目录
- 系统文件IO
- open函数
- 0 & 1 & 2
- 文件描述符的分配规则
- 重定向
- 输入重定向
- 输出重定向
- 追加重定向
- dup2
- FILE
- 文件系统
- inode
- 软硬链接
- 软链接
- 硬链接
- 动态库和静态库
- 动静态库的命名方式
- 静态库
- 制作一个库
- 使用库
- 动态库
- 制作一个库
- 使用库
系统文件IO
open函数
int open(const char *pathname, int flags); //文件存在选这个函数
int open(const char *pathname, int flags, mode_t mode); //文件不存在选这个函数
pathname: 要打开或创建的目标文件
flags: 打开文件时,可以传入多个参数选项,用下面的一个或者多个常量进行“或”运算,构成flags。
参数:
O_RDONLY: 只读打开
O_WRONLY: 只写打开
O_RDWR : 读,写打开
这三个常量,必须指定一个且只能指定一个
O_CREAT : 若文件不存在,则创建它。需要使用mode选项,来指明新文件的访问权限(比如:0666)
O_APPEND: 追加写
O_TRUNC:每次打开对文件时清理
返回值:
成功:新打开的文件描述符
失败:-1
mode_t理解:直接 man 手册,比什么都清楚。
open 函数具体使用哪个,和具体应用场景相关,如目标文件不存在,需要open创建,则第三个参数表示创建文件的默认权限,否则,使用两个参数的open。
0 & 1 & 2
Linux任何一个进程,在启动的时候,默认会3个文件,分别是标准输入0, 标准输出1, 标准错误2.
0,1,2对应的物理设备一般是:键盘,显示器,显示器
🔍当调用write函数时,OS做了什么?
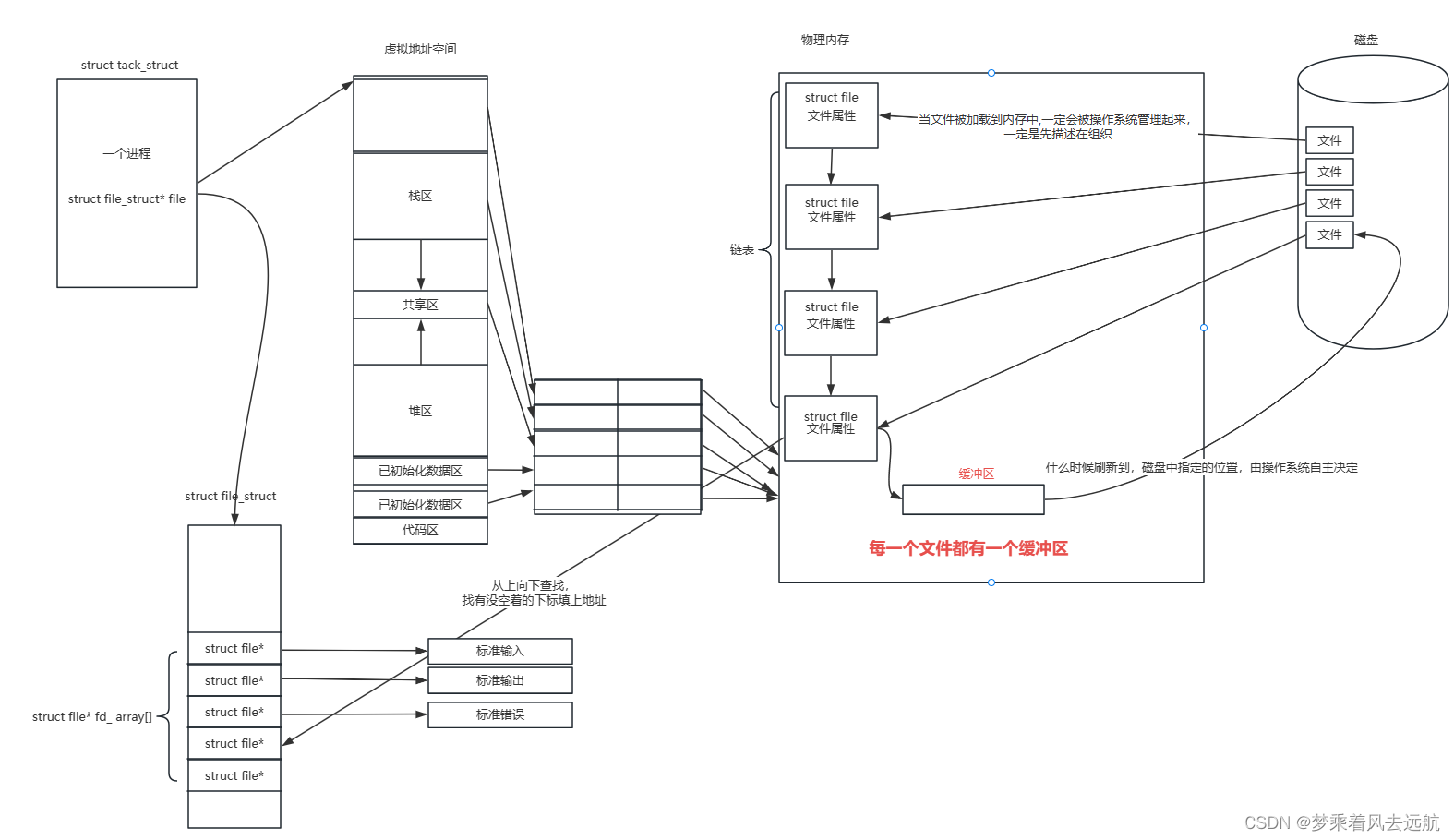
首先执行这个write函数的一定是你自己的进程在执行,不是其他人进程在执行,是你这个进程。当在数据写入时,你其实是调了write函数,然后操作系统识别到系统要用,然后OS就帮你去写入了。他在写入时首先要做的工作,找到你这个进程的PCB,因为是文件操作,所以他要找struct file_struct* file,然后拿着你传进来的文件描述符在数组中找到struct file*,所以就找到匹配的文件,将用户层所对应的数据直接从应用层通过这种索引方式拷贝到对应的缓冲区当中。
write或read函数本质,拷贝函数
文件描述符的分配规则
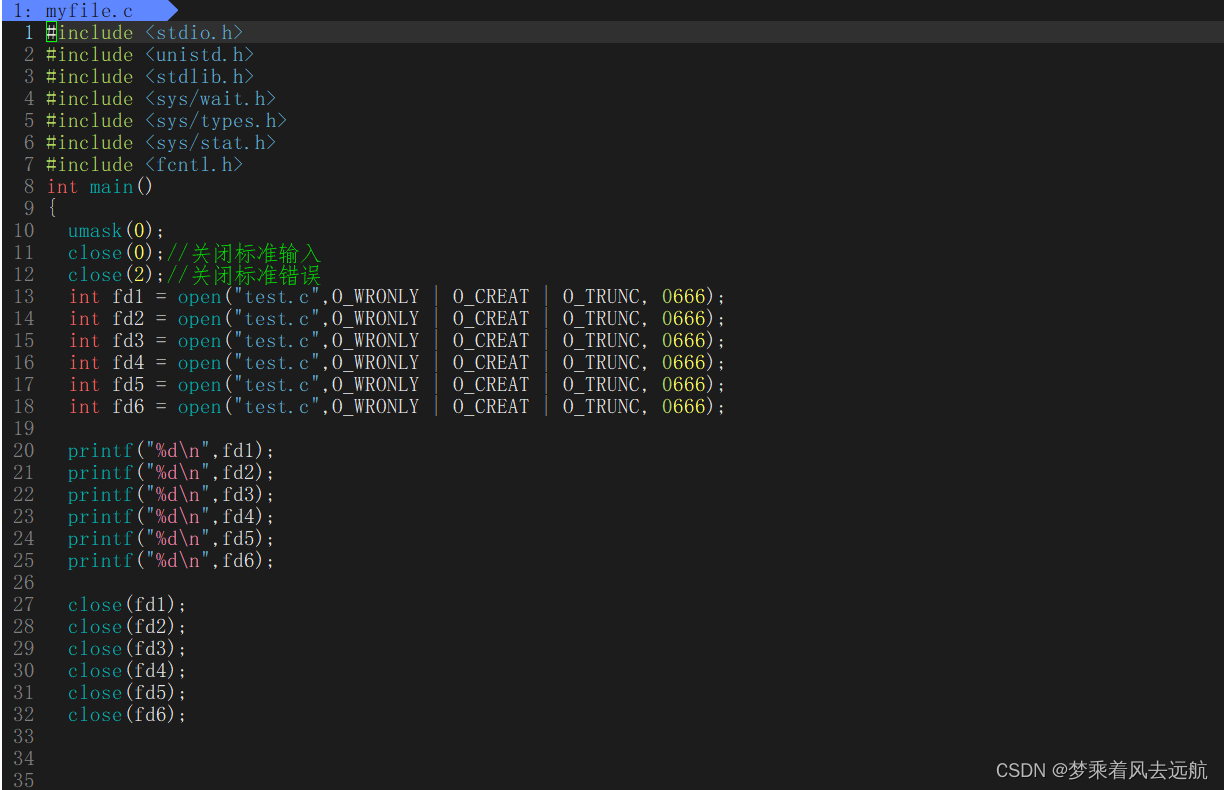
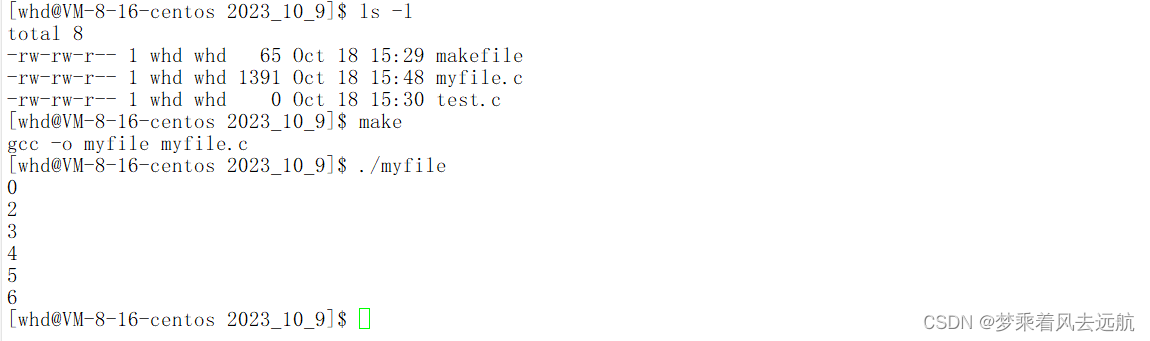
进程中,文件描述符的分配规则:在文件中描述符中,最小的没有被使用的数组元素,分配给新文件或打开的文件,依次从上向下分配。
重定向
重定向的原理:在上层无法感知的情况下,在OS内部更改进程对应的文件描述表中特定下标的指向。
输入重定向
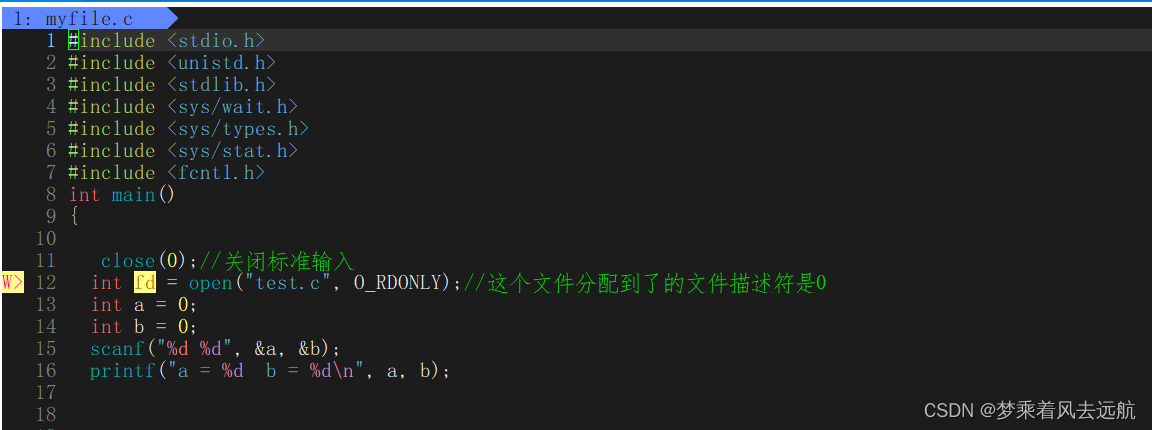

输出重定向
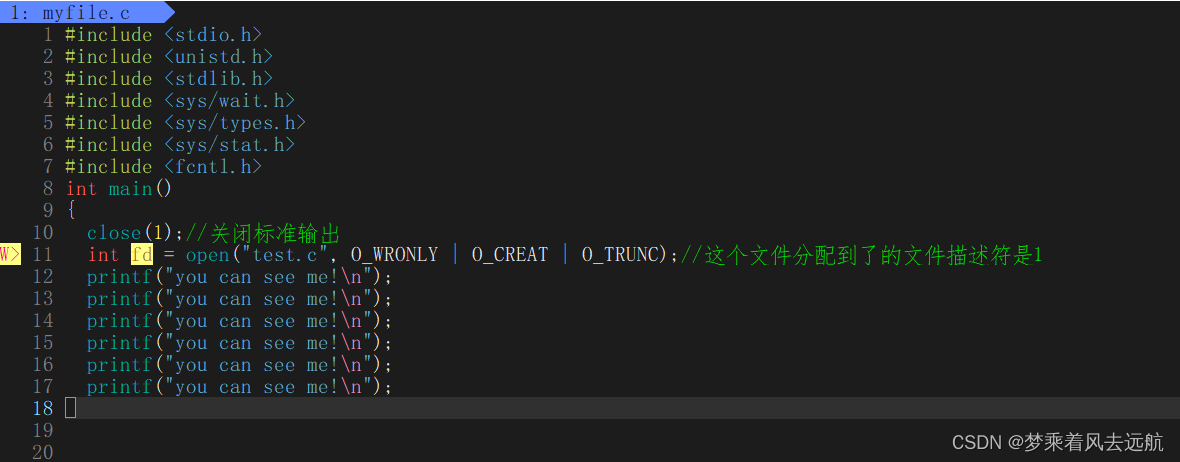
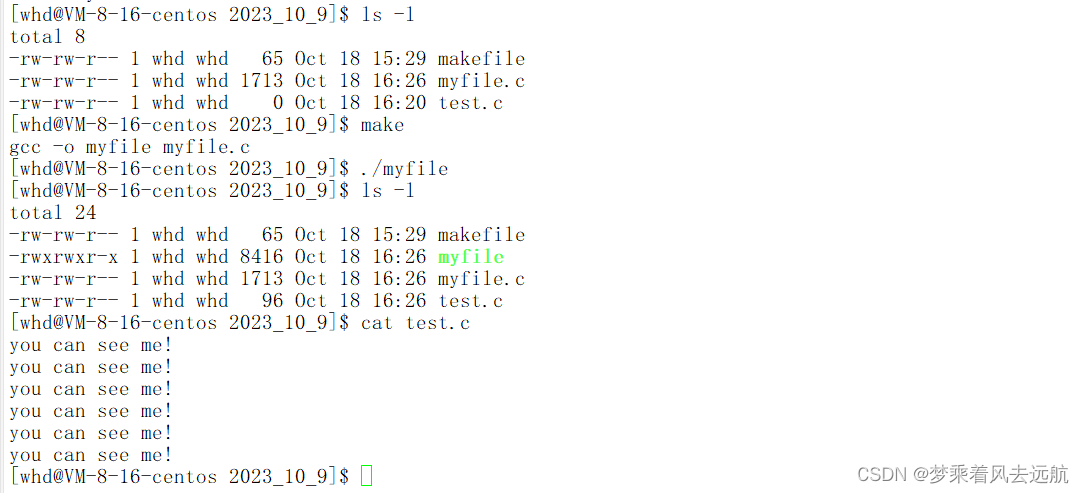
追加重定向
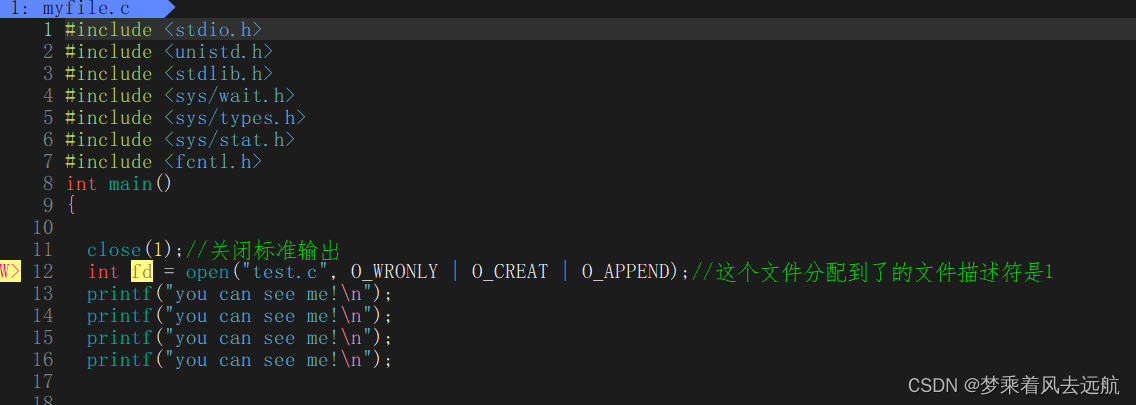

标准输出与标准错误的区别。
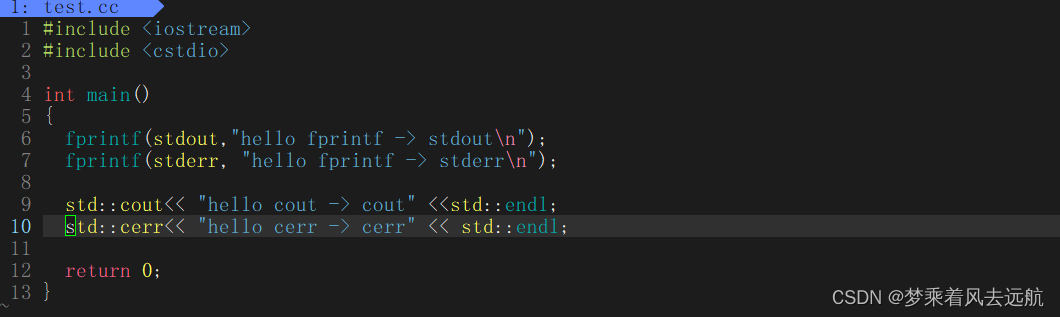
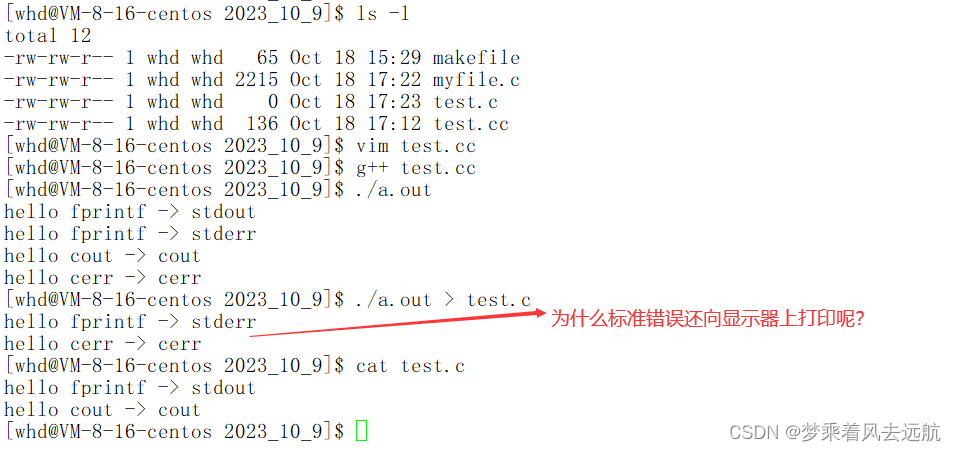
因为:输出重定向,只改的是1标准输出描述符对应的指向,2号标准错误文件描述不受影响。
dup2
int dup2(int oldfd, int newfd);
函数功能:
将newfd文件夹描述符中的内容重定向到oldfd文件描述中。
FILE
因为IO相关函数与系统调用接口对应,并且库函数封装系统调用,所以本质上,访问文件都是通过fd访问的。
所以C库当中的FILE结构体内部,必定封装了fd
我们用的编程语言,都是在操作系统的上层,用C语言时调printf调fprintf,那么这样的接口是你只是把数据从你自己写的代码当中交给了C标准库,C标准库它内部会帮我们维护对应的缓冲区,缓冲区维护好之后,它会按照自己的一定的刷新测略,将数据从你的FILE中的fd刷新到特定进程所对应的文件的缓冲区中,然后在刷新到磁盘中。
C库的刷新策略
- 无缓冲:是在进行写入操作时,直接刷新到OS(操作系统)中。
- 行缓冲:当我们将数据写到缓冲区时,只要碰到
\n,就将\n前的数据刷新的OS中。 - 全缓冲:只有当缓冲区写满时,才将数据刷新到OS中。
显示器采用的是的刷新策略是:行缓存
普通文件采用的是的刷新策略是:全缓冲
🔍为什么要有缓冲区?
节省调用者的时间,系统调用也是要花费时间的。
🔍缓冲区在哪?
在你进行fopen打开文件时,你会得到一个FILE的结构体,缓冲区就在这个FILE结构体中。

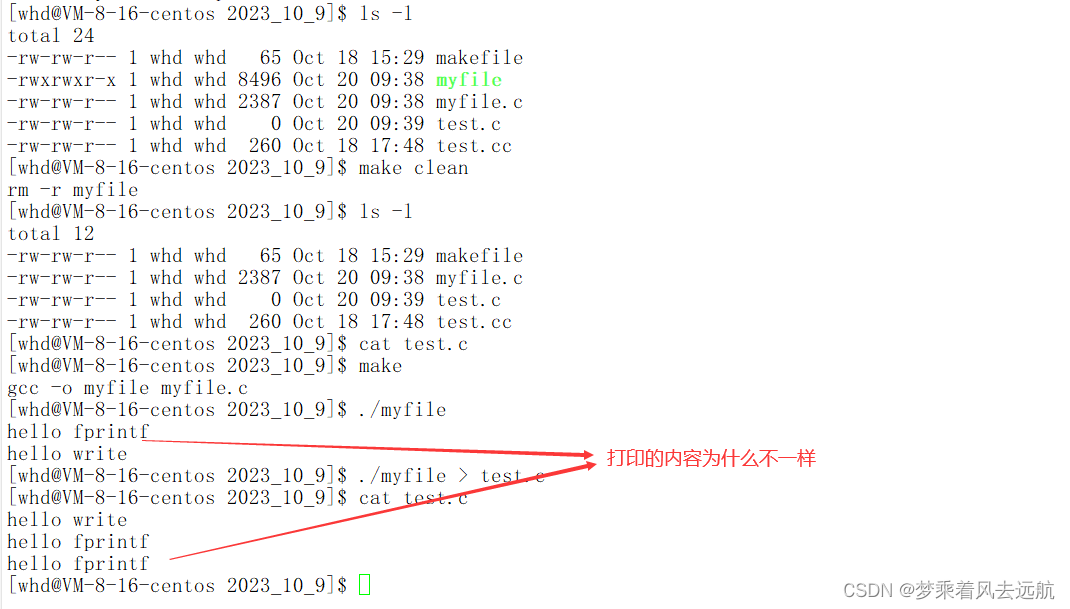
🔍为什么出现这种现象?
首先write是系统调用接口,它不属于C标准库,调用直接写入到操作系统了。fprintf是C标准库函数,它写入数据是先写入到C标准库的的缓冲区中,然后在写入的操作系统中。
一般C库函数写入文件时是全缓冲的,而写入显示器是行缓冲。
-
当写向显示器
写入显示器是行缓冲,fork之前,write fprintf已经刷新完了。 -
当重定向到文件中
printf fwrite库函数会自带缓冲区,当发生重定向到普通文件时,数据的缓冲方式变成了全缓冲。而我们放在缓冲区中的数据,就不会被立即刷新,甚至fork之后但是进程退出之后,会统一刷新,写入文件当中。但是fork的时候,父子数据会发生写时拷贝,所以当你父进程准备刷新的时候,子进程也就有了同样的一份数据,随即产生两份数据。
write函数直接写入到操作系统中。
文件系统
文件根据有没被打开可分为,打开的文件存在于内存又称为内存文件,没打开的文件存在于磁盘又称为磁盘文件,下面我们来谈谈磁盘文件。
文件 = 内容 + 属性;
Linux操作系统的文件是将内容和属性分离的。
inode
文件储存在硬盘上,硬盘的最小存储单位叫做”扇区”(Sector)。每个扇区储存512字节(相当于0.5KB)。
操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个”块”(block)。这种由多个扇区组成的”块”,是文件存取的最小单位。”块”的大小,最常见的是4KB,即连续八个 sector组成一个 block。
文件数据都储存在”块”中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为”索引节点”。
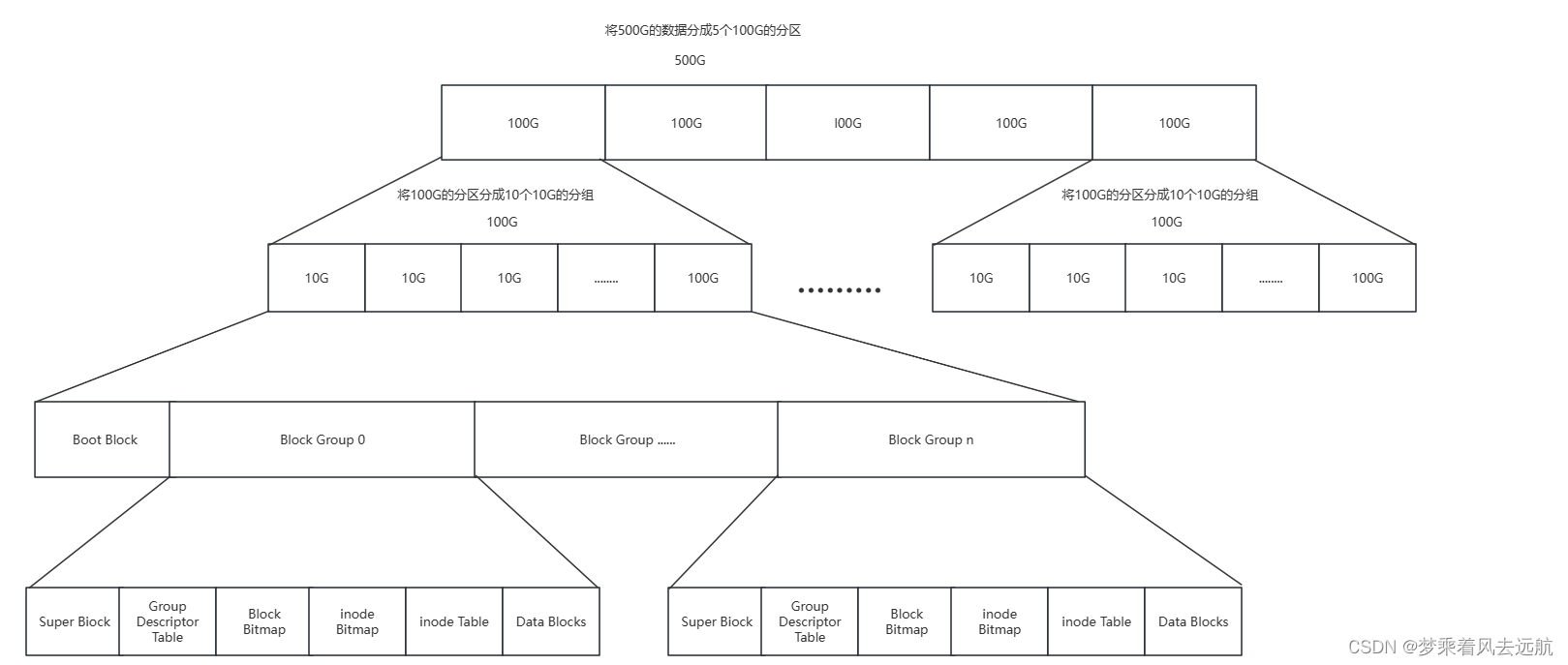
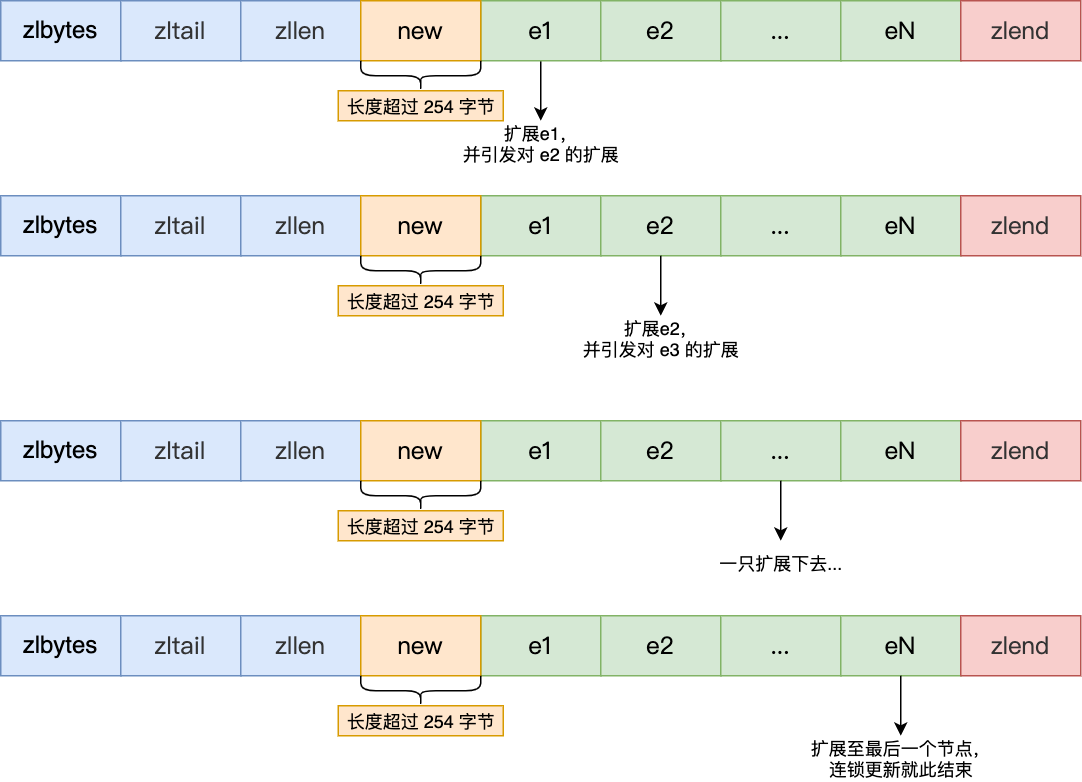
Linux ext2文件系统,上图为磁盘文件系统图(内核内存映像肯定有所不同),磁盘是典型的块设备,硬盘分区被划分为一个个的block。
Boot Block :启动块,大小为1kb,由pc标准规定的,用来存储磁盘分区信息和启动信息,任何文件系统都不能操作该块.
Block Group :ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相同的结构组成.
超级块(Super Biock): 文件系统的所有属性信息包括文件系统的类型,文件系统整个分组的情况,Super Biock在各个分组里面可能都会存在,而且是统一更新的,是为了防止Super Biock区域坏掉。如果出现故障,整个分区不可以被使用,所以做好备份保护数据安全。它是多副本保证分区安全的策略。
Group Descriptor Table(简称GDT):组描述符,描述组属性信息,描述group内各个位置存储的信息,如Block Bitmap的起始位置和length等等
inode Table:一个文件,内部所有属性的集合用inode节点(128字节)表示,这个inode节点保存该文件所以集合属性。一个文件,一个inode。一个分组,内部也会存在大量的文件即会存在大量的inode节点。一个组区域,来专门保存该group内的所有文件的inode节点的称为 inode table也称为(inode表)。分组内部可能会存在多个inode,需要将inode区分开来, 每一个inode都会有自己的inode编号,inode编号,也属于对应文件的属性id。
Data Blocks:我们是用数据块来进行文件内容的保存的,所以一个有效文件,要保存内容,就需要[1, n]数据块,即使要保存的数据是一个字节,也要开一数据块,如果有多个文件呢?需要更多的数据块。可以将Data Blocks看做一个特别大的数组,数组的每个元素的大小是4KB数据块,所以Data Blocks就是存放所有分组文件中,用到的所有数据块。Linux查找一 个文件,是要根据inode编号,来进行文件查找的,包括读取内容! !都是根据inode编号,找到inode节点就是结构体,结构体内部会有一块地址存放Data Blocks数组的下标,这些下标所对应的数据块,就是个文件的内容。一个inode对应一 个文件,该文件inode属性和该文件对应的数据块,是有映射关系的。
inode Bitmap(inode位图):每个bit为表示node Table表中的一个inode是否空闲可用。
Block Bitmap:每个bit为表示Data Blocks数组中的下标是否空闲可用。
[whd@VM-8-16-centos 2023_10_9]$ ls -il
total 32
1572945 drwxrwxr-x 2 whd whd 4096 Oct 22 08:51 list
1314304 -rw-rw-r-- 1 whd whd 65 Oct 18 15:29 makefile
1314306 -rwxrwxr-x 1 whd whd 8496 Oct 20 09:40 myfile
1314302 -rw-rw-r-- 1 whd whd 2387 Oct 20 09:38 myfile.c
1314303 -rw-rw-r-- 1 whd whd 40 Oct 20 09:40 test.c
1314305 -rw-rw-r-- 1 whd whd 260 Oct 18 17:48 test.cc
[whd@VM-8-16-centos 2023_10_9]$

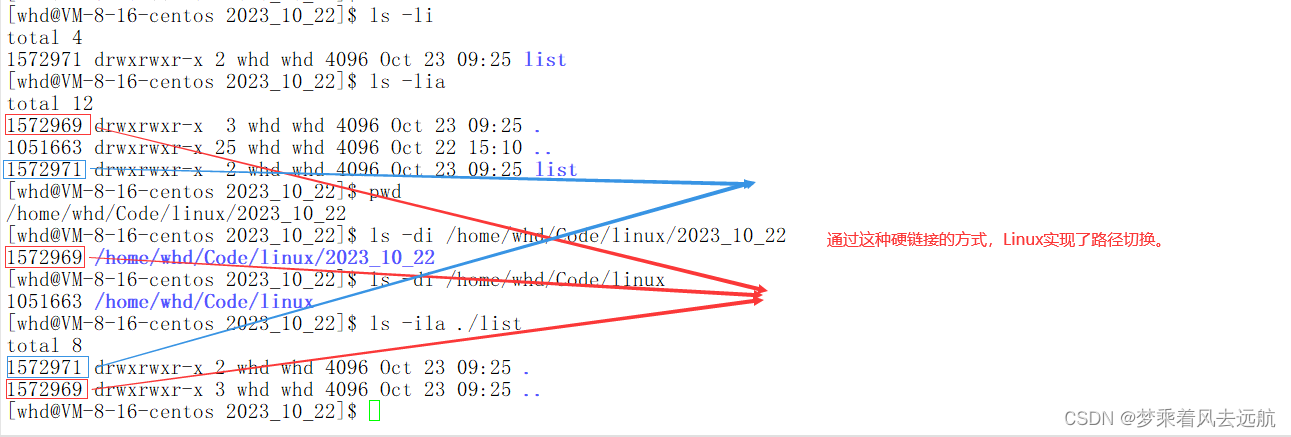
Linux系统只认inode编号,文件的inode属性中, 并不存在文件名。文件名是给用户用的。
任何一个文件,一定在一个目录内部,目录的数据块里面保存的是该目录下文件名和文件inode编号对应的映射关系,而且在目录内,文件名和inode是KV关系。
当我们访问一个文件的时候,我们是在特定目录下访问的比如(cat test.c)先要在当前目录下,找到test.c的inode编号。一个目录也是一个文件,也一定隶属于一个分区, 结合inode, 在该分区中找到分组, 在该分组中inode table中,找到文件的inode。通过inode和对应的data block的映射关系,找到改文件的数据块,并加载到OS,并完成显示到显示器。
🔍Linux如何删除文件?
- 根据文件名找到inode number(inode编号)。
- inode number找到inode属性中存放的该文件使用Data Blocks数据块的编号,根据编号将设置block bitmap对应的比特位置0即。删除内容。
- inode number设置inode bitmap对应的比特位设置为0。删除属性。
- 所以删文件只需要需改位图即可。
inode number是在一个分区内唯一有效的,不能跨分区。
🔍有没有可能,一个分组,数据块没用完,inode没了,或者inode没用完,data block用完了?
有可能,因为inode Bitmap和Block Bitmap是固定大小的。但是没办法解决。
软硬链接
软链接
ln -s myfile.txt my-soft 后者链接前者。
软连接:类似于windows的快捷键,是一个将路径很长的可执行程序,链接到当前路径下,以方便快速执行。

软连接是一个独立的连接文件,有自己的inode number, 必有自己的inode属性和内容。
软连接的文件内部放的是自己所指向文件的路径。所以软链接的文件大小才不一样。
硬链接
ln myfile.txt my-hard后者链接前者。

硬链接和目标文件公用同一个inode number,意味着硬链接一定是和目标文件使用同一个inode
硬链接没有独立的inode。
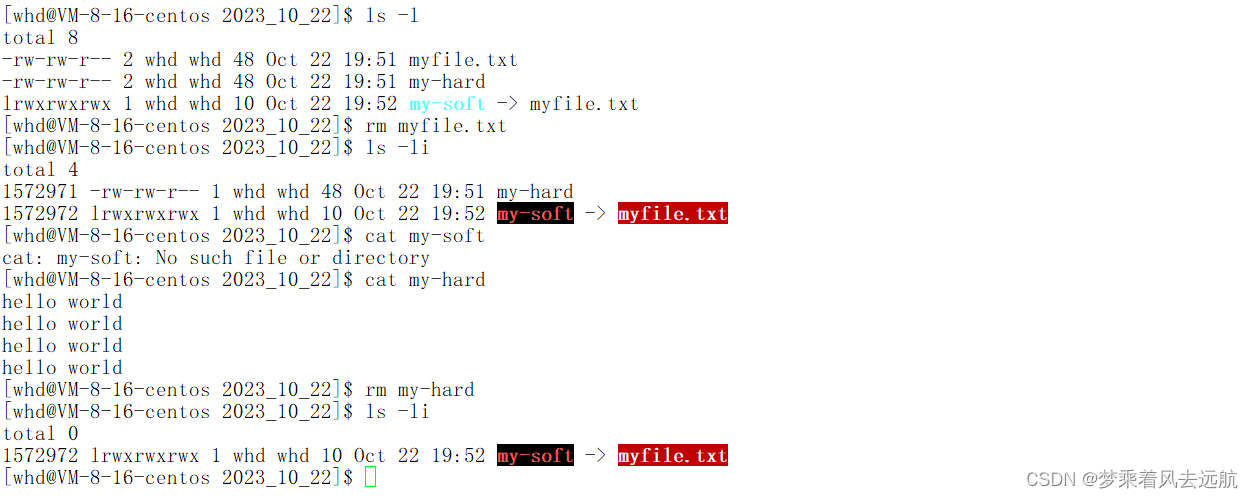
🔍那硬链接究竟干了什么?
建立了新的文件名与旧文件的inode的映射关系,同时将新文件与旧文件映射的同一inode结构体,inode结构体中硬链接数++,如果删除关联这个inode结构体的其中一个文件,inode结构体中硬链接数–,只有inode结构体中硬链接数为0时才是删除,这个硬链接数本质上是引用计数。
LInux不能给目录建立硬链接?

因为容易造成环路问题,比如find查找文件时。
动态库和静态库
- 静态库(.a):是指编译链接时,把库文件的代码全部复制加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。
- 动态库(.so):程序在运行的时候才去链接动态库的代码,一个与动态库链接的可执行文件仅仅包含它用到的函数入口地址的一个表,而不是外部函数所在目标文件的整个机器码
- 动态库可以在多个程序间共享,所以动态链接使得可执行文件更小,节省了磁盘空间。操作系统采用虚拟内存机制允许物理内存中的一份动态库被要用到该库的所有进程共用,节省了内存和磁盘空间。
动静态库的命名方式

Linux动静库文件必须以lib开头 + 文件名 + .(必须是第一个.后跟,如果是动态库so,如果是静态库a)。
头文件

源文件
目标文件
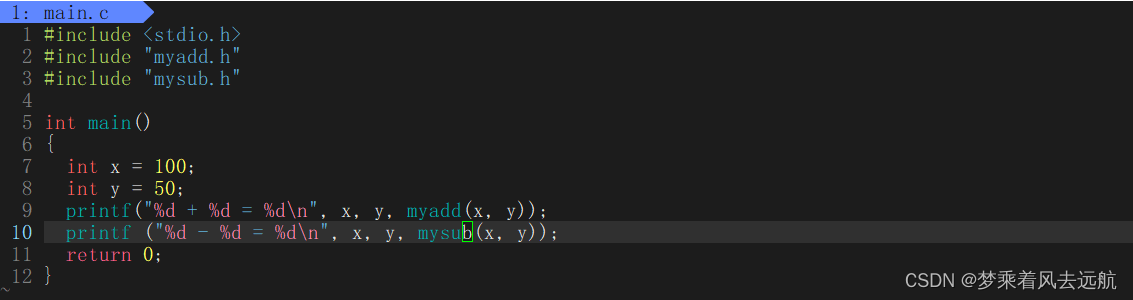
gcc编译第三方库需要携带的三个选项
-I:指定头文件的搜索路径-L:指定库文件的搜索路径-l:指定库文件的名称,只要库名即可(去掉lib,版本号以及后缀)
静态库
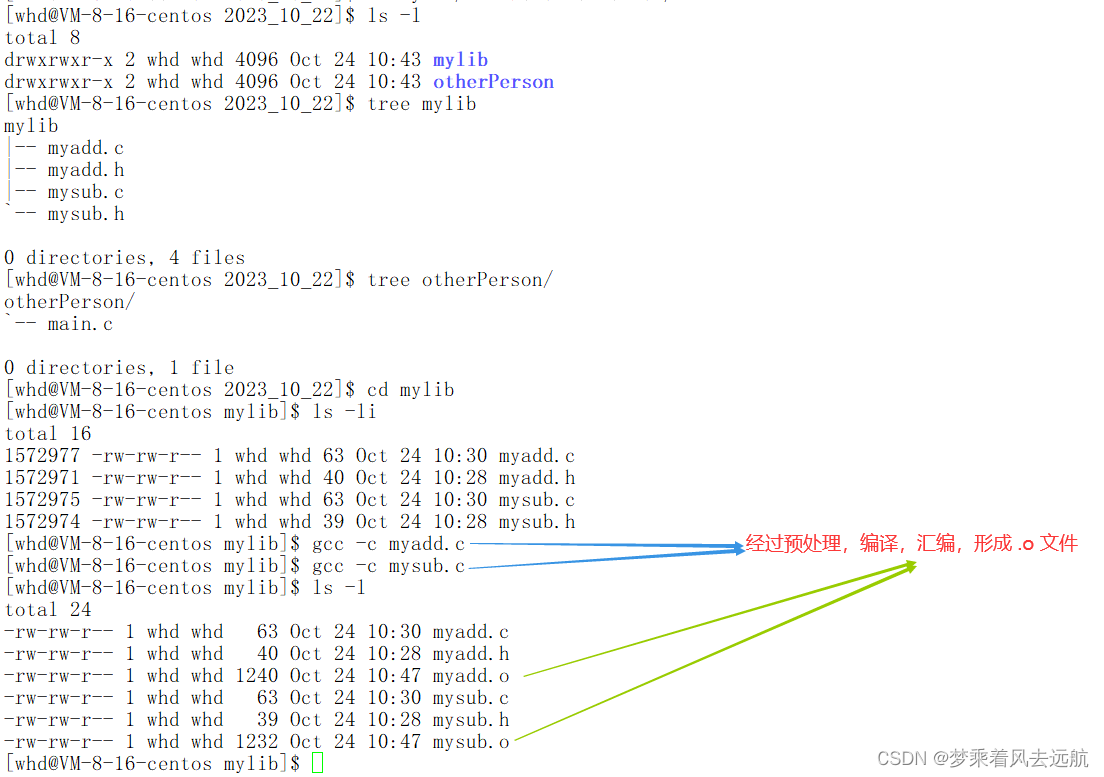
制作一个库
制作一个库必须是经过,预处理,编译,汇编的.o文件。
ar -rc libXXXXX.a *.o
使用库
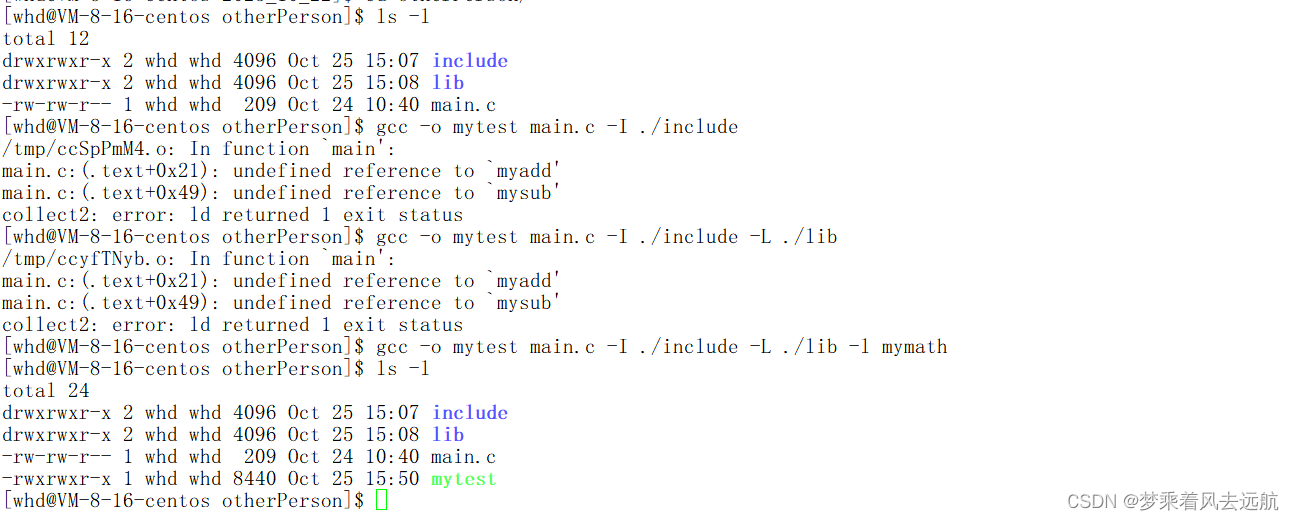
gcc -o mytest main.c -I ./include -L ./lib -l mymath
🔍第三方库的使用。
1.需要指定的头文件,和库文件
2.如果没有默认安装到系统gcc、g+ +默认的搜索路径下,用户必须指明对应的选项,告知编译器: a. 头文件在哪里b.库文件在哪里c.库文件具体是谁
3.将我们下载下来的库和头文件,拷贝到系统默认路径下----在Linux下安装库! ! 那么卸载呢? ?对任何软件而言,安装和卸载的本质就是拷贝到系统特定的路径下
4.如果我们安装的库是第三方的(语言(第一方库),操作系统系统接口(第二方库))库,我们要正常使用,即便是已经全部安装到了系统中,gcc/g++必须用-I指明具体库的名称
动态库
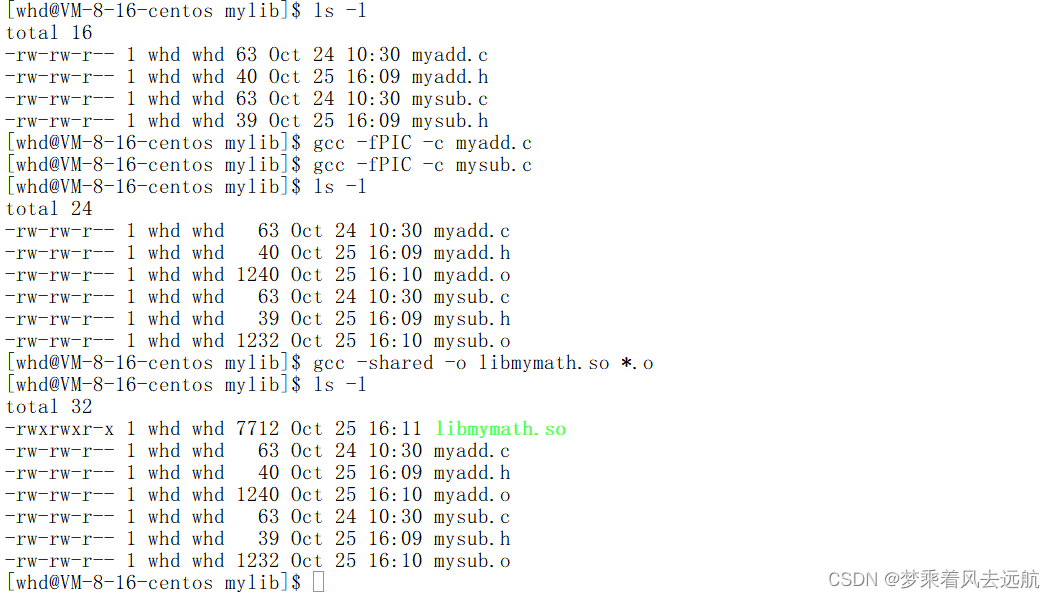
制作一个库
制作一个库必须是经过,预处理,编译,汇编的.o文件。
生成动态库
- fPIC:产生位置无关码(position independent code)
gcc -fPIC -c (.c文件) - shared: 表示生成共享库格式
gcc -shared -o libxxxx.so (经过预处理,编译,汇编的.o文件)
使用库
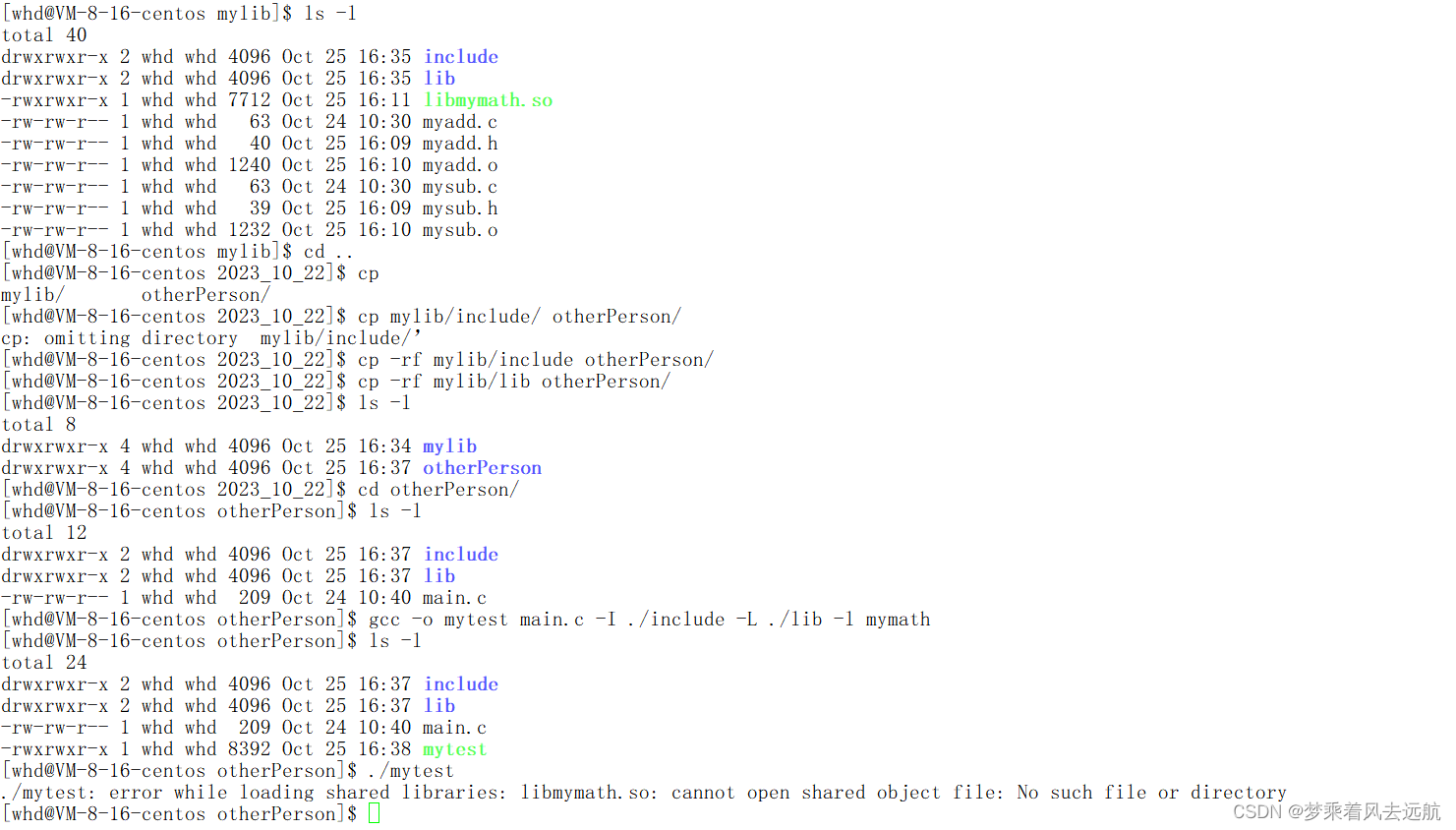
gcc -o mytest main.c -I ./include -L ./lib -l mymath
这条指令,告诉gcc编译器,头文件的路径,指定库的路径,指定库的名称。
./mytest
包含动态库的可执行程序,在运行时要链接动态库。./mytest在运行时,要链接动态库。OS找不到所需的动态库在哪里,所以才运行出错。

🔍运行时OS是如何查找动态库呢?
- 更改
LD_LIBRARY_PATH(临时方案)
LD_LIBRARY_PATH是OS链接动态库时搜索的路径,我们只需要将自己制作的动态库所在的目录追加到LD_LIBRARY_PATH环境变量中即可。
注意这种方法只是临时的,当你重新进入会话时这个环境变量,还需要重新添加。
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:自己制作的动态库所在的路径

- 拷贝.so动态库文件的系统的默认搜索路径下或建立软链接。
建立软连接将自己制作的动态库,链接到系统的默认搜索路径下/lib64
sudo ln -s /home/whd/Code/linux/2023_10_22/otherPerson/lib/libmymath.so /lib64/libmymath.so - 配置
/etc/ld.so.conf.d/,ldconfig更新。
/etc/ld.so.conf.d/:目录中放的是动态链接库的配置文件。配置文件的命名可以自定义,配置文件中放动态库的绝对路径。

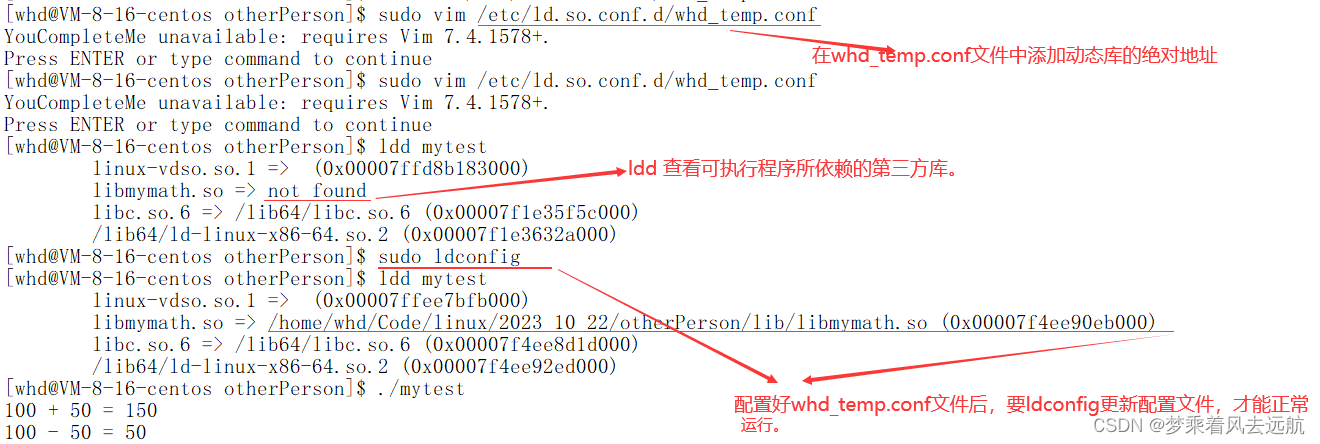
操作系统这三种方案其实它都是会查找处理的。
🔍为什么静态库就能找到?
链接原则:将用户使用的二进制代码直接拷贝到目标可执行程序中! 但是动态库不会!





![释放搜索潜力:基于ES(ElasticSearch)打造高效的语义搜索系统,让信息尽在掌握[1.安装部署篇],支持Linux/Windows部署安装](https://img-blog.csdnimg.cn/d553c7dadca54bdb82a3a234befb74d8.png#pic_center)