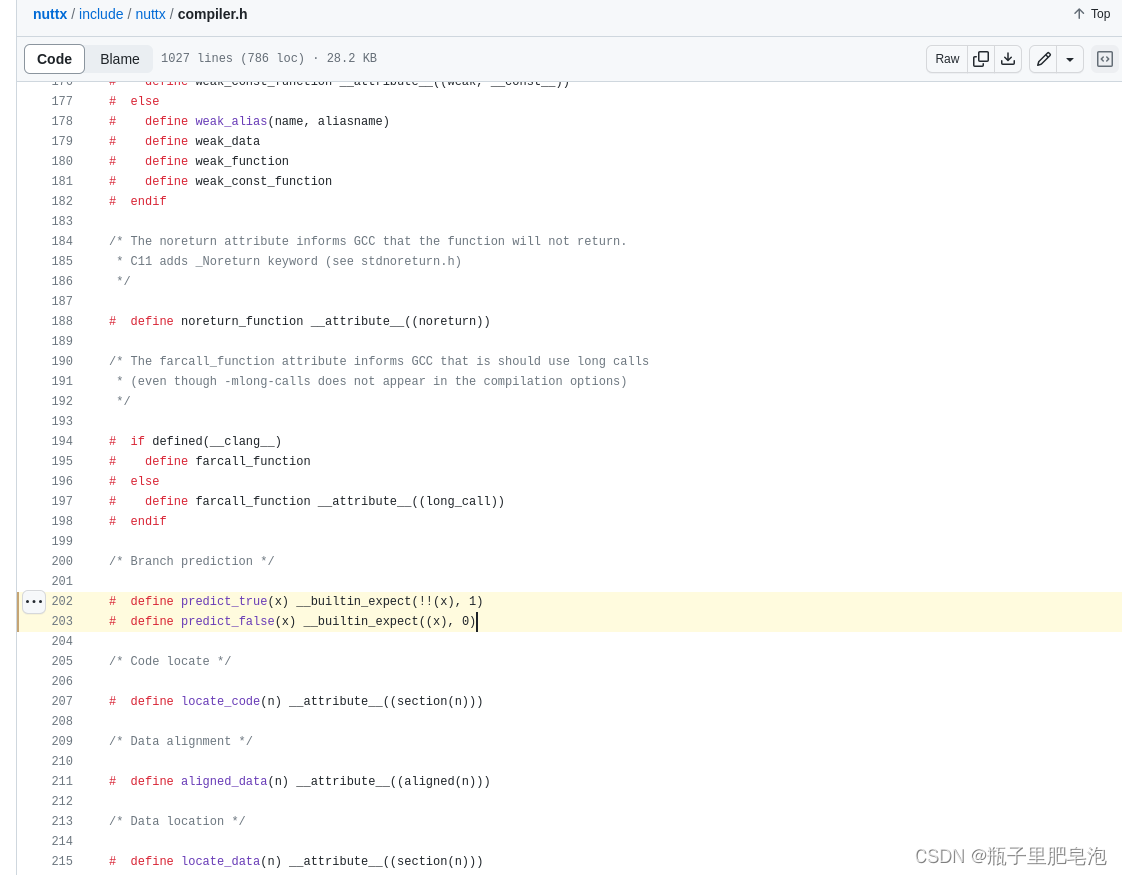
在Linux中,__predict_false和__predict_true是用于优化分支预测的宏。这些宏通过向编译器提供关于条件分支可能结果的提示,来帮助生成更有效的机器代码。
__predict_false宏扩展为一个属性,该属性指示编译器预测给定分支可能为假。这意味着,如果你有一个条件语句,你认为在大多数情况下该条件都不会满足,那么你可以使用__predict_false宏。这样,编译器就会生成一些优化的指令,使得在该条件为假时的执行路径更加高效。
这种优化主要是针对现代处理器的分支预测机制。处理器会尝试预测条件分支的结果,以便提前获取和执行指令。如果预测正确,那么这个跳转指令基本上是免费的,不需要任何额外的处理周期。然而,如果预测错误,那么处理器就需要清空其指令流水线,并重新获取和执行指令,这可能会花费几个处理周期。
因此,使用__predict_false和__predict_true这样的宏可以帮助编译器生成更有效的代码,但前提是你对代码的行为有足够的理解,并且能够准确地预测哪些条件更可能为真或假。在大多数情况下,除非你正在优化一个性能瓶颈,否则可能没有必要使用这些宏。
编译器和处理器通过一种称为分支预测的技术来处理条件分支。这种技术的目标是改进指令流水线中的流动。
编译器在编译时可以进行一些优化,以提高分支预测的准确性。例如,它可以确定最高概率路径,并在整个路径上进行优化,而不仅仅是在基本块内。有时,编译器会生成利用硬件分支预测能力的间接分支代码。
处理器在运行时进行动态分支预测。它会尝试预测条件跳转是否会被采取。如果预测正确,那么这个跳转指令基本上是免费的,不需要任何额外的处理周期。然而,如果预测错误,那么处理器就需要清空其指令流水线,并重新获取和执行指令,这可能会花费几个处理周期。
现代微处理器通常有很长的流水线,这使得错误预测的延迟在10到20个时钟周期之间。因此,使流水线更长会增加对更先进的分支预测器的需求。
值得注意的是,分支预测并不等同于分支目标预测。分支预测试图猜测一个条件跳转是否会被采取。而分支目标预测试图在通过解码和执行指令本身之前猜测一个已采取的条件或无条件跳转的目标。这两种预测通常会合并到同一电路中。
参考nuttx源码,源码路径在:https://github.com/apache/nuttx/blob/master/include/nuttx/compiler.h#L202-L203