目录
1. 分类数据的可视化
1.1 类别散点图(Categorical Scatter Plot)
1.2 类别分布图(Categorical Distribution Plot)
1.3 类别估计图(Categorical Estimate Plot)
1.4 类别单变量图(Categorical Univariate Plot)
2. 线性模型和参数拟合可视化
2.1 线性回归模型可视化(Linear Regression Plot)
2.2 逻辑回归模型可视化(Logistic Regression Plot)
2.3 残差绘图(Residual Plot)
1. 分类数据的可视化
1.1 类别散点图(Categorical Scatter Plot)
类别散点图用于显示不同类别之间的数据点分布,通常使用散点图来表示。
Seaborn中的stripplot和swarmplot函数用于创建这种类型的图。
- 可以通过指定
hue参数来根据另一个分类变量对数据进行分组,以区分更多信息。- 使用
jitter参数可以添加一些随机抖动,以避免数据点的重叠。
示例代码:
import seaborn as sns
import matplotlib.pyplot as plt
# 使用示例数据
data = sns.load_dataset("tips")
# 创建一个类别散点图
sns.stripplot(x="day", y="total_bill", data=data)
# 或者使用swarmplot
sns.swarmplot(x="day", y="total_bill", data=data)
plt.show()
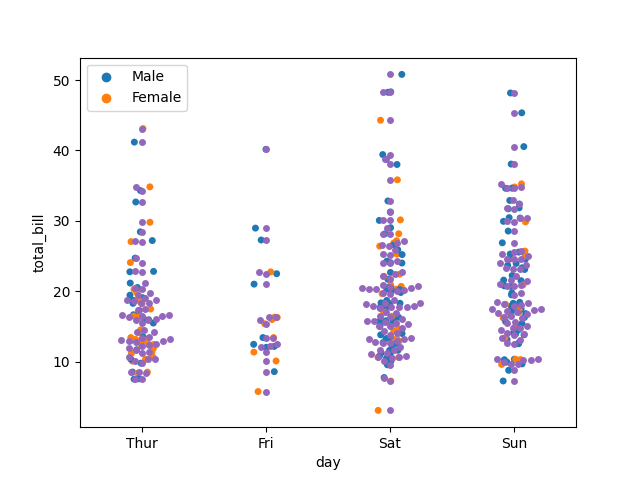
1.2 类别分布图(Categorical Distribution Plot)
类别分布图用于显示类别数据的分布,常用的有boxplot、violinplot和boxenplot等。
Box Plot(箱线图)
箱线图通常用于可视化类别数据的分布,展示了数据的中位数、四分位数和异常值。使用
hue参数可以将数据按照另一个类别变量分组,以便比较不同组之间的分布。Violin Plot(小提琴图)
小提琴图结合了箱线图和核密度估计,可以更详细地显示数据的分布。使用
hue参数可以按照另一个类别变量分组,通过split参数可以将小提琴图分成两部分以更清晰地表示数据。Boxen Plot(Boxen图)
Boxen图是一种更详细的箱线图,它可以更好地显示数据分布的各个部分。它适用于数据集中有大量异常值的情况。
以下是一个示例代码,演示如何在一个代码段中绘制箱线图、小提琴图和 Boxen 图,并使用 hue 参数进行数据分组和 dodge 参数分开多个分类的数据分布:
import seaborn as sns
import matplotlib.pyplot as plt
data = sns.load_dataset("tips")
# 创建一个包含多个子图的画布
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
# 创建箱线图
sns.boxplot(x="day", y="total_bill", hue="sex", data=data, dodge=True, ax=axes[0])
axes[0].set_title("Box Plot")
# 创建小提琴图
sns.violinplot(x="day", y="total_bill", hue="sex", data=data, split=True, ax=axes[1])
axes[1].set_title("Violin Plot")
# 创建 Boxen 图
sns.boxenplot(x="day", y="total_bill", hue="sex", data=data, dodge=True, ax=axes[2])
axes[2].set_title("Boxen Plot")
# 调整子图布局
plt.tight_layout()
plt.show()
结果如下:
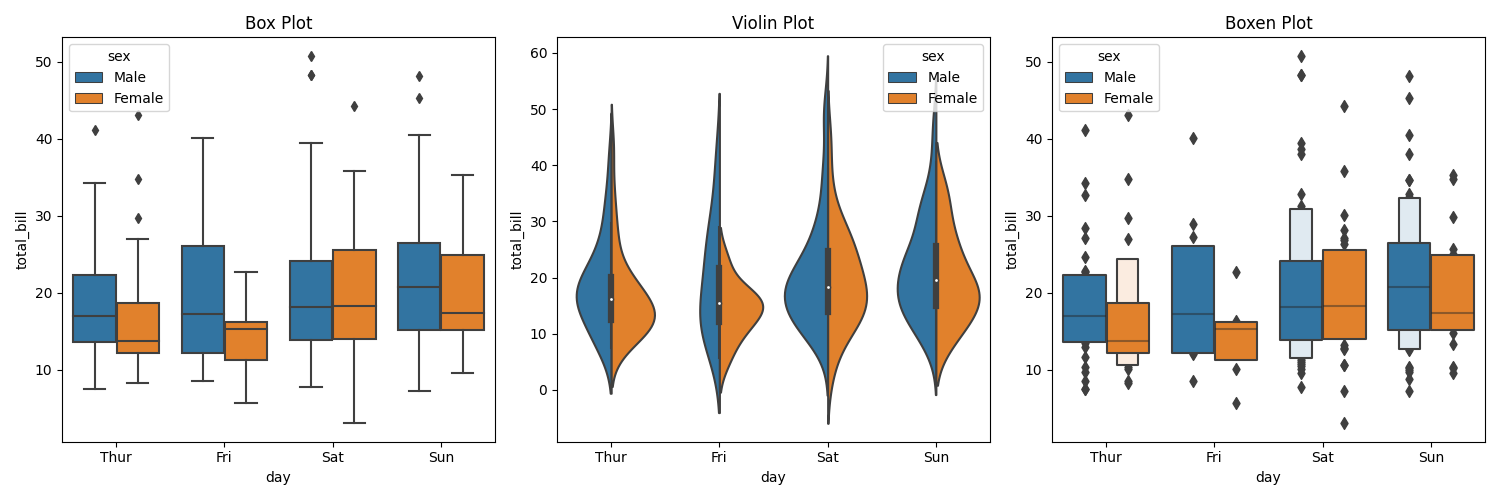
这段代码使用
plt.subplots()创建一个包含 3 个子图的画布,分别绘制箱线图、小提琴图和 Boxen 图,并在每个子图的标题中标注图的类型。你可以根据需要进一步自定义图形的外观和布局。
1.3 类别估计图(Categorical Estimate Plot)
类别估计图用于显示类别数据的估计值,例如均值、中位数等,通常用于汇总和可视化类别数据的分布特征。Seaborn中常用的函数包括barplot和pointplot。
1. Bar Plot(柱状图)
柱状图常用于显示类别数据的中心趋势估计值(如均值),以及可选的置信区间。你可以使用barplot函数来创建柱状图,同时可以根据另一个分类变量使用hue参数进行数据分组。
2. Point Plot(点图)
点图是一种用于显示估计值的可视化方式,它显示估计值(通常是均值)以及可选的误差线。点图的优点是能够清晰地显示估计值和变异性。
import seaborn as sns
import matplotlib.pyplot as plt
# 加载示例数据集
data = sns.load_dataset("tips")
# 创建一个包含两个子图的画布
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# 创建柱状图,显示不同日期(day)的总账单(total_bill)均值
sns.barplot(x="day", y="total_bill", data=data, ci="sd", ax=axes[0])
axes[0].set_title("Bar Plot of Total Bill by Day")
axes[0].set_ylabel("Mean Total Bill")
# 创建点图,显示不同日期(day)的总账单(total_bill)中位数
sns.pointplot(x="day", y="total_bill", data=data, ci="sd", ax=axes[1])
axes[1].set_title("Point Plot of Total Bill by Day")
axes[1].set_ylabel("Median Total Bill")
# 调整子图布局
plt.tight_layout()
plt.show()
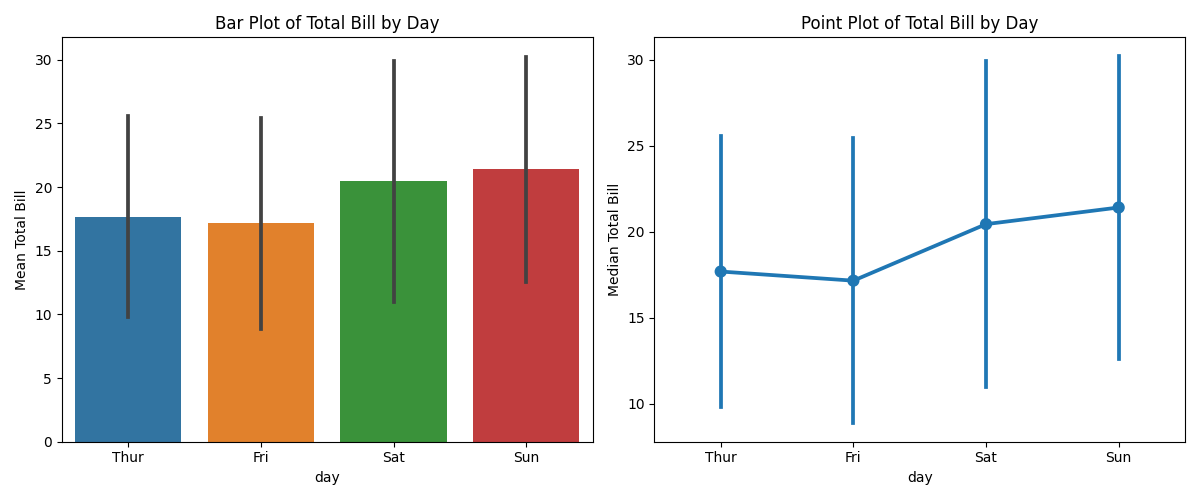
在这个示例中,左侧的柱状图展示了不同日期的总账单均值,而右侧的点图展示了相同日期的总账单中位数。这两种图形强调了不同类别的估计值(均值和中位数),并通过误差线反映了数据的变异性。
1.4 类别单变量图(Categorical Univariate Plot)
类别单变量图用于展示单一类别变量的分布情况,通常用于可视化不同类别的计数或频率。Seaborn提供了几个函数来创建类别单变量图,其中包括countplot和boxenplot。
Count Plot(计数图)
计数图用于显示每个类别的计数(频数),通常用于展示类别的分布情况。你可以使用
countplot函数来创建计数图。Boxen Plot(Boxen图)
虽然
boxenplot通常用于类别数据的分布展示,但也可以用于展示单一类别变量的分布。它显示了类别变量的不同分位数,并且更详细地表示了数据的分布,适用于数据集中存在许多异常值的情况。
import seaborn as sns
import matplotlib.pyplot as plt
data = sns.load_dataset("tips")
# 创建一个包含两个子图的画布
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# 创建计数图,显示不同日期(day)的用餐计数
sns.countplot(x="day", data=data, ax=axes[0])
axes[0].set_title("Count Plot of Days")
axes[0].set_ylabel("Count")
# 创建Boxen图,显示不同性别(sex)的总账单(total_bill)分布
sns.boxenplot(x="sex", y="total_bill", data=data, ax=axes[1])
axes[1].set_title("Boxen Plot of Total Bill by Gender")
axes[1].set_ylabel("Total Bill")
# 调整子图布局
plt.tight_layout()
plt.show()
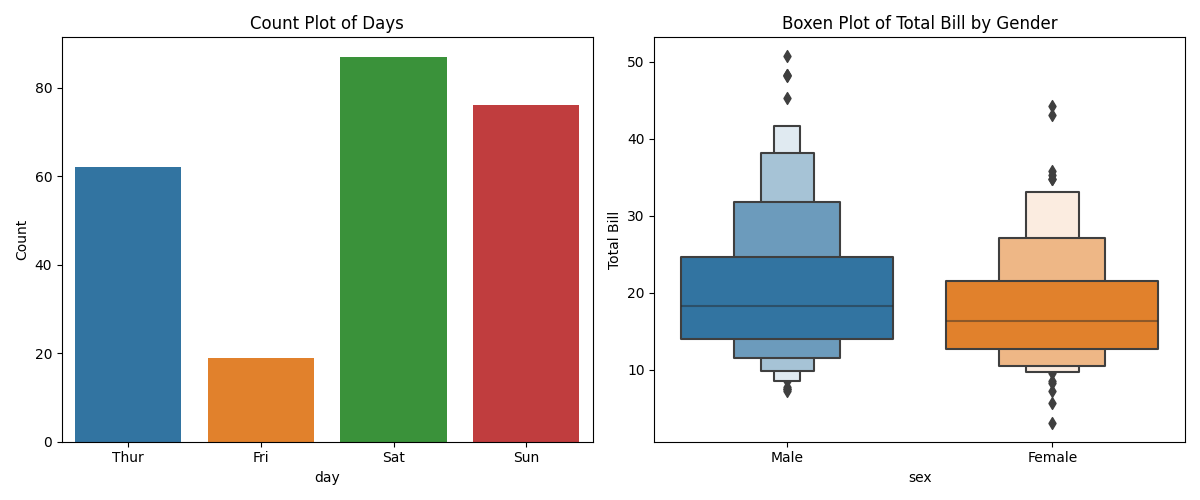
在这个示例中,左侧的计数图展示了不同日期的用餐计数,而右侧的Boxen图展示了不同性别的总账单分布。这两种图形强调了不同类别变量的不同方面,计数图强调了频数分布,而Boxen图提供了更多的分布信息。
2. 线性模型和参数拟合可视化
线性模型和参数拟合的可视化在数据分析和机器学习中非常重要,它可以帮助你理解模型的性能、评估拟合质量以及检查模型的假设。Seaborn提供了一些函数来可视化线性回归模型和逻辑回归模型,以及绘制残差图。
2.1 线性回归模型可视化(Linear Regression Plot)
线性回归模型可视化是一种用于展示线性关系的数据可视化方法。它通过绘制数据点和拟合的直线来呈现线性回归模型的拟合效果。
在Seaborn中,可以使用lmplot()函数绘制线性回归模型可视化图。该函数可以同时显示数据点和拟合的线性回归模型,并提供置信区间。通过调整参数,可以自定义线条的样式、颜色和置信区间的透明度等。
import seaborn as sns
import matplotlib.pyplot as plt
# 使用示例数据
data = sns.load_dataset("tips")
# 使用lmplot绘制线性回归模型可视化
sns.lmplot(x="total_bill", y="tip", data=data, ci=95, scatter_kws={"color": "blue"}, line_kws={"color": "red"})
# 设置标题
plt.title("Linear Regression Plot")
# 调整图形布局,确保标题显示在图内
plt.tight_layout()
# 显示图形
plt.show()
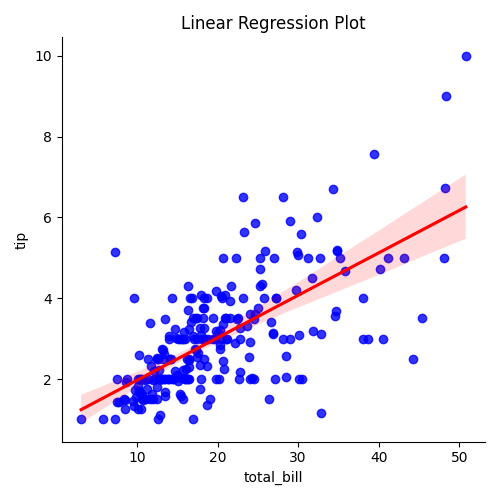
在这个示例中,
lmplot()函数使用了 "tips" 数据集中的 "total_bill" 和 "tip" 变量来创建线性回归模型可视化。参数ci用于指定置信区间的程度(在示例中为95%置信区间),scatter_kws参数用于自定义数据点的样式(蓝色),line_kws参数用于自定义回归线的样式(红色)。
2.2 逻辑回归模型可视化(Logistic Regression Plot)
逻辑回归模型可视化用于展示二分类模型的效果。它通过绘制数据点和拟合的曲线,来展示逻辑回归模型在不同类别上的概率分布。
在Seaborn中,可以使用lmplot()函数绘制逻辑回归模型可视化图。可以设置逻辑回归模型的类型(如logit、probit等),以及其他参数,如置信区间、颜色等。
示例:
import seaborn as sns
import matplotlib.pyplot as plt
# 使用示例数据
data = sns.load_dataset("titanic")
# 使用lmplot绘制逻辑回归模型可视化
sns.lmplot(x="age", y="survived", data=data, logistic=True, ci=None, scatter_kws={"color": "blue"})
# 设置标题
plt.title("Logistic Regression Plot")
# 调整图形布局,确保标题显示在图内
plt.tight_layout()
# 显示图形
plt.show()
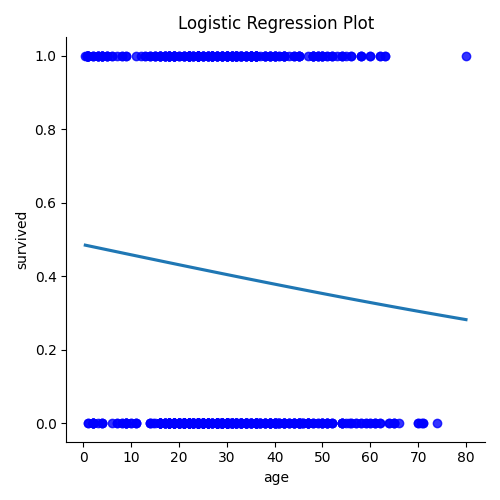
该代码片段的目的是使用逻辑回归模型绘制乘客的年龄和存活情况之间的关系,通过可视化呈现逻辑回归模型的结果。
sns.load_dataset("titanic")会加载 Seaborn 库中的内置数据集 "titanic",其中包含了泰坦尼克号乘客的信息,如年龄、是否存活等。接着,使用
sns.lmplot()函数创建逻辑回归模型的可视化。该函数用于绘制回归关系。在这里,x="age"表示 x 轴为乘客的年龄,y="survived"表示 y 轴为乘客的存活情况,data=data表示数据来自加载的 "titanic" 数据集,logistic=True表示使用逻辑回归模型,ci=None表示不绘制置信区间,scatter_kws={"color": "blue"}表示散点图中点的颜色为蓝色。接下来,通过
plt.title()设置图表的标题为 "Logistic Regression Plot"。
plt.tight_layout()调整图表布局以确保标题在图表内显示。
2.3 残差绘图(Residual Plot)
残差绘图用于检查线性回归模型的拟合效果是否良好。它通过绘制预测值与观测值之间的差异(即残差)来评估模型的拟合程度。
在Seaborn中,可以使用residplot()函数绘制残差绘图。函数会自动计算出残差,并绘制出残差与预测值之间的关系图。通过观察残差的分布情况,我们可以判断模型是否存在线性性、同方差性和独立性的假设违反。
import seaborn as sns
import matplotlib.pyplot as plt
# 加载示例数据
data = sns.load_dataset("tips")
# 使用 lmplot 绘制回归关系图
sns.lmplot(x="total_bill", y="tip", data=data)
# 绘制残差图
sns.residplot(x="total_bill", y="tip", data=data, scatter_kws={"s": 25, "alpha": 0.5})
# 设置图标题
plt.title("Residual Plot")
plt.tight_layout()
# 显示图形
plt.show()
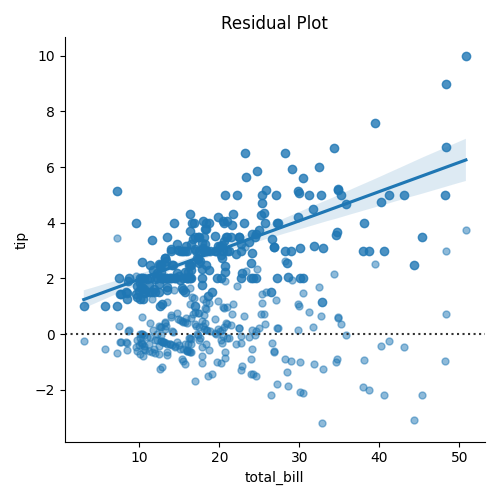
sns.load_dataset("tips")会加载 Seaborn 库中的示例数据集 "tips",包含餐厅顾客消费金额和小费的数据。
sns.lmplot()用于绘制总消费金额 (total_bill) 和小费 (tip) 之间的回归关系图。
sns.residplot()绘制残差图,传入x="total_bill"和y="tip",即自变量和因变量。scatter_kws={"s": 25, "alpha": 0.5}是用于自定义散点图的样式,设置点的大小和透明度。