分析目的
通过电商API接口获取的数据分析销售数据来了解在线销售业务的消费情况,分析用户消费数据来分析用户的消费行为,为用户推荐相匹配的商品。
分析问题
店铺销售情况
每月成交额
每月销售金额
每月消费人数
每月订单数量
每月客单价
不同省份用户数量
不同省份订单数量
不同省份成交金额
订单数随星期分布
订单随小时分布
用户消费行为
用户消费次数
用户消费金额
消费次数与消费金额关系
用户购买周期
新用户、活跃用户、不活跃用户、回流用户、回流率
复购率和回流率
消费人群分层情况
按性别分析
按年龄段分析
按喜好品牌分析
03
结论先行
1、销售金额、订单量、消费人数、客单价在清明小长假、五一小长假、暑假、开学季、十一小长假,几个假期节点表现不错,尤其是开学季的情况最好,在几个关键的节点开始前,店铺一定要提前储备库存,保证货源。
2、北上广销售金额、订单量、消费人数、客单价都优于其他省份,湖南省消费人数少,但是客单价、订单量都表现优异,湖南省潜力巨大,因此要加大对湖南省的宣传力度,增加湖南省的消费人数。
3、75%的消费人群购买力不高,对30岁以下的人群主要推荐亲民价格的商品。
4、40-50岁的人群购买力高,而且男性对高价格的商品购买力强,因此给40-50岁的男性推荐高价格的商品,对女性推荐较高价格的商品。
5、多数用户至少消费了两次,且消费金额与购物次数有较强的正相关,用户消费次数越多销售额越大。可在8天、28天对用户进行召回,引导客户消费。
6、订单集中在早晨,8点到13点是消费高峰期,这段时间要注意维持好网站的稳定性。
7、店铺可以在1-4月份减少营业人员,5-11月增加营业人员,应对销售高峰期。
接下来给大家介绍一下分析的过程,包括数据嗅探、数据清洗等步骤。
04
数据分析过程
数据嗅探
#导入第三方库import osfrom datetime import datetimeimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns%matplotlib inline#设置中文编码和负号的正常显示#plt.rcParams['font.sans-serif']=['SimHei']plt.rcParams['axes.unicode_minus']=False#导入数据df=pd.read_csv('./电子产品销售分析.csv')df.head()
输出结果:
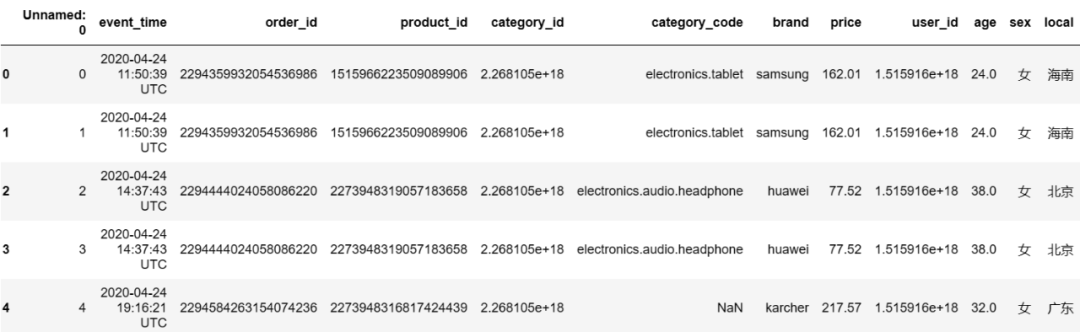
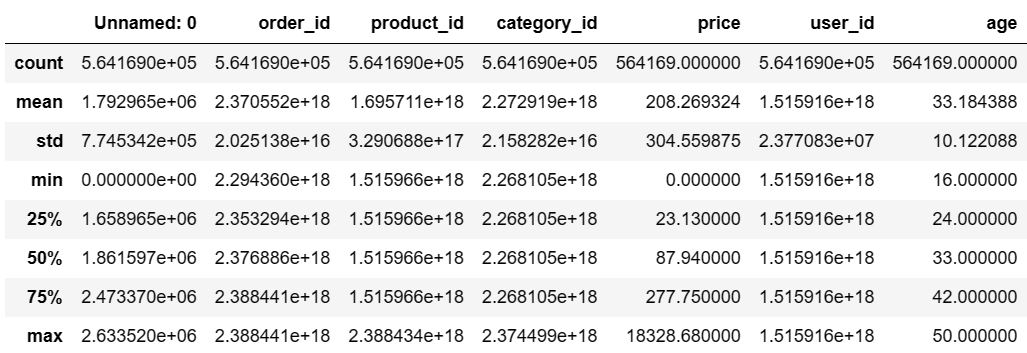
df.describe()输出结果:
数据清洗
#数据清洗和处理#数据类型转化df['event_time'] =pd.to_datetime(df['event_time'].str[:19],format="%Y-%m-%d %H:%M:%S")df['event_time'] = pd.to_datetime(df['event_time'])#计算时间变量df['Month']=df['event_time'].dt.monthdf['Day'] = df['event_time'].dt.daydf['Dayofweek']=df['event_time'].dt.dayofweekdf['hour']=df['event_time'].dt.hourdf.head()
输出结果:

np.sum(df.isnull())输出结果:
Unnamed: 0 0event_time 0order_id 0product_id 0category_id 0category_code 129370brand 27224price 0user_id 0age 0sex 0local 0Month 0Day 0Dayofweek 0hour 0dtype: int64
有两列中有数据缺失值,类别列缺失129370条,品牌列缺失27224条,这两列数值缺失对店铺销售情况的分析和用户消费行为的分析没主要影响,但是其他数据有重要影响,所以这两列缺失值由missing填充。
df.fillna('missing').head()输出结果:

np.sum(df.isnull())输出结果:
Unnamed: 0 0event_time 0order_id 0product_id 0category_id 0category_code 129370brand 27224price 0user_id 0age 0sex 0local 0Month 0Day 0Dayofweek 0hour 0dtype: int64
df['category_code'].fillna('missing',inplace=True)df['brand'].fillna('missing',inplace=True)np.sum(df.isnull())
输出结果:
Unnamed: 0 0event_time 0order_id 0product_id 0category_id 0category_code 0brand 0price 0user_id 0age 0sex 0local 0Month 0Day 0Dayofweek 0hour 0dtype: int64
缺失值已全部填充。
#重复值检查和处理df.duplicated()df.drop_duplicates()
输出结果: