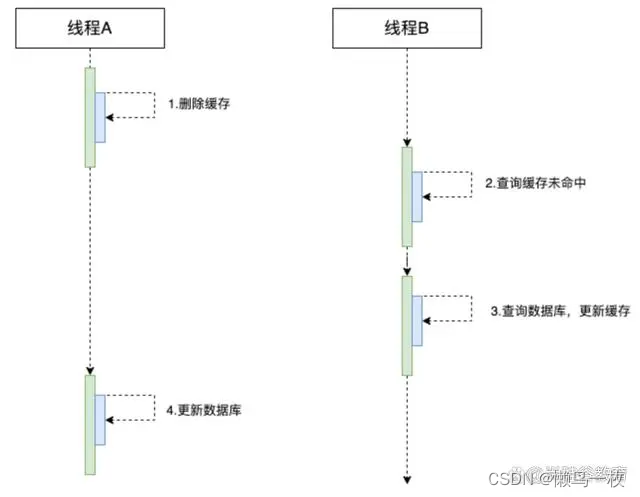
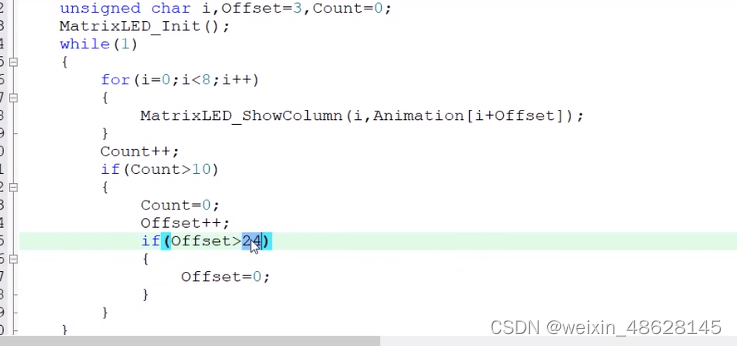
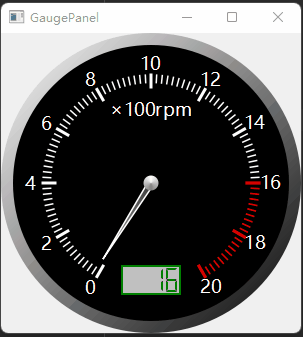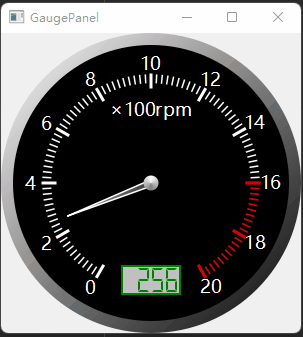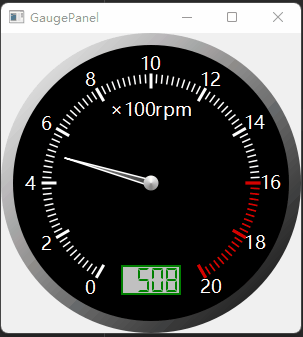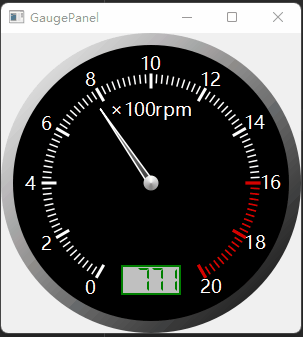
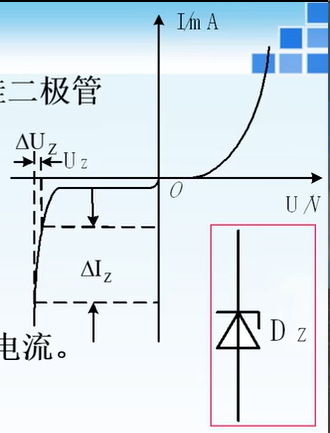
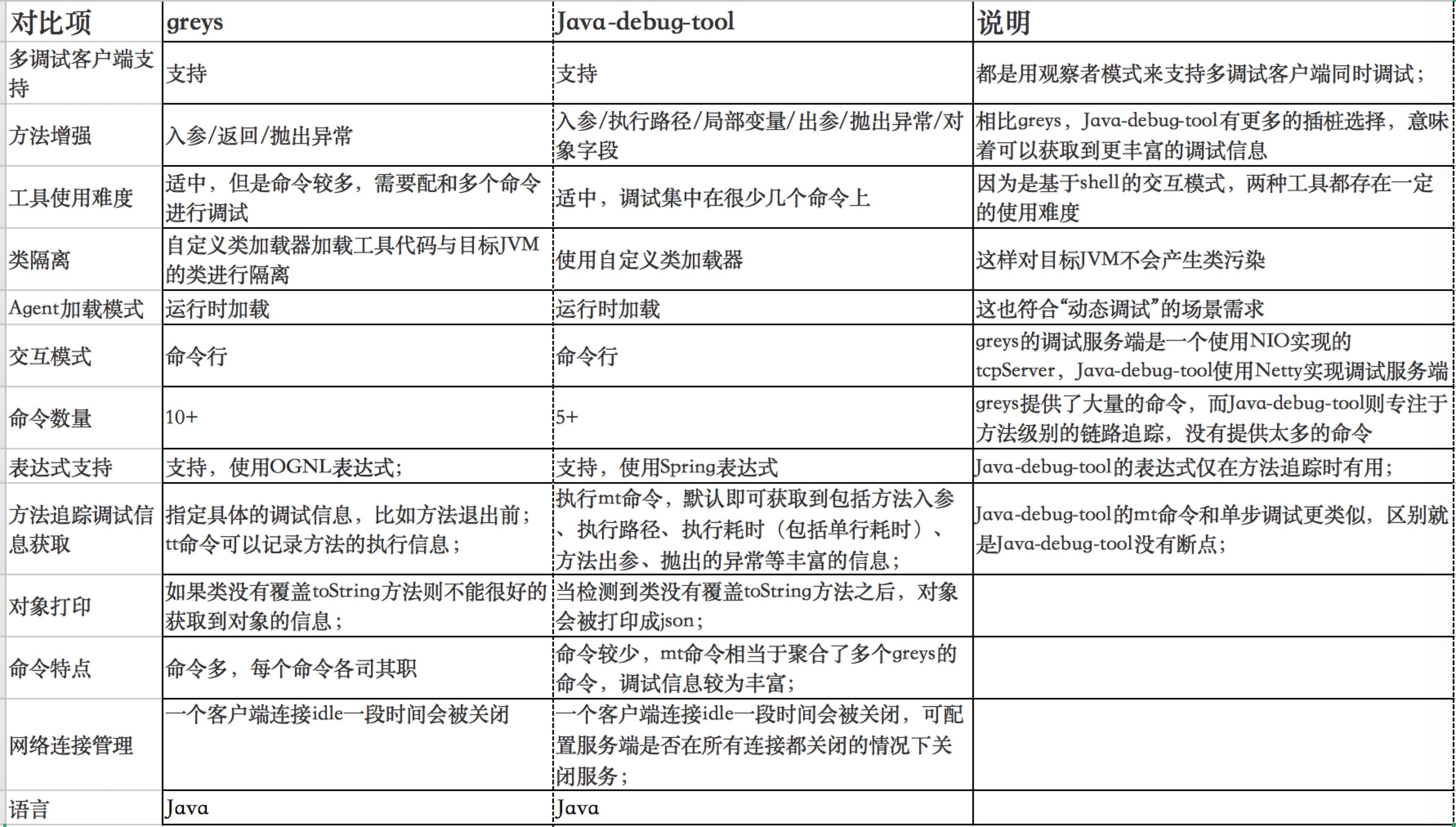
SDXL是一个文生图模型。相比旧版的stable diffusion,SDXL主要的不同有三点:
- 有一个refinement model,通过image-to-image的方式来提高视觉保真度。
- 使用了两个text encoder,OpenCLIP ViT-bigG和CLIP ViT-L。
- 增加了图片大小和长宽比作为输入条件。
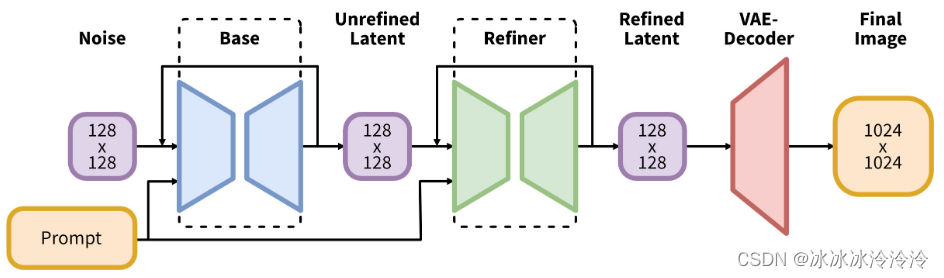
SDXL的结构与以前SD结构的不同如下图:
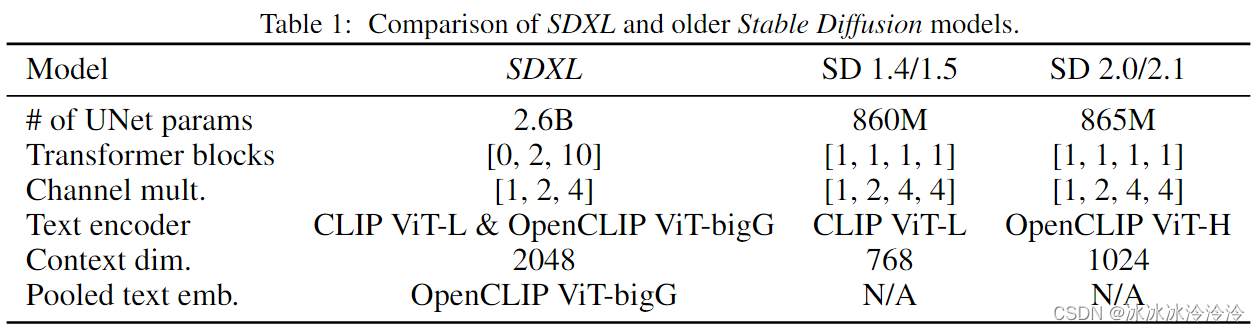
SDXL是一个文生图模型。相比旧版的stable diffusion,SDXL主要的不同有三点:
SDXL的结构与以前SD结构的不同如下图:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1147445.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!

![BUUCTF_练[PASECA2019]honey_shop](https://img-blog.csdnimg.cn/img_convert/17a1cde907f694f396d69af38f049551.png)