前言:
RL(Reinfocement Learning) 强化学习 是机器学习,深度学习一个重点。
后面20章将重点结合一些例子回顾一下经典的强化学习算法。
这里重点介绍一下机器学习中的强化学习算法,以及Gym 工具
目录:
- 简介
- 强化学习基本要素
-
贪心算法
- softmax 算法
- Gym
一 简介
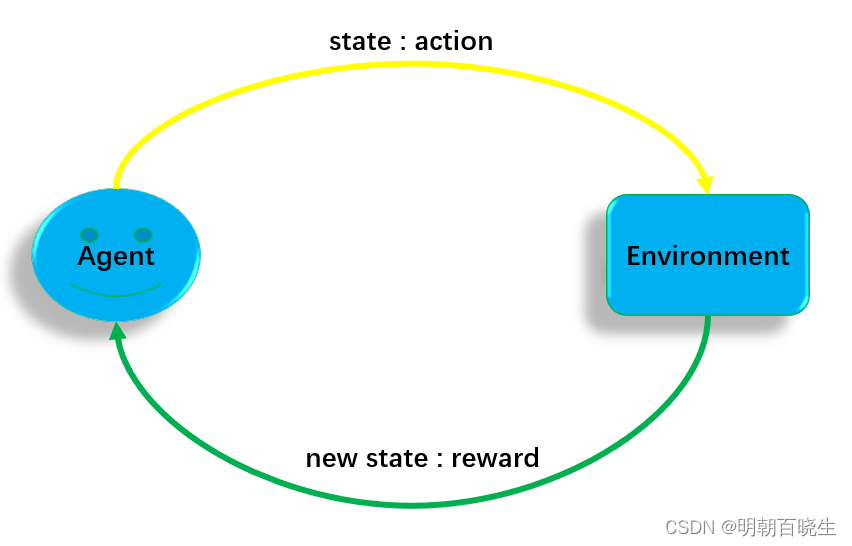
强化学习是智能体(Agent)以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使智能体获得最大的奖赏,强化学习不同于连接主义学习中的监督学习,主要表现在强化信号上,强化学习中由环境提供的强化信号是对产生动作的好坏作一种评价(通常为标量信号),而不是告诉强化学习系统RLS(reinforcement learning system)如何去产生正确的动作。由于外部环境提供的信息很少,RLS必须靠自身的经历进行学习。通过这种方式,RLS在行动-评价的环境中获得知识,改进行动方案以适应环境。
二 强化学习基本要素
| 强化学习五要素 |
| Agent |
| Environment |
| State |
| Action |
| Reward |
t 时刻 Agent 的状态
: t 时刻 Agent 根据当前的
采取的action
: t时刻Agent 采取了action,状态更新到
,得到的reward
策略: 在状态
下面,agent 选择a 的概率。
,通常用Qtable 来维护.
: Agent 在t时刻采取的动作
,获得奖励
,整个过程的贡献.
公式:
为greed算法即t时刻价值仅由t+1时刻收益决定
t时刻价值由随后每一步收益等比例决定。
三 贪心算法
这是机器学习里面一种经典的算法

参数说明:
: n次action 后的平均奖赏:
优化方案:通过每次通过单次奖赏与前边所有次的平均奖赏来计算本次动作后的平均奖赏
若每个动作奖赏的不确定性较大,如概率分布较宽时,则需更多的探索,此时需要较大的ϵ值
若每个动作奖赏的不确定性较小,如概率分布较集中时,则少量的尝试就能很好地近似真实奖赏,此时需要的ϵ较小通常令ϵ取一个较小的常数,如0.1或0.01
若尝试次数非常大,则在一段时间后,奖赏都能很好地近似出来,不再需要探索,这种情形下可让ϵ随着尝试次数的增加而逐渐减小,例如 ϵ=1∕√t
四: softmax
softmax算法是另一种对探索和利用进行这种的算法, 它基于Blotzmann分布:
公式16.4: 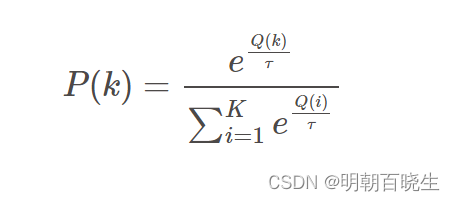
其中Q(i)为当前摇臂的平均奖励,为温度:
其越小则平均奖励搞得摇臂被选取的概率越高,
趋于0时策略将趋于仅利用,
趋于无穷大时策略则将趋于仅探索.

五 Gym
是一个强化学习工具,里面包含很多游戏,用于验证强化学习算法
以一个乒乓球游戏为例:
import gym
env = gym.make('Tennis-v4', render_mode="human")
#print("观测空间: ", env.observation_space)
print("动作空间 ", env.action_space)
print("动作空间s数 ", env.action_space.n)
state = env.reset()
#print("初始状态:", state)
for i in range(5000):
action = env.action_space.sample()
state, reward, done, info = env.step(action)
print('动作:', action, '当前状态:', state, '奖励:', reward, '是否结束:', done, '日志:', info)
print("\n ----end-----")
env.close()
函数介绍:
3.1 reset: 初始化
'''
* @breif: 重置环境,回到初始状态
* @param[in]: seed -> 随机种子
* @retval: 环境初始观测状态
'''
state = env.reset(seed=None)
3.2 make: 环境创建
'''
* @breif: 生成环境对象
* @param[in]: id -> 启用环境的名称
* @param[in]: render_mode -> 渲染模式
* @retval: 环境对象
'''
env = gym.make(id:str, render_mode:str)
3.3 step
'''
* @breif: 单步执行环境动力学过程
* @param[in]: 动作
* @retval: 四元组(当前状态, 奖励, 额外限制, 日志)
'''
state, reward, done,info = env.step(action)
3.4 close
env.close()上面我们通过不同的Algorithm,来更新Qtable,
当学习好了Qtable,
action=np.argmax: 我们可以根据当前的state,选择一个最优的action,
env.step(action): 根据action 来更新环境
env.render: 渲染当前的窗口

安装流程:aPytorch深度强化学习1-1:Gym安装与环境搭建教程(附基本指令表)_安装gym_Mr.Winter`的博客-CSDN博客
强化学习第一节(RL基本概念+工具+R算法)【个人知识分享】_哔哩哔哩_bilibili
第16节:强化学习RL_1.为何学习增强学习_[]_哔哩哔哩_bilibili
周志华《机器学习》“西瓜书”+“南瓜书” :第16章 强化学习
OpenAI Gym 经典控制环境介绍——CartPole(倒立摆) - 知乎
![释放搜索潜力:基于ES(ElasticSearch)打造高效的语义搜索系统,让信息尽在掌握[2.项目讲解篇],支持Linux/Windows部署安装](https://img-blog.csdnimg.cn/d553c7dadca54bdb82a3a234befb74d8.png#pic_center)