1、多表映射
简介一 链接
对于数据库的操作,很多时候我们都是在多表的基础上进行操作的,在这里讲一下多表属性值与列名映射。
案例:这里有一个订单表和一个客户表
CREATE TABLE `t_customer` (`customer_id` INT NOT NULL AUTO_INCREMENT, `customer_name` CHAR(100), PRIMARY KEY (`customer_id`) );
CREATE TABLE `t_order` ( `order_id` INT NOT NULL AUTO_INCREMENT, `order_name` CHAR(100), `customer_id` INT, PRIMARY KEY (`order_id`) );
INSERT INTO `t_customer` (`customer_name`) VALUES ('c01');
INSERT INTO `t_order` (`order_name`, `customer_id`) VALUES ('o1', '1');
INSERT INTO `t_order` (`order_name`, `customer_id`) VALUES ('o2', '1');
INSERT INTO `t_order` (`order_name`, `customer_id`) VALUES ('o3', '1');
1.1对一关系
我们的要求是根据订单id返回该订单信息与客户信息。这是一对一的关系。
对于多表映射,我们先写出实体类,先不考虑对应关系。之后再根据需求在实体类中添加信息。
对于对一关系,我们只要在实体类中添加一个对应实体类的属性即可。
订单类:
package com.cky.pojo;
import lombok.Data;
@Data
public class Order {
private Integer orderId;
private String orderName;
private Integer customerId;
//查询订单以及订单对应的客户信息 对一的关系
private Customer customer;
}
订单mapper接口:
package com.cky.mapper;
import com.cky.pojo.Order;
//查询订单以及订单对应的客户信息 对一的关系
public interface OrderMapper {
Order querybyId(Integer id);
}
订单mapperxml编写
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- namespace等于mapper接口类的全限定名,这样实现对应 -->
<mapper namespace="com.cky.mapper.OrderMapper">
<resultMap id="ordermap" type="order">
<id property="orderId" column="order_id"></id>
<result property="orderName" column="order_name"></result>
<result property="customerId" column="customer_id"></result>
<association property="customer" javaType="customer">
<id column="customer_id" property="customerId"></id>
<result column="customer_name" property="customerName"></result>
</association>
</resultMap>
<select id="querybyId" resultMap="ordermap">
SELECT order_id,order_name,c.customer_id,customer_name
FROM t_order o
LEFT JOIN t_customer c
ON o.customer_id=c.customer_id
WHERE o.order_id=#{orderId}
</select>
</mapper>
对应关系可以参考如下图:

注意:对于单个属性,我们使用association即可,但于多个属性,我们采用collection
mybatis-config.xml配置编写
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
<!-- 使用settings对Mybatis全局进行设置 -->
<!-- 将xxx_xxx这样的列名自动映射到xxXxx这样驼峰式命名的属性名 -->
<setting name="mapUnderscoreToCamelCase" value="true"/>
<!--开启resultMap自动映射 -->
<setting name="autoMappingBehavior" value="FULL"/>
</settings>
<!--给该包的类起别名,第一个字母小写-->
<typeAliases>
<package name="com.cky.pojo"/>
</typeAliases>
<!-- environments表示配置Mybatis的开发环境,可以配置多个环境,在众多具体环境中,使用default属性指定实际运行时使用的环境。default属性的取值是environment标签的id属性的值。 -->
<environments default="development">
<!-- environment表示配置Mybatis的一个具体的环境 -->
<environment id="development">
<!-- Mybatis的内置的事务管理器 -->
<transactionManager type="JDBC"/>
<!-- 配置数据源 -->
<dataSource type="POOLED">
<!-- 建立数据库连接的具体信息 -->
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis"/>
<property name="username" value="cky"/>
<property name="password" value="123456"/>
</dataSource>
</environment>
</environments>
<mappers>
<!-- Mapper注册:指定Mybatis映射文件的具体位置 -->
<!-- mapper标签:配置一个具体的Mapper映射文件 -->
<!-- resource属性:指定Mapper映射文件的实际存储位置,这里需要使用一个以类路径根目录为基准的相对路径 -->
<!-- 对Maven工程的目录结构来说,resources目录下的内容会直接放入类路径,所以这里我们可以以resources目录为基准 -->
<mapper resource="mappers/OrderMapper.xml"/>
<mapper resource="mappers/CustomerMapper.xml"/>
</mappers>
</configuration>
测试类:
public class Mytest {
private SqlSession sqlSession;
@BeforeEach
public void before() throws IOException {
sqlSession=new SqlSessionFactoryBuilder().build(Resources.getResourceAsStream("mybatis-config.xml")).openSession(true);
}
@AfterEach
public void after(){
sqlSession.close();
}
@Test
public void test_01(){
OrderMapper orderMapper = sqlSession.getMapper(OrderMapper.class);
Order order = orderMapper.querybyId(1);
System.out.println(order);
System.out.println(order.getCustomer());
}}
1.2 对多关系
对于1对多的关系,我们只需要在对应的类中添加对多类的属性即可,是一个list集合
比如 我们需要根据客户id返回客户信息以及客户对应的订单信息
则我们在客户类中添加上 订单类的list属性即可
客户类
package com.cky.pojo;
import lombok.Data;
import java.util.List;
@Data
//对多,查询一个客户信息以及客户对应的订单信息
public class Customer {
private Integer customerId;
private String customerName;
private List<Order> orderList;
}
客户mapper接口
package com.cky.mapper;
import com.cky.pojo.Customer;
public interface CustomerMapper {
Customer querycustomerWithOrder(Integer id);
}
客户mapperxml
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "https://mybatis.org/dtd/mybatis-3-mapper.dtd"> <!-- namespace等于mapper接口类的全限定名,这样实现对应 --> <mapper namespace="com.cky.mapper.CustomerMapper"> <resultMap id="customermap" type="customer"> <id property="customerId" column="customer_id"></id> <collection ofType="order" property="orderList"> <id property="orderId" column="order_id"></id> </collection> </resultMap> <select id="querycustomerWithOrder" resultMap="customermap"> SELECT order_id,order_name,c.customer_id,customer_name FROM t_order o LEFT JOIN t_customer c ON o.customer_id=c.customer_id WHERE c.customer_id=#{customerId} </select> </mapper>对应关系
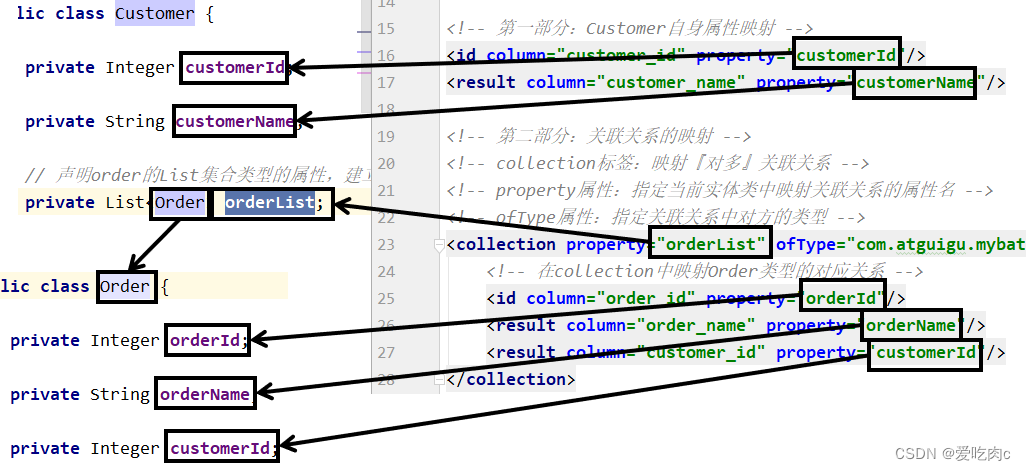
配置xml文件与上边相同
在这里需要注意
1.2.1 多表映射优化
对于对一关系,我们的映射关系resultMap中,不仅写了id还需要写result,但是我们可以开始自动映射,只要我们的关系属性名与列名相同,或者我们开启了驼峰式映射,就可以进行自动的result映射。 比如对多的客户mapperxml文件中resultMap的编写,我们就只写了id。没有写普通列的映射关系。
<!--开启resultMap自动映射 --> <setting name="autoMappingBehavior" value="FULL"/>
对于resultMap中的id属性我们还是需要添上的。
1.3 多表映射总结
resultType只能进行单表映射,所以对于多表映射,我们需要resulMap属性来编写对应的映射关系。

2、动态查询
在现实生活中,我们经常遇到多条件查询的情况。对于多条件查询,就免不了一些属性不取值的情况,那这种动态语句的sql要如何写呢?Mybatis提供了很多标签,大大简化了原始JDBC语句拼接的情况。
2.1 if和where
<!--
List<Employee> selectEmployeeByCondition(Employee employee);
if 可以用来进行判断 如果test里边的返回true,则该语句执行
where 的作用 1.如果where 中有一句语句执行,则添加上where。防止 都不执行 多出一个where
2、去掉多余的and 或者 or
比如 <if test="empName !=null">
emp_name=#{empName}
</if>
不执行
and emp_salary=#{empSalary} 执行
就会导致多一个 and
test中取key :可以访问实体类的属性,但不能访问数据库的字段。
-->
<select id="selectEmployeeByCondition" resultType="employee">
select * from t_emp
<where>
<if test="empName !=null">
emp_name=#{empName}
</if>
<if test="empSalary !=nul">
and emp_salary=#{empSalary}
</if>
</where>
</select>
2.2、set标签
<!--int updateEmployeeDynamic(Employee employee);
update t_tmp set emp_name=#{empName},emp_salary=#{empSalary}
where emp_id=#{empId}
我们需要让 姓名不为空 并且 薪资大于3000 更新
set的作用:1、防止右边语句都不执行,多出一个set,set标签会自动判断需不需要添加set
2、去掉多余的逗号
set 标签也可以和if标签同时使用
-->
<update id="updateEmployeeDynamic">
update t_tmp
<set>
<if test="empName!=null">
emp_name=#{empName},
</if>
<if test="empSalary and empSalary > 3000">
emp_salary=#{empSalary}
</if>
</set>
where emp_id=#{empId}
</update>
2.3 trim标签
使用trim标签控制条件部分两端是否包含某些字符
- prefix属性:指定要动态添加的前缀
- suffix属性:指定要动态添加的后缀
- prefixOverrides属性:指定要动态去掉的前缀,使用“|”分隔有可能的多个值
- suffixOverrides属性:指定要动态去掉的后缀,使用“|”分隔有可能的多个值
比如使用trim来代替set
<update id="updateEmployeeDynamic">
update t_tmp
<trim prefix="set" suffixOverrides=",">
<if test="empName!=null">
emp_name=#{empName},
</if>
<if test="empSalary and empSalary > 3000">
emp_salary=#{empSalary}
</if>
</trim>
where emp_id=#{empId}
</update>
2.4 choose/when/otherwise标签
在多个分支条件中,仅执行一个。
- 从上到下依次执行条件判断
- 遇到的第一个满足条件的分支会被采纳
- 被采纳分支后面的分支都将不被考虑
- 如果所有的when分支都不满足,那么就执行otherwise分支
<!-- List<Employee> selectEmployeeByConditionByChoose(Employee employee) -->
<select id="selectEmployeeByConditionByChoose" resultType="com.atguigu.mybatis.entity.Employee">
select emp_id,emp_name,emp_salary from t_emp
where
<choose>
<when test="empName != null">emp_name=#{empName}</when>
<when test="empSalary < 3000">emp_salary < 3000</when>
<otherwise>1=1</otherwise>
</choose>
<!--
第一种情况:第一个when满足条件 where emp_name=?
第二种情况:第二个when满足条件 where emp_salary < 3000
第三种情况:两个when都不满足 where 1=1 执行了otherwise
-->
</select>
2.5 foreach 标签
可以用来进行批量操作
比如根据id批量查询
<!--
List<Employee> queryBatch(@Param("ids") List<Integer> ids);
select * from t_emp where emp_id in(1,2,3)
-->
<select id="queryBatch" resultType="employee">
select * from t_emp where emp_id in
<!--
collection 是我们要遍历的 集合
open 遍历之前要添加的字符串
close 遍历之后要添加的字符串
separator 分隔符
item 遍历的每一个集合项
-->
<foreach collection="ids" open="(" separator="," close=")" item="id">
//遍历的内容 #{遍历的key}
#{id}
</foreach>
</select>
根据id 批量删除
<!--
int deleteBatch(@Param("ids") List<Integer> ids);
delete from t_emp where emp_id in (1,2,3)
-->
<delete id="deleteBatch">
delete from t_emp where emp_id in
<foreach collection="ids" open="(" separator="," close=")" item="id">
#{id}
</foreach>
</delete>
批量插入
<!--
int insertBatch(@Param("list") List<Employee> employeeslist);
insert into t_emp(emp_name,emp_salary) values("".""),("","")
-->
<insert id="insertBatch">
insert into t_emp(emp_name,emp_salary) values
<foreach collection="list" separator="," item="emp">
(#{emp.empName},#{emp.empSalary})
</foreach>
</insert>
批量更新
上面批量插入的例子本质上是一条SQL语句,而实现批量更新则需要多条SQL语句拼起来,用分号分开。也就是一次性发送多条SQL语句让数据库执行。此时需要在数据库连接信息的URL地址中设置:
<property name="url" value="jdbc:mysql://localhost:3306/
mybatis?allowMultiQueries=true"/>
<!--
int updateBatch(@Param("list") List<Employee> employeeslist);
更新的话比较特殊
实则是多条sql语句一起,上边的删除查询等其实是一条sql语句
-->
<update id="updateBatch">
<foreach collection="list" item="emp">
update t_emp set emp_name=#{emp.empName},emp_salary=#{emp.empSalary}
where emp_id=#{emp.empId}
</foreach>
</update>
在实际开发中,为了避免隐晦的表达造成一定的误会,建议使用@Param注解明确声明变量的名称,然后在foreach标签的collection属性中按照@Param注解指定的名称来引用传入的参数。
比如:
public interface EmployeeMapper {
List<Employee> queryBatch(@Param("ids") List<Integer> ids);
int deleteBatch(@Param("ids") List<Integer> ids);
int updateBatch(@Param("list") List<Employee> employeeslist);
int insertBatch(@Param("list") List<Employee> employeeslist);
}
2.6 sql 标签
抽取重复的SQL片段
<!-- 使用sql标签抽取重复出现的SQL片段 -->
<sql id="mySelectSql">
select emp_id,emp_name,emp_age,emp_salary,emp_gender from t_emp
</sql>
引用已抽取的SQL片段
<!-- 使用include标签引用声明的SQL片段 -->
<select id="" class="">
<include refid="mySelectSql"/>where emp_id=#{empId}
</select>
3、Mybatis高级拓展
3.1 mapper按包批量扫描
1. 需求
Mapper 接口配置文件很多时,在全局配置文件中一个一个注册太麻烦,希望有一个办法能够一劳永逸。
2 配置方式
Mybatis 允许在指定 Mapper 映射文件时,只指定其所在的包:
<mappers>
<package name="com.cky.mapper"/>
</mappers>
此时这个包下的所有 Mapper 配置文件将被自动加载、注册,比较方便。
3、配置要求
- Mapper 接口和 Mapper 配置文件名称一致
- Mapper 接口:EmployeeMapper.java
- Mapper 配置文件:EmployeeMapper.xml
-要求打包后mapper接口和mapper接口的配置文件在同一个文件夹下
这就需要我们
①可以将mapperxml文件放在mapper接口所在的包![不推荐]
② 可以在resources下创建mapper接口包一致的文件夹结构存放mapperxml文件[推荐]
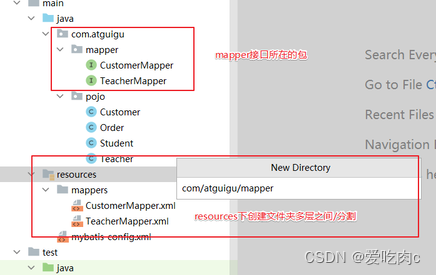

在resources 下创建包 分级的话 要用/ 因为是文件 在resurces下如果使用.的话,仍然是同一级目录。
而在java中 用. 因为创建的是包 要注意
3.2 插件机制和分页插件使用
3.2.1插件机制
MyBatis 对插件进行了标准化的设计,并提供了一套可扩展的插件机制。插件可以在用于语句执行过程中进行拦截,并允许通过自定义处理程序来拦截和修改 SQL 语句、映射语句的结果等。
具体来说,MyBatis 的插件机制包括以下三个组件:
1. `Interceptor`(拦截器):定义一个拦截方法 `intercept`,该方法在执行 SQL 语句、执行查询、查询结果的映射时会被调用。
2. `Invocation`(调用):实际上是对被拦截的方法的封装,封装了 `Object target`、`Method method` 和 `Object[] args` 这三个字段。
3. `InterceptorChain`(拦截器链):对所有的拦截器进行管理,包括将所有的 Interceptor 链接成一条链,并在执行 SQL 语句时按顺序调用。
插件的开发非常简单,只需要实现 Interceptor 接口,并使用注解 `@Intercepts` 来标注需要拦截的对象和方法,然后在 MyBatis 的配置文件中添加插件即可。
PageHelper 是 MyBatis 中比较著名的分页插件,它提供了多种分页方式(例如 MySQL 和 Oracle 分页方式),支持多种数据库,并且使用非常简单。下面就介绍一下 PageHelper 的使用方式。
3.2.2分页插件 PageHelper的使用
1、首先 我们需要在pom.xml 导入外部依赖
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.1.11</version>
</dependency>
2、Mybatis-config.xml 中配置分页插件
<plugins>
<plugin interceptor="com.github.pagehelper.PageInterceptor">
<property name="helperDialect" value="mysql"/>
</plugin>
</plugins>
其中,com.github.pagehelper.PageInterceptor 是 PageHelper 插件的名称,dialect 属性用于指定数据库类型(支持多种数据库)
3、分页插件的使用
@Test
public void testTeacherRelationshipToMulti() {TeacherMapper teacherMapper = session.getMapper(TeacherMapper.class);
PageHelper.startPage(1,2);
// 查询Customer对象同时将关联的Order集合查询出来
List<Teacher> allTeachers = teacherMapper.findAllTeachers();
//注意:在分页配置区我们只能写一句查询语句。
PageInfo<Teacher> pageInfo = new PageInfo<>(allTeachers);将其封装成一个pageinfo实体类对象,我们可以获取很多信息(比如一共多少页,一共多少条信息,当前多少页,是否有下一页等)。
System.out.println("pageInfo = " + pageInfo);
long total = pageInfo.getTotal(); // 获取总记录数
System.out.println("total = " + total);
int pages = pageInfo.getPages(); // 获取总页数
System.out.println("pages = " + pages);
int pageNum = pageInfo.getPageNum(); // 获取当前页码
System.out.println("pageNum = " + pageNum);
int pageSize = pageInfo.getPageSize(); // 获取每页显示记录数
System.out.println("pageSize = " + pageSize);
List<Teacher> teachers = pageInfo.getList(); //获取查询页的数据集合
System.out.println("teachers = " + teachers);
teachers.forEach(System.out::println);}
3.3 orm介绍和逆向工程
3.3.1 Orm介绍
ORM(Object-Relational Mapping,对象-关系映射)是一种将数据库和面向对象编程语言中的对象之间进行转换的技术。它将对象和关系数据库的概念进行映射,最后我们就可以通过方法调用进行数据库操作!!
最终: **让我们可以使用面向对象思维进行数据库操作!!!**
**ORM 框架通常有半自动和全自动两种方式。**
- 半自动 ORM 通常需要程序员手动编写 SQL 语句或者配置文件,将实体类和数据表进行映射,还需要手动将查询的结果集转换成实体对象。
- 全自动 ORM 则是将实体类和数据表进行自动映射,使用 API 进行数据库操作时,ORM 框架会自动执行 SQL 语句并将查询结果转换成实体对象,程序员无需再手动编写 SQL 语句和转换代码。
**下面是半自动和全自动 ORM 框架的区别:**
1. 映射方式:半自动 ORM 框架需要程序员手动指定实体类和数据表之间的映射关系,通常使用 XML 文件或注解方式来指定;全自动 ORM 框架则可以自动进行实体类和数据表的映射,无需手动干预。
2. 查询方式:半自动 ORM 框架通常需要程序员手动编写 SQL 语句并将查询结果集转换成实体对象;全自动 ORM 框架可以自动组装 SQL 语句、执行查询操作,并将查询结果转换成实体对象。
3. 性能:由于半自动 ORM 框架需要手动编写 SQL 语句,因此程序员必须对 SQL 语句和数据库的底层知识有一定的了解,才能编写高效的 SQL 语句;而全自动 ORM 框架通过自动优化生成的 SQL 语句来提高性能,程序员无需进行优化。
4. 学习成本:半自动 ORM 框架需要程序员手动编写 SQL 语句和映射配置,要求程序员具备较高的数据库和 SQL 知识;全自动 ORM 框架可以自动生成 SQL 语句和映射配置,程序员无需了解过多的数据库和 SQL 知识。
常见的半自动 ORM 框架包括 MyBatis 等;常见的全自动 ORM 框架包括 Hibernate、Spring Data JPA、MyBatis-Plus 等。
3.3.2 逆向工程
MyBatis 的逆向工程是一种自动化生成持久层代码和映射文件的工具,它可以根据数据库表结构和设置的参数生成对应的实体类、Mapper.xml 文件、Mapper 接口等代码文件,简化了开发者手动生成的过程。逆向工程使开发者可以快速地构建起 DAO 层,并快速上手进行业务开发。
MyBatis 的逆向工程有两种方式:通过 MyBatis Generator 插件实现和通过 Maven 插件实现。无论是哪种方式,逆向工程一般需要指定一些配置参数,例如数据库连接 URL、用户名、密码、要生成的表名、生成的文件路径等等。
总的来说,MyBatis 的逆向工程为程序员提供了一种方便快捷的方式,能够快速地生成持久层代码和映射文件,是半自动 ORM 思维像全自动发展的过程,提高程序员的开发效率。
**注意:逆向工程只能生成单表crud的操作,多表查询依然需要我们自己编写!**
3.3.3 逆向工程插件MybatisX的使用
a.下载MybatisX插件
b.连接我们的数据库
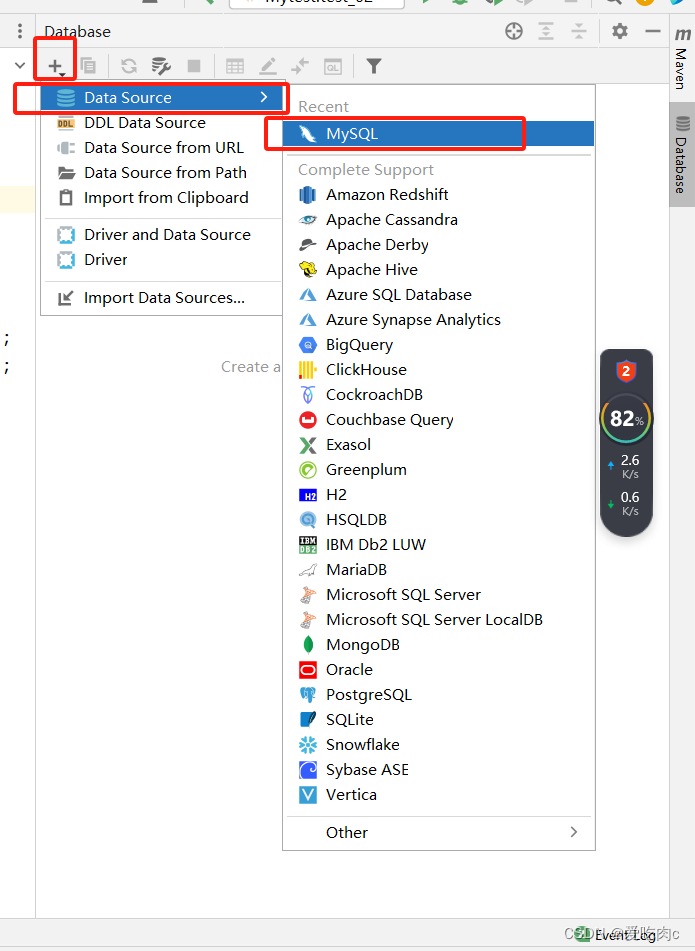
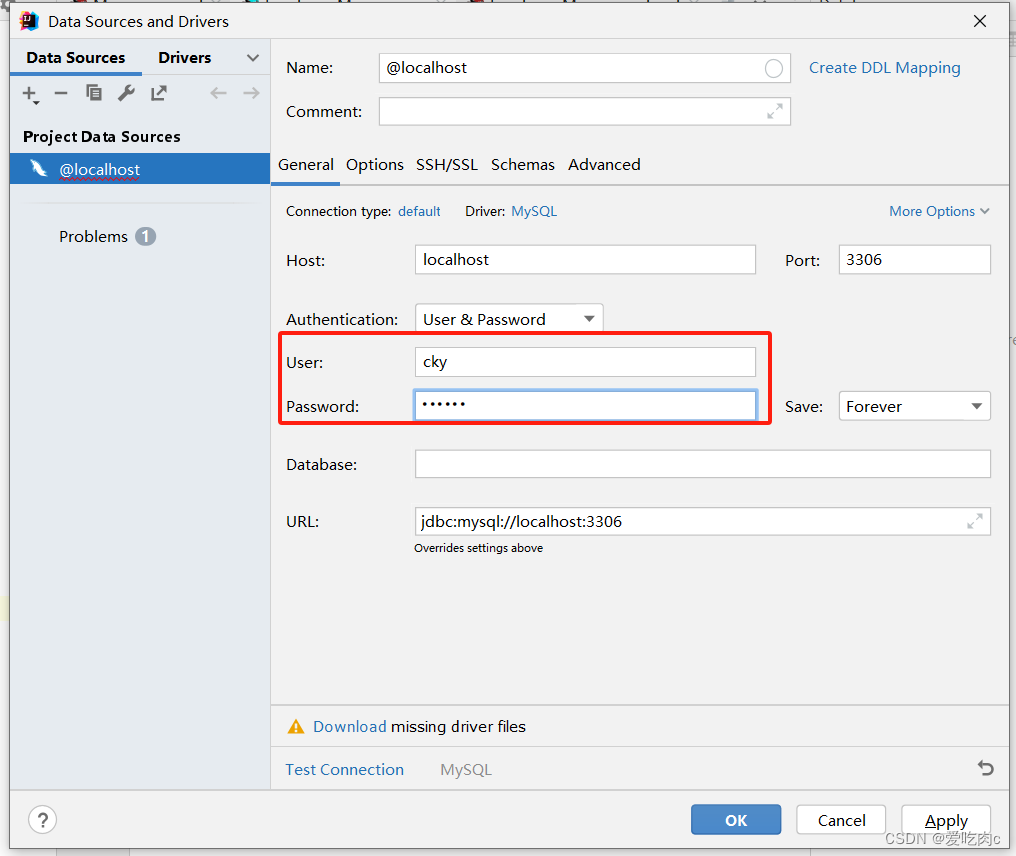

c.逆向工程使用
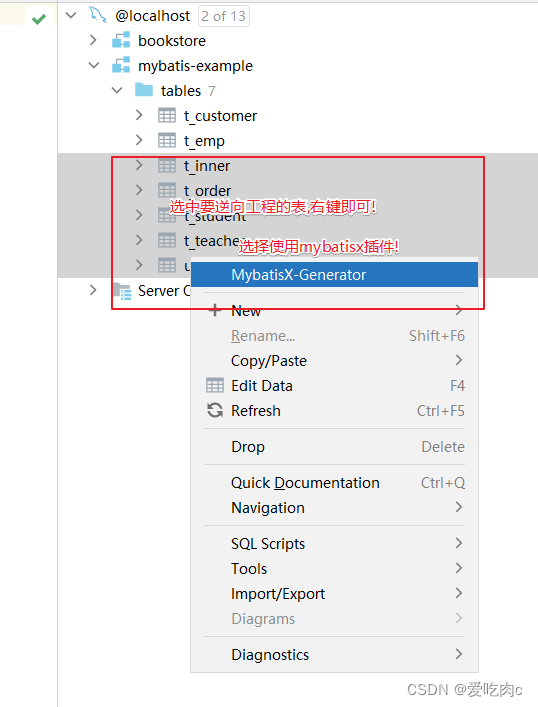
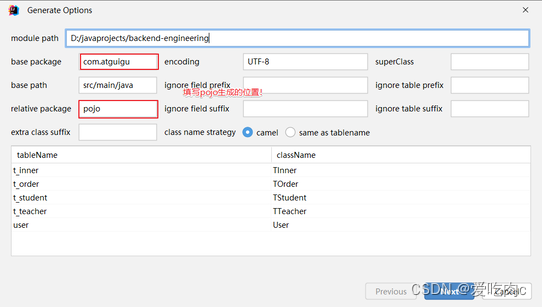
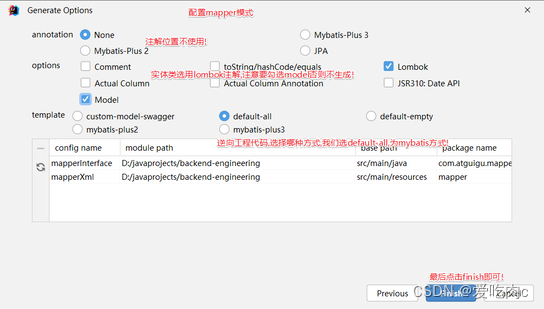
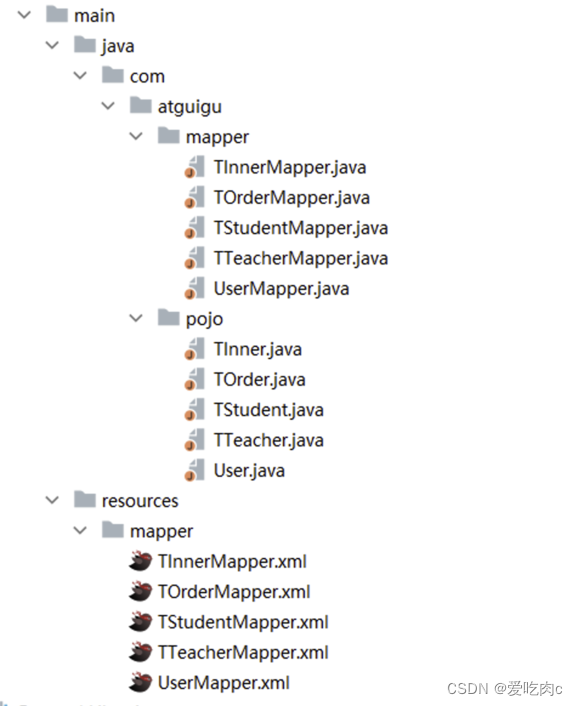
查看生成结果:
4、Mybatis总结