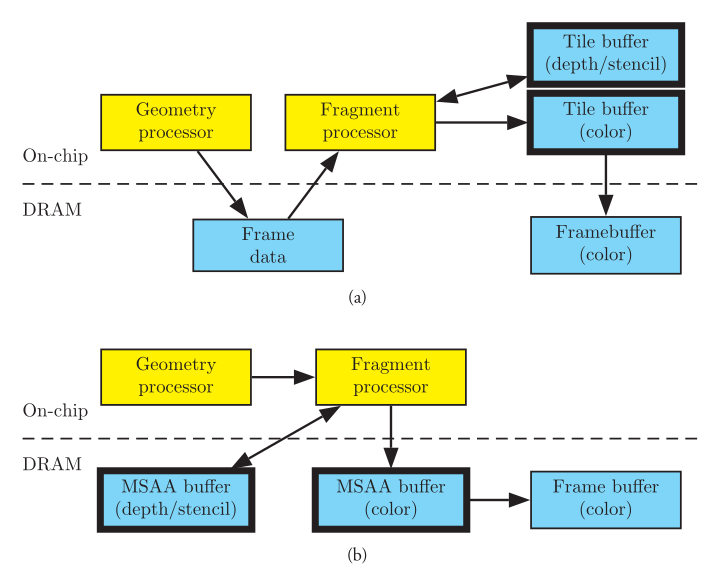
TBR的核心目的是降低带宽,减少功耗,但渲染帧率上并不比IMR快。
- 优点
-
- (1)TBR给消除Overdraw提供了机会,PowerVR用了HSR技术,Mali用了Forward Pixel Killing技术,目标一样,就是要最大限度减少被遮挡pixel的texturing和shading。
- (2)TBR主要是 cached friendly, 在cache里头的速度要比全局内存的速度快的多,以及有可能降低render rate的代价,降低带宽,省电。
- 缺点
-
- (1)这个操作需要在vertex阶段之后,将输出的几何数据写入到DDR,然后才被fragment shader读取。这之间也就是tile写入DDR的开销和fragment shader渲染读取DDR开销的平衡。另外还有一些操作(比如tessellation)也不适用于TBR;
- (2)如果某些三角形叠加在数个图块(Overdraw),则需要绘制数次。这意味着总渲染时间将高于即时渲染模式。
五、不同GPU的Early-DT
- Android——Qualcomm Adreno
-
- 采用外置模块LRZ。在正常渲染管线前,多执行一次VS生成低精度depth texture,以提前剔除不可减的Triangle。
- 说白了,就是直接用硬件做Occlusion Culling,功能类似软光栅遮挡剔除。因为做LRZ时执行VS只需要用到position信息,所以单独抽出position stream,能带来bandwidth和cache的优化。
- Arm Mali采用Forward Pixel Kill技术
-
- 位于管线的位置:发生在Early-z之后
- 数据模型:先进先出的队列
- 后面详细说下Mali
- PowerVR的HSR
-
- HSR = Hide Surface Removal隐形面剔除
- 大体实现原理
-
-
- 从相机射出一根射线,当它遇到第一个不透明物体时会停下来,这样就会打断后面三角形后续PS处理。
-
六、Arm Mali GPU
参考链接:
https://www.youtube.com/watch?v=tnR4mExVClY
1.介绍与移动端系统
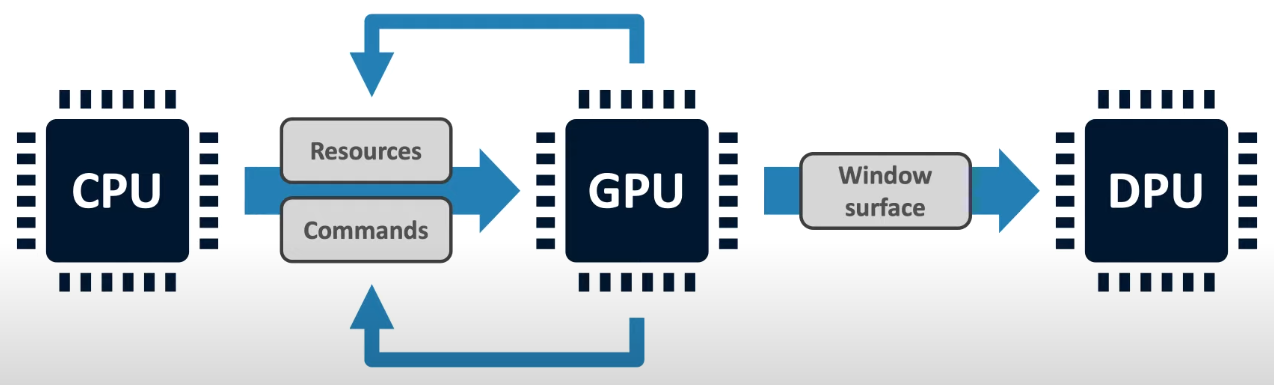
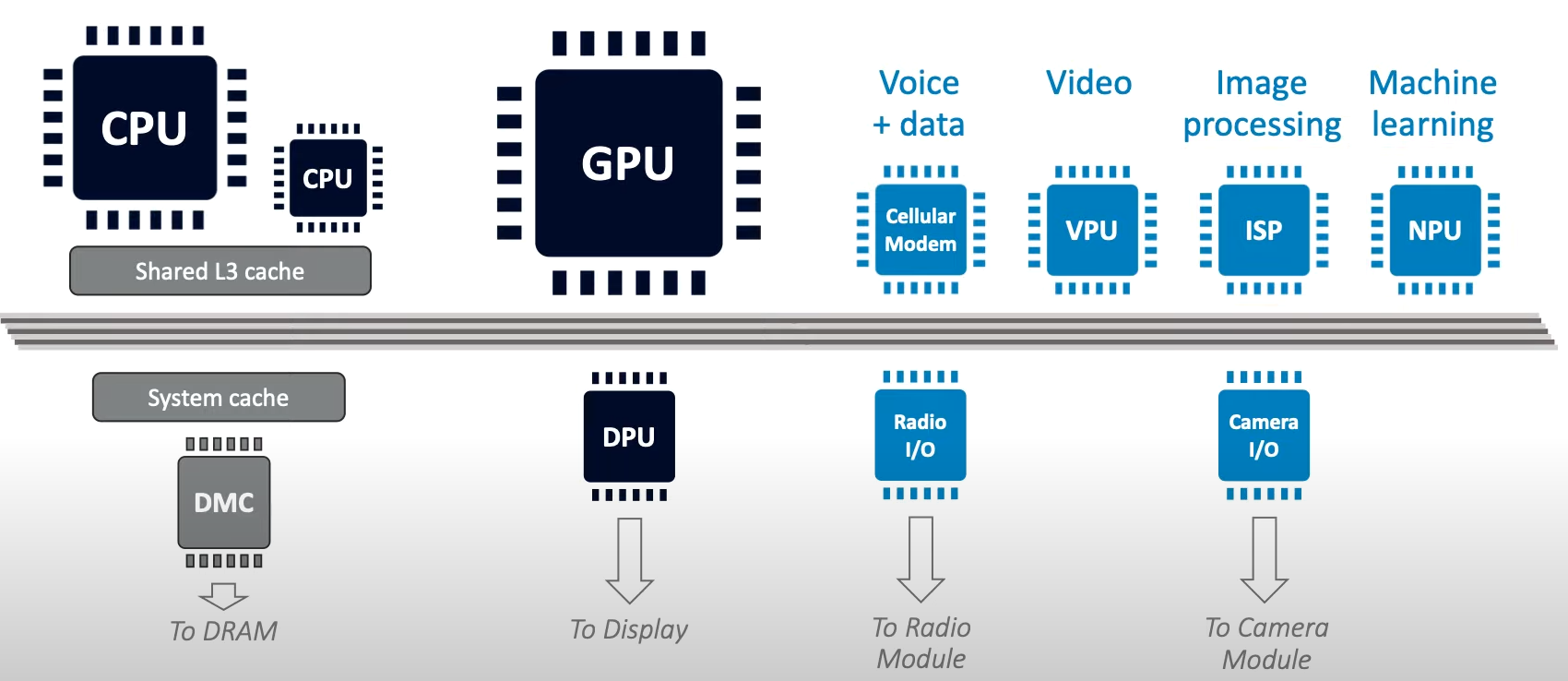
- CPU:用来负责应用程序和驱动程序。
- GPU:负责图形渲染工作
- DPU:负责将影像正确的显示到荧幕上。
- 流程:CPU负责准备模型、贴图等资源,并且向GPU发送命令->GPU将准备好的图形传给DPU->DPU进行显示。
- GPU也可以通过Shader产生一些指令,生成些资源。
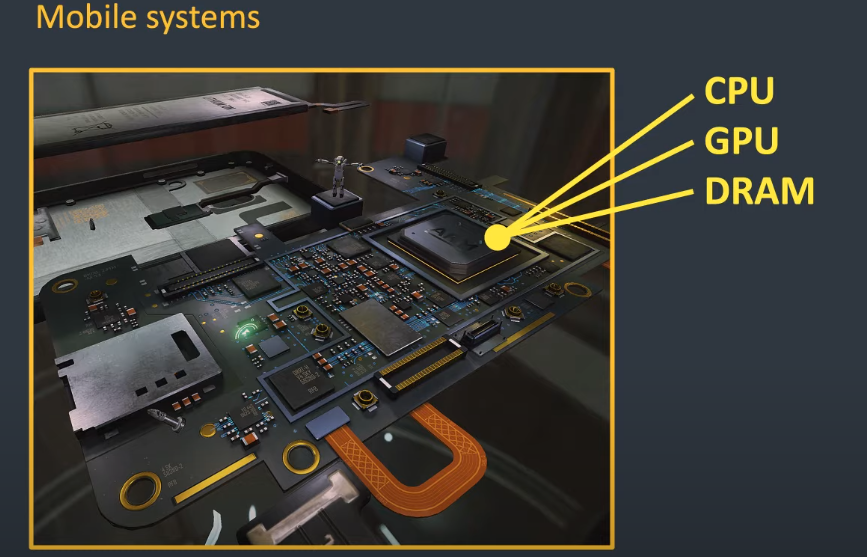
ARM芯片图
- “大”CPU:运行速度。
- “小”CPU:数量多,运行速度慢,系统会将一些运算量简单的计算丢到“小”CPU里,达到效能最大化。
- DRAM:用来存放程序和一些数据。手机的话GPU与CPU会共享存储,而电脑各自有各自的存储空间,其中独立显卡的存储空间又叫做VRAM。存储数据这部分(DRAM)会非常耗电,每1GB/S信息会花费大约100(毫瓦)mw的电力。如果打算分配0.5W的电力在DRAM上,大约可以达到5GB/s的流量,但如果是以60FPS来算的话每个画面大约分到85M的数据,而且这是包含了所有CPU、GPU以及DPU的内存总流量。
- DPU:处理图片的合成、缩放、旋转以及色彩系统的转换等等,而且需要再一定时间内完成。因此在GPU正确的设置,会分担些它的工作,
- CellularModem:负责通讯的数据机。
- VPU:影像压缩以及解压缩处理器。
- ISP:处理照相机影响的讯号处理器。
- NPU:机器学习的加速器。
CellularModem、VPU、ISP、NPU会分配到2~3W的电力来运作。
效能与耗能比
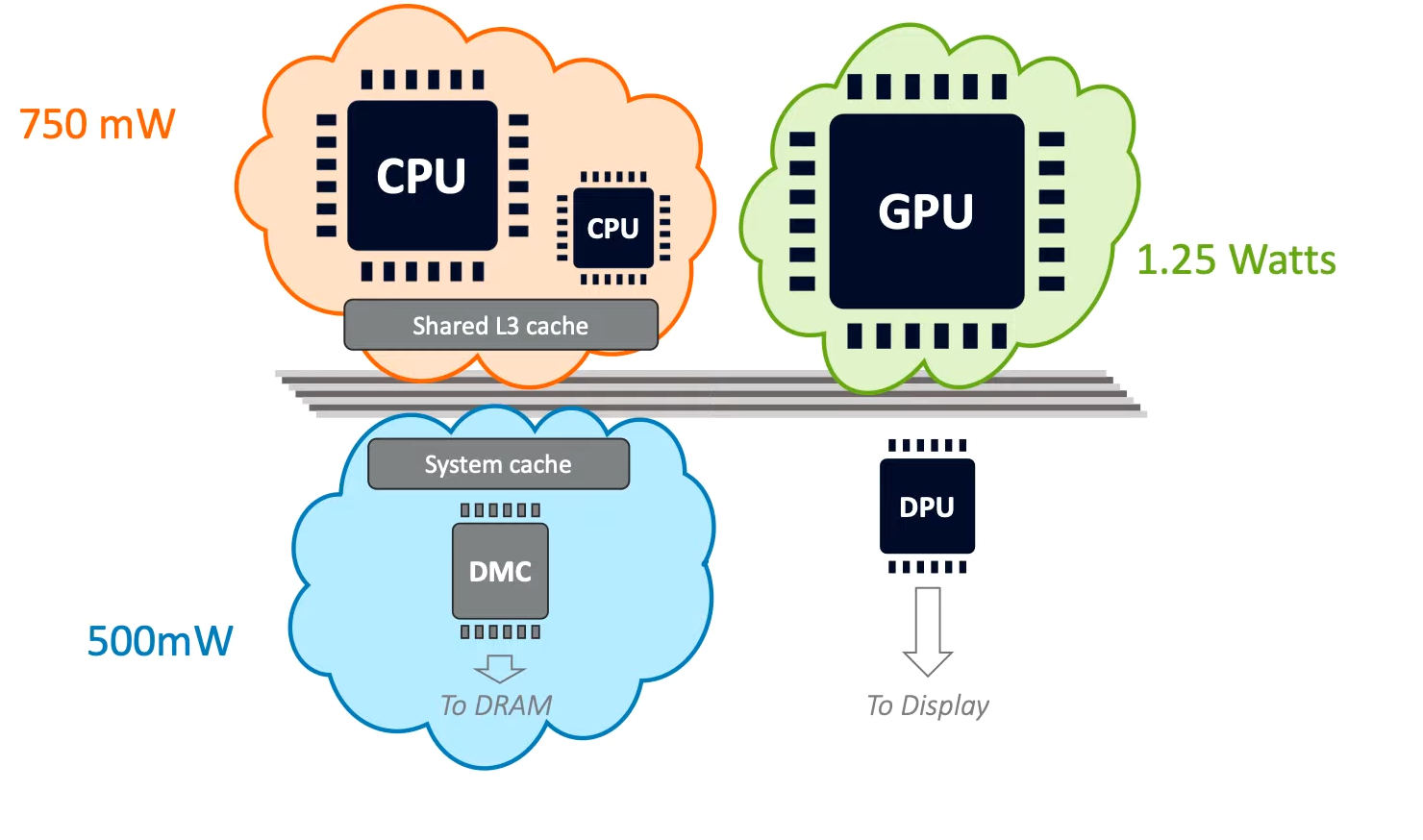
2.5W的电力分配图(DPU耗电极小忽略掉)
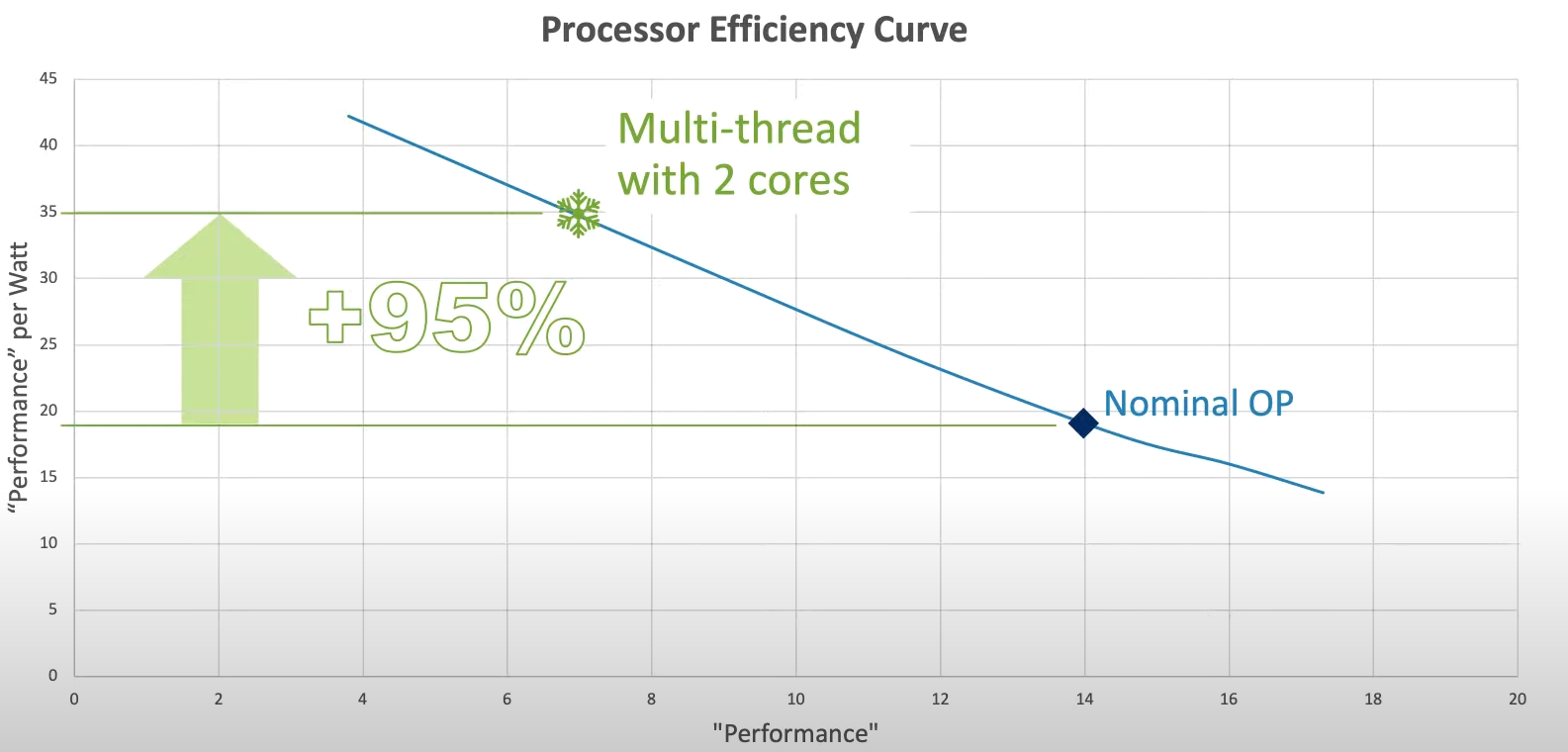
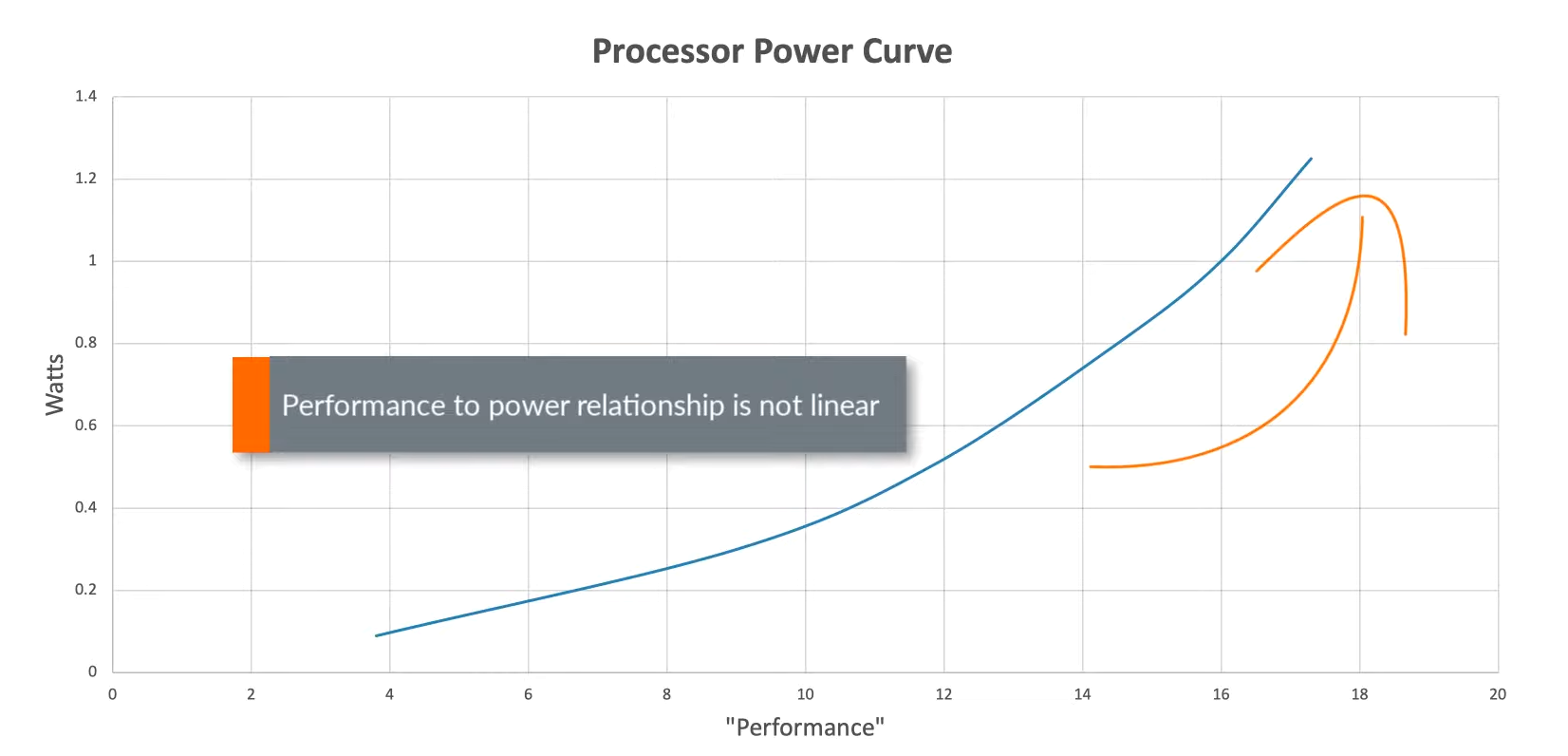
效能与每瓦效能比
可以看出在最大效能(Nominal OP 14分)时,每瓦单位效能比(18分)。
如果将频率降到一半,使用降频后的电压来去驱动CPU那么效能分数会降到7分,但是每瓦效能比可以提高到35分。如果把工作平均分配到两个平行的执行绪上同步处理,则效能分数又可以回到14分,但是却只要消耗一半的电力。
这告诉我们,在一个拥有多CPU丛集的系统上,不论是CPU或者GPU,都是被设计来将复杂的工作分散到多个单元上处理,借此来达到高效率的电力使用,多处理器的设计让更多复杂的应用可以在降频的状态下顺利运行,从而节省电力消耗,因此只要确保工作能被有效的分散到多个执行绪上就可以了。
2.GPU架构
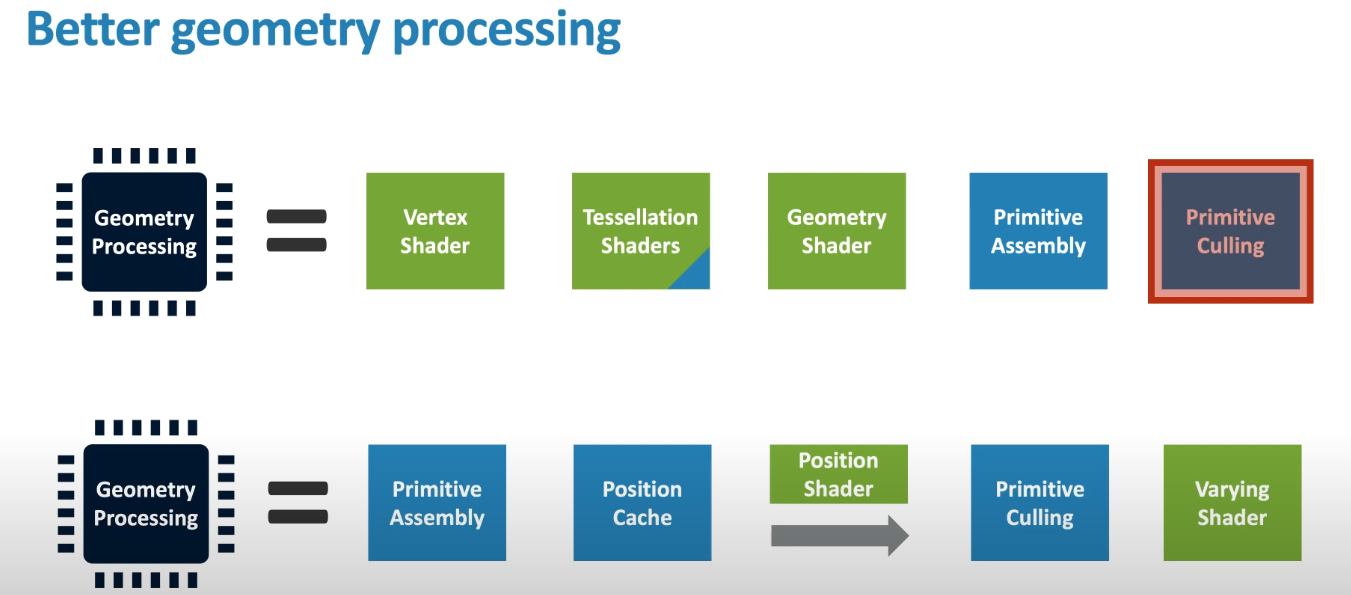
上面是传统GPU管线流程,下面是Mail GPU管线工作流程
IMR渲染流程
此处为语雀视频卡片,点击链接查看:录制_2021_11_25_00_22_13_231.mp4
IMR渲染流程
FIFO:缓冲区,规则先入先出,将三角形推入FIFO缓冲区中,当空间满后,等待Pixel Processing处理。
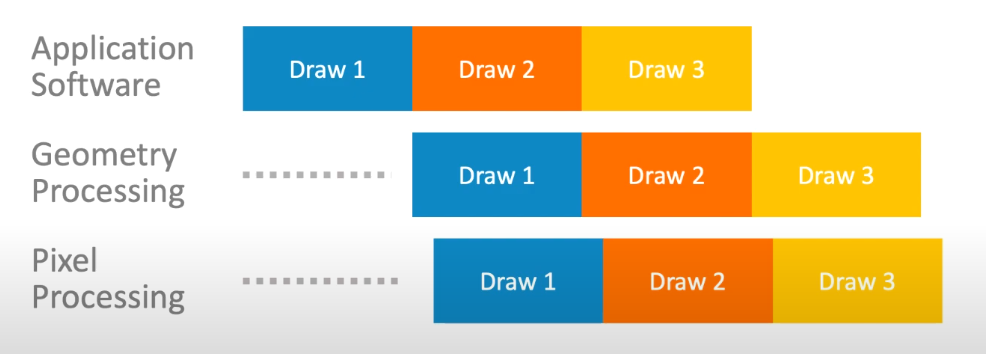
当三角形被推入FIFO中后,像素着色器可以立即进行处理。
此处为语雀视频卡片,点击链接查看:录制_2021_11_25_13_54_10_276.mp4
IMR渲染流程
TBR渲染流程
此处为语雀视频卡片,点击链接查看:录制_2021_11_25_12_52_52_693.mp4
TBR流程中没有FIFO,取而代之的则是tile。

- 所谓的Render Pass会在最后一个Drawcall后产生。
- 几何处理必须先完成才能建立Tile。
- 接着像素处理才开始。
此处为语雀视频卡片,点击链接查看:录制_2021_11_25_12_57_11_612.mp4
TBR渲染流程
每个Tile会在Fragment的渲染完成后才将结果写入内存中,Drawcall有时会在Tile之间交错进行。

shader里写 if else语句会导致执行绪空间利用率不足,因此要避免此类操作。
七、移动端Tile Based Render的优化
- 记得不使用Framebuffer的时候clear或者discard
-
- 主要是清空积存在tile buff上的 frame Data,所以在unity里面对render texture的使用也特别说明了一下,当不再使用这个rt之前,调用一次Discard。在OpenGL ES上善用glClear,gllnvalidateFrameBuffer避免不必要的Resolve(刷system memory)行为
- 不要在一帧里面频繁的切换framebuffer的绑定
-
- 本质上就是减少tile buffer 和system memory之间的 的stall 操作
- 对于移动平台,建议你使用 Alpha 混合,而非 Alpha 测试。在实际使用中,你应该分析并比较 Alpha 测试和 Alpha 混合的表现,因为这取决于具体内容,因此需要测量,通常在移动平台上应避免使用 Alpha 混合来实现透明。需要进行 Alpha 混合时,尝试缩小混合区域的覆盖范围
- 手机上必须要做Alpha Test,先做一遍Depth prepass,参考参考目录的[Alpha Test的双pass 优化思路]
- 图片尽量压缩 例如:ASTC ETC2
- 图片尽量走 mipmap
- 尽量使用从Vertex Shader传来的Varying变量UV值采样贴图(连续的),不要在FragmentShader里动态计算贴图的UV值(非连续的),否则CacheMiss
- 在延迟渲染尽量利用Tile Buffer 存储数据
- 如果你在Unity 里面调整 ProjectSetting/Quality/Rendering/Texture Quality 不同的设置,或者不同的分辨率下,帧率有很多的变化,那么十有八九是带宽出问题啦
- MSAA(增加对framebuffer读取的次数)其实在TBDR上反而是非常快速的。
- 少在FS 中使用 discard 函数,调用gl_FragDepth从而打断Early-DT(HLSL中为Clip,GLSL中为discard )
- 尽可能的在Shader里使用Half Float,如果Shader中仅有少量FP16的运算,且FP16需和FP32混合计算,则统一使用Float,好处:
- (1)带宽用量减少(2)GPU中使用的周期数减少,因为着色器编译器可以优化你的代码以提高并行化程度。(3)要求的统一变量寄存器数量减少,这反过来又降低了寄存器数量溢出风险。具体有哪些数据类型适合用half或者float 或者fix,请查看参考目录的[熊大的优化建议]
- 在移动端的TB(D)R架构中,顶点处理部分,容易成为瓶颈,避免使用曲面细分shader,置换贴图等负操作,提倡使用模型LOD,本质上减少FrameData的压力
参考链接:
[GPU性能指标 ]
https://www.gpuinsight.com/gpu_performance/
[三星的GPU-FrameBuff指导]
GPU Framebuffer Memory: Understanding Tiling | Samsung Developers
[英伟达的TBR教学文章]
On NVIDIA's Tile-Based Rendering | TechPowerUp
[ARM的TBR教学文章]
Documentation – Arm Developer
[苹果OpenGL程序开发指南]
Tuning Your OpenGL ES App
[OpenGL Insights]
https://www.seas.upenn.edu/~pcozzi/OpenGLInsights/OpenGLInsights-TileBasedArchitectures.pdf