提示工程可以描述为一种艺术形式,为大型语言模型(LLMs)创建输入请求,以实现预期的输出。以下是创造单个或一系列提示的不同技巧。
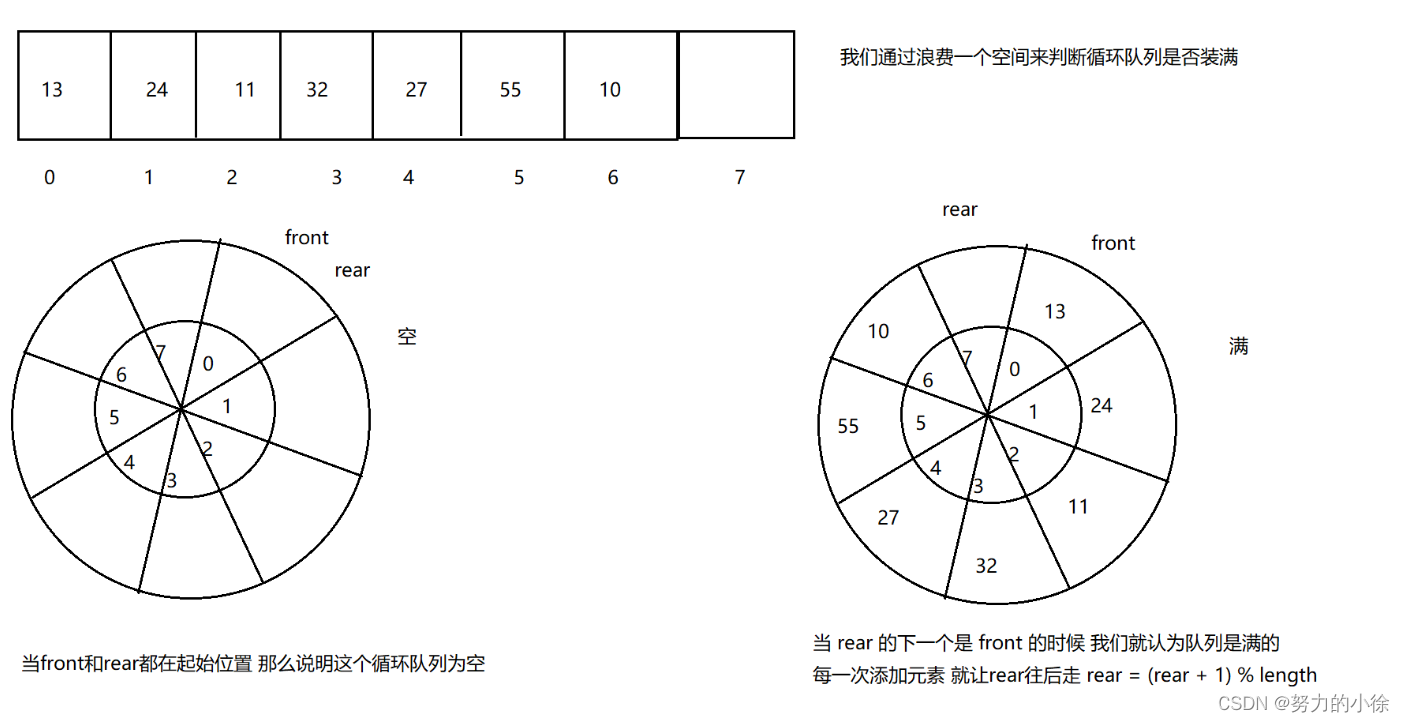
由少到多的提示
推理过程是基于证据和推理得出结论。反过来,可以通过为LLM提供一些关于如何推理和使用证据的示例来生成推理。因此,开发了一种新颖的提示策略,名为从少到多的提示。这种方法基于以下策略:
1. 将复杂问题分解为一系列更简单的子问题,并随后解决每个子问题。
2. 通过先前解决的子问题的答案来促进解决每个子问题。
因此,从少到多的提示是一种使用逐步序列提示以达到最终结论的技术
自答提示
考虑到下面的图片,很明显自问提示是从直接和链式思维提示的进展。
自问提示有趣的地方在于LLM推理被明确地展示出来,并且LLM还将问题分解成更小的后续问题。
LLM知道何时达到最终答案,并可以从中间答案的后续步骤移动到最终答案。

元提示
支撑元提示的关键原则是使代理反思其自身表现并相应地修改其指令。同时使用一个总体的元提示。
思维链提示
我们作为人类会直觉地将一个更大的任务或问题分解成子任务,然后将这些子任务链接在一起。使用一个子任务的输出作为下一个子任务的输入。
通过在OpenAI Playground中使用思维链提示的方法,即提供思维链的具体示例作为指导,可以展示大型语言模型如何发展出复杂的推理能力。
研究表明,当以这种方式被提示时,足够大型的语言模型可以实现推理能力的涌现。
ReAct提示
与人类相比,推理和行动之间的紧密协同作用使得人类能够快速学习新任务并执行强大的推理和决策。即使在面临未预料的情况、信息或不确定性时,我们仍能做到这一点。
大型语言模型已经在链式思维推理(CoT)和提示以及行动(生成行动计划)方面展示了令人印象深刻的结果。
ReAct的想法是将推理和采取行动结合起来。推理使模型能够诱导、跟踪和更新行动计划,而行动则允许从外部来源收集额外的信息。
将这些想法结合起来被称为ReAct,并且它被应用于一组多样化的语言和决策任务中,以展示其相对于最先进的基线方法的有效性,并提高人类可解释性和可信度。
符号推理& PAL(Probabilistic Abstraction Latent Dirichlet Allocation)
LLMs应该不仅能够执行数学推理,还应该能够进行符号推理,涉及与颜色和对象类型相关的推理。考虑以下问题:
I have a chair, two potatoes, a cauliflower, a lettuce head, two tables, a cabbage, two onions, and three fridges. How many vegetables do I have?LLMs应该能够将输入转换为一个字典,其中实体和值根据它们的数量进行分类,同时过滤掉非蔬菜实体。
最后,答案就是字典值的总和,低于从LLM输出的PAL结果:
# note: I'm not counting the chair, tables, or fridgesvegetables_to_count = {'potato': 2,'cauliflower': 1,'lettuce head': 1,'cabbage': 1,'onion': 2}answer = sum(vegetables_to_count.values())
迭代提示
最近,重点已经从LLM微调转向增强提示工程。确保提示具有上下文,包含少量样本训练示例和对话历史记录。
通过迭代过程确保提示包含上下文信息。
迭代提示应建立上下文思维链,排除无关事实和幻觉的生成。交互式上下文感知和上下文提示。
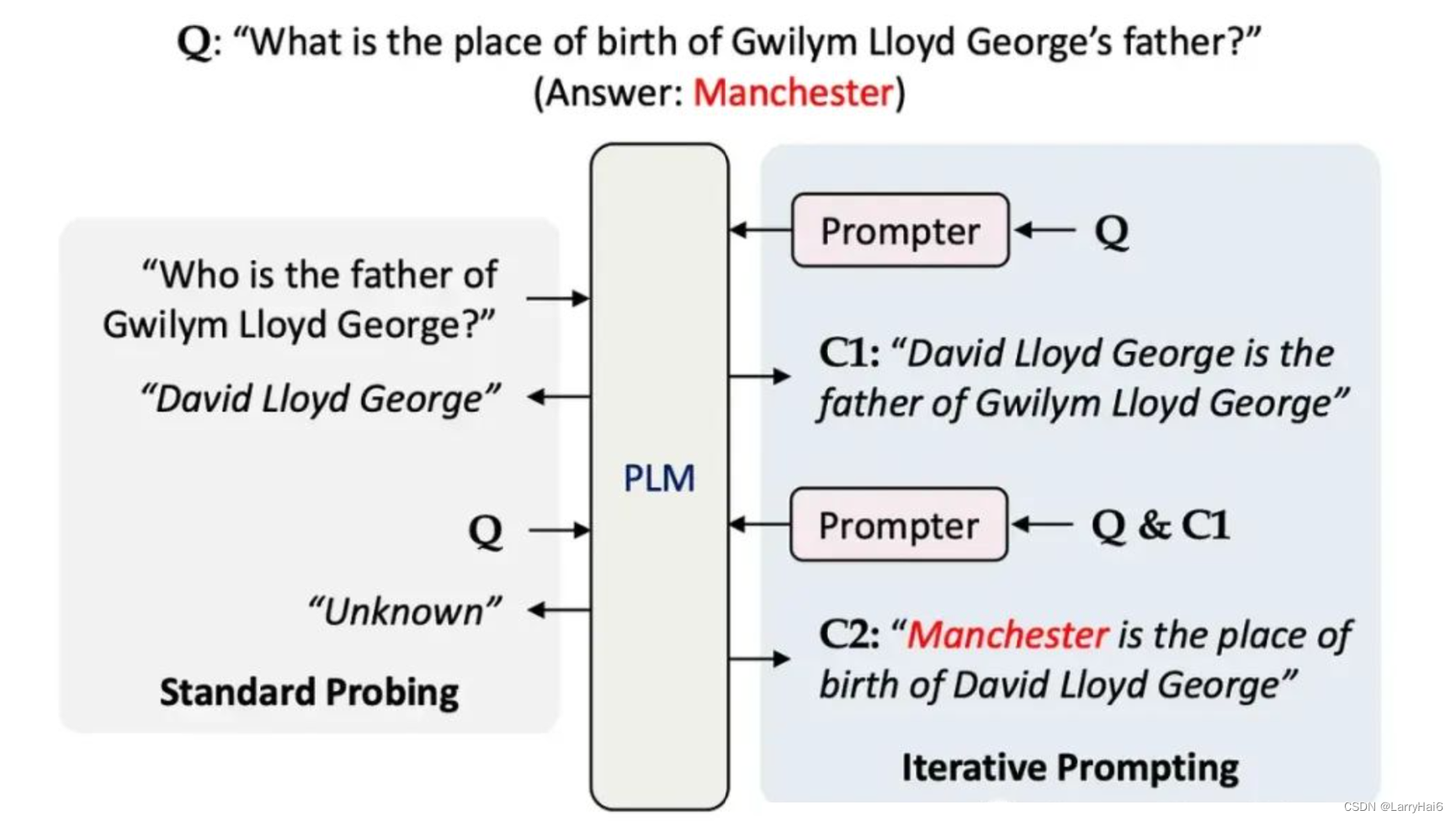
考虑到上面的图片,在C1和C2,知识对于准确回答问题非常重要。迭代提示的方法包含了思维链提示和流水线的强有力元素。
序列提示
顺序提示考虑了使用LLMs构建可靠推荐器的可能性。通常,推荐系统采用流水线架构进行开发,包括多阶段候选生成(检索更多相关项目)和排名(将相关项目排在更高位置)过程。
顺序提示专注于推荐系统的排名阶段,因为大规模候选集上的LLM运行成本较高。
排名性能对检索到的顶级候选项目敏感,更适合检查LLM推荐能力的差异。
自我一致性
与思维链推理不同,自我一致性利用了直觉:复杂的推理问题通常有多个不同的思考路径,导致其唯一正确的答案。
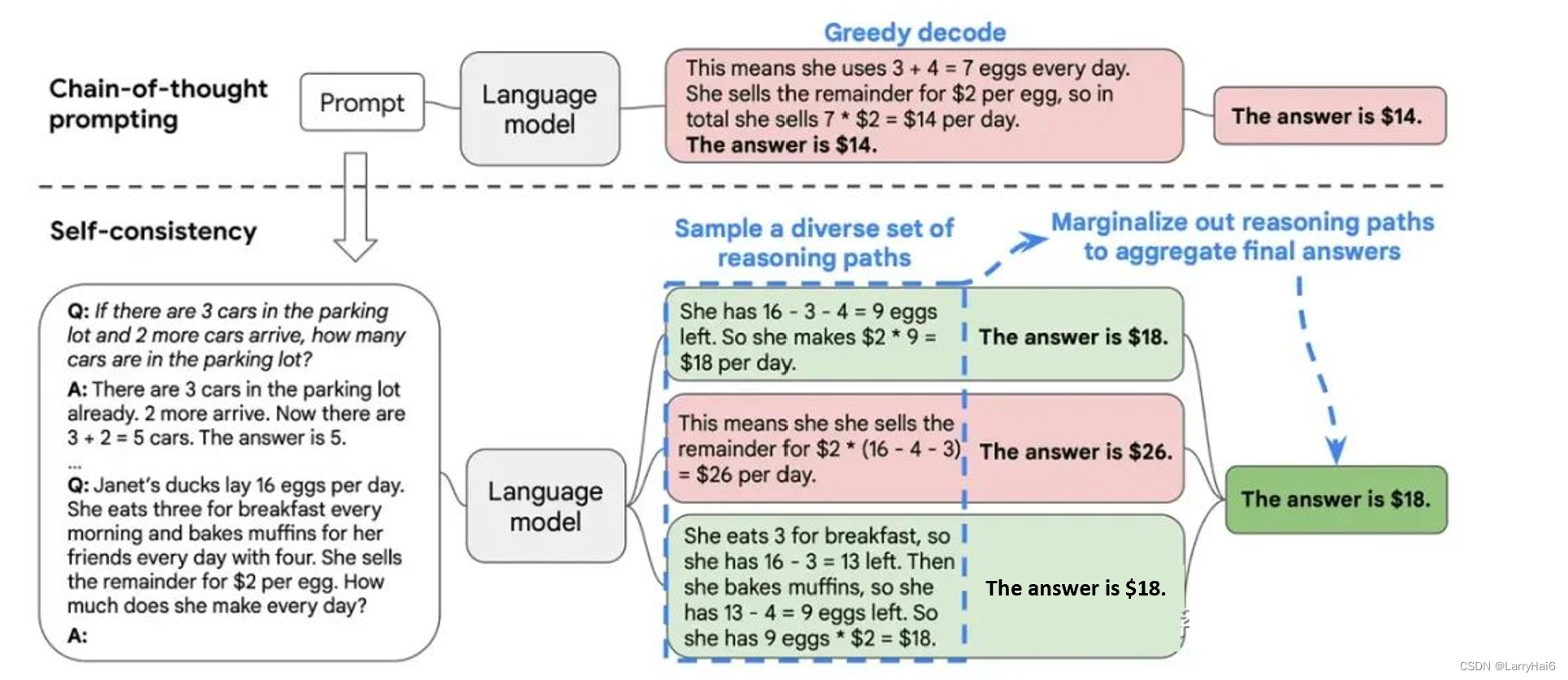
自我一致性方法由三个步骤组成:
-
提示LLM生成思维链(CoT)推理部分。
-
生成多种推理路径。
-
选择最终答案的最一致输出。
自我一致性方法所采用的方法可能会引入增加的开销;特别是如果每个CoT的步骤都涉及调用外部工具和API,则开销会以额外成本和完成往返时间的形式表现出来。
自动推理和工具使用(ART)
已经证明,思维链提示可以从LLMs中引出复杂和顺序推理。而且,对于每个步骤,可以使用外部工具来改进特定节点生成的输出。
开发这些方法学的前提是为了利用冻结的大型语言模型(LLM),从而增强之前训练过的时间戳模型。
自动推理与工具使用(ART)是一个框架,它也利用冻结的模型来生成中间推理步骤作为程序。
ART的方法强烈地提醒了Agents的原则,即将问题分解为多个步骤,并利用工具处理每个分解步骤。
使用ART时,冻结的LLM将新任务的实例分解成多个步骤,并在适当的情况下使用外部工具进行操作。
ART是一种无微调的自由方法,用于自动化多步推理和自动工具选择和使用。
生成的知识
生成知识的原则是,在推理时可以整合知识。这表明可以利用参考知识替代模型微调。
在不同的数据集、常识推理等方面进行了测试。
生成知识的原则得到了像RAG、流水线等技术的发展支持。
----------------------------------
大家好,我是流水,一个资深的IT从业人员和架构师. 非常高兴您能搜索到,并看到这篇文章,希望这篇文章的内容能给您带来新的知识和帮助。
也欢迎扫描以下的二维码或微信搜索 “superxtech”,关注我的微信公众号 , 我会把更多更好的IT领域技术知识带给您!

----------------------------------