文章目录
- 0 背景
- 1 架构
- 1.1 Master
- 1.2 TServer
- 1.3 Tablet
- 2 读写链路
- 2.1 DDL
- 2.2 DML
- 2.3 事务
- 3 KEY 的设计
- 4 Rocksdb 在 YB 中的一些实践
- 总结
0 背景
YugaByteDB 的诞生也是抓住了 spanner 推行的NewSQL 浪潮的尾巴,以 PG 生态为基础 用C++实现的 支持 SQL 以及 CQL 语法的数据库。
设计之初的目标如下:
- 提供一致性能力。通过分布式事务 提供 线性一致性写 ,在 SQL 场景,提供 Seriable, Repeatable Read, Read Committed。在 CQL 场景仅提供 Repeatable Read.
- 提供 通用的查询接口。业界主流的是 以RDBMS 为主的结构化数据的查询接口 SQL 以及 非结构化数据的查询接口 CQL(nosql 体系, cassandra 的查询语言,redis协议等)。这两种接口 YugaByteDB都支持了。
- 提供 高性能。
- 全球部署能力。提供跨 Zone 地域,跨 Region 大洲 级别的部署以及对应的数据复制能力,还有多云部署。
- 云原生架构。可以在任何的公有云/私有云、物理机、容器、虚拟机或者其他商用硬件上部署。没有外部硬件的依赖,比如 原子钟;Kubernetes 的容器化调度也已经完全支持;开源。
后续的介绍对 YugaByteDB 统一称为 YB。
YB 的查询层主要是 YSQL和YCQL 层,YCQL 没有专门的查询优化器和执行器,只有一个语法解析器。YSQL 则复用的 PG的查询引擎,包括 parser,optimizer 和 executor。
YB 架构的核心是在存储层,当然也在向提供AP服务的 mpp 的引擎发力,因为 PG 的执行引擎是火山模型,且是为行存设计,想要服务 AP 场景,性能远远不够。
本篇也主要是看看 YB 的存储层设计,站在 YSQL 角度,可以理解为是PG的存储层的重写。
1 架构
我们启动一个 单机版本的 YB 集群,可以看看其都有哪些进程,以及数据目录的分布形态,这个过程从而帮助我们更好得理解其逻辑架构。
在 MAC 本地,通过 yugabyted 启动集群之后,集群状态如下:

可以看到其对外暴露的配置:
- 副本因子。单机启动,只指定了一个节点,默认就是1副本。
- WebUI。每一个集群会提供一个管理当前集群状态的 web页面,可观测性这种产品能力也是很到位。
- 数据和日志目录。显然并没有暴露元数据管理的相关配置,这也非常合理,用户不需要关注这个。
- 连接YSQL 和 YCQL 的方式。当然,这两种是有不同的访问端口。
再看看进程组的情况:
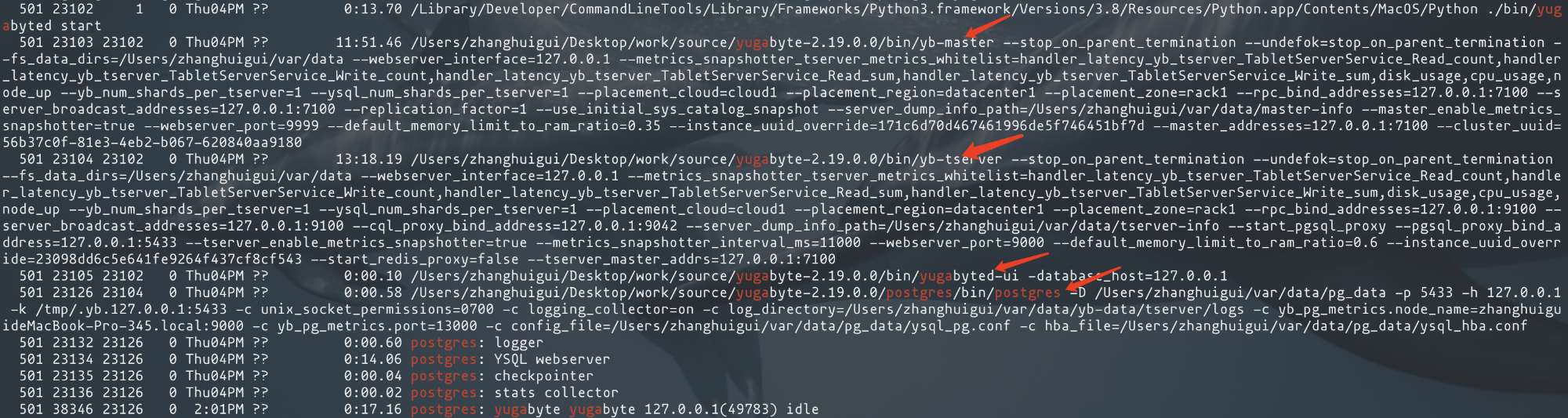
- yb-master 元数据管理的进程,后面会细说,不论有多少个 tserver节点, master最多只会有三个,只要能形成 高可用的 raft-group就可以了。
- yb-tserver 数据存储管理的进程,status展示的 副本因子也是说的 tserver管理数据的副本情况。
- postmaster 进程 以及几个子进程,这个是一个提供psql连接 的无状态 PG进程,兼容 PG SQL 语法,可以处理一些 commands(query),调用对应 YB 处理接口将用户查询请求通过 RPC 发给 tserver 进行查询解析、优化、执行。
- (可选)webserver进程,用于提供集群的可视化展示,就是前面提到的UI页面。
其中yb-master进程和yb-server进程都有各自的数据目录:
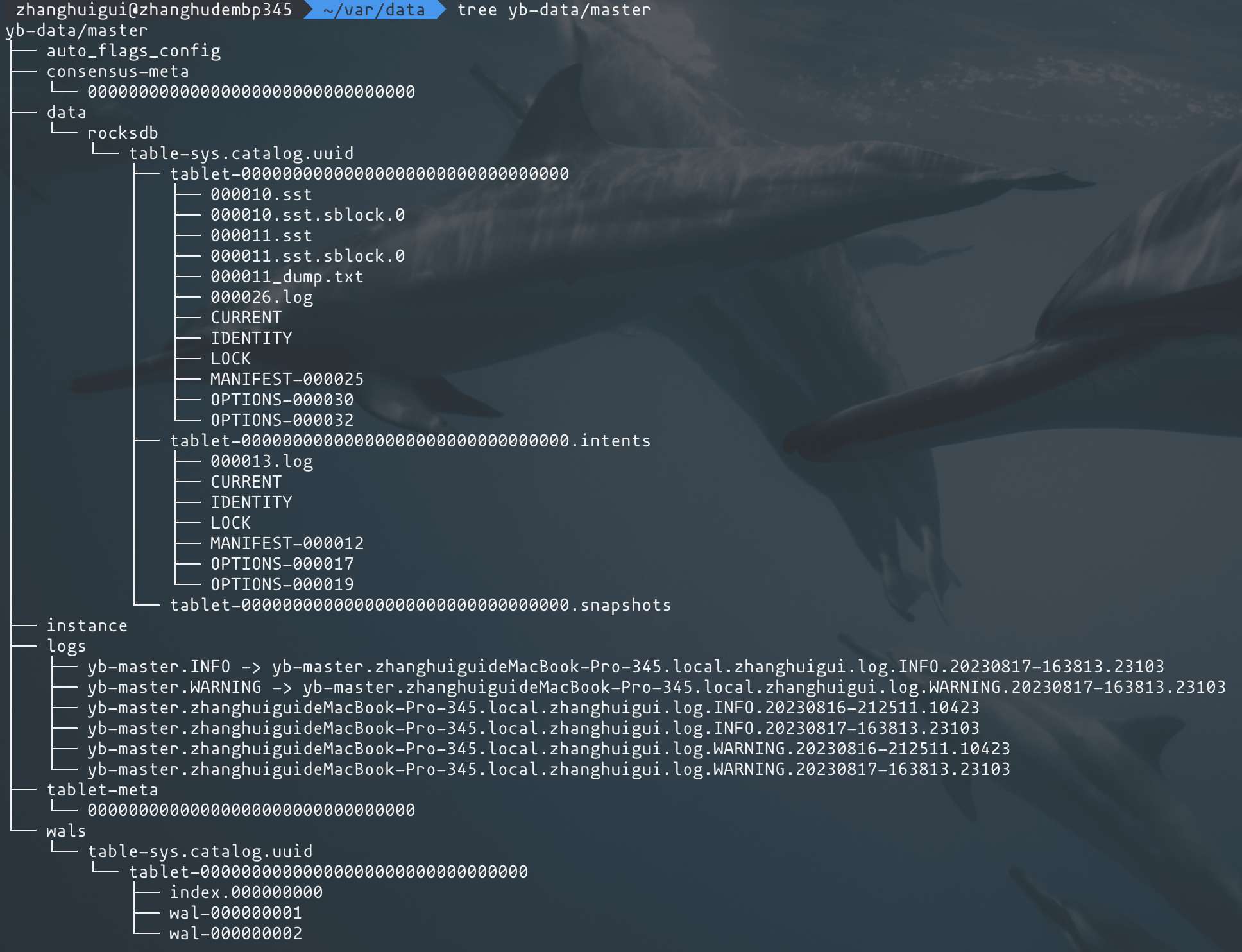
在 yb-data目录下的 master和tserver 数据目录结构都是一样的,在数据表目录之下拥有以 tablet 为子目录的 rocksdb实例 以及 wals目录,保存对应tablet 的 raft-index 和 raft-log。
YB 的核心主要是在 Master 和 TServer 两个进程,接下来看一个官方提供的这两个进程的关系图:

最多三个节点的master进程之间形成了 raft group,通过raft算法的心跳、leader 选举、日志复制的功能来实现高可用;无限 scale out 的 tserver 节点之间也是 raft group,实现数据存储的高可用。
1.1 Master
Master 主要有如下功能:
- 调度集群的 DDL 或者说 集群管理的操作
- 以tablet 为单位 存储元数据
- 负责 tablet 的生成和分发到tserver
- tsever集群 数据的负载均衡、tserver leader 管理的tablet的负载均衡、tserver 节点失败时的数据复制。
前面介绍基本架构的时候会提到 Master 以及 TServer 存储数据的基本单位是 Tablet,Master这里存储 catalog的时候也是 Tablet,不同的 Tablet会在 Master内部形成 raft-group。同样的后续介绍的 TServer存储用户表数据的时候也是以 tablet 为单位,每一个tablet和其他 TServer的副本形成raft-group。
关于 Tablet 工作方式后续会再详细介绍,总之 Master 负责对 所有 Tablet的管理,包括创建、分裂、迁移等。
1.2 TServer
TServer 包含 查询层,即 YSQL 以及 YCQL 的功能 以及 数据存储的功能。

每一个 TServer 存储上可以管理多个 Tablet,不同的 Tablet 与其他 TServer 节点的 tablet 副本会形成 raft-group。一个TServer 节点上 同一个表可能会有多个 tablet,且在同一个表目录下,不同的tablet 在不同的目录,数据是物理隔离,每一个tablet 目录可以理解为一是个 rocksdb实例。
除了查询层之外的所有存储层的功能实现可以理解为都在 docdb中, docdb是一个能够感知schema信息的支持事务的分布式kv存储引擎。
1.3 Tablet
Tablet 支持对表数据的 Hash 分片 以及 Range 分片,Docdb 统一对这一些分片后的 tablet 进行管理。
-
Hash分片下 YB 会选择用户指定的hash-key,比如建表时指定了 id列为primary-key。会取这个列的前两个bytes(16bits)进行hash 映射到对应的tablet中,这样一个表总共会有 2^16 64k个 tablet。
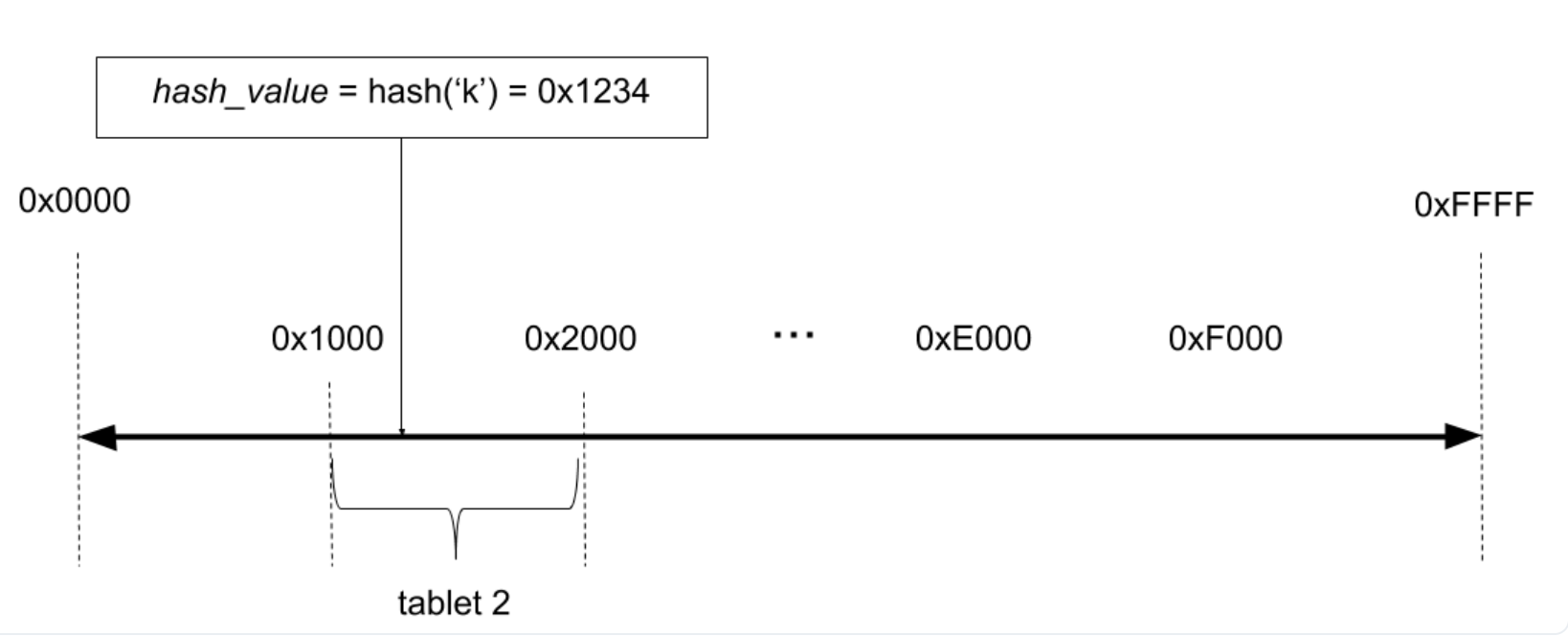
优点: Hash 分片能够尽可能得保证数据跨节点的均匀分布,而且 hash 分片之后的 tablet的管理采用的是一致性hash,在有节点异常或者增加新的节点时能够利用一致性hash 完成高效的tablet 移动。缺点: 这也是所有按 Hash 分片的无奈之初,即 range-scan,比如扫描某一列大于某一个值的所有行,这个成本就会非常高。
-
Range 分片下会将表的主键拆分为多个连续的range,每一个range 作为一个tablet,tablet内部基于主键排序。当然 Range分片下的 tablet 最开始只会有一个,随着数据的插入,每一个tablet的range范围会逐渐增加,到某一个阈值则会触发tablet的分裂。
优点: 当然是range-scan的效率极高,按照上下界扫描某一个表的数据效率是极高的,只需要确认 lower-bound和upper-bound所在的tablet之后 只需要顺序扫描文件就可以了。缺点: range分片的分裂是随着数据的插入进行的,即使用户有很多个可以服务的节点,在没有达到tablet分裂的阈值之前也只能由一个节点调度 query;range 分片下用户的访问热点概率较高,高频访问一段连续的range时负载会集中在很少的几个 tsever节点,这个时候就需要master的参与来为热点访问的节点提供更多的资源。
接下来从 IO 链路 以及 相关的数据存储编码设计 来看看 YB 的存储层是如何实现最开始的目标的。
2 读写链路
数据的读写链路部分 还是以 YSQL为主,YB本身兼容的是PG的协议,这里需要区分DDL 和 DML语句的读写链路。
2.1 DDL
YB 保留了PG 基本所有的的catalog 包括基本的 pg_class,pg_attribute,pg_type等,在initdb的时候写入到 master 集群中 为catalog 创建的tablet中。这样对 catalog的管理就完全集中化了,而且 docdb 对 catalog的数据存储也都是转为了kv,访问也更加符合云上的按需访问的需求,和实际的用户表数据 物理上分离存储又通过docdb统一进行逻辑管理,整体还是非常合理的。后续会详细介绍 YB 对表结构的编码方式。
DDL 主要是对 catalog的增删改查,也就是主要和master进行交互,但是细节上还是会有不少 TServer的参与。
YB实现DDL的数据流转过程如下图:

用户和无状态的 postgres进程建立连接之后,发送的 DDL请求会通过 postgres 进程转发给启动时bind的 tserver的 YQL 层进行 query的解析以及后续的操作。
后续整体的操作可以分为两个部分:
- Master 进程组主要负责将 建表生成的 catalog数据在自己 tablet(initdb时创建好的 PG系统表的存储,以tablet为单位) raft-group内持久化完成 并 根据用户的需求为 TServer 创建对应的 tablet。此时会先向用户返回建表成功,后续的 TServer上的tablet的创建会异步进行。
- TServer进程组 根据Master 分配的 tablet id 异步创建本地的tablet,并按照 master的要求构建一个跨节点的 tablet raft-group。
用户发送建表请求到收到返回,中间会需要 TServer 进行 请求的解析并完成 schema信息的封装,将 schema 通过 rpc 发送到 Master。在 Master上的 DocDB中完成 schema到KV的封装,并通过 raft 完成数据的复制 以及 后续的 apply(将封装好的kv batch写入rocksdb的memtable,raft的复制过程会写raft-log以及raft-index,不需要写WAL;当然这个过程是满足事务语义的,即利用分布式事务完成的线性一致性写)。
后续的 TServer的各个peer上进行 用户表数据的 tablet的创建则是异步进行,master还需要确保 TServer上的各个tablet 都形成了 raft-group,有对应的 leader-peer才算完成。
其他的DDL 也是类似的操作,比如 drop-table,可能由对 catalog的增加变为catalog的对应数据的删除 以及 TServer上 tablet的清理。
2.2 DML
DML 是对用户表的增删改查,本身应只需要TSever的参与,但是在连接的 TServer 第一次访问某一个tablet时需要向 master索取该数据所处的 tablet的leader 信息才行,拿到之后才能到对应的tablet的leader进行数据读/写操作。
以 INSERT 为例,整体数据流如下:
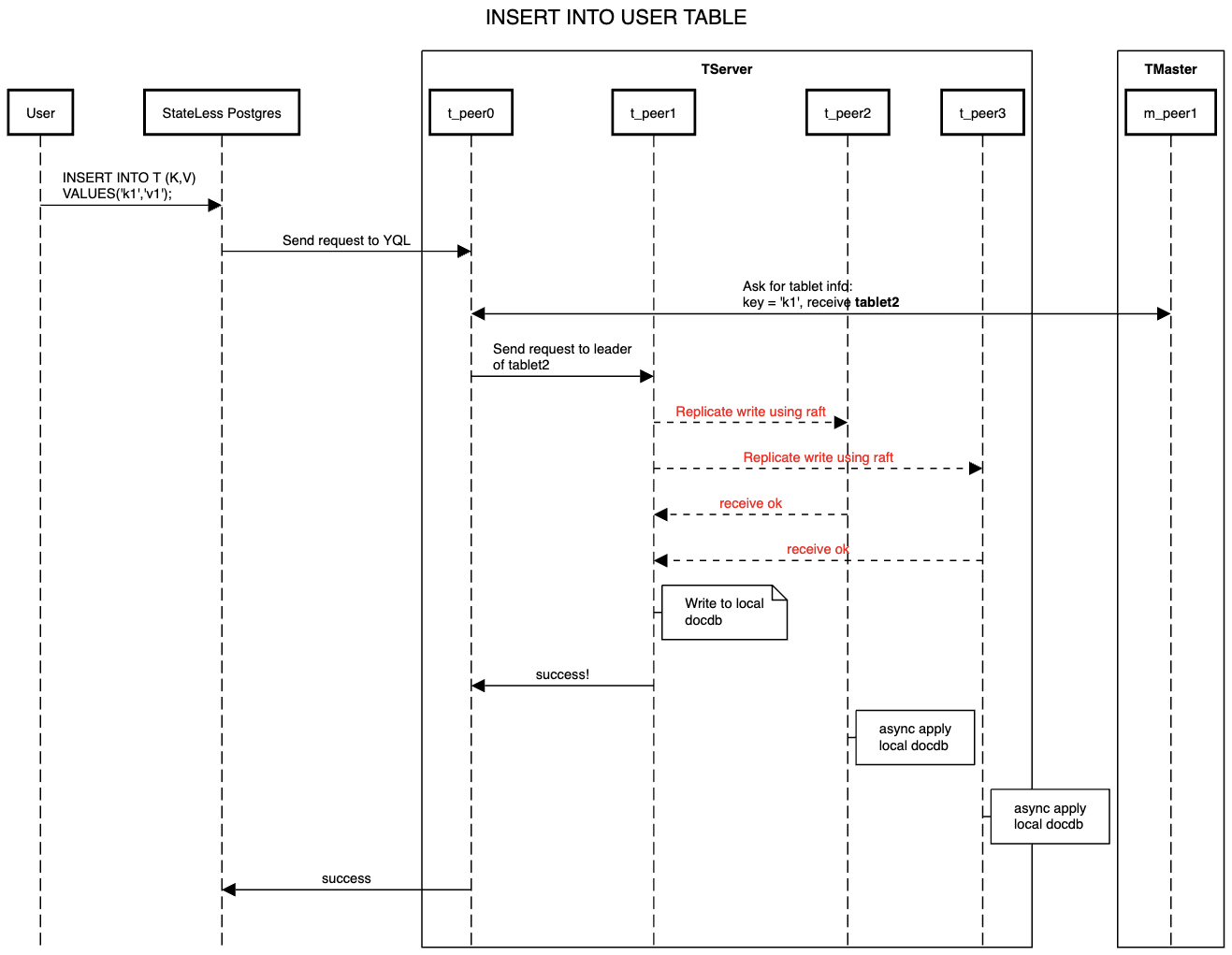
Master 在这个过程仅负责提供要访问的tablet信息即可,其他操作均由 TServer内部完成,且 StateLess Postgres 是一个smart-client,会在自己的内存中缓存访问过的数据的tablet信息,后续对相同range/hash 分片的读写可以不用 t_peer0 以及master的参与,直接去到对应的tablet leader即可。
读请求比较简单,无需复制,从任意一个tablet的peer拿到数据之后会直接返回给客户端。
2.3 事务
事务体系是在 DocDB层实现的,不论是 Master 集群的catalog 持久化到tablet操作还是 TServer的用户表数据持久化到 tablet 操作都会由 DocDB 进行调度,对于每一个请求都会有事务的执行链路,像上面的读写链路因为是单行操作,会直接在tablet leader本地完成,并不需要分布式事务的参与,RPC 会少很多。
但是真实场景,一个事务往往涉及多行数据的操作,多行数据可能还会跨 tablet,这个时候一定是需要分布式事务来保证线性一致性的操作。
YB 在事务隔离级别上的支持,目前对 YSQL 支持 Repeatable Read,Serializable 以及 正在进行中的 RC,因为期望和 PG支持的隔离级别对齐;YCQL 只需要利用 Snapshot支持 Repeatable Read就好了。
实现这几个隔离级别的技术也比较通用:hlc实现MVCC + 乐观锁。
当然,这样的实现目前肯定没有办法和 PG 的悲观事务体系保持一致,不过YB也在向PG的语义兼容,悲观事务也在实现过程中(主要是当前架构的性能问题,不过要支持AP的话 悲观事务体系还是需要有的,AP场景的query执行时间过长,不可能等到提交的时候才发现有冲突而失败,这样的语义用户来说是不能接受的)。所以目前在 OCC的实现下,如果发现两个事务有冲突,则会直接报错,终止其中一个事务的执行链路,不像 PG实现的是 wait-on-conflict语义。当然这个 wait-on-conflict语义也是在实现中,会和 悲观事务一起完成。fail-on-conflict 目前也是用 lock-table来实现,因为所有的写都会发送到对应的leader-tablet,这样对同一个tablet的同一行的修改的冲突检测就可以在一个 TServer的内存中构建 lock-table 并完成检测。
HLC (Hybrid logical clocks)混合逻辑时钟本质是为了提供请求的因果关系,兼容时钟漂移的同时,用较低的成本(TrueTime依赖硬件且成本太高)提供一个全局单调递增语义的序列 且 仍带有时钟属性。因为其本身就是由 physical-clock + logic seq 组成。
关于HLC的细节 以及 算法演进,可以参考之前写过的一篇 计算机的时钟系统演进。
前面说的只是 事务的隔离级别的实现,但是分布式事务的原子性 比如一个事务修改了多个tablet,且这一些tablet分布在不同的peer,如何保证这样的事务的原子性,要么都提交,要么都abort。这个当然是业界通用的实现方案,2PC。
YB分布式事务的写链路如下:
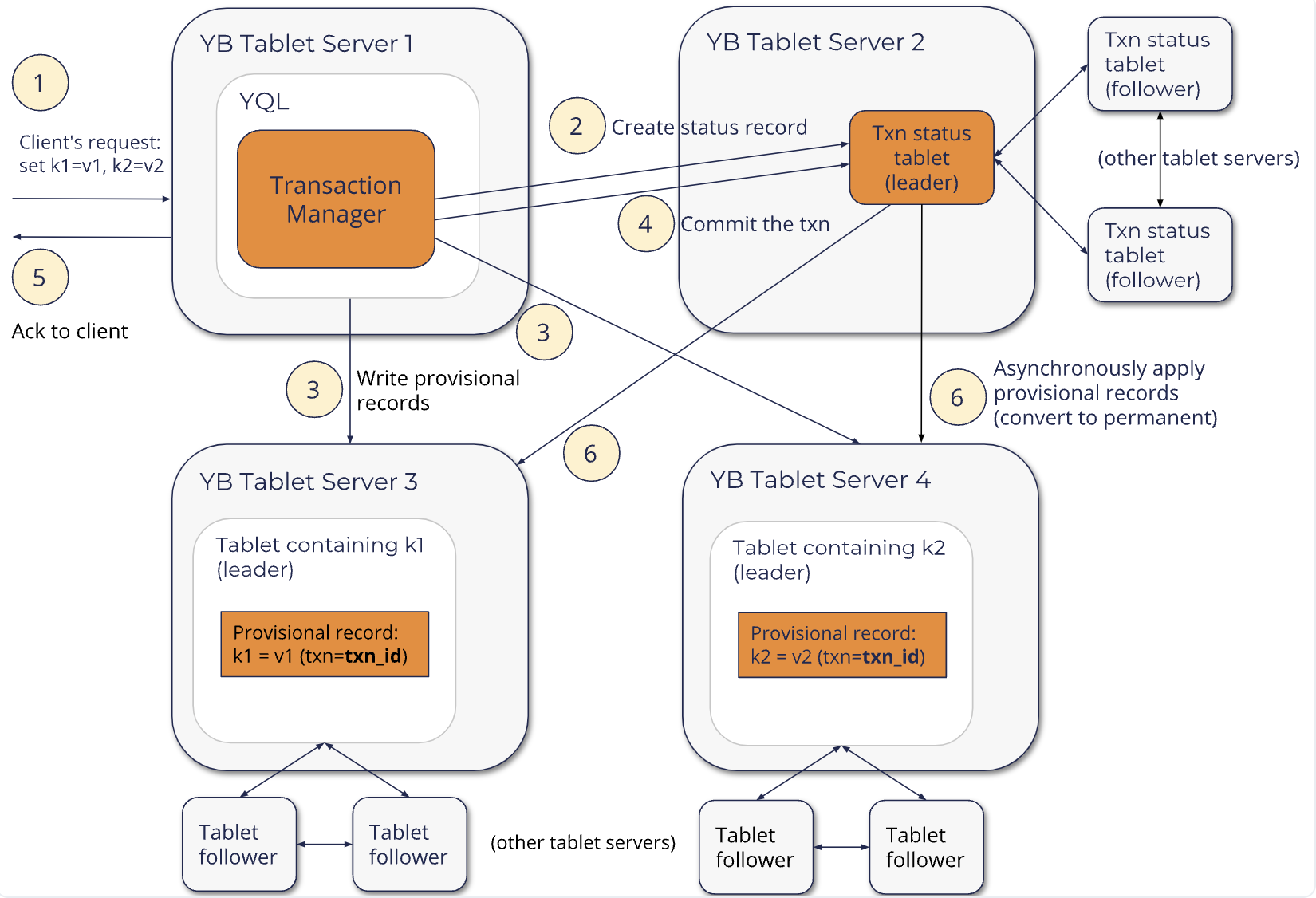
Prepare阶段 主要做的事情有两件:
- 创建一个保存事务状态的额外的tablet:TxnStatus tablet,并向其中写入当前事务的状态信息为pending。事务状态主要服务于可见性,和PG的clog作用一样。
- 向存储数据的tablet 写入临时记录;这里其实还没有到apply,即写的是raft-log,临时记录 主要包含当前事务的 txn-id,要修改的key以及value,不对其他事务可见的hlc 序列等。这个过程中也会做冲突检测,进行fail-on-conflict操作。
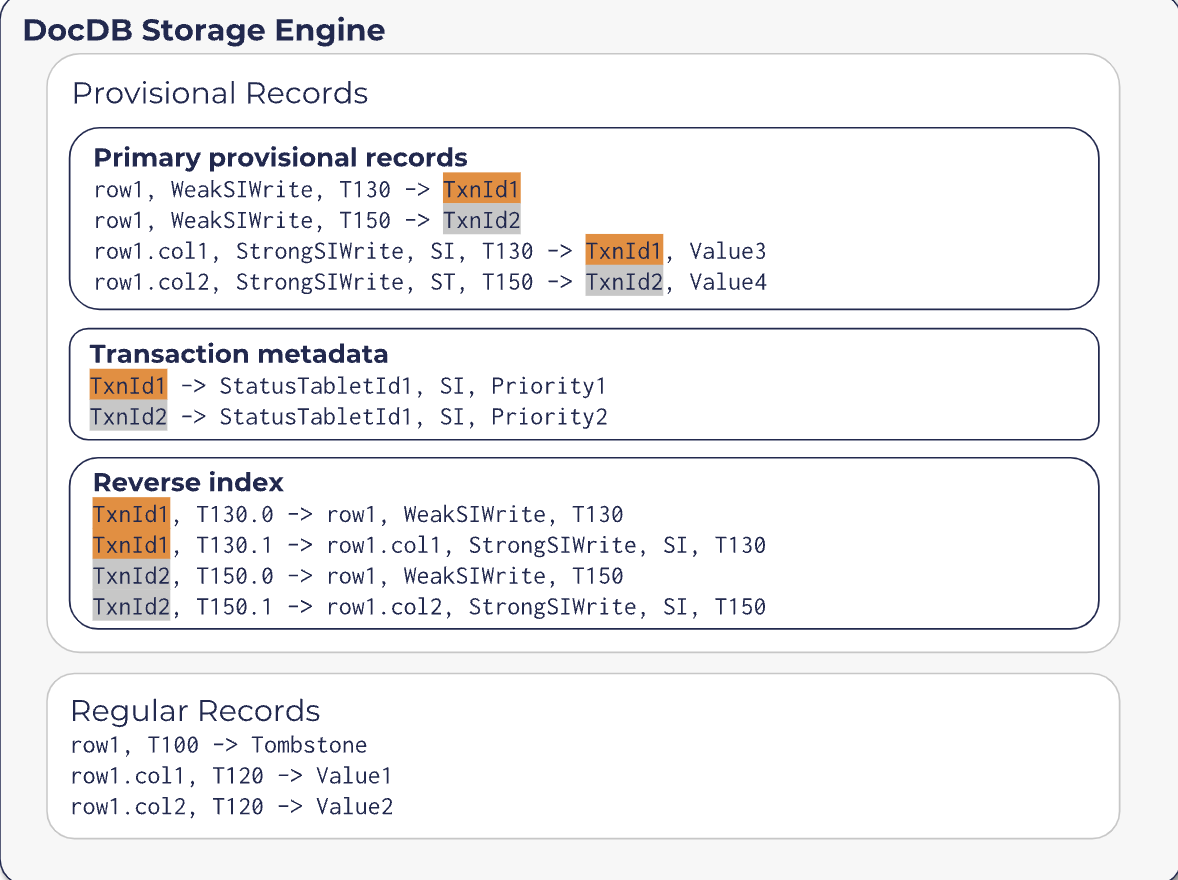
上图是向数据的 tablet中写入的当前事务的临时记录,–> 前后分别是 key和value。
其中 Primary provisiional records中的key格式如下:
- 比如
row1, WeakSIWrite, T130 --> TxnId1表示 TxnId1 对于row1这一行加了WeakSIWrite级别的行锁,且这个key的 hlc版本是 T130。 row1.col2, StrongSIWrite, SI,T150 --> TxnId2, value4,TxnId2 对row1 col2的修改加了StrongSIWrite的冲突锁,且hlc版本是 T150。- 还有事务的元数据,也是保存某一个事务ID以及其对应的 TxnStatus Tablet信息、隔离级别 以及 该事务的优先级等等。
Commit阶段:
Commit时会向 Txn Status tablet发送rpc, 当前事务没有冲突时commit才会成功。Commit成功,则所有的临时数据记录将立即对其他client可见 – 这块猜测是修改了当前事务的 hlc的可见性,比如将最新的hlc(YB里面有一个 safe-time)版本推进到当前事务提交的hlc,否则不太可能说立即可见,类似PG的 latestCompletedXid,这样的实现高效且简单。
Commit完成之后会异步进行数据的apply完成后会临时记录和 当前事务在 Txn Status Tablet的事务状态的清理。
3 KEY 的设计
前面有简单提到过事务部分的临时记录的key的形态,接下来看看 YB 的DocDB如何 将表结构转为kv的。
整体来看 YB 在未来会考虑支持两种形态:
- 将一个表的一行数据编码为多个k/v,这样主要对更新非常友好。但是缺点也很明显,空间放大比较严重,各种标识会被反复存储(hlc,行标识 等);且插入放大太严重,一个insert需要放大为多个kv的插入。
- 一个表的一行编码为一个k/v,这个对读以及 insert非常友好,且空间放大可控。尤其是大宽表,优点上会放大更多。缺点的话就是修改 以及 compaction的成本很高。
当然这两种编码方式都有其适用的场景 以及 痛点的解决方案,目前 YB 还是只支持 第一种编码方式,第二种还在测试中(Packed row format)。
第一种的 Rocksdb k/v 的 编码方式实现如下:
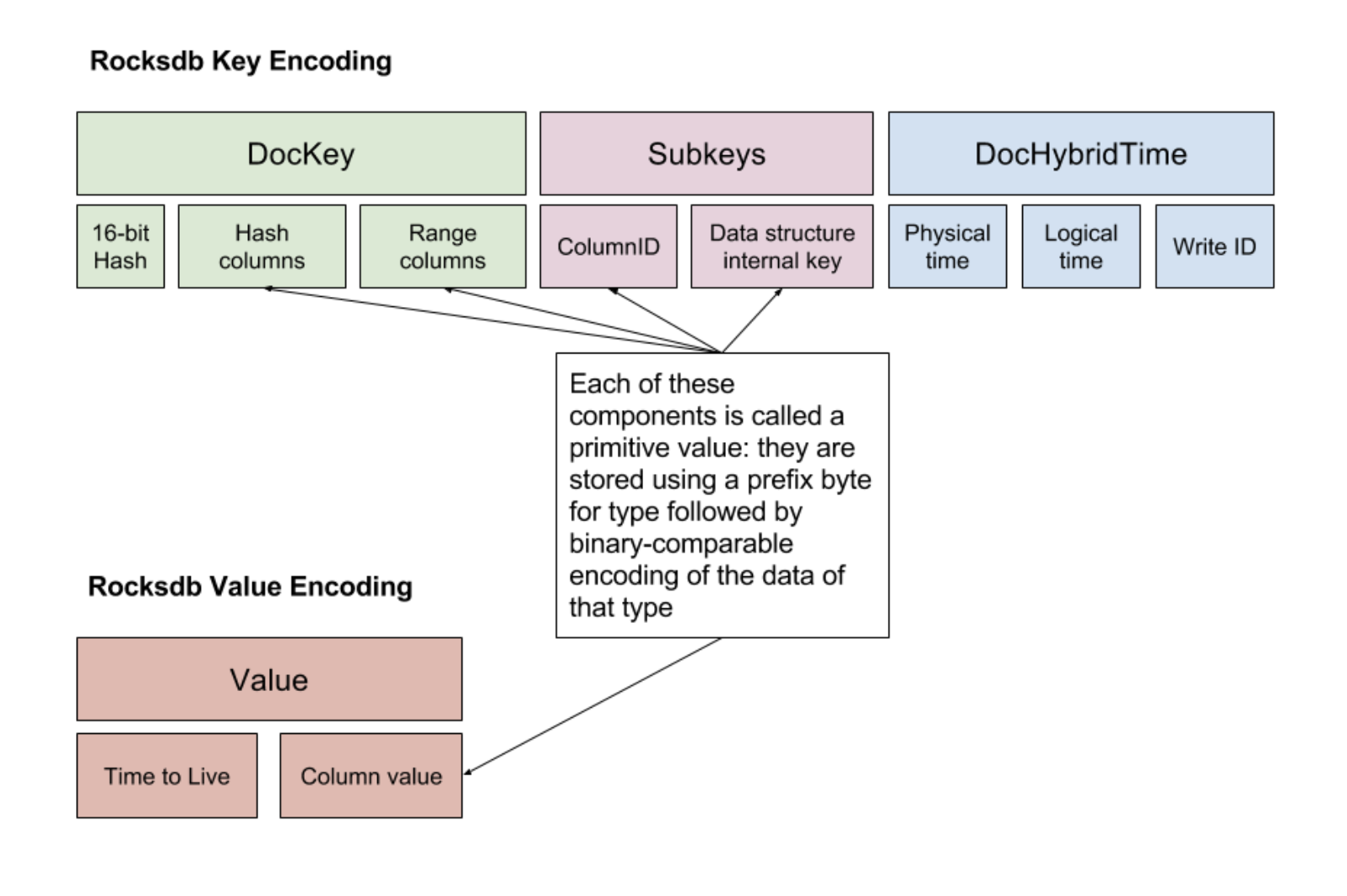
DocKey 是用来标识行,即利用表的主键key的hash值+一个type 来标识SQL的行 或者 CQL的行,type可以用来区分当前key是 hash分片还是 range 分片。
Subkeys 则进一步标识 YSQL 表的列id 或者 CQL的某一个数据结构(set/map/list等)。
DocHybridTime 则是一个 hlc时钟的标识。
Value 在 YSQL下存储的是 列的值,YCQL value 存储的TTL,超过这个时间则需要被清理。
对于 YSQL 来说,我们的数据库表数据的存储会有不少冗余,对于一行来说每一个列都是一个独立的k/v,但是 docKey则需要存储多次(相同前缀的话在Rocksdb是连续存储,虽然对压缩比较友好,但是空间放大仍然是比较严重的),而且insert性能随着表的列宽的增加,性能会越来越差;当然 update/select 性能也还是能够接受的。
4 Rocksdb 在 YB 中的一些实践
在 YB 中,不论是 Master还是 TServer 上,每一个tablet 都是一个rocksdb实例,数据部分的存储都是放在Rocksdb 上,所以对 Rocksdb 也算是深度使用了。
Rocksdb 功能的选择上:
-
因为已经有 raft-log了,且本身是先写raft-log,所以会关闭 rocksdb的wal功能。这里会有一些工业实践的一些问题,如何确保raft-log的回收是正确的,不会被误删除。需要利用 rocksdb-flush时的一些 event-listener机制来去追踪 flush完成的最新的raft-log的序列(hlc序列),这个 hlc 之前的所有的raft-log是都可以被安全清理的。
-
YB 的DocDB的 MVCC实现是跨多Rocksdb实例的(分布式事务,且跨多tablet),所以没有办法使用 Rocksdb本身自带的MVCC以及事务机制,实现过程中看代码是参考了不少 Rocksdb的实现,比如lock-table部分。YB 使用了 rocksdb 提供的 timestamp 功能,将hlc编码到了key里,作为internal-key的一部分,原本rocksdb自己实现的单db内递增的 sequence 是没有必要存在了,这块也被移除了,节省了空间。
使用 Rocksdb 加速YB性能:
- 为 range-scan 构造适配特定数据结构的bloom-filter。这里是可行的,rocksdb有提供 table-filter功能,可以在生成sst的过程中感知特定的数据类型,记录一些信息到 properties中,后续可以在scan的时候使用自己实现的table-filter来做一些数据结构的统计或者检测是否存在这样的类似bloom-filter的功能。
- 可以利用 rocksdb 提供的 table-collector功能,同样生成sst的时候记录一些统计信息到table-properties中,比如记录一些列的min/max/sum 这样的统计信息。后续scan tablet 读取数据的时候内存可以缓存大量的sst的 property-block,在有 上下界 这样的查询语句的时候就能实现 sst-skip,从而跳过大量的sst的访问。
- 内存利用率的提升。block-cache是可以进程内所有 rocksdb实例共享的,能够提升内存利用率,也可以实现自动的热点缓存(某一个tablet数据访问较为频繁,block-cache缓存其 block 可以更多一些)。 memtable的总大小也可以实现跨实例控制,比如可以利用rocksdb-options 搭配一些内存监控测策略来合理 控制当前 TServer进程内所有的 tablet memtable(memstore)内存占用大小。
当然实际肯定还会有一些工业上的问题,比如 TP场景的延时问题,raft-log写盘和memtable-flush 可能会导致磁盘有大毛刺,这个时候有一些rokcsdb的配置以及内核配置能够比较好的解决这一些问题 (比如:ratelimiter + directio_in_compaction/flush–参数忘记了) 。
当然 ratekeeper这种因为有事务流的存在,肯定实在上层做更为合适,比如 YB 就在master实现了这一些功能。
总结
因为个人有一些 Rocksdb 的经验,看到 YB 在Rocksdb上的实践,其实还是有较为可控的研发成本。至少有一个极为稳定的单机k/v存储引擎,以及 TP场景稳定的PG高性能查询引擎,这样 前期 YB 只需要将人力集中投入到存储部分 且用一套较为统一的存储来调度数据以及元数据的读写,真的可以将存储部分做的非常精。
当然 数据库的发展需要跟随时代,如今的云原生数据库 以及 AP 数据库的需求,YB也想要加入,那么新的存储格式的设计(列存:目前这样的key的设计其实也能满足列存的需求了, rocksdb原生append-only 且有工业级的 compaction 以及 压缩实现,每一行的多列在存储上其实也是集中在同一个sst文件内的data-block),新的查询引擎也就需要更多的投入。