摘要:
挑战:
当网络上的图像被大规模检索并被用作个人信息的丰富矿藏时,隐私也面临着风险;
攻击者可以通过从目标类别中查询类似图像以查找任何可用模型来提取私有图像。
提出:
提出了一种基于对抗性示例的新机制,将私人图像“隐藏”在深度哈希空间中,同时保持感知相似性。
具体方案:
- 首先发现汉明距离最大化的简单方法对于暴力对手来说并不稳健。
- 其次,我们通过最大化与原始类别以及所有类别的中心的汉明距离来开发新的损失函数,并将其划分为各种大小的簇。
- 大量实验表明,所提出的防御措施可以将攻击者的努力强化 2-7 个数量级,而不会显着增加计算开销和感知退化。
- 我们还通过黑盒设置证明了哈希空间中 30-60% 的可转移性。
深度哈希:
最先进的图像检索采用深度哈希进行有效的相似性搜索[24-28]。它在训练期间将数据库中的图像量化为低维二进制代码,计算与查询图像的汉明距离,并返回数据库(无意中)收集的相关图像。训练有素的模型将返回具有高度相似性的图像(通常来自同一类别)。通过一些分类信息,例如从目标类别中收集一些图像,攻击者可以查询数据库并检索所有图像,包括那些私人图像。因此,为了逃避检索,隐私保护需要打开深度哈希的盒子,同时保持感知相似性。
目标:
通过对原始图像引入一个小的、精心设计的扰动来最大程度地减少私人图像被提取的机会。
深度神经网络很容易受到对抗性输入的影响——人眼不明显的扰动可能会被添加到错误分类中。原则上,深度哈希应该在设计上继承这些漏洞。最近的一项工作表明,在哈希空间中最大化与原始图像的汉明距离将使系统返回与查询无关的图像,该图像可以直接用于保护私有图像。然而,通过实施该策略,我们发现它只能保护弱对手,而弱对手只能利用原始类别。现实中,强敌更为常见;他们可以枚举所有类别并暴力曝光私人图像。为了应对这一挑战,我们提出了一种新的基于集群的加权距离最大化,可以将哈希码转换为远离所有类别的子空间。
深度哈希:
最先进的图像检索采用深度哈希进行有效的相似性搜索[24-28]。它在训练期间将数据库中的图像量化为低维二进制代码,计算与查询图像的汉明距离,并返回数据库(无意中)收集的相关图像。训练有素的模型将返回具有高度相似性的图像(通常来自同一类别)。通过一些分类信息,例如从目标类别中收集一些图像,攻击者可以查询数据库并检索所有图像,包括那些私人图像。因此,为了逃避检索,隐私保护需要打开深度哈希的盒子,同时保持感知相似性。
目标:
通过对原始图像引入一个小的、精心设计的扰动来最大程度地减少私人图像被提取的机会。
深度神经网络很容易受到对抗性输入的影响——人眼不明显的扰动可能会被添加到错误分类中。原则上,深度哈希应该在设计上继承这些漏洞。最近的一项工作表明,在哈希空间中最大化与原始图像的汉明距离将使系统返回与查询无关的图像,该图像可以直接用于保护私有图像。然而,通过实施该策略,我们发现它只能保护弱对手,而弱对手只能利用原始类别。现实中,强敌更为常见;他们可以枚举所有类别并暴力曝光私人图像。为了应对这一挑战,我们提出了一种新的基于集群的加权距离最大化,可以将哈希码转换为远离所有类别的子空间。
隐私保护:
一种流行的方法是通过差分隐私,将噪声引入答案,以便服务提供商无法检测到用户的存在或不存在。
尽管这些机制在统计基础上提供了可证明的基础,但它们并不是专门用于保护单个记录的推断,例如从数据库检索的私有图像。
少数利用对抗性样本来保护隐私。在[40]中,开发了一种基于对抗性样本的策略来禁用对象检测,因此它无法首先识别对象。[33]中还开发了一种对抗性技术来破坏语义关系并使检索系统返回不相关的图像。我们的工作扩展到[33],以应对强大且适应性强的对手。
威胁模型:
(1)提出场景与假设
社交网络和搜索引擎等平台通常会收集用户信息,包括个人资料、电子邮件、IP 地址,以及最重要的图片。该平台部署了深度图像检索系统,例如 HashNet-ResNet50 [26],以匹配视觉查询中的图像内容以达到营销目的。
为了盈利,该平台还为第三方广告商或数据经纪人(通过称他们为对手而升级)开放了一个接口,他们可以从数据库中匹配和检索相似的图像以进行准确的广告 [38, 39]。
由于服务是按查询进行评级的,因此平台不会对查询数量施加任何限制,但攻击者的预算是固定的。用户(防御者)无法控制隐私策略,因此,他们引入扰动来防止个人图像作为检索结果返回
攻击的流程:
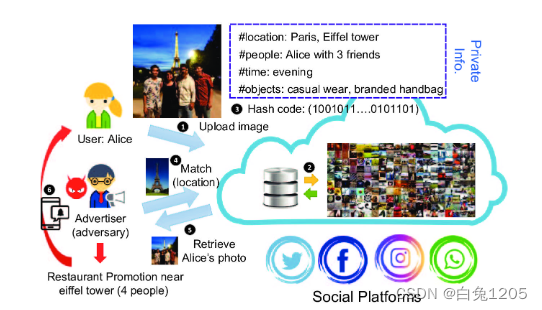
为了最大限度地提高检索质量,攻击者收集一个数据集(攻击集)以类似于数据库。类似地,用户还收集数据集以促进扰动的生成。我们假设两个数据集都是独立的并且与训练集同分布(i.i.d)。为简单起见,本文通过从测试集中随机选择来实现。作为哈希空间中的第一个概念证明,我们假设用户对模型(白盒)有完整的了解,如[32, 33],包括类别、结构、参数、哈希机制和损失函数的信息。然后,当用户尽最大努力估计模型架构和参数时,我们证明了所提出的机制在哈希空间中存在黑盒可转移性。
汉明距离最大化防御:
[33]的工作通过对抗性示例欺骗了基于哈希的图像检索系统,这也可以用作隐私保护技术。目标是最大化扰动图像与原始图像之间的距离,使得汉明距离超过该类别的检索阈值。
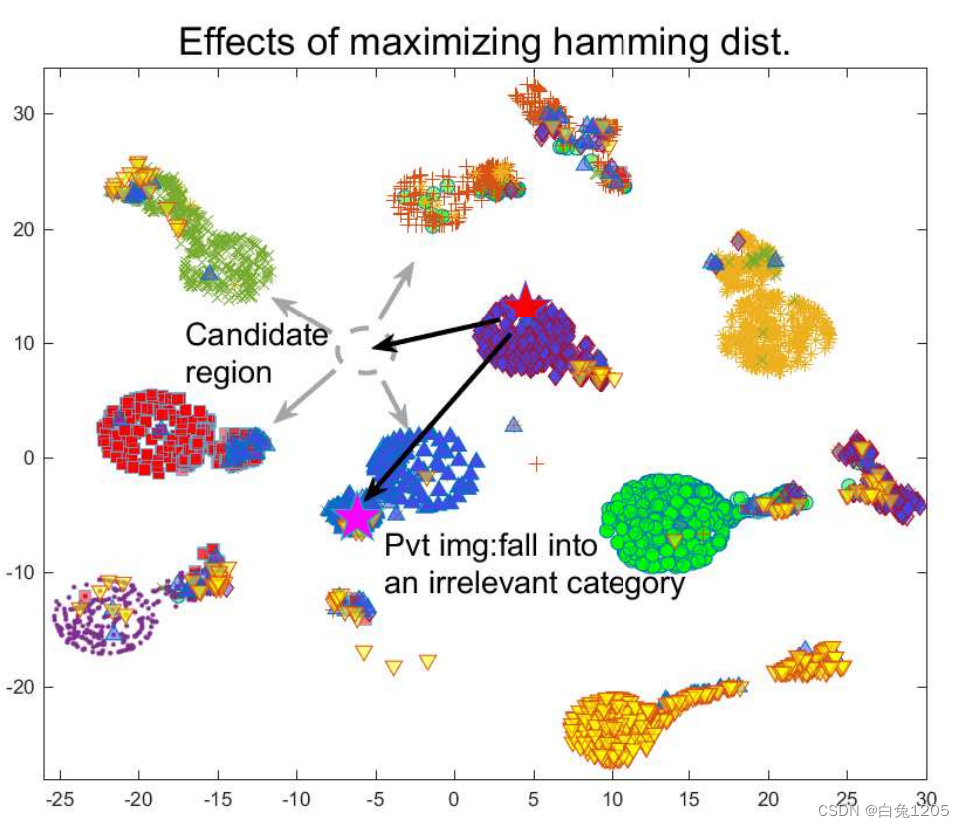
虽然对于针对受保护图像的原始类别的简单查询有效,但当对手枚举其余类别并通过暴力提取受保护图像时,防御很容易受到攻击。这是因为简单地最大化与原始图像的汉明距离可能会无意中将受扰动的图像推入其他类别的附近。图 2 在 MNIST 数据集上的 t-SNE 中可视化了此类情况。正如所观察到的,简单地将私有图像隐藏到一些不相关类别的子空间中仍然容易受到更强大和适应性更强的对手的攻击。为了获得更多见解,我们在图 3 中展示了基于 MNIST [42] 和 CIFAR10 [43] 的一些初步结果。
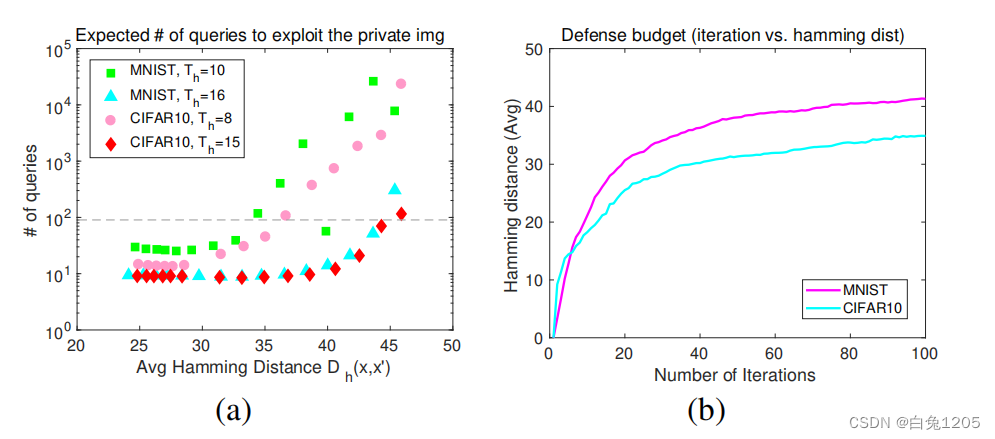
对手可以通过枚举整个攻击集来暴露所有私人图像。由于对手的预算有限,他希望尽量减少这种努力。因此,新的目标最小化了新的损失函数当每次从攻击集中查询随机图像时,我们评估攻击者提取私有图像的平均查询次数。如果将一个私有图像映射到大小为n的攻击集中的n个图像附近,则检索到该图像的概率为n/ n。预期查询次数为N/ N。图3显示了针对强攻击者的预期查询数量,以及根据迭代生成精心制作的扰动[33]的防御努力。根据最佳的F-1分数和精度选择检索阈值Th。
观察1。随着x与x′之间汉明距离的增加,攻击力度呈抛物线上升趋势。然而,一个强大的对手仍然可以在大多数汉明距离的100次查询中提取私有图像。
观察2。经过一定次数的迭代后,平均汉明距离难以进一步最大化。例如,如图3(b)所示,在MNIST和CIFAR10上进行100次迭代后,其平均值在40和35左右达到饱和,与m = 48的总哈希位相差很大。
观察3。当分类特征在汉明空间中越分散时,被保护的图像越容易落入某些样本的检索阈值。由于CIFAR10具有更高的类内多样性,因此对CIFAR10的攻击需要比MNIST更少的努力,这在图3中得到了验证。这使得使用汉明距离最大化的防御在现实世界中变得脆弱,在现实世界中,数据具有复杂和高度的类内/类间多样性。从这些观察中我们可以看出,面对强大的对手,防御是一项挑战。而不是单纯的从原始类别出发的最大化,应该在一个狭窄的子空间内进行优化,以避免:1)暴露于原始类别;2)通过查询其余类别提取;3)视觉质量下降。为了满足这些需求,我们将在下一节中提出一种新机制。
基于聚类的加权距离最大化:
我们提出了一种新的机制,称为基于聚类的加权距离最大化。该思想与中心损失[44]类似,目的是增强对类间特征的辨别能力,并将类内特征拉向其中心,以便更好地分类。然而,在这里,我们通过对抗性透镜来学习如何通过干扰输入图像来生成哈希码,从而使到哈希中心的距离最大化。
为了解释阶级内部的变化,我们用几个中心来表示每个阶级,而不是一个单一的中心。到中心的汉明距离在不同类别中也表现出异质分布。对于某些类别,样本可能在中心周围具有高密度,而其他类别可能分散得更均匀。因此,优化时应考虑类内分布及其到中心的汉明距离;否则,受保护的图像可能会落入高密度区域,在高密度区域中,所有样本的哈希码相似。攻击者可以很容易地利用这些区域来检索私有图像,几率很高。